
Dual-Layer Fusion Model Using Bayesian Optimization for Asphalt Pavement Condition Index Prediction


Abstract
1. Introduction
- Insufficient multimodal feature fusion.
- Limited data-driven effectiveness.
- Bottlenecks in model generalization capability.
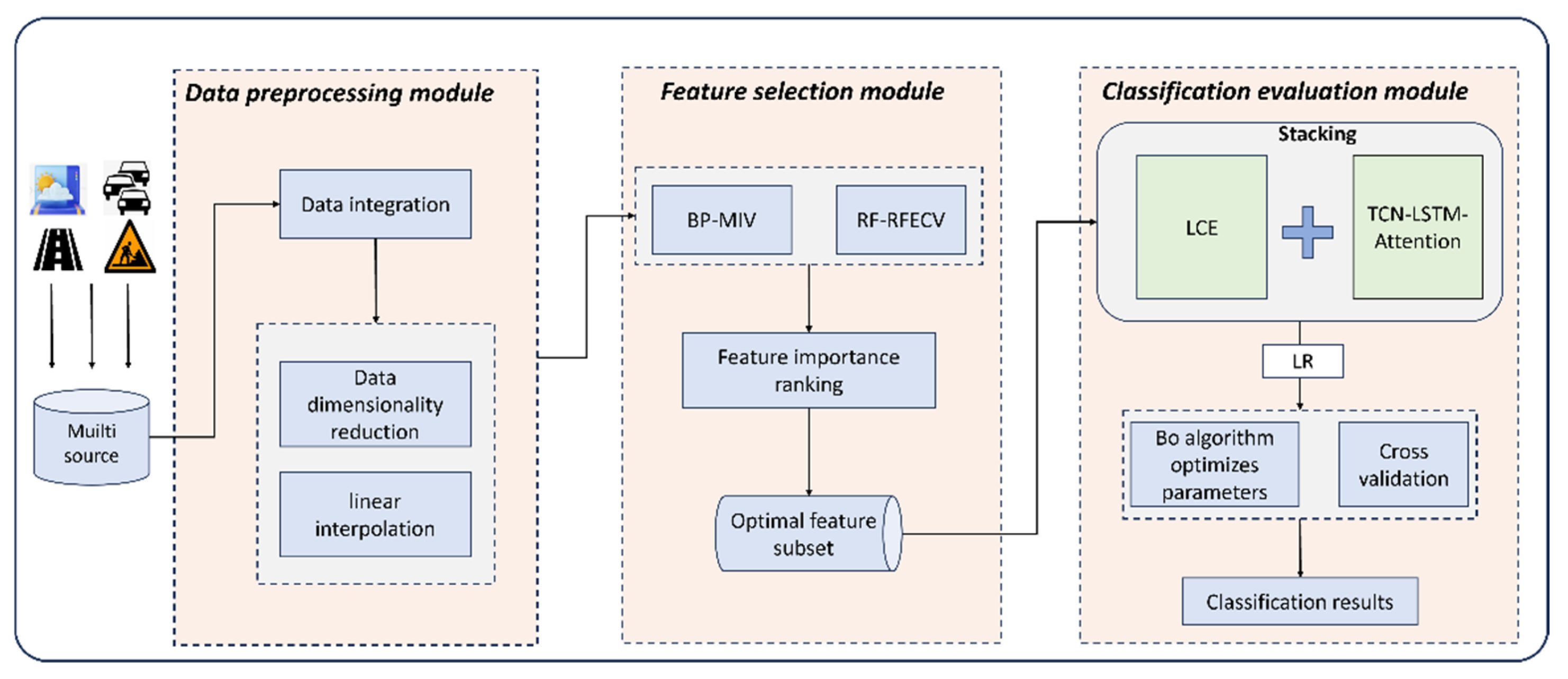
2. BO-DLFF Model Construction
- Innovative Dual-Layer Fusion Strategy
- Design a hybrid tree–neural framework
- Bayesian meta-learning optimization
2.1. First-Layer Fusion Strategy
2.1.1. Module 1: LCE Ensemble Learning Model
- Data partitioning and preprocessing
- Cascade generalization
- Bagging integration
- Prediction aggregation
- Model training and optimization
2.1.2. Module 2: TCN-LSTM-ATT Model
- TCN Network Structure
- Temporal Attention Mechanism
- LSTM Network Structure
2.2. Second Layer Fusion Strategy
2.3. Bayesian Optimization
2.4. DLFF Model Based on the BO Algorithm
| Algorithm 1 BO-DLFF model pavement breakage condition prediction algorithm |
| Input dataset X, y |
| Divide the data set: training set and test set |
| Step1: One layer base learner training |
| for t ← 1 to 2 do |
| if t = 1 then |
| Base Learner 1: LCE |
| Parameter: optimization by BO algorithm |
| else if t = 2 then |
| Base Learner 2: TCN-LSTM-ATT |
| Parameters: optimization by BO |
| Step2: Base Learner Generate Layer 2 Dataset |
| Perform the following operations for each base learner: |
| Train using the training set |
| Predict the training and test sets using the base learner |
| Generate new feature sets (base training feature set, base test feature set) |
| Step3: Build and train the two-layer meta-learner |
| Define the meta-learner: |
| Meta-learner: logistic regression |
| Use the meta-learner to train on the new training meta-feature set |
| Step4: Evaluate model performance |
| Use the meta-learner to make predictions on the tested set of meta-features |
| Output the prediction results |
3. Data Sources
3.1. Multi-Source Dataset Construction
3.2. Analysis of Factors Influencing Multi Source Features
3.2.1. BP-MIV Method
3.2.2. RF-RFECV Method
4. Comparison and Analysis of Results
4.1. Model Training Software and Hardware Environment
4.2. Model Performance Evaluation Metrics
4.3. Results Analysis
4.3.1. BO-DLFF Model Performance
4.3.2. Comparative Analysis of Predictive Models
4.3.3. Ablation Studies
- Ablation Study 1: Rationale for LCE Model Selection
- Ablation Study 2: Exploring the Role of Each Component in the TCN-LSTM-ATT Module
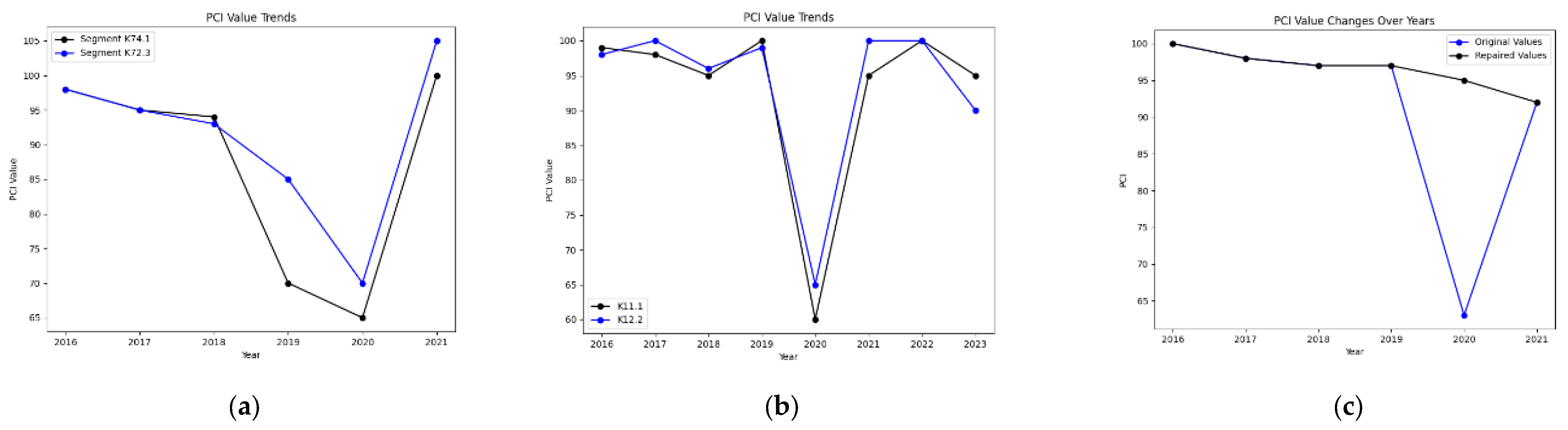
4.3.4. Example Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Gong, H.; Jia, X.; Xiao, R.; Jiang, X.; Ma, Y.; Huang, B. Analysis of critical factors to asphalt overlay performance using gradient boosted models. Constr. Build. Mater. 2020, 262, 120083. [Google Scholar] [CrossRef]
- Shahin, M.Y. Pavement Management for Airports, Roads, and Parking Lots; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Kang, J.; Tavassoti, P.; Chaudhry, M.N.A.R.; Baaj, H.; Ghafurian, M. Artificial intelligence techniques for pavement performance prediction: A systematic review. Road Mater. Pavement Des. 2025, 26, 497–522. [Google Scholar] [CrossRef]
- Butt, A.A.; Shahin, M.Y.; Carpenter, S.H.; Carnahan, J.V. Application of markov process to pavement management systems at network level. In Proceedings of the Third International Conference on Managing Pavement, San Antonio, TX, USA, 22–26 May 1994. [Google Scholar]
- Yang, J.; Gunaratne, M.; Lu, J.J.; Dietrich, B. Use of recurrent Markov chains for modeling the crack performance of flexible pavements. J. Transp. Eng. 2005, 131, 861–872. [Google Scholar] [CrossRef]
- Yang, L.; Qian, Z.; Hu, H. Thermal field characteristic analysis of steel bridge deck during high—Temperature asphalt pavement paving. KSCE J. Civ. Eng. 2016, 20, 2811–2821. [Google Scholar]
- Chen, H.; Saba, R.G.; Liu, G.; Barbieri, D.M.; Zhang, X.; Hoff, I. Influence of material factors on the determination of dynamic moduli and associated prediction models for different types of asphalt mixtures. Constr. Build. Mater. 2023, 365, 130132. [Google Scholar] [CrossRef]
- Zhang, X.; Ji, C. Asphalt pavement roughness prediction based on gray GM (1, 1|sin) model. Int. J. Comput. Intell. Syst. 2019, 12, 897–902. [Google Scholar] [CrossRef]
- Tang, L.; Xiao, D. Monthly attenuation prediction for asphalt pavement performance by using GM (1, 1) model. Adv. Civ. Eng. 2019, 2019, 9274653. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, J.; Wang, K.; Liu, Y.; Wang, Y. Research on performance prediction of highway asphalt pavement based on grey–markov model. Transp. Res. Rec. 2022, 2676, 194–209. [Google Scholar] [CrossRef]
- Ziari, H.; Maghrebi, M.; Ayoubinejad, J.; Waller, S.T. Prediction of Pavement Performance: Application of Support Vector Regression with Different Kernels. Transp. Res. Rec. J. Transp. Res. Board 2016, 2589, 135–145. [Google Scholar] [CrossRef]
- Chen, Y.; Li, F.; Zhou, S.; Zhang, X.; Zhang, S.; Zhang, Q.; Su, Y. Bayesian optimization based random forest and extreme gradient boosting for the pavement density prediction in GPR detection. Constr. Build. Mater. 2023, 387, 131564. [Google Scholar] [CrossRef]
- Li, S.; Shang, Q.; Tian, B. Research on Pavement Skid Resistance Performance Prediction Model Based on Big Data Analysis and XGBoost Algorithm. In Proceedings of the FSDM, Kitakyushu City, Japan, 18–21 October 2019; pp. 558–563. [Google Scholar]
- Gupta, A.; Gowda, S.; Tiwari, A.; Gupta, A.K. XGBoost-SHAP framework for asphalt pavement condition evaluation. Constr. Build. Mater. 2024, 426, 136182. [Google Scholar] [CrossRef]
- Pei, L.; Yu, T.; Xu, L.; Li, W.; Han, Y. Prediction of decay of pavement quality or performance index based on light gradient boost machine. In Proceedings of the International Conference on Intelligent Automation and Soft Computing, Chicago, IL, USA, 26–28 May 2021; Springer: Cham, Switzerland; pp. 1173–1179. [Google Scholar]
- Guo, F.; Qian, Y. Intelligent Pavement Roughness Forecasting Based on a Long Short-Term Memory Model with Attention Mechanism. In Airfield and Highway Pavements 2021; ASCE Press: Reston, VA, USA, 2021; pp. 128–136. [Google Scholar]
- Jalal, M.; Floris, I.; Quadrifoglio, L. Computer-aided Prediction of Pavement Condition Index (PCI) Using ANN. In Proceedings of the International Conference on Computers and Industrial Engineering, Hong Kong, China, 15–17 March 2017. [Google Scholar]
- Sidess, A.; Ravina, A.; Oged, E. A model for predicting the deterioration of the pavement condition index. Int. J. Pavement Eng. 2021, 22, 1625–1636. [Google Scholar] [CrossRef]
- Inkoom, S.; Sobanjo, J.; Barbu, A.; Niu, X. Prediction of the crack condition of highway pavements using machine learning models. Struct. Infrastruct. Eng. 2019, 15, 940–953. [Google Scholar] [CrossRef]
- Zhang, M.; Zhu, F. Study on Multi-index Prediction Method of Asphalt Pavement Performance Based on the Improved GM(1,1) Model. Highw. Transp. Inn. Mong. 2018, 64, 372–380. [Google Scholar]
- Yao, L.; Dong, Q.; Jiang, J.; Ni, F. Establishment of Prediction Models of Asphalt Pavement Performance based on a Novel Data Calibration Method and Neural Network. Transp. Res. Rec. 2019, 2673, 66–82. [Google Scholar] [CrossRef]
- Tabatabaee, N.; Ziyadi, M.; Shafahi, Y. Two-stage support vector classifier and recurrent neural network predictor for pavement performance modeling. J. Infrastruct. Syst. 2012, 19, 266–274. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, J.; Liu, T.; Wang, Y.; Pei, J.; Wang, P. Using PSO-SVR Algorithm to Predict Asphalt Pavement Performance. J. Perform. Constr. Facil. 2021, 35, 04021094. [Google Scholar] [CrossRef]
- Dong, Y.; Shao, Y.; Li, X.; Li, S.; Quan, L.; Zhang, W.; Du, J. Forecasting pavement performance with a feature fusion LSTM-BPNN model. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1953–1962. [Google Scholar]
- Xiao, M.; Luo, R.; Chen, Y.; Ge, X. Prediction model of asphalt pavement functional and structural performance using PSO-BPNN algorithm. Constr. Build. Mater. 2023, 407, 133532. [Google Scholar] [CrossRef]
- Wang, Y.; Li, C.; Wang, X. A multi-source information fusion layer counting method for penetration fuze based on TCN-LSTM. Def. Technol. 2024, 33, 463–472. [Google Scholar] [CrossRef]
- Yang, Y.; Han, L.; Qiu, C.; Zhao, Y. A short-term wave energy forecasting model using two-layer decomposition and LSTM-attention. Ocean Eng. 2024, 299, 117279. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Banik, R.; Biswas, A. Enhanced renewable power and load forecasting using RF-XGBoost stacked ensemble. Electr. Eng. 2024, 106, 4947–4967. [Google Scholar] [CrossRef]
- Scalable Optimization via Probabilistic Modeling: From Algorithms to Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006.
- Ministry of Transport of the People’s Republic of China, JTG-H20-2018 Evaluation Standards for Highway Technical Status on. 2018. Available online: https://xxgk.mot.gov.cn/2020/jigou/glj/202006/t20200623_3313112.html (accessed on 11 April 2025).
- Vamsi, D.; Harinder, D. Assessment of Performance and Maintenance of Flexible Pavement Using KENLAYER and HDM-4. J. Manag. Sci. Eng. Res. 2022, 982, 01205. [Google Scholar] [CrossRef]
- Huang, D.; Jiang, F.; Li, K.; Tong, G.; Zhou, G. Scaled PCA: A new approach to dimension reduction. Manag. Sci. 2022, 68, 1678–1695. [Google Scholar] [CrossRef]
- Bonett, D.G.; Wright, T.A. Sample size requirements for estimating pearson, spearman and kendall correlations. Psychometrika 2000, 65, 23–28. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Learner | Parameter Values |
|---|---|
| LCE | n_estimators = 224, max_features = 27, max_depth = 9 |
| TCN-LSTM-ATT | filters = 32, kernel_size = 3 × 3, neurons = 50 batchsize = 64, learn_rate = 0.001, epochs = 100 |
| Feature Category | Feature Name | Description | Data Type | Time Granularity | Spatial Granularity |
|---|---|---|---|---|---|
| Road Basic Info | Road Age | Number of years since the road was built and put into service | Numerical | Year | 100 m Road Section |
| Layer Thickness | Thickness of each layer of the pavement (upper, middle, lower layers) | Numerical | Static | 100 m Road Section | |
| Climate Data | Monthly Max Temp Mean | Average of the highest temperature each month | Numerical | Month | 100 m Road Section |
| Monthly Min Temp Mean | Average of the lowest temperature each month | Numerical | Month | 100 m Road Section | |
| Annual Avg Temperature | Average temperature for each year | Numerical | Year | 100 m Road Section | |
| Annual Dew Point Temp | Average dew point temperature for each year | Numerical | Year | 100 m Road Section | |
| Monthly Rainfall | Rainfall for each month | Numerical | Month | 100 m Road Section | |
| Annual Rainfall | Total rainfall for each year | Numerical | Year | 100 m Road Section | |
| Traffic Data | Monthly Vehicle Equiv | Equivalent number of vehicles for each month | Numerical | Month | 100 m Road Section |
| Monthly Passenger Ratio | Ratio of passenger vehicles to freight vehicles each month | Numerical | Month | 100 m Road Section | |
| Annual Vehicle Equiv | Equivalent number of vehicles for each year | Numerical | Year | 100 m Road Section | |
| Pavement Damage | Longitudinal Crack Area | Area of longitudinal cracks per 100 m section | Numerical | Static | 100 m Road Section |
| Transverse Crack Area | Area of transverse cracks per 100 m section | Numerical | Static | 100 m Road Section | |
| Block Crack Area | Area of block cracks per 100 m section | Numerical | Static | 100 m Road Section | |
| Pothole Area | Area of potholes per 100 m section | Numerical | Static | 100 m Road Section | |
| Maintenance Data | Maintenance History | Historical maintenance records, including maintenance years and methods | Categorical | Year | 100 m Road Section |
| Feature Factors | Explanation |
|---|---|
| Transverse Cracks | Cracks across the traffic direction. |
| Longitudinal Cracks | Cracks along the traffic direction. |
| 2020 Maintenance | Road maintenance in 2020. |
| July Traffic Volume | Standardized traffic volume in July. |
| July Rainfall | Rainfall in July. |
| Ave. August High Temp | Average highest temperature in August. |
| Annual Traffic Volume | Annual total traffic volume. |
| Annual Rainfall | Annual rainfall and durability assessment. |
| July Dew Point Temp | Dew point temperature in July. |
| P Rainfall | Rainfall in a specific period. |
| February Traffic Volume | Traffic volume in February. |
| Patch Repair | Repairing diseases and restoring smoothness. |
| December Traffic Volume | Year-end traffic and flow impact. |
| January Rainfall | Winter climate and rainfall. |
| Jan. Low Temp Average | Low temperature and cracking risk. |
| April Traffic Volume | Traffic volume in April. |
| Strip Repair | Repair of strip-shaped damaged areas. |
| Dec. Rainfall | Rainfall in December. |
| May Rainfall | Spring climate and rainfall. |
| 2022 Maintenance | Road maintenance in 2022. |
| Net Radiation Intensity | Net radiation difference. |
| Model | R2 | MAE | RMSE | MAPE |
|---|---|---|---|---|
| LSTM | 0.8207 | 1.4827 | 2.2545 | 1.57 |
| RF | 0.8211 | 1.3017 | 2.2521 | 1.40 |
| XGBoost | 0.8334 | 1.5191 | 2.1736 | 1.62 |
| TCN-LSTM-ATT | 0.9091 | 0.9457 | 1.6055 | 1.01 |
| LCE | 0.8931 | 1.0842 | 1.7405 | 1.17 |
| BO-RF | 0.8579 | 1.2438 | 2.0069 | 1.34 |
| BO-XGBoost | 0.8795 | 1.0920 | 1.8483 | 1.18 |
| BO-LCE | 0.9211 | 0.8027 | 1.4956 | 0.86 |
| Model | R2 | MAE | RMSE | MAPE |
|---|---|---|---|---|
| LightGBM | 0.7916 | 1.7235 | 2.2853 | 1.33 |
| BO-LightGBM | 0.8268 | 1.6467 | 2.1051 | 1.12 |
| RF | 0.8211 | 1.3017 | 2.2521 | 1.40 |
| BO-RF | 0.8579 | 1.2438 | 2.0069 | 1.34 |
| XGBoost | 0.8334 | 1.5191 | 2.1736 | 1.62 |
| BO-XGBoost | 0.8795 | 1.0920 | 1.8483 | 1.18 |
| LCE | 0.8931 | 1.0842 | 1.7405 | 1.17 |
| BO-LCE | 0.9211 | 0.8027 | 1.4956 | 0.86 |
| Model | TCN | LSTM | Attention | R2 | MAPE |
|---|---|---|---|---|---|
| Experiment 1 | × | √ | × | 0.8207 | 1.57 |
| Experiment 2 | √ | √ | × | 0.8397 | 1.42 |
| Experiment 3 | × | √ | √ | 0.8782 | 1.18 |
| Ours | √ | √ | √ | 0.9091 | 1.01 |
| Model | R2 | MAE | RMSE | MAPE |
|---|---|---|---|---|
| RF | 0.8267 | 0.1568 | 0.2047 | 1.59 |
| XGBoost | 0.8574 | 0.1423 | 0.1869 | 1.36 |
| TCN-LSTM-ATT | 0.8761 | 0.1357 | 0.1782 | 1.24 |
| LCE | 0.8912 | 0.1308 | 0.1675 | 1.18 |
| BO-DLFF | 0.9035 | 0.1257 | 0.1596 | 1.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, J.; Sun, Z.; Xing, Z.; Pei, L.; Feng, X. Dual-Layer Fusion Model Using Bayesian Optimization for Asphalt Pavement Condition Index Prediction. Sensors 2025, 25, 2616. https://doi.org/10.3390/s25082616
Hao J, Sun Z, Xing Z, Pei L, Feng X. Dual-Layer Fusion Model Using Bayesian Optimization for Asphalt Pavement Condition Index Prediction. Sensors. 2025; 25(8):2616. https://doi.org/10.3390/s25082616
Chicago/Turabian StyleHao, Jun, Zhaoyun Sun, Zhenzhen Xing, Lili Pei, and Xin Feng. 2025. "Dual-Layer Fusion Model Using Bayesian Optimization for Asphalt Pavement Condition Index Prediction" Sensors 25, no. 8: 2616. https://doi.org/10.3390/s25082616
APA StyleHao, J., Sun, Z., Xing, Z., Pei, L., & Feng, X. (2025). Dual-Layer Fusion Model Using Bayesian Optimization for Asphalt Pavement Condition Index Prediction. Sensors, 25(8), 2616. https://doi.org/10.3390/s25082616