

Real-Time Acoustic Detection of Critical Incidents in Smart Cities Using Artificial Intelligence and Edge Networks
 , ,
, ,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
2.1. Hardware Components
2.2. Software Components
2.2.1. Software at the Nodes
2.2.2. Software at the Gateway
2.2.3. The Training Database
2.3. Frontend Functionality
2.4. Graph Parsing
- Define primary and secondary sound categories from the available AudioSet ontology.
- Define the probability thresholds for primary and secondary labels.
- Define the duration of time windows for identifying high-level events.
- Read and parse the JSON file into a graph containing a list of labels of audio events. Events are sorted by their Device_ID and, subsequently, by their timestamps to enable time-sequential processing. Each event includes a timestamp, unique event ID, and associated audio events with class names and probabilities.
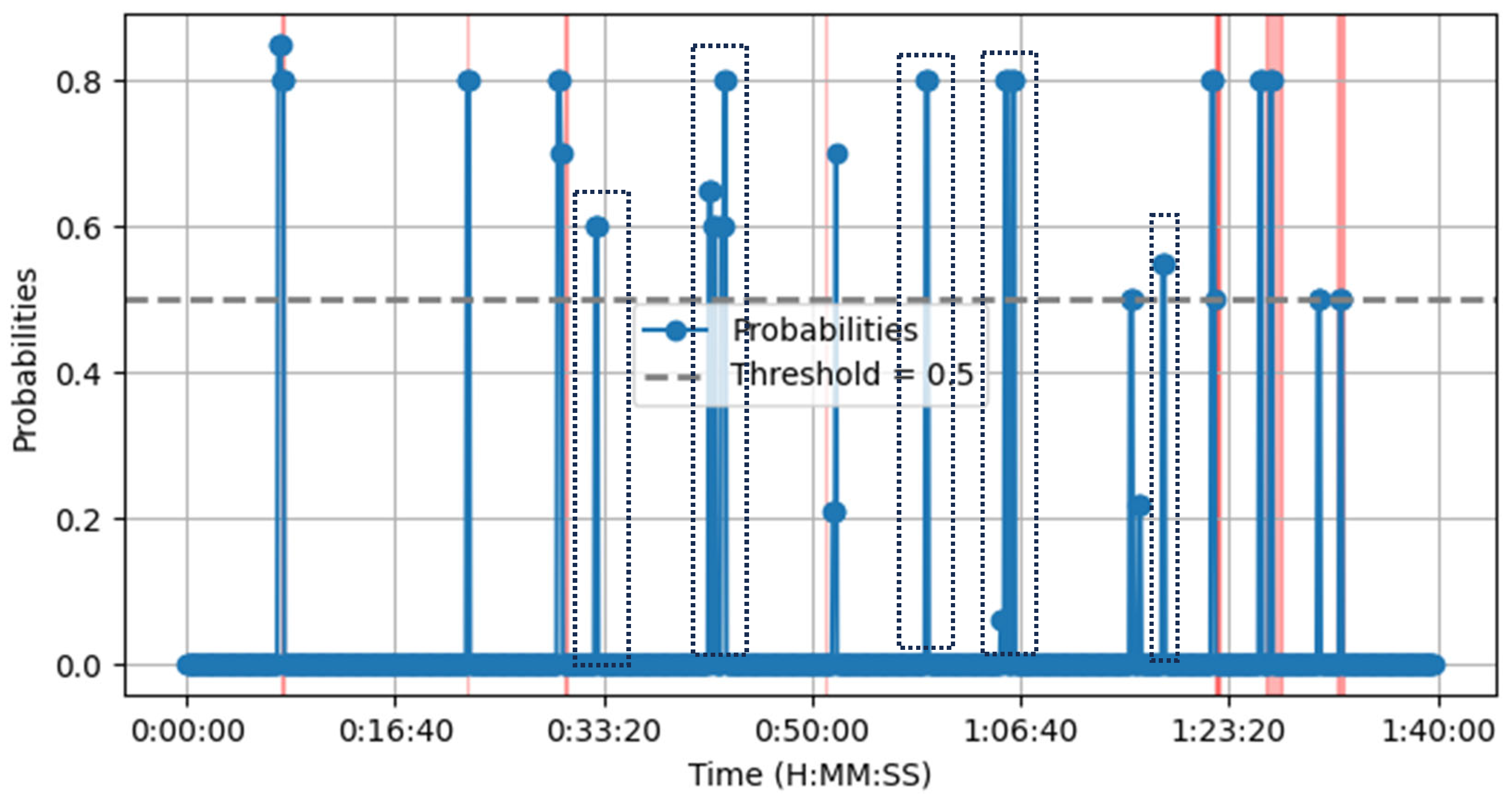
- A rolling window of events is maintained for analysis. For each event, the audio events are filtered based on a probability threshold, and their classes are compared with the primary and secondary sound categories.
- The primary and secondary scores are calculated by summing the probabilities of matching audio events within the time window. Older events outside the time window are removed from consideration.
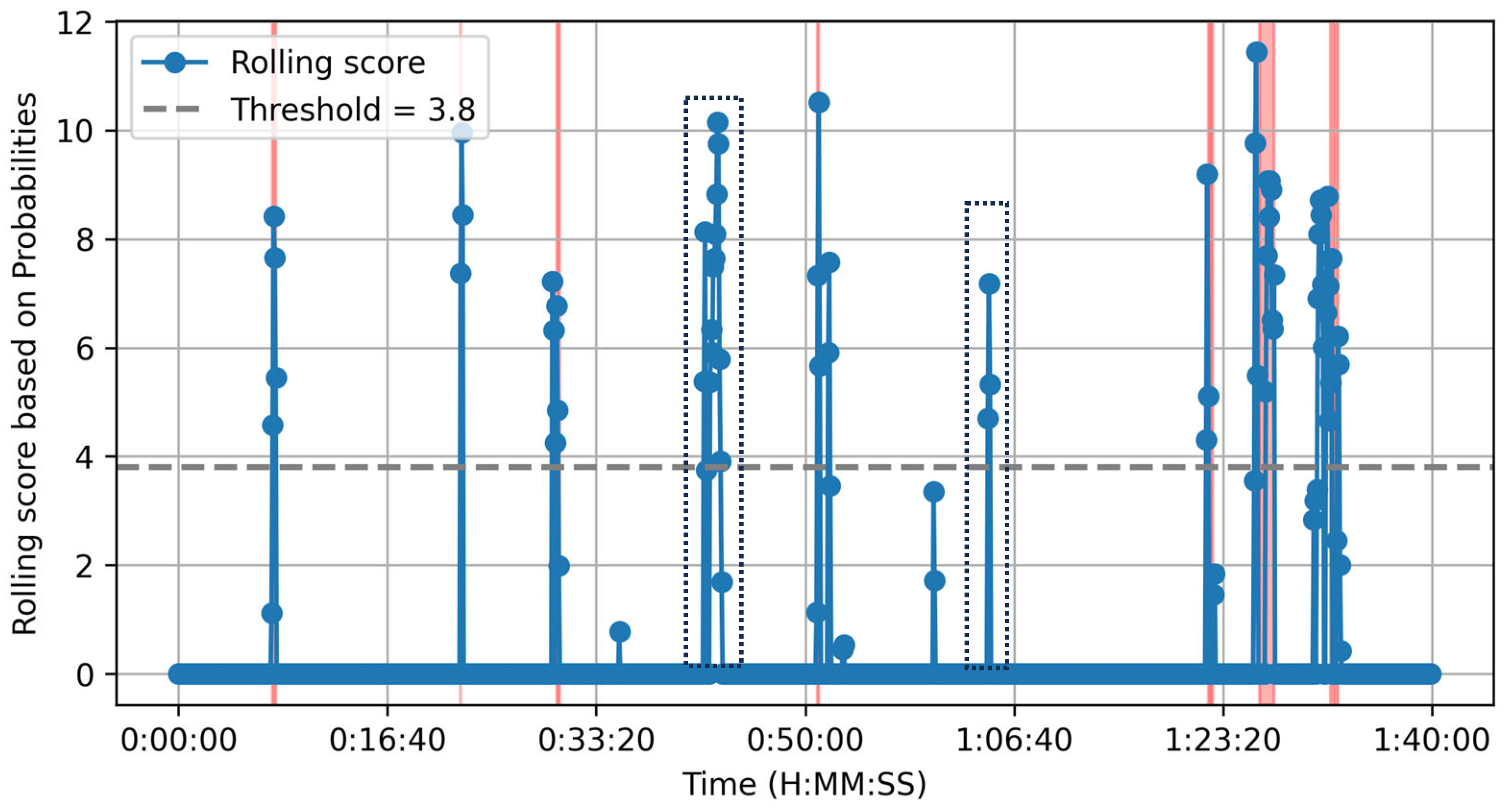
- If the total primary and secondary scores within the time window exceed predefined thresholds, a high-level event is identified. The events contributing to the high-level event are recorded, and their IDs are marked to avoid reprocessing. Subsequently, a classification object is created, including time window of detection, IDs of related events, classes of indicative audio events, and total primary and secondary scores. The classifications of detected high-level events are output to the console. For each high-level event, details such as the time window, related events, indicative classes, and scores are displayed.
2.5. Security Considerations
2.6. Network of Nodes and Distributed Incidents
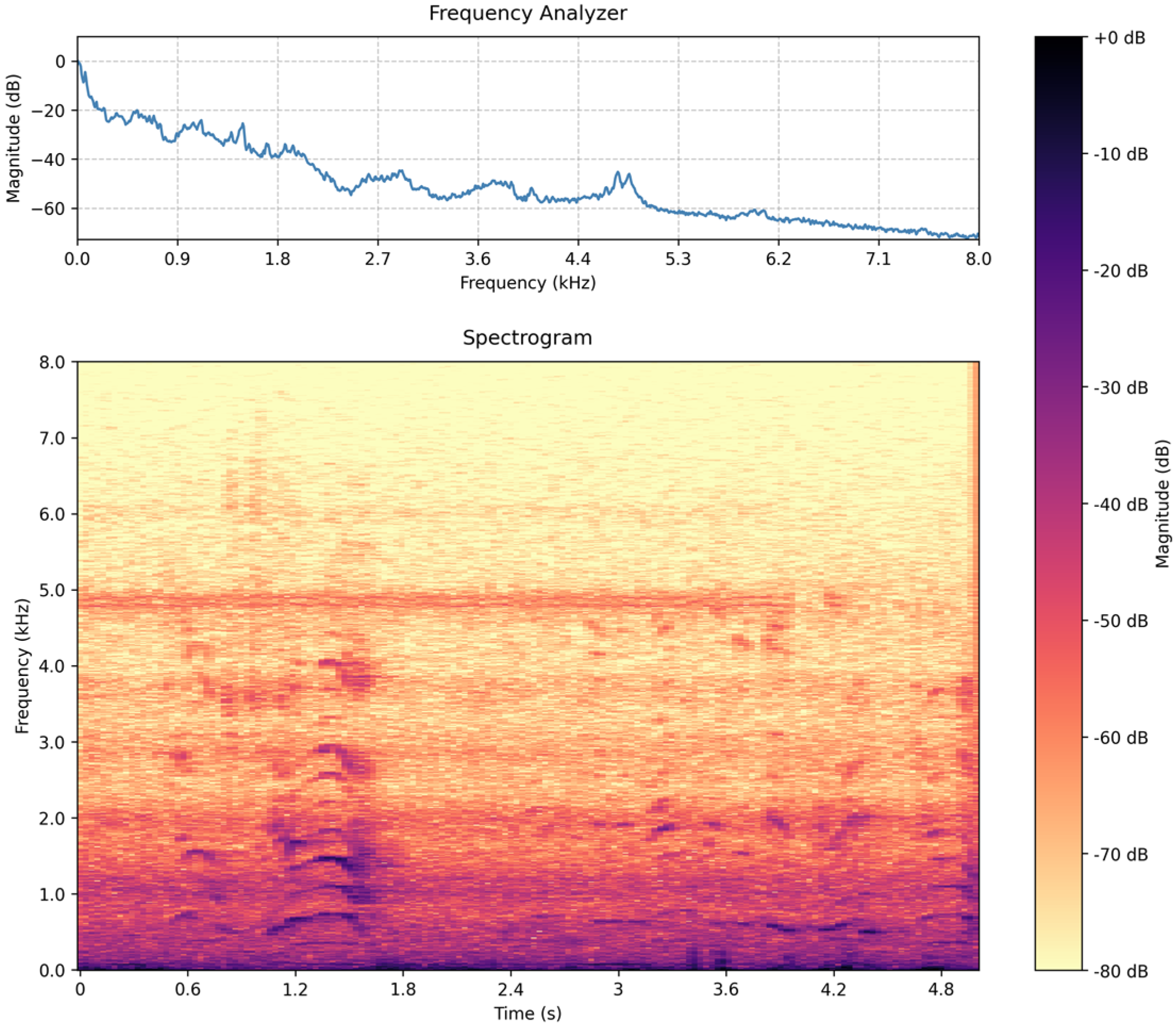
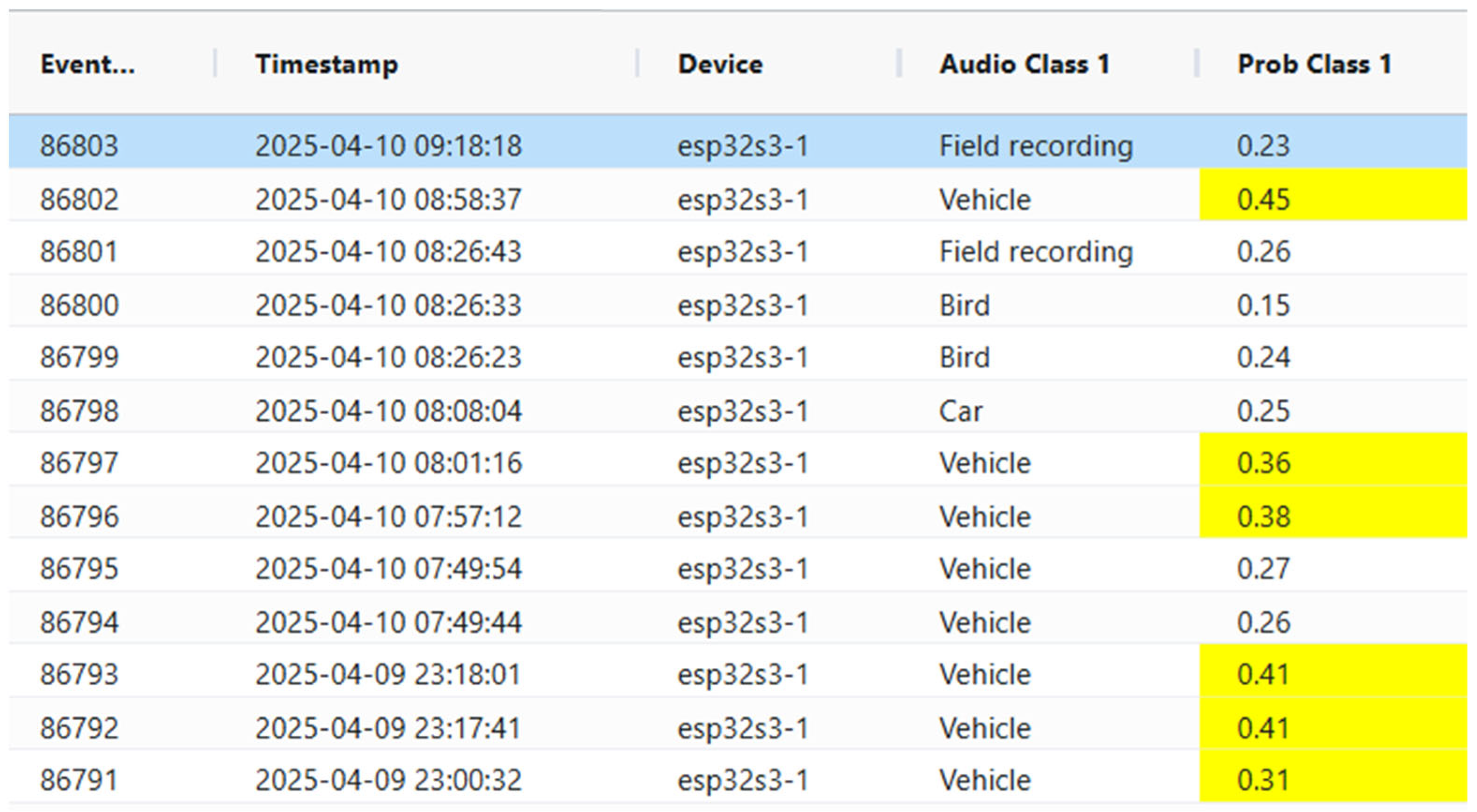
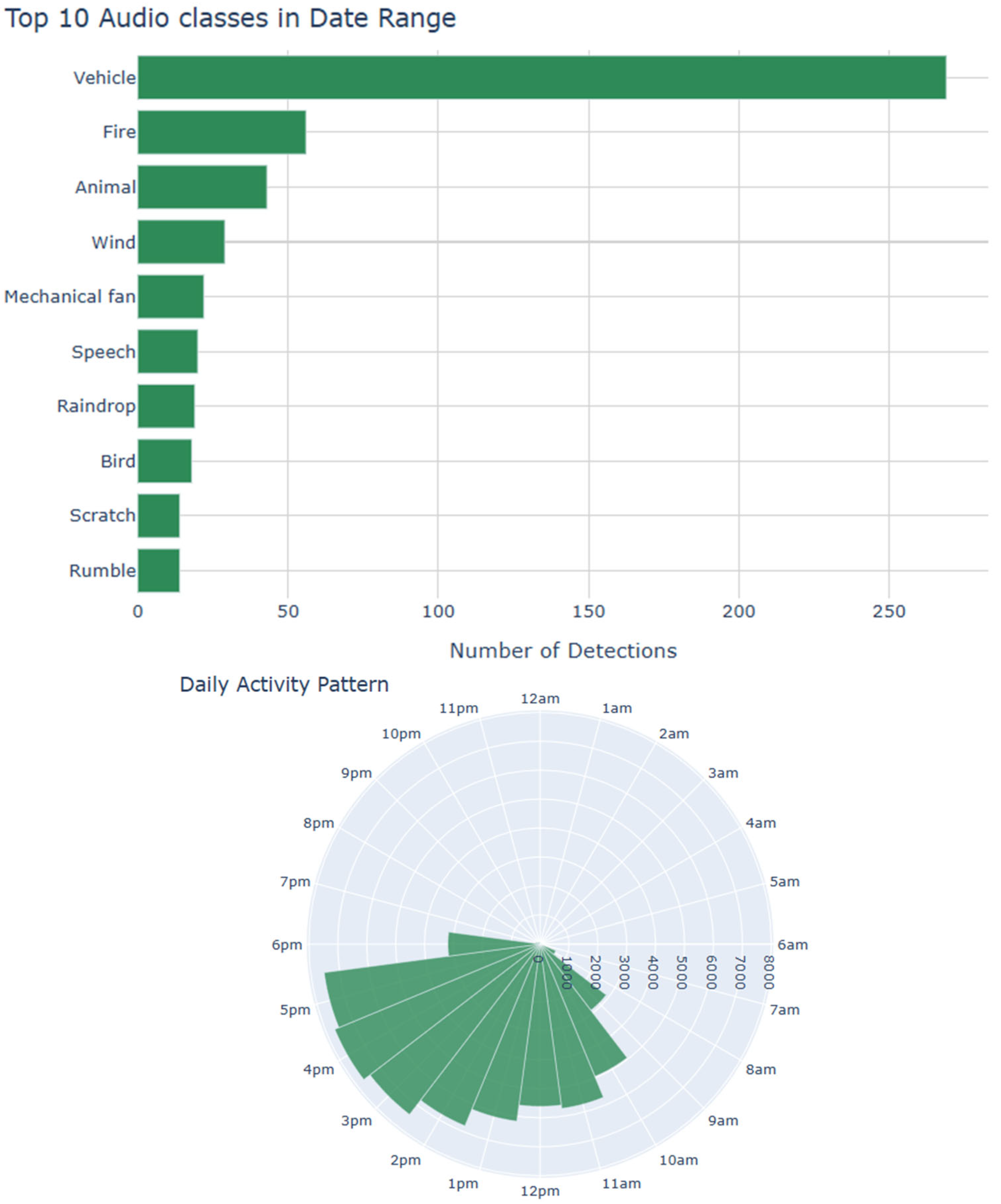
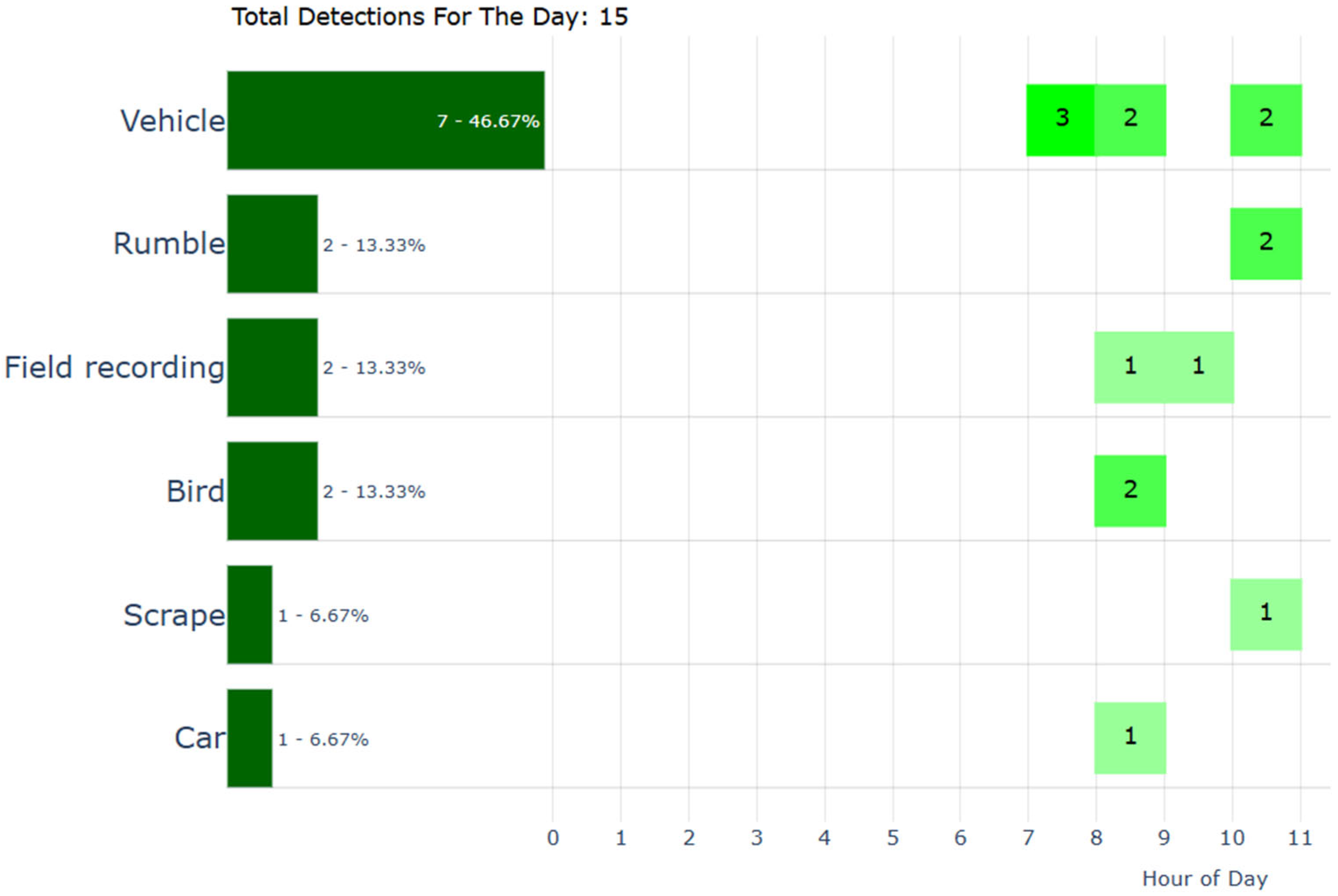
3. Results
- A.
- Accuracy at the audio event level
3.1. Stationary Platforms
3.2. Moving Platforms
- B.
- Accuracy at the incident level
3.3. Incidents of Special Interest
- List all audio events 10 min prior to and after a gunshot. Gunshots and explosions are very brief events.
- List all devices that picked up an explosion at 7.45 am and figured out the direction of arrival/location of the incident. Determine the blast’s direction of arrival and possibly the epicenter through analysis of the RMS values of each audio event.
- Examine all nodes within a rolling time frame and present correlation of labels belonging to the incidence class that indicate the occurrence of an event having a distributive nature (e.g., drone attacks, riot).
3.4. Assessment at the Incident Level
3.4.1. Our Approach
3.4.2. An LLM Approach
3.4.3. Metrics
3.5. Deployment on Edge Devices
3.6. Error Analysis and Mitigation Approaches
- Depending on the context, the class targeted by an AST may not always correspond to an actual incident. A real example observed during experimentation occurred during the transition from 2024 to 2025, when the sensors detected the sound of fireworks, which lasted for about 10 min. Although some classifications were correctly made for “Fireworks” or “Firecracker” sounds, as these classes are included in the AudioSet, many others were identified as “Artillery fire” and “Gunshot, gunfire”. In adverse weather, we observed that the “thunder” class may be confused with “eruption” or “explosion”. The same was observed when distant airplanes were passing over. The audio modality can be fooled, as cries of joy/surprise can be misinterpreted as cries of pain and breaking of things does not necessarily imply an unlawful action. As explained in Section 2, we rely on a hierarchy of sounds within a time frame to classify an incident, and this approach considerably reduces the false alarm cases.
- In moving platforms, Doppler shift distorts the spectral content of audio that does not match the spectral distribution of audio that the transformer was trained, on as the majority of sounds in the AudioSet dataset were taken from stationary microphones.
- Sounds at a distance lose their high-frequency content and may be erroneously classified as other types of impulsive sounds, e.g., “Door”.
- The recordings often contain overlapping classes of sounds because the urban sound scene can become complex. Therefore, an irrelevant sound, e.g., a bird’s vocalization, can receive a higher probability than a target signal. The fact we retain the first three possible classifications mitigates the impact of this.
- Sometimes critical incidents evolve quickly (e.g., a car crash can take less than five seconds, and a gunfire incident may take even less time). This is why we interpret a collection/cluster of targeted labels within a timeframe as an incident and not just a static, single label.
4. Discussion
4.1. Ethical Issues
- Threatening situations: Crimes and terrorist acts in large urban areas are not hypothetical scenarios but real threats that actually occur and demand special attention and preventive measures. The knowledge that public spaces are secured through intelligent monitoring systems is expected to deter such acts.
- Legal and common practices: Surveillance is generally lawful and widely accepted in places like stores, banks, agencies, and airports, where the need for heightened security justifies the installation of video cameras.
- Unattended surveillance: Autonomous surveillance systems are significantly less invasive than traditional monitoring by individuals. These systems eliminate human interference in interpreting sensor data and prevent data broadcasting at any stage of the inference process. This reduces the risk of unauthorized circulation of personal information, thereby aligning with growing public demands for privacy protection.
- Primary function: The main role of unattended surveillance is to detect critical situations in real time and deliver timely warning messages to authorized personnel. It does not engage in any uncontrolled or autonomous actions beyond this scope. The application scenarios emphasize security services in residential areas, workplace environments, and borders, prioritizing citizen safety.
- Political context: The decision to implement acoustic surveillance in public spaces, along with the laws governing this service, is inherently political and shaped by the cultural values of a regime. However, this paper does not address political considerations; it focuses exclusively on applied research.
4.2. Improvements
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RMS | Root, mean square value |
| CA | Certificate Authorities |
| CCTV | Closed-Circuit Television |
| SSL | Secure Sockets Layer |
| HTTPS | Hypertext Transfer Protocol Secure |
| AST | Audio Spectrogram Transformer |
| IoT | Internet of things |
| MQTT | Message Queuing Telemetry Transport |
| NVS | Non-volatile storage |
| TLS | Transport Layer Security |
| GPRS | Message Queuing Telemetry Transport |
| PSRAM | Pseudostatic read-only memory |
| STFT | Message Queuing Telemetry Transport |
| VIT | Vision Transformer |
| SQL | Structured Query Language |
| JSON | JavaScript Object Notation |
| AAC | Advanced Audio Coding |
| MP3 | Moving Picture Experts Group Audio Layer III |
| DoS | Denial of service |
| ACL | Access Control List |
Appendix A. Prompt Syntax Using DSPy
References
- Woodard, P. Modeling and classification of natural sounds by product code hidden Markov models. IEEE Trans. Signal Process. 1992, 40, 1833–1835. [Google Scholar] [CrossRef]
- Potamitis, I.; Ganchev, T. Generalized Recognition of Sound Events: Approaches and Applications. In Multimedia Services in Intelligent Environments. Studies in Computational Intelligence; Tsihrintzis, G.A., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 120. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. An Adaptive Framework for Acoustic Monitoring of Potential Hazards. J Audio Speech Music Proc. 2009, 2009, 594103. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Probabilistic Novelty Detection for Acoustic Surveillance Under Real-World Conditions. IEEE Trans. Multimed. 2011, 13, 713–719. [Google Scholar] [CrossRef]
- Shang, Y.; Sun, M.; Wang, C.; Yang, J.; Du, Y.; Yi, J.; Zhao, W.; Wang, Y.; Zhao, Y.; Ni, J. Research Progress in Distributed Acoustic Sensing Techniques. Sensors 2022, 22, 6060. [Google Scholar] [CrossRef] [PubMed]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio Surveillance: A Systematic Review. Assoc. Comput. Mach. 2016, 48, 4. [Google Scholar] [CrossRef]
- Almaadeed, N.; Asim, M.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. Automatic Detection and Classification of Audio Events for Road Surveillance Applications. Sensors 2018, 18, 1858. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Wang, K.; Li, X. A distributed training framework for abnormal sound detection in industrial devices: Aggregation strategies and performance analysis. Meas. Sci. Technol. 2025, 36, 026127. [Google Scholar] [CrossRef]
- Nogueira, A.F.R.; Oliveira, H.S.; Machado, J.J.M.; Tavares, J.M.R.S. Sound Classification and Processing of Urban Environments: A Systematic Literature Review. Sensors 2022, 22, 8608. [Google Scholar] [CrossRef]
- Zaman, K.; Sah, M.; Direkoglu, C.; Unoki, M. A Survey of Audio Classification Using Deep Learning. IEEE Access 2023, 11, 106620–106649. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Verma, D.; Jana, A.; Ramamritham, K. Classification and mapping of sound sources in local urban streets through AudioSet data and Bayesian optimized Neural Networks. Noise Mapp. 2019, 6, 52–71. [Google Scholar] [CrossRef]
- Greco, A.; Roberto, A.; Saggese, A.; Vento, M. DENet: A deep architecture for audio surveillance applications. Neural. Comput. Appl. 2021, 33, 11273–11284. [Google Scholar] [CrossRef]
- Kong, Q.; Cao, Y.; Iqbal, T.; Wang, Y.; Wang, W.; Plumbley, M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2880–2894. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.-A.; Glass, J. AST: Audio Spectrogram Transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Alsina-Pagès, R.M.; Navarro, J.; Alías, F.; Hervás, M. HomeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors 2017, 17, 854. [Google Scholar] [CrossRef]
- Browning, E.; Gibb, R.; Glover-Kapfer, P.; Jones, K.E. Passive Acoustic Monitoring in Ecology and Conservation 2017; WWF Conservation Technology Series 1(2); WWF-UK: Woking, UK, 2017. [Google Scholar]
- Pijanowski Bryan, C.; Brown Craig, J. Grand Challenges in Acoustic Remote Sensing: Discoveries to Support a Better Understanding of Our Changing Planet. Front. Remote Sens. 2022, 2, 824848. [Google Scholar] [CrossRef]
- Sugai, L.S.M.; Silva, T.S.F.; Ribeiro, J.W.; Llusia, D. Terrestrial Passive Acoustic Monitoring: Review and Perspectives. BioScience 2019, 69, 15–25. [Google Scholar] [CrossRef]
- Dias, A.R.; Santos, N.P.; Lobo, V. Acoustic Technology for Maritime Surveillance: Insights from Experimental Exercises. In Proceedings of the OCEANS 2024—Singapore, Singapore, 14–18 April 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Johnson, E.; Campos-Cerqueira, M.; Jumail, A.; Yusni, A.S.A.; Salgado-Lynn, M.; Fornace, K. Applications and advances in acoustic monitoring for infectious disease epidemiology. Trends Parasitol. 2023, 39, 386–399. [Google Scholar] [CrossRef]
- Wu, H.; Wang, Y.; Liu, X.; Sun, Y.; Yan, G.; Wu, Y.; Rao, Y. Smart Fiber-Optic Distributed Acoustic Sensing (sDAS) With Multitask Learning for Time-Efficient Ground Listening Applications. IEEE Internet Things J. 2024, 11, 8511–8525. [Google Scholar] [CrossRef]
- Jombo, G.; Zhang, Y. Acoustic-Based Machine Condition Monitoring—Methods and Challenges. Eng 2023, 4, 47–79. [Google Scholar] [CrossRef]
- Gabaldon-Figueira, J.C.; Brew, J.; Doré, D.H.; Umashankar, N.; Chaccour, J.; Orrillo, V.; Tsang, L.Y.; Blavia, I.; Fernández-Montero, A.; Bartolomé, J.; et al. Digital acoustic surveillance for early detection of respiratory disease outbreaks in Spain: A protocol for an observational study. BMJ Open 2021, 11, e051278. [Google Scholar] [CrossRef]
- Mou, A.; Milanova, M. Performance Analysis of Deep Learning Model-Compression Techniques for Audio Classification on Edge Devices. Sci 2024, 6, 21. [Google Scholar] [CrossRef]
- Mohaimenuzzaman, M.; Bergmeir, C.; West, I.; Meyer, B. Environmental Sound Classification on the Edge: A Pipeline for Deep Acoustic Networks on Extremely Resource-Constrained Devices. Pattern Recognit. 2023, 133, 109025. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Audio Classification on AudioSet—State-of-the-Art Models and Benchmarks. Available online: https://paperswithcode.com/sota/audio-classification-on-audioset (accessed on 10 April 2025).
- Audio Spectrogram Transformer Fine-Tuned on AudioSet. Available online: https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593 (accessed on 10 April 2025).
- Multilingual Instruction-Tuned Large Language Model. Available online: https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct (accessed on 10 April 2025).
- LLM Inference in C/C++. Available online: https://github.com/ggml-org/llama.cpp (accessed on 10 April 2025).
- The Framework for Programming, Not Prompting, Language Models. Available online: https://dspy.ai/ (accessed on 10 April 2025).
- Triantafyllopoulos, A.; Tsangko, I.; Gebhard, A.; Mesaros, A.; Virtanen, T.; Schuller, B. Computer Audition: From Task-Specific Machine Learning to Foundation Models. arXiv 2024, arXiv:2407.15672. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| “event_id”: “evt_593”, “timestamp”: “2024-11-24 12:01:57”, “audio_events”: [ (“class”: “Screaming”, “probability”: 0.55), (“class”: “explosion”, “probability”: 0.1), (“class”: “Gasp”, “probability”: 0.09)], “related_to”: “evt_585”), ( “event_id”: “evt_595”, “timestamp”: “2024-11-24 12:01:58”, “audio_events”: [ (“class”: “Gunshot, gunfire”, “probability”: 0.22), (“class”: “Burst, pop”, “probability”: 0.19), (“class”: “Explosion”, “probability”: 0.14)], “related_to”: “evt_593” ) |
| Platform | Top 1 | Top 2 | Top 3 |
|---|---|---|---|
| Stationary | 88.8 | 97.2 | 99.3 |
| Moving | 84.3 | 95.6 | 97.1 |
| Type: Gunfire Detected Time Window: 2024-11-24 12:01:57 to 2024-11-24 12:01:58 Related Events: [‘evt_595’, ‘evt_593’] Indicators Used: [‘screaming’, ‘gunshot, gunfire’, ‘explosion’, ‘burst, pop’] Scores: (‘total_primary’: ‘0.65’, ‘total_secondary’: ‘0.55’) Type: High-level Event Detected Time Window: 2024-11-24 12:06:22 to 2024-11-24 12:06:27 Related Events: [‘evt_613’, ‘evt_619’, ‘evt_614’, ‘evt_621’, ‘evt_605’] Indicators Used: [‘screaming’, ‘gunshot, gunfire’, ‘burst, pop’, ‘groan’] Scores: (‘total_primary’: ‘0.41’, ‘total_secondary’: ‘1.70’) |
| Event | Positive | Negative |
|---|---|---|
| 1 | 0:07:30–0:07:46 | 0:18:45 |
| 2 | 0:22:28–0:22:30 | 0:35:10 |
| 3 | 0:30:10–0:30:24 | 0:42:40–0:43:15 |
| 4 | 0:51:00–0:51:06 | 0:51:51–0:51:57 |
| 5 | 1:22:09–1:22:19 | 0:58 |
| 6 | 1:22:25–1:22:30 | 1:00:15–1:00:24 |
| 7 | 1:26:15–1:27:27 | 1:20:55 |
| 8 | 1:31:57–1:32:00 | 1:25:55–1:26:00 |
| Accuracy | Precision | Recall | F1-Score | |||||
|---|---|---|---|---|---|---|---|---|
| Incident | Ours | LLM | Ours | LLM | Ours | LLM | Ours | LLM |
| Crash | 0.882 | 0.706 | 0.8 | 0.615 | 1.0 | 1.0 | 0.889 | 0.762 |
| Raspberry Pi 4 | Raspberry Pi 5 | i5 Laptop | |
|---|---|---|---|
| Time (s) | 14 | 4.6 | 1.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saradopoulos, I.; Potamitis, I.; Ntalampiras, S.; Rigakis, I.; Manifavas, C.; Konstantaras, A. Real-Time Acoustic Detection of Critical Incidents in Smart Cities Using Artificial Intelligence and Edge Networks. Sensors 2025, 25, 2597. https://doi.org/10.3390/s25082597
Saradopoulos I, Potamitis I, Ntalampiras S, Rigakis I, Manifavas C, Konstantaras A. Real-Time Acoustic Detection of Critical Incidents in Smart Cities Using Artificial Intelligence and Edge Networks. Sensors. 2025; 25(8):2597. https://doi.org/10.3390/s25082597
Chicago/Turabian StyleSaradopoulos, Ioannis, Ilyas Potamitis, Stavros Ntalampiras, Iraklis Rigakis, Charalampos Manifavas, and Antonios Konstantaras. 2025. "Real-Time Acoustic Detection of Critical Incidents in Smart Cities Using Artificial Intelligence and Edge Networks" Sensors 25, no. 8: 2597. https://doi.org/10.3390/s25082597
APA StyleSaradopoulos, I., Potamitis, I., Ntalampiras, S., Rigakis, I., Manifavas, C., & Konstantaras, A. (2025). Real-Time Acoustic Detection of Critical Incidents in Smart Cities Using Artificial Intelligence and Edge Networks. Sensors, 25(8), 2597. https://doi.org/10.3390/s25082597