Abstract
With the exploration and exploitation of marine resources, underwater images, which serve as crucial carriers of underwater information, significantly influence the advancement of related fields. Despite dozens of underwater image enhancement (UIE) methods being proposed, the impacts of insufficient contrast and distortion of surface texture during UIE are currently underappreciated. To address these challenges, we propose a novel UIE method, channel-adaptive and spatial-fusion Net (CASF-Net), which uses a network channel-adaptive correction module (CACM) to enhance feature extraction and color correction to solve the problem of insufficient contrast. In addition, the CASF-Net utilizes a spatial multi-scale fusion module (SMFM) to solve the surface texture distortion problem and effectively improve underwater image saturation. Furthermore, we propose a Large-scale High-resolution Underwater Image Enhancement Dataset (LHUI), which contains 13,080 pairs of high-resolution images with sufficient diversity for efficient UIE training. Experimental results show that the proposed network design performs well in the UIE task compared with existing methods.
1. Introduction
Underwater imaging technology plays a critical role in the exploration of ocean resources [1]. Due to the unique characteristics of the underwater environment—such as light attenuation, scattering, and uneven illumination—underwater images often suffer from blurriness, low contrast, and color distortion [2]. These issues not only affect the visual quality of the images but also severely limit their applications in fields like ocean exploration, underwater target detection, and underwater robotic operations. Therefore, developing underwater image enhancement (UIE) technology [3] has become urgent, with the goal of restoring high-quality images by removing degradations like noise, blurriness, and color deviations.
The degradation of underwater images mainly arises from light scattering and absorption caused by suspended particles in water, as well as the varying absorption capacities of water for different wavelengths [4,5]. Water molecules tend to absorb red light, while suspended particles primarily absorb green light, causing underwater images to appear blue-green. Additionally, the imaging depth influences color deviation, giving images a hazy appearance with low-contrast colors. Consequently, UIE technology has emerged. As ocean resource development deepens, the demand for higher-quality underwater images is increasing, further driving the advancement and innovation of UIE technology.
To address severe underwater image degradation, early studies attempted non-physical model-based methods [6,7,8], which directly process pixel values. These methods are simple, fast, and easy to implement, but they may lead to over-enhancement, oversaturation, and color distortion in the resulting images. Subsequently, physics-based UIE methods [9,10,11] were proposed. These methods have shown promising performance in enhancing images from specific underwater scenes, but due to their inherent mechanisms, they lack flexibility and struggle to handle diverse underwater scenarios.
In recent years, given the powerful potential of neural networks, researchers have proposed GAN and CNN-based approaches [12,13,14,15,16,17] to enhance underwater images. Compared to the traditional enhancement methods mentioned above, GAN and CNN methods demonstrate much stronger performance. However, these methods often treat different image channels uniformly, overlooking the inter-channel differences in feature extraction. Figure 1 shows the results of our UIE method and some comparison UIE methods, and the main contributions of this paper can be summarized as follows:
- We introduce the network channel adaptive correction module (CACM), which introduces an adaptive factor to solve the problem of insufficient contrast and effectively improve the contrast of underwater images.
- We introduced the spatial multi-scale fusion module (SMFM) to process spatial information of different scales to solve the problem of surface texture distortion and effectively improve underwater image saturation.
- We propose a novel UIE method, CASF-Net, and conduct extensive comparative experiments on the LHUI underwater dataset. The experimental results show that our method outperforms other methods in both qualitative and quantitative aspects.

Figure 1.
Compared with the existing UIE methods, the image produced by our CASF-Net has the highest PSNR score and best visual quality. The value 34.00 represents the PSNR values, and the yellow font indicates the highest values. (a) Raw image. (b) CLUIE [18]. (c) DCP [10]. (d) FspiralGAN [15]. (e) GC [19]. (f) GDCP [20]. (g) MSCNN [16]. (h) UDCP [9]. (i) Ours. (j) Ground truth.
2. Related Work
In the domains of ocean resource exploration and underwater robotic operations, UIE technology plays a vital role. Recent years have witnessed notable advancements in research and development within this field [21]. Presently, UIE techniques are primarily categorized into two groups: traditional enhancement methods and those based on deep learning. Furthermore, the creation and utilization of datasets are critical in UIE research. With the progress in underwater imaging technology, numerous underwater image datasets have been established in recent years, providing valuable resources for data-driven deep learning approaches and further propelling the advancement of UIE technology.
2.1. Traditional Enhancement Algorithms
Traditional underwater enhancement methods can be classified into non-physical model-based methods and physical model-based methods. Non-physical model-based methods focus on enhancing global contrast by adjusting the histogram distribution of an image, achieving a more even pixel value distribution to improve the image’s visual quality. These methods do not rely on complex underwater optical models but instead operate directly on pixel values to obtain clearer underwater images. [6] combined histogram equalization (HE) with white balance, first applying white balance to correct color casts in blurred images, followed by histogram equalization. This approach leverages the strengths of both techniques, achieving excellent results in color restoration and contrast enhancement. Land et al. [7] introduced the concept of “color constancy” in the human visual system, emphasizing the importance of ambient light in color perception and laying the foundation for the multi-scale Retinex algorithm. Based on the Retinex principle, an enhancement method [8] was developed for single-frame underwater images, effectively improving image brightness and color performance. These non-physical model-based methods are simple, easy to use, and require low computational power, making them particularly suitable for resource-constrained environments. However, since these methods operate directly on the pixels of the image, they may introduce detail loss during the enhancement process, resulting in insufficient accuracy in the local information of the image.
Physics-based UIE methods focus on restoring the true characteristics of an image by simulating the physical phenomena associated with underwater imaging. These approaches treat UIE as an inversion problem, aiming to reverse the degradation caused by the underwater imaging process in order to reconstruct high-quality images. This approach requires estimating parameters of the underwater imaging model, such as background light and transmission maps, to reconstruct the image through inverse degradation processes. For example, method [9] introduced the UDCP algorithm for UIE, inspired by methods [10]. By analyzing the underwater environment, UDCP improves the traditional DCP algorithm, generating clearer underwater images. Wang et al. [11] proposed a new adaptive attenuation-curve prior model based on the adaptive attenuation-curve prior, which adjusts the attenuation curve according to the specific underwater environment to more accurately estimate light attenuation. Physics-based UIE methods restore images by simulating the physical processes of underwater imaging, providing relatively realistic restoration results. However, these methods have limitations, such as difficulty in accurately estimating model parameters affected by multiple factors in real applications. The complex calculations involved can lead to slower processing speeds, and these methods are highly dependent on specific underwater scenes, requiring parameter adjustments for different environments.
2.2. Deep-Learning-Based Methods
As underwater imaging technology has advanced, more datasets of underwater scenes are being published, creating favorable conditions for data-driven deep learning methods. Generative adversarial networks (GANs) and convolutional neural networks (CNNs) have shown tremendous potential in the field of UIE. Li et al. [12] first introduced WaterGAN, a method that converts non-underwater scenes into underwater scenes to generate training data. By training models on these generated underwater images along with real underwater images, the model can enhance murky underwater images into clearer ones. Fabbri et al. [13] proposed the UGAN network architecture, which preserves spatial information generated by the encoder, enabling it to learn information from input images without relying on the final output feature map, thus producing high-quality images. Li et al. [14] introduced a novel underwater image color correction method based on weakly supervised color transfer. Han et al. proposed the FspiralGAN architecture [15], which uses an “equal channel strategy” to improve model speed while maintaining the quality of generated images. Due to the capabilities of convolutional neural networks, numerous CNN-based methods have been developed. Among them, Ren et al. [16] proposed a multi-scale convolutional neural network (MSCNN), which extracts features at different scales through parallel multi-scale convolution layers, effectively improving detail representation in underwater images, allowing the model to handle complex details across diverse underwater environments. Additionally, Fu et al. [17] proposed PUIE, a perception-driven image enhancement method that designs a perceptual loss function, making the enhanced images visually more aligned with human perception. The PUIE method emphasizes color fidelity and contrast enhancement, adaptively adjusting image details in various underwater scenes and improving color distortion and turbidity issues to make the enhanced images appear more natural and realistic. However, existing image enhancement methods do not fully consider the problem of attenuation differences among underwater color channels and still suffer from insufficient contrast, surface texture distortion, and insufficient saturation. To address this, we propose a new method, CASF-Net, which includes two modules: CACM and SMFM, and demonstrates strong performance on the LHUI dataset.
2.3. Underwater Image Datasets
Capturing underwater images is inherently challenging due to the complexities of the underwater environment, making it difficult to obtain true, undistorted scenes. In the early phases of computer vision and underwater image processing, researchers created underwater image datasets that were often limited in quantity, focused on single scenes, and lacked reference features. However, as technology advanced, it became easier to acquire underwater images, and deep learning techniques demonstrated remarkable effectiveness in image processing. Researchers subsequently developed UIE methods to address the blurriness of underwater images and carefully selected images that closely resembled realistic underwater scenes, resulting in the creation of numerous datasets that have significantly contributed to the advancement of UIE technology. For instance, ref. [22] introduced the EUVP dataset, ref. [23] presented the UIEB dataset, and [24] developed the LSUI dataset. However, although many datasets have been proposed, they still face the issue of limited quantity. To address this problem, we propose a new dataset, LHUI.
3. Dataset
Data Collection. The UVEB [25] dataset is a large-scale video collection that includes a significant number of underwater video pairs. However, these video pairs, which include many similar frames, are less effective and time-costly for UIE training. To tackle this challenge, we implemented a frame extraction process to create a more lightweight dataset tailored for image enhancement tasks, referred to as LHUI. Specifically, 10 frames were extracted from each video: for those with more than 50 frames, one frame was taken every five frames; for videos with fewer than 50 frames, the first 10 frames were selected. The LHUI dataset is comprised of two primary components. The first part features underwater videos captured using FIFISH V6 and FIFISH V-EVO cameras, both offering 4 K resolution. These videos were recorded in various marine locations and ports throughout China, representing of the dataset. The second component consists of images obtained from the internet, contributed by underwater photographers, which make up the remaining of the dataset. Overall, the dataset contains 13,080 image pairs, and all images are intended strictly for academic use. To ensure the diversity and applicability of the dataset, we prioritized selecting authentic underwater images with rich water scenes, diverse water types, varying lighting conditions, and high resolutions. These images were further processed to generate clear reference images for image enhancement tasks.
Reference Image Generation. The selection of reference images is similar to [25]. We first used 20 existing optimal UIE methods, including [6,8,9,10,15,16,17,18,19,20,26,27,28,29,30,31,32,33,34,35], to process the collected underwater images, creating a set of 13,080 images. The entire process of selecting the best-enhanced images was conducted under the guidance of ITU-R BT500-13 [36], with 15 observers. All observers used the same experimental equipment, a Redmi-27H 4 K monitor, to perform image quality assessments, resulting in the optimal reference dataset, which serves as the ground truth (GT).
Diversity Analysis. LHUI encompasses a wide range of underwater scenes, including coastal areas, open seas, rivers, lakes, ports, aquariums, and swimming pools. Figure 2a illustrates the scene diversity within the LHUI samples, which mainly includes six types of underwater scenes: blue, green, yellow, white, low-light, and other color deviations. Other color refers to some challenging underwater degraded images that have issues with non-uniform spatial area attenuation, where a single image contains multiple color degradations. Among these, blue scenes have the highest proportion, accounting for 39.2%, followed by green scenes at 38.7%. Although scenes with yellow, white, and low-light conditions are less common, they still make up 22.2% of the dataset. Figure 2b shows the resolution distribution of the LHUI dataset, with the majority of images concentrated in the 2 K to 4 K range, comprising 65.6% of the dataset, followed by the 720 p to 1080 p range, making up 25.1%. Figure 3 compares the resolution distributions of the LHUI, LSUI [24], and UIEB [23] datasets. The LHUI dataset contains a total of 13,080 image pairs, of which 8580 pairs have resolutions above 2 K. In contrast, the LSUI [24] dataset, with a total of 4279 pairs, primarily features resolutions between 0 and 360 p. The UIEB [23] dataset has 890 image pairs, with resolutions mainly distributed between 360 p to 720 p and 720 p to 1080 p. To the best of the authors’ knowledge, LHUI is currently the largest real-world underwater image dataset, offering a large-scale, high-quality set of reference images that can further drive advancements in UIE methods.
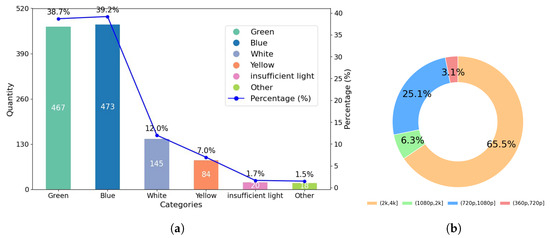
Figure 2.
LHUI data analysis. (a) The diversity of LHUI samples includes six types of color degradation and their respective proportions. (b) The resolution distribution of LHUI.
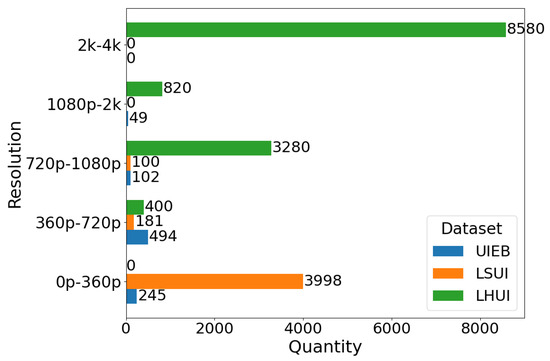
Figure 3.
Comparison of quantity and resolution information among LHUI, UIEB [23], and LSUI [24].
4. Network Architecture
4.1. Overall Pipline
As shown in Figure 4, the proposed CASF-Net is essentially a single-branch network primarily composed of two modules: CACM and SMFM. First, represents the input degraded frame image, which undergoes preliminary feature extraction through a convolution. Then, feature is obtained by passing it through 10 residual blocks. Next, is processed by the CACM to obtain the enhanced feature . Subsequently, passes through 15 SMFM blocks, effectively utilizing spatial and multi-scale receptive field information along with feature fusion techniques to obtain the feature , which can be expressed as:
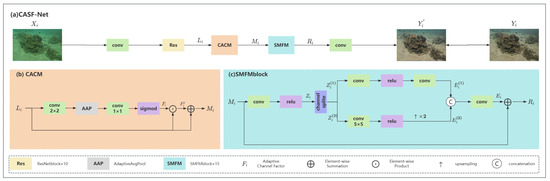
Figure 4.
Overview of the proposed CASF-Net architecture. CACM and SMFM represent the network Channel-Adaptive Correction Module and the Spatial Multi-scale Fusion Module, respectively. Res, AAP, and represent the ResNet residual structure, adaptive average pooling, and network channel-adaptive factors, respectively.
Finally, a convolution is applied to obtain the output image . The proposed CACM module enhances the feature extraction and color correction functions to solve the problem of insufficient contrast, while the SMFM module uses spatial information to capture multi-scale receptive fields for feature fusion to solve the problem of distortion of surface texture and effectively improve the saturation of underwater images.
4.2. CACM
The RGB three-channel information of images has consistently garnered attention. Inspired by DCP [10] and UDCP [9], we combine channel information with deep learning algorithms to generate a network channel-adaptive factor, forming our CACM.
Specifically, the input feature first passes through a convolution and an adaptive average pooling layer to extract more complex features. Then, it is processed through a convolution, followed by the sigmoid activation function to generate the channel-adaptive factor , which can be represented as:
The input feature is corrected to obtain , which is then connected with via a residual connection to produce the output . can be represented as:
CACM performs adaptive modulation of degraded features by introducing network channel-adaptive factors for enhanced feature extraction and color correction to improve image contrast.
4.3. SMFM
Recently, in the field of computer vision [37,38,39,40], spatial and multi-scale receptive field information has become a popular topic. Inspired by [41,42,43,44], we utilize channel separation and a multi-scale mechanism, combined with fusion techniques, to form our SMFM.
Specifically, the input feature is processed through a convolution followed by a ReLU activation function. We then split it evenly along the channel dimension into two parts, and . After standard convolution and activation, produces . For , we apply strided convolution to reduce the feature resolution to half the original, then perform 2x upsampling to restore it to the original size, resulting in feature . The two features from the upper and lower branches are concatenated and finally connected to the residual of feature , producing the output , which can be represented as:
SMFM adopts a channel separation technique to fully utilize the spatial and multi-scale sensory field information and utilizes residual connections to improve learning performance and efficiency, which solves the distortion problem of surface texture and effectively improves the saturation of underwater images.
4.4. Loss Function
In the training process, we use a dual-domain L1 loss function in the spatial and frequency domains, respectively [45,46]. Since the network modules mainly focus on the processing of pixel-level and inter-channel information of blurred images, it leads to insufficient attention to frequency domain information by the model, thereby losing some important details during the image enhancement process. The dual-domain loss function can consider both spatial domain and frequency domain information during the training process, ensuring that the model does not overly ignore frequency domain features during training, thereby improving the quality of the model in enhancing images. For each output/target image pair with the same resolution, loss functions are given by:
where represents the L1 loss, and denotes the frequency domain loss; and y denote the output and GT images, respectively; F represents fast Fourier transform; and is empirically set to 0.1 for balancing dual-domain training.
5. Experiments
5.1. Settings
- Datasets. LHUI contains 12,080 pairs of training images and 1000 pairs of test images, featuring six types of underwater degradation.
- Comparison methods. We compared CASF-Net with 12 UIE methods to verify our performance advantage.
- Evaluation metrics. For the test dataset with reference images, we conducted a full-reference evaluation using the PSNR [47] and SSIM [48] metrics. These two metrics reflect the degree of similarity to the reference, where a higher PSNR [47] value indicates closer image content, and a higher SSIM [48] value reflects a more similar structure and texture.
PSNR is an objective measure used to assess the difference between two images. It reflects the ratio between the signal (the original image) and the noise (the distorted part). The formula for its calculation is:
MAX is the maximum possible pixel value in an image.
SSIM is an indicator tric measure of the similarity in brightness, contrast, and structure of two images. The core idea of SSIM is to view images as a collection of brightness, contrast, and structure, and to evaluate the overall similarity by comparing the similarity of these three aspects. The calculation formula is as follows:
In which and are the mean values of images x and y within a local window, representing the brightness level of the images. and are the variances of images x and y within the local window, representing the contrast of the images. is the covariance between images x and y within the local window, representing the structural similarity of the images. , , where , , and L is the dynamic range of the pixel values.
- Implementation details. We implemented our method using PyTorch and trained it on an NVIDIA Tesla A40 GPU. The network optimization was performed using the ADAM [49] optimizer. The initial learning rate was set to . The total number of iterations was 2 K. The batch size was 128, and the block size of the input image was 128 × 128.
- Algorithm introduction. We briefly introduce the contrast methods used, as shown in Table 1.
5.2. Comparisons with State-of-the-Art Methods
Quantitative comparison. Table 2 shows the results of quantitative experiments for our proposed network, as well as the results of current state-of-the-art UIE methods. The experiments were conducted on our proposed LHUI dataset. Our proposed network achieved good performance among all methods, with the best results in terms of PSNR [47], SSIM [48], and MSE.

Table 1.
A brief introduction to the underwater image enhancement algorithm used.
Table 1.
A brief introduction to the underwater image enhancement algorithm used.
| Methods | Reference | Introduction |
|---|---|---|
| LiteEnhanceNet | [50] | Lightweight CNN Network Model Based on Depthwise Separable Convolution |
| LANet | [26] | Image Enhancement Algorithm Using Multi-Scale Spatial Information and Parallel Attention Mechanism |
| CLUIE | [18] | Underwater image enhancement algorithms with multiple reference learning |
| GC | [19] | Based on the basic knowledge of human vision |
| MSCNN | [16] | Image Dehazing Method Based on Multi-Scale Deep Neural Networks |
| DCP | [10] | Image dehazing method using the dark channel prior |
| FspiralGAN | [15] | Adopting a GAN network model with an equal-channel design |
| CLAHE | [27] | Adaptive Histogram Equalization Enhancement Method |
| MetaUE | [33] | Model-based Underwater Image Enhancement Algorithm |
| GDCP | [20] | Universal Image Restoration Algorithm Using the Dark Channel Prior |
| UDCP | [9] | A method for estimating transmission in underwater environments has been proposed, along with a corresponding underwater image enhancement algorithm |
| PUIE | [17] | Underwater Image Enhancement Method Based on Probabilistic Networks |
Qualitative comparison. Figure 5 presents a comparison of our image enhancement results with state-of-the-art methods on the LHUI dataset. It is evident that our method produces images with the best sharpness, contrast, and detail restoration, closely matching the GT. When handling underwater images with different color domains, many methods perform well only on degraded images within a specific color domain, revealing a lack of generalization ability. Figure 6 compares the three-channel color histograms of the images with the reference image. It is evident that our results are closest to the RGB color space distribution. In contrast, our method achieves the best enhancement results across images from various color domains, fully demonstrating the excellent generalization capability of the proposed model.

Figure 5.
Visual comparisons with state-of-the-art methods on real underwater scenes. 32.29/0.9832 represents the PSNR/SSIM values, and the yellow font indicates the highest values. reference means that the image is the source of GTs. (a) RAW images. (b) Fspiral-GAN [15]. (c) CLAHE [27]. (d) MetaUE [33]. (e) PUIE [17]. (f) LANet [26]. (g) CLUIE [18]. (h) DCP [10]. (i) GC [19]. (j) GDCP [20]. (k) MSCNN [16]. (l) UDCP [9]. (m) Ours. (n) Ground Truth.
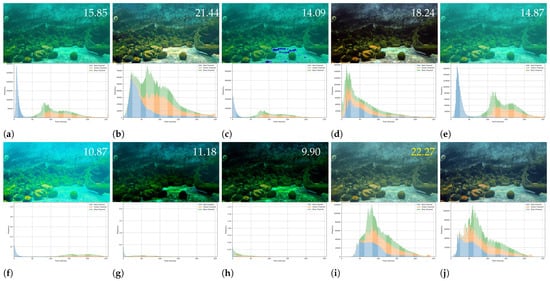
Figure 6.
Comparison chart of three-channel color histograms. 22.27 represents the PSNR values, and the yellow font indicates the highest values. (a) Raw image. (b) CLUIE [18]. (c) DCP [10]. (d) FspiralGAN [15]. (e) GC [19]. (f) GDCP [20]. (g) MSCNN [16]. (h) UDCP [9]. (i) Ours. (j) Ground truth.
Table 2.
Quantitative comparison with state-of-the-art methods. ↑ indicates that higher values are more desirable, and ↓ indicates that lower values are more desirable. Top 1st, 2nd results are marked in red and blue, respectively.
Table 2.
Quantitative comparison with state-of-the-art methods. ↑ indicates that higher values are more desirable, and ↓ indicates that lower values are more desirable. Top 1st, 2nd results are marked in red and blue, respectively.
| Methods | PSNR (dB) ↑ | SSIM ↑ | MSE |
|---|---|---|---|
| LiteEnhanceNet [50] | 24.86 | 0.9175 | 0.8128 |
| LANet [26] | 21.36 | 0.9142 | 1.1893 |
| CLUIE [18] | 18.92 | 0.8877 | 1.8170 |
| GC [19] | 15.65 | 0.8421 | 3.8121 |
| MSCNN [16] | 13.41 | 0.7568 | 5.6020 |
| DCP [10] | 12.67 | 0.7849 | 6.3114 |
| FspiralGAN [15] | 21.14 | 0.8507 | 1.8449 |
| CLAHE [27] | 19.43 | 0.9086 | 1.5046 |
| MetaUE [33] | 15.69 | 0.7937 | 3.0617 |
| GDCP [20] | 13.76 | 0.8209 | 5.2951 |
| UDCP [9] | 10.55 | 0.5591 | 10.1081 |
| PUIE [17] | 23.39 | 0.9302 | 0.7860 |
| Ours | 26.41 | 0.9401 | 0.6881 |
5.3. Ablation Studies
In our study, we designed and conducted a series of ablation experiments to deeply explore the practical effectiveness of the core components of our proposed network. As shown in Table 3, our experiments focused on evaluating two key factors: CACM and SMFM. We first experimented with the baseline model, achieving a PSNR of 23.84 and an SSIM of 0.9226. Next, we added the proposed CACM module to the baseline model, which increased the PSNR to 26.17 and the SSIM to 0.9325, clearly demonstrating the effectiveness of the CACM module. Further, we added the SMFM module to the model, resulting in the best performance, with a PSNR of 26.41 and an SSIM of 0.9401.
Table 3.
Ablation studies. ↑ indicates that higher values are more desirable and ↓ indicates that lower values are more desirable. Top 1st results are marked in red.
As shown in Figure 7, the enhancement result of the Full model has the highest PSNR and SSIM, with the best visual effect. The result of BL has more obvious blurring and haze, the result of BL + CACM has enhanced contrast and reduced blurring compared with BL, and the channel-adaptive factor is conducive to adaptive adjustment of degraded features, which is convenient to achieve the solution of the problem of low contrast. Full Model joins the SMFM module, the texture and color saturation of coral are more obvious, the sense of hierarchy is richer, close to GT, and the use of spatial information capture multi-scale feeling field for feature fusion is conducive to solving the problem of surface texture distortion, and effectively improves the saturation of the underwater image.
This series of experiments not only validated the effectiveness of the proposed modules but also highlighted the superiority of our proposed network.

Figure 7.
Visual comparison of the ablation study sampled from the LHUI dataset. BL represents the baseline, Full Model includes baseline + CACM + SMFM, 28.00/0.9460 represents the PSNR/SSIM values, and the yellow font indicates the highest values.
6. Conclusions
In this work, we created a new large-scale, high-resolution dataset, LHUI, containing 13,080 real-world underwater images. Compared to existing underwater datasets, LHUI features a greater variety of underwater scenes, types of underwater degradation, and high-resolution images, with corresponding clear images provided as references. Additionally, we propose a new image enhancement method, CASF-Net. This network includes two main modules: the CACM and SMFM. By combining channel information with deep learning algorithms and fully utilizing spatial and multi-scale receptive field information, CASF-Net achieves state-of-the-art UIE performance. Extensive experiments have verified that the network is able to solve the problems of insufficient contrast and surface texture distortion, and it is beneficial in improving the saturation of underwater images. However, the dataset may not comprehensively cover all possible underwater environments and conditions, such as low-light deep-sea scenarios. Therefore, we plan to incorporate other general enhancement techniques, such as low-light enhancement [35], in future work. In this process, we may further improve our CACM and SMFM modules, or introduce new modules to achieve better enhancement effects.
Author Contributions
Conceptualization, K.C. and Z.Y.; methodology, K.C.; software, K.C. and Z.L.; writing—original draft preparation, K.C., Z.L., F.Z. and Z.Y.; writing—review and editing, K.C. and Z.Y.; visualization, K.C., Z.L. and F.Z.; supervision, Z.Y.; project administration, Z.Y.; funding acquisition, Z.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Hainan Province Science and Technology Special Fund of China (Grant No. ZDYF2022SHFZ318), the Project of Sanya Yazhou Bay Science and Technology City under Grant No. SKJC-2023-01-004 and the National Natural Science Foundation of China (Grant No. 62171419).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset will be released on https://github.com/yzbouc/LHUI accessed on 15 April 2025.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Urabe, T.; Ura, T.; Tsujimoto, T.; Hotta, H. Next-generation technology for ocean resources exploration (Zipangu-in-the-Ocean) project in Japan. In Proceedings of the OCEANS 2015-Genova, Genova, Italy, 18–21 May 2015; pp. 1–5. [Google Scholar]
- Lurton, X. An Introduction to Underwater Acoustics: Principles and Applications; Springer Science & Business Media: Berlin, Germany, 2002. [Google Scholar]
- Raveendran, S.; Patil, M.D.; Birajdar, G.K. Underwater image enhancement: A comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 2021, 54, 5413–5467. [Google Scholar] [CrossRef]
- Wozniak, B.; Dera, J. Light Absorption by Suspended Particulate Matter (SPM) in Sea Water; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Stramski, D.; Boss, E.; Bogucki, D.; Voss, K.J. The role of seawater constituents in light backscattering in the ocean. Prog. Oceanogr. 2004, 61, 27–56. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.-P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar]
- Drews, P.; Nascimento, E.; Moraes, F.; Botelho, S.; Campos, M. Transmission estimation in underwater single images. In Proceedings of the IEEE international conference on computer vision workshops, Sydney, Australia, 2–8 December 2013; pp. 825–830. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Wang, Y.; Liu, H.; Chau, L.-P. Single underwater image restoration using adaptive attenuation-curve prior. IEEE Trans. Circuits Syst. Regul. Pap. 2017, 65, 992–1002. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Li, C.; Guo, J.; Guo, C. Emerging from water: Underwater image color correction based on weakly supervised color transfer. IEEE Signal Process. Lett. 2018, 25, 323–327. [Google Scholar] [CrossRef]
- Han, R.; Guan, Y.; Yu, Z.; Liu, P.; Zheng, H. Underwater image enhancement based on a spiral generative adversarial framework. IEEE Access 2020, 8, 218838–218852. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.-H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. pp. 154–169. [Google Scholar]
- Fu, Z.; Wang, W.; Huang, Y.; Ding, X.; Ma, K.-K. Uncertainty inspired underwater image enhancement. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 465–482. [Google Scholar]
- Li, K.; Wu, L.; Qi, Q.; Liu, W.; Gao, X.; Zhou, L.; Song, D. Beyond single reference for training: Underwater image enhancement via comparative learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2561–2576. [Google Scholar] [CrossRef]
- Schlick, C. Quantization techniques for visualization of high dynamic range pictures. In Photorealistic Rendering Techniques; Springer: Berlin/Heidelberg, Germany, 1995; pp. 7–20. [Google Scholar]
- Peng, Y.-T.; Cao, K.; Cosman, P.C. Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Wang, Y.; Song, W.; Fortino, G.; Qi, L.-Z.; Zhang, W.; Liotta, A. An experimental-based review of image enhancement and image restoration methods for underwater imaging. IEEE Access 2019, 7, 140233–140251. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Xie, Y.; Kong, L.; Chen, K.; Zheng, Z.; Yu, X.; Yu, Z.; Zheng, B. UVEB: A Large-scale Benchmark and Baseline Towards Real-World Underwater Video Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 22358–22367. [Google Scholar]
- Liu, S.; Fan, H.; Lin, S.; Wang, Q.; Ding, N.; Tang, Y. Adaptive learning attention network for underwater image enhancement. IEEE Robot. Autom. Lett. 2022, 7, 5326–5333. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast limited adaptive histogram equalization. In Graphics Gems IV; Elsevier: Amsterdam, The Netherlands, 1994; pp. 474–485. [Google Scholar]
- Jiang, J.; Ye, T.; Bai, J.; Chen, S.; Chai, W.; Jun, S.; Liu, Y.; Chen, E. Five A + Network: You Only Need 9K Parameters for Underwater Image Enhancement. arXiv 2023, arXiv:2305.08824. [Google Scholar]
- Fu, Z.; Lin, H.; Yang, Y.; Chai, S.; Sun, L.; Huang, Y.; Ding, X. Unsupervised underwater image restoration: From a homology perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022; pp. 643–651. [Google Scholar]
- Zhang, W.; Zhuang, P.; Sun, H.-H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Galdran, A.; Pardo, D.; Picón, A.; Alvarez-Gila, A. Automatic red-channel underwater image restoration. J. Vis. Commun. Image Represent. 2015, 26, 132–145. [Google Scholar] [CrossRef]
- Zhang, W.; Zhou, L.; Zhuang, P.; Li, G.; Pan, X.; Zhao, W.; Li, C. Underwater image enhancement via weighted wavelet visual perception fusion. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2469–2483. [Google Scholar] [CrossRef]
- Zhang, Z.; Yan, H.; Tang, K.; Duan, Y. MetaUE: Model-based meta-learning for underwater image enhancement. arXiv 2023, arXiv:2303.06543. [Google Scholar]
- Guo, C.; Wu, R.; Jin, X.; Han, L.; Zhang, W.; Chai, Z.; Li, C. Underwater ranker: Learn which is better and how to be better. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 702–709. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to See in the Dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–22 June 2018; pp. 3291–3300. [Google Scholar]
- Series, B. Methodology for the subjective assessment of the quality of television pictures. Recomm. ITU-R BT 2012, 13, 500. [Google Scholar]
- Bai, S.; Koltun, V.; Kolter, J.Z. Multiscale deep equilibrium models. Adv. Neural Inf. Process. Syst. 2020, 33, 5238–5250. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Ren, S.; Zhou, D.; He, S.; Feng, J.; Wang, X. Shunted self-attention via multi-scale token aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10853–10862. [Google Scholar]
- Wu, Y.-H.; Liu, Y.; Zhan, X.; Cheng, M.-M. P2T: Pyramid pooling transformer for scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 12760–12771. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3435–3444. [Google Scholar]
- Pan, Z.; Cai, J.; Zhuang, B. Fast vision transformers with hilo attention. Adv. Neural Inf. Process. Syst. 2022, 35, 14541–14554. [Google Scholar]
- Si, C.; Yu, W.; Zhou, P.; Zhou, Y.; Wang, X.; Yan, S. Inception transformer. Adv. Neural Inf. Process. Syst. 2022, 35, 23495–23509. [Google Scholar]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Focal network for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 13001–13011. [Google Scholar]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 4641–4650. [Google Scholar]
- Cui, Y.; Tao, Y.; Bing, Z.; Ren, W.; Gao, X.; Cao, X.; Huang, K.; Knoll, A. Selective frequency network for image restoration. In Proceedings of the The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Korhonen, J.; You, J. Peak signal-to-noise ratio revisited: Is simple beautiful? In Proceedings of the 2012 Fourth International Workshop on Quality of Multimedia Experience, Melbourne, Australia, 5–7 July 2012; pp. 37–38. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, S.; Zhao, S.; An, D.; Li, D.; Zhao, R. LiteEnhanceNet: A lightweight network for real-time single underwater image enhancement. Expert Syst. Appl. 2024, 240, 122546. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).