
Lane Centerline Extraction Based on Surveyed Boundaries: An Efficient Approach Using Maximal Disks



Abstract
1. Introduction
1.1. Related Work
1.2. Motivations and Contributions
- A novel approach for the extraction of the road centerline is proposed, based on MD. Instead of re-sampling the space, MDs are formed directly based on the constraining elements, either segments or their extreme points taken from the road boundaries.
- In addition to the identification of the relevant MDs, a criterion is proposed to link the centers of the MDs into a connected centerline.
- To relieve the computation burden, a segment pairing method to assemble suitable constraining elements is also presented.
- To improve the centerline calculation accuracy, ligatures are identified and additional circles are supplemented to reduce errors in the ligatures.
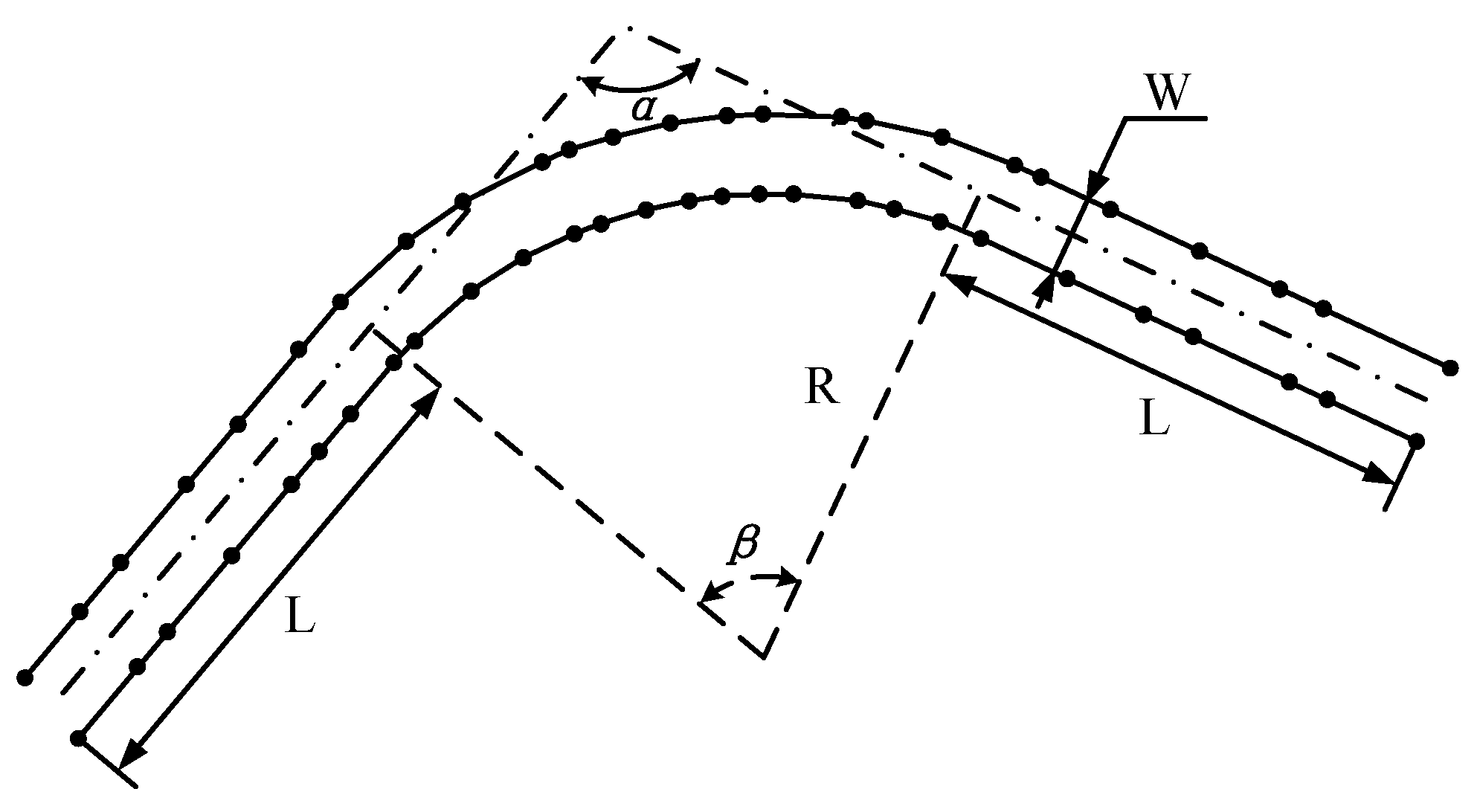
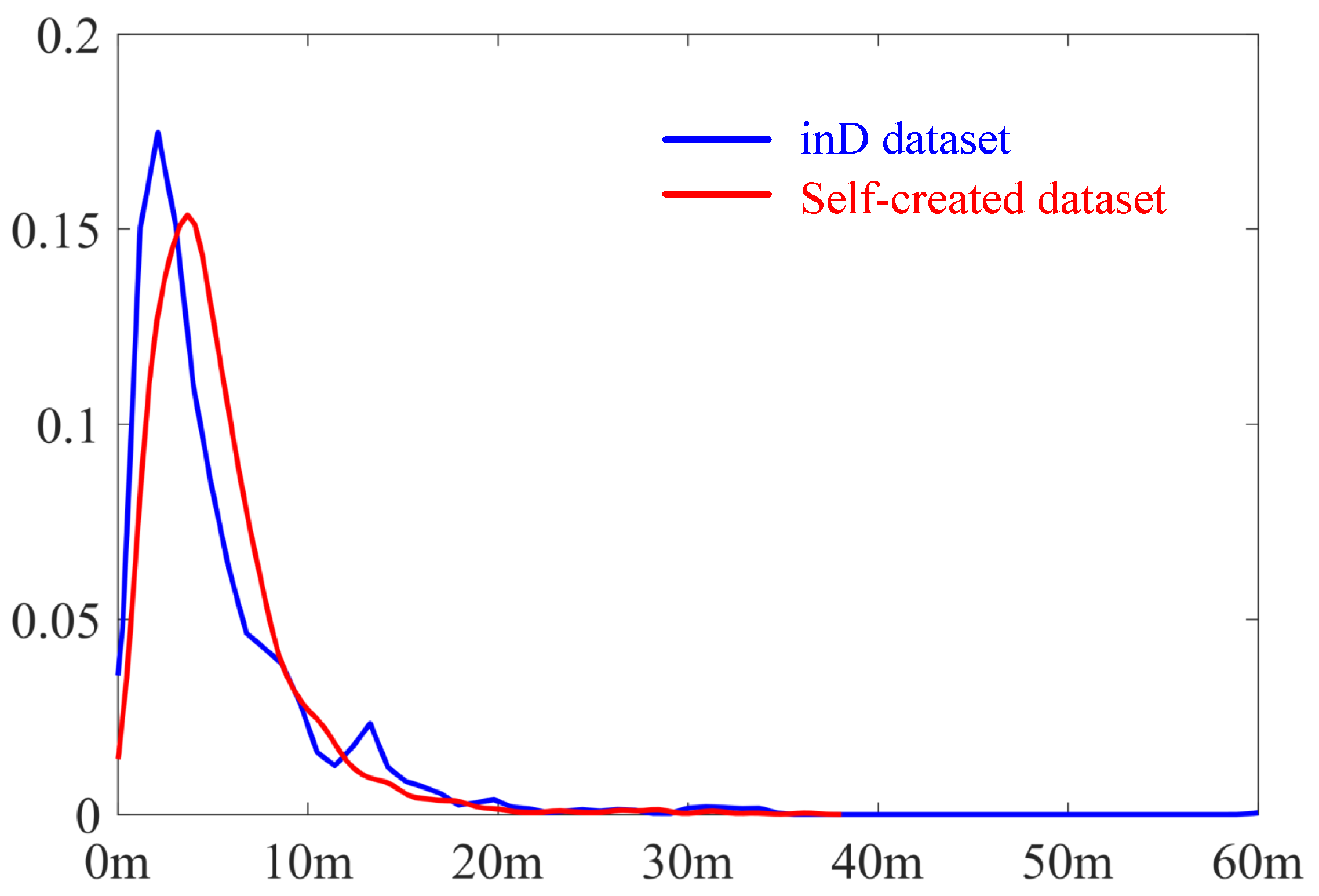
- To overcome the limitations of the available public datasets, and to control the effects of road geometry and sample density, a custom dataset has been generated based on relevant parameters.
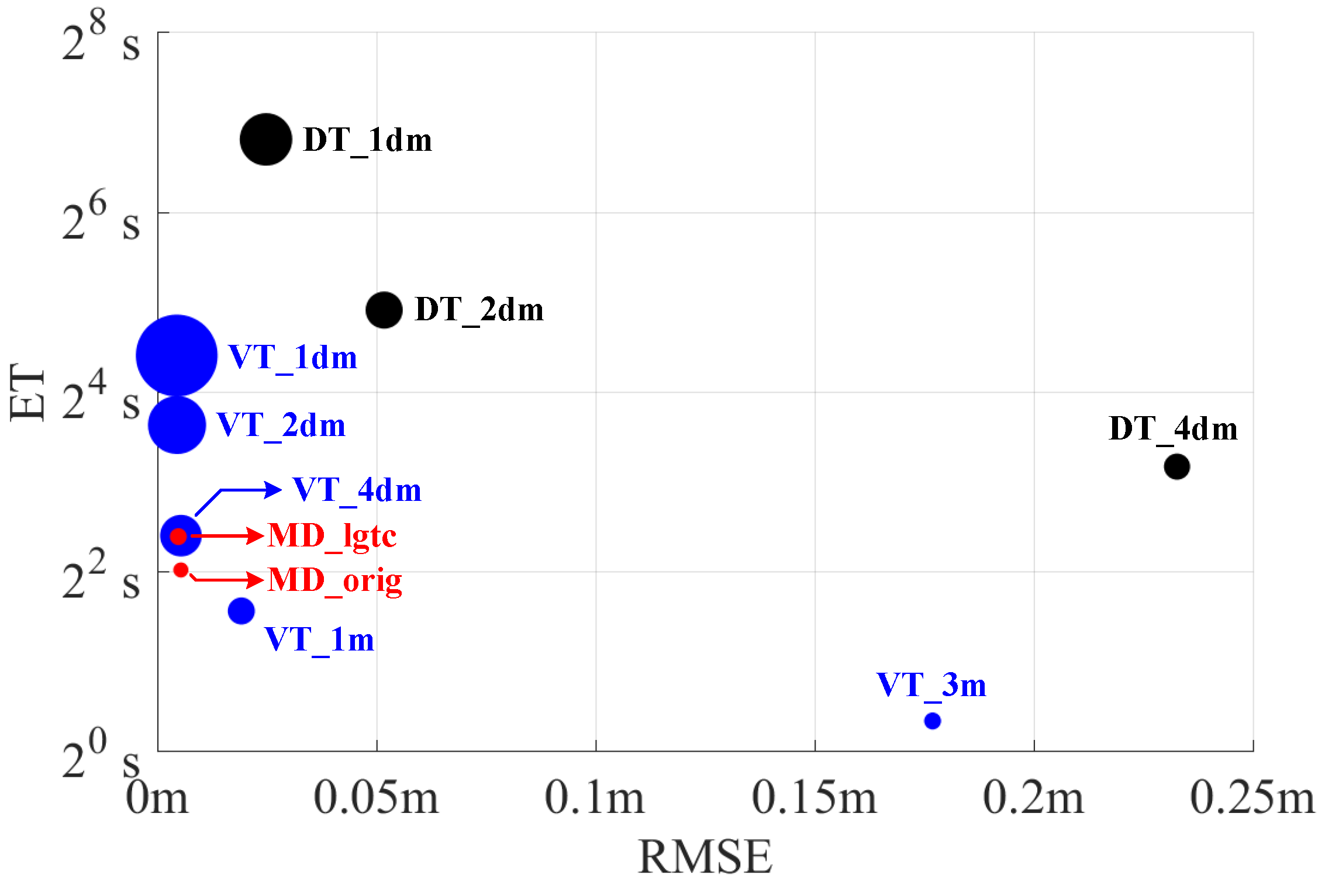
- Performances of the proposed approach and two popular skeletonization methods, based on VT and DT, are compared in sparse and dense scenarios from both a self-created and a public dataset of road layouts.
- By producing a minimal set of centerline points, the proposed method reduces the size of RL maps, is memory-efficient and, while its computational cost is comparable to other skeletonization methods, the reduced amount of data can save computational resources down the processing pipeline, typically in trajectory planning applications.
- The proposed method can be used to convert RL maps from border-based to centerline-based formats, retaining only the significant data points. This simplifies the manual maintenance of the produced RL maps. Additionally, the generated sparse representation of the RL can aid in road network analysis and ease the load for path planning applications.
- This paper provides valuable data on the accuracy, computational cost, and memory usage of the three methods mentioned above (MD, VT, and DT), allowing researchers to select the best approach when performing centerline extraction in dense and sparse scenarios.
- This method can automatically produce accurate centerlines that can be used as ground truth to train DL-based solutions.
2. Methodology
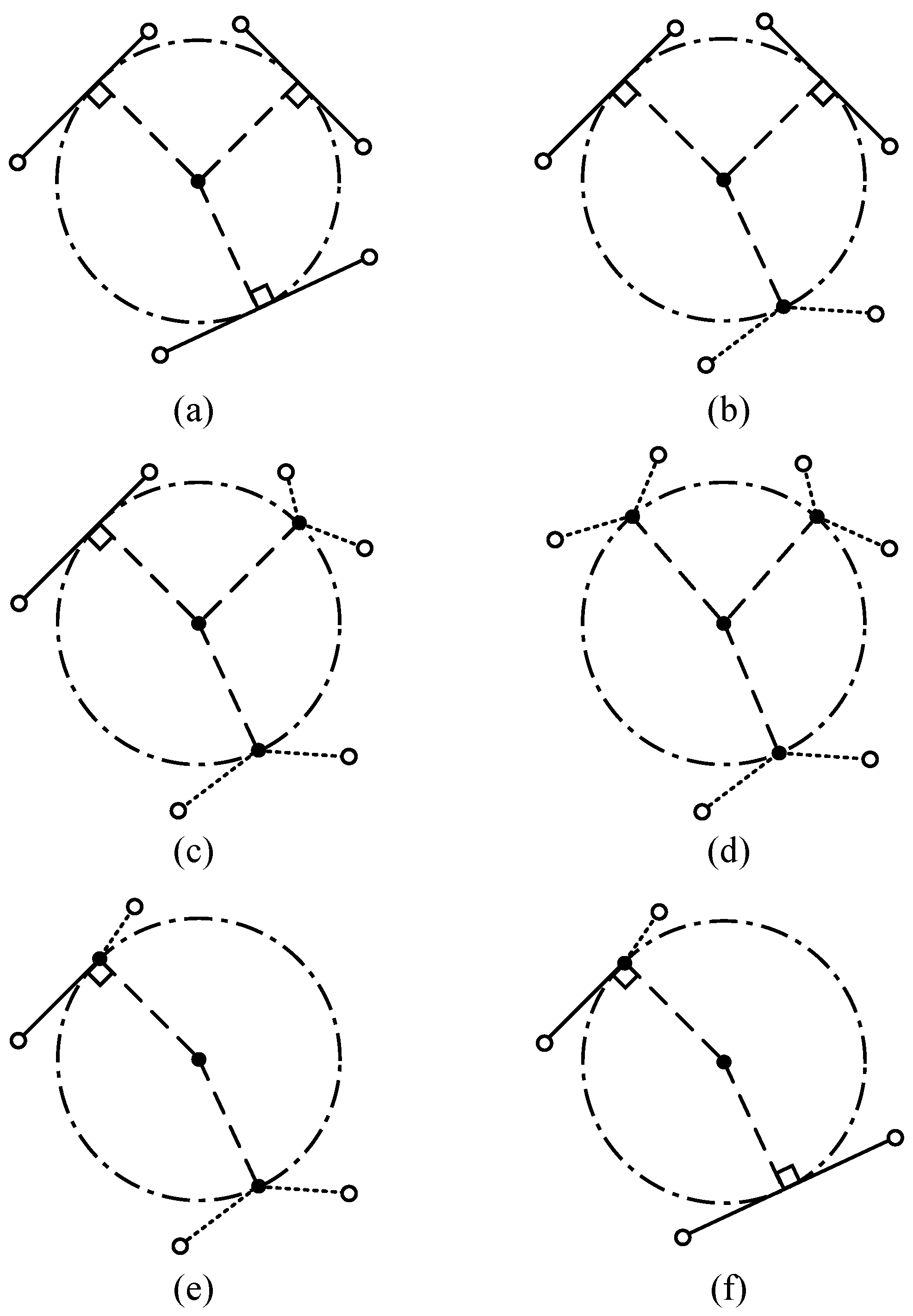
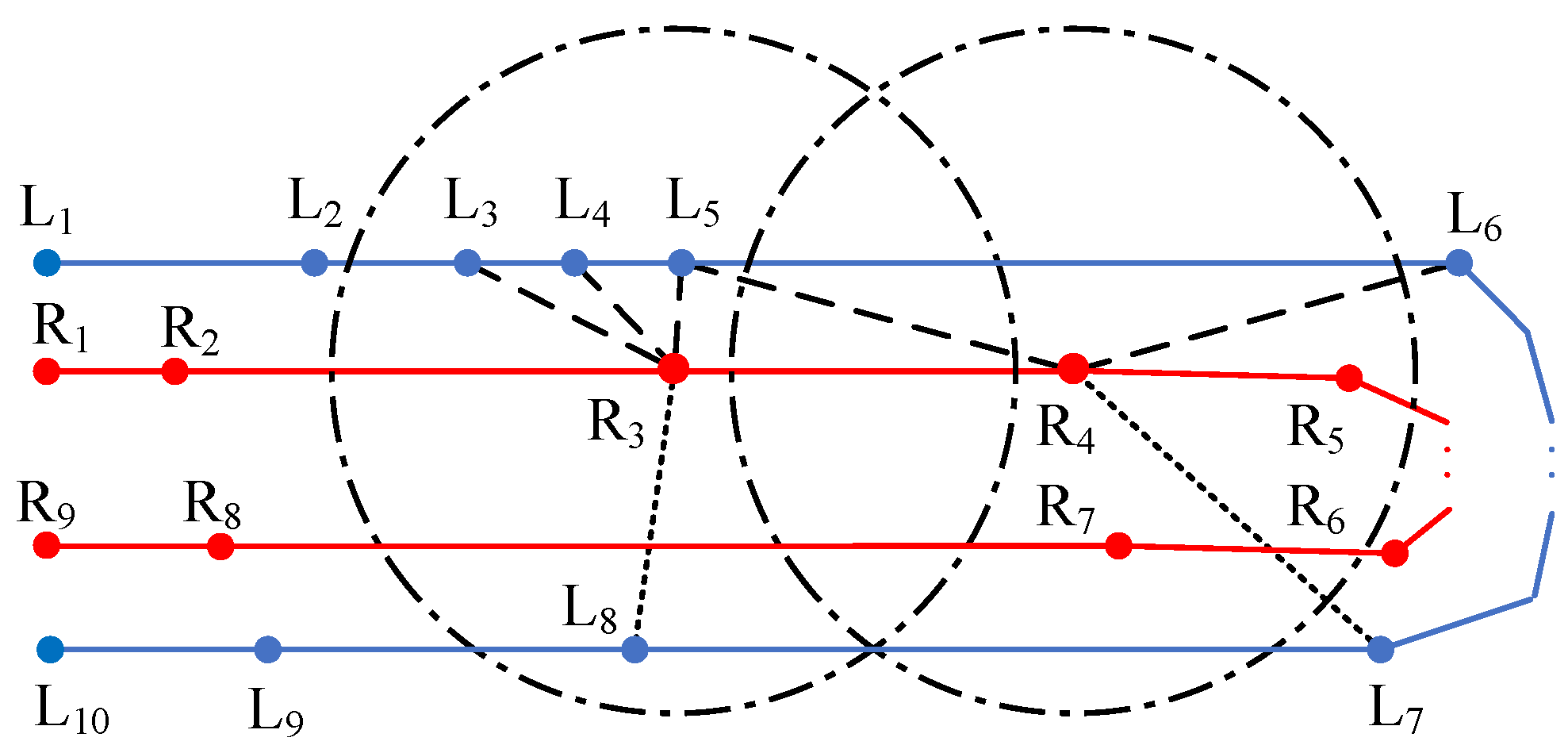
2.1. The Extraction of Lane Center Points Based on MD
2.2. Segment Pairing
2.3. Circle Centers Filtering
2.4. Connectivity of Circle Centers
2.5. Compensation for Ligature
2.6. The Pipeline of the Proposed Method
| Algorithm 1: Centerline Calculation based on MD |
Require: Surveyed points of both road lane borders: Ensure: Calculated centerline
|
2.7. The Extraction of Lane Centerlines Based on VT
2.8. The Extraction of Lane Centerlines Based on DT
3. Experiments and Results
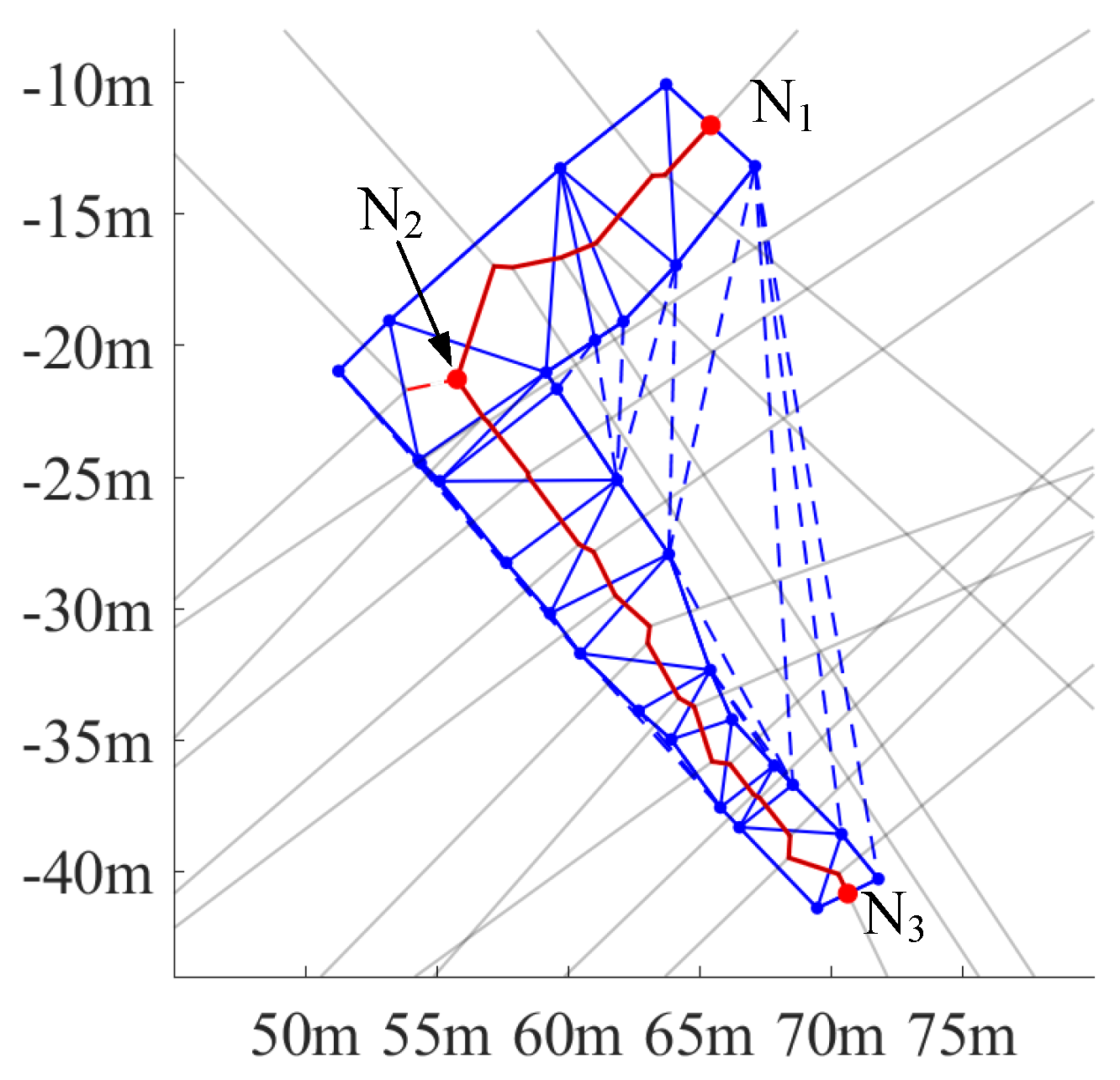
3.1. Data Description
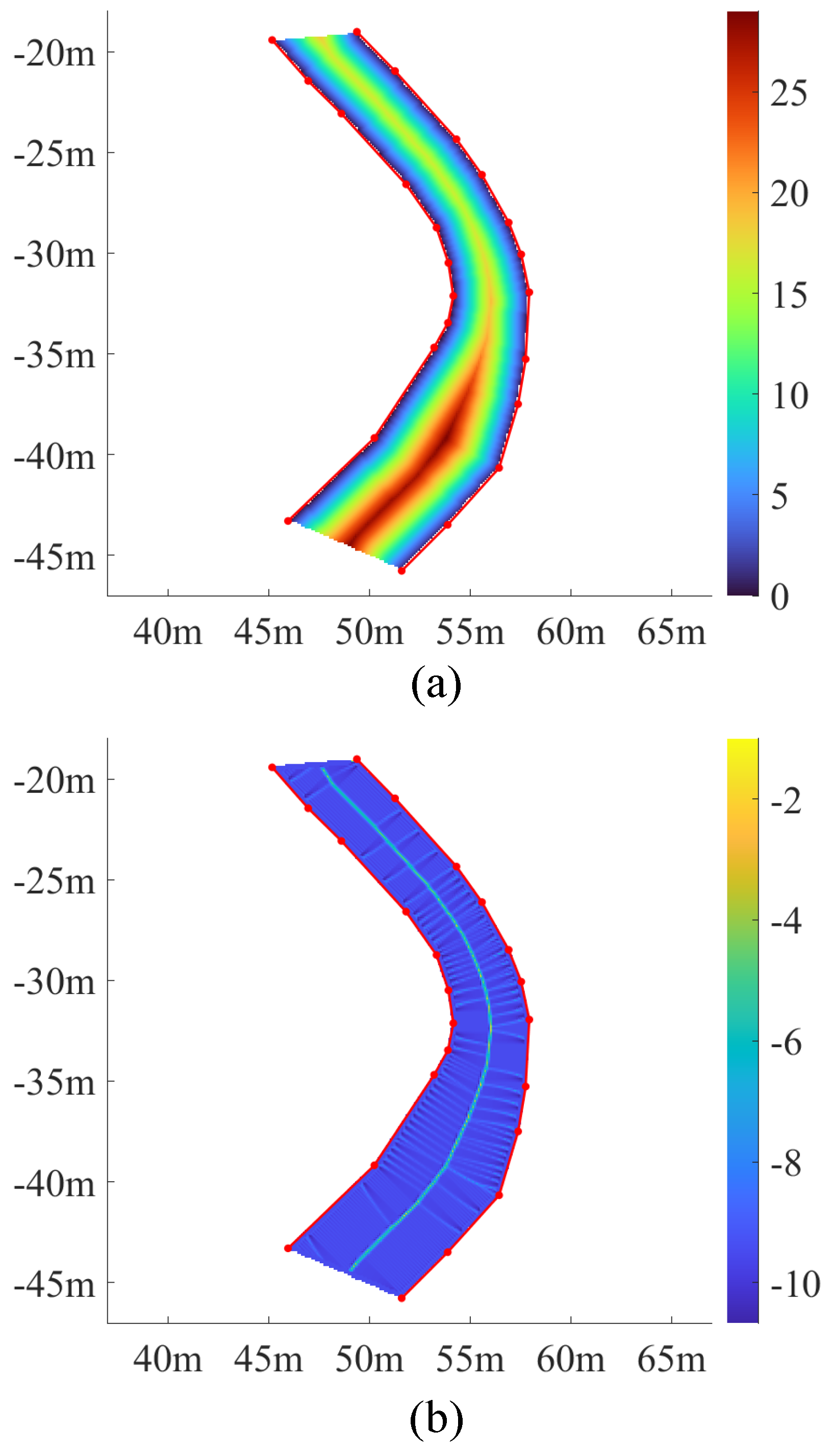
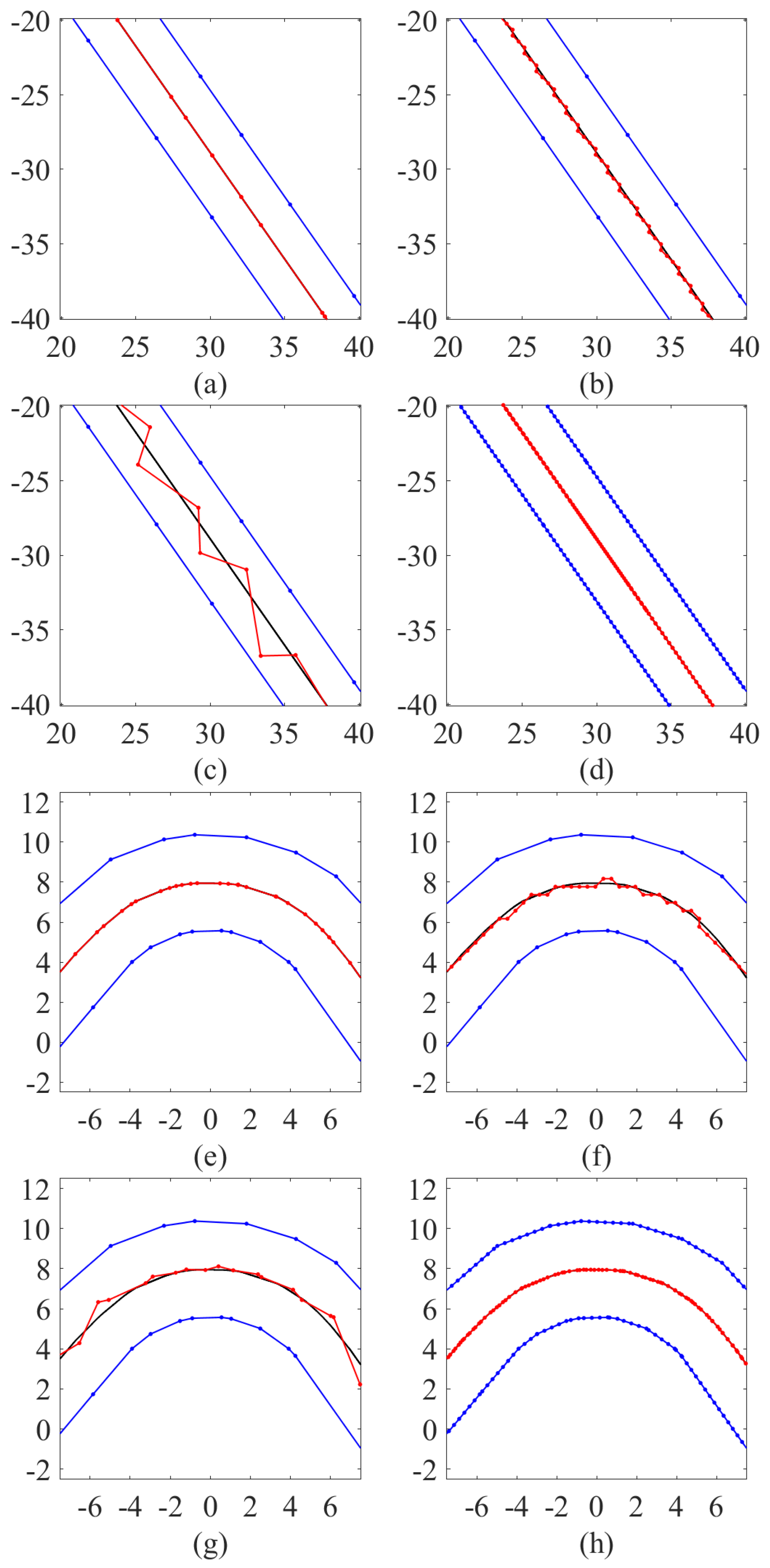
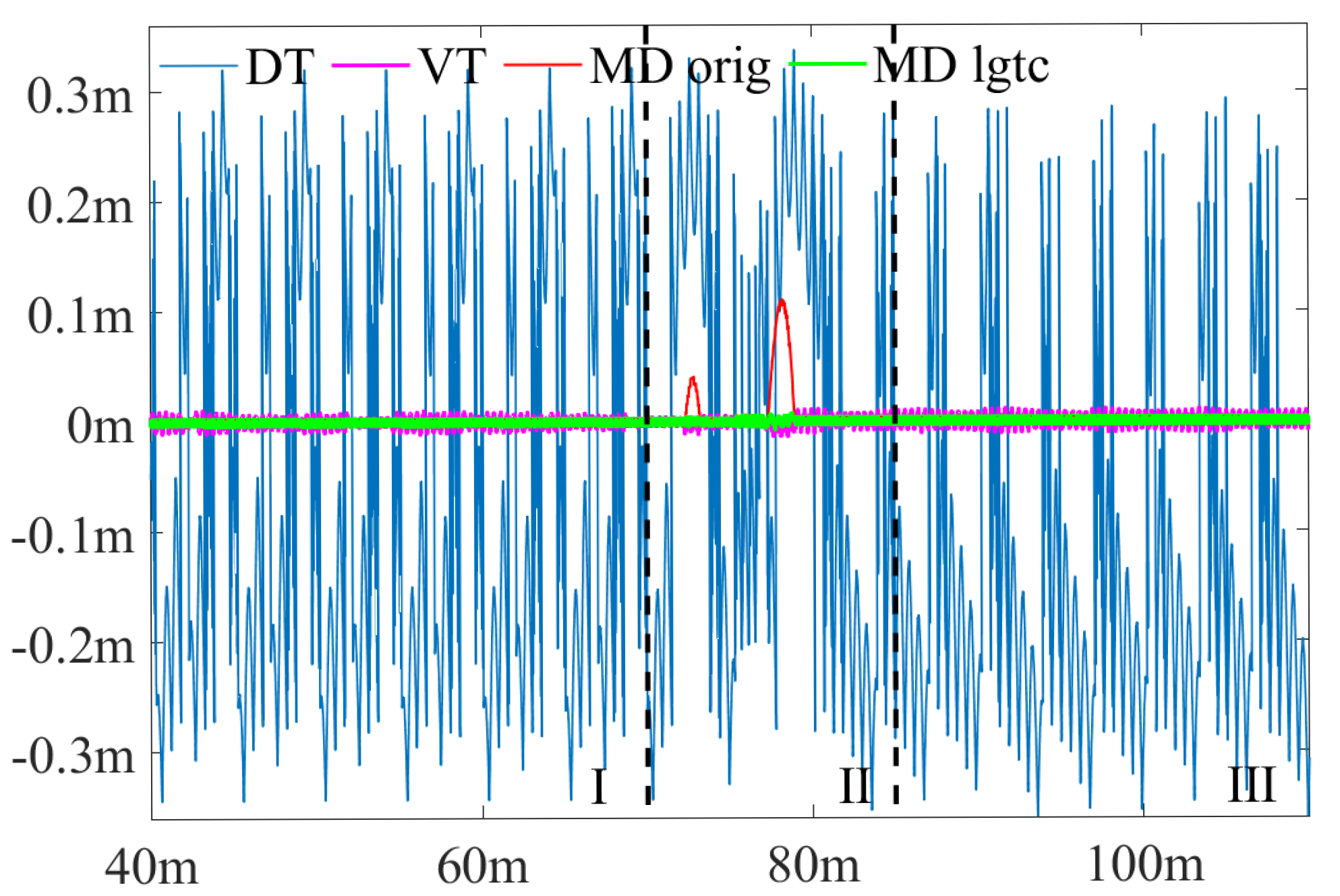
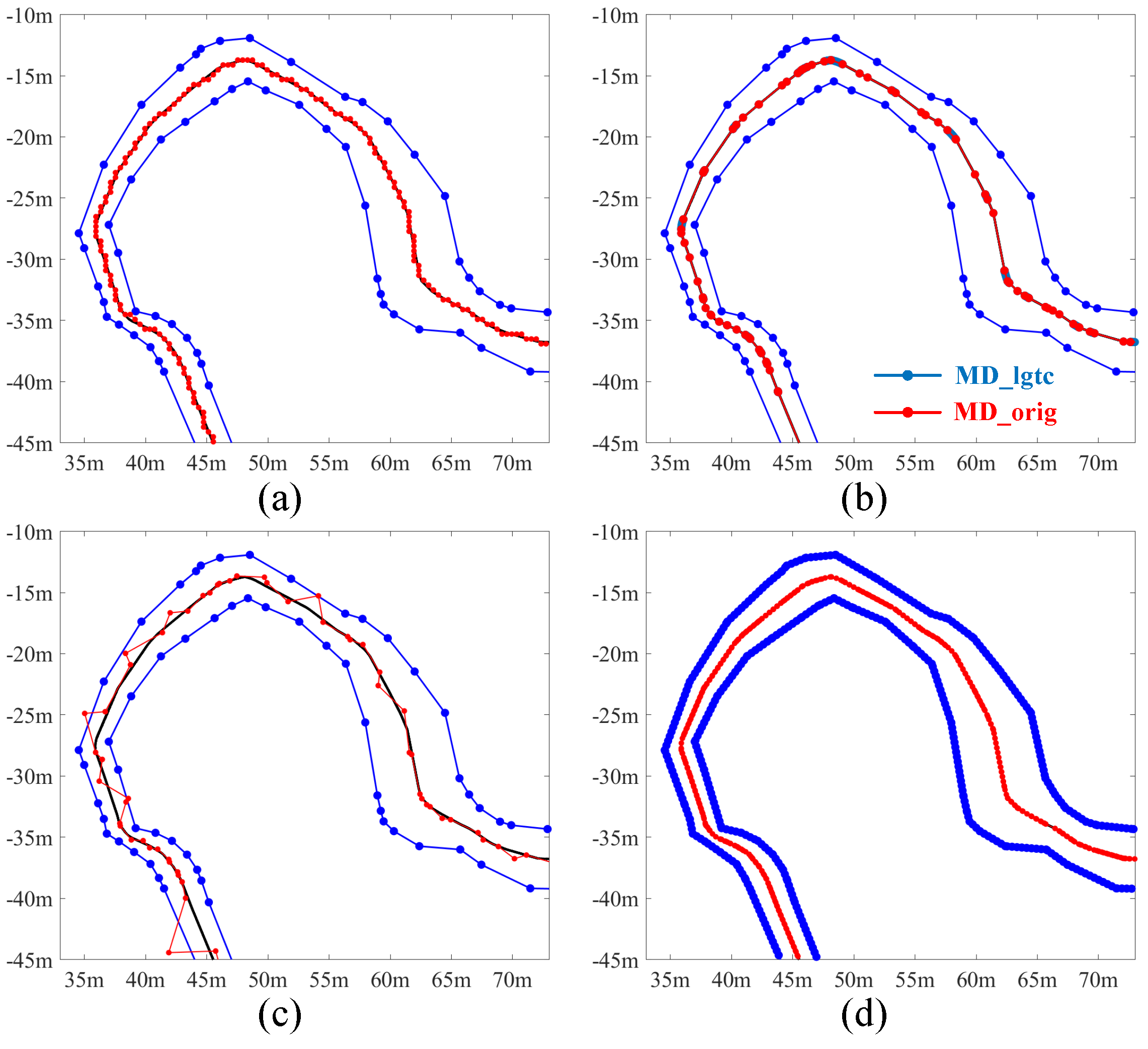
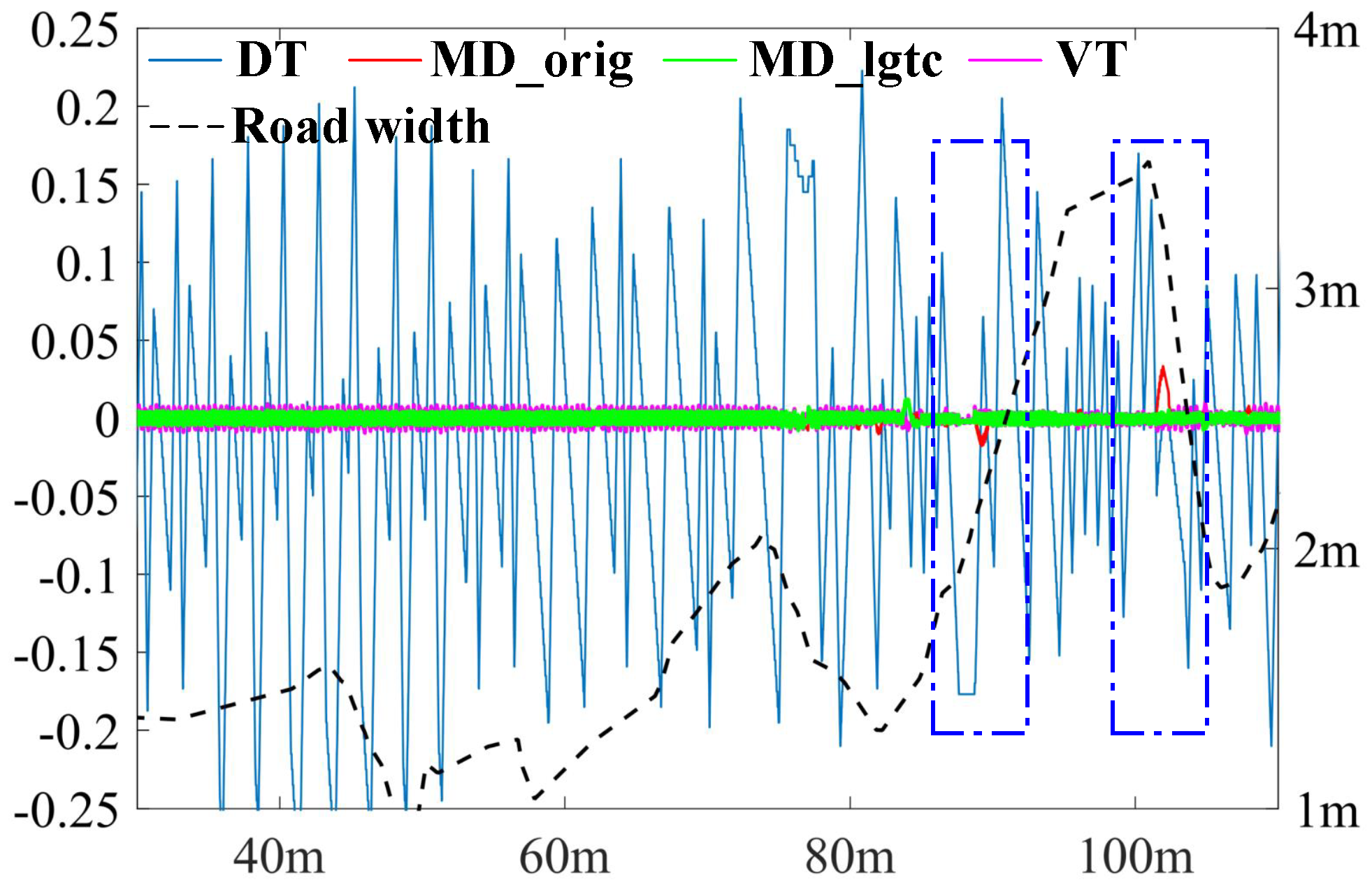
3.2. Experimental Results and Comparisons
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| accu | accumulated |
| avrg | average |
| DL | Deep Learning |
| DT | Distance Transform |
| DLT | Discrete Laplace Transform |
| ET | Execution Time |
| KDE | Kernel Density Estimation |
| lgth | length |
| lgtc | ligature compensation |
| LHS | Latin Hypercube Sampling |
| maxDevi | Maximal Deviation |
| num | number |
| MD | Maximal Disk |
| orig | original |
| RL | Road Layout |
| RMSE | Root Mean Squre Error |
| SAM | Steepest Ascent Method |
| seg | segment |
| SCD | Self-Created Dataset |
| Sce | Scenario |
| std | standard deviation |
| VT | Voronoi Tessellation |
References
- Poggenhans, F.; Pauls, J.H.; Janosovits, J.; Orf, S.; Naumann, M.; Kuhnt, F.; Mayr, M. Lanelet2: A high-definition map framework for the future of automated driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 1672–1679. [Google Scholar]
- Geiger, A.; Lauer, M.; Moosmann, F.; Ranft, B.; Rapp, H.; Stiller, C.; Ziegler, J. Team AnnieWAY’s entry to the 2011 grand cooperative driving challenge. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1008–1017. [Google Scholar] [CrossRef]
- Bender, P.; Ziegler, J.; Stiller, C. Lanelets: Efficient map representation for autonomous driving. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014; pp. 420–425. [Google Scholar]
- Yin, C.; Cecotti, M.; Auger, D.J.; Fotouhi, A.; Jiang, H. Deep-learning-based vehicle trajectory prediction: A review. IET Intell. Transp. Syst. 2025, 19, e70001. [Google Scholar] [CrossRef]
- Murciego, E.; Huélamo, C.G.; Barea, R.; Bergasa, L.M.; Romera, E.; Arango, J.F.; Tradacete, M.; Sáez, Á. Topological road mapping for autonomous driving applications. In Advances in Physical Agents, Proceedings of the 19th International Workshop of Physical Agents (WAF 2018), Madrid, Spain, 22–23 November 2018; Springer: Cham, Switzerland, 2019; pp. 257–270. [Google Scholar]
- Zhang, T.; Zhou, J.; Liu, W.; Yue, R.; Shi, J.; Zhou, C.; Hu, J. SN-CNN: A Lightweight and Accurate Line Extraction Algorithm for Seedling Navigation in Ridge-Planted Vegetables. Agriculture 2024, 14, 1446. [Google Scholar] [CrossRef]
- Li, J.; Su, S.; Zhang, T.; Liu, Z. Research on the Road Network Design Optimization Based on SA-Apriori Analysis Considering Road Traffic Accidents (RTAs). IEEE Access 2024, 12, 160918–160926. [Google Scholar] [CrossRef]
- ASAM OpenDRIVE. 2025. Available online: https://www.asam.net/standards/detail/opendrive/ (accessed on 20 February 2025).
- Althoff, M.; Urban, S.; Koschi, M. Automatic conversion of road networks from opendrive to lanelets. In Proceedings of the 2018 IEEE International Conference on Service Operations and Logistics, and Informatics (SOLI), Singapore, 31 July–2 August 2018; pp. 157–162. [Google Scholar]
- Das, P.; Chand, S.; Singh, N.K.; Singh, P. Automated Road Extraction from Remotely Sensed Imagery using ConnectNet. J. Indian Soc. Remote Sens. 2023, 51, 2105–2120. [Google Scholar] [CrossRef]
- Lourenço, M.; Estima, D.; Oliveira, H.; Oliveira, L.; Mora, A. Automatic rural road centerline detection and extraction from aerial images for a forest fire decision support system. Remote Sens. 2023, 15, 271. [Google Scholar] [CrossRef]
- Wang, Q.; Qin, W.; Liu, M.; Zhao, J.; Zhu, Q.; Yin, Y. Semantic Segmentation Model-Based Boundary Line Recognition Method for Wheat Harvesting. Agriculture 2024, 14, 1846. [Google Scholar] [CrossRef]
- Liu, R.; Song, J.; Miao, Q.; Xu, P.; Xue, Q. Road centerlines extraction from high resolution images based on an improved directional segmentation and road probability. Neurocomputing 2016, 212, 88–95. [Google Scholar] [CrossRef]
- Liu, P.; Wang, Q.; Yang, G.; Li, L.; Zhang, H. Survey of road extraction methods in remote sensing images based on deep learning. PFG—J. Photogramm. Remote Sens. Geoinf. Sci. 2022, 90, 135–159. [Google Scholar] [CrossRef]
- Xiao, F.; Tong, L.; Li, Y.; Luo, S.; Benediktsson, J.A. A General Spline-Based Method for Centerline Extraction from Different Segmented Road Maps in Remote Sensing Imagery. Remote Sens. 2022, 14, 2074. [Google Scholar] [CrossRef]
- Soni, P.K.; Rajpal, N.; Mehta, R. Road centerline extraction from VHR images using SVM and multi-scale maximum response filter. J. Indian Soc. Remote Sens. 2021, 49, 1519–1532. [Google Scholar] [CrossRef]
- Alshaikhli, T.; Liu, W.; Maruyama, Y. Simultaneous extraction of road and centerline from aerial images using a deep convolutional neural network. ISPRS Int. J.-Geo-Inf. 2021, 10, 147. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Jiang, S.; Li, Y.; Wang, J. Narrow road extraction from high-resolution remote sensing images: SWGE-Net and MSIF-Net. Geo-Spat. Inf. Sci. 2024, 1, 1–18. [Google Scholar] [CrossRef]
- Wei, Y.; Hu, X.; Gong, J. End-to-end road centerline extraction via learning a confidence map. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 19–20 August 2018; pp. 1–5. [Google Scholar]
- Biçici, S.; Zeybek, M. Improvements on road centerline extraction by combining voronoi diagram and intensity feature from 3d uav-based point cloud. In Proceedings of the International Conference on Smart City Applications, Virtual, 27–29 October 2021; pp. 935–944. [Google Scholar]
- Oner, D.; Koziński, M.; Citraro, L.; Dadap, N.C.; Konings, A.G.; Fua, P. Promoting connectivity of network-like structures by enforcing region separation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5401–5413. [Google Scholar] [CrossRef]
- Klischat, M.; Liu, E.I.; Holtke, F.; Althoff, M. Scenario factory: Creating safety-critical traffic scenarios for automated vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Liao, B.; Chen, S.; Jiang, B.; Cheng, T.; Zhang, Q.; Liu, W.; Huang, C.; Wang, X. Lane graph as path: Continuity-preserving path-wise modeling for online lane graph construction. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 334–351. [Google Scholar]
- Xiong, X.; Liu, Y.; Yuan, T.; Wang, Y.; Wang, Y.; Zhao, H. Neural map prior for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17535–17544. [Google Scholar]
- Zhuang, X.; Li, Y. Segmentation and angle calculation of rice lodging during harvesting by a combine harvester. Agriculture 2023, 13, 1425. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, Y.; Liao, B.; Xie, J.; Cheng, T.; Sui, W.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Vma: Divide-and-conquer vectorized map annotation system for large-scale driving scene. arXiv 2023, arXiv:2304.09807. [Google Scholar]
- Liu, Y.; Yuan, T.; Wang, Y.; Wang, Y.; Zhao, H. Vectormapnet: End-to-end vectorized hd map learning. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 22352–22369. [Google Scholar]
- Liao, B.; Chen, S.; Zhang, Y.; Jiang, B.; Zhang, Q.; Liu, W.; Huang, C.; Wang, X. Maptrv2: An end-to-end framework for online vectorized hd map construction. Int. J. Comput. Vis. 2024, 133, 1352–1374. [Google Scholar] [CrossRef]
- Chang, M.F.; Lambert, J.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8748–8757. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Wagner, M.G. Real-time thinning algorithms for 2D and 3D images using GPU processors. J.-Real-Time Image Process. 2020, 17, 1255–1266. [Google Scholar] [CrossRef]
- McAllister, M.; Snoeyink, J. Medial axis generalization of river networks. Cartogr. Geogr. Inf. Sci. 2000, 27, 129–138. [Google Scholar] [CrossRef]
- Selvi, H.Z.; Oztug Bildirici, I.; Yerci, M. Triangulation method for area-line geometry-type changes in map generalisation. Cartogr. J. 2010, 47, 157–163. [Google Scholar] [CrossRef]
- Golly, A.; Turowski, J.M. Deriving principal channel metrics from bank and long-profile geometry with the R package cmgo. Earth Surf. Dyn. 2017, 5, 557–570. [Google Scholar] [CrossRef]
- Yang, X.; Pavelsky, T.M.; Allen, G.H.; Donchyts, G. RivWidthCloud: An automated Google Earth Engine algorithm for river width extraction from remotely sensed imagery. IEEE Geosci. Remote Sens. Lett. 2019, 17, 217–221. [Google Scholar] [CrossRef]
- Jalba, A.C.; Sobiecki, A.; Telea, A.C. An unified multiscale framework for planar, surface, and curve skeletonization. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 30–45. [Google Scholar] [CrossRef] [PubMed]
- Boudaoud, L.B.; Sider, A.; Tari, A. A new thinning algorithm for binary images. In Proceedings of the 2015 3rd International Conference on Control, Engineering & Information Technology (CEIT), Tlemcen, Algeria, 25–27 May 2015; pp. 1–6. [Google Scholar]
- Chen, Z.; Yin, X.; Lin, L.; Shi, G.; Mo, J. Centerline extraction by neighborhood-statistics thinning for quantitative analysis of corneal nerve fibers. Phys. Med. Biol. 2022, 67, 145005. [Google Scholar] [CrossRef]
- Ben Boudaoud, L.; Solaiman, B.; Tari, A. A modified ZS thinning algorithm by a hybrid approach. Vis. Comput. 2018, 34, 689–706. [Google Scholar] [CrossRef]
- Matute, J.; Telea, A.C.; Linsen, L. Skeleton-based scagnostics. IEEE Trans. Vis. Comput. Graph. 2017, 24, 542–552. [Google Scholar] [CrossRef]
- Arcelli, C.; Di Baja, G.S.; Serino, L. Distance-driven skeletonization in voxel images. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 709–720. [Google Scholar] [CrossRef]
- Strutz, T. The distance transform and its computation. arXiv 2021, arXiv:2106.03503. [Google Scholar]
- Koka, S.; Anada, K.; Nakayama, Y.; Sugita, K.; Yaku, T.; Yokoyama, R. A comparison of ridge detection methods for DEM data. In Proceedings of the 2012 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Kyoto, Japan, 8–10 August 2012; pp. 513–517. [Google Scholar]
- Niblack, C.W.; Gibbons, P.B.; Capson, D.W. Generating skeletons and centerlines from the distance transform. CVGIP Graph. Model. Image Process. 1992, 54, 420–437. [Google Scholar] [CrossRef]
- Blum, H.; Nagel, R.N. Shape description using weighted symmetric axis features. Pattern Recognit. 1978, 10, 167–180. [Google Scholar] [CrossRef]
- Yang, C.; Indurkhya, B.; See, J.; Grzegorzek, M. Towards automatic skeleton extraction with skeleton grafting. IEEE Trans. Vis. Comput. Graph. 2020, 27, 4520–4532. [Google Scholar] [CrossRef]
- Choi, W.P.; Lam, K.M.; Siu, W.C. Extraction of the Euclidean skeleton based on a connectivity criterion. Pattern Recognit. 2003, 36, 721–729. [Google Scholar] [CrossRef]
- Bai, X.; Latecki, L.J.; Liu, W.Y. Skeleton pruning by contour partitioning with discrete curve evolution. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 449–462. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Cai, Y.; Yuan, W. Voronoi centerline-based seamline network generation method. Remote Sens. 2023, 15, 917. [Google Scholar] [CrossRef]
- Chen, C.; Mei, X.; Hou, D.; Fan, Z.; Huang, W. A Voronoi-Diagram-based method for centerline extraction in 3D industrial line-laser reconstruction using a graph-centrality-based pruning algorithm. Optik 2022, 261, 169179. [Google Scholar] [CrossRef]
- Jiang, Z.; Rahmani, H.; Angelov, P.; Vyas, R.; Zhou, H.; Black, S.; Williams, B. Deep orientated distance-transform network for geometric-aware centerline detection. Pattern Recognit. 2024, 146, 110028. [Google Scholar] [CrossRef]
- Wang, B.; Ma, Y.; Zhang, Y.; Yang, Y.; Wang, Y.; Li, H. An affine transform center line extraction and discontinuity deviation correction method for non-orthogonal grid laser. Phys. Scr. 2023, 98, 115535. [Google Scholar] [CrossRef]
- Malkov, Y.A.; Yashunin, D.A. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 824–836. [Google Scholar] [CrossRef]
- Lee, D.T.; Schachter, B.J. Two algorithms for constructing a Delaunay triangulation. Int. J. Comput. Inf. Sci. 1980, 9, 219–242. [Google Scholar] [CrossRef]
- Aliyan, M.; Hasan, M.Z.; Qayoom, H.; Hussain, M.Z.; Nosheen, S.; Mustafa, M.; Chuhan, S.H.; Yaqub, M.A.; Awan, R.; Bilal, A. Analysis and performance evaluation of various shortest path algorithms. In Proceedings of the 2024 3rd International Conference for Innovation in Technology (INOCON), Bangalore, India, 1–3 March 2024; pp. 1–16. [Google Scholar]
- Tejenaki, S.A.K.; Ebadi, H.; Mohammadzadeh, A. A new hierarchical method for automatic road centerline extraction in urban areas using LIDAR data. Adv. Space Res. 2019, 64, 1792–1806. [Google Scholar] [CrossRef]
- Association, A.S.H.; Officials, T. A Policy on Geometric Design of Highways and Streets, 2018; American Association of State Highway and Transportation Officials: Washington, DC, USA, 2018; Available online: https://books.google.co.uk/books?id=s36gwwEACAAJ (accessed on 7 April 2025).
- Helton, J.C.; Davis, F.J. Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems. Reliab. Eng. Syst. Saf. 2003, 81, 23–69. [Google Scholar] [CrossRef]
- Bock, J.; Krajewski, R.; Moers, T.; Runde, S.; Vater, L.; Eckstein, L. The ind dataset: A drone dataset of naturalistic road user trajectories at german intersections. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1929–1934. [Google Scholar]
- Jiang, H.; Pi, J.; Li, A.; Yin, C. Dynamic local path planning for intelligent vehicles based on sampling area point discrete and quadratic programming. IEEE Access 2022, 10, 70279–70294. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| numLanes | accuLgth [m] | avrgSegLgth [m] | maxSegLgth [m] | minSegLgth [m] | |
|---|---|---|---|---|---|
| Sce1 | 27 | 2884 | 4.13 | 21.51 | 0.10 |
| Sce2 | 34 | 4855 | 6.10 | 88.85 | 0.13 |
| Sce3 | 20 | 1671 | 3.61 | 17.29 | 0.04 |
| Sce4 | 22 | 4024 | 7.08 | 33.90 | 0.23 |
| SCD | 36 | 5473 | 5.31 | 36.19 | 0.35 |
| avrgWidth [m] | maxWidth [m] | minWidth [m] | stdWidth [m] | |
|---|---|---|---|---|
| Sce1 | 1.68 | 4.05 | 0.68 | 0.51 |
| Sce2 | 1.64 | 3.44 | 0.59 | 0.50 |
| Sce3 | 1.67 | 3.89 | 0.43 | 0.61 |
| Sce4 | 1.71 | 4.48 | 0.75 | 0.51 |
| SCD | 2.08 | 3.65 | 0.45 | 1.02 |
| Method | ET [s] | Point Number | maxDevi of All Lanes [mm] | RMSE of All Lanes [mm] | |
|---|---|---|---|---|---|
| MD | orig | 4.053 | 3675 | 119.3 | 5.4 |
| lgtc | 5.243 | 4566 | 119.3 | 4.8 | |
| DT | 0.4 m | 8.997 | 11,050 | 959.2 | 226.8 |
| 0.2 m | 30.109 | 22,136 | 207.9 | 51.7 | |
| 0.1 m | 112.317 | 44,258 | 101.2 | 24.8 | |
| 0.02 m | 2168.122 | 221,366 | 21.2 | 7.2 | |
| VT | sparse | 0.692 | 2077 | 58,446.8 | 7458.7 |
| 4 m | 0.8205 | 3734 | 1664.1 | 319.9 | |
| 3 m | 1.264 | 4598 | 1051.4 | 176.8 | |
| 1 m | 2.953 | 11,718 | 161.3 | 19.2 | |
| 0.4 m | 5.280 | 27,730 | 32.3 | 5.4 | |
| 0.2 m | 12.405 | 54,290 | 15.6 | 4.5 | |
| 0.1 m | 21.195 | 107,581 | 12.5 | 4.4 | |
| Methods | Sce1 | Sce2 | Sce3 | Sce4 | Sce1–4 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| maxDevi | RMSE | maxDevi | RMSE | maxDevi | RMSE | maxDevi | RMSE | Point Number | ||
| MD | lgtc | 18.1 | 4.5 | 19.7 | 4.3 | 23.8 | 4.4 | 15.1 | 4.3 | 9782 |
| VT | 4 m | 910.2 | 214.9 | 828.4 | 248.7 | 1236.8 | 236.6 | 812.9 | 222.1 | 4554 |
| VT | 0.4 m | 15.6 | 5.1 | 16.4 | 5.0 | 16.6 | 5.3 | 13.6 | 4.8 | 33,734 |
| Methods | Sce1 | Sce2 | Sce3 | Sce4 | Sce1–4 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| maxDevi | RMSE | maxDevi | RMSE | maxDevi | RMSE | maxDevi | RMSE | Point Number | ||
| MD | lgtc | 93.9 | 5.9 | 88.1 | 5.3 | 36.8 | 4.5 | 35.8 | 4.3 | 10,777 |
| VT | 4 m | 1173.5 | 241.5 | 1411.8 | 330.0 | 1970.5 | 450.8 | 992.7 | 313.2 | 4688 |
| VT | 0.4 m | 17.4 | 5.5 | 20.1 | 5.7 | 24.5 | 6.3 | 15.5 | 5.2 | 33,728 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, C.; Cecotti, M.; Auger, D.J.; Fotouhi, A.; Jiang, H. Lane Centerline Extraction Based on Surveyed Boundaries: An Efficient Approach Using Maximal Disks. Sensors 2025, 25, 2571. https://doi.org/10.3390/s25082571
Yin C, Cecotti M, Auger DJ, Fotouhi A, Jiang H. Lane Centerline Extraction Based on Surveyed Boundaries: An Efficient Approach Using Maximal Disks. Sensors. 2025; 25(8):2571. https://doi.org/10.3390/s25082571
Chicago/Turabian StyleYin, Chenhui, Marco Cecotti, Daniel J. Auger, Abbas Fotouhi, and Haobin Jiang. 2025. "Lane Centerline Extraction Based on Surveyed Boundaries: An Efficient Approach Using Maximal Disks" Sensors 25, no. 8: 2571. https://doi.org/10.3390/s25082571
APA StyleYin, C., Cecotti, M., Auger, D. J., Fotouhi, A., & Jiang, H. (2025). Lane Centerline Extraction Based on Surveyed Boundaries: An Efficient Approach Using Maximal Disks. Sensors, 25(8), 2571. https://doi.org/10.3390/s25082571