
A KWS System for Edge-Computing Applications with Analog-Based Feature Extraction and Learned Step Size Quantized Classifier



Abstract
1. Introduction
- Outstanding trade-off between classification accuracy and complexity. The proposed KWS system employs the same analog feature extraction configuration as in [10], but achieves higher accuracy, 92.33% with the full-precision model and 91.35% with the quantized model, compared to 91.00% in [10]. The GRU-based classifier uses only 80 neurons per layer, versus 128 in the reference design.
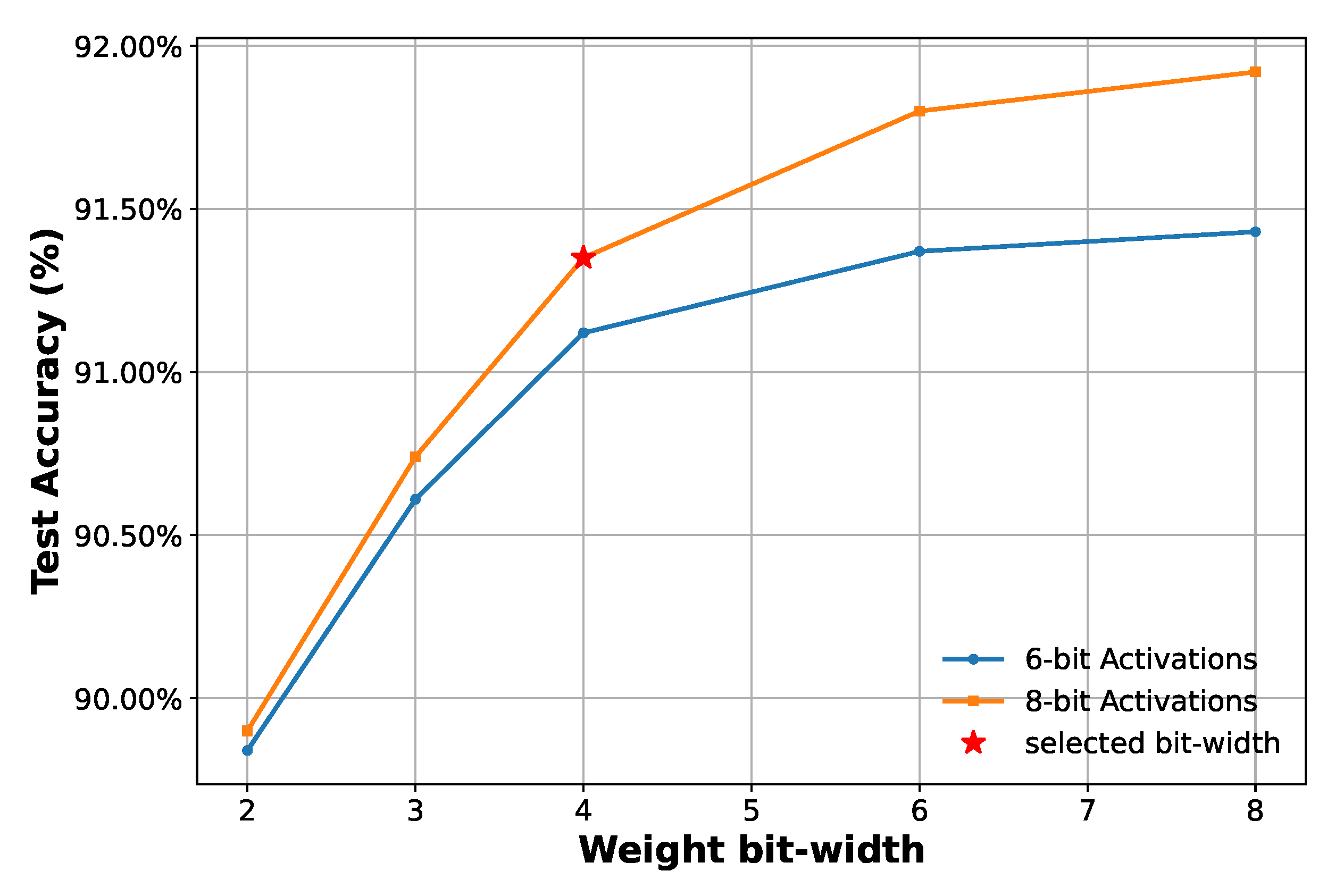
- Learned Step Size (LSQ) and Look-Up Table (LUT)-aware quantization for efficient deployment. Unlike previous works that use post-training or fixed-point quantization, the model leverages LSQ and LUT-aware quantization during training. This enables adaptive optimization of quantization parameters, reducing memory and power consumption while maintaining high recognition accuracy. The resulting model operates with 4-bit weights and 8-bit activations (W4A8), significantly lowering computational complexity compared to models using 8-bit weights and 12-bit or higher activations in [12,15].
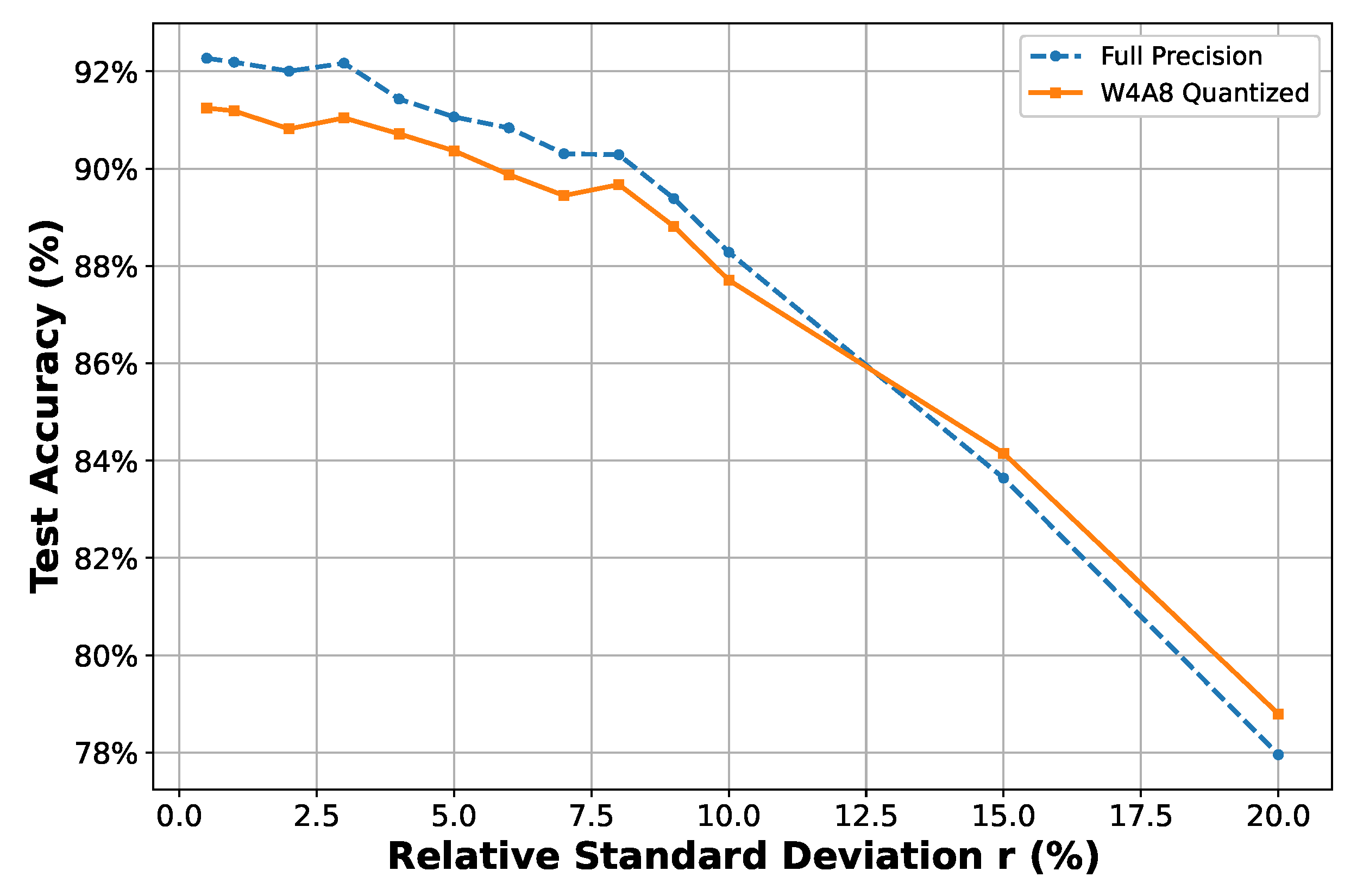
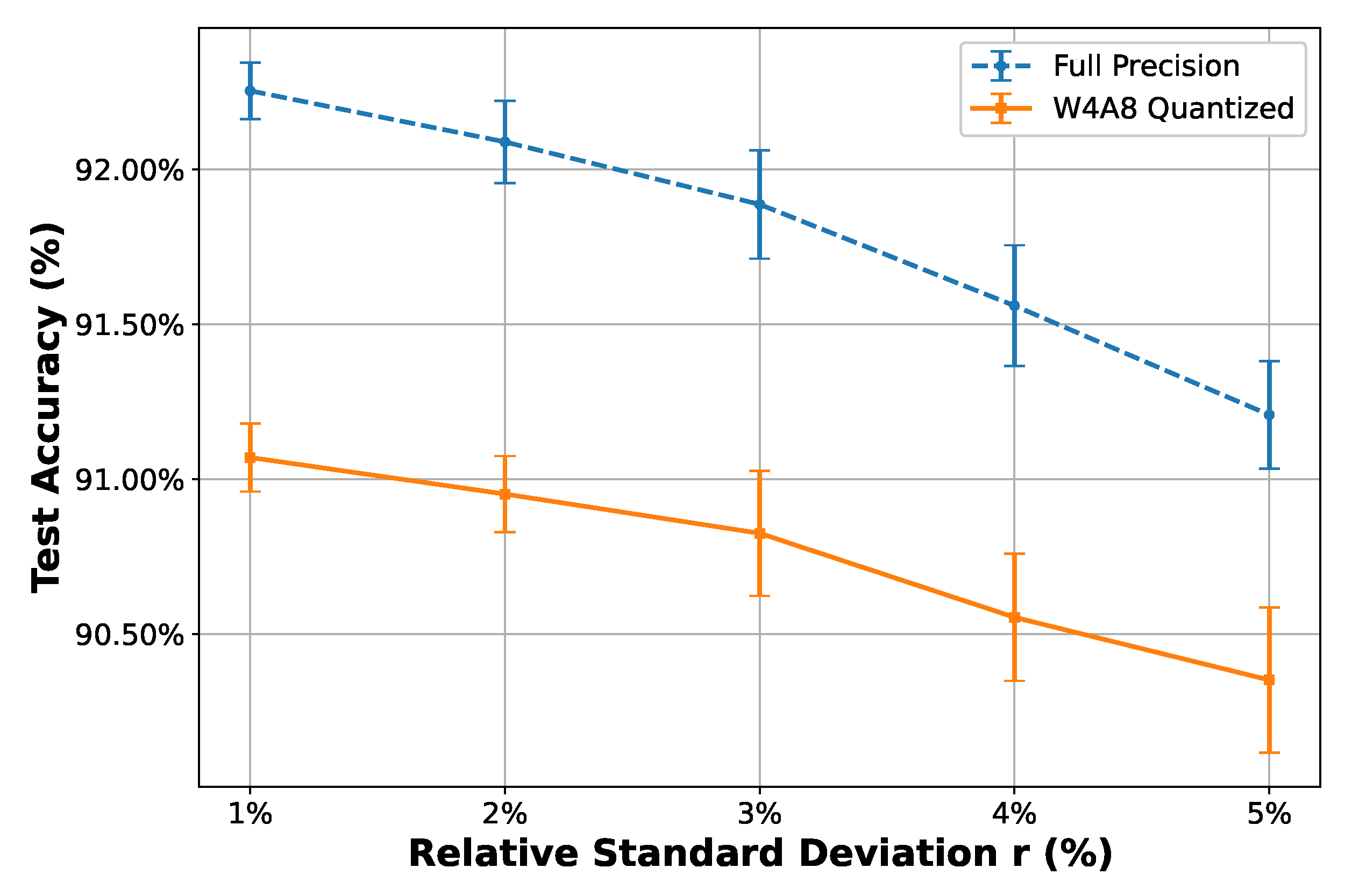
- Noise and impairments robustness analyses of the AFE. The quantized model maintains 91% accuracy at 40 dB SNR and tolerates up to a 5% relative standard deviation from the nominal parameters in filtering operations (due to mismatch and PVT), demonstrating suitable robustness for practical edge-AI systems.
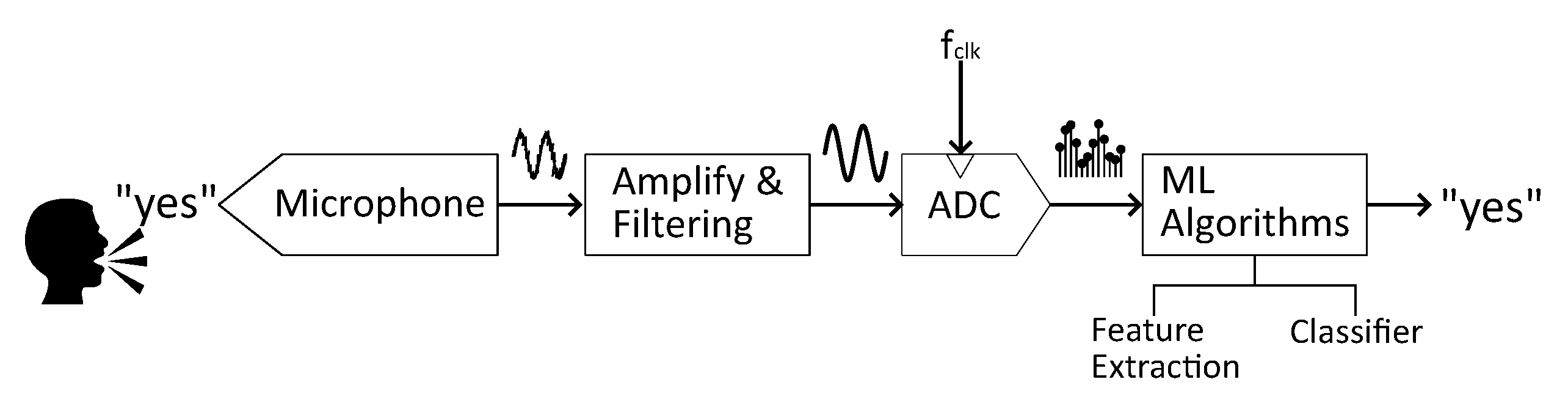
2. Description of the Proposed KWS Architecture
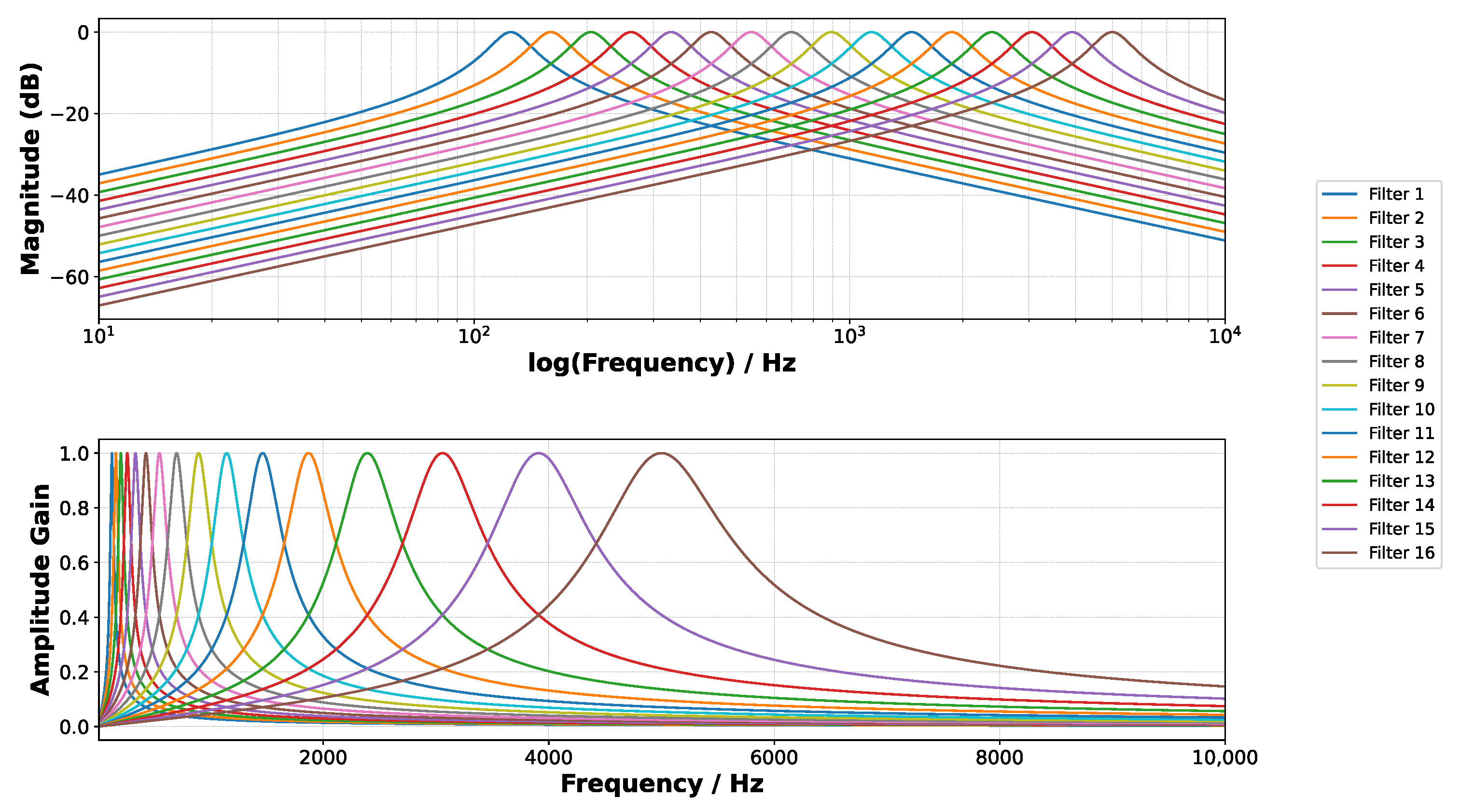
2.1. Behavioral Modeling of the Analog Filter Bank Feature Extractor
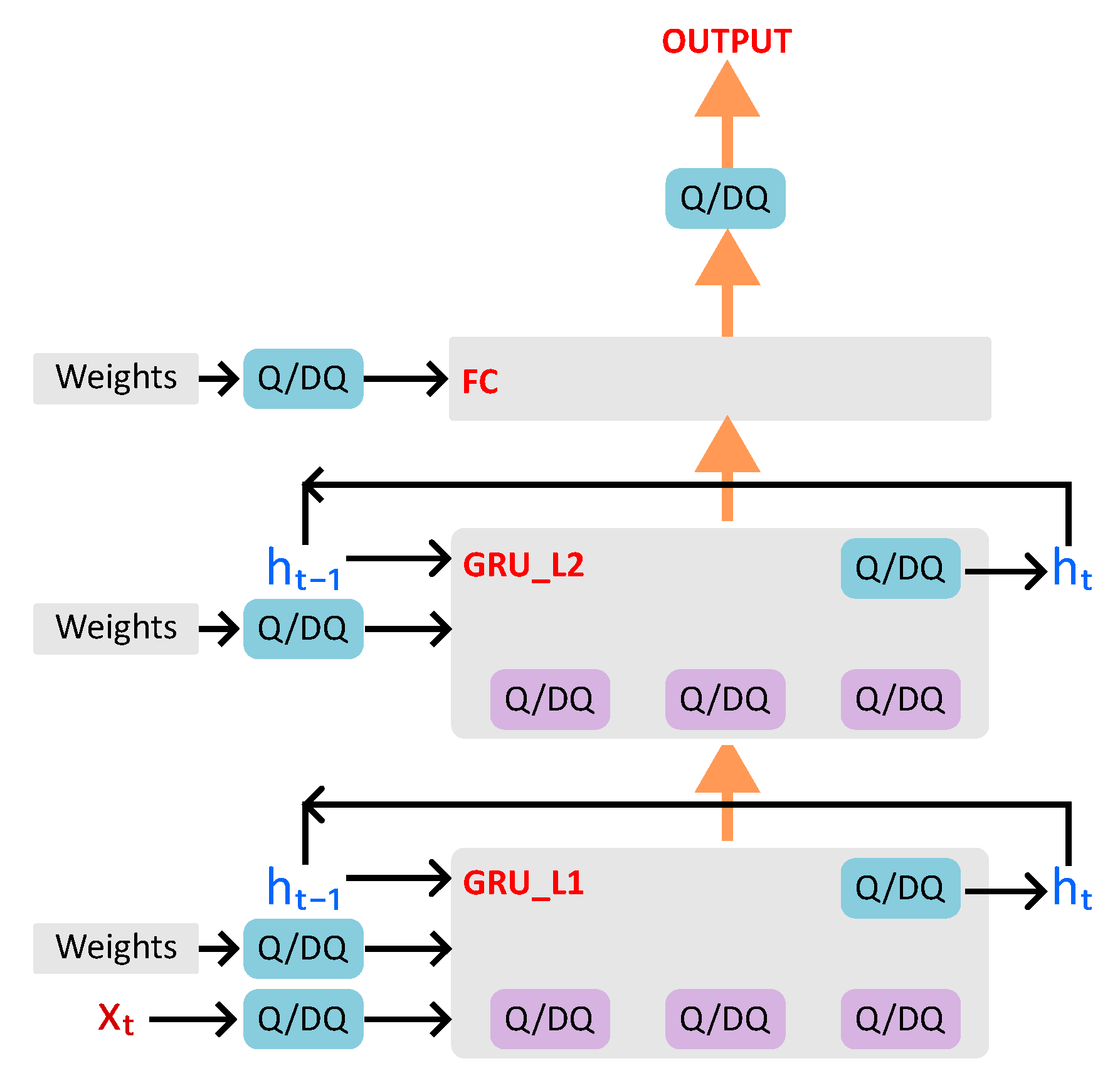
2.2. GRU-Based Classifier
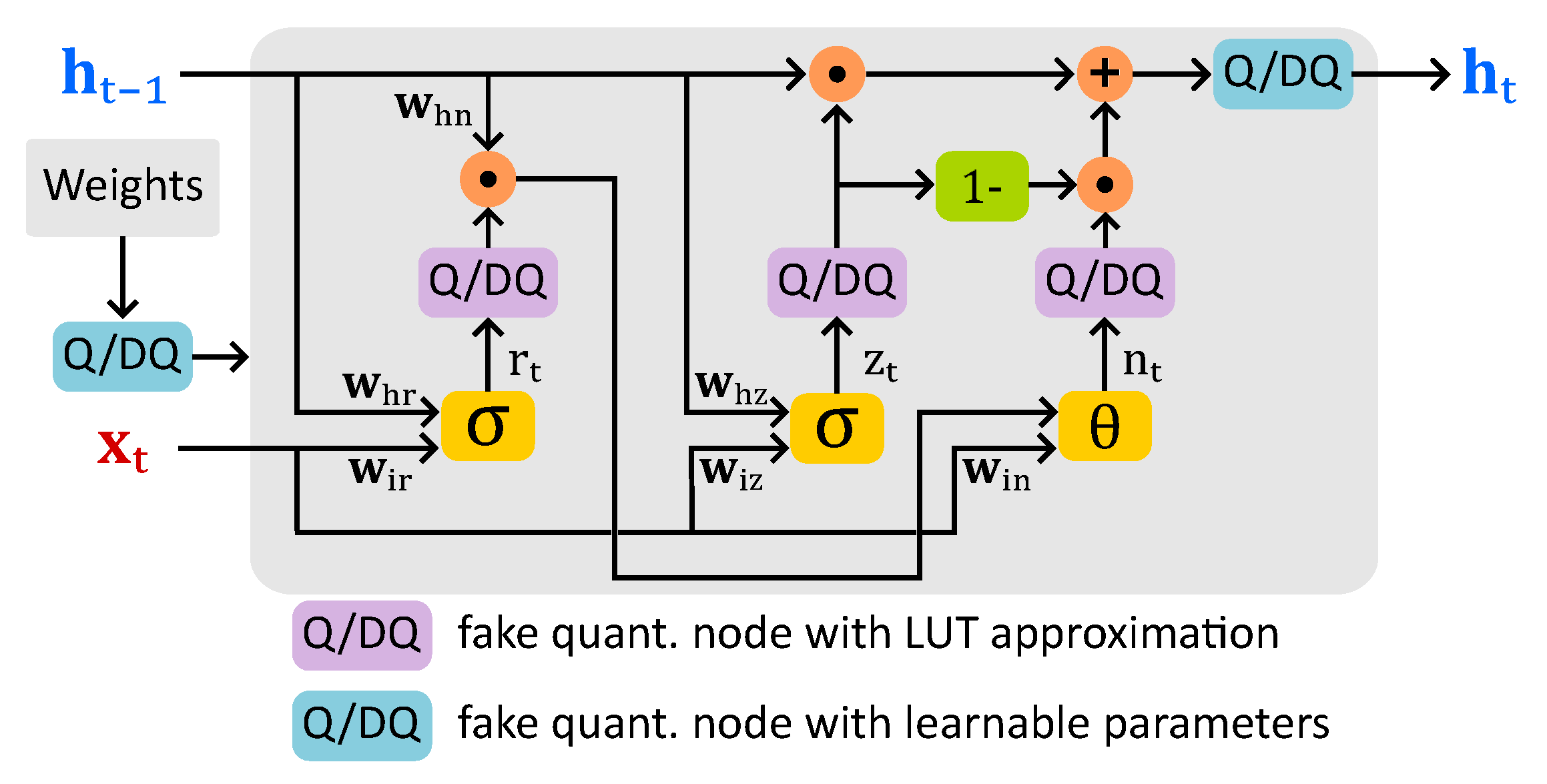
3. Learned Step Size Quantized GRU Classifier
3.1. Background
3.2. Methodology
| Algorithm 1: Quantization for Sigmoid and Tanh with LUT Approximation |
 |
| Algorithm 2: Learned Step Size Quantization (LSQ) with Gradient Scaling |
 |
4. Training, Performance Results and Comparison
4.1. Data Preparation
4.2. Training
- Number of epochs: 20 to 150;
- Batch size: 16 to 256;
- Learning rate: to ;
- Weight decay: to ;
- GRU dropout: 0.0 to 0.5;
- Learning rate scheduler decay factor: 0.1 to 0.9.
| Algorithm 3: Initialization of Activation Quantization Step Size and Zero Point |
 |
| Algorithm 4: Initialization of Weight Quantization Step Size |
 |
4.3. Results and Discussion
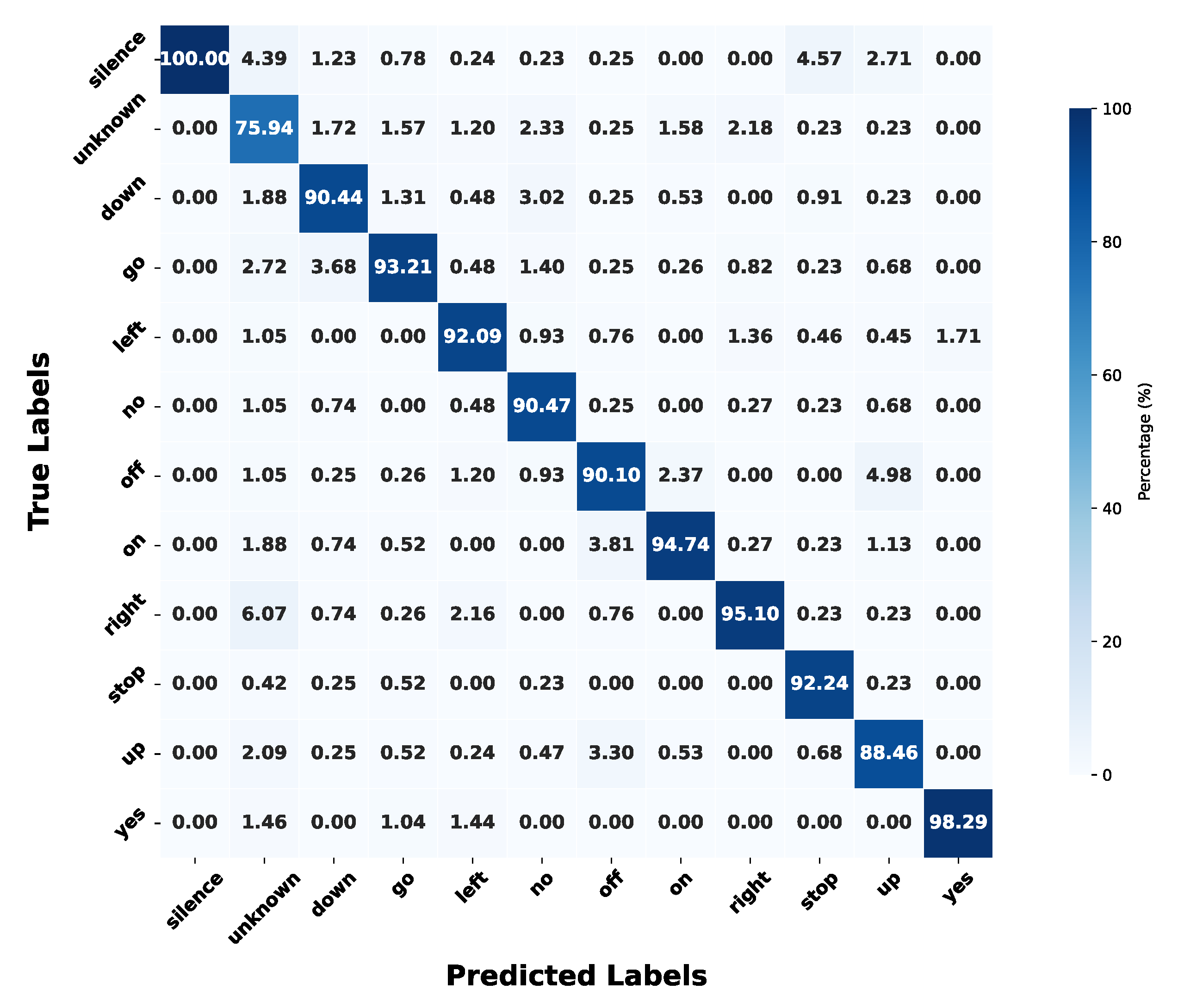
4.3.1. Classification Results
4.3.2. Hardware Resource Estimation
4.3.3. Noise and Analog Impairments Robustness Analyses
- (1)
- Input-referred AFE noise
- (2)
- Filter Parameter Variation (Mismatch and PVT)
- Trend exploration: The relative standard deviation r of the log-normal perturbation model is modified from 0.5% to 20%. For each r, a single random perturbation instance is applied to observe overall classification accuracy trends under increasing levels of mismatch and PVT variations.
- Expanded statistical analysis: Based on the previously concluded trends, five representative values are selected. For each value, 30 Monte Carlo trials are conducted by independently sampling perturbations from the corresponding log-normal distribution. This sampling-based strategy allows the natural emergence of statistical variation patterns, including typical and rare cases, without explicitly constraining the samples to fixed confidence intervals. The resulting accuracy statistics (mean and standard deviation) provide a comprehensive view of system robustness under realistic stochastic parameter shifts.
4.3.4. Comparison and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LSQ | Learned step size |
| GRU | Gated recurrent unit |
| KWS | Keyword spotting |
| GSCDv2 | Google speech command dataset v2 |
| MAC | Multiply-accumulate |
| AI | Artificial intelligence |
| ASR | Automatic speech recognition |
| VAD | Voice activity detection |
| AFE | Analog front-end |
| LUT | Loop-up table |
| FC | fully connected |
| RNN | Recurrent neural network |
| LSTM | Long-short term memory |
| CNN | Convolutional neural network |
| CRNN | Convolutional recurrent neural network |
| DS-CNN | Depth-wise separable convolutional neural network |
| PTQ | Post-training quantization |
| QAT | Quantization-aware training |
| FQN | Fake quantization node |
| STE | Straight-through estimator |
| TPE | Tree-structured parzen estimator |
| TPR | True positive rate |
| FEx | Feature extractor |
| RMS | Root mean square |
| SNR | Signal-to-noise ratio |
| PVT | Process-voltage-temperature |
| SLU | Spoken language understanding |
| FSCD | Fluent speech commands dataset |
References
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yu, C.H.; Kim, H.E.; Shin, S.; Bong, K.; Kim, H.; Boo, Y.; Bae, J.; Kwon, M.; Charfi, K.; Kim, J.; et al. 2.4 ATOMUS: A 5 nm 32TFLOPS/128TOPS ML System-on-Chip for Latency Critical Applications. In Proceedings of the 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 18–22 February 2024; Volume 67, pp. 42–44. [Google Scholar] [CrossRef]
- Yang, M.; Yeh, C.H.; Zhou, Y.; Cerqueira, J.P.; Lazar, A.A.; Seok, M. Design of an Always-On Deep Neural Network-Based 1-μW Voice Activity Detector Aided with a Customized Software Model for Analog Feature Extraction. IEEE J. Solid-State Circuits 2019, 54, 1764–1777. [Google Scholar] [CrossRef]
- Shen, Y.; Straeussnigg, D.; Gutierrez, E. Towards Ultra-Low Power Consumption VAD Architectures with Mixed Signal Circuits. In Proceedings of the 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 21–25 May 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Shan, W.; Yang, M.; Wang, T.; Lu, Y.; Cai, H.; Zhu, L.; Xu, J.; Wu, C.; Shi, L.; Yang, J. A 510-nW Wake-Up Keyword-Spotting Chip Using Serial-FFT-Based MFCC and Binarized Depthwise Separable CNN in 28-nm CMOS. IEEE J. Solid-State Circuits 2021, 56, 151–164. [Google Scholar] [CrossRef]
- Kawada, A.; Kobayashi, K.; Shin, J.; Sumikawa, R.; Hamada, M.; Kosuge, A. A 250.3 μW Versatile Sound Feature Extractor Using 1024-point FFT 64-ch LogMel Filter in 40 nm CMOS. In Proceedings of the 2024 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 3–6 November 2024; pp. 183–187. [Google Scholar] [CrossRef]
- Moini, A. Vision Chips; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- Gutierrez, E.; Perez, C.; Hernandez, F.; Hernandez, L. Time-Encoding-Based Ultra-Low Power Features Extraction Circuit for Speech Recognition Tasks. Electronics 2020, 9, 418. [Google Scholar] [CrossRef]
- Shen, Y.; Perez, C.; Straeussnigg, D.; Gutierrez, E. Time-Encoded Mostly Digital Feature Extraction for Voice Activity Detection Tasks. In Proceedings of the 2024 IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 19–23 May 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Mostafa, A.; Hardy, E.; Badets, F. 17.8 0.4V 988 nW Time-Domain Audio Feature Extraction for Keyword Spotting Using Injection-Locked Oscillators. In Proceedings of the 2024 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 18–22 February 2024; Volume 67, pp. 328–330. [Google Scholar] [CrossRef]
- Croce, M.; Friend, B.; Nesta, F.; Crespi, L.; Malcovati, P.; Baschirotto, A. A 760-nW, 180-nm CMOS Fully Analog Voice Activity Detection System for Domestic Environment. IEEE J. Solid-State Circuits 2021, 56, 778–787. [Google Scholar] [CrossRef]
- Kim, K.; Gao, C.; Graça, R.; Kiselev, I.; Yoo, H.J.; Delbruck, T.; Liu, S.C. A 23-μW Keyword Spotting IC with Ring-Oscillator-Based Time-Domain Feature Extraction. IEEE J. Solid-State Circuits 2022, 57, 3298–3311. [Google Scholar] [CrossRef]
- Narayanan, S.; Cartiglia, M.; Rubino, A.; Lego, C.; Frenkel, C.; Indiveri, G. SPAIC: A sub-μW/Channel, 16-Channel General-Purpose Event-Based Analog Front-End with Dual-Mode Encoders. In Proceedings of the 2023 IEEE Biomedical Circuits and Systems Conference (BioCAS), Toronto, ON, Canada, 19–21 October 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, Q.; Kim, K.; Gao, C.; Zhou, S.; Jang, T.; Delbruck, T.; Liu, S.C. DeltaKWS: A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM. IEEE Trans. Circuits Syst. Artif. Intell. 2024, 2, 79–87. [Google Scholar] [CrossRef]
- Yang, H.; Seol, J.H.; Rothe, R.; Fan, Z.; Zhang, Q.; Kim, H.S.; Blaauw, D.; Sylvester, D. A 1.5-μW Fully-Integrated Keyword Spotting SoC in 28-nm CMOS with Skip-RNN and Fast-Settling Analog Frontend for Adaptive Frame Skipping. IEEE J. Solid-State Circuits 2023, 59, 29–39. [Google Scholar] [CrossRef]
- Zhang, Y.; Suda, N.; Lai, L.; Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. arXiv 2018, arXiv:1711.07128. [Google Scholar] [CrossRef]
- Bartels, J.; Hagihara, A.; Minati, L.; Tokgoz, K.K.; Ito, H. An Integer-Only Resource-Minimized RNN on FPGA for Low-Frequency Sensors in Edge-AI. IEEE Sens. J. 2023, 23, 17784–17793. [Google Scholar] [CrossRef]
- Campos, V.; Jou, B.; Giró-i-Nieto, X.; Torres, J.; Chang, S.F. Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks. arXiv 2018, arXiv:1708.06834. [Google Scholar] [CrossRef]
- Gao, C.; Neil, D.; Ceolini, E.; Liu, S.C.; Delbruck, T. DeltaRNN: A Power-efficient Recurrent Neural Network Accelerator. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, FPGA’18, New York, NY, USA, 25–27 February 2018; pp. 21–30. [Google Scholar] [CrossRef]
- Kusupati, A.; Singh, M.; Bhatia, K.; Kumar, A.; Jain, P.; Varma, M. FastGRNN: A Fast, Accurate, Stable and Tiny Kilobyte Sized Gated Recurrent Neural Network. arXiv 2019, arXiv:1901.02358. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv 2024, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model Compression and Hardware Acceleration for Neural Networks: A Comprehensive Survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. arXiv 2017, arXiv:1712.05877. [Google Scholar] [CrossRef]
- Bartels, J.; Tokgoz, K.K.; A, S.; Fukawa, M.; Otsubo, S.; Li, C.; Rachi, I.; Takeda, K.I.; Minati, L.; Ito, H. TinyCowNet: Memory- and Power-Minimized RNNs Implementable on Tiny Edge Devices for Lifelong Cow Behavior Distribution Estimation. IEEE Access 2022, 10, 32706–32727. [Google Scholar] [CrossRef]
- Sari, E.; Courville, V.; Nia, V.P. iRNN: Integer-only Recurrent Neural Network. arXiv 2022, arXiv:2109.09828. [Google Scholar] [CrossRef]
- Esser, S.K.; McKinstry, J.L.; Bablani, D.; Appuswamy, R.; Modha, D.S. Learned Step Size Quantization. arXiv 2020, arXiv:1902.08153. [Google Scholar] [CrossRef]
- Bhalgat, Y.; Lee, J.; Nagel, M.; Blankevoort, T.; Kwak, N. LSQ+: Improving low-bit quantization through learnable offsets and better initialization. arXiv 2020, arXiv:2004.09576. [Google Scholar] [CrossRef]
- PyTorch. GRU—PyTorch 2.6.0 Documentation. Available online: https://pytorch.org/docs/stable/generated/torch.nn.GRU.html (accessed on 12 February 2025).
- Bengio, Y.; Léonard, N.; Courville, A. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation. arXiv 2013, arXiv:1308.3432. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar] [CrossRef]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar] [CrossRef]
- Rybakov, O.; Kononenko, N.; Subrahmanya, N.; Visontai, M.; Laurenzo, S. Streaming Keyword Spotting on Mobile Devices. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; ISCA: Winona, MN, USA, 2020. [Google Scholar] [CrossRef]
- Villamizar, D.A.; Muratore, D.G.; Wieser, J.B.; Murmann, B. An 800 nW Switched-Capacitor Feature Extraction Filterbank for Sound Classification. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1578–1588. [Google Scholar] [CrossRef]
- Croon, J.A.; Sansen, W.; Maes, H.E. Matching Properties of Deep Sub-Micron MOS Transistors, 1st ed.; The Springer International Series in Engineering and Computer Science; Springer: New York, NY, USA, 2005; pp. XII, 206. [Google Scholar] [CrossRef]
- Zhou, S.; Li, Z.; Delbruck, T.; Kim, K.; Liu, S.C. An 8.62μW 75dB-DRSoC End-to-End Spoken-Language-Understanding SoC with Channel-Level AGC and Temporal-Sparsity-Aware Streaming-Mode RNN. In Proceedings of the 2025 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 16–20 February 2025; Volume 68, pp. 238–240. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Villamizar TCASI’21 [35] | Kim JSSC’22 [12] | Yang JSSC’23 [15] | Mostafa ISSCC’24 [10] | Chen TCASAI’24 [14] | Zhou ISSCC’25 [37] 5 | This Work | |
|---|---|---|---|---|---|---|---|
| Feature Ex. | Analog | Analog | Digital | Analog | Digital | Analog | Analog 1 |
| # Channels | 32 | 16 | 26 | 16 | 10 | 16 | 16 |
| Classifier | Li-GRU 2 | GRU | Skip RNN | GRU 2 | Delta GRU | Delta GRU | GRU 3 |
| # RNN layers | - | 2 | 1 | 2 | 1 | 2 | 2 |
| Units / layer | - | 48 | 64 | 128 | 64 | 64 | 80 |
| NN Quant. | - | 8b w 14b acti. | 8b w 12b acti. | - | 8b w - acti. | 8b w 8b acti. | 4b w 8b acti. |
| NN Memory (kB) | - | 24 | 18 | - | 24 | 48 | 34.8 4 |
| Dataset | GSCDv2 | GSCDv2 | GSCDv1 | GSCDv2 | GSCDv2 | FSCD | GSCDv2 |
| # Classes (# KWs) | 12 (10) | 12 (10) | 7 (5) | 10 (10) | 12 (10) | 32 (-) | 12 (10) |
| Accuracy (%) | 92.10% | 86.03% | 92.80% | 91.00% | 89.50% | 92.9% | 91.35% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, Y.; Wu, B.; Straeussnigg, D.; Gutierrez, E. A KWS System for Edge-Computing Applications with Analog-Based Feature Extraction and Learned Step Size Quantized Classifier. Sensors 2025, 25, 2550. https://doi.org/10.3390/s25082550
Shen Y, Wu B, Straeussnigg D, Gutierrez E. A KWS System for Edge-Computing Applications with Analog-Based Feature Extraction and Learned Step Size Quantized Classifier. Sensors. 2025; 25(8):2550. https://doi.org/10.3390/s25082550
Chicago/Turabian StyleShen, Yukai, Binyi Wu, Dietmar Straeussnigg, and Eric Gutierrez. 2025. "A KWS System for Edge-Computing Applications with Analog-Based Feature Extraction and Learned Step Size Quantized Classifier" Sensors 25, no. 8: 2550. https://doi.org/10.3390/s25082550
APA StyleShen, Y., Wu, B., Straeussnigg, D., & Gutierrez, E. (2025). A KWS System for Edge-Computing Applications with Analog-Based Feature Extraction and Learned Step Size Quantized Classifier. Sensors, 25(8), 2550. https://doi.org/10.3390/s25082550