
YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery
Abstract
1. Introduction
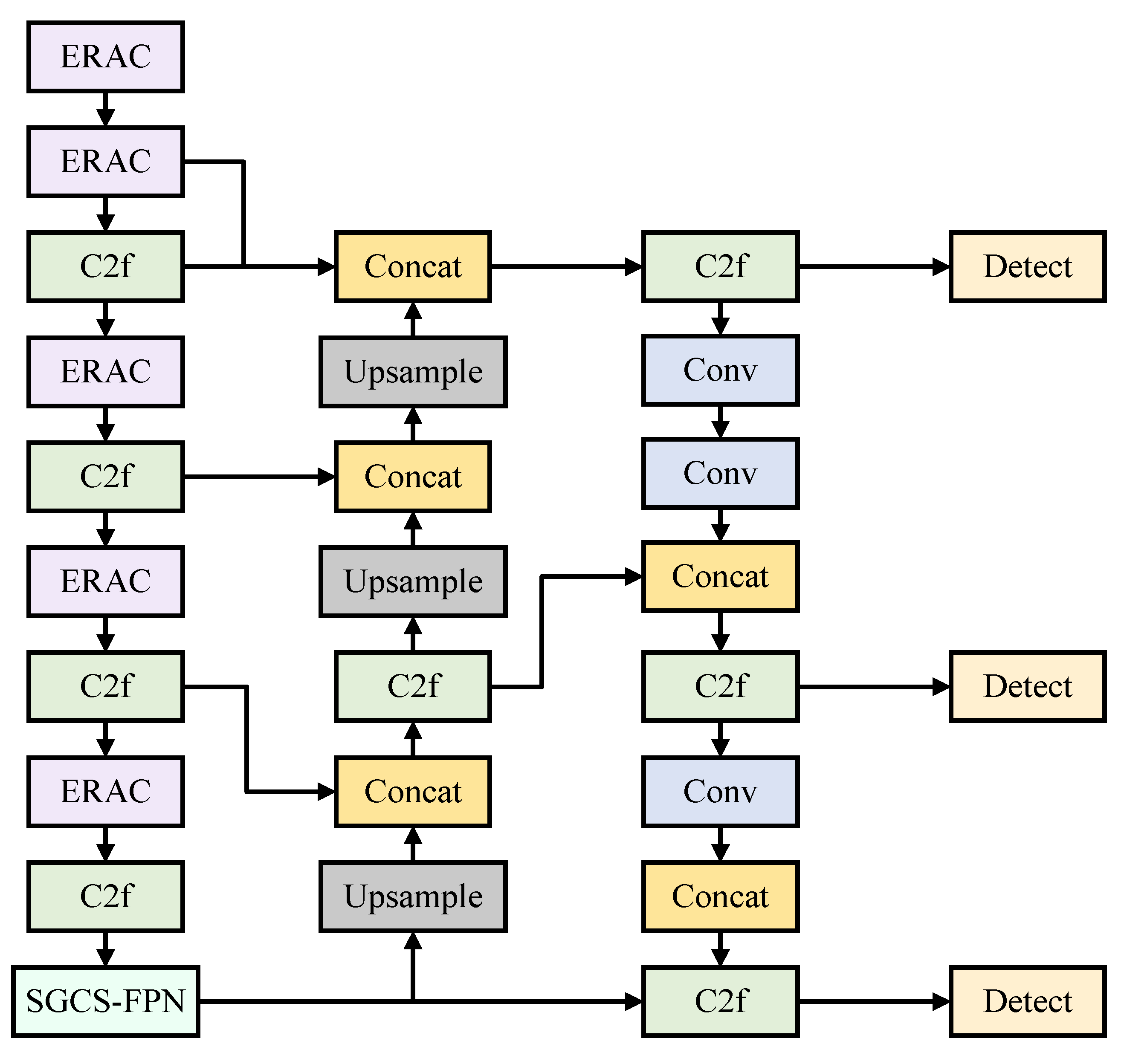
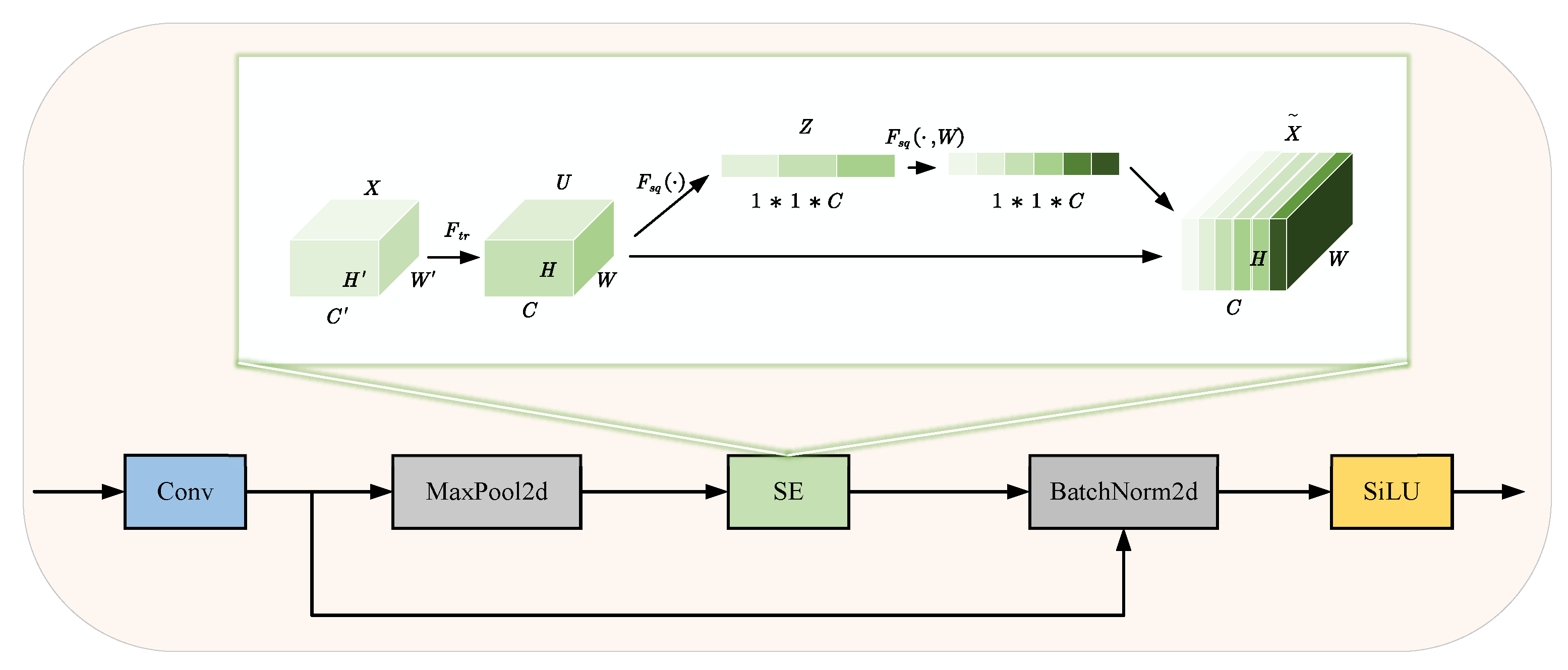
- Enhanced Residual Attention Convolution Module (ERAC): Compared to the traditional Conv module, the ERAC module enhances the ability to capture small target features by expanding the receptive field and introducing an attention mechanism. Additionally, the residual connection structure effectively mitigates the gradient vanishing problem, ensuring the stability of model training.
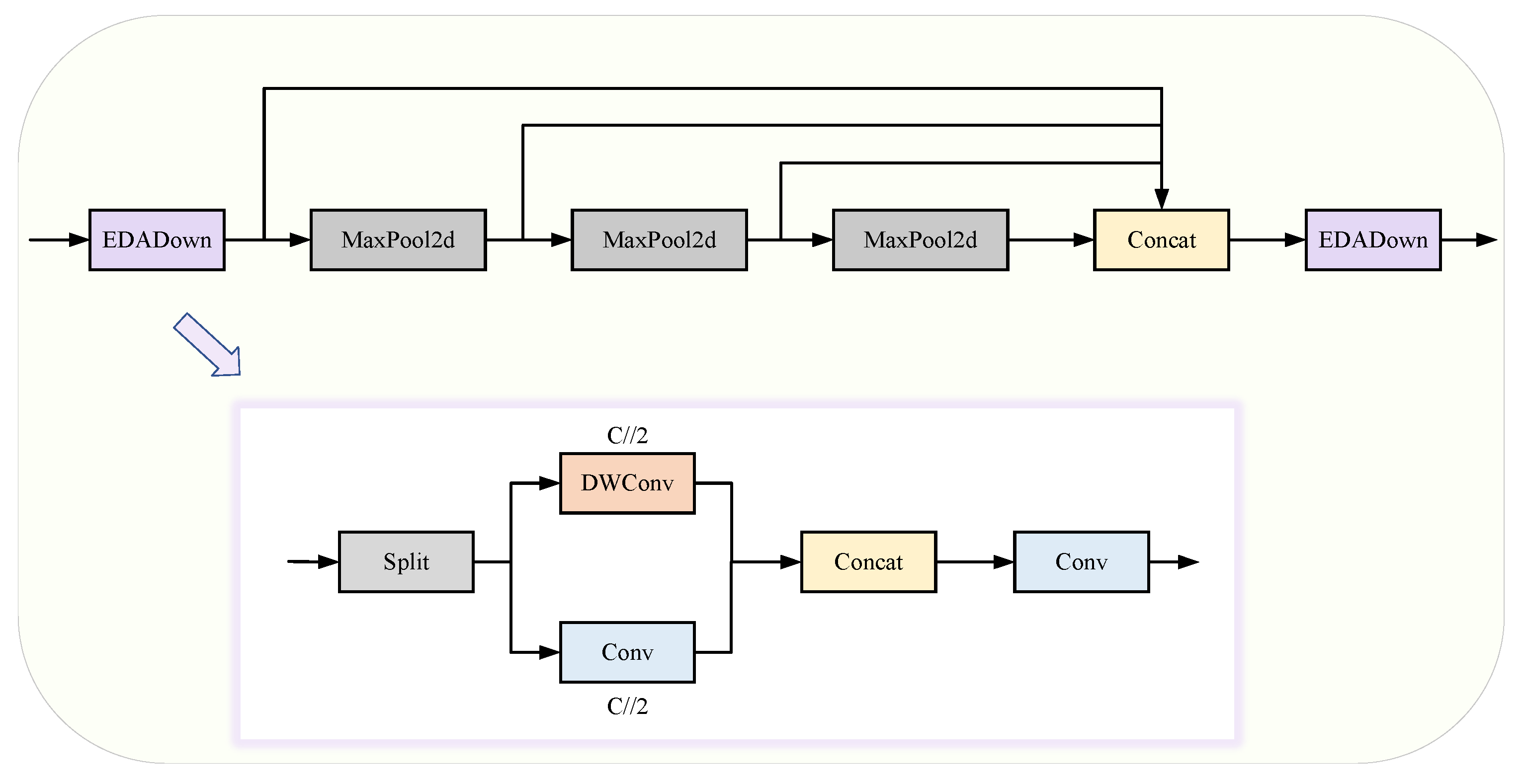
- Parallel Depth-Aware Spatial Pyramid Pooling Module (PD-ASPP): Compared to the SPPF module, PD-ASPP employs a multi-branch parallel mechanism combined with depthwise separable convolution, reducing computational redundancy and enhancing the feature representation capability for multi-scale targets.
- Shallow Guided Cross-Scale Feature Pyramid Network (SGCS-FPN): Addressing the shortcomings of existing feature pyramid networks that often lose small target information in deep networks, SGCS-FPN introduces shallow feature guidance branches to establish cross-scale semantic associations, significantly improving the detection performance for small targets.
- Adjustable Weighted Intersection Over Union (WIoU): Compared to the traditional CIoU loss function, WIoU enhances the target localization regression mechanism by dynamically adjusting the positioning loss weight strategy. This improvement boosts the recognition accuracy and coordinate localization precision of the model in complex drone scenarios.
2. Related Works
3. Method
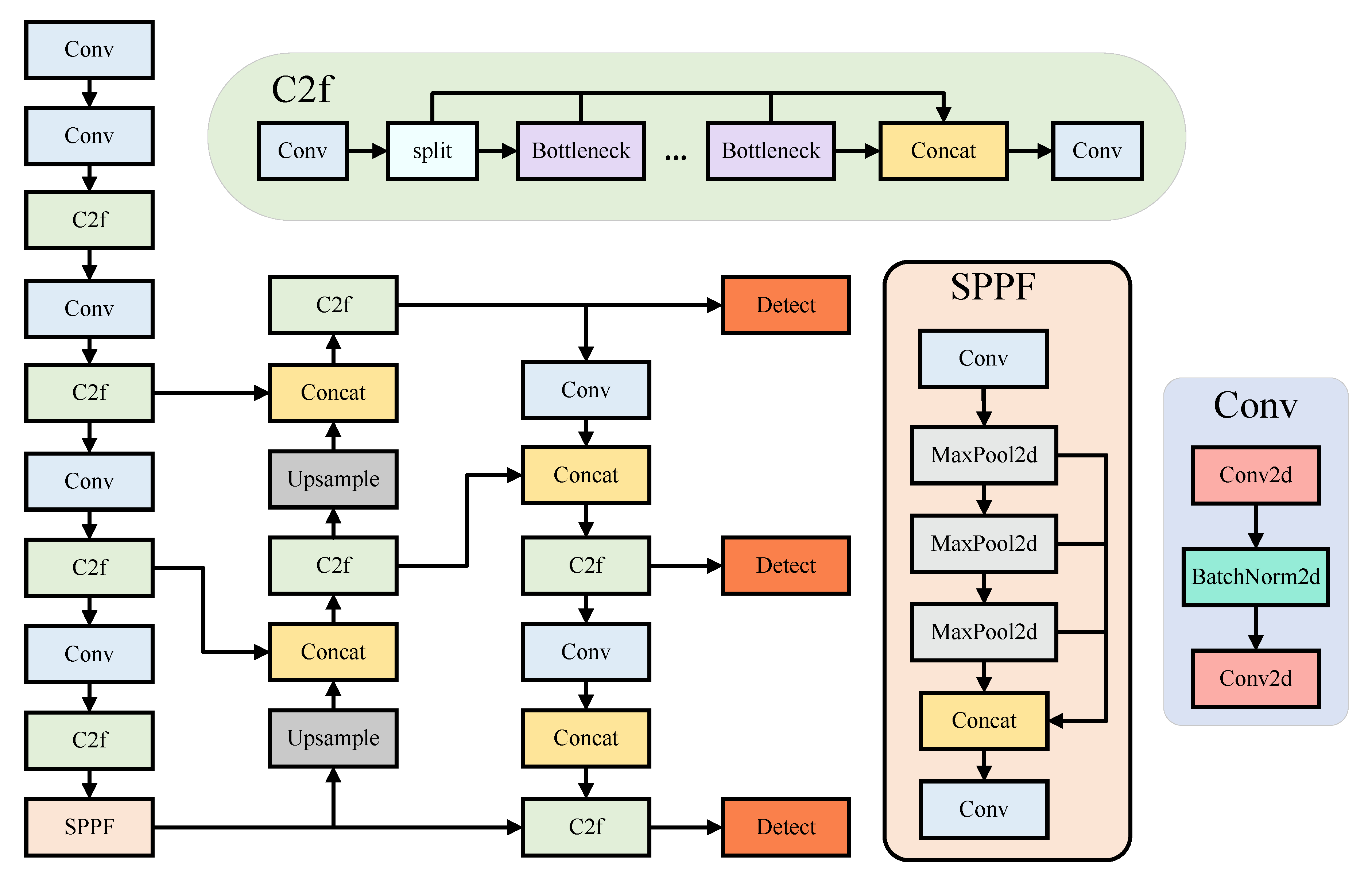
3.1. YOLO-MARS
3.1.1. ERAC Module
3.1.2. PD-ASPP Module
3.1.3. SGCS-FPN
3.1.4. WIoU
4. Experiments and Analysis
4.1. Dataset
4.2. Experimental Environment and Training Parameters
4.3. Evaluation Metrics
4.4. Ablation Experiments
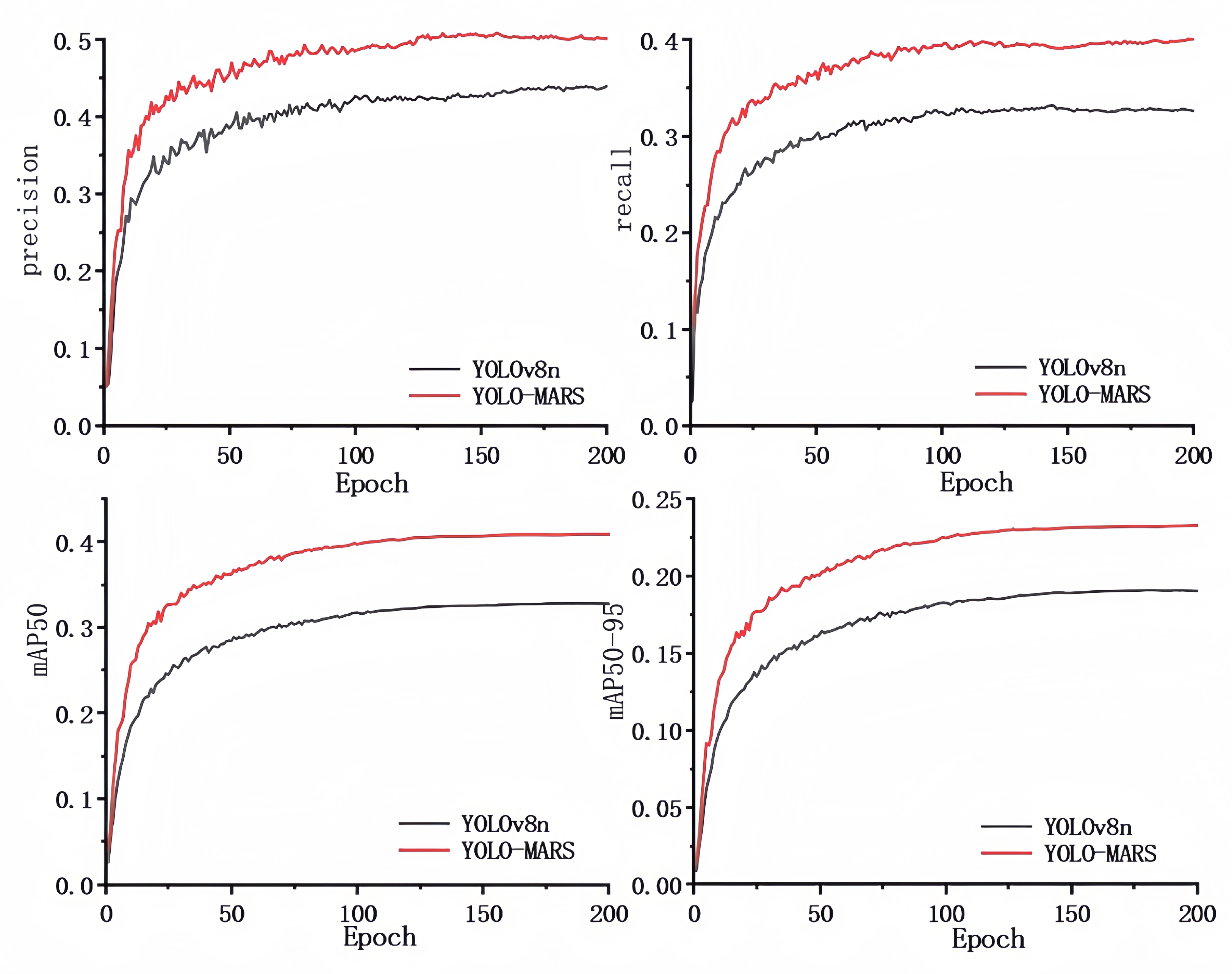
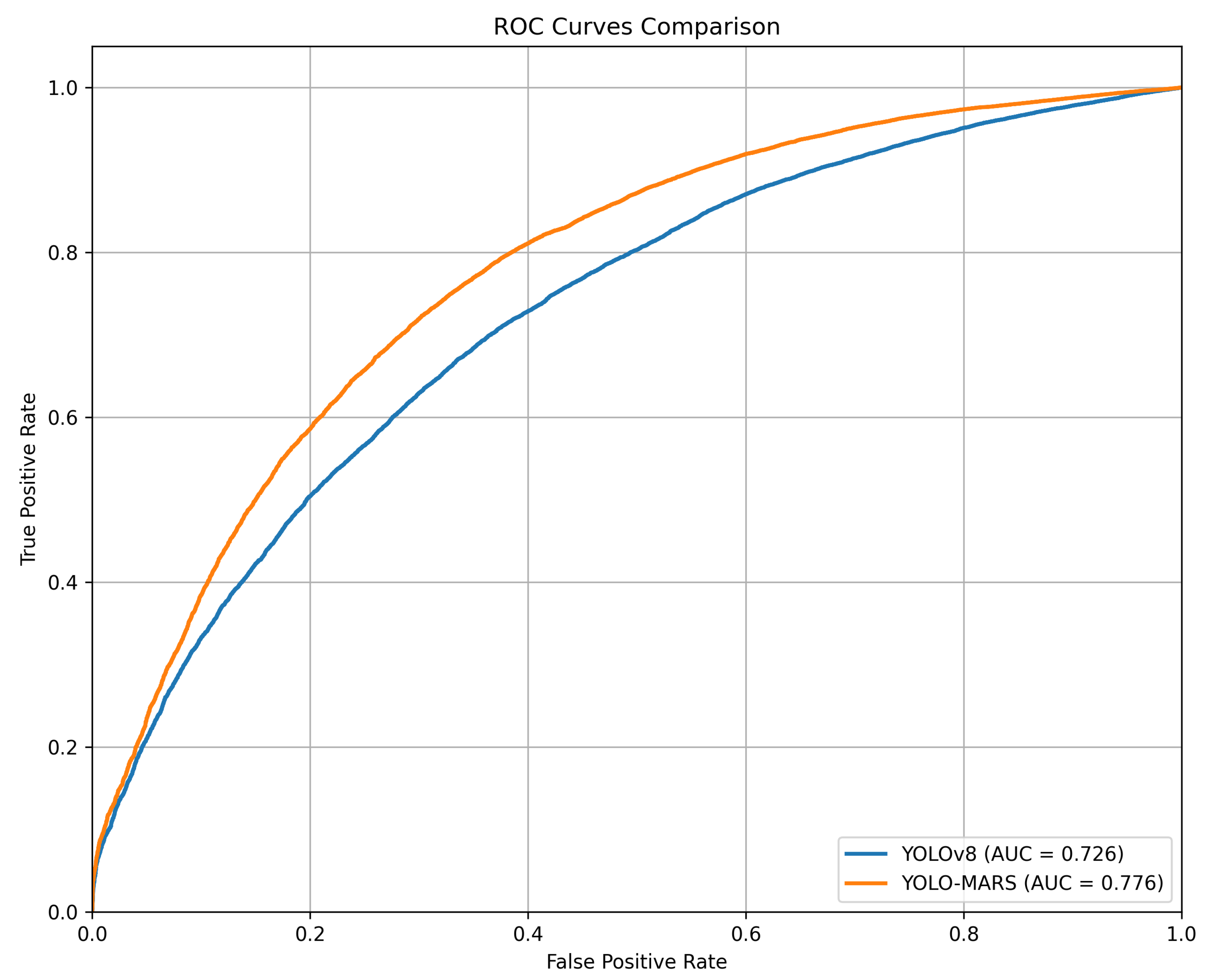
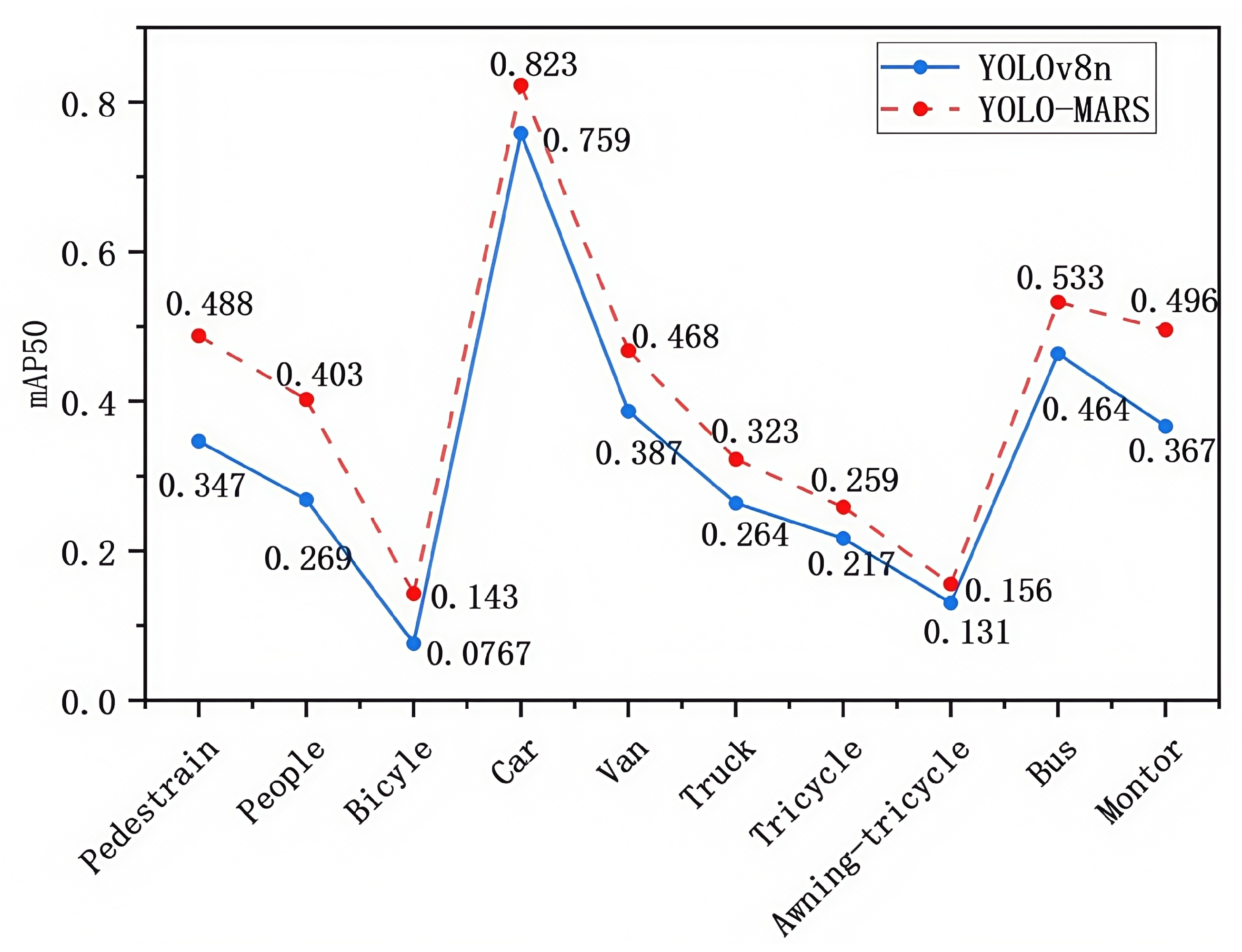
4.5. Experimental Results Analysis
4.6. Comparative Experiments
4.7. Visualization Results Analysis
4.8. Extended Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.I.; Dou, Z.; Almaita, E.K.; Khalil, I.M.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned Aerial Vehicles (UAVs): A Survey on Civil Applications and Key Research Challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- Cai, W.; Wei, Z. Remote Sensing Image Classification Based on a Cross-Attention Mechanism and Graph Convolution. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8002005. [Google Scholar] [CrossRef]
- Zhao, Z.-A.; Wang, S.; Chen, M.-X.; Mao, Y.-J.; Chan, A.C.-H.; Lai, D.K.-H.; Wong, D.W.-C.; Cheung, J.C.-W. Enhancing Human Detection in Occlusion-Heavy Disaster Scenarios: A Visibility-Enhanced DINO (VE-DINO) Model with Reassembled Occlusion Dataset. Smart Cities 2025, 8, 12. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector With Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1758–1770. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12592–12601. [Google Scholar] [CrossRef]
- Fang, Q.F.; Han, D.; Wang, Z. Cross-Modality Fusion Transformer for Multispectral Object Detection. arXiv 2021, arXiv:2111.00273. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, R.; Zheng, B.; Wang, H.; Fu, Y. Infrared Small Target Detection with Scale and Location Sensitivity. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 17490–17499. [Google Scholar] [CrossRef]
- Yang, F.; Fan, H.; Chu, P.; Blasch, E.; Ling, H. Clustered Object Detection in Aerial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8310–8319. [Google Scholar] [CrossRef]
- Du, B.; Huang, Y.; Chen, J.; Huang, D. Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13435–13444. [Google Scholar] [CrossRef]
- Yang, Y.; Zang, B.; Song, C.; Li, B.; Lang, Y.; Zhang, W.; Huo, P. Small Object Detection in Remote Sensing Images Based on Redundant Feature Removal and Progressive Regression. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5629314. [Google Scholar] [CrossRef]
- Ma, W.; Wang, X.; Zhu, H.; Yang, X.; Yi, X.; Jiao, L. Significant Feature Elimination and Sample Assessment for Remote Sensing Small Objects’ Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5615115. [Google Scholar] [CrossRef]
- Tian, G.; Liu, J.; Yang, W. A Dual Neural Network for Object Detection in UAV Images. Neurocomputing 2021, 443, 292–301. [Google Scholar] [CrossRef]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.-H. Single Image Dehazing via Multi-Scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2020, 128, 240–259. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-Purpose Oriented Single Nighttime Image Haze Removal Based on Unified Variational Retinex Model. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1643–1657. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyond Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar] [CrossRef]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar] [CrossRef]
- Zhu, P.F.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 213–226. [Google Scholar] [CrossRef]
- Fan, Q.; Li, Y.; Deveci, M.; Zhong, K.; Kadry, S. LUD-YOLO: A Novel Lightweight Object Detection Network for Unmanned Aerial Vehicle. Inf. Sci. 2025, 686, 121366. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W. RFAG-YOLO: A Receptive Field Attention-Guided YOLO Network for Small-Object Detection in UAV Images. Sensors 2025, 25, 2193. [Google Scholar] [CrossRef] [PubMed]
- Suo, J.; Wang, T.; Zhang, X.; Chen, H.; Zhou, W.; Shi, W. HIT-UAV: A High-Altitude Infrared Thermal Dataset for Unmanned Aerial Vehicle-Based Object Detection. Sci. Data 2023, 10, 227. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Configuration |
|---|---|
| Operating systems | Linux |
| CPU | AMD EPYC 9754 (Amd, CA, USA) |
| GPU | NVIDIA RTX 3090 (Nvidia, CA, USA) |
| Deep learning architecture | Pytorch 1.10.0 + Cuda 11.2 |
| Parameters | Setup |
|---|---|
| Image size | 640 × 640 |
| Epochs | 200 |
| Learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.0005 |
| Batch size | 16 |
| Model | Params (M) | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|
| A | 3.01 | 43.6 | 32.9 | 32.8 | 19.1 |
| B | 3.02 | 46.3 | 34.2 | 34.5 | 20.0 |
| C | 2.89 | 46.6 | 35.9 | 35.4 | 20.2 |
| D | 2.93 | 49.6 | 39.8 | 40.8 | 23.5 |
| E | 2.93 | 50.2 | 40.0 | 40.9 | 23.4 |
| Model | Params (M) | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|
| SSD | 24.4 | 21.0 | 35.5 | 23.9 | 10.2 |
| Faster-RCNN | 41.2 | 45.5 | 33.8 | 33.2 | 17.0 |
| QueryDet | 18.9 | 41.4 | 33.4 | 31.6 | 17.4 |
| YOLOv5s | 7.2 | 44.8 | 34.1 | 33.3 | 33.2 |
| YOLOv7-tiny | 6.02 | 47.5 | 36.2 | 35.3 | 19.6 |
| YOLOv8n | 3.01 | 43.6 | 32.9 | 32.8 | 19.1 |
| YOLOv8s | 11.12 | 50.4 | 37.1 | 39.1 | 23.6 |
| YOLOv11n | 2.58 | 43.3 | 32.3 | 32.1 | 18.7 |
| LUDY-N [30] | 2.81 | 47.0 | 34.7 | 35.2 | - |
| RFAG-YOLO [31] | 5.94 | 49.6 | 37.8 | 38.9 | 23.1 |
| YOLO-MARS | 2.93 | 50.2 | 40.0 | 40.9 | 23.4 |
| Model | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|
| SSD | 75.1 | 67.8 | 72.1 | 41.89 |
| Faster-RCNN | 73.7 | 67.5 | 70.2 | 40.2 |
| YOLOv5n | 83.4 | 72.1 | 78.5 | 51.5 |
| YOLOv6n | 85.6 | 71.6 | 78.8 | 51.3 |
| YOLOv8n | 83.0 | 73.7 | 80.3 | 53.0 |
| YOLO-MARS | 90.7 | 78.8 | 85.2 | 55.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Peng, Y.; Li, J. YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery. Sensors 2025, 25, 2534. https://doi.org/10.3390/s25082534
Zhang G, Peng Y, Li J. YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery. Sensors. 2025; 25(8):2534. https://doi.org/10.3390/s25082534
Chicago/Turabian StyleZhang, Guofeng, Yanfei Peng, and Jincheng Li. 2025. "YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery" Sensors 25, no. 8: 2534. https://doi.org/10.3390/s25082534
APA StyleZhang, G., Peng, Y., & Li, J. (2025). YOLO-MARS: An Enhanced YOLOv8n for Small Object Detection in UAV Aerial Imagery. Sensors, 25(8), 2534. https://doi.org/10.3390/s25082534