
A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic Segmentation of Point Clouds


Abstract
1. Introduction
2. Related Work
2.1. Camera-Based Methods
2.2. LiDAR-Based Methods
2.3. Multi-Sensor Fusion-Based Methods
3. Network Principle and Design
3.1. Dimensional Unification Based on Perspective Projection
3.2. CMF Network Structure
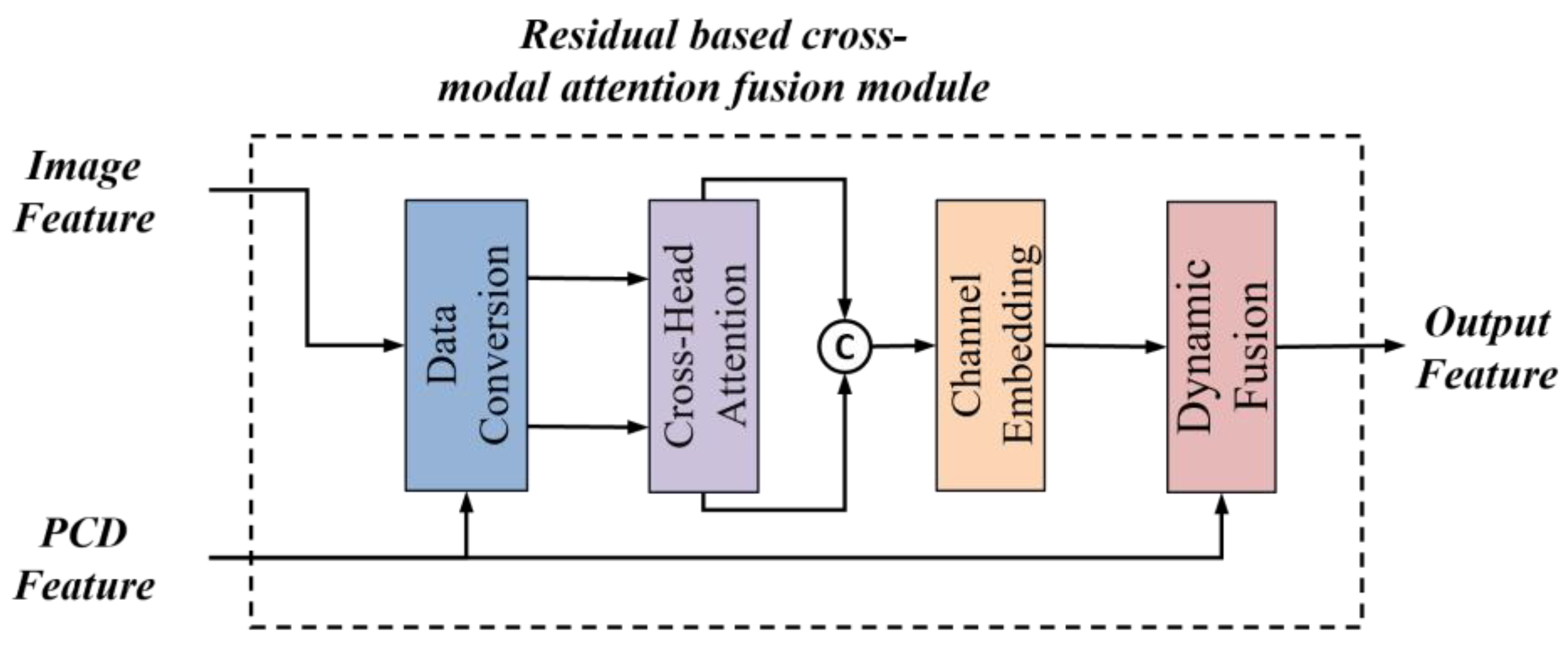
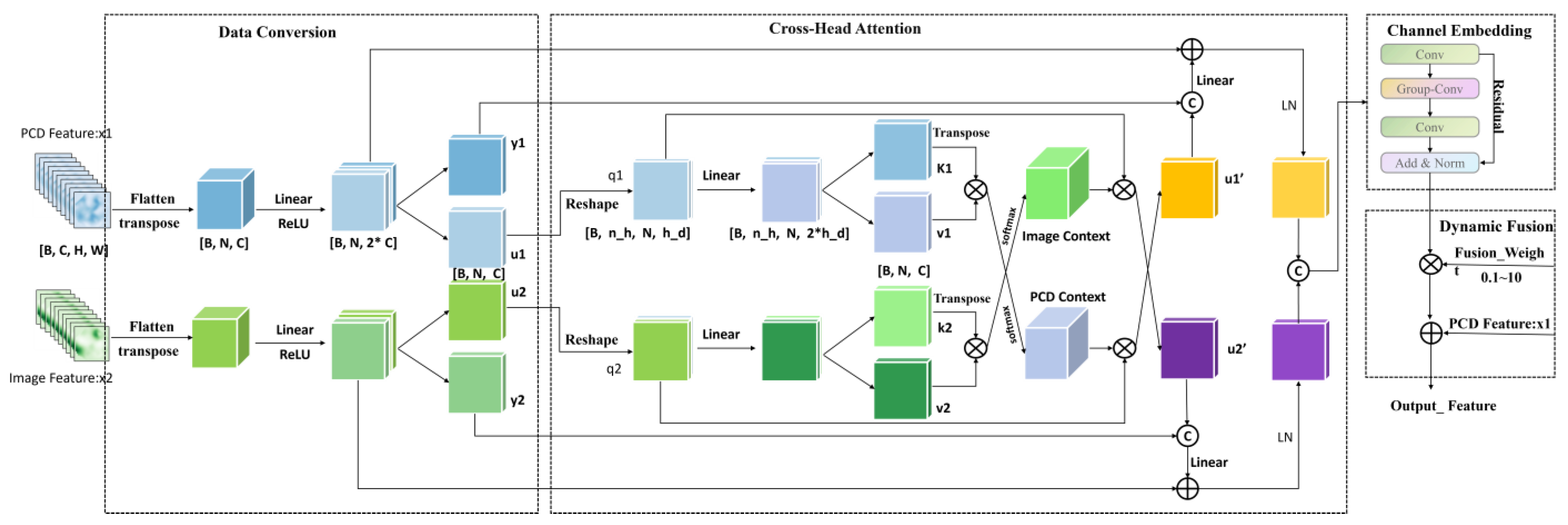
3.3. Residual Fusion Module Based on Cross-Modal Attention
3.4. Perceptual Guided Cross-Entropy Loss Function
4. Experimental Results Processing and Analysis
4.1. Implementation Details
4.2. Comparisons of Benchmark Datasets
4.2.1. Results Based on SemanticKITTI
4.2.2. Results Based on nuScenes
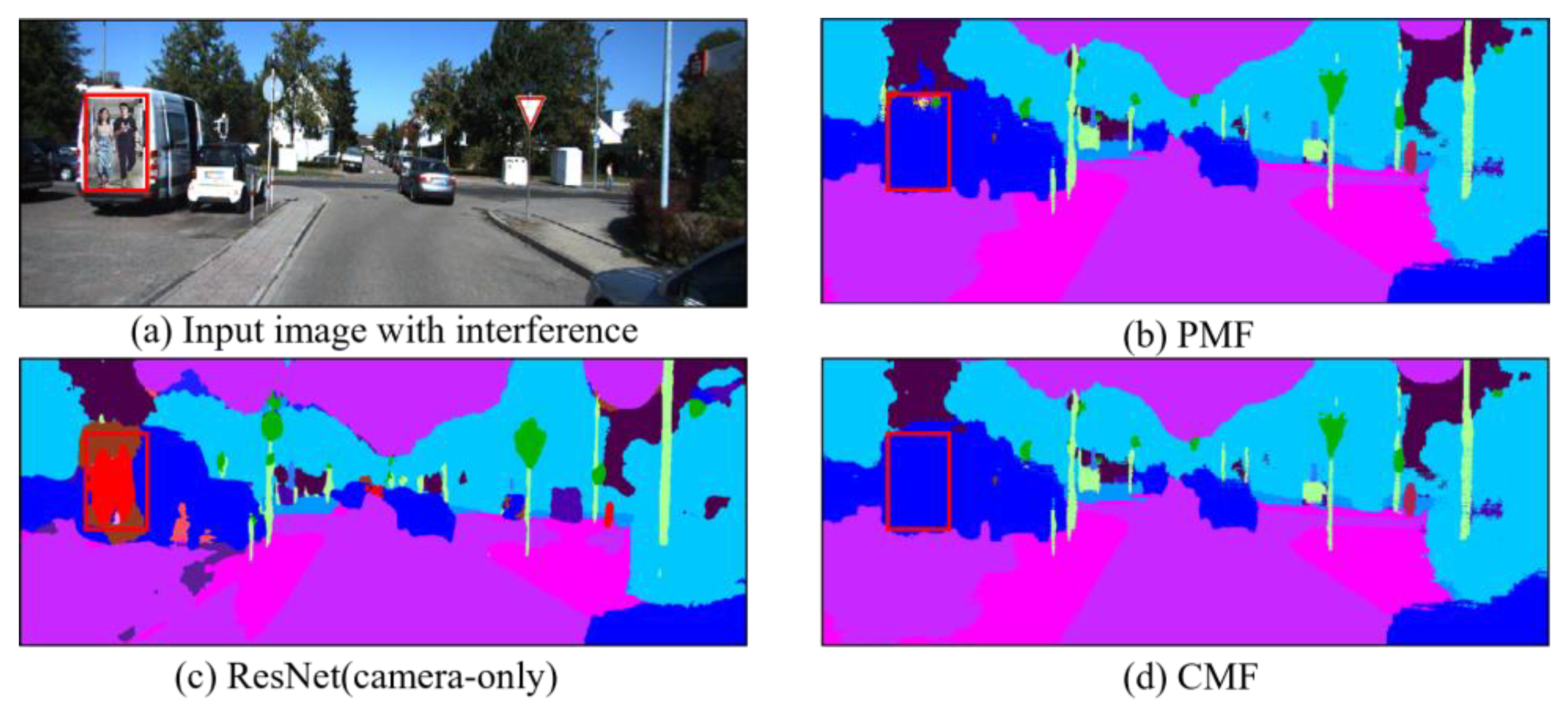
4.3. Qualitative Evaluation
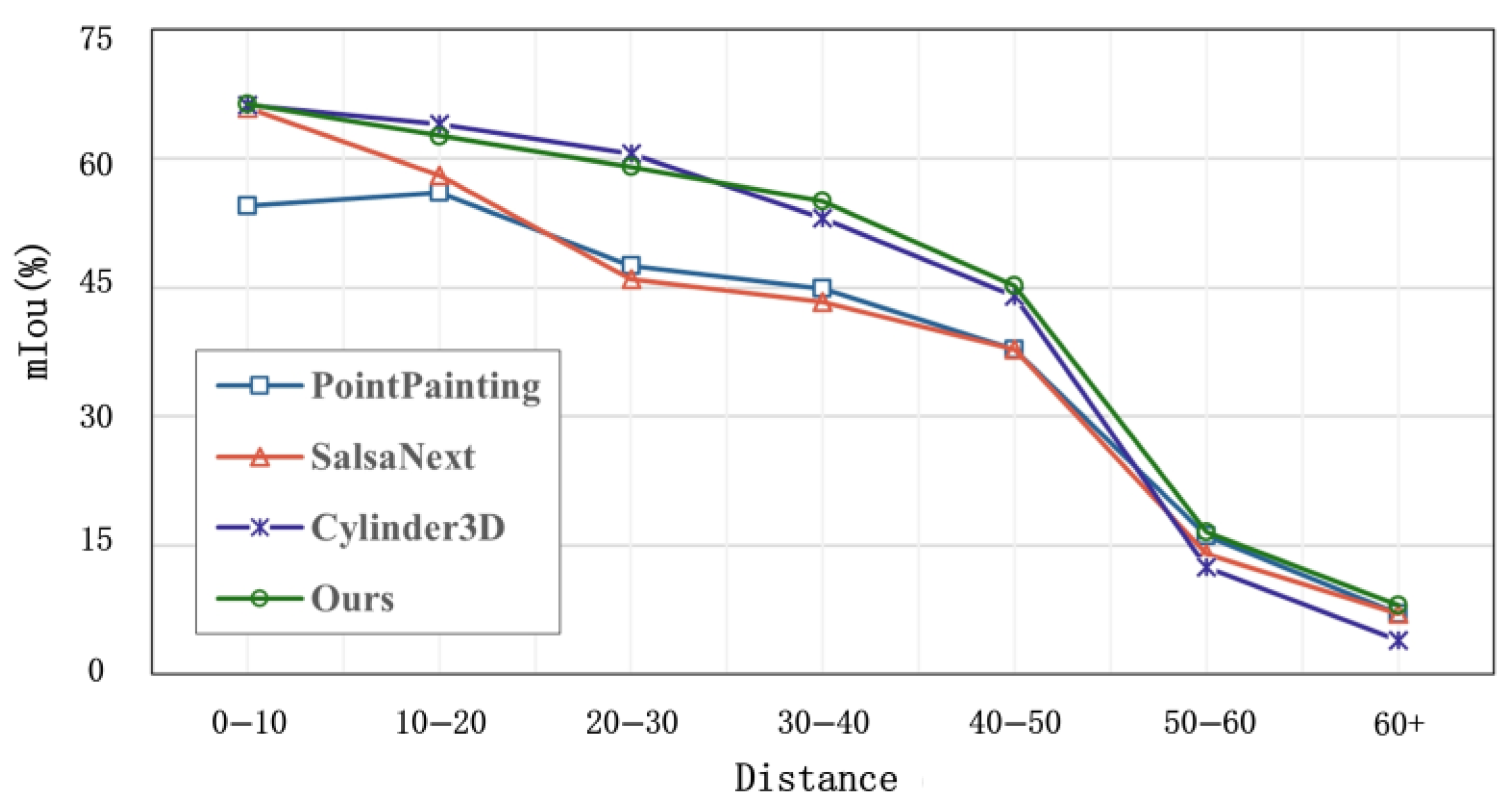
4.4. Distance-Based Evaluation
4.5. Ablation Experiments
4.5.1. Impact of Network Components
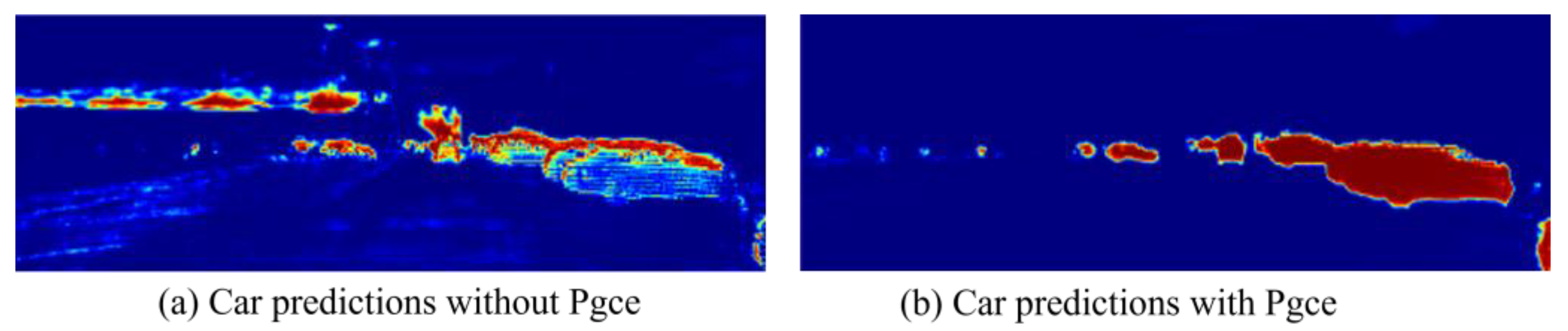
4.5.2. Effect of the Loss Function
4.6. Confrontation Analys
4.7. Efficiency Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Li, Z.; Wang, W.; Hu, L.; Xu, J.; Yuan, M.; Wang, Z.; Ren, Y.; Ye, Y. Multi-supervised bidirectional fusion network for road-surface condition recognition. PeerJ Comput. Sci. 2023, 9, e1446. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Sharma, A.; Nikashina, P.; Gavrilenko, V.; Tselykh, A.; Bozhenyuk, A.V.; Masud, M.; Meshref, H. A Graph Neural Network (GNN)-Based Approach for Real-Time Estimation of Traffic Speed in Sustainable Smart Cities. Sustainability 2023, 15, 11893. [Google Scholar] [CrossRef]
- Kim, J.; Lee, C.; Chung, D.; Kim, J. Navigable Area Detection and Perception-Guided Model Predictive Control for Autonomous Navigation in Narrow Waterways. IEEE Robot. Autom. Lett. 2023, 8, 5456–5463. [Google Scholar] [CrossRef]
- Meng, X.; Liu, Y.; Fan, L.; Fan, J. YOLOv5s-Fog: An Improved Model Based on YOLOv5s for Object Detection in Foggy Weather Scenarios. Sensors 2023, 23, 5321. [Google Scholar] [CrossRef]
- Natan, O.; Miura, J. End-to-End Autonomous Driving with Semantic Depth Cloud Mapping and Multi-Agent. IEEE Trans. Intell. Veh. 2022, 8, 557–571. [Google Scholar] [CrossRef]
- Yang, J.; Chen, G.; Huang, J.; Ma, D.; Liu, J.; Zhu, H. GLE-net: Global-local information enhancement for semantic segmentation of remote sensing images. Sci. Rep. 2024, 14, 25282. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Yang, R.; Zheng, C.; Wang, L.; Zhao, Y.; Fu, Z.; Dai, Q. MAE-BG: Dual-stream boundary optimization for remote sensing image semantic segmentation. Geocarto Int. 2023, 38, 2190622. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, J.; Zhu, M.; Xie, Y.; He, H.; Liu, Y.; Guo, L.; Lai, J.; Guo, Y.; You, J. Fast and accurate semantic segmentation of road crack video in a complex dynamic environment. Int. J. Pavement Eng. 2023, 24, 2219366. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Duan, Y. MVG-Net: LiDAR Point Cloud Semantic Segmentation Network Integrating Multi-View Images. Remote Sens. 2024, 16, 2821. [Google Scholar] [CrossRef]
- Park, J.; Kim, K.; Shim, H. Rethinking Data Augmentation for Robust LiDAR Semantic Segmentation in Adverse Weather. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Meyer, G.P.; Charland, J.; Hegde, D.; Laddha, A.; Vallespi-Gonzalez, C. Sensor Fusion for Joint 3d Object Detection and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar] [CrossRef]
- Xiao, A.; Zhang, X.; Shao, L.; Lu, S. A Survey of Label-Efficient Deep Learning for 3D Point Clouds. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 9139–9160. [Google Scholar] [CrossRef]
- Vishnupriya Chowdhary, S.; Neelima, N. LiDAR Point Clouds in Autonomous Driving Integrated with Deep Learning: A Tech Prospect. In Proceedings of the 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sus-tainable Technologies (ICAECT), Bhilai, India, 11–12 January 2024; pp. 1–5. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Genova, K.; Yin, X.; Kundu, A.; Pantofaru, C.; Cole, F.; Sud, A.; Brewington, B.; Shucker, B.; Funkhouser, T.A. Learning 3D Semantic Segmentation with only 2D Image Supervision. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 361–372. [Google Scholar]
- Li, J.; Dai, H.; Ding, Y. Self-Distillation for Robust LiDAR Semantic Segmentation in Autonomous Driving. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Strudel, R.; Garcia Pinel, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7242–7252. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Yan, S.; Wu, C.; Wang, L.; Xu, F.; An, L.; Guo, K.; Liu, Y. DDRNet: Depth Map Denoising and Refinement for Consumer Depth Cameras Using Cascaded CNNs. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Xu, J.; Xiong, Z.; Bhattacharyya, S. PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–23 June 2022; pp. 19529–19539. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Álvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense Contrastive Learning for Self-Supervised Visual Pre-Training. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3023–3032. [Google Scholar]
- Qi, C.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Supplementary Material. arXiv 2017, arXiv:1612.00593v2. [Google Scholar]
- Qi, C.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, A.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11105–11114. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Lai, X.; Chen, Y.; Lu, F.; Liu, J.; Jia, J. Spherical Transformer for LiDAR-Based 3D Recognition. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17545–17555. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020. [Google Scholar]
- Kong, L.; Liu, Y.; Chen, R.; Ma, Y.; Zhu, X.; Li, Y.; Hou, Y.; Qiao, Y.; Liu, Z. Rethinking range view representation for lidar segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 228–240. [Google Scholar] [CrossRef]
- Engel, N.; Belagiannis, V.; Dietmayer, K.C. Point Transformer. IEEE Access 2020, 9, 134826–134840. [Google Scholar] [CrossRef]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point Transformer V2: Grouped Vector Attention and Partition-Based Pooling. arXiv 2022, arXiv:2210.05666. [Google Scholar]
- Wu, X.; Jiang, L.; Wang, P.; Liu, Z.; Liu, X.; Qiao, Y.; Ouyang, W.; He, T.; Zhao, H. Point Transformer V3: Simpler, Faster, Stronger. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 4840–4851. [Google Scholar]
- Li, J.; Dai, H.; Han, H.; Ding, Y. MSeg3D: Multi-Modal 3D Semantic Segmentation for Autonomous Driving. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21694–21704. [Google Scholar]
- Yin, R.; Cheng, Y.; Wu, H.; Song, Y.; Yu, B.; Niu, R. FusionLane: Multi-Sensor Fusion for Lane Marking Semantic Segmentation Using Deep Neural Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1543–1553. [Google Scholar] [CrossRef]
- Madawy, K.E.; Rashed, H.; Sallab, A.E.; Nasr, O.A.; Kamel, H.; Yogamani, S.K. RGB and LiDAR fusion based 3D Semantic Segmentation for Autonomous Driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 7–12. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. PointPainting: Sequential Fusion for 3D Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2019; pp. 4603–4611. [Google Scholar]
- Zhuang, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-Aware Multi-Sensor Fusion for 3d Lidar Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16280–16290. [Google Scholar]
- Biswas, D.; Tešić, J. Domain Adaptation with Contrastive Learning for Object Detection in Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.; Blaschko, M.B. The Lovász-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks. arXiv 2018, arXiv:1705.08790. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NE, USA, 27–30 June 2015; pp. 770–778. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2016, arXiv:1608.03983v5. [Google Scholar]
- Ioannou, G.; Tagaris, T.; Stafylopatis, A. AdaLip: An Adaptive Learning Rate Method per Layer for Stochastic Optimization. Neural Process. Lett. 2023, 55, 6311–6338. [Google Scholar] [CrossRef]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution. arXiv 2020, arXiv:2007.16100. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Foroosh, H. PolarNet: An Improved Grid Representation for Online LiDAR Point Clouds Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9598–9607. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Input | Car | Bicycle | Motorcycle | Truck | Other Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic Sign | mIoU (%) | Rise/Fall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RandLA-Net [32] | L | 92.0 | 8.0 | 12.8 | 74.8 | 46.7 | 52.3 | 46.0 | 0.0 | 93.4 | 32.7 | 73.4 | 0.1 | 84.0 | 43.5 | 83.7 | 57.3 | 73.1 | 48.0 | 27.3 | 50.5 | 13.7 |
| RangeNet++ [37] | L | 89.4 | 26.5 | 48.4 | 33.9 | 26.7 | 54.8 | 69.4 | 0.0 | 92.9 | 37.0 | 69.9 | 0.0 | 83.4 | 51.0 | 83.3 | 54.0 | 68.1 | 49.8 | 34.0 | 51.2 | 13.0 |
| SequeeneSegV3 [53] | L | 87.1 | 34.3 | 48.6 | 47.5 | 47.1 | 58.1 | 53.8 | 0.0 | 95.3 | 43.1 | 78.2 | 0.3 | 78.9 | 53.2 | 82.3 | 55.5 | 70.4 | 46.3 | 33.2 | 53.3 | 10.9 |
| SalsaNext [38] | L | 90.5 | 44.6 | 49.6 | 86.3 | 54.6 | 74.0 | 81.4 | 0.0 | 93.4 | 40.6 | 69.1 | 0.0 | 84.6 | 53.0 | 83.6 | 64.3 | 64.2 | 54.4 | 39.8 | 59.4 | 4.8 |
| SPVNAS [54] | L | 96.5 | 44.8 | 63.1 | 59.9 | 64.3 | 72.0 | 86.0 | 0.0 | 93.9 | 42.4 | 75.9 | 0.0 | 88.8 | 59.1 | 88.0 | 67.5 | 73.0 | 63.5 | 44.3 | 62.3 | 1.9 |
| Cylinder3D [33] | L | 96.4 | 61.5 | 78.2 | 66.3 | 69.8 | 80.8 | 93.3 | 0.0 | 94.9 | 41.5 | 78.0 | 1.4 | 87.5 | 50.0 | 86.7 | 72.2 | 68.8 | 63.0 | 42.1 | 64.9 | −0.7 |
| PointPainting [46] | L + C | 94.7 | 17.7 | 35.0 | 28.8 | 55.0 | 59.4 | 63.6 | 0.0 | 95.3 | 39.9 | 77.6 | 0.4 | 87.5 | 55.1 | 87.7 | 67.0 | 72.9 | 61.8 | 36.5 | 54.5 | 9.7 |
| RGBAL [45] | L + C | 87.3 | 36.1 | 26.4 | 64.6 | 54.6 | 58.1 | 72.7 | 0.0 | 95.1 | 45.6 | 77.5 | 0.8 | 78.9 | 53.4 | 84.3 | 61.7 | 72.9 | 56.1 | 41.5 | 56.2 | 8.0 |
| PMF [47] | L + C | 94.6 | 47.0 | 62.1 | 66.4 | 74.2 | 78.1 | 70.7 | 0.0 | 96.2 | 42.4 | 80.5 | 0.1 | 86.5 | 59.2 | 88.5 | 72.7 | 75.1 | 63.7 | 42.0 | 63.2 | 1.0 |
| CMF (Ours) | L + C | 96.6 | 45.6 | 66.0 | 61.6 | 76.4 | 78.8 | 75.5 | 0.5 | 96.7 | 45.2 | 80.9 | 1.5 | 89.5 | 64.3 | 88.9 | 72.9 | 75.4 | 65.9 | 43.5 | 64.5 |
| Method | Input | Barrier | Bicycle | Bus | Car | Construction | Motorcycle | Pedestrian | Traffic Cone | Trailer | Truck | Drivable | Other Flat | Sidewalk | Terrain | Manmade | Vegetation | mIoU (%) | Rise/Fall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RangeNet++ [37] | L | 66.0 | 21.3 | 77.2 | 80.9 | 30.2 | 66.8 | 69.6 | 52.1 | 54.2 | 72.3 | 94.1 | 66.6 | 63.5 | 70.1 | 83.1 | 79.8 | 65.5 | 13.8 |
| PolarNet [55] | L | 74.7 | 28.2 | 85.3 | 90.9 | 35.1 | 77.5 | 71.3 | 58.8 | 57.4 | 76.1 | 96.5 | 71.1 | 74.7 | 74 | 87.3 | 85.7 | 71.0 | 8.3 |
| SalsaNext [38] | L | 74.8 | 34.1 | 85.9 | 88.4 | 42.2 | 72.4 | 72.2 | 63.1 | 61.3 | 76.5 | 96 | 70.8 | 71.2 | 71.5 | 86.7 | 84.4 | 72.2 | 7.1 |
| RangeFormer [39] | L | 78 | 45.2 | 94 | 92.9 | 58.7 | 83.9 | 77.9 | 69.1 | 63.7 | 85.6 | 96.7 | 74.5 | 75.1 | 75.3 | 89.1 | 87.5 | 78.1 | 1.2 |
| 2DPASS [16] | L+ C | 74.4 | 44.3 | 93.6 | 92 | 54 | 79.7 | 78.9 | 57.2 | 72.5 | 85.7 | 96.2 | 72.7 | 74.1 | 74.5 | 87.5 | 85.4 | 76.4 | 2.9 |
| 2D3DNet [17] | L + C | 78.3 | 55.1 | 95.4 | 87.7 | 59.4 | 79.3 | 80.7 | 70.2 | 68.2 | 86.6 | 96.1 | 74.9 | 75.7 | 75.1 | 91.4 | 89.9 | 79.0 | 0.3 |
| PMF [47] | L + C | 74.1 | 46.6 | 89.8 | 92.1 | 57 | 77.7 | 80.9 | 70.9 | 64.6 | 82.9 | 95.5 | 73.3 | 73.6 | 74.8 | 89.4 | 87.7 | 76.9 | 2.4 |
| CMF (Ours) | L + C | 78.4 | 54.5 | 95.7 | 91.1 | 64.2 | 85.2 | 79.6 | 73.2 | 66.7 | 85.5 | 95.9 | 74.3 | 75 | 74.9 | 88.9 | 86.8 | 79.3 |
| Baseline | PP | ASPP | RF | RCF | mIoU (%) | |
|---|---|---|---|---|---|---|
| 1 | ✓ | 57.2 | ||||
| 2 | ✓ | ✓ | 57.6 | |||
| 3 | ✓ | ✓ | ✓ | 60.2 | ||
| 4 | ✓ | ✓ | ✓ | ✓ | 62.8 | |
| 5 | ✓ | ✓ | ✓ | ✓ | 63.6 |
| Foc Loss + Lov Loss | Pe Loss | Pgce Loss | mIoU (%) | |
|---|---|---|---|---|
| 1 | ✓ | 61.7 | ||
| 2 | ✓ | ✓ | 63.6 | |
| 3 | ✓ | ✓ | 64.5 |
| #FLOPs | #Params. | Inference Time | mIoU | |
|---|---|---|---|---|
| PointPainting | 51.0 G | 28.1 M | 2.3 ms | 54.5% |
| RGBAL | 55.0 G | 13.2 M | 2.7 ms | 56.2% |
| SalsaNext | 31.4 G | 6.7 M | 1.6 ms | 59.4% |
| Cylinder3D | - | 55.9 M | 62.5 ms | 64.9% |
| PMF | 854.7 G | 36.3 M | 22.3 ms | 63.6% |
| CMF (ours) | 620.2 G | 34.7 M | 20.1 ms | 64.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Wang, X.; Zhao, J.; Hua, X. A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic Segmentation of Point Clouds. Sensors 2025, 25, 2474. https://doi.org/10.3390/s25082474
Shi H, Wang X, Zhao J, Hua X. A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic Segmentation of Point Clouds. Sensors. 2025; 25(8):2474. https://doi.org/10.3390/s25082474
Chicago/Turabian StyleShi, Huisheng, Xin Wang, Jianghong Zhao, and Xinnan Hua. 2025. "A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic Segmentation of Point Clouds" Sensors 25, no. 8: 2474. https://doi.org/10.3390/s25082474
APA StyleShi, H., Wang, X., Zhao, J., & Hua, X. (2025). A Cross-Modal Attention-Driven Multi-Sensor Fusion Method for Semantic Segmentation of Point Clouds. Sensors, 25(8), 2474. https://doi.org/10.3390/s25082474