1. Introduction
The optimization of on-street parking allocation has become a critical issue in the face of accelerating urbanization. As parking demand continues to rise, particularly during peak hours, the limited availability of parking spaces exacerbates traffic congestion, increases carbon emissions, and significantly hinders overall urban mobility efficiency [
1]. This issue not only contributes to immediate inefficiencies but also affects broader social and economic outcomes, such as increased travel time, reduced productivity, and higher operational costs for businesses and individuals. Studies emphasize that the spatial and temporal imbalance in parking demand is a key factor driving these inefficiencies in parking resource utilization [
2]. High demand areas, such as central business districts, frequently face parking shortages, while peripheral regions remain underutilized due to a lack of effective allocation systems [
3]. Addressing this imbalance is essential, not only to alleviate congestion and optimize parking in high-demand areas, but also to enhance overall urban efficiency, and to support sustainable, low-carbon transportation.
Various optimization solutions have been suggested to improve parking resource use and mitigate traffic inefficiencies, including dynamic parking assignment, intelligent guiding systems, and model-based allocation frameworks [
4]. These systems automatically modify parking spot distribution based on real-time demand, hence minimizing search durations and parking failure rates. Recent research has integrated multi-agent systems (MAS) and reinforcement learning (RL) to enhance adaptive scheduling in intricate contexts [
5,
6]. Moreover, intelligent parking guidance systems employing sensors and vehicle-to-infrastructure (V2I) technologies have been deployed in many cities to aid drivers in finding available parking spaces, thereby mitigating congestion resulting from ineffective parking searches [
7,
8].
However, current approaches still encounter major difficulties when applied to the complexity of urban environments, even with the increased focus on dynamic parking distribution. Traditional static allocation methods, like first-in-first-out (FIFO) [
9] and service-in-random-order (SIRO) [
10], are insufficient for managing the extremely changing characteristics of parking demand. These methods fail to adapt to real-time variations, resulting in systemic inefficiencies and the suboptimal use of parking resources. Although more sophisticated approaches, such as online parking assignment systems [
11], seek to address these difficulties, they frequently depend on unrealistic assumptions. This encompasses the constant accessibility of high-resolution, real-time data regarding parking requests and space occupancy, alongside centralized control systems capable of executing globally best decisions. In reality, these requirements are seldom fulfilled, especially during times of maximum congestion or unforeseen disruptions, where parking behaviors become erratic and the necessity for flexible, decentralized management is imperative.
Furthermore, the ongoing spatial disparity between parking availability and demand intensifies system inefficiencies. Areas with high demand frequently face significant shortages, whereas periphery locations are underutilized despite possessing adequate parking places. Despite recent research proposing dynamic reallocation strategies to tackle this issue, several analyses continue to neglect critical behavioral elements, such as parking costs, which profoundly affect user choices and demand distribution [
12,
13]. The model provided in this study does not consider pricing, which constitutes a shortcoming of the current research. Subsequent research will focus on incorporating pricing mechanisms into the optimization framework.
These constraints underscore the pressing necessity for intelligent, decentralized, and adaptive optimization frameworks that can respond to dynamic, partially observable environments [
14]. Contemporary deep reinforcement learning models, despite their potential, frequently depend on centralized control frameworks, exhibit inadequate coordination among agents [
11,
15], and neglect to account for long-term effects such as parking time. These constraints impede their scaling and result in inferior performance [
16]. This paper tackles these problems by presenting a multi-agent reinforcement learning system aimed at surmounting these limitations and providing a decentralized, scalable, and adaptable solution for real-time parking distribution.
To address these issues, this study proposes a multi-agent reinforcement learning framework tailored to the complex nature of dynamic on-street parking allocation. On-street parking is chosen as the focus of this study due to its significant impact on urban mobility and its unique characteristics, including high variability in demand across different times and locations, and its sensitivity to external factors such as traffic congestion and local events. The proposed framework is designed to be decentralized, scalable, and adaptive to real-time conditions, offering the following key contributions:
An MARL parking allocation framework is established to address the intricate and fluctuating characteristics of urban parking demand. The system facilitates cooperative decision-making among several actors to enhance real-time parking distribution. A DRL-based modeling approach is provided to improve the utilization and allocation efficiency of parking resources;
An innovative exploration technique is developed and included into the MARL framework to reduce the likelihood of premature random actions resulting in unsatisfactory long-term allocation strategies. The technique successfully captures spatiotemporal fluctuations in parking demand, ensuring quicker convergence and enhanced adaptation to intricate urban parking environments;
To substantiate the proposed framework, two prevalent baseline models, First In, First Out (FIFO) [
9] and Service In Random Order (SIRO) [
10] are employed for comparative analysis. A realistic parking simulation environment is created to enable quantitative performance analysis of various allocation algorithms. Experimental findings indicate that the proposed MARL framework markedly surpasses conventional baselines regarding parking resource efficiency, demand equilibrium, and overall allocation efficacy.
The subsequent sections of this work are structured as follows:
Section 2 examines the current literature regarding parking allocation.
Section 3 delineates the parking allocation problem and presents baseline methodologies for comparative evaluation.
Section 4 delineates the proposed MARL framework, encompassing the DRL model, learning algorithms, and exploration methodologies.
Section 5 delineates the experimental configuration and simulation outcomes, offering a comparative assessment of various allocation methodologies.
Section 6 ultimately encapsulates the principal contributions of this study and delineates prospective avenues for further investigation.
4. Methodology
4.1. Overall Framework of Reinforcement Learning
The proposed reinforcement learning framework aims to dynamically optimize urban parking resource allocation through a structured multi-agent approach. The process begins with state representation, where real-time and historical data are integrated to derive key environmental variables, including current occupancy levels, forecasted parking demand, active vehicle parking requests, and the availability of parking spaces. To effectively capture the spatiotemporal dependencies inherent in parking systems, Graph Convolutional Networks (GCNs) are employed to model spatial correlations across parking zones, while Gated Recurrent Units (GRUs) are utilized to capture temporal dynamics. These extracted features constitute a high dimensional observation space that serves as the input for intelligent decision-making agents.
Based on the observed states, agents generate actions that determine parking space allocations. The action space consists of two types of agents—(1) optimized agents, which leverage reinforcement learning to adaptively adjust their allocation strategies, and (2) static agents, which operate with fixed rule-based policies in non-learning regions. This hybrid agent structure allows the system to maintain decision-making stability in non-optimized areas while promoting adaptive behavior in critical regions. The overall interaction process is illustrated in
Figure 2, which outlines parking requests, processed through observation, decision-making, feedback, and iterative policy updates.
To guide the learning process, a delayed reward function is designed to balance multiple objectives; it penalizes excessive cruising time and incentivizes successful parking allocations. When a parking request is successfully completed, a reward is returned based on system-level efficiency and demand–response considerations. This reward mechanism enables agents to learn long-term optimal strategies through experience.
The policy learning process is further enhanced through multi-agent coordination using the multi-agent deterministic policy gradient framework. In this setup, a centralized evaluator supports joint learning by sharing information across agents, which improves the overall allocation efficiency. Through continuous interactions between state observation, decision-making, reward feedback, and policy updates, the framework enables real-time, scalable, and adaptive parking management in dynamic urban environments.
4.2. State, Action, Reward
4.2.1. Agent
The set of agents is defined as , where each roadside parking facility is regarded as an individual agent. These agents are categorized into two distinct types: optimized allocation agents , which dynamically adjust parking allocation strategies based on real-time parking demand and supply–demand equilibrium, and non-optimized allocation agents , which adhere to pre-established parking management policies without engaging in the optimization process. The optimized allocation agents, leverage adaptive decision-making mechanisms to enhance the efficiency of parking resource utilization, whereas the non-optimized allocation agents, , operate under static allocation rules.
4.2.2. State
The observation space is defined as , with the corresponding state space denoted as . At the t-th parking request , the observation of agent , represented as consists of two main components—agent-specific attributes and information provided by the parking platform. The agent-specific attributes include a unique identifier for each agent, its affiliated parking management entities, and the number of available parking spaces at its location. The parking platform provides real-time information, including the time step at which the parking request occurs, the geographical distance from the request location to the parking facility , the estimated time of arrival, and the number of vehicles currently cruising toward in search of parking. Additionally, the observation incorporates predicted future parking demand in the vicinity of , which is estimated based on historical data and predictive models. The joint observation at the t-th step, which consists of the observations of all agents, is denoted as and formally expressed as . The system state at time step is represented as , which aggregates the observations of all agents, reflecting the overall distribution of parking resources and serving as the foundation for parking resource optimization and allocation decisions.
4.2.3. Action
The action space is defined as
. At time step
the action of agent
, denoted as
, represents its service decision in response to the parking request
. For optimized allocation agents
, actions are dynamically generated in real time based on a reinforcement learning model, allowing the system to adapt to real-time parking demand and supply–demand equilibrium. In contrast, non-optimized allocation agents
operate under predefined management strategies, where their actions are determined in advance and remain fixed regardless of individual parking requests
. The joint action at time step
, representing the collective decisions of all agents, is formally expressed as
This joint action integrates the dynamically optimized decisions of reinforcement learning-based agents with the static operational strategies of fixed-rule agents, serving as the basis for implementing parking resource allocation policies within the management system.
4.2.4. State Transition
At time step , the state transition of the environment is governed by the transition function , where defines the probabilistic mapping from the current state to the subsequent state under the influence of the joint action . The evolution of is influenced not only by the newly generated parking request but also by a combination of environmental factors, including variations in parking resource availability, the dynamics of cruising vehicles, and the cumulative impact of historical decision-making. Specifically, following the processing of the parking request , at time step , the system updates supply–demand conditions based on the current state and joint action . As a new parking request emerges, the system further refines the allocation of parking resources, resulting in the transition to the next system state . This transition process encapsulates the interplay between real-time parking demand, dynamic supply adjustments, and strategic decision-making, forming the foundation for the optimization of parking resource allocation.
4.2.5. Reward Function
A delayed reward design is proposed, where the reward function
is returned only after the completion of parking request
at time step
. The reward is defined as
where
is a base incentive to encourage requests to be directed to optimized agents in
.
penalizes prolonged cruising, promoting faster and more efficient allocation behavior. While the numerical value of the reward may appear smaller in successful cases due to the subtraction, it represents the net benefit of an effective allocation and is always higher than the reward for failure or inaction. The “otherwise” case refers to parking requests that are either routed to non-optimized areas,
, or rejected before reaching an actionable decision point, due to lacking availability or timeout. In such cases, no reward is returned to the agent.
In the multi-agent reinforcement learning framework, the rewards are shared among all
agents in the optimized allocation zone, facilitating cooperative decision-making. In contrast, for
agents in non-optimized allocation zones, whose policies remain fixed, rewards are not considered. The optimized agents
compete with
, while also cooperating to maximize the expected cumulative reward across all parking requests
throughout the day,
where
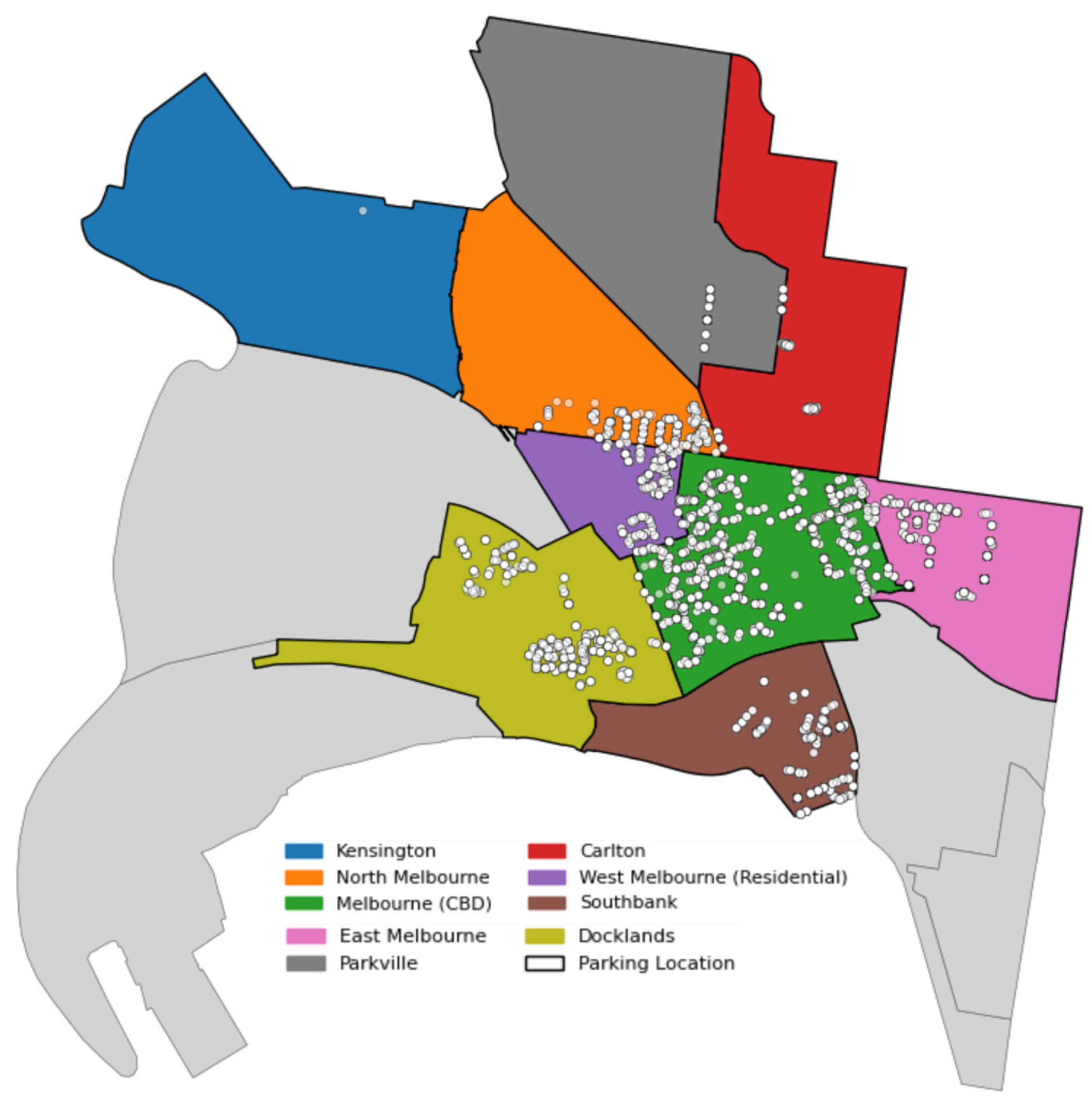
represents the discount factor. The comprehensive roadside parking system is administered by the Melbourne government, with parking spots distributed according to district divisions. The core region is designated for optimum allocation, whereas surrounding areas adhere to established distribution statutes.
Furthermore, to improve system performance and account for real-world limitations, a maximum user waiting time is established. If a parking request is not completed within the specified time frame, it is deemed unsuccessful, and no reward will be granted. This promotes the acquisition of more effective and prompt allocation tactics.
4.3. Adaptive Interaction Modelling for Dynamic Parking Allocation
In dynamic parking allocation, parking facilities consistently engage within a competitive and changing market landscape. The accurate modeling of inter-agent interactions is crucial, as a facility’s capacity to attract vehicles relies not only on its own characteristics, such as pricing and availability, but also on its relationships with adjacent facilities, encompassing both competition and collaboration. An accurate depiction of these interactions improves situational awareness and enables efficient parking allocation decisions. Nonetheless, two principal obstacles must be confronted when simulating these interactions at an urban scale.
The initial problem is defining the extent of interactions. In extensive urban areas, the quantity of parking facilities is considerable, rendering it computationally impractical and unwarranted to represent all paired interactions. Not all facilities exert a substantial influence on each other, especially when they are geographically remote. This study organizes parking facilities into regional partitions according to their adjacency relationships. Interactions are mostly analyzed inside and across spatially proximate areas, where facilities either directly compete for demand or collaborate to optimize parking availability. This systematic method guarantees that the interaction network encompasses the most pertinent competitive and cooperative factors while preserving computing efficiency.
The second challenge involves comprehending the nature of inter-agent interactions. Parking decisions are affected by various factors, such as occupancy rates, proximity to destinations, and walking distances. Competitive interactions occur when neighboring establishments cater to overlapping demand, prompting consumers to select between them based on immediate availability. Conversely, collaborative partnerships arise when many facilities jointly manage surplus demand, like when overflow from a completely occupied venue is channeled to proximate alternatives. These interactions are influenced by spatial proximity and temporal variations in demand, requiring a modeling technique that accurately reflects their changing attributes.
This study utilizes a graph-based interaction modeling framework that integrates a Graph Attention Network to tackle these difficulties. The parking system is depicted as a dynamic heterogeneous graph, with nodes representing parking facilities and edges indicating adjacency-based interactions. A two-stage graph attention mechanism is presented to adaptively weight the influence of surrounding facilities, rather than utilizing static aggregation strategies. At each time step, a facility dynamically consolidates information from its neighbors, prioritizing the most pertinent competitive influences, such as proximate facilities with analogous demand patterns, while diminishing the weight attributed to less significant interactions. This approach facilitates a context-sensitive depiction of parking market dynamics, guaranteeing the system’s responsiveness to variations in spatial and temporal settings.
The preference for the Graph Attention Network over conventional static aggregation techniques is driven by its capacity to dynamically learn and modify interaction weights. In the graph attention network, each parking facility node dynamically assesses the significance of its neighbors according to their conditions. When adjacent parking zones display comparable geographical attributes and temporal demand trends, the model allocates more attention weights to their interactions. In contrast, neighbors with diminished spatial or temporal relevance are assigned lesser weights. This selective aggregation allows the model to prioritize more significant interactions in the decision-making process.
All attention weights are normalized via a Softmax function, guaranteeing that the aggregate of weights for neighboring nodes equals one. This architecture improves the clarity and reliability of information synthesis.
4.4. Adaptive Meta Learning for Strategy Generation
In extensive dynamic parking allocation, training separate policies for each parking request would result in significant computational burden, rendering real-time decision-making impractical. This study employs an adaptive meta-policy learning framework to enhance computational efficiency and improve policy adaptability by utilizing a shared policy network to produce region-aware personalized policies. The proposed method utilizes a meta-policy generator alongside a Gated Recurrent Unit (GRU) to extract long-term parking features, rather than training distinct policies for individual agents, and employs a learnable hypernetwork to dynamically modify agent-specific policy parameters. The GRU is tasked with documenting historical parking characteristics, encompassing occupancy trends, variations caused by holidays and weather conditions, and discrepancies in parking failure rates. These temporal attributes function as the meta-representation of each agent, and are articulated as
where
is the GRU output from the previous time step,
is the current input feature derived from the reinforcement learning model, and
is the allocation action from the previous step. This formulation enables agents to retain a memory of parking demand patterns across different regions, ensuring that policies are adapted to long-term variations in parking demand. Based on the extracted meta-features
, a learnable hypernetwork
is introduced to generate agent-specific parameters for personalized allocation strategies,
These parameters define the individualized decision-making strategies for each agent, ensuring that allocation policies are continuously adjusted according to historical occupancy patterns and environmental fluctuations. Each agent
determines its allocation action using a personalized policy network, formulated as
where
represents a learnable transformation function, such as a neural network, responsible for mapping input features to a latent representation, while
serves as a scaling factor that adjusts the output to align with the practical priority range for parking allocation. To address the challenge of strategy generalization across heterogeneous parking environments, the proposed framework incorporates a region-specific adaptation mechanism that mitigates the potential drawback of policy homogenization in shared-policy architectures. First, the GRU captures regional demand variations, ensuring that learned strategies account for long-term differences between urban centers and residential areas. Second, the policy adaptation mechanism is updated through an online reinforcement learning process that allows policies to dynamically optimize over time, preventing performance degradation due to shifting demand conditions. Finally, the hypernetwork dynamically generates agent-specific policy parameters, ensuring that the shared framework retains the flexibility required for individual decision-making.
4.5. Graph-Based Representation Learning for Large-Scale Parking Allocation
In the context of multi-agent reinforcement learning (MARL), Lowe et al. [
43] proposed a decentralized execution and centralized training framework, where the observations and actions of all agents (i.e.,
and
) are used as inputs for the state and joint action in order to facilitate the training process. However, in the context of our roadside parking allocation problem, directly using the joint observation
and joint action
presents two main issues.
Firstly, it fails to sufficiently model the intricate interactions among agents, which are critical for accurately capturing the systemic dynamics and emergent trends within the parking market. Secondly, as the number of agents increases, the dimensionality of the joint observations and actions escalates, leading to substantial scalability issues, most notably the curse of dimensionality, in large-scale multi-agent systems such as the one considered in this study.
To address these issues, we propose a pooling representation module, designed to learn a compact yet semantically rich global representation of the parking market. This representation serves as an effective state-action representation, supporting centralized learning for large-scale agent systems. For simplicity, in this section, we omit the time step subscript .
4.5.1. Multi-View Heterogeneous Graph
Building on the theoretical framework of modeling the entire roadside parking market as a “dynamic heterogeneous graph”, we introduce a multi-view heterogeneous graph method designed to extract high-dimensional data from the parking market and distil them into a more compact and informative representation. Specifically, we begin by integrating the actions of dynamic parking allocation agents
into the graph
by concatenating the actions with their respective observations. This process aggregates the parking allocation information for all agents, thus constructing a complete representation of the parking market, denoted as
. We then apply the model to
in order to capture the interactions among all agents, resulting in enhanced observations for each agent, expressed as
where
represents a learnable parameter, and
encompasses the enhanced observations for both dynamic and fixed agents, denoted as
, which are essential for modeling the complex interdependencies within the parking market. Subsequently, a learnable pooling operation is performed to extract key features from the parking market, generating a latent representation while eliminating redundant information. In particular, the projection vector
is used to map
into importance scores for the agents,
where
is a learnable projection vector. Based on the learned importance scores
, we select the top
most significant agents and discard the others, as follows:
Here,
represents the importance scores of the top
agents. A gating operation is then employed to control the retention of relevant information. The importance scores are normalized into a gating vector, which is element-wise multiplied with
,
In this context, ⊙ denotes element-wise multiplication, and the normalization function
is implemented via the Softmax operation. This gating mechanism allows gradients to propagate through the projection vector
, facilitating its learning through backpropagation. By learning {
}, a permutation-invariant readout operation is applied to extract a comprehensive representation from the dynamic parking allocation agents,
Similarly, a comprehensive representation
is derived for the fixed parking allocation agents
, using distinct learnable projection vectors and the remaining number of agents. Ultimately, the latent representation of the entire parking market is expressed as
In summary, the proposed framework combines the competitive and cooperative dynamics of the parking market, providing a comprehensive solution to the issues of large-scale agent coordination and interaction.
4.5.2. Contrastive Graph Representation Learning for Multi-Agent Coordination
A direct challenge concerns how to effectively train the Heterogeneous Graph Pooling (HGP) method to extract meaningful latent representations of the roadside parking market. One straightforward approach is to update the HGP through the reinforcement learning (RL) objective function. However, RL algorithms optimize agent policies based on feedback rewards from the environment, making this approach inherently more complex compared to supervised learning methods. Consequently, learning effective latent representations from high-dimensional input through RL is a challenging task. Inspired by contrastive learning in image-based models, we propose a Graph Contrastive Learning (GCL) objective as an auxiliary task to promote the learning of latent state-action representations from the high-dimensional roadside parking market.
Specifically, given a query instance
, a positive instance
, and
negative instances
, the contrastive learning objective is designed to encourage the query instance
to align with the positive instance
, while pushing it away from the negative instances
in order to learn distinguishable representations. The query instance
is derived by applying HGP on the subgraph
, as follows:
The position of the parking request is selected as the center, and the nearest parking facilities, along with their corresponding edges, are chosen to form the subgraph . This process is analogous to cropping a subregion from a geographical map. Similarly, the subgraph for the positive instance is extracted from the same graph , but with a randomly selected center. The subgraphs for the negative instances are randomly cropped from other graphs within the batch. The representations for both the positive instance and the negative instances are obtained using the same method.
The loss function is then employed to optimize the GCL objective function,
A bilinear projection is used to assess the similarity between instances. is a learnable parameter. The objective function is treated as an auxiliary task and is optimized alongside the RL objective.
4.6. Optimized Centralized Policy Learning
A centralized actor–critic policy learning framework is proposed to improve the efficiency of multi-agent decision-making in extensive, dynamic parking allocation. This method is especially applicable in scenarios where agents need to continuously modify parking availability and pricing, providing a more refined control compared to discrete-action models. The centralized training and decentralized execution model facilitates global coordination while ensuring computational practicality in large agent networks. The actor–critic architecture stabilizes policy updates by utilizing both individual agent policies and a common evaluator, effectively tackling the non-stationarity challenges present in decentralized learning systems.
At each time step, given the joint observation and the dynamic heterogeneous graph representation of the system, the policy module and the meta-generator module are updated to maximize the estimated expected return,
where
and
are the learnable parameters of the model and meta-generator, respectively, and
represents the experience replay buffer containing state-transition tuples
. The latent representation
is computed at time step
, and
serves as the centralized evaluator shared across all agents, used to estimate the expected return.
To mitigate the non-stationarity issues inherent in decentralized multi-agent learning, a centralized evaluator aggregates global information while maintaining computational efficiency.
The optimization of both the centralized evaluator and the contrastive heterogeneous graph pooling learning module is achieved by jointly minimizing the reinforcement learning objective and the graph contrastive learning objective, formulated as
where
, and
and
are the learnable parameters of the evaluator
In this context,
and
denote the target policy of agent
and the target evaluator for delayed parameters, respectively.
To further enhance policy learning robustness, graph contrastive learning is incorporated as an auxiliary objective to refine latent state action representations. By maximizing the similarity between augmented positive representations while increasing the divergence from negative representations, the proposed framework ensures more informative feature encoding.
6. Conclusions
Acquiring high-quality spatiotemporal parking demand and supply data remains a significant challenge due to the variability of urban traffic conditions and the limited deployment of parking sensors. The complexities introduced by dynamic demand patterns and spatial dependencies further complicate the accurate prediction and allocation of parking resources. To address these challenges, this paper presents a Multi-Agent Reinforcement Learning (MARL)-based framework, incorporating Graph Convolutional Networks (GCNs) into the MARL-GCN model, designed to optimize on-street parking allocation. The model effectively captures spatial correlations between parking areas and the temporal variations in parking demand, providing a scalable solution for urban parking management.
To account for the diversity in parking demand across different urban areas, we develop a task-specific spatial model to represent the unique spatial relationships between parking spots and demand grids. Additionally, to enhance the allocation process, we introduce a time-adaptive learning module that captures the dynamic, nonlinear relationships between parking supply and demand. This enables the model to effectively address fluctuations in parking demand and allocate spaces in real-time.
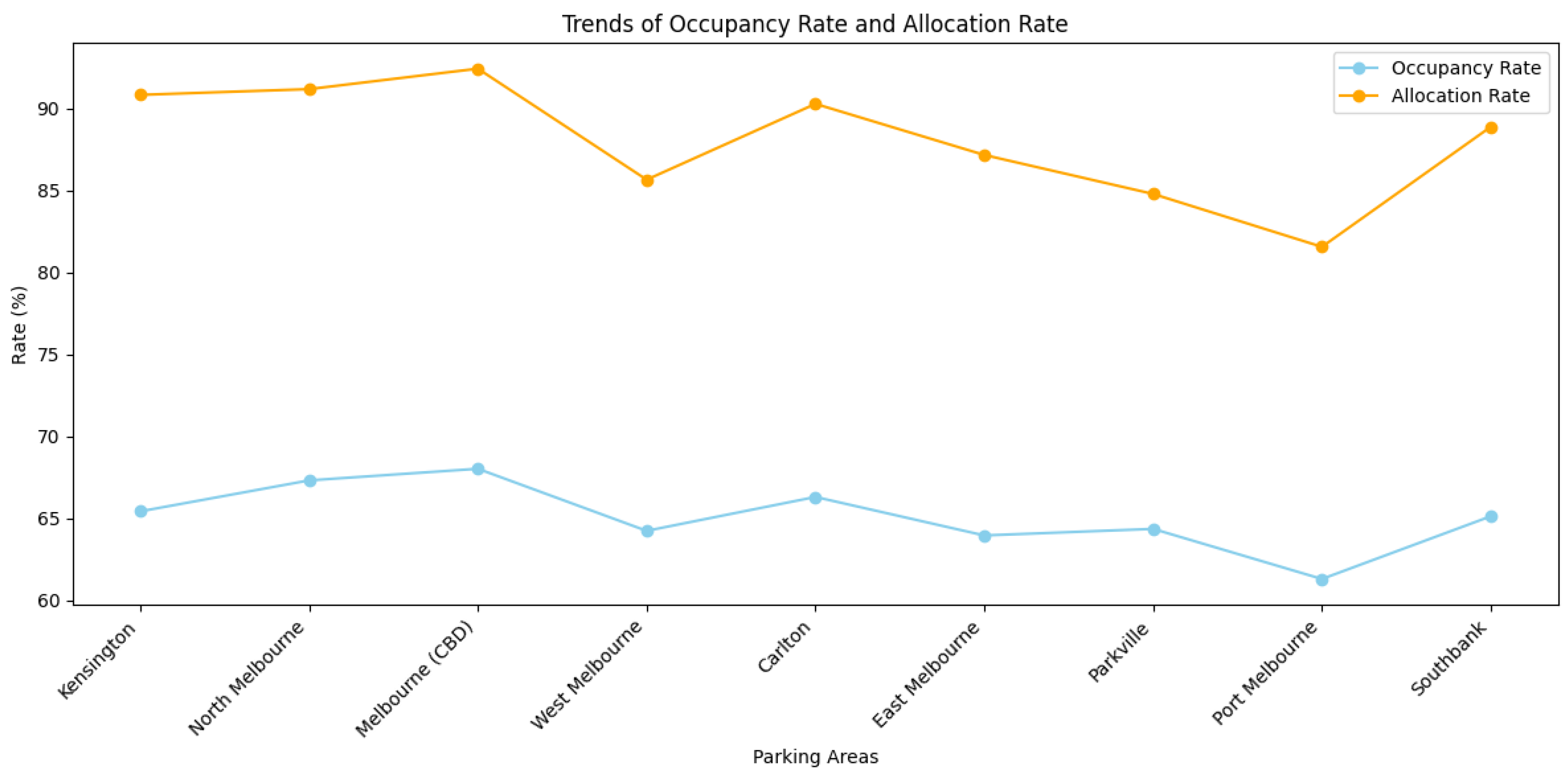
Moreover, in response to the challenges of competition and cooperation in parking allocation, the MARL-GCN model incorporates an adaptive framework capable of adjusting its strategy according to peak and off-peak demand variations, ensuring efficient resource allocation throughout the day. The model outperforms traditional strategies, such as first-in first-out (FIFO) and Service in Random Order (SIRO), particularly in high-demand areas, such CBD and Southbank.
The results of this study demonstrate that the MARL-GCN model effectively tackles complex, large-scale parking allocation tasks in dynamic urban environments. However, potential limitations remain. The model does not incorporate parking pricing strategies or behavioral factors such as user preferences and compliance, which are important for fully capturing real-world decision-making dynamics.
Future work may focus on improving the model’s generalizability by integrating real-time traffic and behavioral data, exploring lightweight deployment strategies, and incorporating pricing mechanisms to enhance policy responsiveness and user engagement in broader urban applications.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}