
An Algorithm for Mining the Living Habits of Elderly People Living Alone Based on AIoT


Abstract
1. Introduction
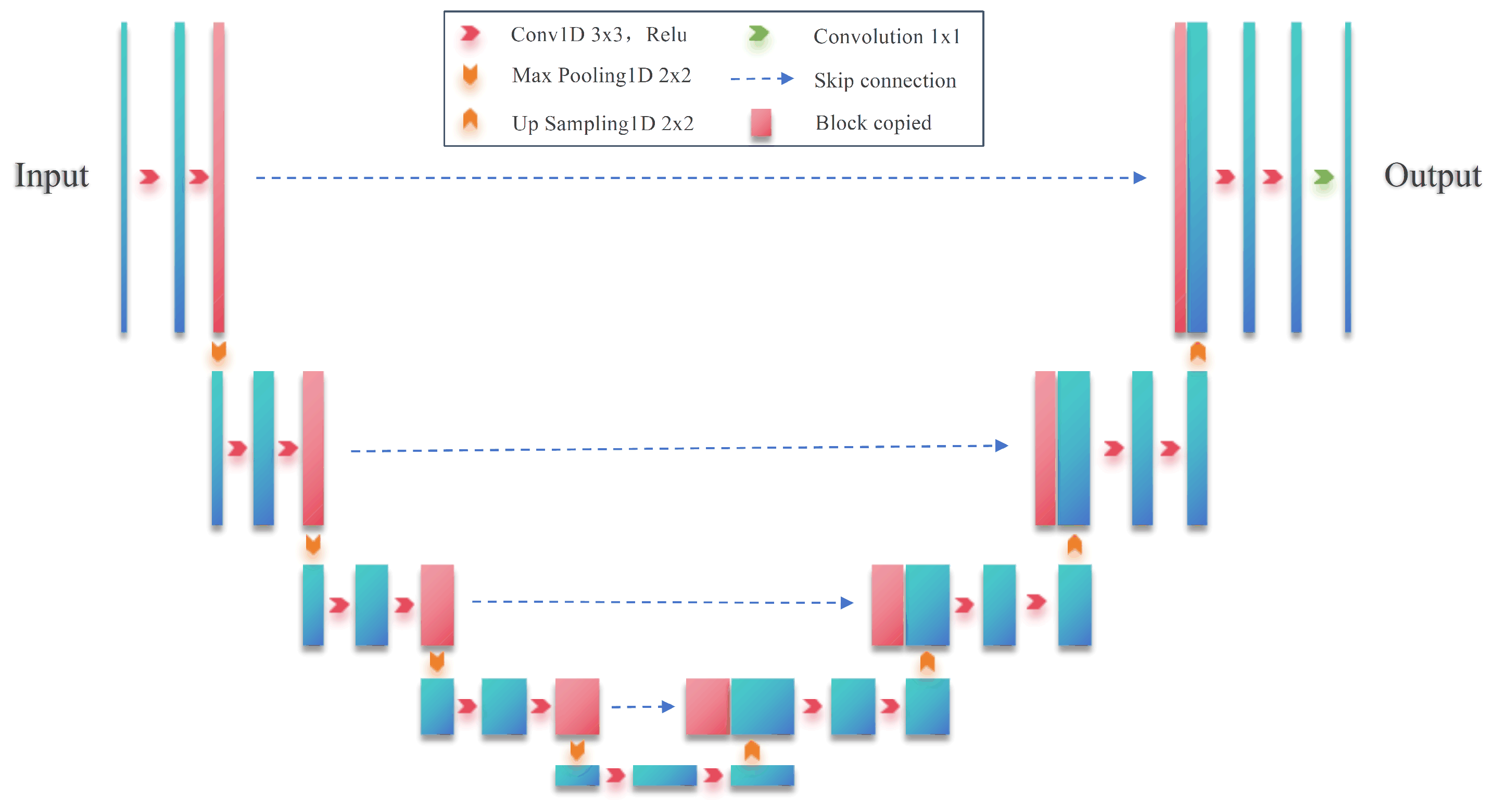
- This study uses a one-dimensional U-Net network to classify the behavioral data of elderly individuals living alone. The encoder applies one-dimensional convolution and pooling to capture local features and reduce data dimensions. The decoder uses upsampling and skip connections to restore high-resolution features, integrating detailed information from the encoder. This approach minimizes information loss. The final classification is performed through the output layer, effectively identifying the daily behavior patterns of the elderly.
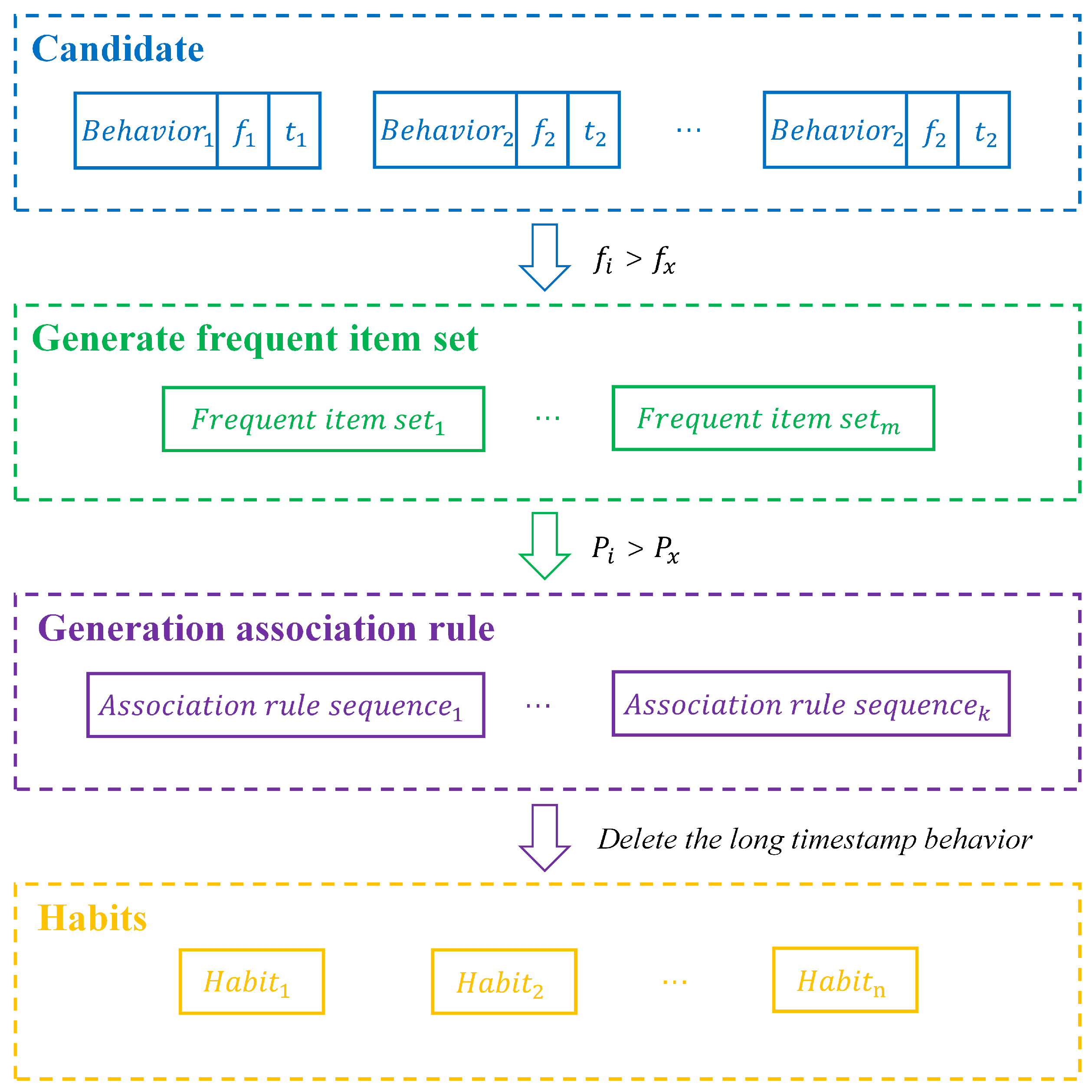
- By using temporal association rule mining, the inclusion of timestamps helps capture the time dependency and periodicity of behavior patterns, revealing the long-term habits of elderly individuals. For example, it can identify associations like “waking up at 8 AM” or “taking a walk at 10 AM daily”, focusing on both the behaviors and their timing. This method has solved the problem of traditional association rules being unable to effectively handle the time factor, thus enhancing the analysis precision and practicality of behavioral data.
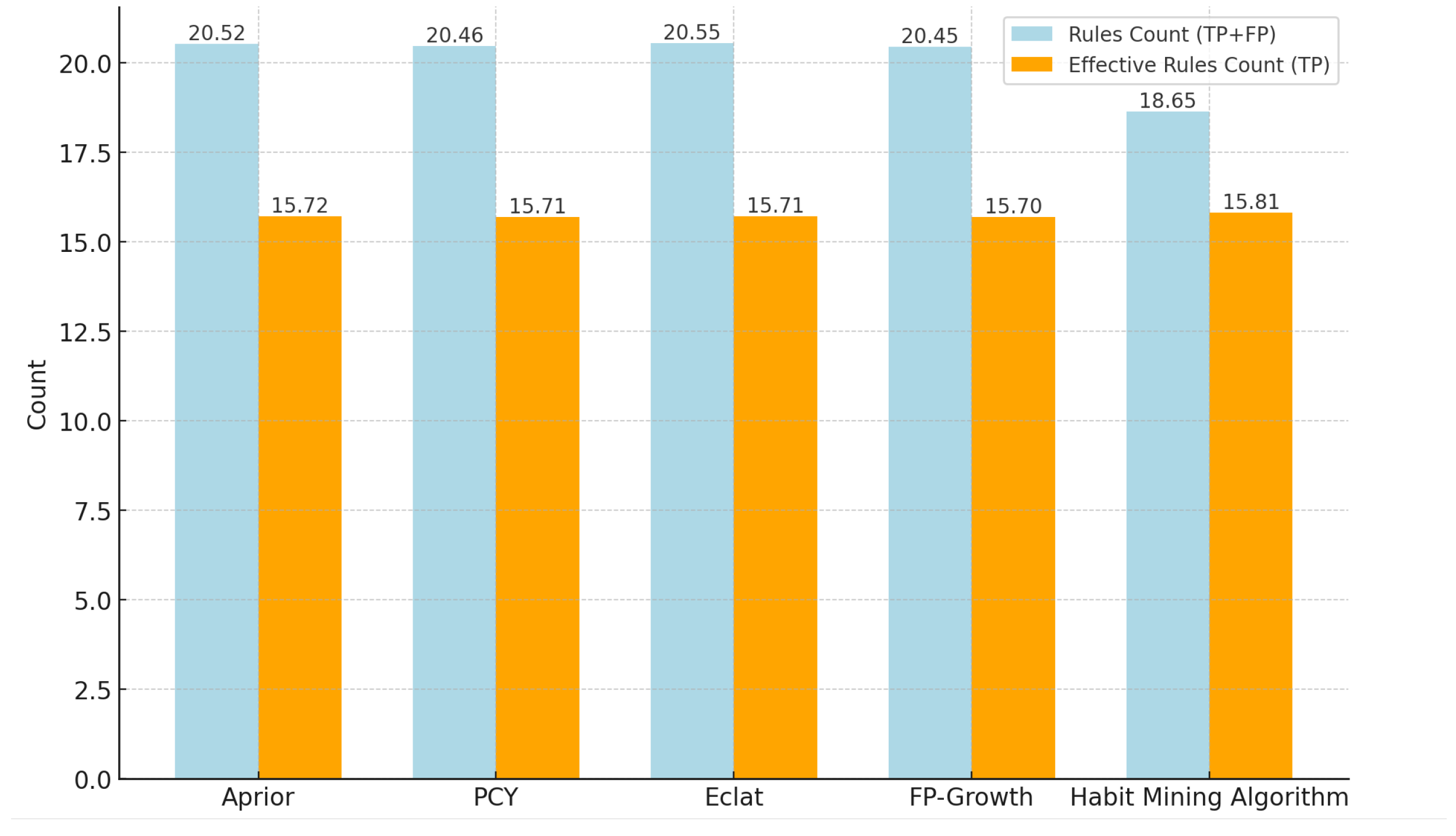
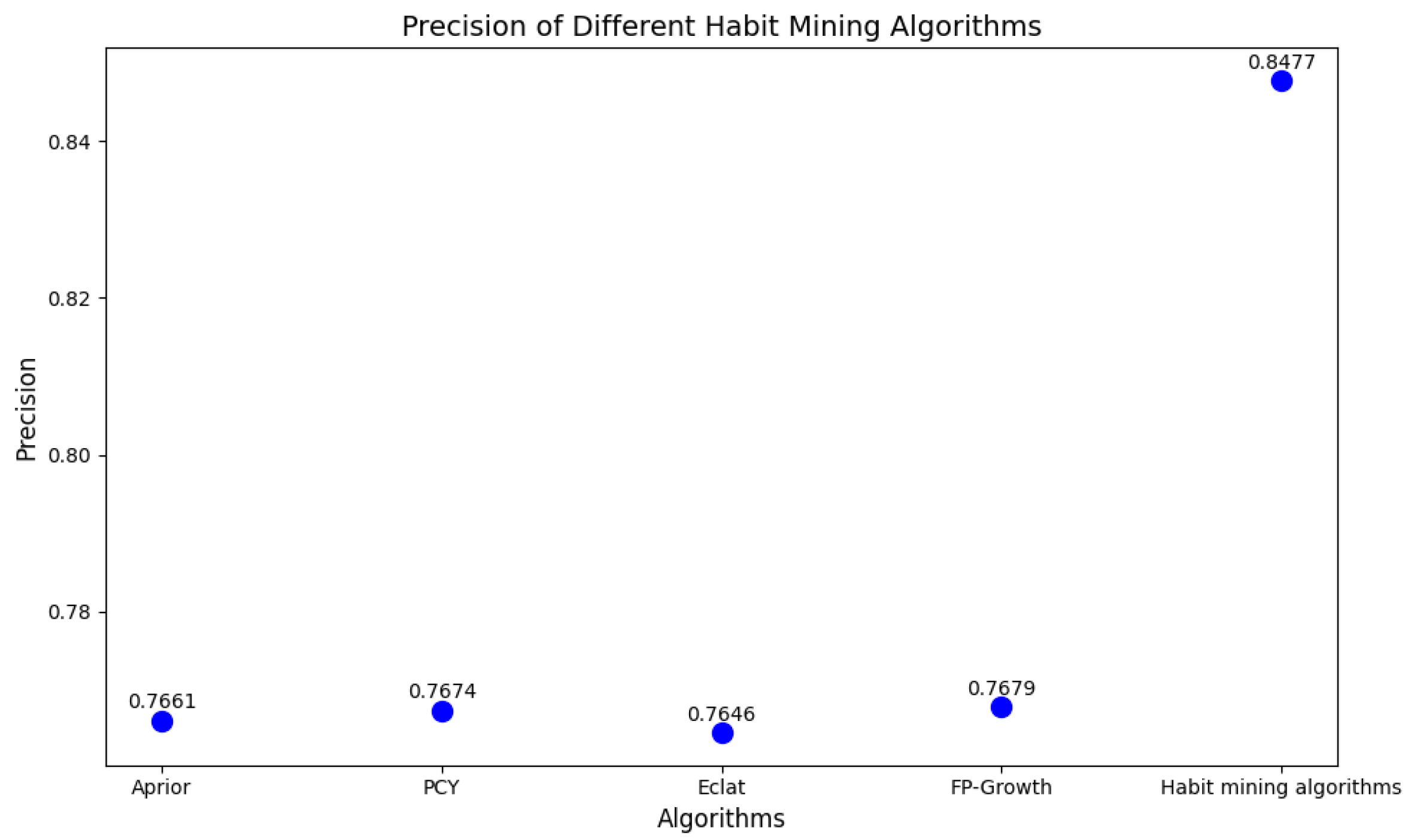
- Experiments show that this algorithm is superior to the existing sota algorithm in all aspects. Regarding behavior recognition, the average balance accuracy of ARUBA is 1.96% higher than that of the sota algorithm with the ARUBA dataset. In the MILAN dataset, the average weighted F1 value and the average balance accuracy of sota algorithm are improved by 1% and 1.82%, respectively. In terms of association rules, with the same dataset, the precision of the proposed algorithm is improved by 7.98% compared with the existing sota algorithm.
2. Related Work
2.1. Human Activity Recognition Algorithms
2.2. Association Rule Algorithms
3. Proposed Method
3.1. Preliminary
3.1.1. U-Net
3.1.2. Association Rule Algorithm
3.1.3. Problem Definition
3.2. Habit Mining Algorithm Architecture
3.2.1. Data Preprocessing
3.2.2. Feature Extraction and Classification
3.2.3. Habit Mining Algorithm
4. Experiments
4.1. Experiments Setup
Experimental Data Preprocessing
4.2. Evaluation Metrics
Implementation Settings
4.3. Ablation Experiments and Sensitivity Analysis
5. Related Discussion
5.1. Discussion on Superiority
5.2. Discussion on Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, L.X. Study on the Social Synergy Mechanism of Home Safety for the Elderly Living Alone. J. Popul. 2024, 46. [Google Scholar]
- de Paiva Santos, R.; Cristina, W.; Araujo, T. Elderly People Living Alone. Fisioter. Bras 2019, 20. [Google Scholar] [CrossRef]
- Henning-Smith, C.; Tuttle, M.; Tanem, J.; Jantzi, K.; Kelly, E.; Florence, L.C. Social isolation and safety issues among rural older adults living alone: Perspectives of Meals on Wheels programs. J. Aging Soc. Policy 2024, 36, 282–301. [Google Scholar] [CrossRef] [PubMed]
- Durgun, Y. Fall detection systems supported by TinyML and accelerometer sensors: An approach for ensuring the safety and quality of life of the elderly. Int. Sci. Vocat. Stud. J. 2023, 7, 55–61. [Google Scholar] [CrossRef]
- Bouaziz, G.; Brulin, D.; Pigot, H.; Campo, E. Detection of social isolation based on meal-taking activity and mobility of elderly people living alone. IRBM 2023, 44, 100770. [Google Scholar] [CrossRef]
- Wu, W.; Long, S.; Cerda, A.A.; Garcia, L.Y.; Jakovljevic, M. Population ageing and sustainability of healthcare financing in China. Cost Eff. Resour. 2023, 21, 97. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. Using Language Model to Bootstrap Human Activity Recognition Ambient Sensors Based in Smart Homes. Electronics 2021, 10, 2498. [Google Scholar] [CrossRef]
- Kong, Y.L.; Liu, J. Research on Data Mining of User Behavior and Control Strategy in Smart Home. Electronics 2013, 24, 39–42. [Google Scholar]
- Liang, T.K.; Zeng, B.; Liu, J.Q. An FP-Growth-based method for mining smart home users’ temporal association manipulation habits. Comput. Appl. Res. 2020, 37, 385–389. [Google Scholar]
- Li, G.Z.; Wang, H.C.; Li, S.G. An Improved Apriori Algorithm for Association Rules. Telkomnika Indones. J. Electr. Eng. 2013, 11, 942–946. [Google Scholar] [CrossRef]
- Gupta, N.; Gupta, S.K.; Pathak, R.K.; Jain, V.; Rashidi, P.; Suri, J.S. Human activity recognition in artificial intelligence framework: A narrative review. Comput. Appl. Res. 2022, 55, 4755–4808. [Google Scholar]
- Ray, A.; Kolekar, M.H.; Balasubramanian, R.; Hafiane, A. Transfer learning enhanced vision-based human activity recognition: A decade-long analysis. Int. J. Inf. Manag. Data Insights 2023, 2, 100142. [Google Scholar] [CrossRef]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Multi-level feature fusion for multimodal human activity recognition in Internet of Healthcare Things. Inf. Fusion 2023, 94, 17–31. [Google Scholar]
- Hou, K.M.; Diao, X.; Shi, H.; Ding, H.; Zhou, H.; de Vaulx, C. Trends and challenges in AIoT/IIoT/IoT implementation. Sensors 2023, 23, 5074. [Google Scholar] [CrossRef]
- Chataut, R.; Phoummalayvane, A.; Akl, R. Unleashing the power of IoT: A comprehensive review of IoT applications and future prospects in healthcare, agriculture, smart homes, smart cities, and industry 4.0. Sensors 2023, 23, 7194. [Google Scholar] [CrossRef]
- Park, E.; Del Pobil, A.P.; Kwon, S.J. The Role of Internet of Things (IoT) in Smart Cities: Technology Roadmap-oriented Approaches. Sustainability 2018, 10, 1388. [Google Scholar] [CrossRef]
- Salama, R.; Al-Turjman, F.; Aeri, M.; Yadav, S.P. Internet of intelligent things (IoT)-An overview. In Proceedings of the 2023 International Conference on Computational Intelligence, Communication Technology and Networking (CICTN), Ghaziabad, India, 20–21 April 2023; pp. 801–805. [Google Scholar]
- Sadeghi-Niaraki, A. Internet of Thing (IoT) review of review: A Bibliometric overview since its foundation. Future Gener. Comput. Syst. 2023, 143, 361–377. [Google Scholar] [CrossRef]
- Sun, K.; Wang, X.; Miao, X.; Zhao, Q. A review of AI edge devices and lightweight CNN deployment. Neurocomputing 2024, 614, 128791. [Google Scholar]
- Sarker, I.H. Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar]
- Waheed, S.R.; Rahim, M.S.M.; Suaib, N.M.; Salim, A.A. CNN deep learning-based image to vector depiction. Multimed. Tools Appl. 2023, 82, 20283–20302. [Google Scholar] [CrossRef]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Cho, H.; Yoon, S.M. Divide and Conquer-Based 1D CNN Human Activity Recognition Using Test Data Sharpening. Sensors 2018, 18, 1055. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.F. Research on Human Behavior Recognition for Lightweight Sensors Based on Knowledge Distillation. Ph.D. Thesis, Wuhan Textile University, Wuhan, China, 2024. [Google Scholar]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar]
- Gülmez, B. Stock price prediction with optimized deep LSTM network with artificial rabbits optimization algorithm. Expert Syst. Appl. 2023, 227, 120346. [Google Scholar]
- Yin, L.; Wang, L.; Li, T.; Lu, S.; Tian, J.; Yin, Z.; Li, X.; Zheng, W. U-Net-LSTM: Time series-enhanced lake boundary prediction model. Land 2023, 12, 1859. [Google Scholar] [CrossRef]
- Sherif, K.; Azmy, M.; Alakkari, K.; Abotaleb, M.; El-Kenawy, E.S.M. Deep Learning in IoT: An LSTM Approach for NDVI Forecasting. In Proceedings of the 2023 3rd International Conference on Electronic Engineering (ICEEM), Menouf, Egypt, 7–8 October 2023; pp. 1–7. [Google Scholar]
- Hsueh, Y.L.; Lie, W.N.; Guo, G.Y. Human Behavior Recognition from Multiview Videos. Inf. Sci. 2020, 517, 275–296. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar]
- Zhu, X.B.; Qiu, H.L. Human activity recognition with smartphone sensor data. Comput. Eng. Appl. 2016, 52, 1–5, 49. [Google Scholar] [CrossRef]
- Zhong, R.; Wang, H. Research of Commonly Used Association Rules Mining Algorithm in Data Mining. In Proceedings of the 2011 International Conference on Internet Computing and Information Services, Hong Kong, China, 17–18 September 2011; pp. 219–222. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.H.; Shahbahrami, A. A survey of evolutionary computation for association rule mining. Inf. Sci. 2020, 524, 318–352. [Google Scholar]
- Santoso, M.H. Application of association rule method using apriori algorithm to find sales patterns case study of indomaret tanjung anom. Brill. Res. Artif. Intell. 2021, 1, 54–66. [Google Scholar]
- Mohamad, S.K.; Tasir, Z. Exploring how feedback through questioning may influence reflective thinking skills based on association rules mining technique. Think. Ski. Creat. 2023, 47, 101231. [Google Scholar] [CrossRef]
- Hela, S.; Amel, B.; Badran, R. Early anomaly detection in smart home: A causal association rule-based approach. Artif. Intell. Med. 2018, 91, 57–71. [Google Scholar] [CrossRef] [PubMed]
- Kang, K.J.; Ka, B.; Kim, S.J. A service scenario generation scheme based on association rule mining for elderly surveillance system in a smart home environment. Eng. Appl. Artif. Intell. 2012, 25, 1355–1364. [Google Scholar]
- Heierman, E.O.; Cook, D.J. Improving home automation by discovering regularly occurring device usage patterns. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; pp. 537–540. [Google Scholar] [CrossRef]
- Niu, S.F. A Research on Smart Home User Behavior Pattern Based on Cloud-Based Data Warehouse; Beijing University of Posts and Telecommunications: Beijing, China, 2014; CNKI:CDMD:2.1015.527901. [Google Scholar]
- Apiletti, D.; Baralis, E.; Cerquitelli, T.; Garza, P.; Pulvirenti, F.; Venturini, L. Frequent Itemsets Mining for Big Data: A Comparative Analysis. Big Data Res. 2017, 9, 67–83, ISSN 2214–5796. [Google Scholar]
- Wang, H.; Cao, P.; Yang, J.; Zaiane, O. Narrowing the semantic gaps in u-net with learnable skip connections: The case of medical image segmentation. Neural Netw. 2024, 178, 106546. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-net and its variants for medical image segmentation: A review of theory and applications f. IEEE Access 2021, 9, 82031–82057. [Google Scholar]
- Du, G.; Cao, X.; Liang, J.; Chen, X.; Zhan, Y. Medical Image Segmentation based on U-Net: A Review. J. Imaging Sci. Technol. 2020, 64, jist0710. [Google Scholar] [CrossRef]
- Williams, C.; Falck, F.; Deligiannidis, G.; Holmes, C.C.; Doucet, A.; Syed, S. A unified framework for U-Net design and analysis. Adv. Neural Inf. Process. Syst. 2023, 36, 27745–27782. [Google Scholar]
- Beeche, C.; Singh, J.P.; Leader, J.K.; Gezer, N.S.; Oruwari, A.P.; Dansingani, K.K.; Chhablani, J.; Pu, J. Super U-Net: A modularized generalizable architecture. Pattern Recognit. 2022, 128, 108669. [Google Scholar] [PubMed]
- Bouchabou, D.; Nguyen, S.; Lohr, C.; Leduc, B.; Kanellos, I. Fully convolutional network for activity recognition in smart homes. Proceedings of DL-HAR 2020; Springer: Singapore, 2021; pp. 111–125. [Google Scholar]
- Li, L.; Ding, P.; Chen, H.; Wu, X. Frequent Pattern Mining in Big Social Graphs. IEEE Trans. Emerg. Top. Comput. Intell. 2012, 6, 638–646. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Lstm networks using smartphone data for sensor—Based human activity recognition in smart homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef] [PubMed]
- Ashfaq, A.; Lingman, M.; Nowaczyk, S. KAFE: Knowledge and Frequency Adapted Embeddings. In Machine Learning, Optimization, and Data Science; Nicosia, G., Ed.; Lecture Notes in Computer Science, Springer: Cham, Switzerland, 2021. [Google Scholar]
- Cook, D.J.; Schmitter-Edgecombe, M. Assessing the quality of activities in a smart environment. Methods Inf. Med. 2009, 48, 480–485. [Google Scholar]
- Liciotti, D.; Bernardini, M.; Romeo, L. A sequential deep learning application for human activity recognition in smart homes. Neurocomputing 2020, 396, 501–513. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 25 | 50 | 75 | 100 |
|---|---|---|---|---|
| LSTM | 87.00 | 90.67 | 93.67 | 97.00 |
| FCN | 91.00 | 97.33 | 97.33 | 98.67 |
| U-Net | 95.00 | 97.33 | 97.33 | 99.33 |
| LSTM+Embedding | 92.00 | 98.00 | 98.00 | 100.00 |
| FCN+Embedding | 99.67 | 99.67 | 100.00 | 100.00 |
| U-Net+Embedding | 99.67 | 100.00 | 100.00 | 100.00 |
| model | 25 | 50 | 75 | 100 |
|---|---|---|---|---|
| LSTM | 68.00 | 75.00 | 84.67 | 84.00 |
| FCN | 83.00 | 88.67 | 91.33 | 76.00 |
| U-Net | 93.33 | 93.00 | 94.00 | 95.00 |
| LSTM+Embedding | 75.33 | 93.33 | 96.67 | 96.67 |
| FCN+Embedding | 94.00 | 96.67 | 96.67 | 98.33 |
| U-Net+Embedding | 95.00 | 97.33 | 98.00 | 99.00 |
| Model | 25 | 50 | 75 | 100 |
|---|---|---|---|---|
| LSTM | 81.45 | 70.37 | 77.68 | 80.33 |
| FCN | 83.42 | 85.68 | 85.07 | 85.79 |
| U-Net | 90.43 | 91.07 | 90.20 | 91.61 |
| LSTM+Embedding | 76.34 | 89.77 | 94.23 | 95.08 |
| FCN+Embedding | 93.27 | 95.07 | 95.76 | 95.87 |
| U-Net+Embedding | 95.23 | 95.89 | 96.03 | 95.91 |
| Model | 25 | 50 | 75 | 100 |
|---|---|---|---|---|
| LSTM | 48.67 | 57.70 | 62.71 | 60.34 |
| FCN | 74.91 | 75.15 | 77.65 | 67.97 |
| U-Net | 82.77 | 83.30 | 84.15 | 83.57 |
| LSTM+Embedding | 61.35 | 82.05 | 84.57 | 87.93 |
| FCN+Embedding | 90.30 | 87.83 | 86.77 | 85.57 |
| U-Net+Embedding | 92.15 | 89.86 | 88.25 | 84.92 |
| Experimental Setup | Number of Rules (TP+FP) | Number of Valid Rules (TP) | Precision |
|---|---|---|---|
| U-net only | / | / | / |
| FP-Growth | 20.450 | 15.703 | 0.7679 |
| U-Net+FP-Growth | 19.974 | 15.774 | 0.7897 |
| U-Net+Embedding+FP-Growth | 18.653 | 15.813 | 0.8477 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Lu, Y.; Jiang, Y. An Algorithm for Mining the Living Habits of Elderly People Living Alone Based on AIoT. Sensors 2025, 25, 2299. https://doi.org/10.3390/s25072299
Wu J, Lu Y, Jiang Y. An Algorithm for Mining the Living Habits of Elderly People Living Alone Based on AIoT. Sensors. 2025; 25(7):2299. https://doi.org/10.3390/s25072299
Chicago/Turabian StyleWu, Jiaxuan, Yuxin Lu, and Yueqiu Jiang. 2025. "An Algorithm for Mining the Living Habits of Elderly People Living Alone Based on AIoT" Sensors 25, no. 7: 2299. https://doi.org/10.3390/s25072299
APA StyleWu, J., Lu, Y., & Jiang, Y. (2025). An Algorithm for Mining the Living Habits of Elderly People Living Alone Based on AIoT. Sensors, 25(7), 2299. https://doi.org/10.3390/s25072299