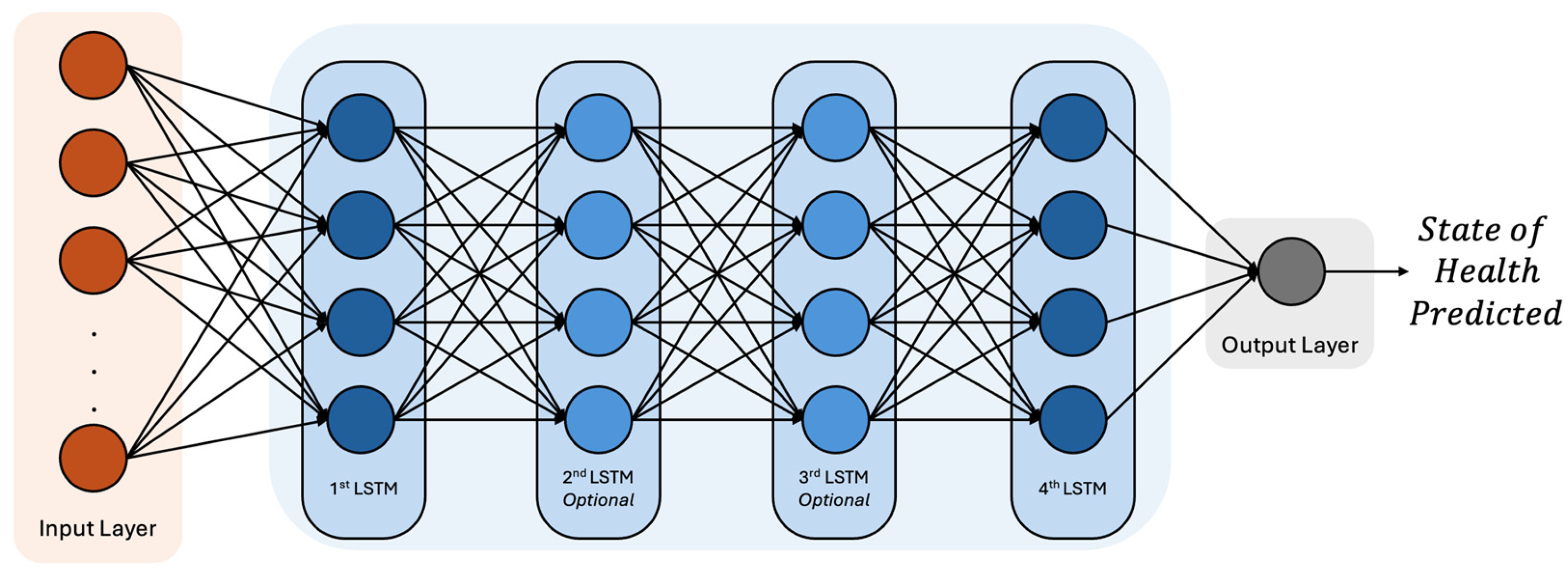
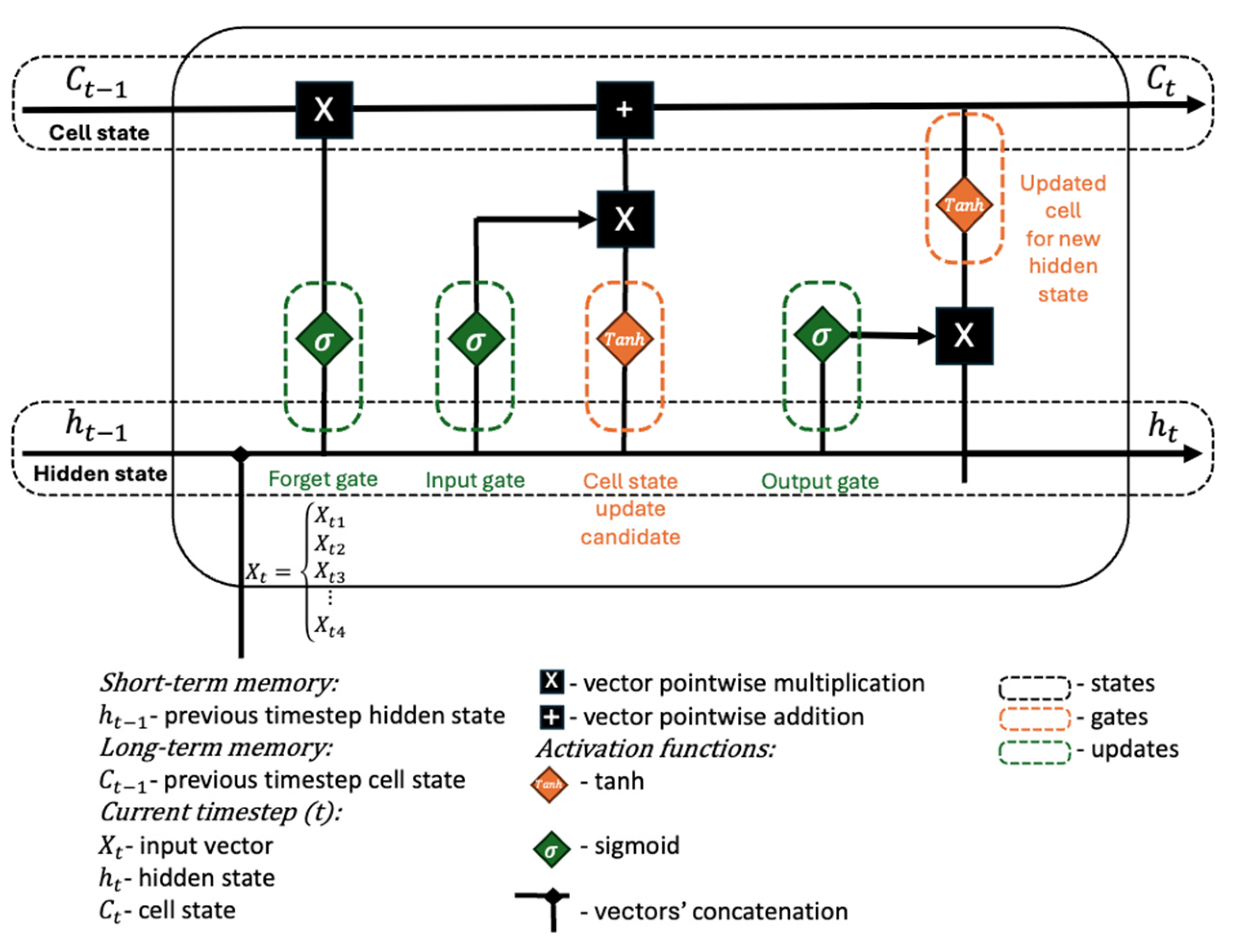
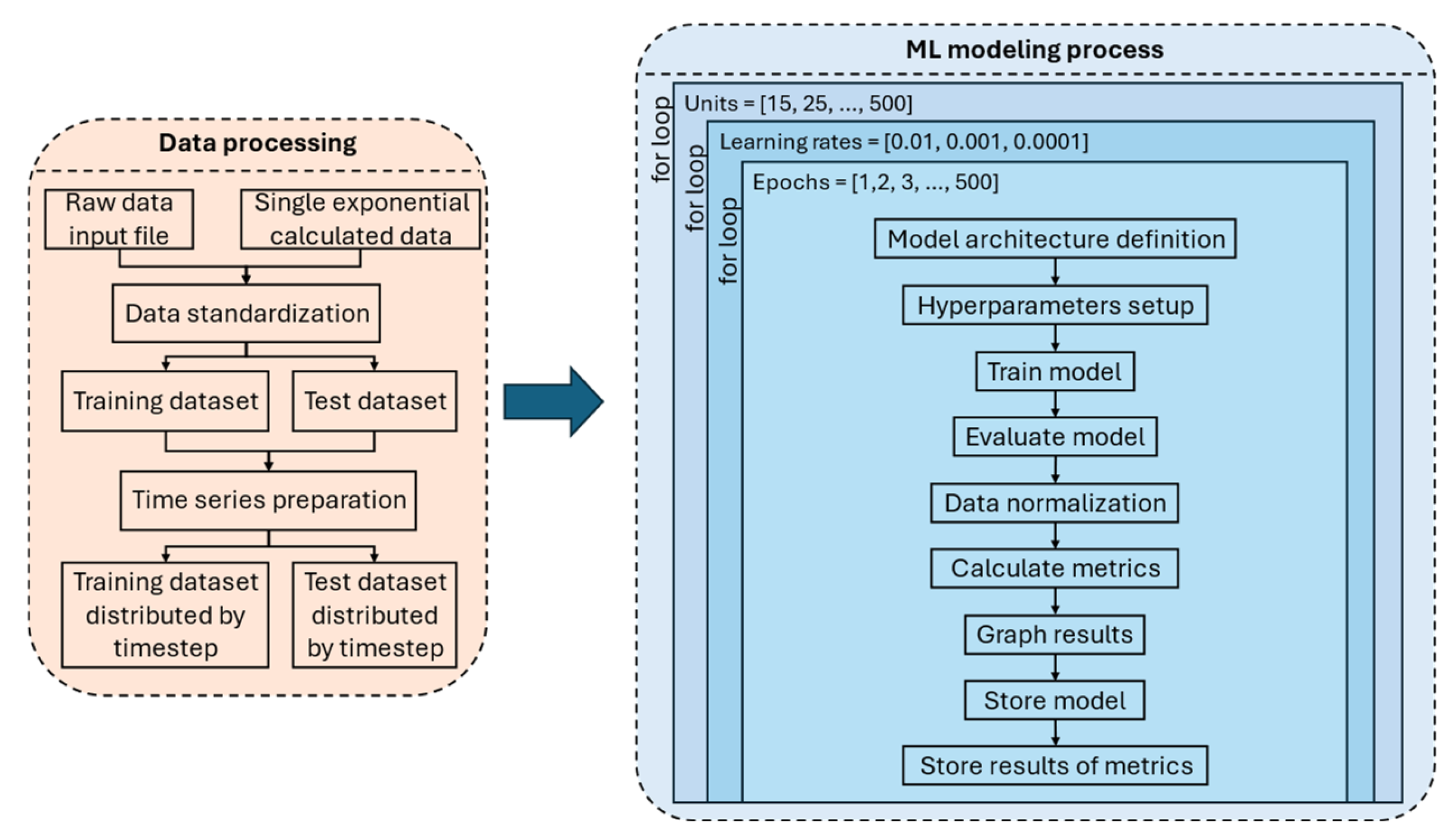
In this section, the performance of the trained LSTM-based models is analyzed, considering different architectural configurations and hyperparameter selections. The results demonstrate that the model successfully captures the temporal dependencies in battery degradation, leading to accurate SOH estimation and RUL predictions. Moreover, graphical representations of the predicted values obtained after training with NASA’s raw and SEM datasets versus actual SOH values show that the model follows the degradation curve with minimal deviation, validating its robustness. These findings underscore the potential of LSTM networks in battery health prediction applications and highlight the importance of hyperparameter optimization in enhancing predictive performance.
3.2. Comparative Analysis
In this section, a detailed analysis of the results obtained from the comparative evaluation of different ML algorithms and various experimental scenarios, as described in
Section 2, is presented. The primary objective of this comparative study is to assess the effectiveness of different ML-based approaches in predicting the SOH and estimating the RUL of lithium-ion batteries under diverse operating conditions. The analysis provides valuable insights into the performance, computational efficiency, and accuracy of each method in order to determine the most suitable model for battery health forecasting. The selection of the best-performing models was conducted by identifying those that achieved the lowest values in the MSE and RMSE metrics. These performance indicators were used as primary evaluation criteria to ensure the models exhibited the highest accuracy in predicting the SOH and RUL of the lithium-ion batteries. To illustrate the evaluation process, battery B0007 from the dataset [
37] has been selected as a representative example.
Table 3 presents the results obtained by varying the number of LSTM layers and the quantity of training records while keeping the number of units and learning rate constant across all tested configurations. Based on the evaluation metrics, the best-performing model for each hyperparameter combination was selected as the optimal configuration for that specific scenario. Consequently, the best model from each set of hyperparameter combinations was included in
Table 4, following this selection process.
Table 4 provides a comprehensive summary of the best metric results obtained after systematically evaluating all possible combinations of hyperparameters for each type of LSTM architecture tested in this study. The architectures considered include the simple, medium, and complex configurations, each varying in the number of layers and overall structural complexity. Additionally, the results are presented based on different quantities of training samples, allowing for a detailed analysis of how the amount of available data influences model performance. The hyperparameters tested in this evaluation, as previously detailed in
Section 2.2, include key factors such as the number of units per layer, the learning rate, and the number of epochs. By systematically exploring various hyperparameter settings across different architectures and training sample sizes, this analysis aims to identify the most effective model configuration for accurately predicting the SOH of the battery.
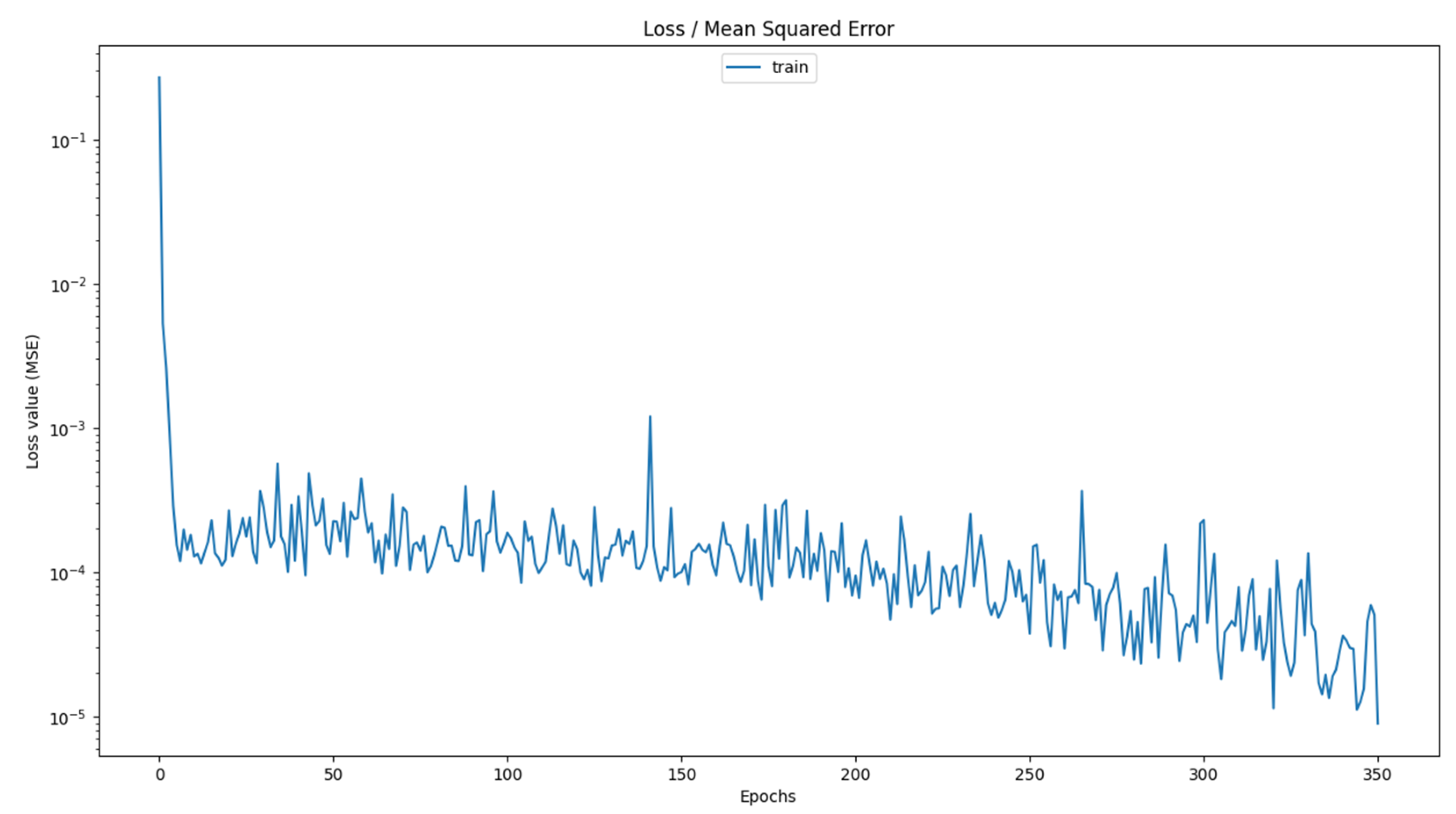
After analyzing the results, a detailed discussion regarding the operating scenario with EP can be conducted. It was observed that the best predictive performance was achieved when using the minimum quantity of training samples, which in this case consisted of 50 records. This finding highlights the potential of achieving accurate SOH estimation with a reduced dataset, which is particularly beneficial in practical applications where data collection may be limited or costly. Furthermore, across all scenarios that give the best performance, the optimal architecture consisted of only two LSTM memory layers. Additionally, it was found that the most effective models were those configured with a relatively small number of units per layer, reinforcing the idea that an excessively large network does not always yield superior results. Another critical observation from the results was that some of the best performing models do not require the full 500 epochs to converge. An example is shown in
Figure 5 in the case of the MLP scenario with three LSTM layers trained with SE (the Y axis is on a logarithmic scale).
The same methodology described previously was applied to the MLP and AP scenarios to analyze model performance across different stages of battery degradation. In the case of MLP, it was observed that most of the best-performing models were obtained using four LSTM layers. Additionally, the optimal learning rate remained consistent at 0.001 across all tested configurations. All the models in this scenario required the full 500 epochs for training. Another notable observation is that the number of units per layer remained relatively small in most cases, with only one exception where a higher number of units was used. For the AP scenario, the best results were achieved using two LSTM layers, while the learning rate remained unchanged at 0.001, like the MLP case. A significant finding in this scenario is that all models demonstrated convergence and started to fit the data within fewer than 500 epochs. To ensure a consistent and equidistant selection of training records across the different prediction scenarios, the final chosen configurations corresponded to 50 records for EP, 80 records for MLP, and 110 records for AP. This structured approach allowed for a comprehensive comparison of performance at different battery life stages.
Figure 6 illustrates the relationship between different learning rates (0.01, 0.001, 0.0001) and the number of units (15, 25, 50, 100, 150, 200, 500) tested in the model training process. The size of each data point represents the RMSE metric obtained after testing, where larger points indicate higher RMSE values and lower performance, while smaller points correspond to better models. This graph was generated using all the results obtained from tests made in the EP and AP operating scenarios, where models were trained with 50 and 110 records, represented in blue and orange, respectively. The graph shows that the EP scenario exhibits a higher RMSE, likely due to the smaller amount of training data used. However, it is important to note that for models with 15, 25, and 50 units and a learning rate of 0.0001, the RMSE values were similar across both scenarios, indicating that the quantity of training records had minimal impact under these specific conditions.
The EP scenario explained before in
Section 2.1 is specifically considered for this assessment. As part of this analysis,
Table 5 presents a comprehensive summary of the key performance metrics for comparison according to the RDT and SEM scenarios for each of the LSTM architectures tested. These metrics serve as critical indicators of the model’s accuracy and reliability, allowing for a thorough comparison of the different approaches.
Table 5 provides a comparison of the performance of different models trained under varying conditions across all scenarios, including the simple, medium, and complex architectures. From the results presented, it is evident that the models trained using the SEM approach demonstrate superior performance when compared to those trained only on RDT data. This observation is consistent across all experimental setups, highlighting the advantage of incorporating a pre-processed degradation representation for improved predictive accuracy in battery SOH estimation. The SEM, by capturing the underlying degradation trend in a more structured manner, enhances the learning process of the ML models, leading to lower error metrics and a more reliable prediction capability. Another particularly noteworthy finding from the comparative analysis is that the simplest model architecture, which consists of only two LSTM layers, outperforms the more complex models in terms of predictive accuracy and overall performance. Despite the expectation that deeper architectures with additional layers might enhance the model’s ability to capture intricate dependencies in battery degradation patterns, the results indicate that increasing model complexity does not necessarily lead to better outcomes. Instead, the additional layers in the medium and complex architectures may introduce unnecessary complexity, leading to potential overfitting or difficulties in optimizing the learning process. This finding underscores the importance of selecting an appropriate model complexity to achieve optimal performance, rather than if larger and more sophisticated architectures inherently yield superior results.
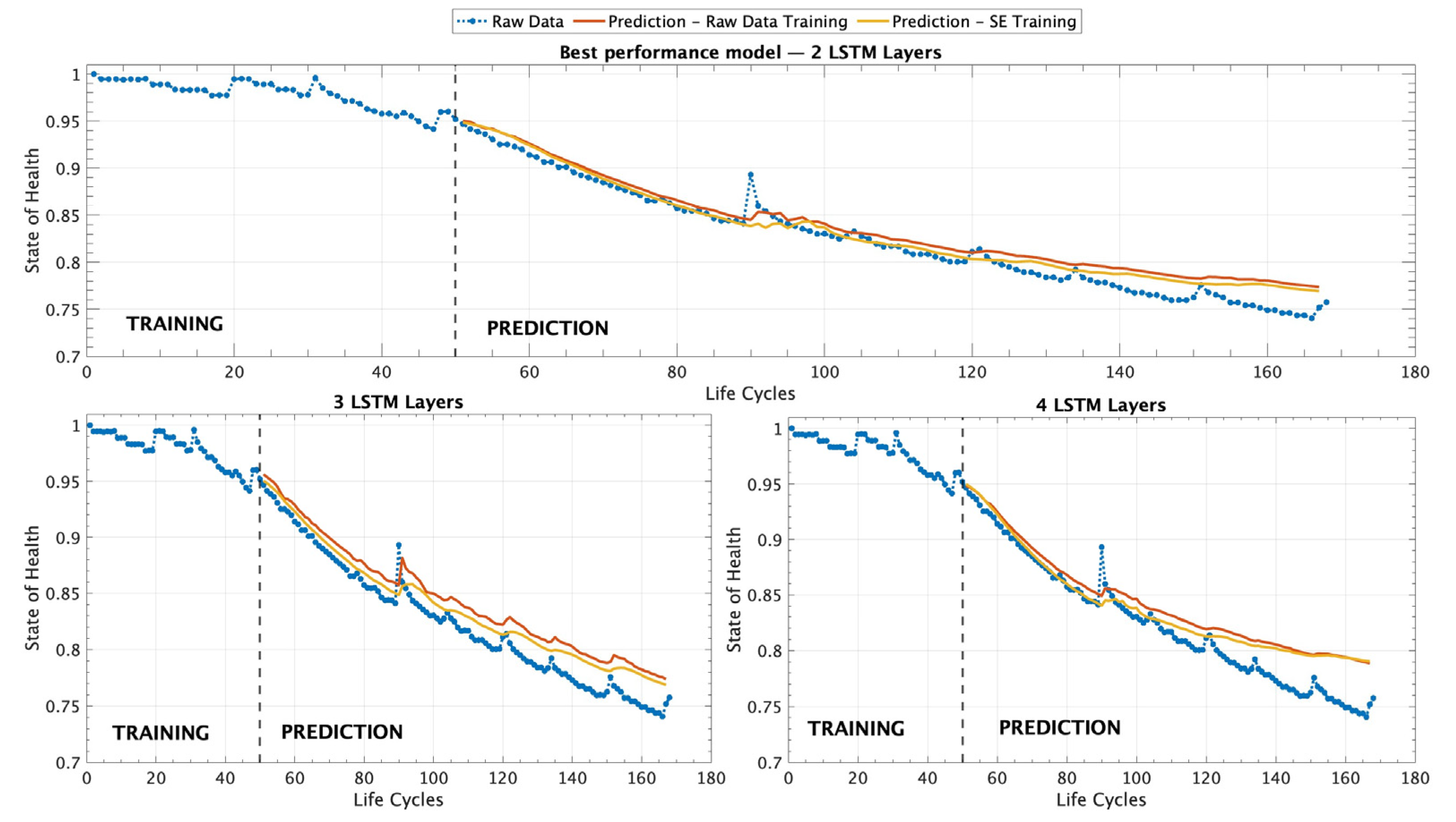
Figure 7 provides a comprehensive visualization of all the different experimental scenarios that were tested using the different ML models trained with a dataset containing only 50 records as an EP model.
Figure 7 presents a set of three graphical representations that illustrate the predictive performance of the different LSTM architectures tested in this study. The first graph, on top, corresponds to the model that demonstrated the best overall performance, which is composed of two LSTM layers. This architecture outperformed the other configurations in terms of accuracy and predictive capability, as evidenced by the evaluation metrics reported in
Table 5. The superior performance of this model suggests that a simpler structure with two layers is sufficient to capture the underlying patterns of battery degradation effectively. The second and third graphs in
Figure 7 correspond to the results obtained from models with three and four LSTM layers, respectively. However, the results indicate that while these deeper architectures were able to learn from the training data, they did not surpass the accuracy achieved by the two-layer model. The comparative analysis presented in
Figure 7 highlights the importance of selecting an optimal model architecture and hyperparameters that balance complexity and the generalization capability, ensuring that the predictive model remains both accurate and efficient for battery SOH estimation.
Table 6 presents the results obtained from the models trained using a dataset consisting of 80 records MLP, allowing for a more extensive learning process compared with the previous scenario with 50 training samples EP. The table provides a detailed comparison of the predictive performance of each tested architecture, highlighting key evaluation metrics that assess the accuracy and reliability of the SOH estimation. The inclusion of multiple architectures in the evaluation ensures a comprehensive understanding of the relationship between the number of layers, the network depth, and the overall model performance. Furthermore, the results contribute to determining the most effective model configuration for battery degradation forecasting.
Table 6 provides a clear comparison of the performance between the SEM and RDT training scenarios, demonstrating that the models trained with the SEM consistently achieve significantly better results. In this case, the most complex model, consisting of four LSTM layers, yields the lowest MSE and RMSE, indicating superior predictive accuracy and robustness in battery SOH estimation.
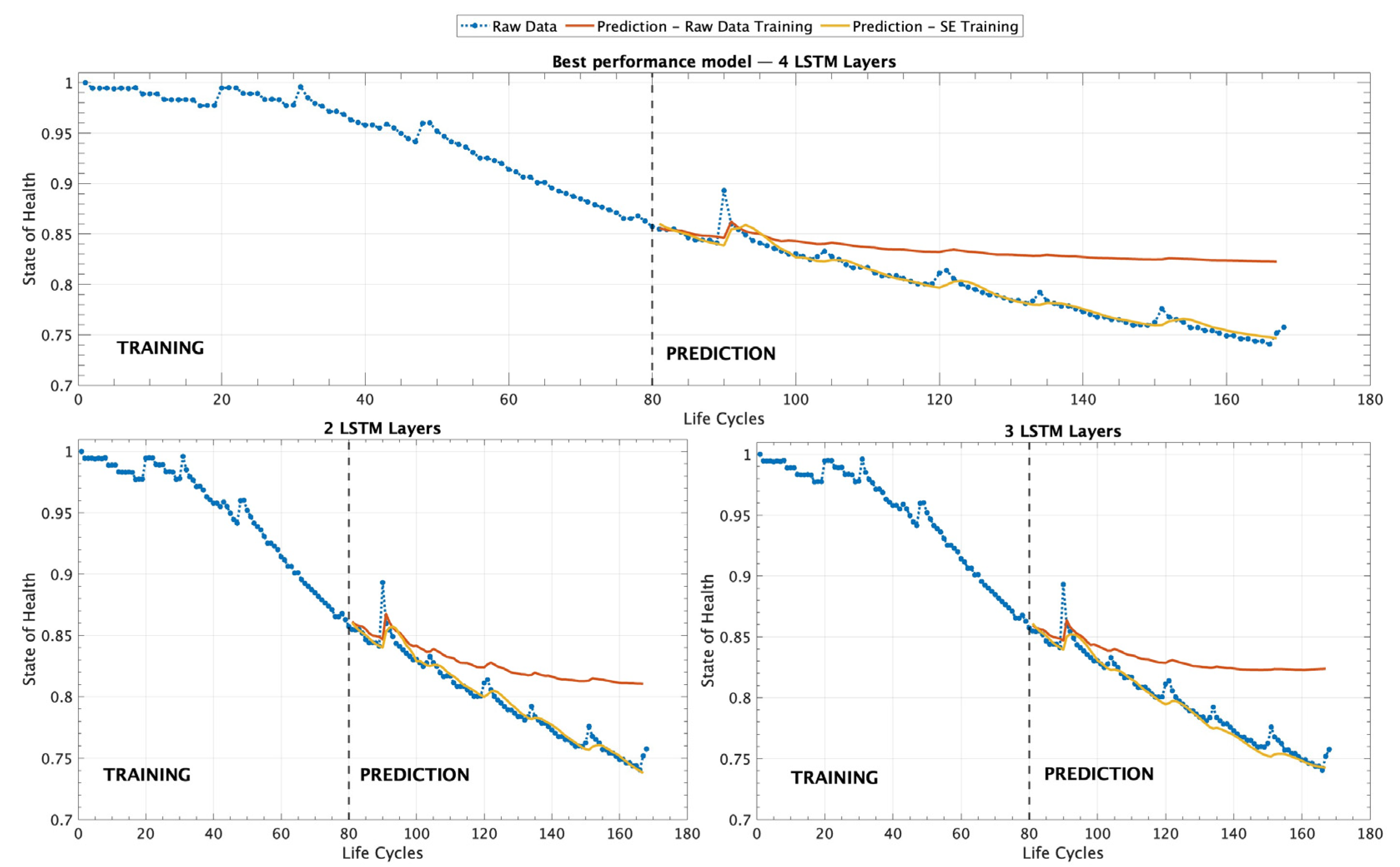
Figure 8 provides a detailed visualization of the different experimental scenarios analyzed, serving as a complement to
Table 6 by graphically representing the results. It illustrates the performance of different ML models trained with a dataset consisting of 80 records within the MLP operating scenario.
Figure 8 presents three different graphs that illustrate the performance of different ML models tested under the MLP scenario. The first graph, on top, corresponds to the model composed of four LSTM layers (complex), which demonstrated the best overall performance according to the evaluation metrics presented in
Table 6. This model exhibited the lowest MSE and RMSE, indicating its superior ability to accurately predict the SOH of the battery. The second and third graphs, located on the left and right sides of the figure, respectively, display the results obtained from models utilizing two and three LSTM layers.
Table 7 presents the results obtained for the various architectural models trained under the AP operating scenario, which was made using a dataset consisting of 110 records.
Table 7 presents a comprehensive comparison of the performance between the SEM and RDT training scenarios, highlighting that models trained using the SEM approach consistently achieve superior results. Notably, in this case, the simplest model, composed of two LSTM layers, demonstrates the best metrics, indicating enhanced predictive accuracy and robustness in estimating the SOH of the battery. To further illustrate these findings,
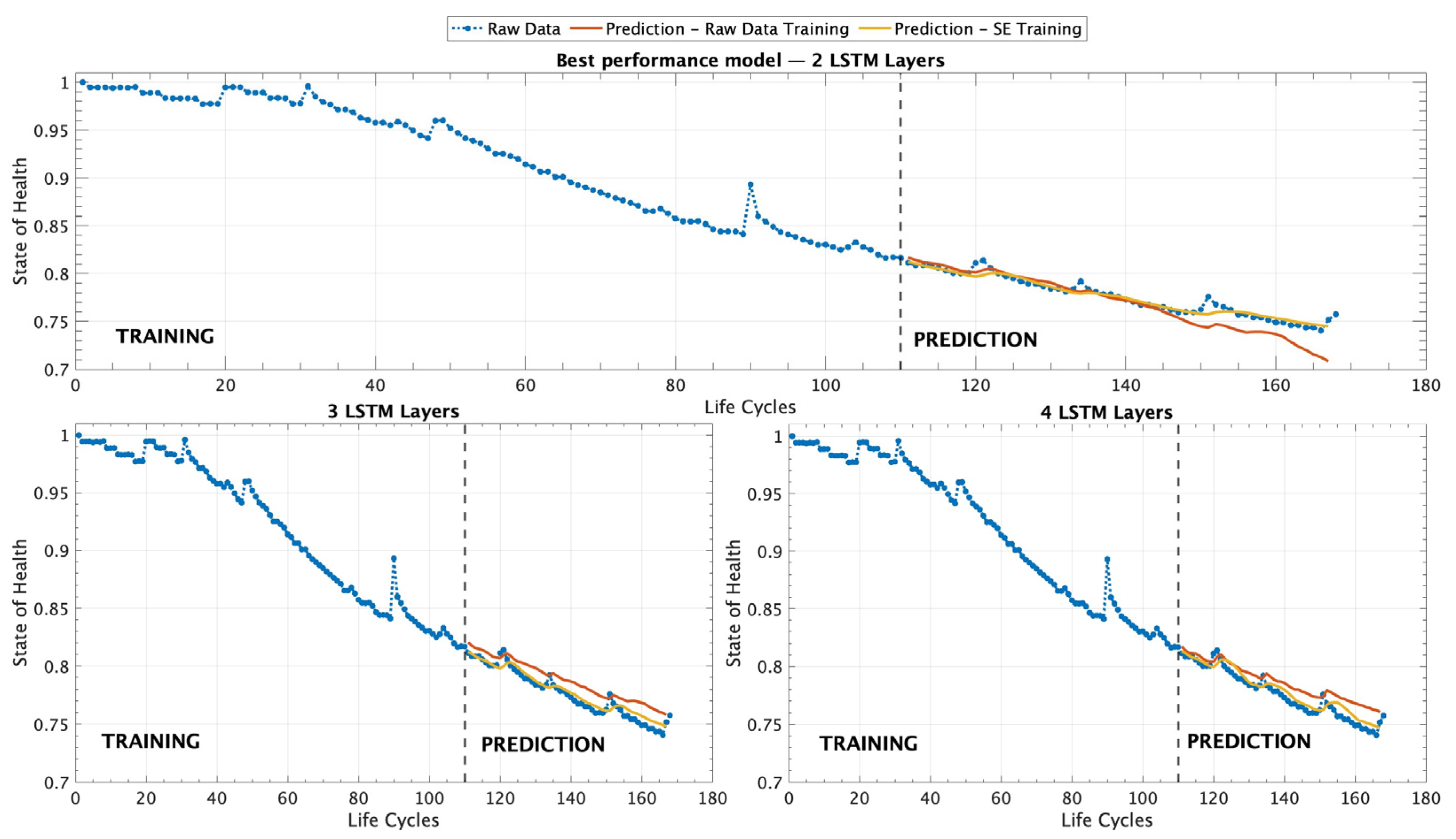
Figure 9 provides a detailed graphical representation of the different experimental scenarios analyzed. This figure serves as a visual complement to
Table 7, offering an intuitive depiction of the performance of various LSTM architecture models trained with a dataset containing 110 records within the AP operating scenario.
Figure 9 displays three graphs depicting the performance of the different models evaluated under the AP scenario. The top graph represents the model with two LSTM layers, which achieved the best performance based on the evaluation metrics in
Table 7. The graphs on the left and right illustrate the results obtained from models with three and four LSTM layers, respectively, providing a comparative view of their performance in estimating the state of health of the battery.
Figure 10 presents a comparative visualization of the best-performing models from each operational scenario. The EP scenario is displayed at the top, followed by the MLP scenario in the middle, and the AP scenario at the bottom. Across all scenarios, models trained using the SEM consistently outperform those trained with RDT, demonstrating superior predictive accuracy and stability. When considering only the evaluation metrics, the AP scenario, trained with the largest dataset of 110 records to predict approximately 60 future cycles, exhibits the most accurate performance. However, the MLP scenario, trained with only 80 records, also demonstrates highly reliable predictive behavior. In this scenario, it is important to highlight that the model trained with raw experimental data exhibited suboptimal performance. This outcome may be attributed to several factors, including the presence of higher noise levels in the data acquisition process, as it is derived from real-world conditions. Additionally, unaccounted variability within the dataset, such as fluctuations caused by environmental conditions, diverse operational scenarios, or inconsistencies in battery manufacturing, could further impact the model’s ability to generalize effectively. Additionally, the EP scenario, which corresponds to approximately 30 percent of the battery’s lifespan, provides a strong SOH prediction, highlighting the robustness of the proposed approach across different training conditions. As expected, the performance of the EP scenario, which was trained with 50 records, is weaker compared with the MLP and AP scenarios. The reduced amount of training data likely constrained the model’s ability to capture the underlying degradation patterns effectively, leading to higher MSE and RMSE values.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}