1. Introduction
In recent years, deep neural networks (DNNs) have achieved remarkable success across various computer vision applications, such as image classification [
1], object detection [
2], video analysis [
3], and semantic segmentation [
4]. The effectiveness of these networks is attributed to depth and width, resulting in complex computations and a substantial demand for storage units, which makes the models unsuitable for deployment on resource-constrained edge devices [
5]. Consequently, many researchers have proposed model compression methods, including network pruning [
6], knowledge distillation [
7], low-rank decomposition [
8], and quantization [
9]. Network pruning has become increasingly popular in real-time neural network deployment at the network edge because it maintains model performance without changing the original architecture and processes effectively with other compression techniques.
As a critical technique for selecting acceleration modes, network pruning is typically categorized into structured general-purpose pruning and unstructured custom pruning. Unstructured pruning operates by removing individual weights to reduce the number of parameters, aiming to create irregular sparse networks while minimizing accuracy loss [
10,
11]. However, irregular sparsity can disrupt memory access patterns, resulting in decreased efficiency during inference or training on hardware accelerators. Therefore, specialized hardware is required to achieve effective acceleration for unstructured pruning. In contrast, structured pruning targets specific components, allowing for acceleration on general-purpose platforms without the specialized hardware [
12]. For instance, filter pruning reduces model size by removing entire channels within network layers, but the loss of intrinsic components limits the performance improvement of the network [
13,
14]. More recently, stripe pruning, which is a finer-grained structured pruning method, has gained significant attention [
15,
16]. Stripe pruning avoids directly removing intrinsic components of the network and offers a more flexible pruning method through sparse selection compared to filter pruning. However, most existing stripe pruning methods concentrate on optimizing filter shapes and parameter selection but do not fully utilize the intra-filter information. Additionally, the stripe pruning methods typically impose global sparsity constraints during pruning, neglecting the adaptability between subnetworks and specific tasks, which will lead to diminished network performance.
The pruning criterion is another key factor for the effective implementation of network pruning [
17]. Commonly used pruning criteria include methods based on magnitude, norms, significance, and loss functions. Magnitude-based pruning [
18] assumes that parameters with smaller absolute values exert less influence on the network output, and the norm-based methods [
19] define specific rules, such as sparse
or
regularization [
20,
21] to evaluate the importance of parameters. Significance or sensitivity pruning [
22] ranks weights based on the respective contribution to the network, while loss-based methods [
23] assess the importance of weights by comparing changes in network loss with and without the weight. These methods offer different perspectives on determining which parameters or structures to prune, depending on the relative importance to the overall network performance. While single-criterion pruning is straightforward, the lack of flexibility still limits the complex information interactions within the neural network. Moreover, pruning criteria require significant parameter differences between important and unimportant filters. However, methods solely based on norm regularization or loss functions often fail to effectively drive the elements of the parameter matrix toward zero, resulting in suboptimal pruning performance.
Motivated by the works above, this paper introduces an information extraction-based sparse stripe pruning method (IESSP). IESSP utilizes internal network feature information to guide sparse feature extraction, integrating it with stripe selection to enhance both precision and efficiency in pruning. At a finer granularity, filters extract information using diverse shape matrices, which are then incorporated into the decision-making process of stripe pruning, improving the overall network performance. To address potential instability from excessive sparsity, we propose an adaptive sparsity training strategy. In contrast to the sole use of
and
regularization, this strategy incorporates feature information with task-specific
sparsity regularization, embedding it into the objective function for optimized sparsity selection. The difference between the layers of the proposed method and existing methods is depicted in
Figure 1. Through this approach, IESSP captures the relationship between training loss and sparsity configuration, enabling adaptive optimization. Experimental results on benchmark datasets demonstrate that IESSP outperforms existing techniques.
The major contributions of this paper are as follows:
Novel pruning method. We propose an information extraction-based sparse stripe pruning method (IESSP) that adaptively adjusts sparsity during training. By leveraging sparsity regularization, it guides filter stripe selection through information extraction. The method incorporates an information extraction module (IEM) to further enhance stripe selection by improving layer interactions and focusing the network on key patterns.
Novel loss function. We propose a novel loss function that introduces adaptive sparsity in neural networks by dynamically adjusting the sparsity of the filter skeleton through regularization. This approach strikes a balance between performance and compactness, enhancing feature selection efficiency and reducing redundancy while preserving model performance.
Extensive experiments. We conduct experiments across multiple datasets and architectures, comparing our method with state-of-the-art techniques to demonstrate its effectiveness.
The paper is organized as follows:
Section 2 reviews network pruning techniques and sparsity regularization methods.
Section 3 introduces the IESSP method and its efficient implementation using optimization algorithms.
Section 4 demonstrates the application of IESSP to various neural networks for image classification tasks on different datasets.
Section 5 concludes with a comprehensive summary.
3. Methodology
This section primarily focuses on the proposed sparse stripe pruning method. In
Section 3.1, we present the overall framework of the approach, along with a regularization method designed for sparse feature extraction. The proposed sparse training and IEM are illustrated in
Figure 2. In
Section 3.2, a
sparse training strategy is introduced to optimize the balance between network sparsity and feature extraction capabilities.
3.1. The IESSP Framework Architecture
This study introduces a novel approach that integrates feature information extraction and sparsity regularization. By incorporating a self-feedback mechanism, the method dynamically balances performance with sparsity, enabling the network to efficiently learn both compact and expressive representations. Central to this framework is the sparsity regularization term,
, defined as:
where
is the vector of the convolution kernel masks for layer
l.
where
K represents the kernel size, and
N denotes the number of filters.
represents the
-norm used to quantify the importance of filter stripes. By penalizing less significant elements, the regularization term induces selective sparsity, allowing the network to prioritize critical features during training.
To enhance flexibility, a mixed-norm formulation is introduced, defined as:
which eliminates ineffective stripes while preserving the model’s ability to capture essential features and maintain its predictive performance. However, sparsity regularization alone is insufficient to fully exploit feature interdependencies across layers.
To address this issue, we propose a novel pruning approach via a mask-based mechanism applied along the direction of the convolutional kernel shape (stripe direction), implemented in the information extraction module (IEM). Specifically, the IEM module utilizes the average mask shape from the previous layer to impose a special constraint on the filter shape of the subsequent layer. This approach ensures hierarchical balance across layers, achieving a more efficient pruning mechanism. Let us define the transformation of feature masks between consecutive layers. The feature mask of the current layer is used to modulate the feature mask of the next layer,
, by applying the average convolution kernel mask,
, derived from the previous layer. The equation for this interaction can be described as:
where
represents the mask of the
n-th filter in the previous layer, and
N is the total number of filters in that layer,
is the initial mask of the next layer. The formula for calculating the average convolution kernel mask
in Equation (
6) assumes that the kernel size
is the same across all layers.
During the training process, the convolution kernel masks are continuously updated. During inference, stripes are pruned in subsequent convolution operations when the mask values fall below a predefined threshold . This mechanism allows pruning to dynamically adjust based on the importance of each stripe within the network. To ensure consistency between pruning and shape optimization, we integrate the stripe statistics of all layers into the loss function as a constraint. This ensures that pruning aligns with inter-layer shape optimization, preventing pruning from disrupting the overall architecture’s performance.
3.2. Loss Function Design for Adaptive Sparsity Optimization
In contrast to traditional methods that rely on pre-training and over-parameterized networks, the proposed method directly learns from the original network. To emphasize the importance of individual stripes within each filter, it progressively constructs a more compact structure by identifying redundant components and incorporating convolution kernel masks. However, the introduction of these convolution kernel masks may affect network performance. To achieve a more compact and efficient structure while controlling the sparsity of the convolution kernel masks, we introduce regularization constraints into the optimization process. These constraints ensure that redundant features are reduced, while the performance of the network is preserved. The total training loss function is defined as follows:
where
denotes the parameters of the
L convolutional layers in the network. The cross-entropy loss,
, represents the difference between the predicted output and the true label,
denotes that the mask is updated with the network,
, where
is the output vector of the target network, and
denotes the weight coefficient. Additionally,
refers to the Heaviside step function,
represents the current loss value, and
represents the average loss value from the previous epoch.
To further enhance sparsity and optimize network performance, we refine the control over the convolution kernel masks by introducing additional regularization terms. These terms impose constraints on the sparsity of the convolution kernel masks, progressively forming a more compact structure. The optimization objective is defined as:
where
represents the stripe statistics of all layers, which serve as a constraint to ensure consistency between pruning and inter-layer shape optimization. The second part of the equation,
, represents the mixed regularization term applied to the masks. Here,
encourages sparsity in the convolution kernel masks, promoting the pruning of less important features, while
helps to smooth the mask values, ensuring that the model does not become excessively sparse in an unstructured manner. The combination of both regularization terms helps balance the pruning process by controlling the sparsity and smoothness of the kernel masks, thereby optimizing feature retention during pruning.
In this context, the weight coefficient plays a pivotal role in regulating the sparsity penalty applied to stripe significance. Networks that achieve an optimal level of sparsity tend to minimize loss more efficiently, demonstrating that compact network architectures can enhance computational efficiency across various tasks. However, when sparse networks underperform on specific tasks, it becomes crucial to moderate the sparsity process to balance task performance with network sparsity. The optimization process is further complicated by the interplay of multiple constraints, such as weight decay and the convolution kernel mask sparsity. This complexity often leads global sparsity techniques to converge more slowly, ultimately degrading performance. To address these challenges, the proposed method shifts away from a global sparsity learning approach for the convolution kernel masks and adopts an independent sparsity learning strategy. This targeted approach offers more effective optimization by addressing sparsity at a finer level. Unlike traditional methods that depend on empirically selected hyperparameters, the proposed approach dynamically adjusts the sparsity strength based on the evolving loss state during network training. This adaptive mechanism eliminates the need for manual hyperparameter tuning, enhancing both the flexibility and robustness of the training process. By balancing sparsity during training, the strategy ensures that the network achieves an optimal equilibrium between performance and sparsity at various stages. As training progresses, the sparsity level is adjusted based on internal feedback, enabling the network to achieve maximum compression while preserving performance. This dynamic adaptation not only improves computational efficiency but also reduces the risk of overfitting.
To further promote sparsity in the mask, the proposed method introduces an additional term into the loss function, specifically designed to encourage a more distinct sparse configuration. This penalty term imposes stricter constraints on the mask values, effectively promoting the suppression of less significant stripes. As a result, the model refines its feature selection process, producing a more compact and efficient representation of the underlying data. The penalty term not only helps eliminate redundant information but also maintains a balance between sparsity and performance, ensuring that critical features are preserved while minimizing redundancy. By guiding the optimization towards masks with minimal non-zero elements, this approach fosters the creation of a more sparse and interpretable model structure. Importantly, the penalty term ensures that the model maintains satisfactory performance without compromising its ability to capture essential patterns from the input data, thereby guaranteeing both efficiency and effectiveness. Furthermore, the proposed method integrates feedback during training, refining the calculation of cross-entropy and enhancing information exchange between layers. This improves the network’s robustness while ensuring the selection and representation of critical features, achieving a better balance between sparsity and performance. By combining feature integration with sparse regularization, the method not only improves model performance but also optimizes efficiency in practical applications.
4. Experiment
This section presents comprehensive experimental results to analyze the proposed IESSP method. Network pruning experiments are conducted on the CIFAR-10 dataset [
47], utilizing the single-branch network VGG-16 [
48] and multi-branch networks, including ResNet20, ResNet32, and ResNet56 from the ResNet family [
49]. Furthermore, compact models such as ResNet18 and ResNet34 were trained on the large-scale ILSVRC-2012 dataset [
50].
Table 1 provides comprehensive descriptions of the datasets and network architectures, along with the rationale for their selection. This ensures a fair and meaningful comparison with state-of-the-art methods, including PFEC [
24], FPGM [
30], NISP [
51], GAL [
52], HRank [
31], EACP [
53], SOKS [
45], and SWP [
43].
4.1. Datasets and Experimental Setup
For CIFAR-10, standard data augmentation techniques, including random cropping and horizontal flipping, were applied to enhance generalization. Training was conducted for 160 epochs using the stochastic gradient descent (SGD) optimization algorithm, with a momentum of 0.9, a weight decay of
, and a batch size of 64. The initial learning rate was set to 0.1 and reduced by a factor of 0.1 at the 80th and 120th epochs. To control the pruning process, the pruning threshold
was fixed at 0.05, according to the reference [
43]. The sparsity coefficient
was set to
.
For ILSVRC-2012, standard preprocessing techniques, such as random cropping and flipping, were applied during training, while a center crop of size was used for testing. The training spanned 90 epochs, with the initial learning rate starting at 0.1 and being reduced by a factor of 0.1 every 30 epochs. The same SGD optimization parameters—momentum of 0.9 and weight decay of —were utilized. Similar to CIFAR-10, the pruning threshold and sparsity coefficient were kept consistent at 0.05 and , respectively.
All models were implemented in PyTorch (version 2.3.0) and trained on NVIDIA RTX 4090 GPUs, with CUDA version 12.4. The GPUs were manufactured by NVIDIA and sourced from the USA. The smaller scale and lower resolution of CIFAR-10 make it an accessible but nontrivial benchmark for exploring the proposed pruning method, particularly for compact models. Conversely, the large scale and complexity of ILSVRC-2012 allow for a more comprehensive evaluation of scalability, feature extraction, and generalization capabilities across diverse categories. Key evaluation metrics, such as the number of model parameters, floating-point operations (FLOPs), and classification accuracy, were employed to assess model compression and performance. Consistent with existing methodologies, only top 1 accuracy was reported for CIFAR-10, while both top 1 and top 5 accuracies were included for ILSVRC-2012.
4.2. Comparison with Other Methods
In this section, to validate the effectiveness of the proposed method, IESSP is compared with other state-of-the-art compression methods on the CIFAR-10 and ILSVRC-2012 datasets. The comparative results are presented in
Table 4 and
Table 5.
Table 4 presents the results of applying IESSP to the VGG-16 model for the CIFAR-10 classification task and compares it with other state-of-the-art techniques. For methods like PFEC, which perform filter pruning using a regularization sparsity ratio factor, IESSP outperforms with an accuracy of 93.69% while compressing the model by a factor of 20. For methods like FPGM, which use geometric median-based importance determination, IESSP also excels in accuracy and compression rate, 6.7 times smaller than the compressed FPGM model while achieving improved accuracy. This is because IESSP targets internal filter redundancy at a finer granularity than filters, achieving good pruning results while maintaining task accuracy. Compared to stripe-wise pruning methods like SWP, IESSP enhances model performance in terms of accuracy and demonstrates further potential in model compression. In the case of kernel optimization methods like ASK, IESSP achieves a six-fold higher compression ratio while maintaining higher accuracy. This is because kernel optimization methods are designed for specific kernel shapes, neglecting the complex receptive fields required by the network. IESSP, on the other hand, does not restrict filter shapes, allowing the learning matrix to choose freely and preserving more receptive fields, resulting in improved performance. For methods like SOKS, which involve designing kernel shapes in groups, IESSP achieves a higher compression ratio than SOKS and performs better in accuracy, reaching 94.16%. In summary, IESSP retains high network compression ratios and maximizes network performance thanks to the richness of the learning matrix. Experimental results demonstrate that the IESSP method proposed in this paper shows superior performance in lightweight neural networks with simple structures and provides a method for deploying VGGNet structures on mobile devices.
Table 4 demonstrates the IESSP method’s impact on ResNet-20 and compares it with other state-of-the-art models. ResNet-20 is a lightweight network, and compressing this network can be challenging. Compared to the MIL method, IESSP compresses ResNet-20 by 40% of the original model while maintaining an accuracy of 91.27%, only 0.16% lower than MIL. Compared to pruning models using the geometric median method, FPGM, IESSP achieves a higher compression rate, compressing FLOPs by an additional 8.3 M and achieving 0.44% higher accuracy than FPGM. For the ASK method, which prunes models using specified kernel shapes, IESSP outperforms in compression rate, compressing by an additional 0.02 M FLOPs, though with 0.5% lower accuracy than ASK. In the case of SOKS, a method that uses groups to specify shapes, IESSP compresses more parameters than SOKS and exhibits better model performance, with an accuracy 0.5% higher than SOKS.
Table 4 demonstrates the impact of the IESSP method on ResNet-32 and compares it with other state-of-the-art pruning techniques. Compared to the MIL method, IESSP achieves a higher compression rate, reducing the model size while maintaining an accuracy of 92.84%, which is 2.12% higher than MIL. When compared to the SFP method, both of which use a soft filter pruning strategy, IESSP improves accuracy by 2.76%. FPGM, another established pruning method, results in a lower compression rate than IESSP and achieves an accuracy that is 0.53% lower. ASK, which prunes based on specified kernel shapes, is another competitive method, but IESSP achieves better accuracy, with an improvement of 0.65%, though its compression rate is slightly lower than ASK. Compared to the SOKS method, IESSP outperforms it in terms of accuracy, demonstrating the effectiveness of IESSP in balancing model size and predictive performance.
Table 4 showcases the impact of the IESSP method on ResNet-56 and compares it with other state-of-the-art models. ResNet-56 is a lightweight network, and compressing this network can be challenging. Compared to the PFEC method, IESSP compresses ResNet-56 by 61.3% of the original model while achieving an accuracy of 93.65%, surpassing MIL’s classification accuracy by 0.59%. Compared to the NISP method for model pruning, IESSP achieves a higher compression rate, compressing FLOPs by an additional 0.14 M and achieving 0.66% higher accuracy than NISP. Compared to the GAL method for model pruning, IESSP achieves a slightly lower compression rate by 0.04 M FLOPs but outperforms GAL in accuracy, achieving a 0.57% higher accuracy. Regarding the SWP method, which prunes models using filter skeleton search, IESSP excels in classification accuracy, compressing by 0.16 M FLOPs less than ASK but achieving 0.67% higher classification accuracy. For the ASK method, which prunes models using specified kernel shapes, IESSP outperforms in compression rate, compressing by 0.13M FLOPs more than ASK, and achieves 0.63% higher accuracy than ASK. In the case of SOKS, a method that uses groups to specify shapes, IESSP compresses 0.04 M fewer parameters than SOKS and exhibits better model performance with 0.57% higher accuracy than SOKS.
Table 5 presents the performance of the IESSP method on ResNet-18 and ResNet-34, comparing it with other state-of-the-art model compression techniques. ResNet-18, being a relatively lightweight network, faces challenges in maintaining high accuracy while compressing. Compared to the baseline, IESSP reduces the number of parameters in ResNet-18 by 48.25% and FLOPs by 56.59%, with only a 1.09% drop in top 1 accuracy, achieving 69.33%. Compared to the MIL method, IESSP not only achieves a significant improvement in compression rate but also retains high performance, with a 0.56% increase in top 1 accuracy. When compared to the SFP and FPGM methods, IESSP shows similar compression rates but higher accuracy, particularly surpassing FPGM by 0.99% in top 1 accuracy. Additionally, in comparison with the SOKS method, while IESSP compresses parameters 0.22M less than SOKS, its top 1 accuracy improves by 0.57%, demonstrating its advantage in balancing compression and accuracy. For ResNet-34, IESSP also performs impressively. Compared to the baseline, IESSP achieves a significant advantage in compression, reducing the number of parameters by 53.90% and FLOPs by 58.96%, while maintaining a top 1 accuracy of 73.18%, only a 0.83% drop from the baseline’s 74.01%. Compared to the PFEC method, IESSP improves top 1 accuracy by 1.01%, showing excellent performance despite a slightly lower compression rate. Compared to the ASK method, IESSP not only excels in compression rate, reducing parameters by 42.98% and FLOPs by 42.66%, but also improves top 1 accuracy by 0.57%. In comparison with the NISP method, IESSP compresses FLOPs further while maintaining a high top 1 accuracy of 73.18%, demonstrating its robust compression capability in large-scale networks.
The comparative results indicate that the IESSP method can significantly reduce network redundancy while maintaining network performance, making it applicable to both large models and lightweight models, as well as multi-branch networks.
4.3. Ablation Studies
This section presents a comprehensive analysis of the impact of various hyperparameters on model training and the resulting pruning outcomes. Through ablation experiments, this paper explores the impact of adjusting specific hyperparameters on the training process and pruning strategy. By examining these factors in detail, the experiments aim to provide insights into optimizing the balance between model accuracy and computational efficiency.
4.3.1. Impact of Different Threshold
The pruning threshold
is a critical factor in selecting stripe features and plays a key role in regulating sparsity effectively [
43]. An excessively high threshold may lead the model to misclassify important features as redundant, thereby diminishing its representational capacity. Conversely, a threshold that is too low may fail to adequately eliminate redundant structures, limiting the effectiveness of pruning.
In the experiments conducted on the CIFAR-10 dataset, the VGG-16 model was used as the baseline for image classification, systematically exploring the impact of varying pruning thresholds. As shown in
Table 6, the IESSP method yielded different pruning outcomes at different threshold levels. Notably, with a threshold of 0.03, the model efficiently identifies and removes redundant components, achieving an accuracy of 94.16%, while reducing the parameter count by a factor of five and cutting FLOPs by 50%.
However, as the threshold increases, excessive sparsity begins to degrade classification accuracy, even though network compression continues to improve. These results highlight the delicate balance required in selecting an optimal pruning threshold for model performance. While aggressive pruning can significantly reduce the model size and computational demand, there is a critical threshold beyond which further compression results in diminishing returns on accuracy. This underscores the importance of a balanced pruning approach, one that minimizes model size while maintaining or enhancing performance. Considering the impact of different pruning thresholds on the model, the thresholds for all other layers are uniformly set to 0.05.
In conclusion, the findings emphasize the need for careful tuning of the pruning threshold to achieve the right balance between efficiency and accuracy. This balance is especially crucial in applications where both computational resources and model performance are paramount, such as in mobile or edge devices.
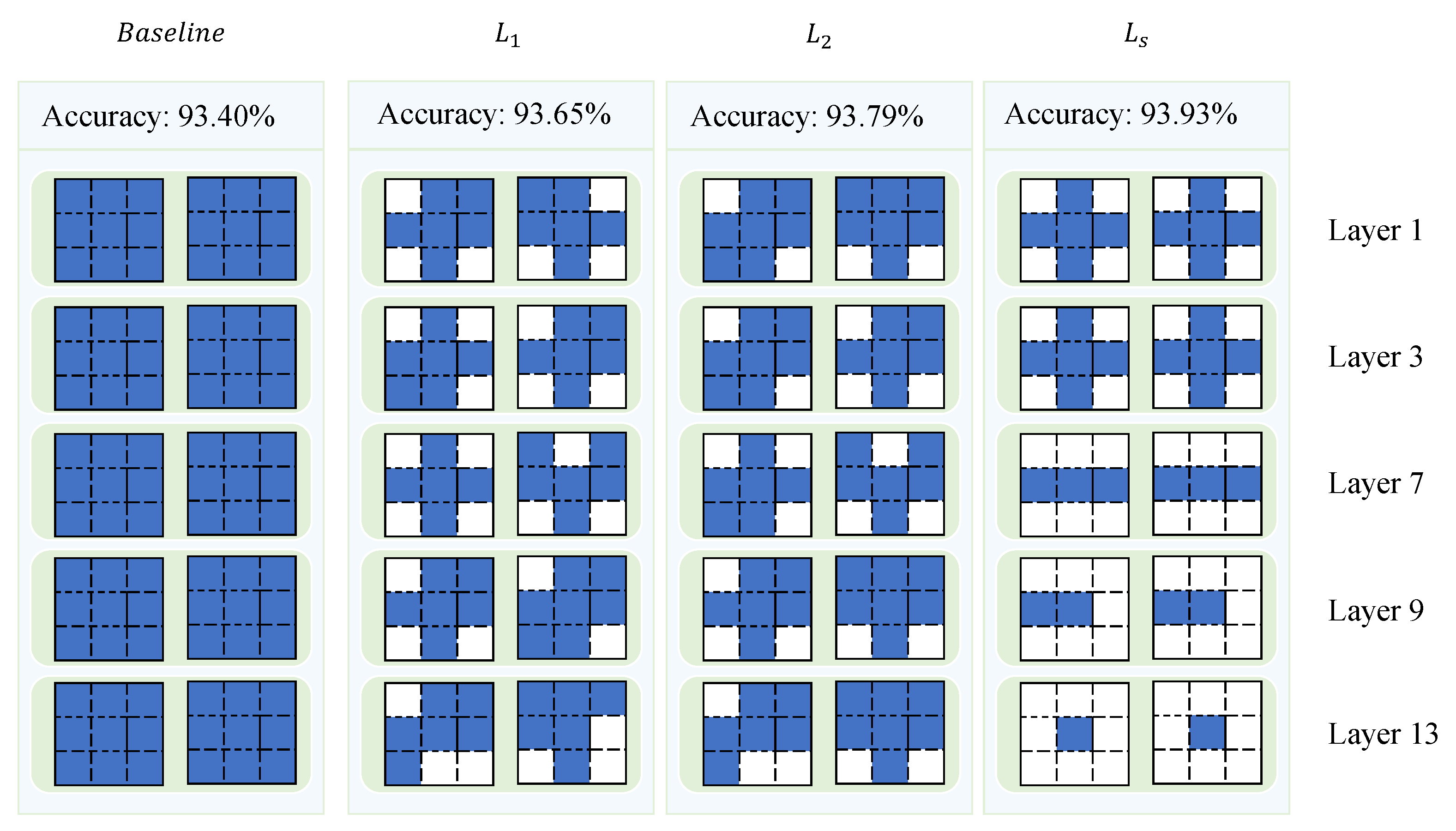
4.3.2. Impact of Different Regularization
To evaluate the effectiveness of the proposed hybrid regularization method, we conducted an ablation study comparing its performance to that of
and
regularization. The experiments were carried out on the VGG-16 model using the CIFAR-10 dataset, with a pruning threshold
of 0.05 and a regularization strength
of
for all methods, as shown in
Table 7. The results revealed that
regularization achieved a classification accuracy of 93.69%, while
regularization yielded a marginally higher accuracy of 93.79%. In contrast, the hybrid regularization method, which combines the advantages of both
and
regularization, achieved the highest accuracy of 93.93%. This demonstrates that the hybrid regularization approach provides a consistent, albeit modest, improvement in classification performance over the traditional
and
methods. Overall, the findings suggest that the hybrid regularization method strikes a better balance between sparsity and feature retention, leading to enhanced model efficiency and generalization without compromising performance.
4.3.3. Impact of Information Extraction Module
To evaluate the effectiveness of the proposed information extraction module (IEM), we conducted an ablation study comparing the compression results and performance of models with and without the IEM module. The experiments were carried out on the CIFAR-10 dataset, using both the VGG-16 and ResNet-56 models. A pruning threshold of 0.05 and a regularization strength of were used in the experiments.
As shown in
Table 8, the inclusion of the IEM module leads to a reduction in both the number of parameters and computational complexity while maintaining the model’s accuracy. Specifically, for the VGG-16 model, the IEM module achieves the same accuracy as the baseline model but reduces the number of parameters from 1.28 M to 0.81 M and decreases FLOPs from 106.82 M to 75.73 M, demonstrating a notable improvement in compression efficiency.
Similarly, for the ResNet-56 model, the IEM module slightly improves accuracy from 93.61% to 93.65%, while reducing the number of parameters from 0.39 M to 0.35 M, and achieving a minor reduction in FLOPs from 49.5 M to 49.2 M. These results highlight the ability of the IEM module to effectively maintain or even enhance model performance, while significantly improving the compression rate, particularly in terms of parameter reduction.
Overall, the inclusion of the IEM module demonstrates its capacity to balance information flow within the network, making it a valuable component for improving both the compression performance and efficiency of deep neural networks. The results underscore its effectiveness in enhancing model sparsity without compromising performance.
4.4. Network Visualization
Deep neural networks (DNNs) have achieved revolutionary success in computer vision, demonstrating outstanding performance across a wide range of tasks. However, their “black-box” nature presents significant challenges for both research and practical deployment. To address these challenges, visualization techniques have become essential tools, enabling detailed inspection of the network’s internal workings, performance evaluation, and a deeper understanding of the features learned during training.
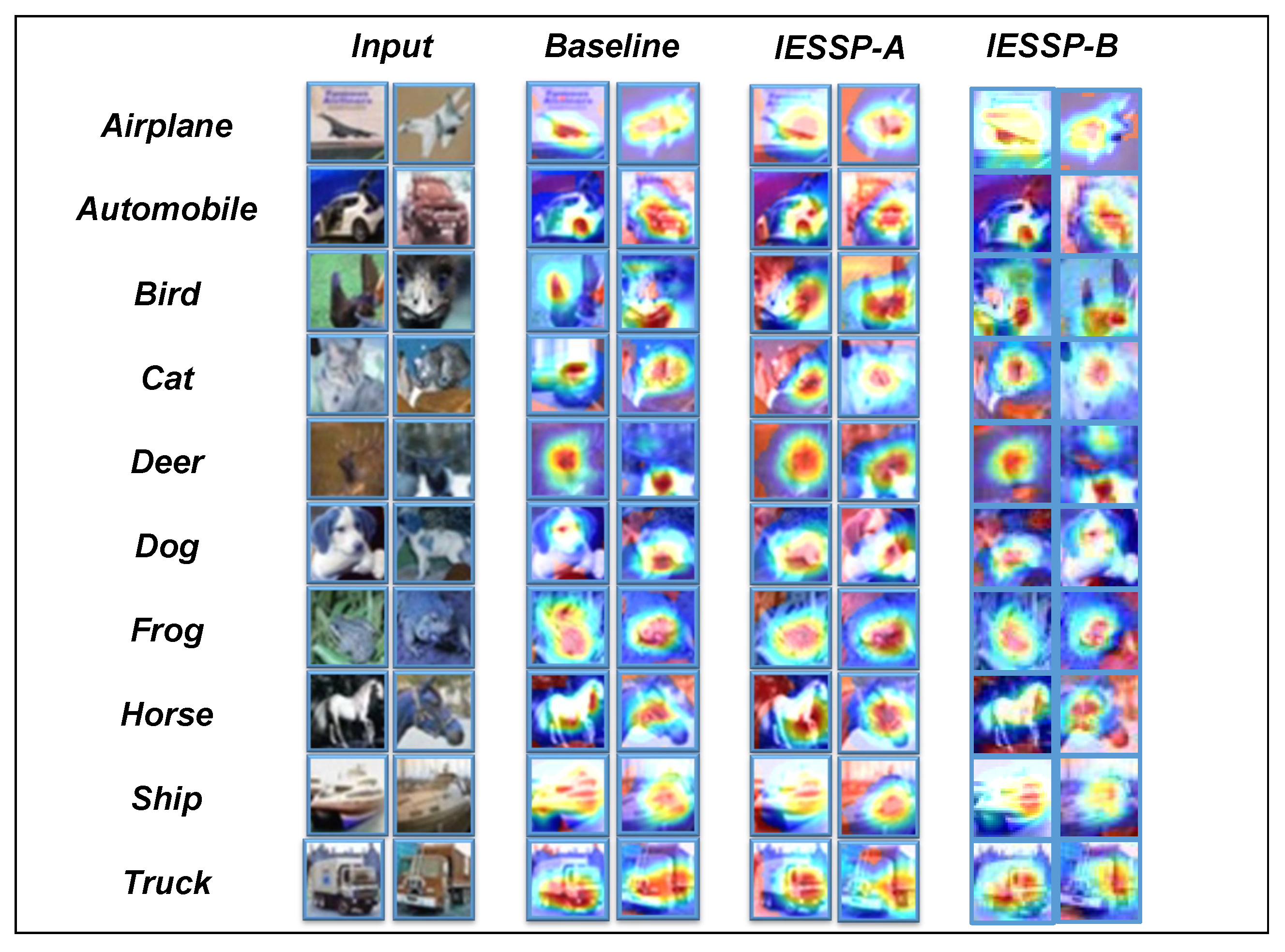
In this study, we introduce Class Activation Maps (CAMs) [
60] as the primary visualization method for analyzing pruned networks. A CAM is an effective technique for exploring the decision-making process of networks in image classification tasks. By highlighting the regions of the input image that most significantly influence the network’s predictions, CAM provides an in-depth analysis. As demonstrated in
Figure 4,
Figure 5 and
Figure 6, the CAM visualizations on the CIFAR-10 dataset show that the pruned network focuses on the most relevant regions for classification.
Although this section is primarily qualitative, our experimental observations reveal that for instances within the same category, the network consistently activates similar regions of the image. Specifically, we observed that samples from different models concentrate on similar regions of the image, indicating that, despite the pruning process, the network retains its ability to extract important features effectively.
In conclusion, the use of CAM not only validates the effectiveness of the proposed pruning method but also provides valuable insights into the internal workings of the network, contributing to a deeper understanding of neural network operations and advancing future developments in network design and performance optimization.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}