
Real-Time American Sign Language Interpretation Using Deep Learning and Keypoint Tracking





Abstract
1. Introduction
- Developed a real-time AI-driven ASL interpretation system capable of accurately spelling out names and locations through hand gesture recognition.
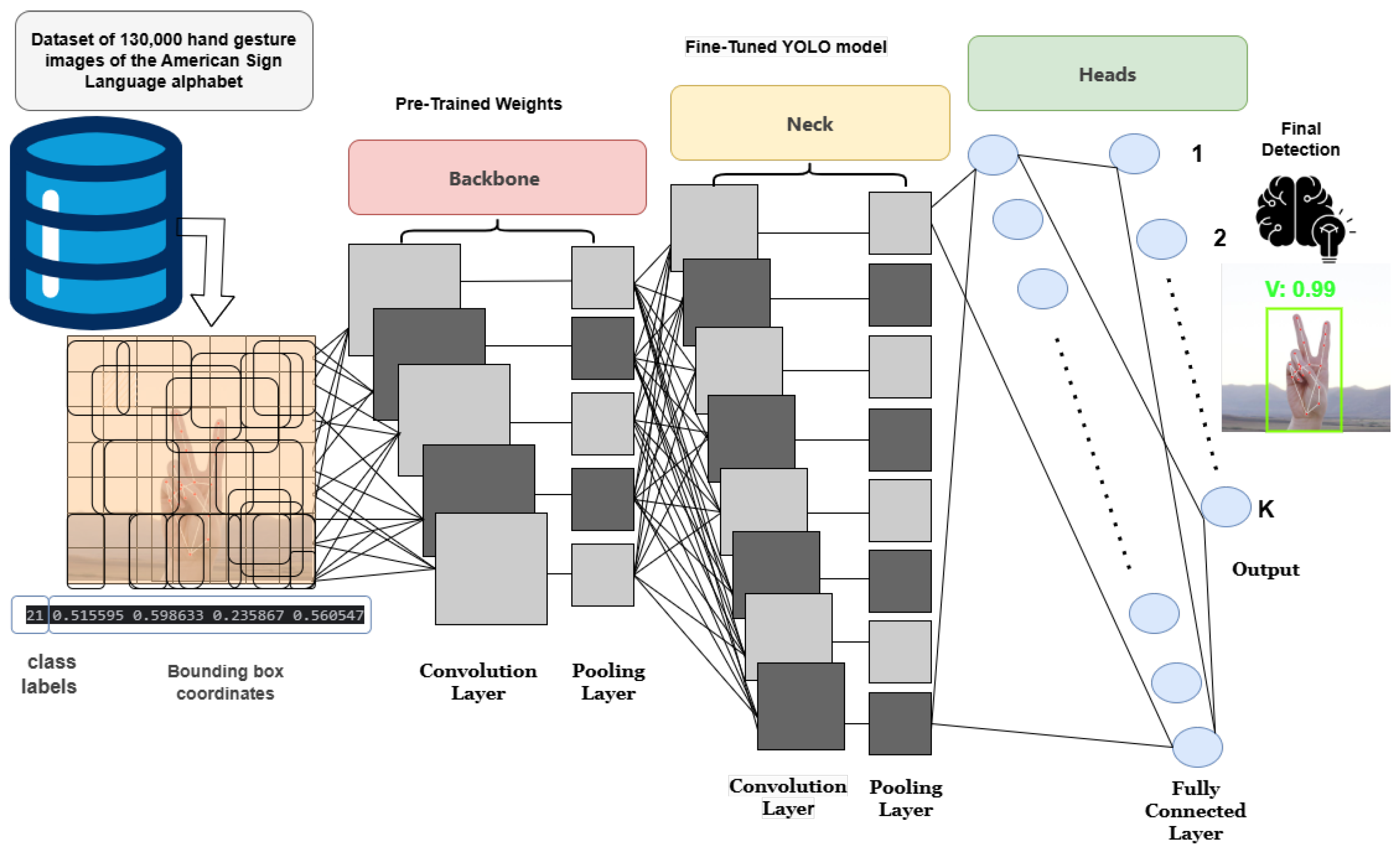
- Integrated YOLOv11 for gesture detection and MediaPipe for hand tracking, ensuring both high accuracy and fast inference speeds.
- Implemented keypoint-based annotation techniques to enhance the model’s ability to capture subtle variations in finger positioning, improving classification precision.
- Utilized a standard built-in webcam as a vision-based optical sensor for gesture data acquisition, demonstrating the system’s practical application in real-time human–computer interaction and AI-driven assistive technology.
- Achieved an impressive 98.2% mean Average Precision (mAP@0.5), demonstrating the system’s reliability in recognizing ASL letters.
- Curated and processed a large-scale dataset of 130,000 ASL hand gesture images, each annotated with 21 keypoints to enhance model learning and generalization.
2. Background
2.1. Transfer Learning
2.2. YOLO
2.2.1. Detection Pipeline
2.2.2. Bounding Box Prediction
- (x, y): Center coordinates of the object.
- (w, h): Width and height relative to the image size.
- Confidence Score: Probability of an object being present.
2.2.3. Class Prediction
2.2.4. Non-Maximum Suppression (NMS)
2.2.5. Final Output
2.3. MediaPipe
2.3.1. BlazePalm Detector
2.3.2. Hand Landmark Model
2.3.3. Keypoint Representation
- represents the i-th keypoint.
- are the normalized coordinates within the range .
3. Related Work
4. Methodology
4.1. Dataset Description
- Different lighting environments: bright, dim, and shadowed.
- Various backgrounds: natural outdoor settings and indoor scenes.
- Multiple angles and hand orientations for robustness.
- Training set: 80%.
- Validation set: 10%.
- Testing set: 10%.
4.2. Data Preprocessing
- Auto-orientation: Ensuring the correct alignment of images regardless of the original orientation.
- Resizing: Standardizing all images to 640 × 640 pixels for consistency.
- Contrast adjustment: Enhancing visual clarity using contrast stretching.
- Grayscale conversion: Applied to 10% of images to improve robustness to color variations.
4.3. Data Augmentation
- Flipping: Horizontal and vertical flips to introduce diverse orientations.
- Rotation: Random variations between −10° and +10° to simulate natural hand positioning.
- Brightness adjustment: Random modifications within ±15% to accommodate lighting variations.
- Grayscale conversion: Selectively applied to certain images to enhance the model’s focus on gesture structure.
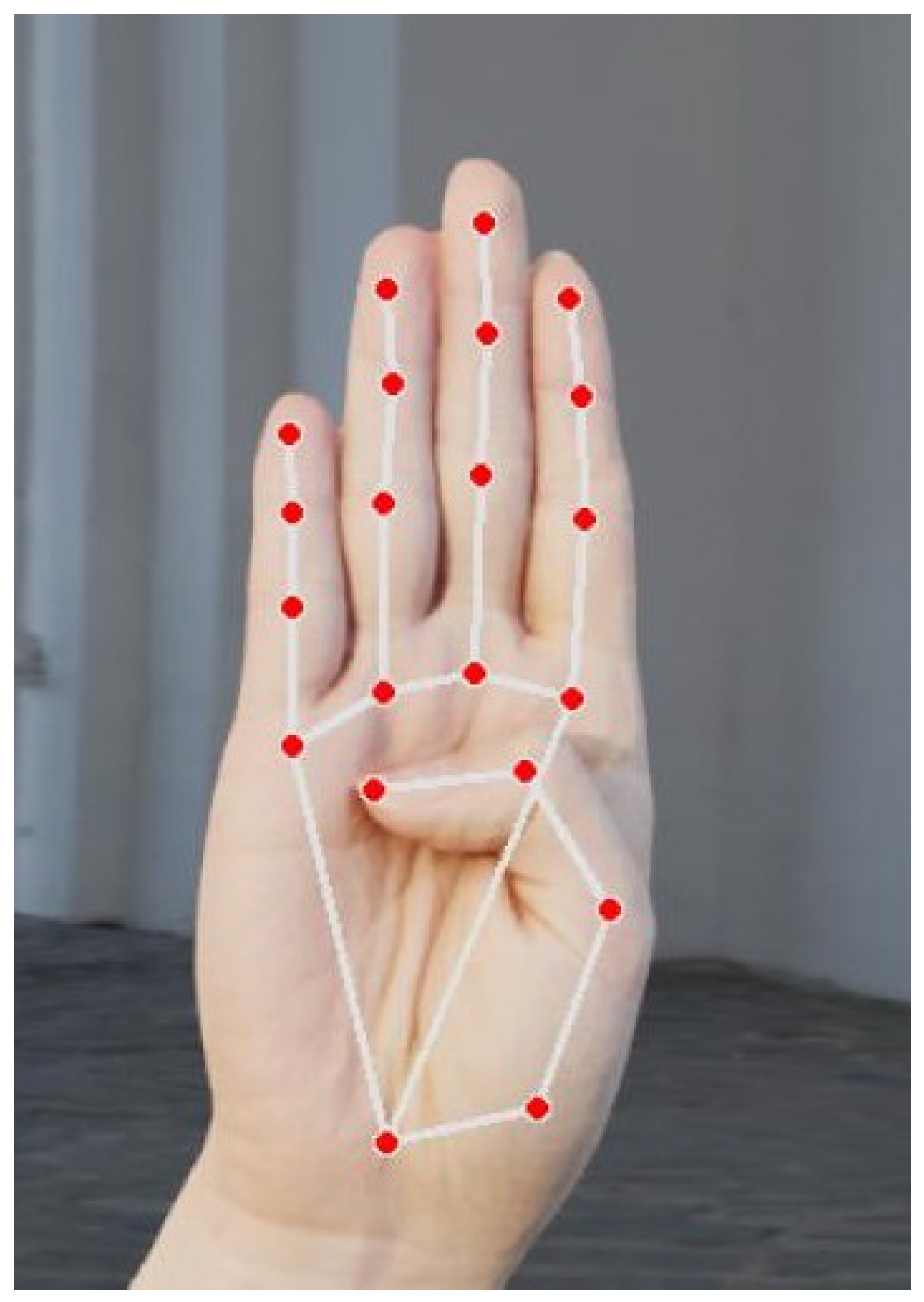
4.4. Data Annotation
- Hand Landmark Detection:
- MediaPipe extracted 21 keypoints corresponding to joints and finger positions of the hand.
- The detected keypoints were scaled and normalized to maintain consistency across varying image resolutions.
- Bounding Box Calculation:A bounding box was generated to enclose only the 21 keypoints that were previously captured on the hand by determining the minimum and maximum coordinates from the extracted keypoints.
4.4.1. Bounding Box Computation
Finding the Bounding Box Extent
Computing Bounding Box Dimensions
Determining the Bounding Box Center
Normalization for YOLO Format
4.4.2. Annotation Format for YOLO
- Class Label: An integer (0–25) representing the ASL letter.
- 21 Keypoint Coordinates: Normalized values stored aswhere represents the i-th keypoint, and are in the range [0, 1].
- Bounding Box: Stored in the YOLO format as
4.4.3. Data Balancing
5. Results and Discussion
5.1. Model Performance and Evaluation Metrics
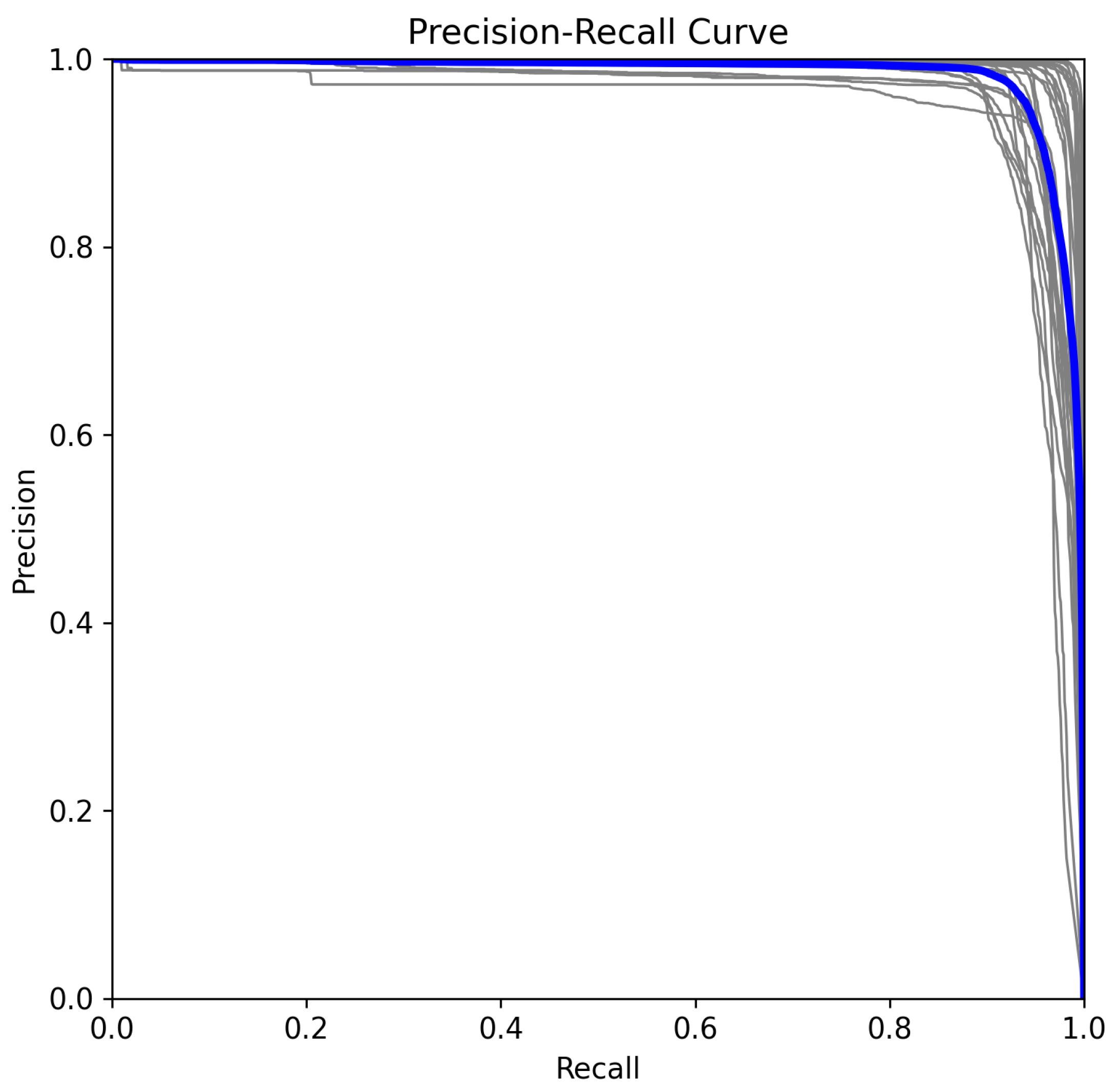
5.2. Precision–Recall Analysis in Multiclass Classification
- (True Positives): Correctly classified instances of class c.
- (False Positives): Instances incorrectly classified as class c.
- (False Negatives): Instances of class c that were misclassified.
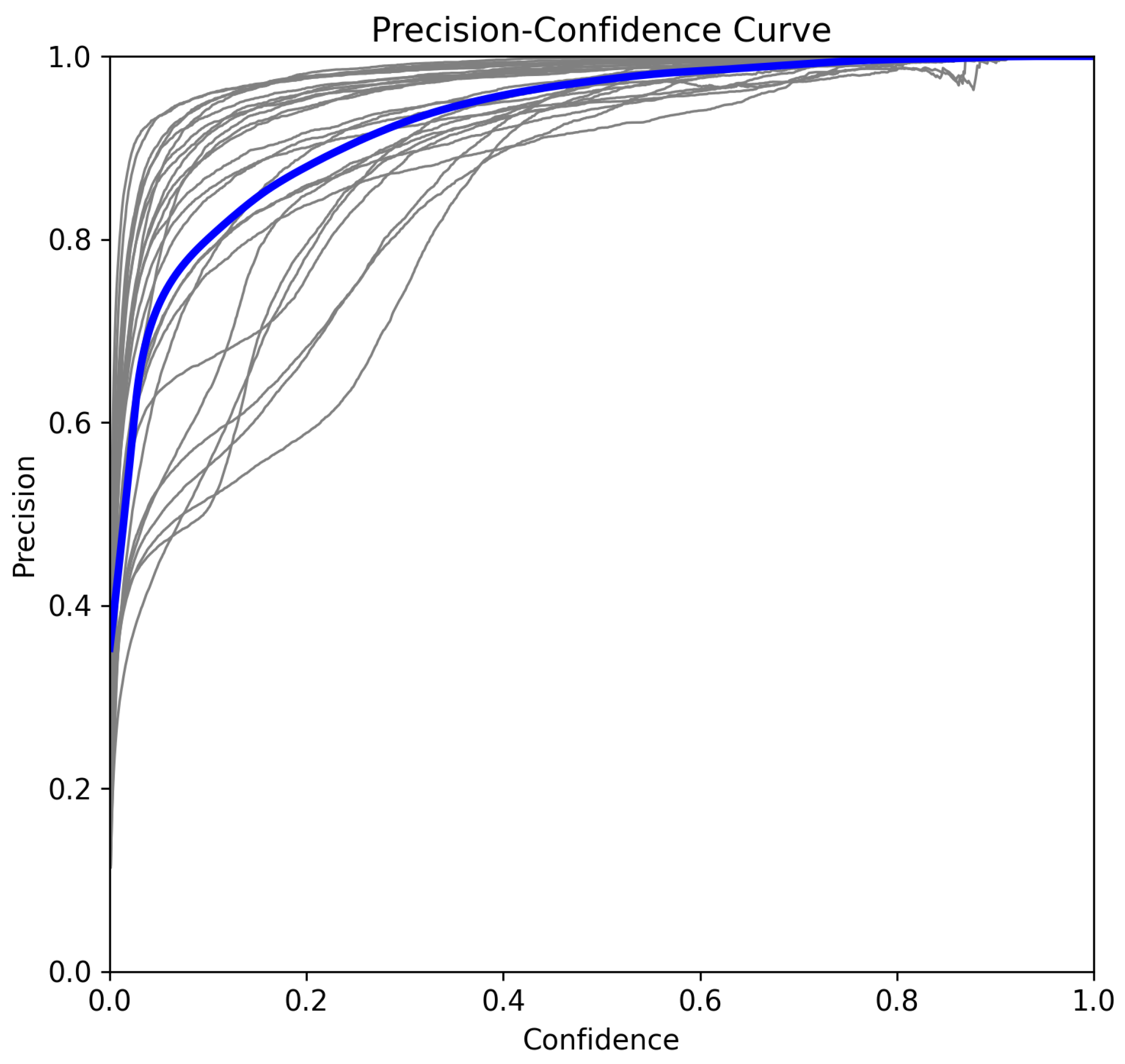
5.3. Confidence-Based Evaluations for Multiclass Classification
5.3.1. Recall–Confidence Curve
5.3.2. Precision–Confidence Curve
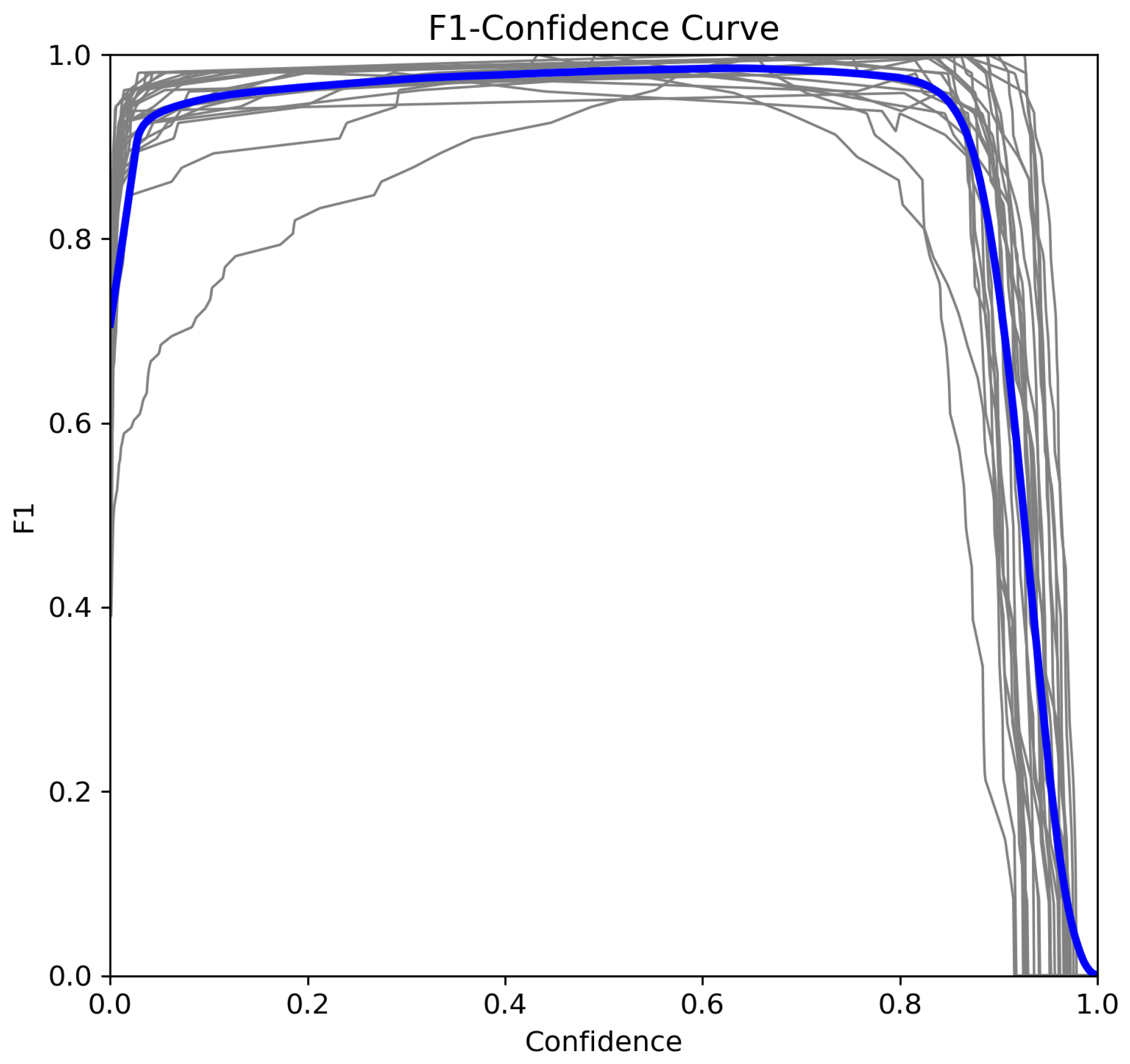
5.3.3. F1–Confidence Curve
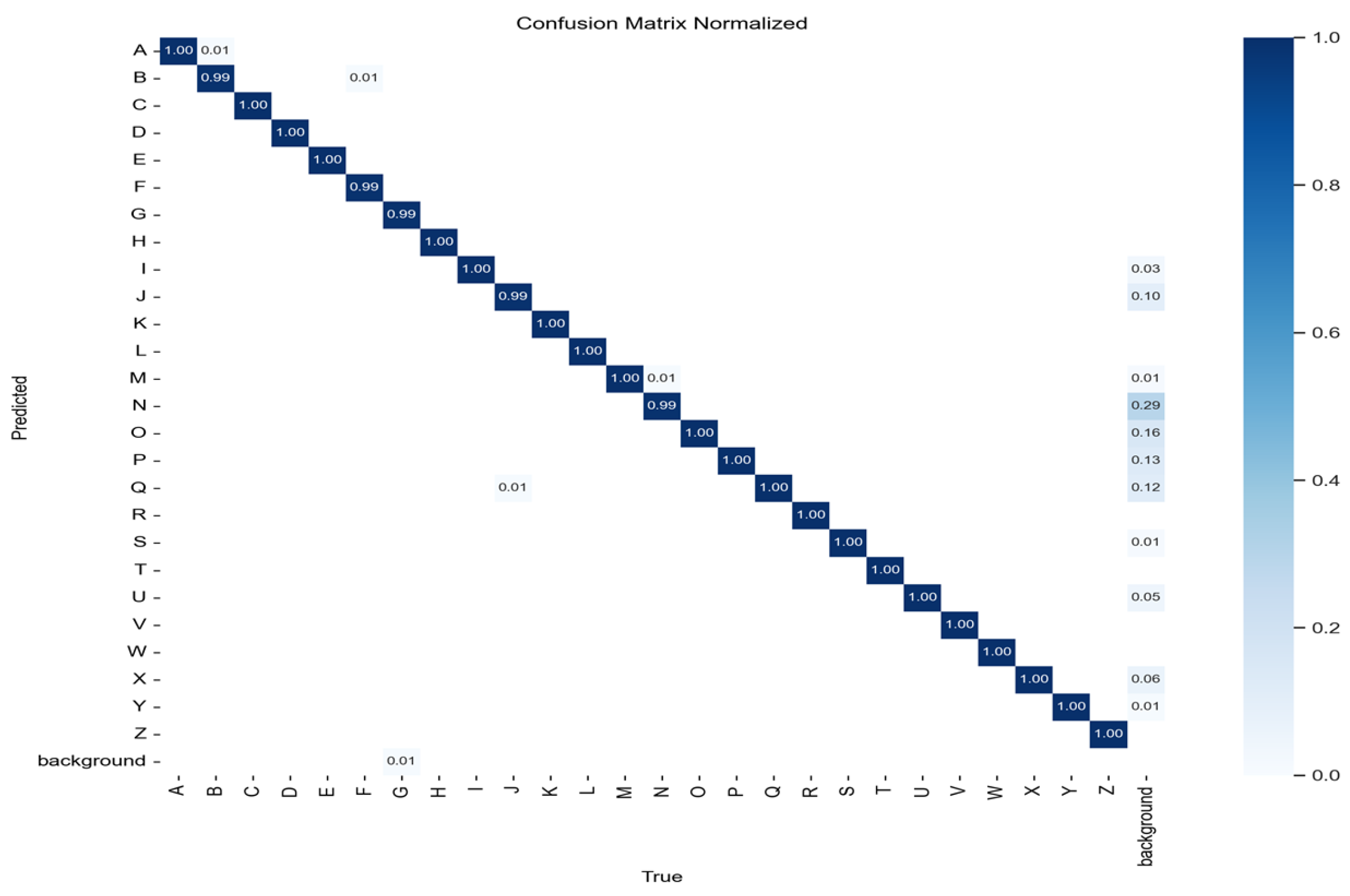
5.4. Confusion Matrix Analysis
- The model demonstrates high classification accuracy with minimal misclassifications.
- Class-wise performance remains consistent, ensuring robustness across all ASL alphabet classes.
- Confusion is minimal, confirming the effectiveness of the YOLO11n architecture in distinguishing ASL gestures.
5.5. Evaluation of a Real-Time ASL Interpretation System
5.5.1. System Specifications
- Operating Environment: Python 3.10.11 and PyTorch 2.2.1.
- Hardware: 12th Gen Intel Core i7-1260P CPU.
5.5.2. Performance Analysis
- Preprocessing: 1.1 ms.
- Inference (Model Prediction): 70.9 ms.
- Loss Calculation: 0.0 ms.
- Postprocessing: 0.5 ms.
5.5.3. Robustness Across Different Conditions
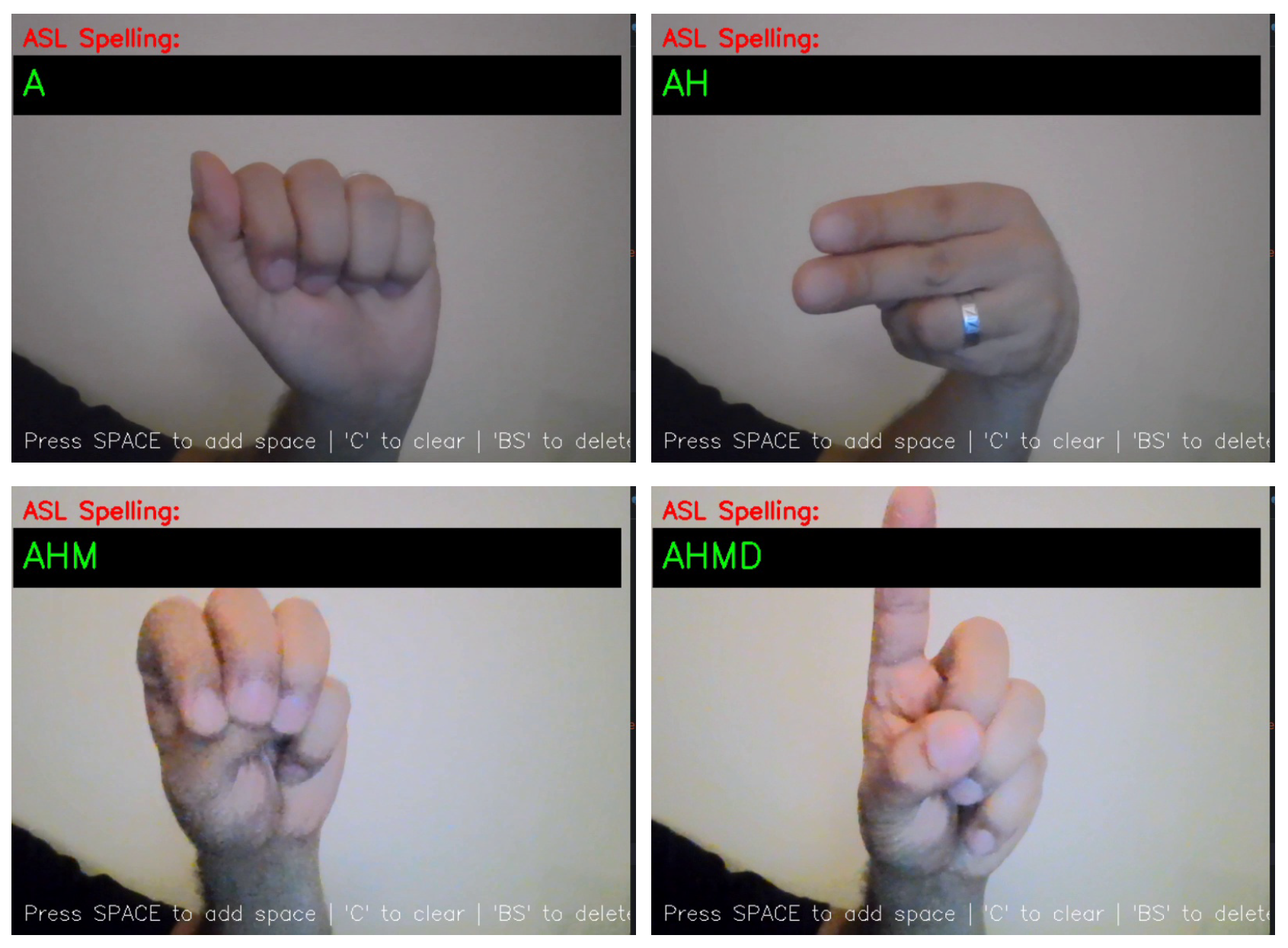
5.5.4. ASL Translation to Names and Locations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Papatsimouli, M.; Sarigiannidis, P.; Fragulis, G.F. A survey of advancements in real-time sign language translators: Integration with IoT technology. Technologies 2023, 11, 83. [Google Scholar] [CrossRef]
- Alsharif, B.; Ilyas, M. Internet of things technologies in healthcare for people with hearing impairments. In IoT and Big Data Technologies for Health Care; Springer: Cham, Switzerland, 2022; pp. 299–308. [Google Scholar]
- Cui, R.; Liu, H.; Zhang, C. Recurrent Convolutional Neural Networks for Continuous Sign Language Recognition by Staged Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7361–7369. [Google Scholar]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- ZainEldin, H.; Gamel, S.A.; Talaat, F.M.; Aljohani, M.; Baghdadi, N.A.; Malki, A.; Badawy, M.; Elhosseini, M.A. Silent no more: A comprehensive review of artificial intelligence, deep learning, and machine learning in facilitating Deaf and mute communication. Artif. Intell. Rev. 2024, 57, 188. [Google Scholar] [CrossRef]
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2019, 10, 131–153. [Google Scholar] [CrossRef]
- Zdravkova, K.; Krasniqi, V.; Dalipi, F.; Ferati, M. Cutting-edge communication and learning assistive technologies for disabled children: An artificial intelligence perspective. Front. Artif. Intell. 2022, 5, 970430. [Google Scholar] [CrossRef]
- Guo, J.; Liu, Y.; Lin, L.; Li, S.; Cai, J.; Chen, J.; Huang, W.; Lin, Y.; Xu, J. Chromatic plasmonic polarizer-based synapse for all-optical convolutional neural network. Nano Lett. 2023, 23, 9651–9656. [Google Scholar] [CrossRef]
- Alsharif, B.; Alanazi, M.; Altaher, A.S.; Altaher, A.; Ilyas, M. Deep Learning Technology to Recognize American Sign Language Alphabet Using Mulit-Focus Image Fusion Technique. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life Using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 1–6. [Google Scholar]
- Ali, M.L.; Zhang, Z. The YOLO framework: A comprehensive review of evolution, applications, and benchmarks in object detection. Computers 2024, 13, 336. [Google Scholar] [CrossRef]
- Alaftekin, M.; Pacal, I.; Cicek, K. Real-time sign language recognition based on YOLO algorithm. Neural Comput. Appl. 2024, 36, 7609–7624. [Google Scholar] [CrossRef]
- Saxena, S.; Paygude, A.; Jain, P.; Memon, A.; Naik, V. Hand Gesture Recognition using YOLO Models for Hearing and Speech Impaired People. In Proceedings of the 2022 IEEE Students Conference on Engineering and Systems (SCES), Prayagraj, India, 1–3 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Ye, T.; Huang, S.; Qin, W.; Tu, H.; Zhang, P.; Wang, Y.; Gao, C.; Gong, Y. YOLO-FIX: Improved YOLOv11 with Attention and Multi-Scale Feature Fusion for Detecting Glue Line Defects on Mobile Phone Frames. Electronics 2025, 14, 927. [Google Scholar] [CrossRef]
- Hoermann, S.; Henzler, P.; Bach, M.; Dietmayer, K. Object detection on dynamic occupancy grid maps using deep learning and automatic label generation. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 826–833. [Google Scholar]
- Li, Y.; Wang, T.; Kang, B.; Tang, S.; Wang, C.; Li, J.; Feng, J. Overcoming classifier imbalance for long-tail object detection with balanced group softmax. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10991–11000. [Google Scholar]
- Dobranskỳ, M. Object Detection for Video Surveillance Using the SSD Approach. Master’s Thesis, Technical University of Košice, Košice, Slovakia, 2019. [Google Scholar]
- Rajendran, A.K.; Sethuraman, S.C. A survey on yogic posture recognition. IEEE Access 2023, 11, 11183–11223. [Google Scholar] [CrossRef]
- Pinochet, D. Computational Gestural Making: A Framework for Exploring the Creative Potential of Gestures, Materials, and Computational Tools; Massachusetts Institute of Technology: Cambridge, MA, USA, 2023. [Google Scholar]
- Noroozi, F.; Corneanu, C.A.; Kamińska, D.; Sapiński, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018, 12, 505–523. [Google Scholar]
- Zhang, H.; Tian, Y.; Zhang, Y.; Li, M.; An, L.; Sun, Z.; Liu, Y. Pymaf-x: Towards well-aligned full-body model regression from monocular images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12287–12303. [Google Scholar]
- Zhao, L.; Li, X.; Zhuang, Y.; Wang, J. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3219–3228. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dima, T.F.; Ahmed, M.E. Using YOLOv5 algorithm to detect and recognize American sign language. In Proceedings of the 2021 International Conference on Information Technology (ICIT), Amman, Jordan, 14–15 July 2021; pp. 603–607. [Google Scholar]
- Al-Shaheen, A.; Çevik, M.; Alqaraghulı, A. American sign language recognition using yolov4 method. Int. J. Multidiscip. Stud. Innov. Technol. 2022, 6, 61–65. [Google Scholar]
- Buttar, A.M.; Ahmad, U.; Gumaei, A.H.; Assiri, A.; Akbar, M.A.; Alkhamees, B.F. Deep learning in sign language recognition: A hybrid approach for the recognition of static and dynamic signs. Mathematics 2023, 11, 3729. [Google Scholar] [CrossRef]
- Imran, A.; Hulikal, M.S.; Gardi, H.A. Real Time American Sign Language Detection Using Yolo-v9. arXiv 2024, arXiv:2407.17950. [Google Scholar]
- Kurniawan, R.; Wijaya, Y.A. YOLOv8 Algorithm to Improve the Sign Language Letter Detection System Model. J. Artif. Intell. Eng. Appl. (JAIEA) 2025, 4, 1379–1385. [Google Scholar]
- Alsharif, B.; Altaher, A.S.; Altaher, A.; Ilyas, M.; Alalwany, E. Deep learning technology to recognize american sign language alphabet. Sensors 2023, 23, 7970. [Google Scholar] [CrossRef]
- Alsharif, B.; Alanazi, M.; Ilyas, M. Machine Learning Technology to Recognize American Sign Language Alphabet. In Proceedings of the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life Using AI, Robotics and IoT (HONET), Boca Raton, FL, USA, 4–6 December 2023; pp. 173–178. [Google Scholar]
- Raschka, S. Model evaluation, model selection, and algorithm selection in machine learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]
- Brownlee, J. Imbalanced Classification with Python: Better Metrics, Balance Skewed Classes, Cost-Sensitive Learning; Machine Learning Mastery: San Francisco, CA, USA, 2020. [Google Scholar]
- Sundaresan Geetha, A.; Alif, M.A.R.; Hussain, M.; Allen, P. Comparative Analysis of YOLOv8 and YOLOv10 in Vehicle Detection: Performance Metrics and Model Efficacy. Vehicles 2024, 6, 1364–1382. [Google Scholar] [CrossRef]
- Alalwany, E.; Alsharif, B.; Alotaibi, Y.; Alfahaid, A.; Mahgoub, I.; Ilyas, M. Stacking Ensemble Deep Learning for Real-Time Intrusion Detection in IoMT Environments. Sensors 2025, 25, 624. [Google Scholar] [CrossRef]
- Aldahoul, N.; Karim, H.A.; Sabri, A.Q.M.; Tan, M.J.T.; Momo, M.A.; Fermin, J.L. A comparison between various human detectors and CNN-based feature extractors for human activity recognition via aerial captured video sequences. IEEE Access 2022, 10, 63532–63553. [Google Scholar] [CrossRef]
- Naing, K.M.; Boonsang, S.; Chuwongin, S.; Kittichai, V.; Tongloy, T.; Prommongkol, S.; Dekumyoy, P.; Watthanakulpanich, D. Automatic recognition of parasitic products in stool examination using object detection approach. PeerJ Comput. Sci. 2022, 8, e1065. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Keypoint ID(s) | Hand Part |
|---|---|
| 0 | Wrist |
| 1, 2, 3, 4 | Thumb |
| 5, 6, 7, 8 | Index Finger |
| 9, 10, 11, 12 | Middle Finger |
| 13, 14, 15, 16 | Ring Finger |
| 17, 18, 19, 20 | Pinky Finger |
| Ref | Year | Model | Dataset (Images) | Precision | Recall | F1-Score | mAP@0.5 | Real-Time |
|---|---|---|---|---|---|---|---|---|
| [24] | 2021 | YOLOv5 | 2425 | 95% | 97% | 96% | 98% | No |
| [25] | 2022 | YOLOv4 | 8000 | 96.00% | 96.00% | 96.00% | 98.01% | Yes |
| [26] | 2023 | YOLOv6 | 8000 | 96.00% | 96.00% | 96.00% | 96.22% | Yes |
| [27] | 2024 | YOLOv9 | 1334 | 96.83% | 92.96% | - | 97.84% | Yes |
| [28] | 2025 | YOLOv8 | Video-based dataset | 100% | 99% | 89% | 96% | Yes |
| Our work | 2025 | YOLOv11 | 130,000 | 98.50% | 98.10% | 99.10% | 98.20% | Yes |
| Metric | Value |
|---|---|
| Precision (P) | 0.985 |
| Recall (R) | 0.981 |
| F1-Sore (F) | 0.991 |
| mAP@0.5 | 0.982 |
| mAP@0.5–0.95 | 0.933 |
| Inference Speed | 1.3 ms per image |
| Post-processing Speed | 0.3 ms per image |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsharif, B.; Alalwany, E.; Ibrahim, A.; Mahgoub, I.; Ilyas, M. Real-Time American Sign Language Interpretation Using Deep Learning and Keypoint Tracking. Sensors 2025, 25, 2138. https://doi.org/10.3390/s25072138
Alsharif B, Alalwany E, Ibrahim A, Mahgoub I, Ilyas M. Real-Time American Sign Language Interpretation Using Deep Learning and Keypoint Tracking. Sensors. 2025; 25(7):2138. https://doi.org/10.3390/s25072138
Chicago/Turabian StyleAlsharif, Bader, Easa Alalwany, Ali Ibrahim, Imad Mahgoub, and Mohammad Ilyas. 2025. "Real-Time American Sign Language Interpretation Using Deep Learning and Keypoint Tracking" Sensors 25, no. 7: 2138. https://doi.org/10.3390/s25072138
APA StyleAlsharif, B., Alalwany, E., Ibrahim, A., Mahgoub, I., & Ilyas, M. (2025). Real-Time American Sign Language Interpretation Using Deep Learning and Keypoint Tracking. Sensors, 25(7), 2138. https://doi.org/10.3390/s25072138