
DP-YOLO: A Lightweight Real-Time Detection Algorithm for Rail Fastener Defects


Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | YOLOv5s | YOLOv8s | YOLOv10s |
|---|---|---|---|
| Release Time | 2020 | 2023 | 2024 |
| Parameters | 7.2 M | 11.2 M | 7.2 M |
| FLOPs | 17.0 G | 28.6 G | 21.6 G |
| COCO mAP | 37.2% | 44.9% | Higher (specific values to be released) |
| Inference Speed | Fast | Faster | Fastest (optimized computational efficiency) |
| Use Cases | Embedded devices, mobile, real-time detection | High-precision real-time detection, large-scale video analysis | High-precision real-time detection, large-scale video analysis |
| The complexity of deployment | It supports exporting models in multiple formats, which enables it to be easily deployed across various hardware platforms, including mobile devices, edge devices, and servers. | Although it also supports exporting in multiple formats, more optimization and adaptation work may be required during the actual deployment process. | Although it has significant performance improvements, its new architecture and training methods may require more optimization and adaptation work to achieve optimal performance across different platforms. |
| Community Support and Documentation | It enjoys extensive community support and abundant documentation resources, which enable developers to quickly find solutions and resources to address problems. | Although its community is also growing, compared to YOLOv5s, its community resources and documentation may not be as rich. | As a newer version, its community support and documentation resources are still being continuously improved. |
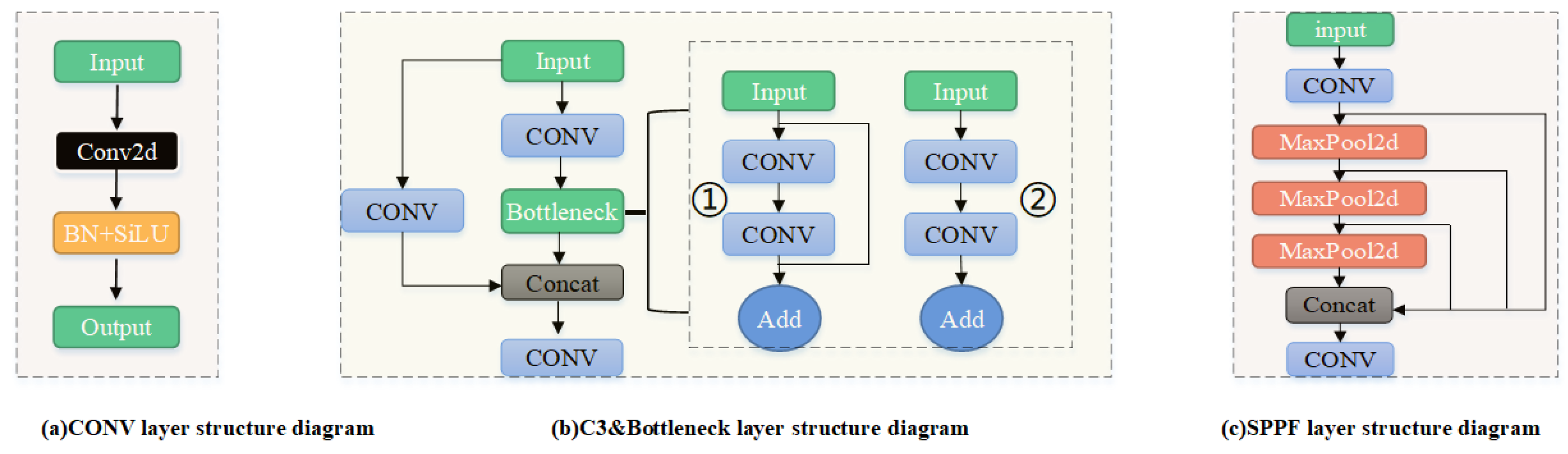
2. The Basic Framework of YOLOv5
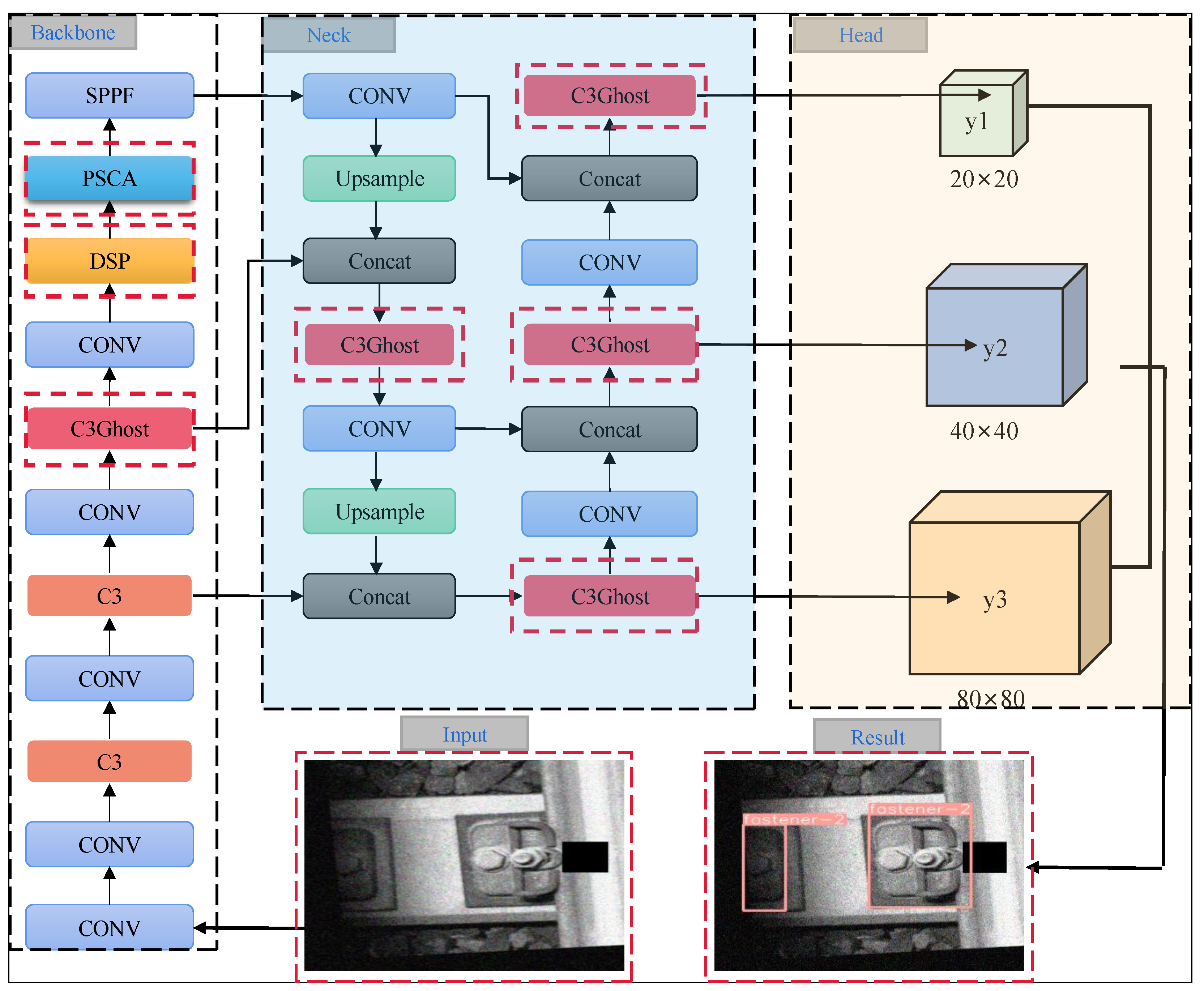
3. DP-YOLO Network Module
3.1. Design of the DSP Module Based on Depthwise Separable Convolution
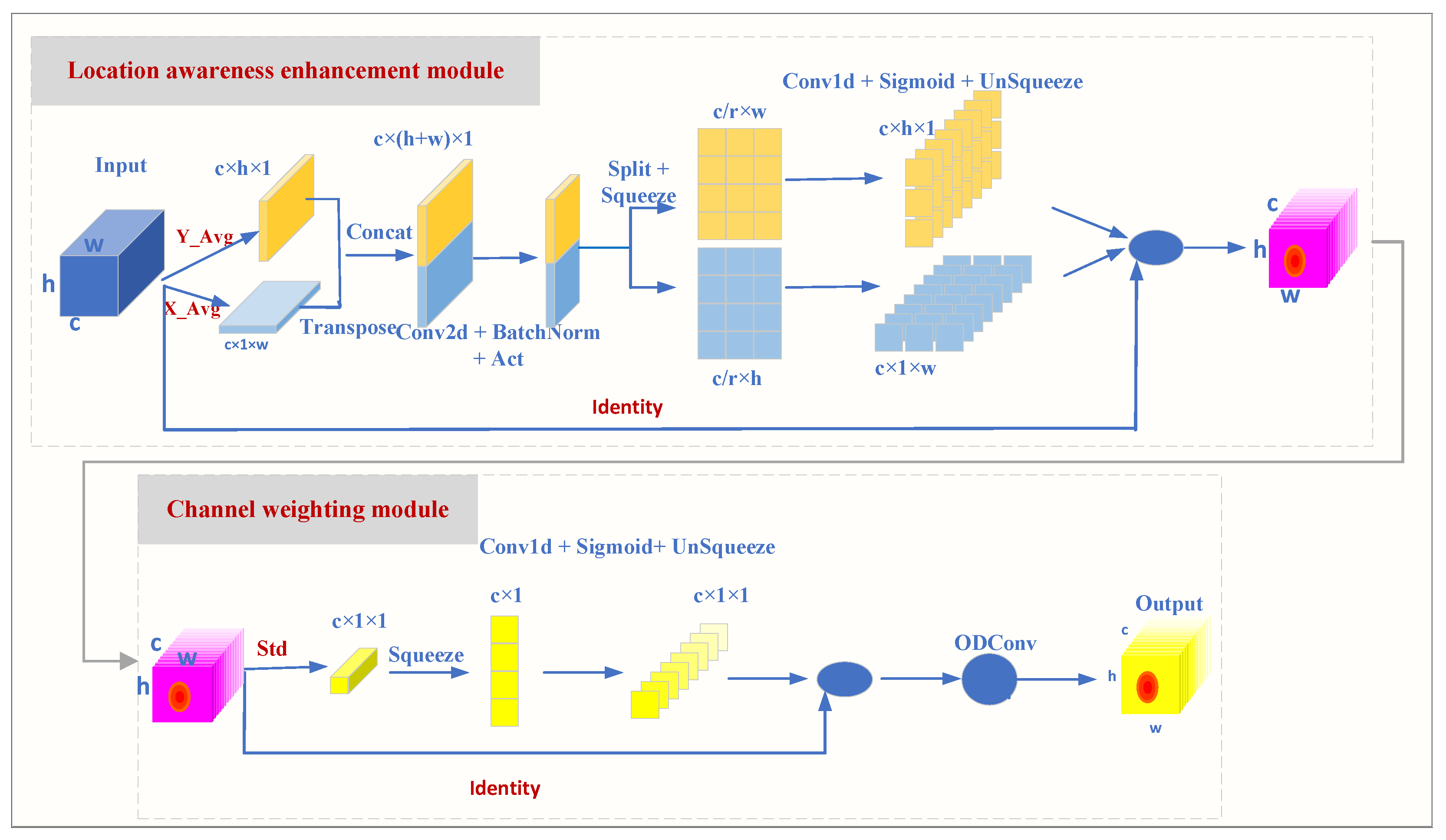
3.2. PSCA Attention Mechanism
- 1D Convolutional Transformation: Use 1D convolution (Conv1d) to transform , , , and to generate intermediate feature maps:
- Activation Function: Apply an activation function (such as ReLU or SiLU) to the intermediate feature maps to enhance the non-linearity of the features. Here, , , r denotes the downsampling ratio, which is used to control the size of the module.
- Fusion Learning: Combine the intermediate feature maps from two directions and the standard deviation feature maps to generate the final channel weight map:
- Channel Weighting: Use the generated channel weight map to weight the original feature map to generate the final feature map:
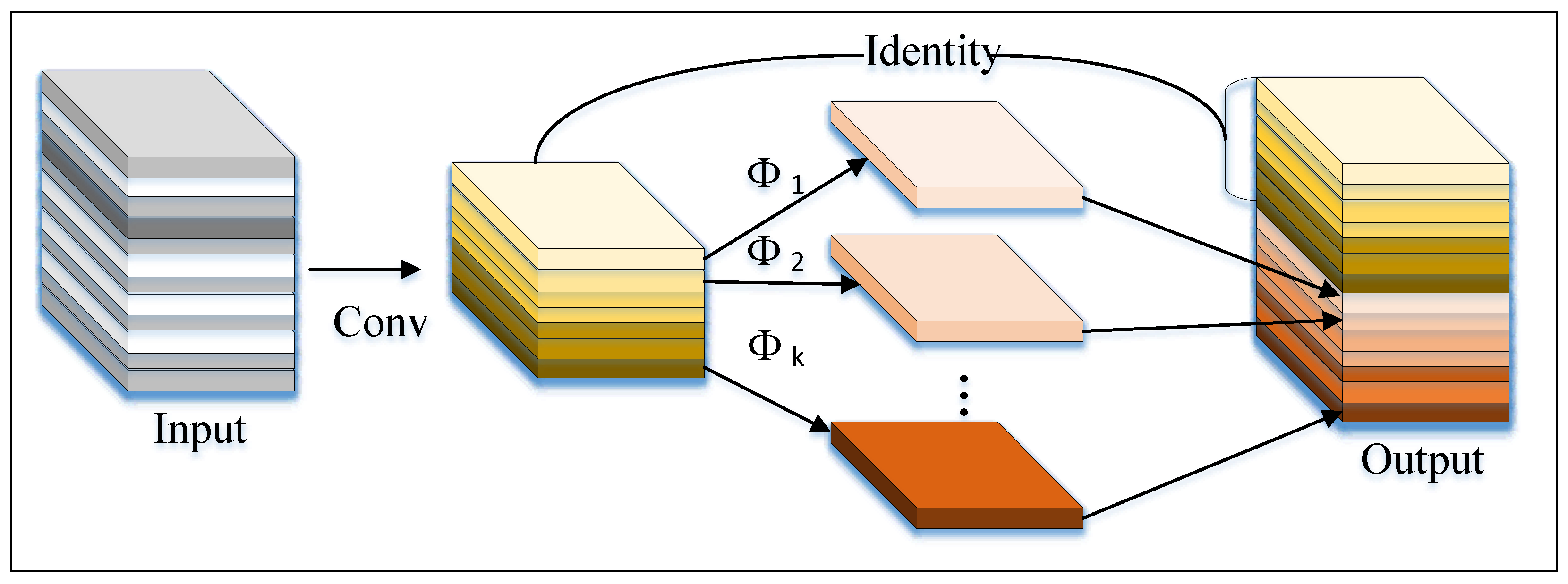
3.3. GhostC3 Module
3.4. Alpha-IoU Loss
4. Experiments and Analysis
4.1. Railway Track Fastener Defect Detection Dataset and Evaluation Criteria
4.2. Experimental Environment and Parameter Setting
4.3. Experimental Results and Analysis
4.3.1. Ablation Experiment
4.3.2. Comparison of Experimental Results of Different Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cha, Y.J.; Ali, R.; Lewis, J.; Büyüköztürk, O. Deep learning-based structural health monitoring. Autom. Constr. 2024, 161, 105328. [Google Scholar] [CrossRef]
- Cha, Y.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar] [CrossRef]
- Song, W.; Liao, B.; Ning, K.; Yan, X. Improved Real-Time Detection Transformer-Based Rail Fastener Defect Detection Algorithm. Mathematics 2024, 12, 3349. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, NV, USA, 27–30 June 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot MultiBox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3–8. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. arXiv 2021. [Google Scholar] [CrossRef]
- Wei, F.; Zhou, J.P.; Tan, X.; Lin, J.; Tian, L.; Wang, H. Lightweight YOLOv5 detection algorithm for low-altitude micro UAV. J. Optoelectron. 2024, 35, 641–649. [Google Scholar] [CrossRef]
- Li, H.; Li, H.; Hou, Z.; Song, H.; Liu, J.; Dai, P. Feature Augmentation Based on Pixel-Wise Attention for Rail Defect Detection. Appl. Sci. 2022, 12, 8006. [Google Scholar] [CrossRef]
- Zou, X.; Peng, T.; Zhou, Y. UAV-Based Human Detection with Visible-Thermal Fused YOLOv5 Network. IEEE Trans. Ind. Inform. 2023, 99, 3814–3823. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Tan, F.; Zhai, M.; Zhai, C. Foreign object detection in urban rail transit based on deep differentiation segmentation neural network. Heliyon 2024, 10, e37072. [Google Scholar] [CrossRef] [PubMed]
- Kang, D.H.; Cha, Y.J. Efficient attention-based deep encoder and decoder for automatic crack segmentation. Struct. Health Monit. 2022, 21, 2190–2205. [Google Scholar] [CrossRef] [PubMed]
- Choi, W.; Cha, Y.J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Roboflow. Fastener Defect Detection. 2023. Available online: https://universe.roboflow.com/learning-dvrz6/fastener-defect-detection (accessed on 1 January 2023).
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.F.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-dimensional dynamic convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based Attention Module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. arXiv 2021, arXiv:2110.13675. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]






| Attention Mechanism | mAP0.5% | Parameters/M | GFLOPs | FPS |
|---|---|---|---|---|
| NAM [27] | 85.2 | 7.06 | 15.8 | 309 |
| ECA [28] | 85.9 | 7.06 | 15.8 | 305 |
| CA [29] | 86.0 | 7.04 | 15.8 | 306 |
| CBAM [30] | 86.2 | 8.22 | 15.8 | 298 |
| SE [31] | 86.0 | 7.04 | 15.8 | 310 |
| PSCA | 86.4 | 7.04 | 15.8 | 315 |
| Algorithm | mAP0.5/% | mAP0.5:0.95/% |
|---|---|---|
| YOLOv5 + IoU loss | 85.8 | 55.5 |
| YOLOv5 + GIoU loss | 85.8 | 55.5 |
| YOLOv5 + DIoU loss | 86.1 | 55.9 |
| YOLOv5 + CIoU loss(default) | 86.1 | 55.9 |
| YOLOv5 + SIoU loss | 86.2 | 56.1 |
| YOLOv5 + Alpha-IOU loss | 86.2 | 56.8 |
| Improved Scheme | mAP0.5/% | mAP0.5:0.95/% | Parameters/M | GFLOPs | FPS | Model Size (MB) | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Model | PSCA | DSP | C3Ghost | Alpha-IoU | ||||||
| A | × | × | × | × | 0.858 | 0.555 | 7.02 | 15.8 | 310 | 14.4 |
| B | × | × | × | ✓ | 0.858 | 0.568 | 7.01 | 15.8 | 310 | 13.7 |
| C | × | ✓ | × | × | 0.863 | 0.561 | 6.89 | 13.4 | 302 | 13.5 |
| D | ✓ | × | × | × | 0.864 | 0.562 | 7.04 | 15.8 | 315 | 13.7 |
| E | ✓ | ✓ | × | ✓ | 0.867 | 0.574 | 7.04 | 15.8 | 303 | 13.7 |
| F | ✓ | ✓ | × | × | 0.869 | 0.564 | 6.89 | 13.4 | 306 | 13.5 |
| H | ✓ | ✓ | ✓ | ✓ | 0.871 | 0.576 | 6.92 | 13.4 | 315 | 13.5 |
| Model | Image-Size | mAP0.5/% | ||||||
|---|---|---|---|---|---|---|---|---|
| All | fastener | fastener-2 | fastener_broken | fastener2_broken | trackbed_stuff | Missing | ||
| Faster-RCNN | 640 × 640 | 50.2 | 61.5 | 49.6 | 58.4 | 64.6 | 31.5 | 98.2 |
| Cascade R-CNN | 640 × 640 | 69.3 | 72.3 | 65.4 | 79.6 | 75.5 | 40.4 | 99.3 |
| SSD | 512 × 512 | 60.1 | 72.2 | 58.4 | 68.4 | 69.9 | 32.4 | 96.8 |
| YOLOX | 640 × 640 | 80.3 | 92.4 | 74.3 | 90.5 | 91.2 | 40.3 | 98.4 |
| CenterNet | 640 × 640 | 86.9 | 94.7 | 83.6 | 91.1 | 97.4 | 42.7 | 98.4 |
| YOLOv7 | 640 × 640 | 87.1 | 97.6 | 85.7 | 92.3 | 99.6 | 46.6 | 97.3 |
| YOLOv5s (Baseline) | 640 × 640 | 85.8 | 97.2 | 85.3 | 92.0 | 99.5 | 43.5 | 97.1 |
| DP-YOLO (ours) | 640 × 640 | 87.1 | 97.9 | 86.7 | 92.9 | 99.6 | 47.3 | 96.2 |
| Model | mAP0.5/% | ||||||
|---|---|---|---|---|---|---|---|
| All | fastener | fastener-2 | fastener_broken | fastener2_broken | trackbed_stuff | Missing | |
| YOLOv5s (Baseline) | 85.8 | 97.2 | 85.3 | 92.0 | 99.5 | 43.5 | 97.1 |
| YOLOv5-Mobilev3s | 81.1 | 92.4 | 80.2 | 88.4 | 96.2 | 39.6 | 98.6 |
| YOLOv5-Mobilev3l | 82.3 | 93.3 | 81.3 | 89.4 | 97.8 | 40.5 | 98.3 |
| YOLOv5-ShuffleNet | 81.4 | 92.6 | 80.4 | 88.7 | 96.6 | 40.1 | 98.5 |
| YOLOv5-Ghost | 85.5 | 96.9 | 83.3 | 92.3 | 99.1 | 42.6 | 98.2 |
| YOLOv3-Tony | 73.9 | 84.3 | 71.9 | 81.3 | 84.2 | 34.7 | 99.5 |
| DP-YOLO (ours) | 87.1 | 97.9 | 86.7 | 92.9 | 99.6 | 47.3 | 96.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Sun, Q.; Han, Z.; Zhai, F. DP-YOLO: A Lightweight Real-Time Detection Algorithm for Rail Fastener Defects. Sensors 2025, 25, 2139. https://doi.org/10.3390/s25072139
Chen L, Sun Q, Han Z, Zhai F. DP-YOLO: A Lightweight Real-Time Detection Algorithm for Rail Fastener Defects. Sensors. 2025; 25(7):2139. https://doi.org/10.3390/s25072139
Chicago/Turabian StyleChen, Lihua, Qi Sun, Ziyang Han, and Fengwen Zhai. 2025. "DP-YOLO: A Lightweight Real-Time Detection Algorithm for Rail Fastener Defects" Sensors 25, no. 7: 2139. https://doi.org/10.3390/s25072139
APA StyleChen, L., Sun, Q., Han, Z., & Zhai, F. (2025). DP-YOLO: A Lightweight Real-Time Detection Algorithm for Rail Fastener Defects. Sensors, 25(7), 2139. https://doi.org/10.3390/s25072139