

SDA-Net: A Spatially Optimized Dual-Stream Network with Adaptive Global Attention for Building Extraction in Multi-Modal Remote Sensing Images
Abstract
:1. Introduction
- (1)
- A Spatial Information Optimization Module (SIOM) is designed to effectively align spatial feature representations across different modalities. By leveraging feature modulation, decomposition, and reassembly, SIOM enhances multi-modal feature representation, bridges the gap between heterogeneous data, and reduces feature redundancy caused by early fusion.
- (2)
- An Adaptive Global Attention Fusion Module (AGAFM) is proposed to intelligently guide multi-scale and multi-modal feature fusion. By modeling the dynamic relationships between spectral channels and spatial positions through global-adaptive attention mechanisms, AGAFM bridges semantic mismatches, balances local and global features, and generates high-quality fused features with improved discriminative capabilities for building extraction tasks.
2. Related Work
3. Methods
3.1. Overall Architecture
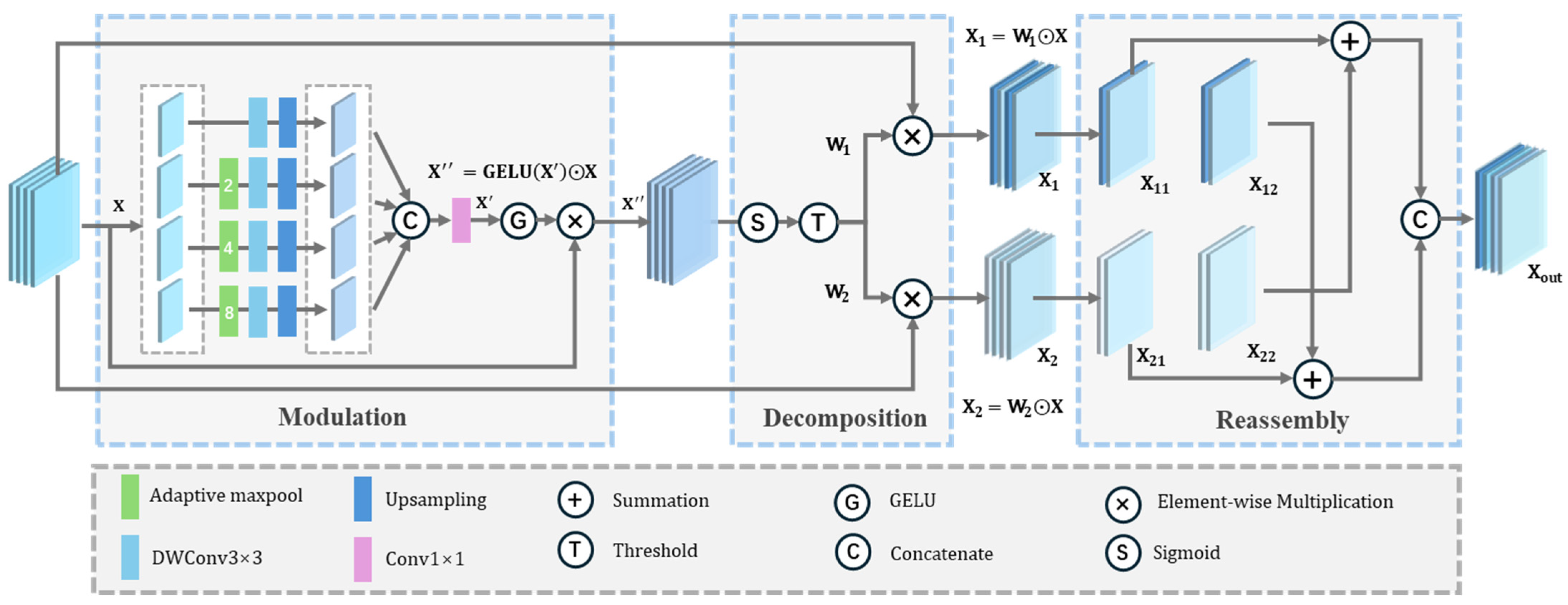
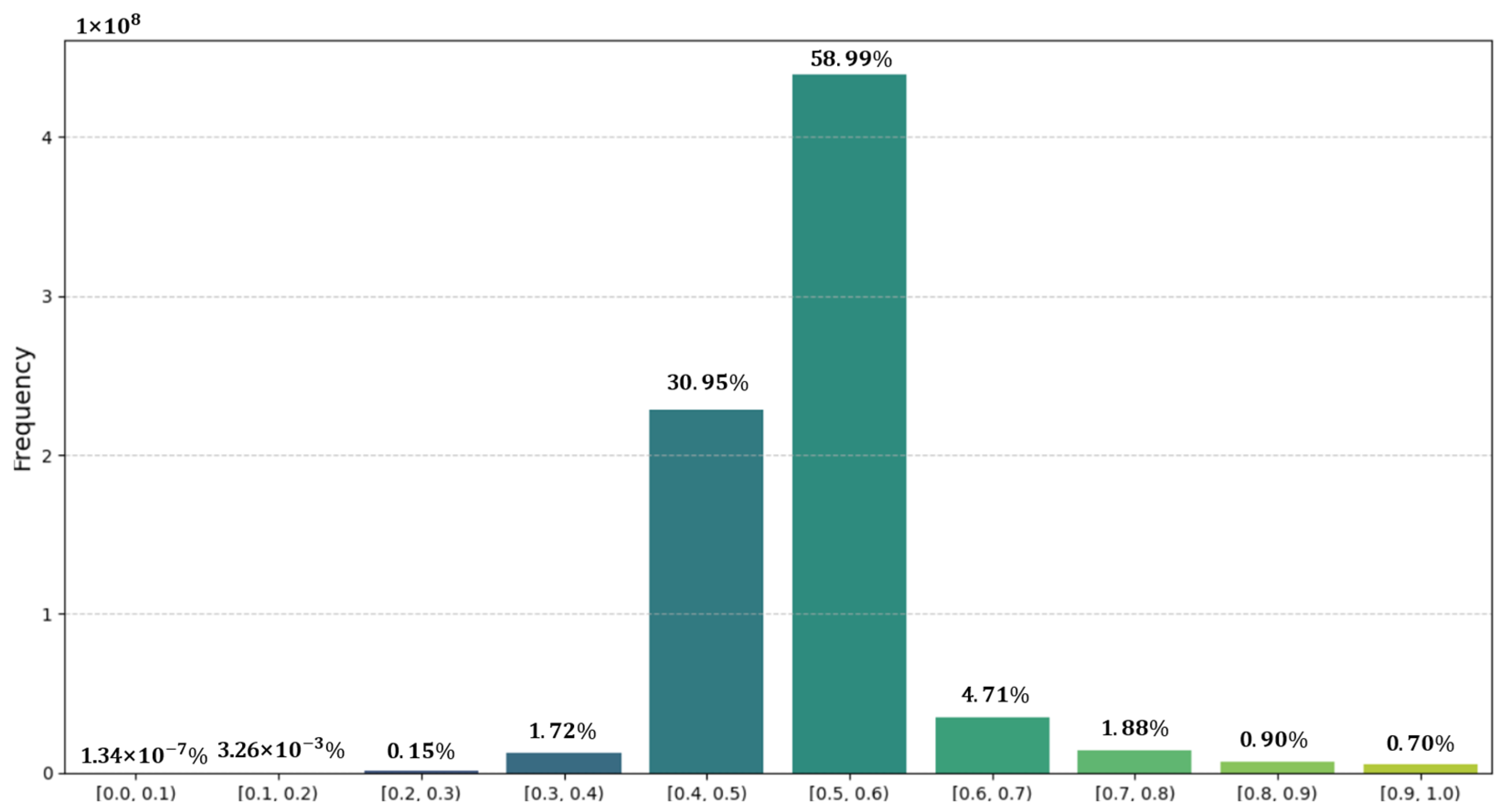
3.2. Spatial Information Optimization Module
3.3. Adaptive Global Attention Fusion Module
4. Experiments
4.1. Datasets and Experimental Setup
4.2. Loss Function
4.3. Comparative Experiment
4.3.1. ISPRS Potsdam Dataset
4.3.2. ISPRS Vaihingen Dataset
4.3.3. DFC23 Track2 Dataset
4.4. Ablation Study
4.4.1. ISPRS Vaihingen Dataset
4.4.2. DFC23 Track2 Dataset
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Cheng, H.; Yao, S.; Hu, Z. Building extraction from high-resolution remote sensing imagery based on multi-scale feature fusion and enhancement. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLIII-B3-2022, 55–60. [Google Scholar] [CrossRef]
- Hu, M.; Li, J.; A, X.; Zhao, Y.; Lu, M.; Li, W. FSAU-Net: A network for extracting buildings from remote sensing imagery using feature self-attention. Int. J. Remote Sens. 2023, 44, 1643–1664. [Google Scholar] [CrossRef]
- Qiu, S.; Zhou, J.; Liu, Y.; Meng, X. An effective dual encoder network with a feature attention large kernel for building extraction. Geocarto Int. 2024, 39, 2375572. [Google Scholar] [CrossRef]
- Guo, Z.; Pan, J.; Xie, P.; Zhu, L.; Qi, C.; Wang, X.; Ren, Z. MFFNet: A building change detection method based on fusion of spectral and geometric information. Geocarto Int. 2024, 39, 2322053. [Google Scholar] [CrossRef]
- Jiao, T.; Guo, C.; Feng, X.; Chen, Y.; Song, J. A comprehensive survey on deep learning multi-modal fusion: Methods, technologies and applications. Comput. Mater. Contin. 2024, 80, 1–35. [Google Scholar] [CrossRef]
- Tang, Q.; Liang, J.; Zhu, F. A comparative review on multi-modal sensors fusion based on deep learning. Signal Process. 2023, 213, 109165. [Google Scholar] [CrossRef]
- Teimouri, M.; Mokhtarzade, M.; Zoej, M.J.V. Optimal fusion of optical and SAR high-resolution images for semiautomatic building detection. GISci. Remote Sens. 2016, 53, 45–62. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Chen, Y.; Li, Z.; Li, H.; Wang, H. Progressive fusion learning: A multimodal joint segmentation framework for building extraction from optical and SAR images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 178–191. [Google Scholar] [CrossRef]
- Yuan, Q.; Shafri, H.Z. Multi-modal feature fusion network with adaptive center point detector for building instance extraction. Remote Sens. 2022, 14, 4920. [Google Scholar] [CrossRef]
- Hosseinpour, H.; Samadzadegan, F.; Javan, F.D. CMGFNet: A deep cross-modal gated fusion network for building extraction from very high-resolution remote sensing images. ISPRS J. Photogramm. Remote Sens. 2022, 184, 96–115. [Google Scholar] [CrossRef]
- Chen, D.; Tu, W.; Cao, R.; Zhang, Y.; He, B.; Wang, C.; Shi, T.; Li, Q. A hierarchical approach for fine-grained urban villages recognition fusing remote and social sensing data. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102661. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, Q.; Zhang, X.; Hu, Z.; Chen, J.; Zhong, C.; Li, H. CUGUV: A Benchmark Dataset for Promoting Large-Scale Urban Village Mapping with Deep Learning Models. Sci. Data 2025, 12, 390. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Q.; Shafri, H.Z.M.; Alias, A.H.; Hashim, S.J. Multiscale semantic feature optimization and fusion network for building extraction using high-resolution aerial images and LiDAR data. Remote Sens. 2021, 13, 2473. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-Conquer: Confluent Triple-Flow Network for RGB-T Salient Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef]
- Zhou, W.; Sun, F.; Jiang, Q.; Cong, R.; Hwang, J.-N. WaveNet: Wavelet Network With Knowledge Distillation for RGB-T Salient Object Detection. IEEE Trans. Image Process. 2023, 32, 3027–3039. [Google Scholar] [CrossRef]
- Wu, W.; Guo, S.; Shao, Z.; Li, D. CroFuseNet: A semantic segmentation network for urban impervious surface extraction based on cross fusion of optical and SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2573–2588. [Google Scholar] [CrossRef]
- Li, H.; Zhu, F.; Zheng, X.; Liu, M.; Chen, G. MSCDUNet: A deep learning framework for built-up area change detection integrating multispectral, SAR, and VHR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5163–5176. [Google Scholar] [CrossRef]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep learning in multimodal remote sensing data fusion: A comprehensive review. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102926. [Google Scholar] [CrossRef]
- Shi, X.; Huang, H.; Pu, C.; Yang, Y.; Xue, J. CSA-UNet: Channel-spatial attention-based encoder–decoder network for rural blue-roofed building extraction from UAV imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6514405. [Google Scholar] [CrossRef]
- Chang, J.; He, X.; Li, P.; Tian, T.; Cheng, X.; Qiao, M.; Zhou, T.; Zhang, B.; Chang, Z.; Fan, T. Multi-scale attention network for building extraction from high-resolution remote sensing images. Sensors 2024, 24, 1010. [Google Scholar] [CrossRef]
- Guo, J.; Jia, N.; Bai, J. Transformer based on channel-spatial attention for accurate classification of scenes in remote sensing image. Sci. Rep. 2022, 12, 15473. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Pan, X.; Yang, S.; Yang, X.; Xu, K. Multi-modal remote sensing image segmentation based on attention-driven dual-branch encoding framework. J. Appl. Remote Sens. 2024, 18, 026506. [Google Scholar] [CrossRef]
- Guyer, R.K.; MacKay, D.J.C. Markov Random Fields and Their Applications; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Cui, L.-L. Study on object-oriented classification method by integrating various features. J. Remote Sens. 2006, 1, 104–110. [Google Scholar] [CrossRef]
- Zhuang, L.; Ng, M.K.; Gao, L.; Wang, Z. Eigen-CNN: Eigenimages plus eigennoise level maps guided network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5512018. [Google Scholar] [CrossRef]
- Su, Y.; Zhu, Z.; Gao, L.; Plaza, A.; Li, P.; Sun, X.; Xu, X. DAAN: A deep autoencoder-based augmented network for blind multilinear hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5512715. [Google Scholar] [CrossRef]
- Han, Z.; Yang, J.; Gao, L.; Zeng, Z.; Zhang, B.; Chanussot, J. Dual-branch subpixel-guided network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5521813. [Google Scholar] [CrossRef]
- Zhang, X.; Li, L.; Di, D.; Wang, J.; Chen, G.; Jing, W.; Emam, M. SERNet: Squeeze and excitation residual network for semantic segmentation of high-resolution remote sensing images. Remote Sens. 2022, 14, 4770. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.Y.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Feng, W.Q.; Sui, H.G.; Hua, L.; Xu, C. Improved deep fully convolutional network with superpixel-based conditional random fields for building extraction. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 52–55. [Google Scholar] [CrossRef]
- Hui, J.; Du, M.K.; Ye, X.; Qin, Q.M.; Sui, J. Effective Building Extraction From High-Resolution Remote Sensing Images With Multitask Driven Deep Neural Network. IEEE Geosci. Remote Sens. Lett. 2019, 16, 786–790. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Format, 11–17 October 2021; pp. 10012–10022. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar] [CrossRef]
- Ho, J.; Kalchbrenner, N.; Weissenborn, D.; Salimans, T. Axial Attention in Multidimensional Transformers. arXiv 2019, arXiv:1912.12180. [Google Scholar]
- Han, D.; Ye, T.; Han, Y.; Xia, Z.; Song, S.; Huang, G. Agent Attention: On the Integration of Softmax and Linear Attention. arXiv 2023, arXiv:2312.08874. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arxiv 2021, arXiv:2102.04306. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Zhu, W.; Zhu, X.; He, N.; Xu, Y.; Cao, T.; Li, Y.; Huang, Y. A method for building extraction in remote sensing images based on SwinTransformer. Int. J. Digit. Earth 2024, 17, 2353113. [Google Scholar] [CrossRef]
- Diao, K.; Zhu, J.; Liu, G.; Li, M. MDTrans: Multi-scale and dual-branch feature fusion network based on Swin Transformer for building extraction in remote sensing images. IET Image Process. 2024, 18, 2930–2942. [Google Scholar] [CrossRef]
- Fu, W.; Xie, K.; Fang, L. Complementarity-aware local–global feature fusion network for building extraction in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5617113. [Google Scholar] [CrossRef]
- Sun, Y.; Zhao, Y.; Han, X.; Gao, W.; Hu, Y.; Zhang, Y. A feature enhancement network combining UNet and vision transformer for building change detection in high-resolution remote sensing images. Neural Comput. Appl. 2025, 37, 1429–1456. [Google Scholar] [CrossRef]
- Zhou, H.; Luo, F.; Zhuang, H.; Weng, Z.; Gong, X.; Lin, Z. Attention Multihop Graph and Multiscale Convolutional Fusion Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5508614. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for remote sensing image semantic segmentation. arxiv 2024, arXiv:2405.10530. [Google Scholar] [CrossRef]
- Jiang, M.; Zeng, P.; Wang, K.; Liu, H.; Chen, W.; Liu, H. FECAM: Frequency enhanced channel attention mechanism for time series forecasting. Adv. Eng. Inform. 2023, 58, 102158. [Google Scholar] [CrossRef]
- Xiang, X.; Wang, Z.; Zhang, J.; Xia, Y.; Chen, P.; Wang, B. AGCA: An Adaptive Graph Channel Attention Module for Steel Surface Defect Detection. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 36–46. [Google Scholar] [CrossRef]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar] [CrossRef]
- International Society for Photogrammetry and Remote Sensing. ISPRS 2D Semantic Labeling Contest—Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-potsdam.aspx (accessed on 20 October 2024).
- International Society for Photogrammetry and Remote Sensing. ISPRS 2D Semantic Labeling Contest—Vaihingen. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-sem-label-vaihingen.aspx (accessed on 25 October 2024).
- Persello, C.; Hänsch, R.; Vivone, G.; Chen, K.; Yan, Z.; Tang, D.; Huang, H.; Schmitt, M.; Sun, X. 2023 IEEE GRSS data fusion contest: Large-scale fine-grained building classification for semantic urban reconstruction. IEEE Geosci. Remote Sens. Mag. 2023, 11, 94–97. [Google Scholar] [CrossRef]
- Park, S.-J.; Hong, K.-S.; Lee, S. RDFNet: RGB-D multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar]
- Jiang, J.; Zheng, L.; Luo, F.; Zhang, Z. RedNet: Residual encoder-decoder network for indoor RGB-D semantic segmentation. arXiv 2018, arXiv:1806.01054. [Google Scholar] [CrossRef]
- Chen, X.; Lin, K.-Y.; Wang, J.; Wu, W.; Qian, C.; Li, H.; Zeng, G. Bi-directional cross-modality feature propagation with separation-and-aggregation gate for RGB-D semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 561–577. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| SERNet | 96.06 | 94.56 | 95.30 | 91.03 |
| RDFNet | 93.10 | 93.91 | 93.50 | 87.78 |
| RedNet | 96.81 | 90.23 | 93.40 | 87.62 |
| MMFNet | 96.03 | 96.64 | 96.33 | 92.93 |
| ADEUNet | 97.60 | 96.77 | 97.18 | 94.52 |
| SA-Gate | 97.42 | 96.46 | 96.94 | 94.06 |
| CMGFNet | 98.03 | 96.93 | 97.48 | 95.08 |
| TransUnet | 95.84 | 95.53 | 95.68 | 91.37 |
| ST-Unet | 96.79 | 96.21 | 96.50 | 93.24 |
| SDA-Net | 98.10 | 97.22 | 97.66 | 95.42 |
| Method | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| SERNet | 90.63 | 92.68 | 91.65 | 84.58 |
| RDFNet | 96.60 | 93.88 | 95.22 | 90.88 |
| RedNet | 95.99 | 95.32 | 95.65 | 91.66 |
| MMFNet | 95.50 | 93.29 | 94.39 | 89.36 |
| ADEUNet | 97.25 | 94.92 | 96.07 | 92.44 |
| SA-Gate | 96.83 | 94.64 | 95.72 | 91.80 |
| CMGFNet | 96.98 | 94.97 | 95.96 | 92.24 |
| TransUnet | 95.58 | 93.77 | 94.67 | 89.87 |
| ST-Unet | 96.41 | 95.52 | 95.97 | 92.25 |
| SDA-Net | 97.08 | 96.05 | 96.56 | 93.35 |
| Method | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| SERNet | 87.21 | 84.08 | 85.62 | 74.85 |
| RDFNet | 89.58 | 83.51 | 86.44 | 76.10 |
| RedNet | 87.20 | 87.72 | 87.46 | 77.71 |
| MMFNet | 91.37 | 89.72 | 90.54 | 82.71 |
| ADEUNet | 87.62 | 86.36 | 86.98 | 76.97 |
| SA-Gate | 88.79 | 87.39 | 88.08 | 78.71 |
| CMGFNet | 91.23 | 79.06 | 84.71 | 73.48 |
| TransUnet | 87.16 | 85.53 | 86.34 | 75.97 |
| ST-Unet | 90.38 | 86.19 | 88.24 | 78.95 |
| SDA-Net | 91.69 | 91.02 | 91.35 | 84.08 |
| Encoder | SIOM | AGAFM | Precision (%) | Recall (%) | F1 (%) | IoU (%) | F (G) | P (M) | T (s) |
|---|---|---|---|---|---|---|---|---|---|
| ResNet50 | - | - | 92.10 | 89.12 | 90.59 | 82.79 | 44.91 | 48.41 | 0.094 |
| Axial SA | - | - | 93.93 | 92.54 | 93.23 | 87.33 | 52.68 | 18.00 | 0.151 |
| Transformer | - | - | 93.99 | 93.07 | 93.53 | 87.84 | 114.52 | 89.06 | 0.761 |
| Dual-Stream | - | - | 95.68 | 92.34 | 93.98 | 88.64 | 189.06 | 53.91 | 0.279 |
| Dual-Stream | √ | - | 95.34 | 94.87 | 95.10 | 90.66 | 189.13 | 53.92 | 0.422 |
| Dual-Stream | √ | √ | 97.08 | 96.05 | 96.56 | 93.35 | 189.14 | 62.27 | 1.331 |
| T | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| 0.3 | 91.61 | 89.40 | 90.49 | 82.63 |
| 0.4 | 91.37 | 89.94 | 90.65 | 82.90 |
| 0.45 | 91.85 | 90.84 | 91.34 | 84.06 |
| 0.5 | 91.69 | 91.02 | 91.35 | 84.08 |
| 0.55 | 91.34 | 91.38 | 91.35 | 84.08 |
| 0.6 | 90.90 | 91.26 | 91.08 | 83.63 |
| 0.7 | 90.77 | 91.00 | 90.88 | 83.30 |
| 0.8 | 90.65 | 90.80 | 90.72 | 83.03 |
| Fusion Method | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|
| Sum | 86.50 | 85.12 | 85.80 | 75.14 |
| Cat | 88.43 | 87.43 | 87.93 | 78.45 |
| CA | 89.31 | 88.26 | 88.78 | 79.83 |
| SA | 88.42 | 88.01 | 88.22 | 78.91 |
| CSA | 89.62 | 89.21 | 89.42 | 80.86 |
| AGAFM | 91.69 | 91.02 | 91.35 | 84.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, X.; Xu, K.; Yang, S.; Liu, Y.; Zhang, R.; He, P. SDA-Net: A Spatially Optimized Dual-Stream Network with Adaptive Global Attention for Building Extraction in Multi-Modal Remote Sensing Images. Sensors 2025, 25, 2112. https://doi.org/10.3390/s25072112
Pan X, Xu K, Yang S, Liu Y, Zhang R, He P. SDA-Net: A Spatially Optimized Dual-Stream Network with Adaptive Global Attention for Building Extraction in Multi-Modal Remote Sensing Images. Sensors. 2025; 25(7):2112. https://doi.org/10.3390/s25072112
Chicago/Turabian StylePan, Xuran, Kexing Xu, Shuhao Yang, Yukun Liu, Rui Zhang, and Ping He. 2025. "SDA-Net: A Spatially Optimized Dual-Stream Network with Adaptive Global Attention for Building Extraction in Multi-Modal Remote Sensing Images" Sensors 25, no. 7: 2112. https://doi.org/10.3390/s25072112
APA StylePan, X., Xu, K., Yang, S., Liu, Y., Zhang, R., & He, P. (2025). SDA-Net: A Spatially Optimized Dual-Stream Network with Adaptive Global Attention for Building Extraction in Multi-Modal Remote Sensing Images. Sensors, 25(7), 2112. https://doi.org/10.3390/s25072112