4.1. Models’ Performance
In the presented study, we used various data and model-tuning approaches to obtain predictions of flowering in 12 deciduous woody plants that most closely reflected conventional field observations.
4.1.1. Data Treatment
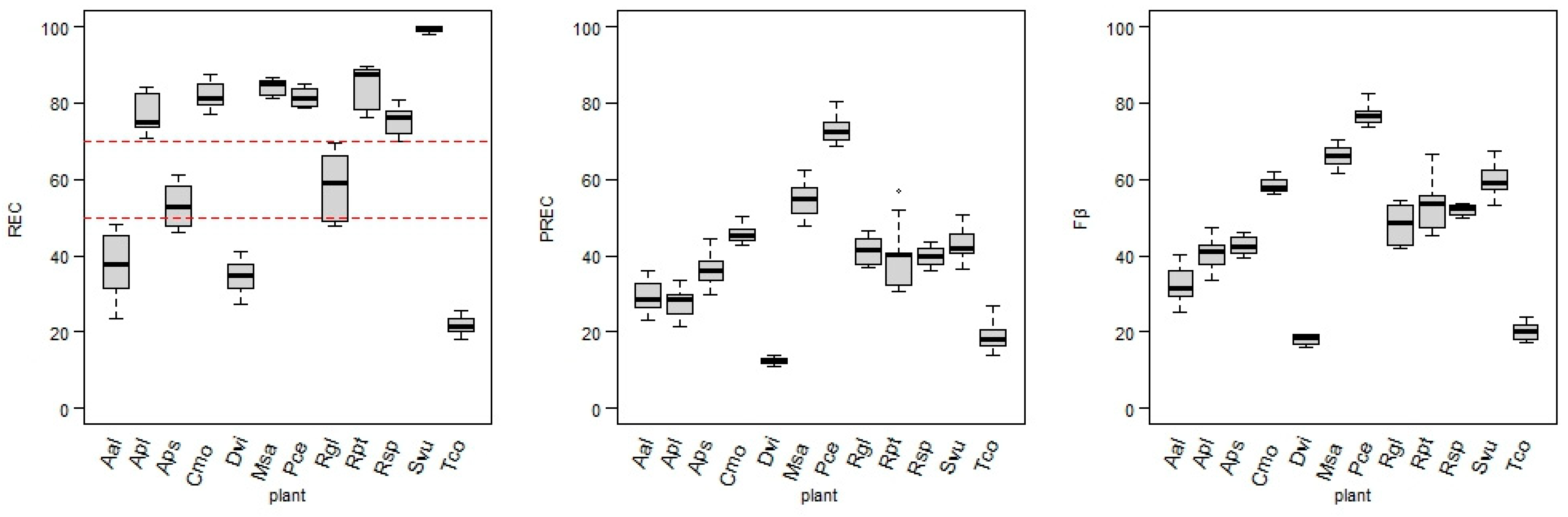
When no additional tuning was applied, various target designation methods (A, B, or C) did not give an overall better performance in the REC values. According to the REC, data treatment A was the most suitable for Aal and Tco, while the least was for Apl, Aps, Dvi, Rgl, and Rpt (
Table A3). Removing data from the start and end of flowering (data treatment B) was helpful in the cases of Cmo, Msa, Rgl, Rpt, Rsp, and Svu plants, but resulted in the lowest REC of Pce and Tco. The semi-supervised (C) data treatment resulted in the highest REC for Apl, Aps, Dvi, and Pce (for Aps, Dvi and Pce C.nt gave the best performance of all), while the lowest was for Aal, Cmo, Msa, Rsp, and Svu.
4.1.2. Model Tuning
Feature selection (fs) applied to each data treatment did not robustly influence most models’ performances. However, Apl and Cmo noticed a slight increase in the REC values, while for the Aal, Dvi, Msa, and Svu models, feature selection brought a deterioration in the REC values for all three data treatments. Data filtering (df) had a generally stronger impact on the model’s performance than feature selection (fs). Filtering positively affected all the treatments for plants such as Aal, Apl, Msa, Svu, Tco, and Rgl. In the case of Rgl, the REC has been raised by about 10% due to df. For the Cmo and Rsp models, REC values drop every time after gei.sd filtering.
The simultaneous application of feature selection and data filtering (fs.df) either enhanced or reduced the positive impact of a single (df or fs) model-tuning process in most cases. This transformation increased all the REC values for three data treatments of Apl and Rgl and caused REC decreases in Rsp models.
4.1.3. Joint Effect of Data Treatment and Model Tuning
The joint effect of data treatment and model-tuning analysis indicates that treatment A was sufficient enough to reach the highest REC of all the treatments in only two cases: Aal and Tco. However, both are characterized by low REC values in any model applied. Treatment B, jointly with model tuning, improved the models’ performance (by reaching the highest REC values) for five plants: Cmo, Msa, Rgl, Rsp, and Svu. Semi-supervised treatment (C) and tuning improved positive class identification in six plant models: Apl, Aps, Dvi, Pce, Rpt, and Svu. The Svu models B.df, B.fs.df, and C.fs.df were characterized by REC = 100%.
Considering various models’ performance with respect to the morphological characteristics of the analyzed plants, e.g., flower abundance, petal colors, and inflorescence placement on plant stems (
Table 1), a separate model adaptation to each analyzed plant may be required in future method application.
4.1.4. Diel Classification Results
The effectiveness of the diel classifications, which can be compared with conventional observation, varies among the models. Taking into account the frequency of field observations (usually once or twice a week), most models (Aal, Apl, Cmo, Dvi, Msa, Pce, Rgl, Rpt, Rsp, and Svu) showed shifts from the onset date that were not higher or equal to the possible error resulting from the frequency of the observations.
The described methodology utilized two classes and was not designed to designate the peak of flowering, another commonly recorded phase in field phenological observations. However, the flowering duration is even more informative than another single point in time, as it can serve as data that are useful in a study of available food resources for pollinators, a plant’s condition, or its plasticity to environmental factors [
5,
34]. In this study, models for nine plants—Apl, Aps, Cmo, Msa, Pce, Rgl, Rpt, Rsp, and Svu—can predict the flowering duration from the date of the actual beginning (0–3 day shift) to the end of flowering, in some cases equal to the observed BBCH 67 (Cmo, Msa, Rgl, Rpt, and Rsp models), in others extended to late signs of flowering, as phases BBCH 68–69 (Apl, Aps, Pce, and Svu models).
As climatic factors have changed rapidly in recent years, with a significant increase in air temperatures, which is the main factor in advancing plant development timing [
5,
35], a deeper understanding of plant phenology at both the individual and population levels is suggested by multiple authors [
5,
34,
36]. Through the presented method, flowering period designation (with its onset date, flowering termination, and duration) is more reachable than with time-consuming field observations. In addition, these parameters are far more accurate regarding the plant response to climatic factors than one point in time indicating when the flowering begins, to which conventional phenology is often limited [
34].
The Aal, Dvi, and Tco models have the poorest performance in predicting flowering duration, with less than half of DOYs (or even none). However, CLDOY threshold value manipulation (lowering to 40%) enabled classification improvement for the Aal model, which resulted in a significant increase in predictions: from FDS 42% (5/12 days) to 75% (9/12 days). At the same time, the number of misclassified days rose by only one, but in a period of flowering extremes. Such threshold manipulation was not effective in the Dvi and Tco models due to inconsistencies in the percentage of correctly classified images even at the peak of flowering and a high rate of incorrect positive class predictions long after the end of the flowering stage. Nevertheless, even with a few days offset or missing from predictions, consistent phenological information obtained automatically can still provide valuable data about long-term trends in flowering time, since the first increase in the number of images classified as flowering occurs during the observed flowering.
4.2. Limitations
4.2.1. Plant Characteristics and Location
The models’ performance seems to be dependent on plant visual characteristics. The flowers or inflorescence of ornamental plants (Cmo, Msa, Pce, Rosa sp., or Svu) are clearly visible due to the distinguished petal color, size, and flower abundance, which caused the contrast to their overall crown color in comparison with leaf verdancy and resulted in a more robust change in the RGB parameters. Plants with flowering emergence before leaf unfolding (Apl in addition to Msa and Pce) have flowering that is contrasting with the crown’s bare branches. For the above-mentioned plants, the models’ application enables effective flowering predictions and allows for the future reduction or elimination of ground observations since the accuracy of automatic observations is comparable with the observer’s reports. The Aal, Dvi, and Tco models proved much less sufficient in flowering predictions. All three plants have flowers hidden between the leaves (Dvi) or small, greenish flowers (Aal, Tco), making no contrast with the crown color from the phases before and after flowering. Hence, plants with more subtle flowering patterns will limit the effectiveness of this method.
Plant distance from the camera may affect the predictions in a limited way. The Cmo, Msa, Pce, Rpt, Rsp, and Svu models, with good prediction results, are located relatively close to the phenocamera (20–50 m). Yet, Apl models resulted in good predictions even though the plant grows over 100 m from the camera and is partially covered by vegetation located closer to the camera. Further-located plants are also usually partially covered by neighboring plants. Nevertheless, the plant fragment depicted on the images was enough to predict the flowering of Apl, Cmo, and Pce.
4.2.2. Observer’s Bias
Supervised machine learning involves observer-labeled data, on which algorithms then “learn” to identify patterns that are difficult to distinguish using simple statistical analyses. Therefore, successful flowering classification in this study depended on field observations and the observer’s correct plant phenophase identification. However, field observations are known for being prone to bias according to the observer’s experience and/or even preferences. An assessment of the growth stage is subjective and may differ between observers, and it occurs most often in the case of extreme stages [
25]. Some studies deal with this issue by sending several phenological observers to assess the plant growth stages [
37].
Field observation frequency is not strictly specified [
2,
25], and it varies between research (e.g., compare [
38] and [
8]). In this study, observations carried out at 2–4-day intervals were sufficient to determine the dates of the beginning and end stages of the flowering of individual plants. Reducing the number of observations could decrease the quality of the field phenological data, especially if the observation gap occurred when the first flowers opened (phases BBCH 60 and BBCH 61). These situations happened in the first year (2022) of observations for Aps, Dvi, Tco, and Aal. Thus, the ground-based data collected in the next year (2023) were applied to determine more precise labels in the training sets for these four plants.
Field observations are also limited due to the observer’s position relative to the plant. In tall tree studies, when both distance and the flowers’ small size can bias the observations (Apl, Aps, and Tco in this paper), even the use of binoculars can be insufficient for observing the first signs of flowering (BBCH 60 and BBCH 61).
The traditional phenological observations are separated in time. Plant phenological events are continuous processes, and the transition from one phase to another can occur within hours rather than days. Then, reporting ground observations, even daily, may not reflect the actual date of the phase. That considers mainly the phase onset and secondary growth stages (percentage of opened flowers). In this study, Cmo and Rsp were characterized by a dynamic transition of the subsequent flowering phases, in which the development of the flowering stage from 10% of open flowers (BBCH 61) to full flowering (BBCH 65) took place in less than 2 days. Determining the rate of the opened flowers itself is a difficult task for the observer. Therefore, field observations are often limited to the first signs of flowering [
2,
39]).
Despite the mentioned limitations, conventional field phenological observations are significant in phenology studies and provide ground truth data for any further remote sensing method. The observation’s robustness can be enhanced by handheld photography, allowing the comparisons between secondary phases, and by binoculars that help to spot flowers in hardly reachable parts of the plants. In the context of historical field observations, thanks to their continuity and long time series (reaching even to previous centuries and millennia), ground observations determine valuable information about changes in the plant response to abiotic factors in time [
2,
36] and at a level that, for new and more advanced methods, is still under development.
4.3. Phenological Methods Comparison
Digital repeat photography originated in modern color-based ecosystem phenology, where improvements in CO2 flux studies were needed. This application required phenological data about the vegetation season’s start, peak, and end. In a similar way, satellite data began to be used for this purpose in earlier years. Despite that goal, multiple attempts were made to go beyond vegetation indices in both satellites and RGB cameras. They concern the automation of phenological observations, including flowering.
Dixon et al. [
12] detected the flowering of
Corymbia calophylla trees on satellite data using a random forest regression algorithm and ground truth data derived from UAV images from an RGB camera. A satellite pixel resolution of 6 × 6 m allowed for flowering predictions for trees with clearly visible flowers that were abundant and contrasting with the crown greenness, with the purpose of predicting the spatial proportion of flowering.
The research by Dixon et al. is based on earlier attempts at flowering recognition in
Corymbia calophylla. Campbell and Fearns [
40] used ground images of the plant to detect white flowers using pixels with a parallelepiped algorithm. This approach was constrained by a minimal resolution of 10 pixels per flower to accurately distinguish flowering from the background (leaves, stems, branches).
In research by Nagai et al. [
14], Mann et al. [
16], Li et al. [
41], and Taylor and Browning [
15], digital repeat photography derived from phenocameras was used for the flowering analysis; however, the methodologies in those studies vary considerably. In the first one, where the tropical forest canopy was observed, and individual crowns were analyzed, no automation of phenology classification was applied.
In Mann et al. [
16] and Li et al. [
41], the deep learning method (CNN and YOLO, respectively) and phenocamera close-ups were used for the flower detection of small
Dryas spp. subshrubs and
Camellia oleifera, respectively. The first research allowed for the precise definition of the start, peak, and end of flowering; in second yield estimation was based on the detection of plant’s particular growth stages.
Taylor and Browning [
15] presented the machine learning method for the broadest application with data from various agricultural PhenoCam network image time series [
20]. VGG16, a deep learning model, was trained to classify dominant cover types, crop types, and phenological status, including flowering. The image data for training were labeled according to the visual inspection of the images themselves, not based on field observations. Thus, some phenological stages had to be converted into one, including tassels, flowers, and seeds development in the cereal crop type, which in the BBCH scale are stages BBCH5, BBCH6, and BBCH7, respectively.
A combination of ground truth data and digital imagery was the research subject of Nezval et al. [
8] and Guo et al. [
42]. In both studies, vegetation curves calculated from RGB channels for the close-ups of three tree species in floodplain forest [
8] and summer maize field [
42] were compared with the dates of the growth stages obtained by observers at the sites. The former research used the daily aggregated data of green chromatic coordinates for predicting phenology, and in the latter, all the color indices (also aggregated) and relations between pixels were considered.
The mentioned research depicts many possibilities to use and combine various phenological tools. With their resolution, satellites are more suitable for vegetation canopy research than individuals [
12]. Satellite data can cover large areas but with a low resolution, and they suffer due to data noise caused by clouds and/or aerosol presence. RGB cameras, both fixed and movable, can obtain information about the canopy [
14,
15] or individual plants [
8,
14,
16,
39,
40,
41]. However, their cost, in terms of funding and labor, can increase robustly when the research requires multiple cameras [
16] due to the zoomed view or drones needed to operate them [
12]. The way of processing data is also an important issue, as the techniques using large computing power [
12,
16,
41] can reduce the practical usefulness of the method.
Considering all the research above, the method described here presents a novel approach to digital repeat photography analysis. It allows for the utilization of inputs from every single image of the whole year time series, while extracting the ROIs’ averaged data on RGB channels. This is a characteristic simplification of the standard approach in digital repeat photography. While the need for standardization of the phenocamera technique is signalized [
3], there are attempts to reduce the illumination conditions’ effect on the image time series [
43] in the context of vegetation curves reflecting canopy greenness more accurately. However, these undesired types of interferences allow flowering detection, and smoothing noisy vegetation indices would blur the flowering information from the data. Applying a weighted
k-nearest neighbors binary classification algorithm on simplified but not smoothed color indices is computationally efficient compared with deep learning and some other machine learning techniques, allowing the quick and easy performance of the phenological analysis.
4.4. Potential Applications
A presented combination of the methods can be easily applied at sites where conventional observations are carried out, e.g., botanical gardens and arboreta, where plenty of ornamental woody plants are usually present and in the vicinity of each other. Sites with a relatively high density of plants that the camera frame can cover should be suitable to enable a cost-effective comparison of plants from various habitats and with different sensitivity levels to changes in crucial climate factors in one location [
4,
38,
44]. Orchards and nurseries are the other types of sites that can gain from utilizing the presented method. It can allow comparisons between varieties and can be further used to study varieties’ adaptation and resilience to climatic factors. This method uses RGB parameters and data representing the differences between image pixels during flowering caused by the contrast in flowers and the background colors (leaves, branches), expressed by the standard deviation of the RGB features. Hence, the method is worthy of testing in other ecosystems, such as crops, grasslands, and shrub communities, especially with a predominance of one species.
Digital repeat photography enables treating plant development in terms of continuous processes by recording changes in plant visual characteristics in a high frequency, which is particularly desirable in dynamically changing environmental conditions.
Applying the presented method to previously collected image time series, when calibrated using field-reported data, creates an opportunity to extend the long-term flowering study of the plants that are present within the camera frame. Moreover, digital repeat photography can provide a backup dataset for the eventuality of the observer’s importance in research sites beyond simple growth stage determination. Applying this method can potentially reduce the number of research visits, hence reduce human labor costs, and therefore increase the number of studied plant species.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}