
An Overview and Comparison of Traditional Motion Planning Based on Rapidly Exploring Random Trees


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background
2.1. System Dynamics
2.2. Linear Quadratic Regulator
2.3. Control Barrier Functions
2.4. Control Lyapunov Functions
3. The RRT-Based Motion Planning
3.1. The RRT Algorithm and Its Variations
- Sample: The procedure provides independent identically distributed samples from .
- Steer: Given two states , the Steer procedure returns a state that lies between and while maintaining , for a prespecified constant . It is typically defined by
- Nearest node: Given a tree with a set of nodes and a set of edges , the procedure provides a node in that is closest to , i.e.,
- Collision test: Given two points , the procedure returns True if and only if the line segment between and lies entirely within , i.e.,
| Algorithm 1: Body of RRT and RRT* algorithms |
 |
| Algorithm 2: ExtendRRT |
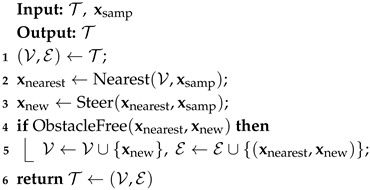 |
3.2. The RRT* Algorithm and Its Variations
- Near nodes: Given a tree with a set of nodes and a set of edges , the procedure utilizes a pre-defined distance to identify a set of near nodes in that are close to . This is typically defined as the set of all nodes within a closed ball of radius centered at , i.e.,where the radius is defined byn is the number of vertices in the tree, d is the dimension of the space, and is a constant.
- Choose Parent: The procedure tries to find collision-free paths between a selected node and all its near nodes, and selects the near node that yields the lowest cost of as the parent of .
- Rewire: The procedure attempts to connect a selected node with each node in its neighborhood . If the trajectory from to the near node results in a lower cost for , then becomes the new parent of .
| Algorithm 3: ExtendRRT* |
 |
4. The RRT-Based Motion Planning with Dynamics
4.1. The LQR-RRT* Algorithm
- LQRNearest: The procedure identifies a node in that is closest to according to the cost function, i.e.,
- Near nodes: the procedure employs the cost function to find a set of near nodes in that are close to , i.e.,where is consistent with Equation (7).
- Steer: Given two states, , the LQR controller generates a sequence of optimal controls that steer a state trajectory from to .
4.2. The CBF-RRT Algorithm and Its Variations
- Safe steer: Given a state , a time horizon , and a control reference , the procedure steers the state to an exploratory new state . Concretely, it generates a sequence of control inputs by solving a sequence of CBF-QPs (Equation (4)) that steers a collision-free trajectory to at time .
| Algorithm 4: CBF-RRT |
 |
- LQR-CBF-Steer: Given two states , the LQR controller generates a sequence of optimal controls that steer a state trajectory from to . The CBF constraints are checked to ensure that the generated trajectory is collision-free. If none of the CBF constraints are violated, then is added to the tree. Otherwise, the trajectory is truncated so that the end state is safe, and the end state is then added to the tree.
5. Experimental Results
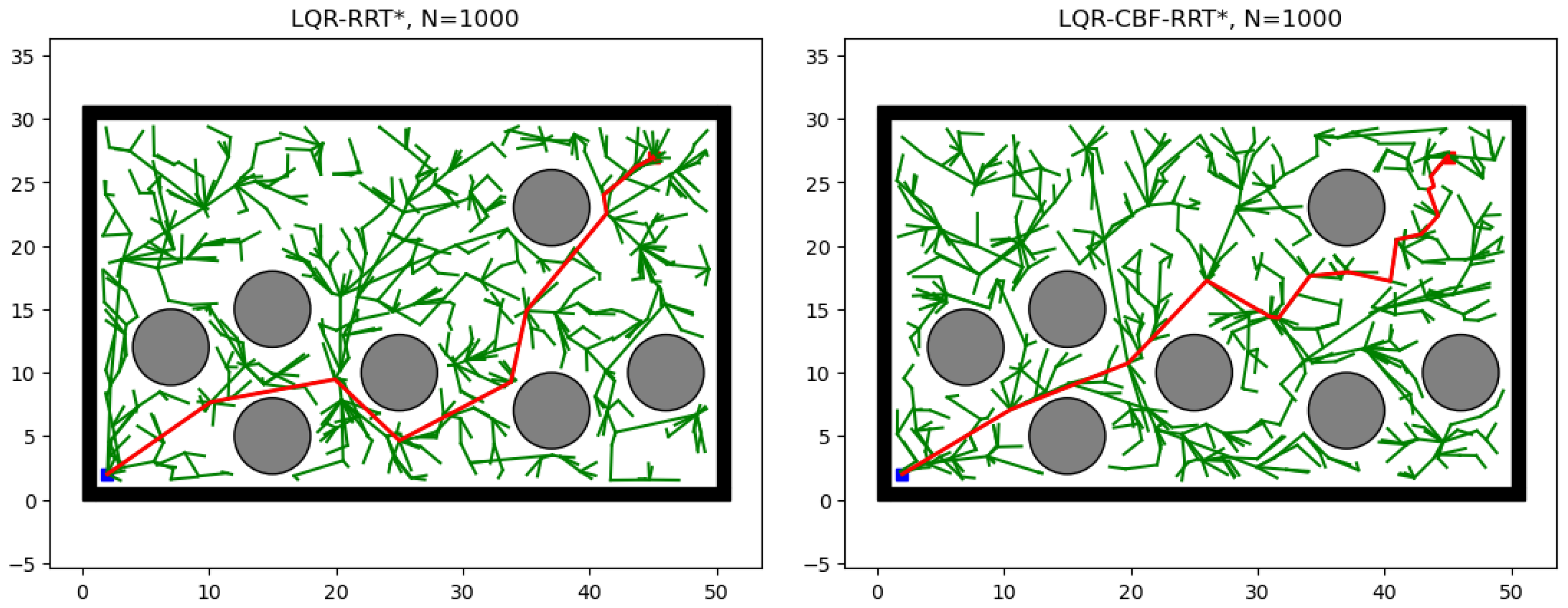
5.1. Path Planning
5.2. Double Integrator Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- González, D.; Pérez, J.; Montero, V.M.; Nashashibi, F. A Review of Motion Planning Techniques for Automated Vehicles. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1135–1145. [Google Scholar] [CrossRef]
- Liu, Y.; Badler, N.I. Real-Time Reach Planning for Animated Characters Using Hardware Acceleration. In Proceedings of the 16th International Conference on Computer Animation and Social Agents, CASA 2003, New Brunswick, NJ, USA, 7–9 May 2003; IEEE Computer Society: Washington, DC, USA, 2003; pp. 86–93. [Google Scholar] [CrossRef]
- Taylor, R.H.; Menciassi, A.; Fichtinger, G.; Fiorini, P.; Dario, P. Medical Robotics and Computer-Integrated Surgery. In Springer Handbook of Robotics; Siciliano, B., Khatib, O., Eds.; Springer Handbooks; Springer: Berlin/Heidelberg, Germany, 2016; pp. 1657–1684. [Google Scholar] [CrossRef]
- Latombe, J. Motion Planning: A Journey of Robots, Molecules, Digital Actors, and Other Artifacts. Int. J. Robot. Res. 1999, 18, 1119–1128. [Google Scholar] [CrossRef]
- Beyer, T.; Jazdi, N.; Göhner, P.; Yousefifar, R. Knowledge-based planning and adaptation of industrial automation systems. In Proceedings of the 20th IEEE Conference on Emerging Technologies & Factory Automation, ETFA 2015, Luxembourg, 8–11 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Lozano-Pérez, T.; Wesley, M.A. An Algorithm for Planning Collision-Free Paths Among Polyhedral Obstacles. Commun. ACM 1979, 22, 560–570. [Google Scholar] [CrossRef]
- Schwartz, J.T.; Sharir, M. On the “piano movers” problem. II. General techniques for computing topological properties of real algebraic manifolds. Adv. Appl. Math. 1983, 4, 298–351. [Google Scholar] [CrossRef]
- Asano, T.; Asano, T.; Guibas, L.J.; Hershberger, J.; Imai, H. Visibility-Polygon Search and Euclidean Shortest Paths. In Proceedings of the 26th Annual Symposium on Foundations of Computer Science, Portland, OR, USA, 21–23 October 1985; IEEE Computer Society: Washington, DC, USA, 1985; pp. 155–164. [Google Scholar] [CrossRef]
- Alexopoulos, C.; Griffin, P.M. Path planning for a mobile robot. IEEE Trans. Syst. Man Cybern. 1992, 22, 318–322. [Google Scholar] [CrossRef]
- Canny, J.F. The Complexity of Robot Motion Planning; MIT Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Brooks, R.A.; Lozano-Pérez, T. A subdivision algorithm in configuration space for findpath with rotation. IEEE Trans. Syst. Man Cybern. 1985, 15, 224–233. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Koenig, S.; Likhachev, M.; Furcy, D. Lifelong Planning A. Artif. Intell. 2004, 155, 93–146. [Google Scholar] [CrossRef]
- Koenig, S.; Likhachev, M. Fast replanning for navigation in unknown terrain. IEEE Trans. Robot. 2005, 21, 354–363. [Google Scholar] [CrossRef]
- Gavrilut, I.; Tepelea, L.; Gacsádi, A. CNN processing techniques for image-based path planning of a mobile robot. In Proceedings of the WSEAS 15th International Conference on Systems, Corfu Island, Greece, 14–16 July 2011; pp. 259–263. [Google Scholar]
- Al-Sagban, M.; Dhaouadi, R. Neural-based navigation of a differential-drive mobile robot. In Proceedings of the 12th International Conference on Control Automation Robotics & Vision, ICARCV 2012, Guangzhou, China, 5–7 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 353–358. [Google Scholar] [CrossRef]
- Engedy, I.; Horvath, G. Artificial neural network based mobile robot navigation. In Proceedings of the 2009 IEEE International Symposium on Intelligent Signal Processing, Budapest, Hungary, 26–28 August 2009; pp. 241–246. [Google Scholar] [CrossRef]
- Zhong, Y.; Shirinzadeh, B.; Yuan, X. Optimal Robot Path Planning with Cellular Neural Network. In Advanced Engineering and Computational Methodologies for Intelligent Mechatronics and Robotics; IGI Global: Hershey, PA, USA, 2013; pp. 19–38. [Google Scholar] [CrossRef]
- Hills, J.; Zhong, Y. Cellular neural network-based thermal modelling for real-time robotic path planning. Int. J. Agil. Syst. Manag. 2014, 7, 261–281. [Google Scholar] [CrossRef]
- Chen, C.; Seff, A.; Kornhauser, A.L.; Xiao, J. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 2722–2730. [Google Scholar] [CrossRef]
- Bansal, M.; Krizhevsky, A.; Ogale, A.S. ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst. In Proceedings of the Robotics: Science and Systems XV, Freiburg im Breisgau, Germany, 22–26 June 2019. [Google Scholar] [CrossRef]
- Zhou, Q.; Gao, S.; Qu, B.; Gao, X.; Zhong, Y. Crossover Recombination-Based Global-Best Brain Storm Optimization Algorithm for Uav Path Planning. Proc. Rom. Acad. Ser. A Math. Phys. Tech. Sci. Inf. Sci. 2022, 23, 209–218. [Google Scholar]
- Roberge, V.; Tarbouchi, M.; Labonté, G. Comparison of Parallel Genetic Algorithm and Particle Swarm Optimization for Real-Time UAV Path Planning. IEEE Trans. Ind. Inform. 2013, 9, 132–141. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J. Trajectory Optimization with Particle Swarm Optimization for Manipulator Motion Planning. IEEE Trans. Ind. Inform. 2015, 11, 620–631. [Google Scholar] [CrossRef]
- Morin, M.; Abi-Zeid, I.; Quimper, C. Ant colony optimization for path planning in search and rescue operations. Eur. J. Oper. Res. 2023, 305, 53–63. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Proceedings of the Proceedings of the 1985 IEEE International Conference on Robotics and Automation, St. Louis, MO, USA, 25–28 March 1985; IEEE: Piscataway, NJ, USA, 1985; pp. 500–505. [Google Scholar] [CrossRef]
- Bahwini, T.; Zhong, Y.; Gu, C. Path planning in the presence of soft tissue deformation. Int. J. Interact. Des. Manuf. (IJIDeM) 2019, 13, 1603–1616. [Google Scholar] [CrossRef]
- Chiang, H.; Malone, N.; Lesser, K.; Oishi, M.; Tapia, L. Path-guided artificial potential fields with stochastic reachable sets for motion planning in highly dynamic environments. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2015, Seattle, WA, USA, 26–30 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2347–2354. [Google Scholar] [CrossRef]
- Zhao, D.; Yi, J. Robot Planning with Artificial Potential Field Guided Ant Colony Optimization Algorithm. In Proceedings of the Advances in Natural Computation, Second International Conference, ICNC 2006, Xi’an, China, 24–28 September 2006; Proceedings, Part II; Lecture Notes in Computer Science. Jiao, L., Wang, L., Gao, X., Liu, J., Wu, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4222, pp. 222–231. [Google Scholar] [CrossRef]
- Hu, Y.; Yang, S.X. A Knowledge based Genetic Algorithm for Path Planning of a Mobile Robot. In Proceedings of the Proceedings of the 2004 IEEE International Conference on Robotics and Automation, ICRA 2004, New Orleans, LA, USA, 26 April–1 May 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 4350–4355. [Google Scholar] [CrossRef]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; TR 98-11; Computer Science Department, Iowa State University: Ames, IA, USA, 1998; Available online: https://msl.cs.illinois.edu/~lavalle/papers/Lav98c.pdf (accessed on 10 December 2024).
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Qureshi, A.H.; Ayaz, Y. Intelligent bidirectional rapidly-exploring random trees for optimal motion planning in complex cluttered environments. Robot. Auton. Syst. 2015, 68, 1–11. [Google Scholar] [CrossRef]
- Gammell, J.D.; Srinivasa, S.S.; Barfoot, T.D. Informed RRT*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2014, Chicago, IL, USA, 14–18 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2997–3004. [Google Scholar] [CrossRef]
- Islam, F.; Nasir, J.; Malik, U.; Ayaz, Y.; Hasan, O. RRT*-Smart: Rapid convergence implementation of RRT* towards optimal solution. In Proceedings of the 2012 IEEE International Conference on Mechatronics and Automation, Chengdu, China, 5–8 August 2012; pp. 1651–1656. [Google Scholar] [CrossRef]
- Kobilarov, M. Cross-Entropy Randomized Motion Planning. In Proceedings of the Robotics: Science and Systems VII, University of Southern California, Los Angeles, CA, USA, 27–30 June 2011; Durrant-Whyte, H.F., Roy, N., Abbeel, P., Eds.; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar] [CrossRef]
- Kuffner, J.J., Jr.; LaValle, S.M. RRT-Connect: An Efficient Approach to Single-Query Path Planning. In Proceedings of the 2000 IEEE International Conference on Robotics and Automation, ICRA 2000, San Francisco, CA, USA, 24–28 April 2000; IEEE: Piscataway, NJ, USA, 2000; pp. 995–1001. [Google Scholar] [CrossRef]
- Jordan, M.; Perez, A. Optimal Bidirectional Rapidly-Exploring Random Trees; Technical Report MIT-CSAIL-TR-2013-021; Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology: Cambridge, MA, USA, 2013. [Google Scholar]
- Webb, D.J.; van den Berg, J. Kinodynamic RRT*: Asymptotically optimal motion planning for robots with linear dynamics. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 5054–5061. [Google Scholar] [CrossRef]
- Perez, A.; Platt, R., Jr.; Konidaris, G.D.; Kaelbling, L.P.; Lozano-Pérez, T. LQR-RRT*: Optimal sampling-based motion planning with automatically derived extension heuristics. In Proceedings of the IEEE International Conference on Robotics and Automation, ICRA 2012, St. Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2537–2542. [Google Scholar] [CrossRef]
- Yang, G.; Vang, B.; Serlin, Z.; Belta, C.; Tron, R. Sampling-based Motion Planning via Control Barrier Functions. In Proceedings of the Proceedings of the 2019 3rd International Conference on Automation, Control and Robots; Prague, Czech Republic, 11–13 October 2019, ICACR 2019; pp. 22–29. [CrossRef]
- Ahmad, A.; Belta, C.; Tron, R. Adaptive Sampling-based Motion Planning with Control Barrier Functions. In Proceedings of the 61st IEEE Conference on Decision and Control, CDC 2022, Cancun, Mexico, 6–9 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4513–4518. [Google Scholar] [CrossRef]
- Hespanha, J.P. Linear Systems Theory, 2nd ed.; Princeton University Press: Princeton, NJ, USA, 2018. [Google Scholar]
- Blanchini, F.; Miani, S. Set-Theoretic Methods in Control, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Xu, X.; Tabuada, P.; Grizzle, J.W.; Ames, A.D. Robustness of Control Barrier Functions for Safety Critical Control. In Proceedings of the 5th IFAC Conference on Analysis and Design of Hybrid Systems, ADHS 2015, Atlanta, GA, USA, 14–16 October 2015; IFAC-PapersOnLine. Egerstedt, M., Wardi, Y., Eds.; Elsevier: Amsterdam, The Netherlands, 2015; Volume 48, pp. 54–61. [Google Scholar] [CrossRef]
- Khalil, H. Nonlinear Systems: Global Edition; Pearson: London, UK, 2015. [Google Scholar]
- LaValle, S.M.; Kuffner, J.J., Jr. Randomized Kinodynamic Planning. Int. J. Robot. Res. 2001, 20, 378–400. [Google Scholar] [CrossRef]
- Yang, G.; Cai, M.; Ahmad, A.; Belta, C.; Tron, R. Efficient LQR-CBF-RRT*: Safe and Optimal Motion Planning. arXiv 2023, arXiv:2304.00790. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Y.; Chen, Q.; Yan, X. An Overview and Comparison of Traditional Motion Planning Based on Rapidly Exploring Random Trees. Sensors 2025, 25, 2067. https://doi.org/10.3390/s25072067
Chu Y, Chen Q, Yan X. An Overview and Comparison of Traditional Motion Planning Based on Rapidly Exploring Random Trees. Sensors. 2025; 25(7):2067. https://doi.org/10.3390/s25072067
Chicago/Turabian StyleChu, Yang, Quanlin Chen, and Xuefeng Yan. 2025. "An Overview and Comparison of Traditional Motion Planning Based on Rapidly Exploring Random Trees" Sensors 25, no. 7: 2067. https://doi.org/10.3390/s25072067
APA StyleChu, Y., Chen, Q., & Yan, X. (2025). An Overview and Comparison of Traditional Motion Planning Based on Rapidly Exploring Random Trees. Sensors, 25(7), 2067. https://doi.org/10.3390/s25072067