Highlights:
Addressing the challenges in the forecasting tasks of non-stationary signals in aircraft engines, a forecasting method using enhanced SAN and LSTM under multi-operating conditions is proposed in this paper. This study adopts a condition recognition technology to identify the operating conditions. L1 filtering is used to extract the trend part and give a quantitative estimation of slice length in enhanced SAN. Furthermore, a tail amendment technology is added to expand the application of enhanced SAN. The validity of the proposed method is verified by the test data of an aircraft engine, and the results show the effectiveness and superiority of the proposed method.
What are the main findings?
- Multi-operating conditions are recognized.
- Slice length is estimated.
- Tail amendment technology is adopted.
What are the implications of the main findings?
- Condition recognition technology identifies the operating conditions and divides the conditions into several models for training and testing.
- Compared with the choices of slice length based on experience in traditional SAN, L1 filtering gives a quantitative estimation of slice length by the second-order difference, offering more specificity towards analyzed data.
- Tail amendment technology expands the application range of enhanced SAN, allowing it to deal with data of different sequence lengths.
Abstract
Trend forecasting and early anomaly warnings are important for avoiding aircraft engine failures or accidents. This study proposes a trend forecasting method based on enhanced Slice-level Adaptive Normalization (SAN) using a Long Short-Term Memory (LSTM) neural network under multi-operating conditions. Firstly, a condition recognition technology is constructed to automatically identify the operating conditions based on the predetermined judgment conditions, and vibration signal features are adaptively divided into three typical operating conditions, namely, the idling operating condition, the starting operating condition and the utmost operating condition. The features of original signals are extracted to reduce the impacts of signal fluctuations and noise preliminarily. Secondly, enhanced SAN is used to normalize and denormalize the features to alleviate non-stationary factors. To improve prediction accuracy, an L1 filter is adopted to extract the trend term of the features, which can effectively reduce the overfitting of SAN to local information. Moreover, the slice length is quantitatively estimated by the fixed points in L1 filtering, and a tail amendment technology is added to expand the applicable range of enhanced SAN. Finally, an LSTM-based forecasting model is constructed to forecast the normalized data from enhanced SAN, serving as input during denormalization. The final results under different operating conditions are the output from denormalization. The validity of the proposed method is verified using the test data of an aircraft engine. The results show that the proposed method can achieve higher forecasting accuracy compared to other methods.
1. Introduction
Aircraft engines play an important role in the aviation industry, and their health status closely relates to the safety and stability of the aircraft. However, aircraft engines are prone to abnormality and failure under varying operating conditions, which may lead to significant economic losses and even casualties. The vibration signals of aircraft engines contain abundant abnormal information. Therefore, vibration signals are critical for vibrational characteristic analysis, which can be used for fault diagnosis [1]. Some indicators of vibration signals, such as vibration features, can reveal the health state of aircraft engines [2]. Generally, when an aircraft engine works in normal conditions, these indicators are relatively stable with small fluctuations. When an aircraft engine shows abnormality and failures, these indicators will undergo significant changes, even sharp increases or decreases. Therefore, we can develop a forecasting method to analyze the trends in vibration signal features and identify early abnormalities, which can provide an early warning of possible machinery faults by referencing the forecasting part, and is significant for ensuring the safety and reliability of aircraft engines [3].
Forecasting methods can be used to estimate future data with historical information. Trend-forecasting methods can be divided into three main types: model-based forecasting methods, knowledge-based forecasting methods and data-based forecasting methods [4]. One precondition of model-based forecasting methods is to obtain an accurate mathematical model and fault model of vibration components. The main advantage of model-based forecasting methods is that they can meet real-time requirements. However, aircraft engine signals are usually found in complex nonlinear vibration systems, and vibration signals and vibration faults are affected by many factors. Therefore, it is time-consuming and laborious to build a suitable and accurate mathematical model [5], which means that model-based forecasting methods cannot be used easily in practical applications. Knowledge-based forecasting methods do not need an accurate mathematical model, making full use of expert knowledge and experience in various subjects. Two typically applied types of knowledge-based forecasting are expert system forecasting and fuzzy logic forecasting [6]. One disadvantage of expert system forecasting is that knowledge bases have limited fault patterns. If no matching rule exists with symptoms in the knowledge base, this can easily result in misdiagnosis or the failure of diagnosis. Fuzzy logic forecasting can use expert knowledge to construct a fuzzy rule base, and can make full use of expert knowledge and experience. However, it is difficult to choose a suitable membership function for fuzzy logic [7]. Data-based forecasting is mainly based on machine learning. A forecasting model can be trained using collected historical monitoring data, and future results can be forecasted by the trained model. Traditional machine learning methods include Support Vector Machine (SVM) [8], Gradient Boosting Regression Tree (GBRT) [9], Extreme Gradient Boosting (XGBoost) [10], Autoregressive Integrated Moving Average (ARIMA) [11], and so on. These methods were applied to data-based forecast methods early on. With the development of deep learning, many deep learning methods have been used to construct forecasting models. Deep neural networks have been widely applied in time series forecasting [12]. Artificial Neural Networks (ANNs) play a significant role in time series prediction due to their universal approximation ability, nonlinear modeling characteristics, and use of data-driven training models [13,14]. A backpropagation (BP) neural network is applied for forecasting as well [15]. The Recurrent Neural Network (RNN) is a typical neural network used in time series forecasting, which can be utilized to capture the temporal dependence by summarizing the past information in the time series [16]. However, some scholars found that RNN suffers from a problem of gradient explosion [17]. The Long Short-Term Memory (LSTM) neural network is utilized to address that problem in RNN [18]. The neural network algorithms used in deep learning, such as Convolutional Neural Network (CNN) [19], the LSTM neural network, and so on, have achieved good results in forecasting applications [20]. Other algorithms like Gated Recurrent Unit (GRU) [21] and the Bidirectional Long Short-Term Memory Network (Bi-LSTM) [22] are developed on the basis of LSTM. Moreover, the appearance of attention has been used to develop a widely used model—Transformer [23]. Many variants have also spawned from this. Informer [24] improves upon the attention mechanism of Transformer to process long sequences more efficiently. Autoformer [25] introduces a decomposition mechanism based on Transformer. DLinear [26] is introduced as a simpler model compared with Transformer. This data-driven prediction method does not rely on establishing accurate prior models, and can be flexibly applied based on historical data, achieving higher prediction accuracy and greater feasibility in handling prediction problems.
However, directly processing the original signal during forecasting will cause the forecasting model to overfit local information to some extent [27]. Generally, the vibration signals collected from the aircraft engine may contain non-stationary factors. Therefore, the difference of distribution between input and horizon series, which is called distribution shift, will reduce the forecasting accuracy. To address the non-stationary forecasting task, a forecasting model with special normalization is needed. Spatial and Temporal Normalization (NST) [28] is one of the special normalization methods that extracts high-frequency components and local components from the original data through both temporal and spatial modules, respectively. However, the distribution of the sequence is considered to be constant in NST. Reversible Instance Normalization (RevIN) [29] is another normalization method that adopts two layers to decompose and forecast the result. Similarly, RevIN has the same drawbacks as NST. The distribution shift in Time Series (Dish-TS) [30] tries to learn the distribution in the future, but the complicated learning stage adversely affects the forecasting result. Among those normalization methods, Slice-level Adaptive Normalization (SAN) [31] uses two-stage training schema, while RevIN and NST use one-stage training schema. The two-stage training schema in SAN independently trains the evolving trend from the statistic property and deals with the forecasting task by divide and conquer, which makes it more robust and suitable for non-stationary tasks. On the other hand, the data at the slice level allows for the better capturing of local distribution in the future. The slice length of SAN is a very important adjustable parameter that affects the forecasting result. Traditional SAN adopts experience values for slice length and lacks the specificity of current data, and this may lead to a poor prediction.
To address these problems, this paper proposes a forecast method based on enhanced SAN using the LSTM neural network, which can be used to predict the trend of aircraft engine performance under different operating conditions. Firstly, a condition recognition technology is used to identify the typical operating conditions of vibration signal features. Secondly, enhanced SAN is used to normalize and denormalize the features to alleviate non-stationary factors. L1 filtering [32] is adopted to extract the trend of the features to capture global information. Moreover, the slice length is quantitatively estimated by the fixed points in L1 filtering, and a tail amendment technology is added to expand the applicable range of enhanced SAN. Finally, an LSTM-based forecasting model is constructed to forecast the normalized data from enhanced SAN, and the data from the LSTM model will be used as the input of denormalization. The final results under different operating conditions are the output from denormalization. The validity of the proposed method is verified by the test data for an aircraft engine. The results show that the proposed method can achieve higher forecasting accuracy than comparative methods in almost all error indicators.
The main contributions of the proposed method are as follows:
- A condition recognition technology is adopted for identifying three typical operating conditions automatically;
- The trend parts of the signals are extracted with L1 filtering in enhanced SAN and the slice length is quantitatively estimated by the second-order difference of the fixed points in L1 filtering;
- A tail amendment technology is used in the last incomplete slice of enhanced SAN, extending the application range of the method.
2. Basic Theory
2.1. L1 Filtering
L1 filtering is a variation on Hodrick–Prescott (H-P) filtering. The characteristic of L1 filtering is that the trend estimates of filtering are smooth in the sense of being piecewise linear, making this an effective method for estimating the trend components that are piecewise linear from time series.
Suppose here that includes the trend part and the residual part , that is, . L1 filtering is used to optimize the trend part and the residual part. The ultimate goal of L1 filtering is that the trend part needs to be smooth and the residual part should be as small as possible. The objective function of L1 filtering can be formulated as:
where X(n) is the feature extracted from the original vibration signal, Y(n) is the trend part of the feature and is an adjusting parameter. The useful information is often contained in Y(n). Meanwhile, the LSTM neural network can perform better with filtered features.
The filtering effect can be determined by adjusting parameter . The larger is, the more smoothly the trend part performs, which means that the filtering can concentrate more on global information, but ignores the detail. Conversely, a small will cause filtering concentrate on local information, but neglect the trend.
Considering the residual part , the optimization objective function can be written in matrix form as
where is the Toeplitz matrix, denotes the L1 norm of , and denotes the L2 norm of Z. is an adjustable parameter, and it controls the proportion of global part and local part.
The signal filtered by L1 filtering will exhibit a piecewise linear feature. The fixed points between different linear parts are dividing points of their respective segments, where the signal in each segment displays a linear feature.
2.2. Slice-Level Adaptive Normalization
SAN is primarily proposed to address the non-stationary data distribution issue. Considering the distribution difference between the input sequence and the horizon sequence, directly normalizing the output part using the input part may cause a prediction bias. SAN uses slicing normalization to remove non-stationary factors and assists the forecasting models in predicting better results with input series. To estimate the evolving distribution for each horizon slice, SAN applies a two-layer perceptron network to learn statistics distribution for a future slice.
We assume that the input series are split into R non-overlapping slices equally, and the horizon series split with the same slice length as well. The statistics prediction [31] procedure with Multi-Layer Perceptron (MLP) can be described as
where and are the mean and standard deviation of R input slices, respectively. denotes the overall mean of input series, while and represent the mean and standard deviation prediction of output slices, respectively. is the normalized series. and are learnable vectors. is MLP layers.
The standard deviation is predicted via a similar method. The error between the statistics prediction parameter and the real statistic parameter is used as the loss function of the backpropagation network. Since the normalization flow of SAN serves in the capacity of a constraint for the forecasting model, the integrity forecast process is a bi-level optimization problem. The overall training procedure can be formulated as
where represents the loss of the forecasting model, represents the loss of statistics prediction, and are weight parameters in the corresponding training procedure, respectively. The primary objective at the upper level is to achieve accuracy in forecasting results with respect to ground truth, and the goal at the lower level is to ensure the similarity in distribution between the normalized output and ground truth.
The training paradigm of the forecasting model with SAN can be decoupled into two stages. Firstly, an estimation of the horizon distribution can be trained by using stochastic gradient descent. Secondly, the forecasting model trains while the statistics prediction model is frozen. The forecasting model can handle the simpler task with normalized data after statistics prediction.
2.3. Long Short-Term Memory Neural Network
The LSTM neural network evolved from the Recurrent Neural Network (RNN). It consists of one input layer, one output layer, and one or more hidden layers. A hidden layer of the LSTM neural network contains many neurons called memory cells. Each memory cell includes three gates: an input gate, an output gate and a forget gate, denoted by , and , respectively. The structure of the memory cell is shown in Figure 1.
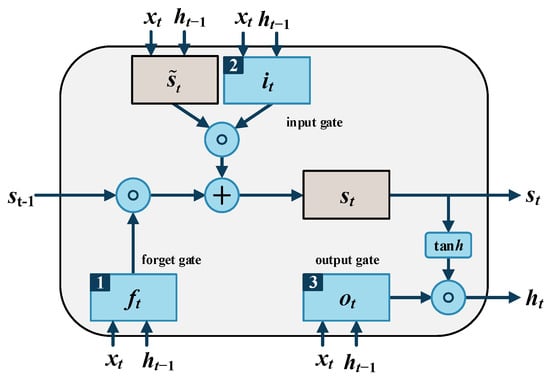
Figure 1.
Structure of LSTM memory cell.
At every t moment, each gate receives and handles the input now and the output from the last moment. The three kinds of gates have different purposes, numbered 1, 2 and 3 in Figure 1. Forget gate decides which information to be deleted and which to commit to memory. The input gate controls the input information. The output gate controls the information delivered to the next memory cell.
Suppose is the input vector at moment t, is the output vector at moment t, , , , , , , and are weight matrixes, , , and are bias vectors, , and are activation vectors, and and represent the state of the cell and the state of the candidate cell, respectively. The calculation of parameters at moment t proceeds as follows.
In the forget gate, the unit decides which part of information is useless based on the current input, the output of the t − 1 time storage unit, and the bias of the forget gate. It calculates the activation vector of the gate at moment t from the input , the output at last moment, and the bias . Then, it scales the activation vector to a range from 0 to 1 via a sigmoid activation function. The calculation procedure can be formulated as
In the input gate, the unit decides which part of the information needs to be added to the state of the cell. Initially, it calculates the state of the candidate cell as
Then, it calculates the activation vector as
After finishing the calculation of the forget gate and input gate, the state of the cell updates as
where is the Hadamard product.
In the output gate, the output vector is calculated via the following formulae
Finally, LSTM updates its weight parameters using these memory cells.
3. Proposed Method Based on Enhanced SAN Using LSTM
The actual aircraft engine vibration signals are often non-stationary and contain random fluctuations, which will reduce the subsequent prediction accuracy. To mitigate the above effects, this paper proposes a trend forecast method-based enhanced SAN using the LSTM neural network under multi-operating conditions. The proposed method mainly contains two sections named condition recognition and enhanced SAN, as follows.
3.1. Condition Recognition
Aircraft engines usually run under varying operating conditions, which makes vibrational signals vary greatly in different distributions. Considering the changes in the operating conditions in aircraft engine vibration signals, a condition judgement is adopted in the proposed method to recognize the operating conditions, enabling the forecasting model to produce the corresponding results under different operating conditions.
To represent the main operating conditions during the operation, three operating conditions are chosen to represent the typical scenario, namely, the idling operating condition, the starting operating condition and the utmost operating condition. The idling operating condition represents the idling state of engine, during which the rotation speed of the aircraft engine is relatively low. The starting operating condition represents the starting state of the engine, when the working mode of the engine changes from the community land mode to the air mode. The utmost operating condition represents the max throttle state of engine, that is, here, the power level angle controlled by the throttle is relatively high.
The discrimination indicators of the idling operating condition include the range of low-pressure rotor speed, the range of high-pressure rotor speed, and fluctuation values of low-pressure rotor speed and high-pressure rotor speed. The discrimination indicators of the starting operating condition include the state mark of the engine state between the entry mark and the exit mark. The discriminations of the utmost operating condition include the range of low-pressure rotor speed, the range of high-pressure rotor speed, and the fluctuation values of power level angle. In addition, the determination of the idling operating condition and the utmost operating condition needs to be maintained for a period of time. The recognition of the starting operating condition will be identified first, followed closely by the idling operating condition recognition, and subsequently by the utmost operating condition recognition.
A condition recognition technology is adopted to identify the operating conditions according to the above discrimination. Additionally, given that original vibrational signal contains noise with fluctuation, the features of the original signal are extracted for forecasting. The vibration total value in the front axle is extracted in the idling operating condition, the second harmonic component in the high-pressure rotor in the front axle is extracted in the starting operating condition, and the vibration component value in the front axle is extracted in the utmost operating condition. These are typical features of aircraft vibrational signals that can reflect the vibrational characteristics of the data. The condition recognition technology identifies the operation condition of the features through a certain length of data. After the recognition of the operating condition, the features of the aircraft engine in the operating condition will be input into the forecasting model under the corresponding operating condition, and will generate the forecasting result.
3.2. Enhanced Slice-Level Adaptive Normalization
To get rid of the effects of local information in traditional SAN, L1 filtering is used to extract the trend part of the original signal in enhanced SAN, which facilitates the calculation of the distribution parameters, with fewer details causing interference.
The actual data of vibration features may possess non-stationary factors, that is, the input series and horizon series may distribute in different levels. The effect of the additional SAN is to mitigate the weakness so that the distribution of the input and horizon parts in every sequence can perform to similar levels. The slice length of SAN is a key adjustment parameter that affects the forecasting result. However, traditional SAN adopts the slice length in experience values, which may lead to a poor prediction.
Moreover, considering that L1 filtering gives data in a linear-part form, the filtered data in each part seem to exhibit proximity in the distribution. The mean and standard deviation of the filtered data will be closer in each part compared with those calculated in a random section. Meanwhile, SAN performs statistics prediction with a fixed slice length, and calculates the estimation of mean and standard deviation in each slice. The mean provides the general scale of the slice, and the standard deviation shows the degree of dispersion. The slice length is an undetermined parameter in SAN, which has a considerable influence on statistics prediction.
To better illustrate the effect of trend extraction by L1 filtering, an example of L1 filtering with different is given. The original data are shown in Figure 2a, and the filtered data with different are shown in Figure 2b, Figure 2c and Figure 2d, respectively.
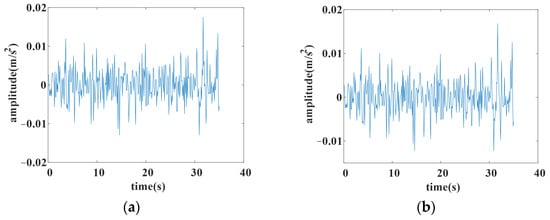
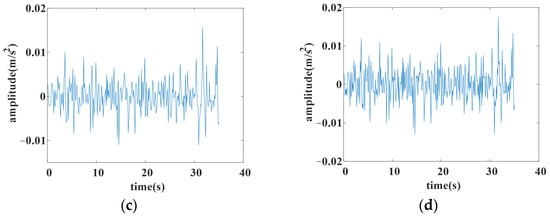
Figure 2.
The result of L1 filtering with different lambda. (a) Original data; (b) filtered with lambda 0.0002; (c) filtered with lambda 0.0005; (d) filtered with lambda 0.001.
Comparing the original data with the filtered ones, it can be argued that the larger is, the stronger the filtering effects, which suggests that the trend part is significantly concentrated. Meanwhile, more detailed information on the original data will be lost with a larger . Thus, should be assigned an appropriate value that can extract the trend part of the original data with less loss of local information. The choice of determines the expected data to predict in the forecasting model.
To give a quantitative estimation of slice length in SAN, a second-order difference D2 of the filtered aircraft engine vibration signal is calculated by L1 filtering,
where is a difference operation and z(x) is the signal filtered by L1 filtering.
The second-order difference D2 is used to find the fixed points, such as the dividing points between the linear parts in Figure 2b, in an obvious way. An example of D2 is shown in Figure 3. It can be easier to find the amount of dividing points that are almost at the peak of the part in the filtered data. Suppose the amount of fixed points of a filtered aircraft engine vibration feature is M, and the length of the original data is L; is regarded as an average interval length, adopted as a quantitative estimation of slice length.
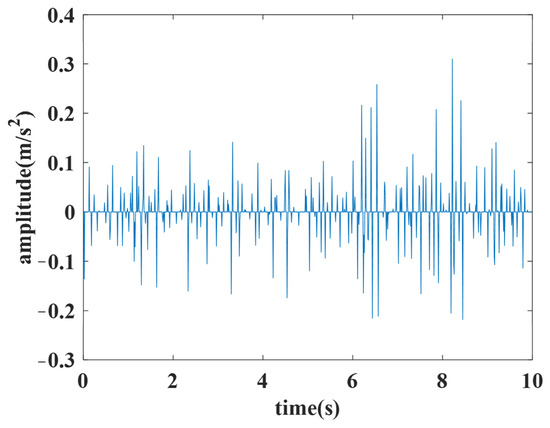
Figure 3.
The second difference of filtered data.
Suppose that slice length is Q; enhanced SAN splits the original series into R slices, where . The mean and standard deviation for each slice can be calculated by
where is the input vibration feature value of slice at moment t, and and are the mean and standard deviation of slice , respectively. Then, enhanced SAN normalizes the slices with the statistic parameters as
where is the normalized feature, is a small constant set to avoid the zero denominator, and is the Hadamard product. The normalized slices are restored data without non-stationary factors that will be input into the forecasting model LSTM.
The statistics prediction of slice statistics can be carried out according to the procedure in Section 2.2, and the results of statistics prediction will be used in the denormalization. In denormalization, enhanced SAN denormalizes the output from LSTM by the results of statistics prediction in Section 2.2, and restores non-stationary factors to give an accurate estimation.
Suppose the output sequence , with forecasting length, as the output from LSTM, where SAN splits the output series into V slices that have the same slice length Q with normalization. The denormalization procedure can be formulated as
where and are the mean and standard in the output of statistics prediction, respectively, and is the final forecasting output.
In addition, considering that SAN requires the sequence length to be an integer multiple of the slice length, the statistic prediction model cannot handle an indivisible length to obtain an integer amount for complete slices. We can directly calculate the statistic prediction results using the final slice with data points in an incomplete slice. However, the output may show large fluctuation, especially in situations with few data points in the last incomplete slice. Insufficient data points may lead to a non-negligible deviation, which will affect the final forecasting accuracy.
A tail amendment technology is adopted to improve this situation. For a sequence length without an integer multiple, an amendment will be used in the last incomplete slice.
Suppose the last incomplete slice has length P, which is less than slice length Q; the added technology will allow a modified calculation of the slice as part of the complete length with amendment. The series X input as slices will be modified. The modified last slice with amendment includes two parts. The former part is calculated by decaying the estimation of the slice before the last incomplete one. The latter part is calculated by the last incomplete slice with amendment. The data points of two parts after amendment can be formulated as
where is the former part of the modified last slice, and is the latter part of the modified last slice. The final modified slice consists of the former part and the latter part in a continuous order, as .
Exponential decay in the former part is used to decrease the effects of the data points with long time steps, which indicates that nearer historical data will have a larger effect on the forecasting result. The length of the former part is the same as Q-P. The length of the latter part is the same as the length of the last incomplete slice. The latter part is calculated with a fixed exponential enlargement. The enlargement is used to emphasize the data in the last incomplete part.
The tail amendment technology can eliminate the unstable effects caused by the last incomplete slice.
The algorithm of the training procedure of ESAN is shown in Algorithm 1.
| Algorithm 1. Implementation of training procedure |
| Suppose: Input series ; horizon series ; 1: Calculate slice length Q by L1 filtering 2: Tail amendment technology 3: Initialize parameters 4: while not converge do 5: for all input , horizon do 6: Compute input statistics by Equation (12) with Q 7: Predict future statistics by Equation (3) using 8: Update using loss function 9: end for 10: end while >Training of the statistics prediction model 11: while not converge do 12: for all input , horizon do 13: Compute input statistics by Equation (12) with Q 14: Normalize input series to by Equation (13) 15: Forecast 16: Predict future statistics by Equation (3) using 17:. .detach(), .detach() >Stop-gradient, freeze the statistics prediction model 18: Denormalize to by Equation (14) 19: Update using loss function 20: end for 21: end while >Training of the forecasting model |
Here, and are weight parameters in the statistic prediction model and forecasting model, respectively.
3.3. Forecasting Model
The original forecasting task is split via a two-stage strategy in enhanced SAN. The first stage is intended to learn the general direction and dispersion of future data with the statistic prediction model in enhanced SAN. The second stage aims to perform the sequential prediction of future data with the normalized data from enhanced SAN. LSTM is used for the second stage subtask, with the help of enhanced SAN for an easier subtask, as the LSTM neural network can perform better with stationary data in a forecasting task.
The training procedure includes the statistic prediction model and LSTM forecasting model. Firstly, the features in three typical operating conditions are put into enhanced SAN. Features are normalized by enhanced SAN and the statistic prediction model is trained. Then, normalized data are set as the input of the LSTM forecasting model, and the LSTM model gives the prediction of future data. Next, the prediction from the LSTM model is denormalized by the output of statistic prediction in enhanced SAN. The data after denormalization are the final result of the forecasting model.
After the training procedure, a validation set is used to adjust the learning rate by the error between the prediction and ground truth. Finally, the trained forecasting model generates the forecasting result in the testing set of the dataset.
The flowchart of the proposed method is shown in Figure 4.
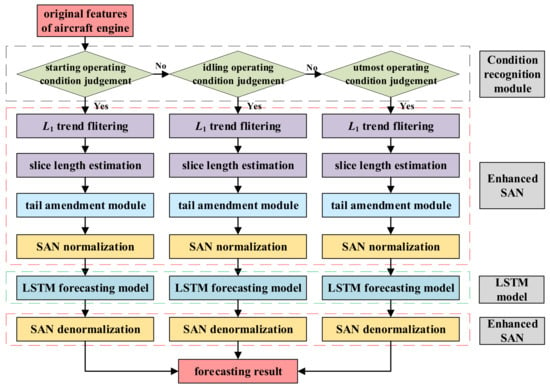
Figure 4.
Flowchart of the proposed method.
4. Performance Analysis of Proposed Methods
To validate the proposed method, aircraft engine data are used to analyze the performance of the proposed method.
4.1. Aircraft Engine Dataset
The dataset comes from the test drive data of a real aircraft engine. The structure of the aircraft engine is shown in Figure 5. In Figure 5, numbers 1–5 indicate the positions of the five main bearings of an aircraft engine.
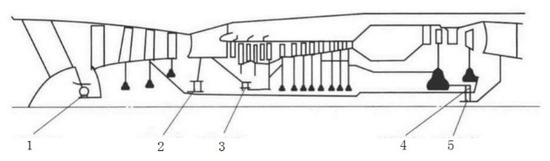
Figure 5.
Structure of an aircraft engine.
The features of the aircraft engine include 8 features in front axle and 8 features in rear axle, amounting to 16 features. The 8 features in the front or rear axle include the vibration total, vibration component, base harmonic component of high-pressure rotor, second harmonic component of high-pressure rotor, third harmonic component of high-pressure rotor, base harmonic component of low-pressure rotor, second harmonic component of low-pressure rotor and third harmonic component of low-pressure rotor. An example of the vibration’s total value in the front axle is shown in Figure 6.
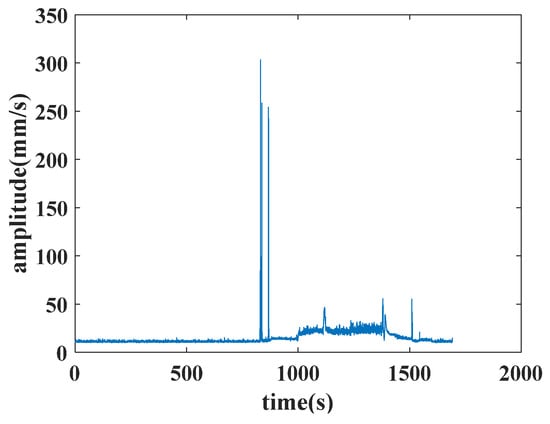
Figure 6.
Example of the vibration’s total value in the front axle.
Each data point of the feature is calculated in 0.2 s. The original features of the aircraft engine contain varying operating conditions. The operating conditions of an aircraft engine vary widely, making it impractical to analyze all of them. Thus, this paper selects three typical operating conditions including the idling operating condition, the start operating condition and the utmost operating condition as the representative operating conditions to process. The discriminations of three operating conditions are set as follows.
The discriminations of the idling operating condition include the low-pressure rotor speed varying within a certain range, the high-pressure rotor speed varying within a certain range, and the fluctuation values of both low-pressure rotor speed and high-pressure rotor speed being less than a threshold.
The discriminations of the starting operating condition include the following: the entry mark requires the state mark of the engine state changing from a certain value to another value; the exit mark requires the state mark of the engine state changing from a certain value to another value; and the start operating condition occurs between the entry mark and the exit mark.
The discriminations of the utmost operating condition include the low-pressure rotor speed and high-pressure rotor speed both varying within a same specific range, the range of the throttle lever angle varying within a certain range, and the fluctuation values of the throttle being less than a threshold. Both the idling operating condition and the utmost operating condition also require 20 continuous seconds.
The analyzed features are the vibration total value in the front axle for the idling operating condition, the second harmonic component value in the high-pressure rotor of the front axle for the start operating condition, and the vibration component value in the front axle for the utmost operating condition. The stitched features extracted from the original features in three typical operating conditions are used for the experiment. The experiment features of the idling operating condition, the start operating condition and the utmost operating condition are depicted in Figure 7.
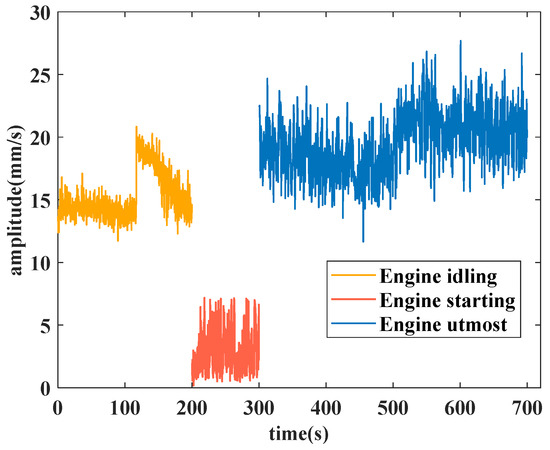
Figure 7.
Extracted features in three operating conditions for the experiment.
Each feature in its operating condition has 1000 data points, wherein the idling operating condition calculates a feature data point every 0.2 s, the starting operating condition calculates a feature data point every 0.1 s, and the utmost operating condition calculates a feature datapoint every 0.4 s. Different time intervals are set to ensure that the density of data meet the requirements in model training.
In the training part of the model, three feature data sets are put into the proposed method separately, and we can obtain three models corresponding to these three different operating conditions. In the idling operating condition, the training dataset is from 0 to 166 s. In the starting operating condition, the training dataset is from 0 to 71 s. In the utmost operating condition, the training dataset is from 0 to 314.4 s.
In the test part of the model, a stitched signal combined with three operating conditions is given to verify the validity of the proposed method. A training partial sequence and the test part of the experiment data are shown in Figure 8.
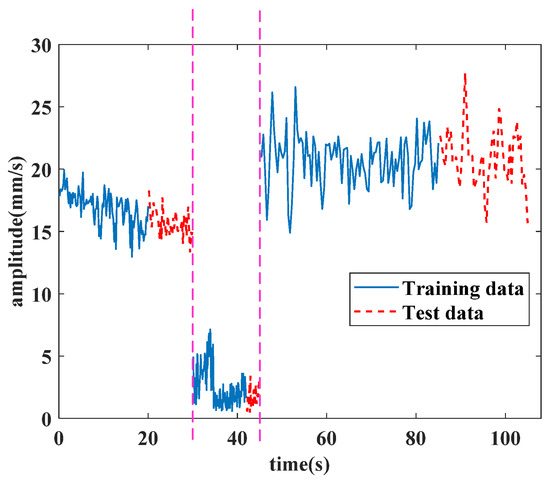
Figure 8.
Stitched data with three operating conditions for the forecasting test.
The three operating conditions’ data are separated by a pink dashed line; the first part is the idling operating condition, while the second part is the starting operating condition, and the third part is the utmost operating condition. The partial training part data, positioned at the end of the training part, are set as the test input for the forecasting result. The test data in Figure 8 are the sequences followed by respective training parts in chronological order. The condition recognition technology identifies the operating condition by this discrimination. Firstly, the technology identifies if the starting operating condition is met or not. Then, it calculates the data in 20 continuous seconds to find the idling operating condition and the utmost operating condition. The values of continuous seconds are adjustable. Besides this, the starting operating condition is also judged by its discrimination. The test parts are the real data used for forecasting, and the lengths of the forecasting sequence are 10 s under the idling operating condition, 3 s under the starting operating condition and 20 s under the utmost operating condition. All the experiments were implemented in Python 3.8 and PyTorch 1.9.0, and were conducted on a single NVIDIA RTX 960 8 GB GPU. The operating system was Windows 10.
4.2. Validation on Tail Amendment Technology
Furthermore, to validate the behavior of the tail amendment technology in enhanced SAN, an experiment with different sequence lengths is carried out. The dataset comprises the data under the idling operating condition. The same settings are used in this experiment as were used in Section 3, except for sequence lengths, which were set as 78, 79 and 80, respectively. The slice length is 5 and the only sequence length in the integer multiple is 80. Enhanced SAN with sequence lengths of 78 and 79 can also be calculated after amendment. The forecasting results for different length are shown in Figure 9.
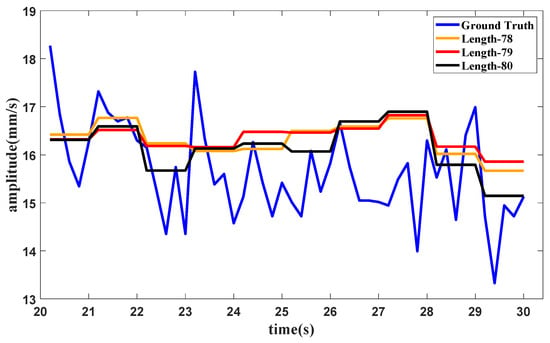
Figure 9.
Forecasting results with different sequence lengths.
It can be seen from the results that datasets with different sequence lengths can achieve approximate performance. The purpose of this amendment technology is to expand the application range of ESAN so that it can handle data with various lengths. The difference between the results is mainly caused by the sequence length itself, which may also be related to the application of the decay part to some extent. In general, the amendment technology can give a robust and accurate prediction, and the application of the amendment technology can extend the use range of enhanced SAN.
4.3. Ablation Study
To evaluate the effectiveness of the components of the proposed method, an ablation study with the aircraft engine signal dataset shown in Section 3 is conducted. The same experimental settings as those in Section 3 are used in this study. The forecasting results are here generated under three typical operating conditions. The vibration total value in the front axle is chosen for the idling operating condition, the second harmonic component value in the high-pressure rotor of the front axle is chosen for the start operating condition, and the vibration component value in the front axle is chosen for the utmost operating condition. The comparison methods involve conducting ablation studies on the method components for SAN or L1. The comparison methods used in the ablation study include SAN+LSTM and L1+LSTM. In SAN+LSTM, the slice length of SAN is set as one of the experimental values, such as 5, 8 or 10. In the proposed method, the slice lengths of enhanced SAN are set to match the amounts of fixed points in L1 filtering, where the slice lengths in the idling operating condition and the starting operating condition are both set as 5, and the slice length in the utmost operating condition is set as 3. The forecasting results of the proposed method and the comparison methods are shown in Figure 10, Figure 11 and Figure 12, respectively.
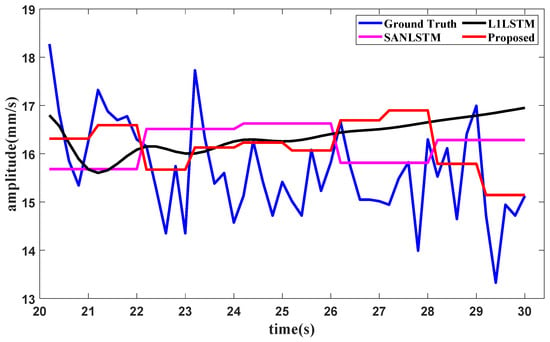
Figure 10.
Ablation forecasting result for the idling operating condition.
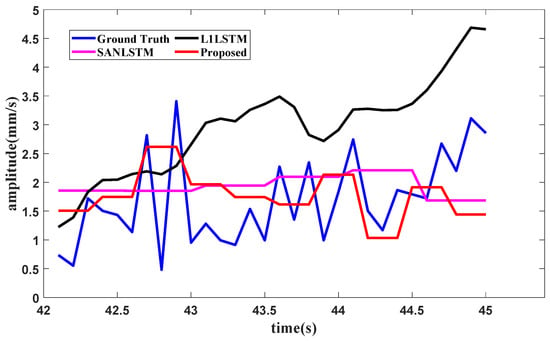
Figure 11.
Ablation forecasting result for the starting operating condition.
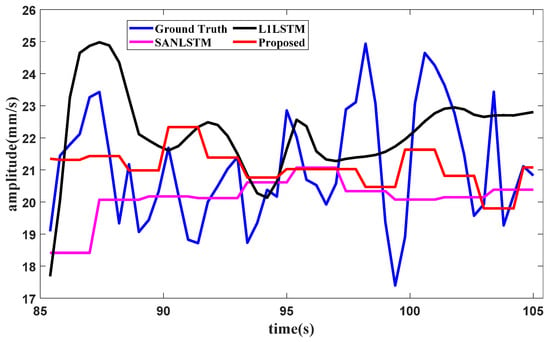
Figure 12.
Ablation forecasting result for the utmost operating condition.
Root Mean Square Error (RMSE) and Mean Absolute Percentage Error (MAPE) are used to measure the forecasting error. RMSE is the root of the mean error in the square. MAPE is the average relative error with an absolute value as a percentage. The smaller the RMSE or MAPE, the higher the accuracy of the forecasting result. An error table of RMSE and MAPE for the comparing methods used in the ablation study is shown in Table 1. The least error in each indicator is bold in the table.

Table 1.
Error of compared methods for the ablation study.
The difference between the result and error for SAN+LSTM and the proposed method shows that L1 filtering benefits the method with SAN, not only via the trend extraction of the filtering, but also via the quantitative estimation of slice length. It indicates that SAN can provide a better prediction that follows the fluctuation of distribution. Therefore, the proposed method can achieve better forecasting results with enhanced SAN.
4.4. Comparison of Forecasting Performance of Different Methods
To show the superiority of the proposed method, three other methods have been employed as comparison methods, namely, SAN+DLinear [31], Transformer [33] and Informer [34]. In SAN+DLinear, the slice length of SAN is set with the experimental values 5, 8 and 10, and the result with the least error is chosen for comparison. In the proposed method, the slice lengths of enhanced SAN are set to match the amounts of fixed points in L1 filtering, where the slice length in the idling operating condition and the starting operating condition are both set as 5, and slice length in the utmost operating condition is set as 3. The batch size is set as 64 in the idling operating condition and the starting operating condition, and in the utmost operating condition, the batch size is set as 32. The learning rate is set as 0.055 and the early stop patience is set as 5.
Suppose that the partial training data in Figure 8 are used to test the forecasting method; when the training data in the first part in Figure 8 are subjected to the proposed method, the condition recognition technology identifies the operating condition as idling, with data provided in 20 s. The forecasting method requires the last 16 s of data for the lookback window, and the forecast result of the total vibration value in the front axle under the idling operating condition is shown in Figure 13.
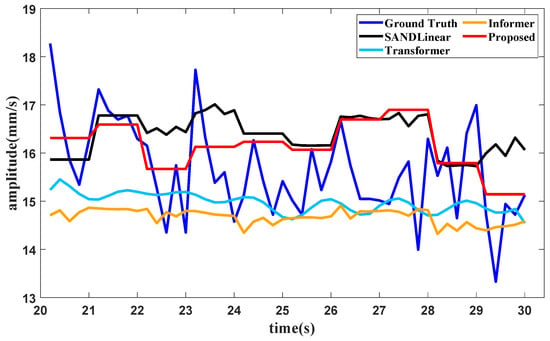
Figure 13.
Forecast results of the vibration total value in the front axle produced with different methods.
A test of the method with different slice lengths under the idling operating condition is conducted. In the proposed method, the slice length is set as 5. The slice lengths are set as 3, 4 and 6 for the methods using SAN, LSTM and tail amendment technology. The results of the methods with different slice lengths in the idling operating condition are shown in Figure 14.
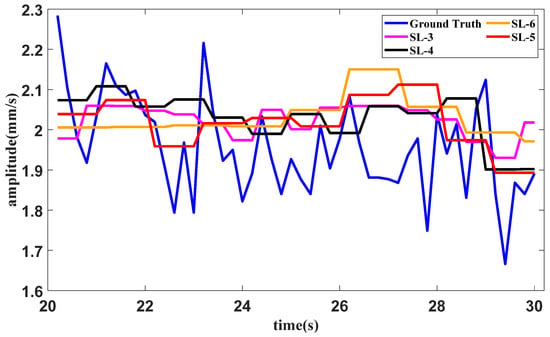
Figure 14.
Forecast results of the idling operating condition with different slice lengths.
The error table of the method in the idling operating condition with different slice lengths is shown in Table 2. The lowest error for each indicator is bold in the table.
Table 2.
Errors of methods with different slice lengths in the idling operating condition.
When it comes to the training data of the second part, the condition recognition technology identifies the operating condition as starting from 30 s to 42 s. The forecasting method needs the last 6 s of data for the lookback window, and the forecasting result of the second harmonic component value in the high-pressure rotor of the front axle under the starting operating condition is shown in Figure 15.
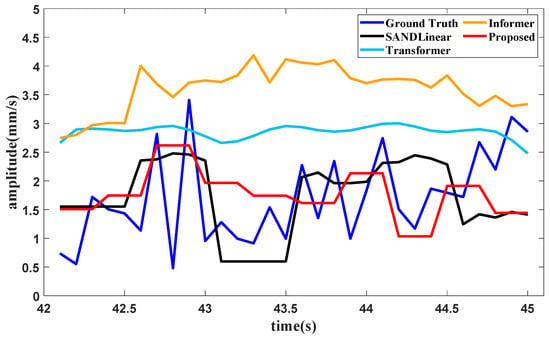
Figure 15.
Forecasting result of the second harmonic component in the high pressure rotor in the front axle.
Similarly, a test of forecasting with different slice lengths under the starting operating condition is conducted. In the proposed method, the slice length is set as 5. The slice lengths are 3, 4 and 6 in the methods containing SAN, LSTM and tail amendment technology. The forecasting result is shown in Figure 16.
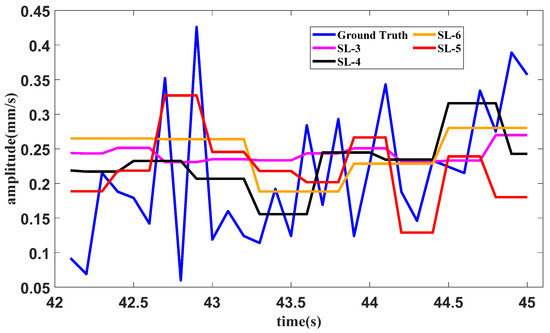
Figure 16.
Forecasting result of the starting operating condition with different slice lengths.
The errors of different slice lengths in the starting operating condition are shown in Table 3. The least error in each indicator is bold in the table.
Table 3.
Error of methods with different slice lengths in the starting operating condition.
When the training data of the third part are input, the condition recognition technology identifies the operating condition as the utmost with data in 20 s, and the data from 45 s to 85 s are all in the utmost operating condition as well. The forecasting method requires the last 32.4 s of data for the lookback window, and the forecasting result of the vibration component value in the front axle under the utmost operating condition is shown in Figure 17.
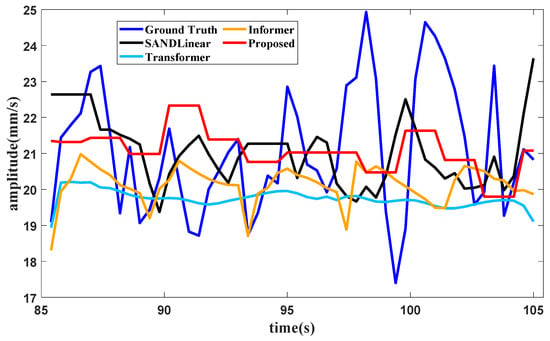
Figure 17.
Forecasting result of the vibration component value in the front axle.
Similarly, a test of forecasting with different slice lengths in the starting operating condition is conducted. In the proposed method, the slice length is set as 3. The slice lengths are further set as 2, 4 and 5 in the methods that contain SAN, LSTM and tail amendment technology. The forecasting result is shown in Figure 18.
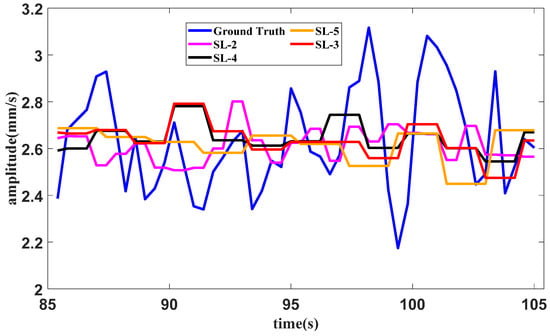
Figure 18.
Forecasting result of the utmost operating condition with different slice lengths.
The errors associated with different slice lengths in the utmost operating condition are shown in Table 4. The least error in each indicator is bold in the table.
Table 4.
Errors of methods with different slice lengths in the utmost operating condition.
It can be seen from Figure 14, Figure 16 and Figure 18, as well as Table 2, Table 3 and Table 4, that the proposed method with the quantitative estimation of slice length by L1 filtering produces the lowest error in half of the ratios. The slice length with the lowest error in the starting operating condition is 4, which is close to the estimation of 3 given by L1 filtering.
The RMSE and MAPE values of different methods of forecasting under three operating condition are shown in Table 5. The least error in each indicator is bold in the table.
Table 5.
Errors of the different forecasting methods.
It can be seen from Figure 13, Figure 14 and Figure 15 and Table 5 that several forecasting methods can basically forecast the features of the vibration signal under the three typical operating conditions of an aircraft engine. The results of Transformer and Informer remain relatively stable. The reason may be that the requirement for a large amount of data is not satisfied, and the standard deviation in normalization is fairly small, affecting the final result. The resultng figures show that SAN+DLinear and the proposed method can produce better predictions under relative operating conditions. It can also be seen in Table 2 that the proposed method can achieve almost the highest accuracy compared with other forecasting methods under different operating conditions.
5. Conclusions
In this study, a trend forecasting method for the vibration signal of an aircraft engine is proposed by combing enhanced SAN using LSTM under multi-operating conditions. The condition recognition technology can identify the idling operating condition, the starting operating condition and the utmost operating condition automatically. To alleviate non-stationary factors in the data, an enhanced SAN is adopted to address the non-stationary data distribution issue, in which L1 filtering is used to extract the trend part of the signal. Furthermore, L1 filtering gives a quantitative estimation of slice length in enhanced SAN using the fixed points, given the greater specificity of the current data compared with previous values. A tail amendment technology is applied to expand the application range of the enhanced SAN. The forecasting results under multi-operating conditions are produced by the forecasting model using LSTM with enhanced SAN. A performance analysis of the proposed method with aircraft engine vibrational signals is conducted to verify the validity of the proposed method, and the following conclusions can be obtained:
- Enhanced SAN with L1 filtering can alleviate non-stationary data effectively, which benefits the forecasting model. The proposed method can forecast the vibrational data in aircraft engines well;
- The tail amendment technology used in the last incomplete slice can achieve a closer result compared with the complete one, widening SAN’s application range;
- The proposed method can achieve higher forecasting accuracy compared with other forecasting methods for aircraft engine features, which shows the effectiveness and superiority of the proposed method.
Author Contributions
Conceptualization, J.L., S.L. and K.Y.; methodology, J.L. and K.Y.; validation, K.Y., W.W. and P.Z.; formal analysis, J.L. and K.Y.; investigation, K.Y. and W.W.; resources, J.L. and P.Z.; data curation, K.Y. and W.W.; writing—original draft preparation, K.Y.; writing—review and editing, J.L. and S.L.; visualization, K.Y.; funding acquisition, J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the National Natural Science Foundation of China grant number 52405113, the Youth Fund project of Natural Science Foundation of Jiangsu Province grant number BK20241401, the Jiangsu Provincial Double-Innovation Doctor Program grant number 202030364 and the Scientific Research Foundation for NUAA grant number YAH20008.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data cannot be made publicly available upon publication because they contain commercially sensitive information. The data that support the findings of this study are available upon reasonable request from the authors.
Conflicts of Interest
Peng Zhang is employed by the company AECC Guiyang Engine Design Research Institute. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Lu, J.; Wu, W.; Huang, X.; Yin, Q.; Yang, K. A modified active learning intelligent fault diagnosis method for rolling bearings with unbalanced samples. Adv. Eng. Inform. 2024, 60, 102397. [Google Scholar]
- Lu, J.; Zhang, C.; Cui, R.; Li, S. Quantitative condition assessment method for rotating machinery using fuzzy neural network. Meas. Sci. Technol. 2024, 35, 086112. [Google Scholar]
- Xia, C.; Yan, Y.; Tan, Y.; Wu, W. Research on forecasting aircraft engine vibration signals based on the MAE model. IEEE Access 2022, 10, 110676–110688. [Google Scholar]
- Jiang, D.; Qian, H.; Wang, Y. Data driven prediction of fatigue residual stiffness of braided ceramic matrix composites based on Latent-ODE. Compos. Struct. 2023, 323, 117504. [Google Scholar]
- Li, Y.; Li, W.; Lei, Y. Residual life prediction of turbofan based on feature enhancement and spatiotemporal information embedding. Appl. Res. Comput. 2024, 41, 1001–1007. [Google Scholar]
- Wang, X.; Niu, R. Spatial forecast of landslides in three gorges based on spatial data mining. Sensors 2009, 9, 2035–2061. [Google Scholar] [CrossRef] [PubMed]
- Lu, F.; Jiang, C.; Huang, J.; You, C. A novel data hierarchical fusion method for gas turbine engine performance fault diagnosis. Energies 2016, 9, 828. [Google Scholar] [CrossRef]
- Mahdi, E.; Leiva, V.; Mara’Beh, S.; Martin-Barreiro, C. A new approach to predicting cryptocurrency returns based on the gold prices with support vector machines during the COVID-19 pandemic using sensor-related date. Sensors 2021, 21, 6319. [Google Scholar]
- Zhan, X.; Zhang, S.; Szeto, W.; Chen, X. Multi-step-ahead traffic speed forecasting using multi-output gradient boosting regression tree. J. Intell. Transp. Syst. 2020, 24, 125–141. [Google Scholar]
- Wang, Y.; Sun, S.; Chen, X.; Zeng, X.; Kong, Y.; Chen, J.; Guo, Y.; Wang, T. Short-term load forecasting of industrial customers based on SVMD and XGBoost. Int. J. Electr. Power Energy Syst. 2021, 129, 106830. [Google Scholar]
- Rose, D.E. Forecasting aggregates of independent Arima processes. J. Econom. 1997, 5, 323–345. [Google Scholar]
- Jan, J.C.; Hung, S.; Chi, S.Y.; Chern, J.C. Neural network forecast model in deep excavation. J. Comput. Civ. Eng. 2002, 16, 59–65. [Google Scholar]
- Panigrahi, S.; Behera, S.H. A hybrid ETS–ANN model for time series forecasting. Eng. Appl. Artif. Intell. 2017, 66, 49–59. [Google Scholar]
- Bennett, C.; Stewart, R.A.; Beal, C.D. ANN-based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar]
- He, S.; Wu, X.; Bai, Z.; Zhang, J.; Lou, S.; Mu, G. Data-Driven Power Prediction for Proton Exchange Membrane Fuel Cell Reactor Systems. Sensors 2024, 24, 6120. [Google Scholar] [CrossRef] [PubMed]
- Zimmermann, H.G.; Tietz, C.; Grothmann, R. Forecasting with Recurrent Neural Networks: 12 Tricks. Neural Netw. 2012, 7700, 687–707. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar]
- Schmidhuber, J.; Hochreiter, S. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and K-means clustering approach. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing, Jeju, Republic of Korea, 13–16 February 2017. [Google Scholar]
- Jin, X.; Lin, L.; Zhong, S.; Ding, G.; Liu, Y. The process neural network method for predicting the vibration trend of aircraft engine. Vib. Test. Diagn. 2011, 31, 331–334+396–397. [Google Scholar]
- Mahjoub, S.; Chrifi-Alaoui, L.; Marhic, B.; Delahoche, L. Predicting Energy Consumption Using LSTM, Multi-Layer GRU and Drop-GRU Neural Networks. Sensors 2022, 22, 4062. [Google Scholar] [CrossRef]
- Mughees, N.; Mohsin, S.A.; Mughees, A.; Mughees, A. Deep sequence to sequence Bi-LSTM neural networks for day-ahead peak load forecasting. Expert Syst. Appl. 2021, 175, 114844. [Google Scholar]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer networks for trajectory forecasting. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 21 May 2021. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient Transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 19–21 May 2021. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In Proceedings of the Advances in Neural Information Processing Systems 34, Montreal, QC, Canada, 7–10 December 2022. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers effective for time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Tang, Y.; Yu, F.; Pedrycz, W.; Yang, X.; Wang, J.; Liu, S. Building Trend Fuzzy Granulation based LSTM Recurrent Neural Network for Long-term Time Series Forecasting. IEEE Trans. Fuzzy Syst. 2022, 30, 1599–1613. [Google Scholar]
- Deng, J.; Chen, X.; Jiang, R.; Song, X.; Tsang, I.W. St-norm: Spatial and temporal normalization for multi-variate time series forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021. [Google Scholar]
- Kim, T.; Kim, J.; Tae, Y.; Park, C.; Choi, J.; Choo, J. Reversible instance normalization for accurate time-series forecasting against distribution shift. In Proceedings of the Tenth International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Fan, W.; Wang, P.; Wang, D.; Wang, D.; Zhou, Y.; Fu, Y. Dish-TS: A general paradigm for alleviating distribution shift in time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Liu, Z.; Chen, M.; Li, Z.; Huang, Z.; Liu, Q.; Xie, Y.; Chen, E. Adaptive normalization for non-stationary time series forecasting: A temporal slice perspective. In Proceedings of the Advances in Neural Information Processing Systems 36, New Orleans, LA, USA, 5–9 December 2023. [Google Scholar]
- Kim, S.; Koh, K.; Boyd, S.; Gorinevsky, D. L1 trend filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar]
- Vakaruk, S.; Karamchandani, A.; Sierra-Garcia, J.E.; Mozo, A.; Gómez-Canaval, S.; Pastor, A. Transformers for multi-horizon forecasting in an industry 4.0 use case. Sensors 2023, 23, 3516. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Li, Z.; Wang, Y.; Dong, D.; Gu, C.; Lou, X.; Zhang, P. Informer model with season-aware block for efficient long-term power time series forecasting. Comput. Electr. Eng. 2024, 119, 109492. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).