Abstract
Frequency-crossing signals are widely found in nature and various engineering systems. Currently, achieving high-resolution time-frequency (TF) representation and accurate instantaneous frequency (IF) estimation for these signals presents a challenge and is a significant area of research. This paper proposes a solution that includes a high-concentration TF representation network and an IF separation and estimation network, designed specifically for analyzing frequency-crossing signals using classical TF analysis and U-net techniques. Through TF data generation, the construction of a U-net, and training, the high-concentration TF representation network achieves high-resolution TF characterization of different frequency-crossing signals. The IF separation and estimation network, with its discriminant model, offers flexibility in determining the number of components within multi-component signals. Following this, the separation network model, with an equal number of components, is utilized for signal separation and IF estimation. Finally, a comparison is performed against the short-time Fourier transform, synchrosqueezing transform, and convolutional neural network. Experimental validation shows that our proposed approach achieves high TF concentration, exhibiting robust noise immunity and enabling precise characterization of the time-varying law of frequency-crossing signals.
1. Introduction
Widely present in fields such as sonar, radar, speech, biomedical science, and geophysics, multi-component non-stationary signals are often composed of different oscillatory components. Some of the component signals carry important information needed for practical applications. Therefore, it is necessary to accurately describe the instantaneous amplitude and frequency of each component signal of a multi-component non-stationary signal, which is conducive to gaining insights into the complex structure of the signal, understanding the system used to generate the signal, and predicting its future behavior. This is of much significance for various applications of the multi-component non-stationary signals [1,2,3,4].
In the analysis and processing of multi-component non-stationary signals, frequency-crossing signals—signals where IFs intersect in the TF domain—are commonly found in fields such as underwater acoustics, radar, and mechanical engineering. Examples of these include dolphin communication signals [5] and continuous-wave radar [6]. The critical challenge in addressing related application issues lies in effectively extracting the IF information from these frequency-crossing signals. TF analysis can be employed to track how frequency information varies over time, thereby aiding in the assessment of non-stationary signals [7,8]. However, the constraints of uncertainty principles and cross-interference terms lead to the low resolution of TF representation and the inaccurate characterization of signal features for various classical linear TF analysis methods such as short-time Fourier transform (STFT), wavelet transform (WT), and chirplet transform (CT) [9], as well as the quadratic TF analysis methods like Wiger Ville distribution (WVD) [7]. Consequently, achieving high accuracy in signal analysis becomes challenging.
In order to enhance the resolution of TF representation and improve the accuracy of information characterization, F. Auger [10] and I. Daubechies [11] proposed the TF rearrangement method and synchrosqueezing transforms (SSTs). Their methods not only achieve highly concentrated TF representations by rearranging or filtering the TF energy or coefficients of traditional TF transforms, such as STFT and WT, but also improve the accuracy of the TF location of non-stationary signals. However, this method can be considered as a post-processing transformation of the traditional methods of TF analysis. Its effect depends on the performance of traditional TF transformation, and it requires that multi-component signals meet certain separation conditions—specifically, that the IFs of each component signal are distinct and separable. Therefore, it is challenging to process the frequency-crossing signals, encountering such problems as the distortion of TF features and energy diffusion.
In recent years, there has been plenty of research conducted on the high-concentration TF representation and instantaneous frequency estimation of frequency-crossing signals. In reference [12], an iterative rearrangement algorithm was proposed to improve the readability of TF representations of intersecting regions. In references [13,14,15], CT was used to transform the signal to be analyzed into a three-dimensional space of time-frequency-chirp rate. This approach successfully separates frequency-crossing signals based on the differences in linear chirp rates (CR) between the components. Similarly, the IF estimation of frequency-crossing signals was achieved in references [5,16] by determining the CR values of the intersecting points of TF ridges. However, the TF basis functions used in these methods are fixed, which limits their effectiveness in feature representation. Currently, deep learning-based TF network methods have attracted widespread attention for obtaining upgradable TF basis functions. In reference [17], a convolutional autoencoder network was applied to enable the high-resolution TF representation of non-stationary signals. This network can automatically reduce the interference from cross-interference terms. For similar purposes, several WVD-based high-resolution TF network models were proposed to minimize cross-interference terms and achieve concentrated TF representation. These include a model that combines skipping 2D convolutional blocks with weighted blocks [18], a semi-supervised learning model based on the Mean Teacher approach [19], and a generative adversarial network [20]. In reference [21], an end-to-end network architecture called TFA net was proposed, with various TF characteristics of signals obtained by learning different basis functions. In reference [6], an AMTFN deep network was proposed to learn basis functions through multi-scale 1D convolutional kernels for the generation of TF feature maps. Then, communication channel attention mechanisms were incorporated into AMTFN to selectively rescale the TF feature maps.
Despite the significant progress made in the analysis and processing of frequency-crossing signals, there are still some outstanding problems. Firstly, current methods often produce inaccurate TF characterization when handling multi-component signals, particularly those with slight variations in CR values under noisy environments. It is still necessary to develop different TF networks that demonstrate strong generalization capabilities and robustess, fast processing time, and suitability for small sample sizes [22,23]. Secondly, the IF extraction algorithms based on TF representation lack adaptive ability. Therefore, it is necessary to set the parameters of the algorithm according to the specific features of the signal. Thirdly, the existing methods of neural network-based frequency-crossing signals analysis mainly focus on achieving high-resolution TF representations. However, they tend to overlook the development of models and networks applicable to extract the IFs of frequency-crossing signals.
To address the issues associated with frequency-crossing signals, a deep learning-based model for high-resolution TF feature characterization and IF estimation is developed. The main contributions of this paper are summarized as follows:
(1) A high-concentration TF representation model based on U-Net [24] is established to analyze frequency-crossing signals, expanding U-Net’s application in signal analysis. Unlike existing WVD-based and TF basis function learning models, the proposed model excludes the influence of cross-terms of WVD and performs feature fusion between low-resolution and high-resolution TF features to capture crucial TF details and reduce the information loss caused by an excessive focus on TF high-concentration.
(2) An IF separation and estimation network is constructed to determine the number of components in frequency-crossing signals and to adaptively extract the crossed IFs.
(3) The advantages of each design in the proposed model are validated through comparative analysis. Experimental studies demonstrate that the proposed approaches yield TF representations with high energy concentration and a noise-free background, successfully identifying the crossed IFs.
The rest of this paper is organized as follows: Section 2 provides a brief review of the frequency-crossing signal model and the STFT. Section 3 and Section 4 introduce the developed networks for high-concentration time-frequency representation and instantaneous frequency separation and estimation, respectively. In Section 5, we present the simulation results along with the processing results for a real bat echolocation signal. Finally, we conclude and discuss our findings in Section 6.
2. Signal Model and Short-Time Fourier Transform
In reality, signals are usually of multi-component, non-stationary nature, which means that the amplitude and frequency of the signals change constantly over time. In mathematics, they can be modeled as the sum of multiple modes of amplitude modulation and frequency modulation, for which they are known as multi-component non-stationary signals. For a P-component non-stationary signal, the mathematical model is expressed as follows:
where and represent the instantaneous amplitude and instantaneous phase of the component signal , respectively, and j represents an imaginary unit. The instantaneous frequency of the k-th component is expressed as .
If there are , and m, n, , such that , for which the signal is referred to as a frequency-crossing signal. Accurately characterizing and separating such signals presents a challenge in non-stationary signal analysis.
In this paper, TF data are created through a simple and intuitive short-time Fourier transform (STFT) without cross-term interference. By applying a window function , time shift and frequency modulation are performed to obtain the TF basis function . Then, the mathematical definition of STFT is established as follows:
where the superscript ∗ denotes the complex conjugate. In this definition, the STFT is the process of extracting the local frequency spectrum of a signal through the window function , which reflects the relationship between the signal’s frequency spectrum and time.
3. High-Concentration TF Representation Network of Frequency-Crossing Signals
Fully convolutional networks (FCNs) [25] can be applied to solve image segmentation problems at the semantic level by classifying images at the pixel level. By replacing the fully connected layers of classic convolutional neural networks (CNNs) with convolutional layers, FCN can accept the input images of any size and output the feature maps of the corresponding size, rather than generating a fixed-length feature vector as was previously done. Through a series of operations such as convolution, downsampling, convolution, upsampling, and deconvolution, FCN can predict each pixel of an input image while maintaining the relative position of features of the original image. Therefore, this method requires fewer training images to complete image segmentation more accurately.
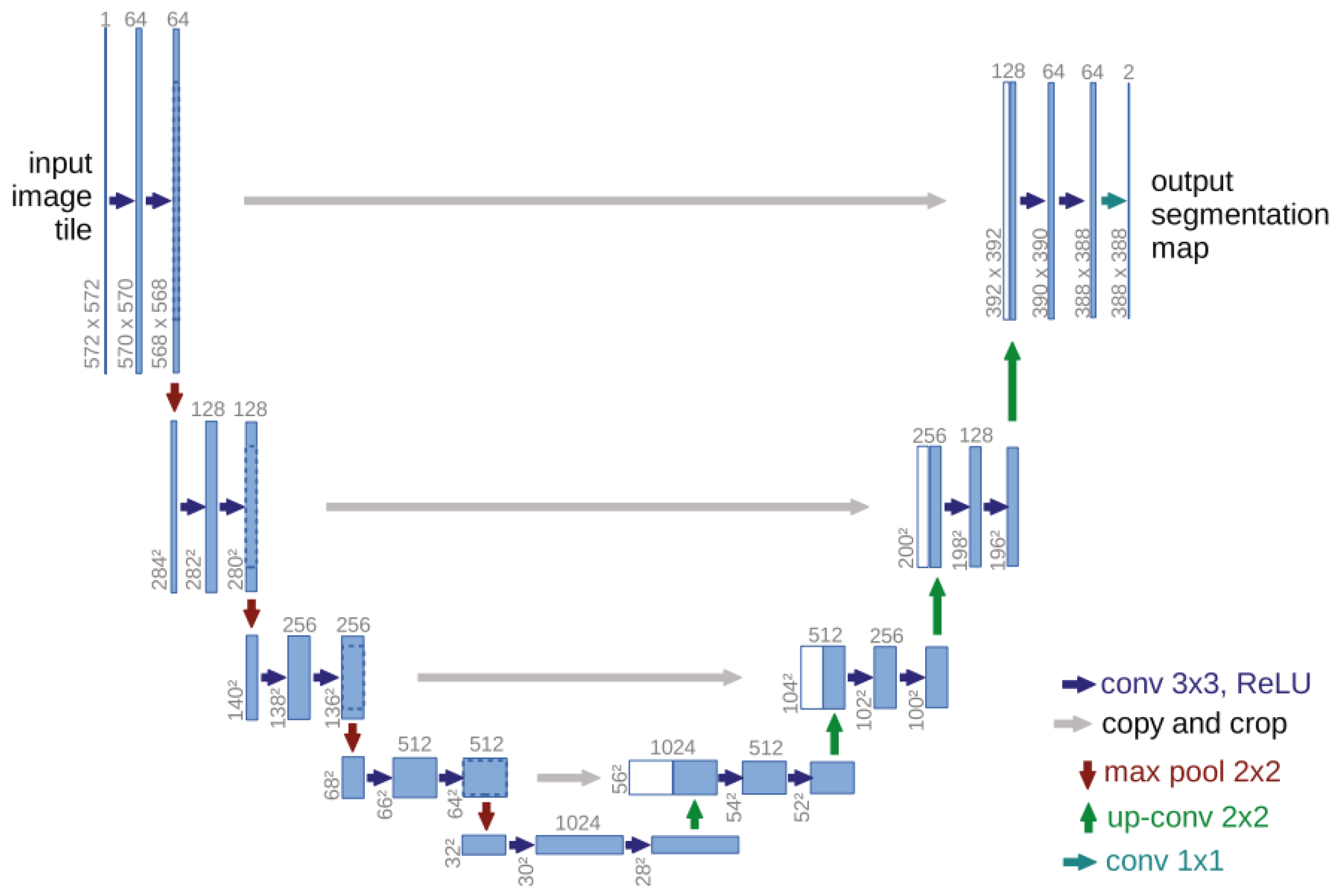
Compared to FCNs, U-Net directly connects intermediate features from the encoder layers to corresponding layers in the decoder, preserving low-resolution details. This architecture enables superior accuracy, computational efficiency, and robustness to noise and low-contrast images [26]. Figure 1 shows the U-net structure.
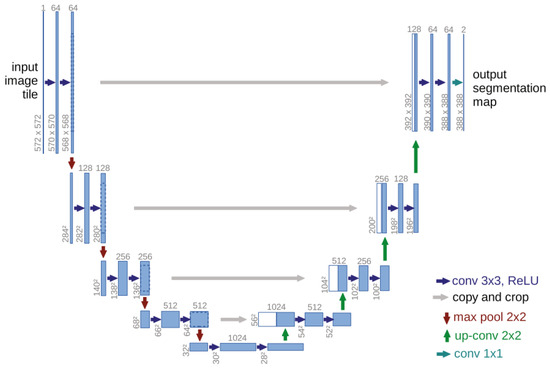
Figure 1.
U-net structure [24].
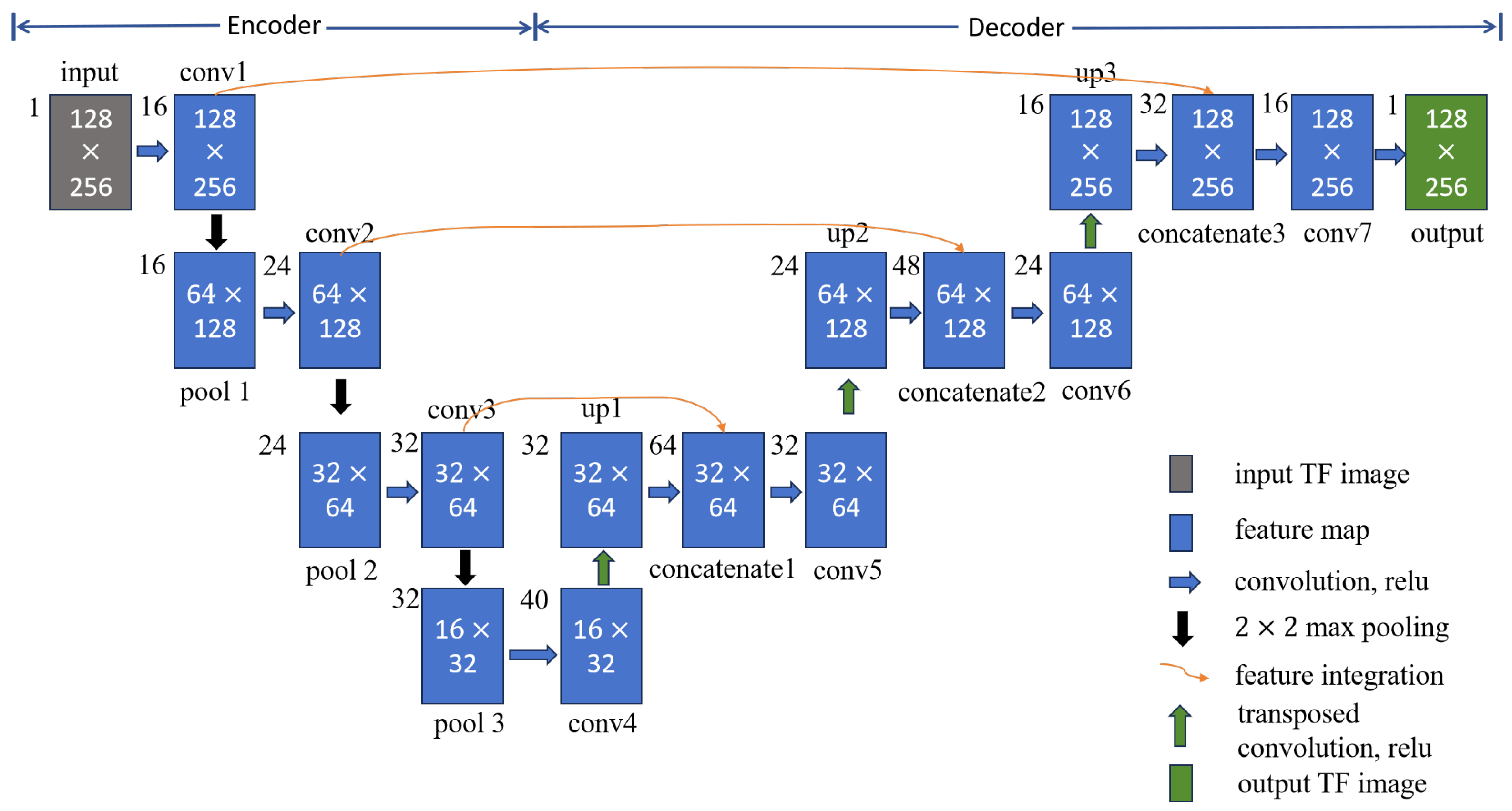
Building upon the advantages of the U-net and its effective applications in medical image segmentation [26], WVD enhancement [27], and infrared small object detection [28], this section extends its design to achieve noise-robust and high-concentration TF representation of frequency-crossing signals. The structure of the developed network, named the high-concentration TF representation network, is shown in Figure 2, using a 128 × 256 TF map as a representative case. When the TF map of energy diffusion is inputted, feature maps are generated through convolutional and pooling layers. Dimensionality reduction is also applied to these feature maps to decrease computational complexity and reduce the risk of overfitting. Following this, transpose convolution and upsampling techniques are employed to restore the size of the feature maps progressively. The feature maps produced through pooling and upsampling, which are of the same size, are then concatenated along the depth dimension to avoid strong energy signal dominance and enhance the detailed features of the TF map. This process of upsampling, concatenation, and deconvolution is repeated until an output image is generated that matches the size of the original TF map.
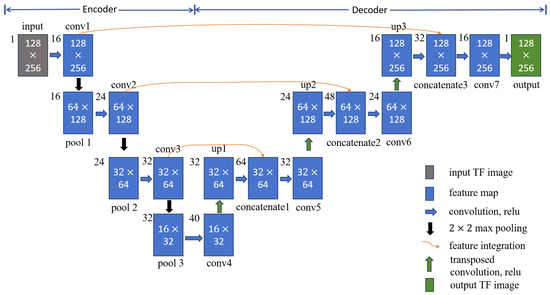
Figure 2.
High-concentration TF representation network architecture.
Indeed, the high-concentration TF representation network is composed of an encoder layer and a decoder layer, as noted in Figure 2. In the encoding layer, there are three convolutional layers (conv1, conv2, conv3) and three pooling layers (pool1, pool2, pool3), with a convolution kernel size of 5 × 5. The decoding layer consists of three transposed convolutional layers (conv4, conv5, conv6) and upsampling layers (up1, up2, up3), which are purposed to extract detailed features. In addition, the network is applicable for performing feature fusion between the pooled feature map and the upsampled feature map (concatenate1, concatenate2, concatenate3), which further supplements the detailed features with a 3 × 3 convolution kernel. Finally, a 5 × 5 convolution kernel (conv7) is used to achieve high-concentration TF representation for the signal of the same size as the original TF map. Table 1 lists the number and size of convolution kernels in the high-concentration TF representation network.

Table 1.
Convolution layer parameters in the high-concentration TF representation network.
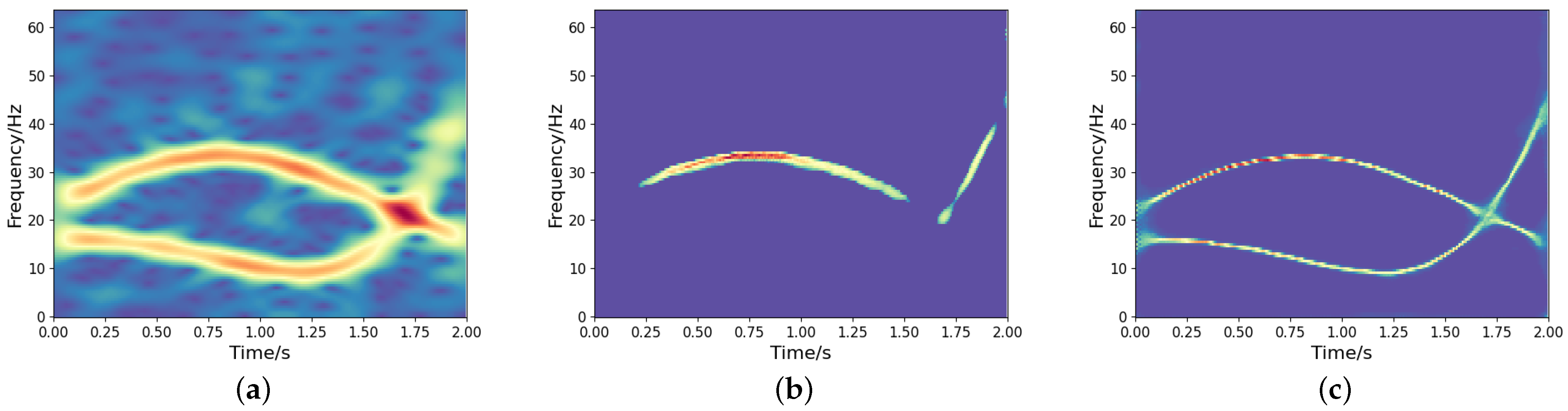
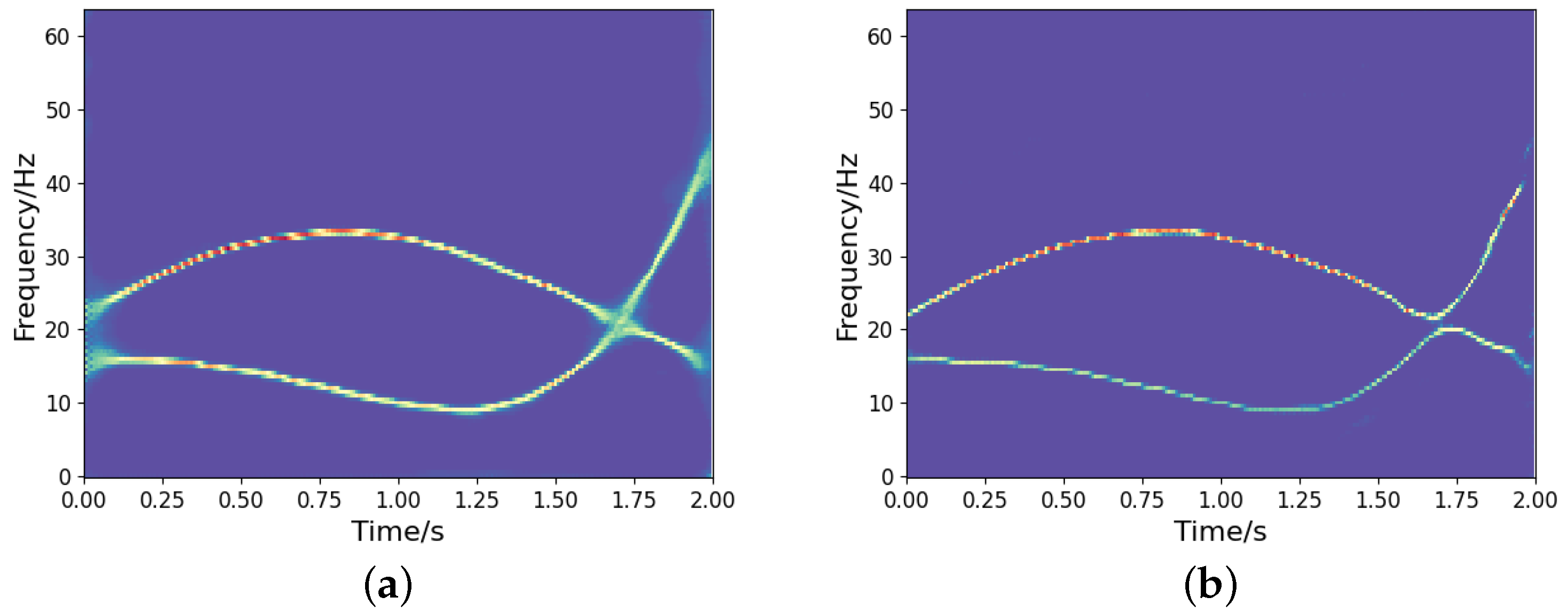
To investigate the impact of the feature fusion (i.e., concatenate1, concatenate2, concatenate3) on TF output, we conduct comparative experiments using two networks: the proposed high-resolution TF representation network and its counterpart without concatenation. A noisy frequency-crossing signal is processed through both architectures, and the STFT of the signal and its experimental results are presented in Figure 3. The results demonstrate that feature fusion effectively utilizes low-resolution TF features while suppressing the information loss associated with the one-sided pursuit of high-concentration of strong energy parts, resulting in an accurate and concentrated TF distribution. This highlights its crucial role in maintaining coherent TF representations under noisy conditions.
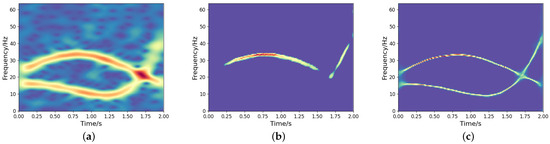
Figure 3.
TF analysis of a noisy frequency-crossing signal. (a) The STFT of the signal; (b) TF output without concatenation; (c) TF output by the proposed model.
4. Instantaneous Frequency Separation and Estimation Network
Given the IFs of a signal, the instantaneous amplitude of the signal can be determined by solving the least squares problem:
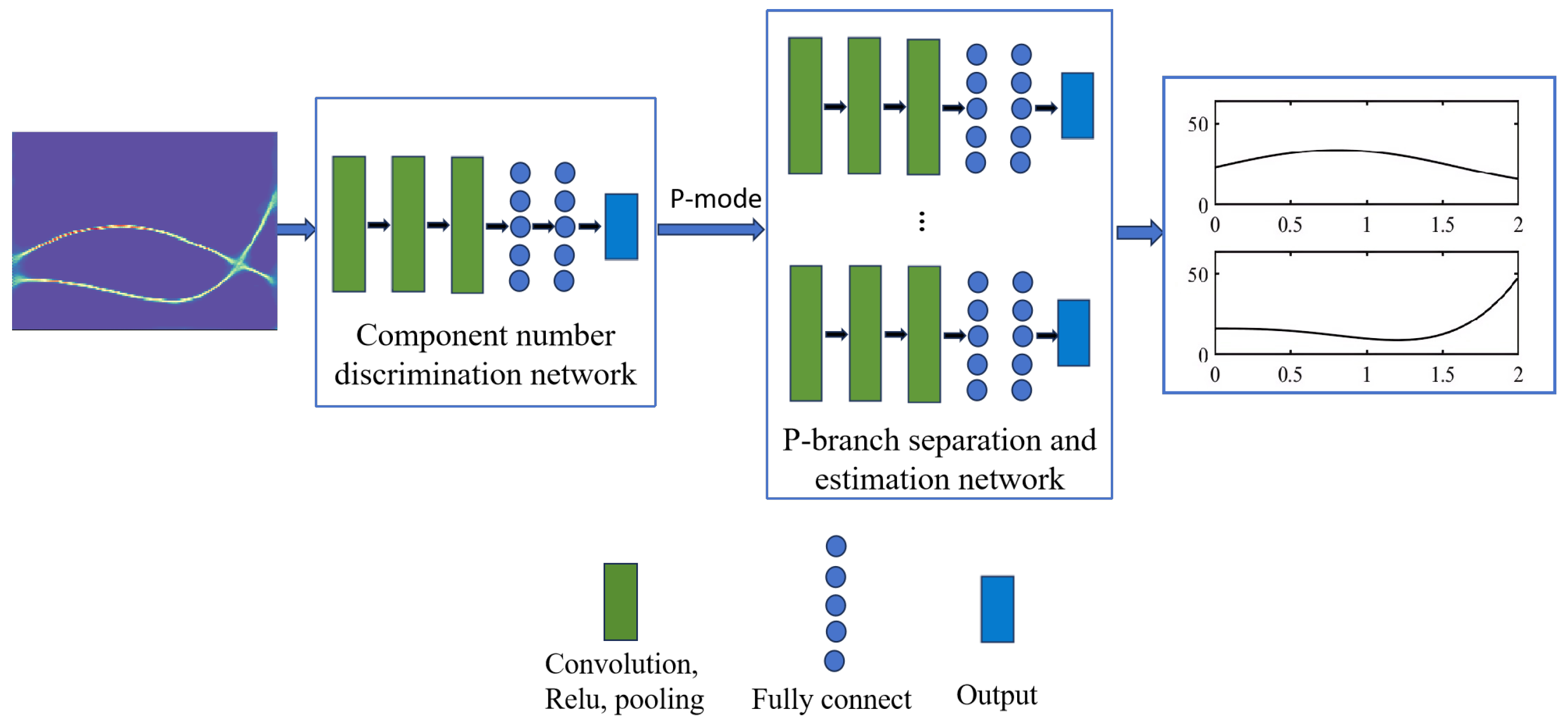
In this equation, , , and denote the discrete signal, amplitude, and phase after sampling, respectively. The function indicates the diagonalization of the vector, while denotes the transposition. Therefore, accurately estimating the IF of a frequency-crossing signal is essential for analyzing non-stationary signals. However, unlike the research on high-resolution TF analysis of frequency-crossing signals, less attention has been paid to exploring the instantaneous information extraction methods for crossing signals. In light of this section, an IF separation and estimation network is proposed for frequency-crossing signals. Firstly, a discriminative network is constructed to determine the number of signal components. On this basis, an IF separation and estimation network suitable for frequency-crossing signals is built to extract the IF of each component of a signal. The architecture of the developed network is illustrated in Figure 4.
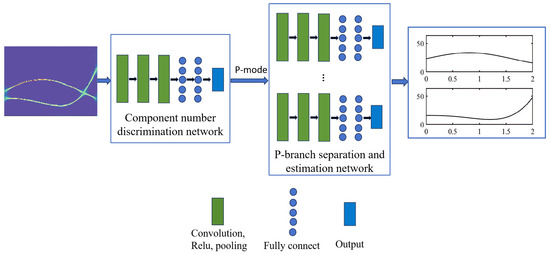
Figure 4.
The architecture of the developed network for IF detection.
4.1. Determination of Number of Components
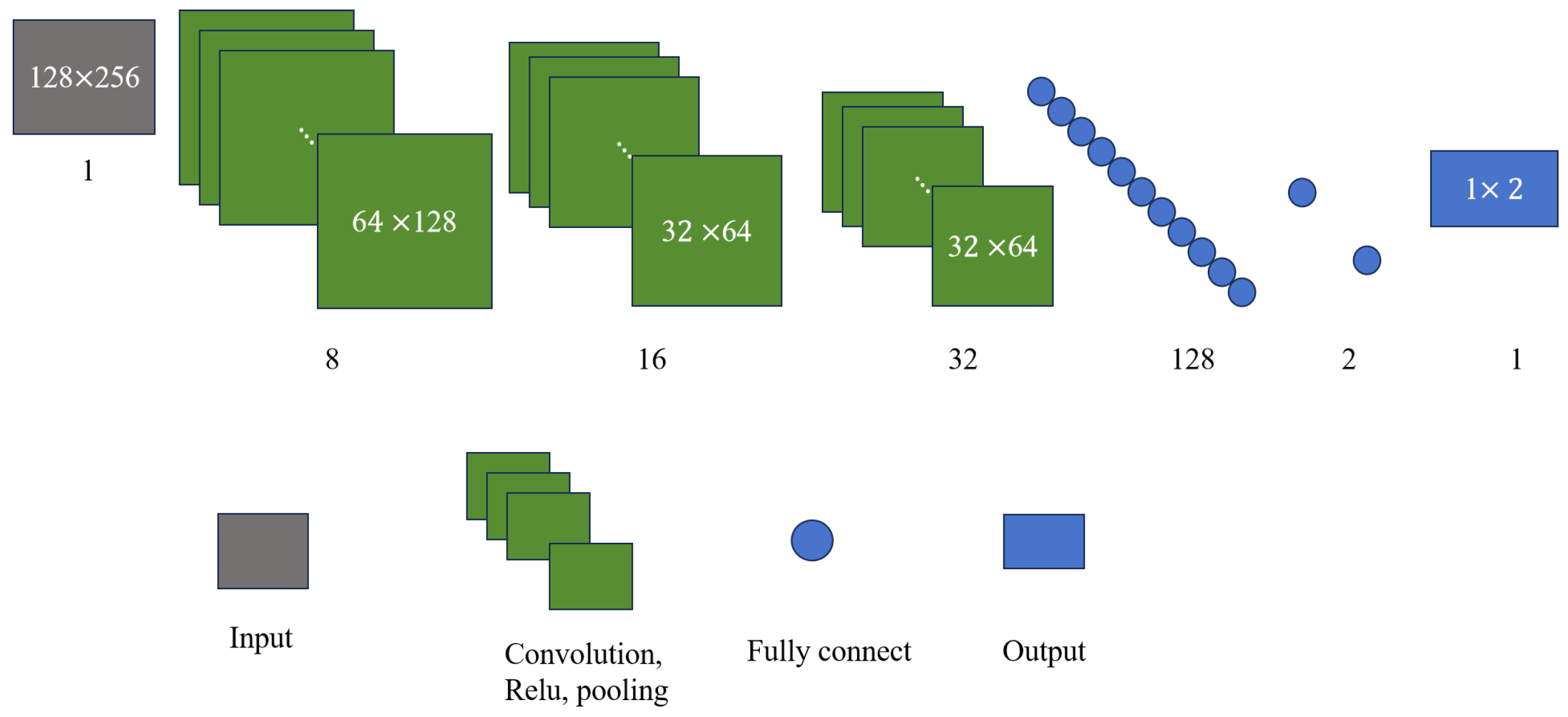
In this section, a CNN model is established to determine the number of components in a multi-component frequency-crossing signal and to confirm the number of branches to be used in the separation model. Assume that the number of components in a signal is 2 or 3 and that the input of the model is a 128 × 256 high-concentration TF image. Building on this, we construct the component number discrimination network, as illustrated in Figure 5. The network consists of three convolutional layers, each followed by pooling layers, using a 3 × 3 convolution kernel. After a fully connected layer is passed through, the features are mapped into a vector that represents the probability value of the number of components.
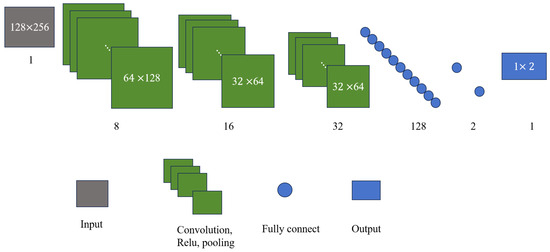
Figure 5.
Component number discrimination network for two-component signals.
4.2. Extraction of Instantaneous Frequency
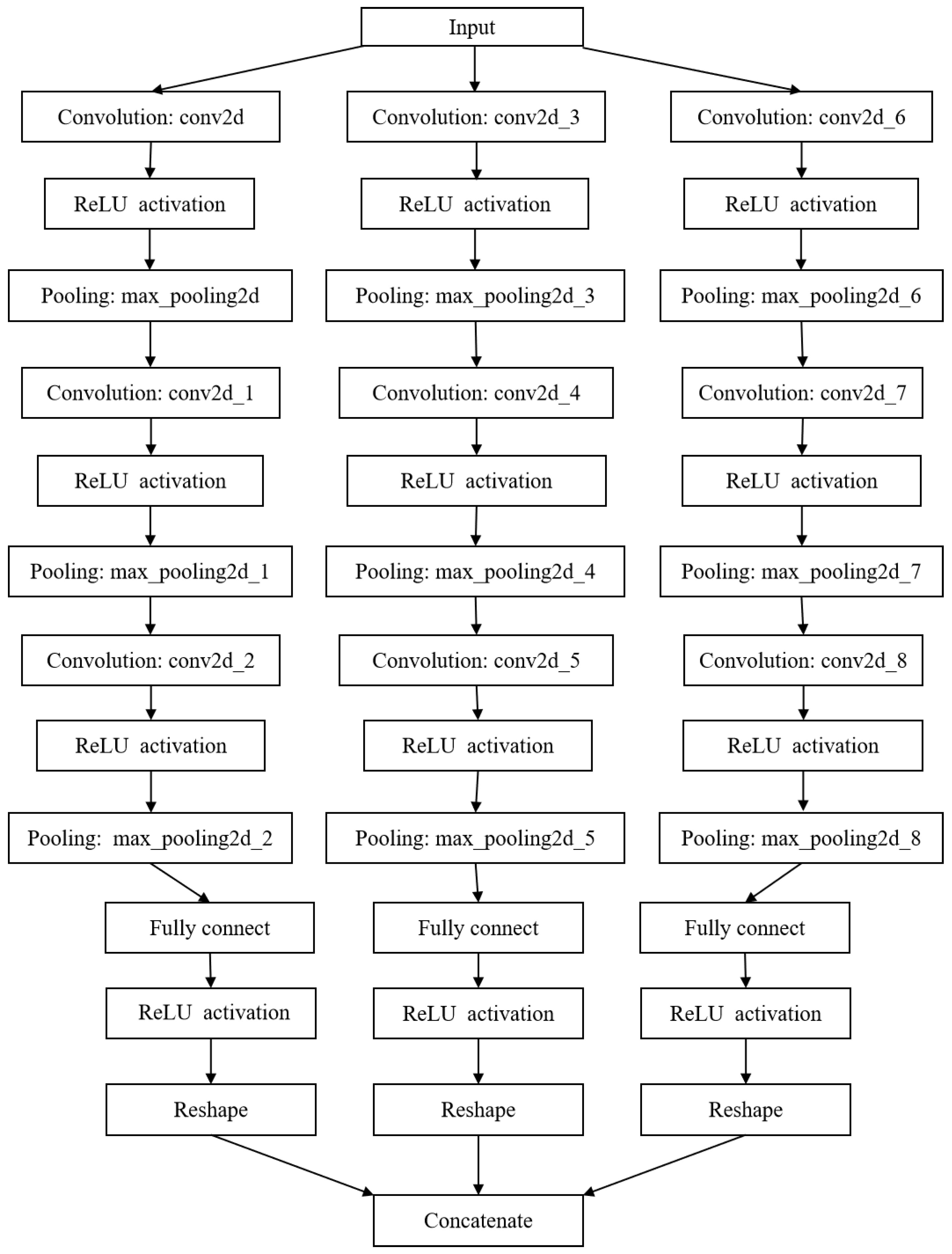
As described in the previous section, the number of components in a multi-component signal can be determined with the component number discrimination network, which is set as P. A P-branch separation network is constructed to separate the IF information of each component signal from the high-concentration TF representation. Each branch consists of a convolutional layer, a ReLU activation layer, and a max pooling layer. The TF features are mapped into a vector of the same length as the signal passes through the fully connected layer. Finally, the vector is concatenated into an IF estimation matrix, as illustrated in Figure 4. Figure 6 shows the basic architecture of the IF separation and estimation network of a frequency-crossing signal with three components. This network involves three single-branch models. Table 2 lists the parameter settings of the model’s convolutional layer.
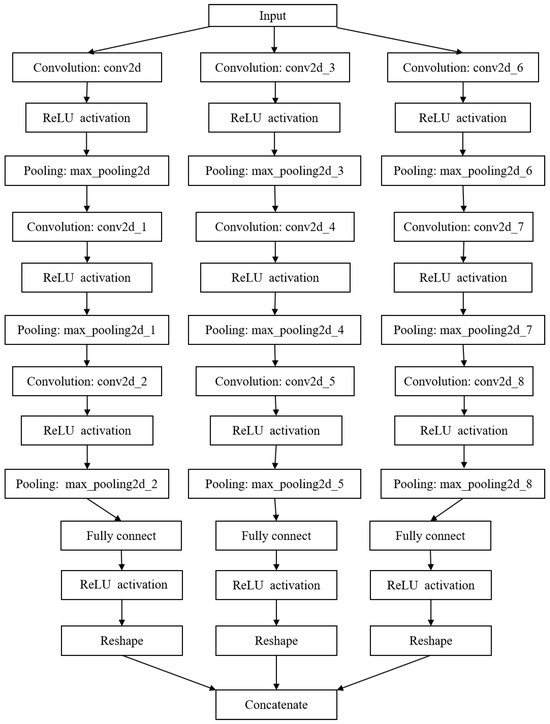
Figure 6.
Instantaneous frequency separation and estimation network for three-component signals.
Table 2.
Convolution layer parameters in the IF separation and estimation network.
5. Network Training and Numerical Results
5.1. Data Generation
This paper focuses on two-component and three-component signals using a mathematical model that is expressed as follows:
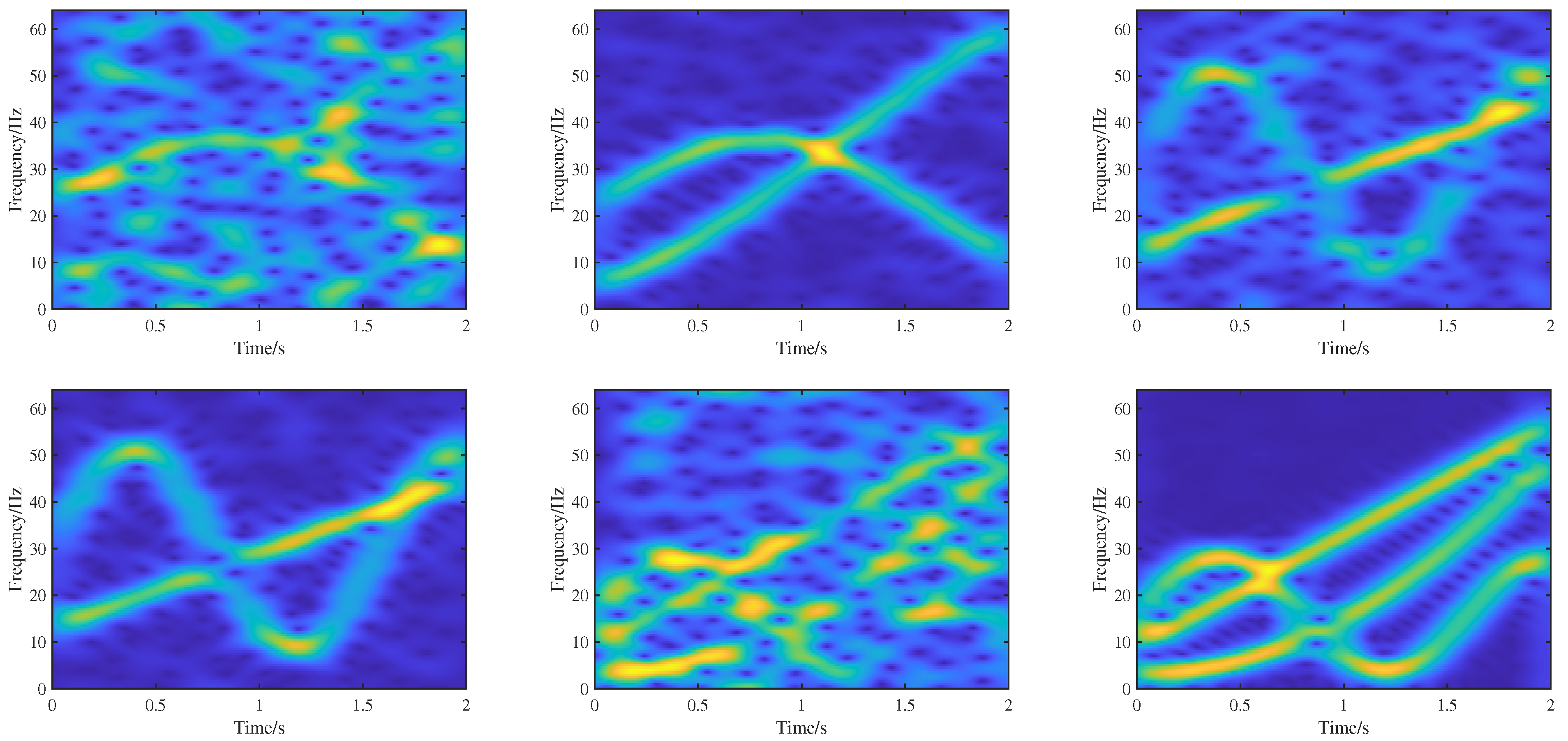
where is the Gaussian noise, the signal sampling frequency is set as 128 Hz, with a sampling duration of 2 seconds, are signal parameters randomly generated from [−20 50] making the true IF values between 0 and a half of the sampling frequency. For each group of signals, there are 10 different signal-to-noise ratios (SNRs) of noise signals, including −10 dB −5 dB, 1 dB, 5 dB, 10 dB, 15 dB, 20 dB, 25 dB, 30 dB, and 35 dB. The total number of sample signals is 10,000. The STFT with a Hanning window (57 points) is performed on these signals to generate 10,000 TF images with a size of 128 × 256. With 9000 images taken as the training set, the remaining 1000 images are taken as the validation set. During the training process, we utilize ideal TF representations as labeled data for the high-concentration TF representation network, while real IF information served as labeled data for the IF separation and estimation network. Figure 7 shows six TF training samples.
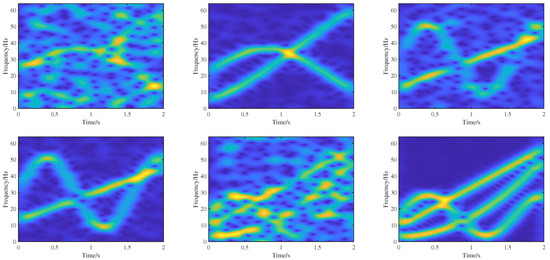
Figure 7.
Six TF images featuring different models and noise levels.
5.2. High-Concentration TF Representation Results
The loss function used in this section is the mean square loss (MSE) function, of which its formula is expressed as follows:
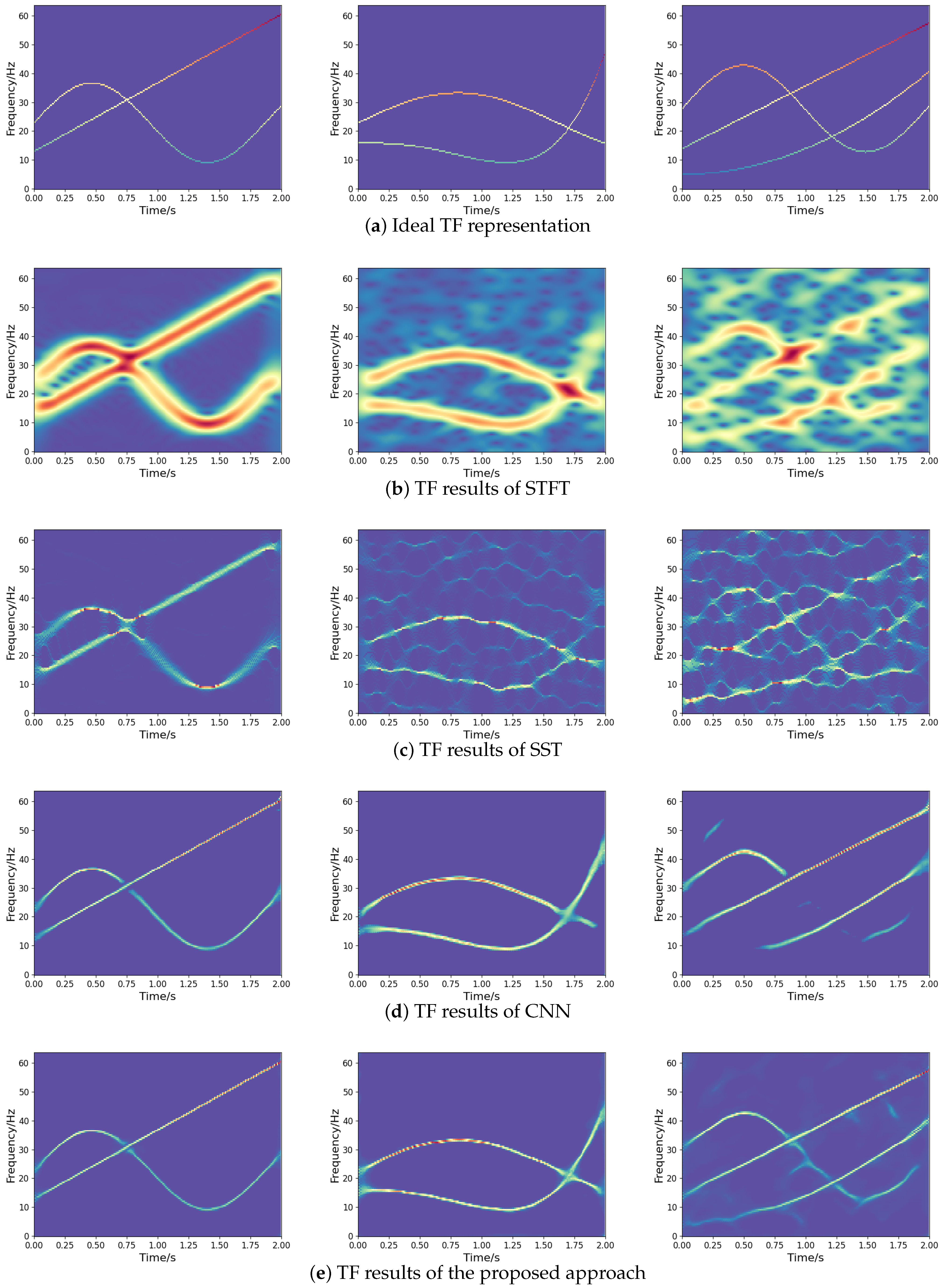
where denote the output, and denote the ideal TF representation, as presented in Figure 8a. The optimizer relies on Adam for optimization, with an initial learning rate of 0.001. During the training phase, the dataset is divided into batches of 32 and trained 500 times. In order to better demonstrate the effectiveness of the network, the experimental results are compared with STFT, synchrosqueezing transform (SST) [11], and TF network based on CNN [17] (abbreviated as CNN). The experimental results are presented in Figure 8.
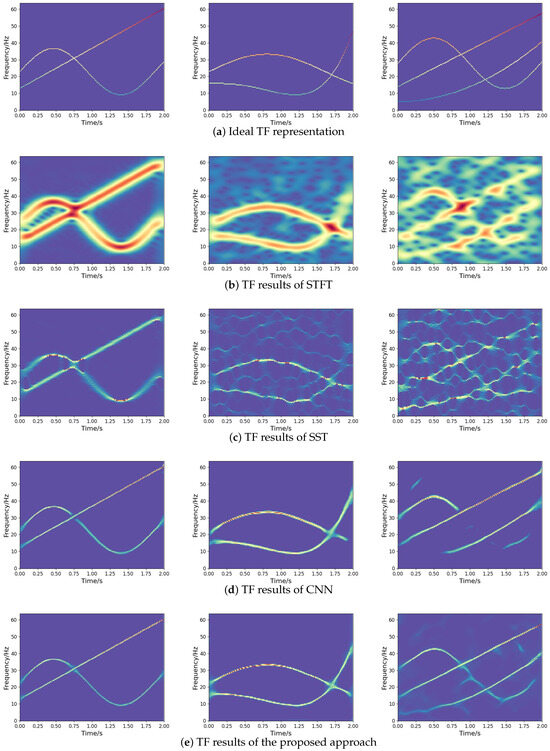
Figure 8.
TF representations of different methods for noisy frequency-crossing signals.
As revealed by the numerical experiments, the STFT method leads to a lower TF resolution for frequency-crossing signals, while the SST method improves the TF resolution of STFT. In spite of this, some problems remain, such as energy diffusion and feature blurring. Obtained by inputting the TF dataset generated in this paper for training, the experimental results of CNN are not as expected, due to energy diffusion and information loss. Compared to other methods, the method proposed in this paper is more effective in TF representation, which improves the TF concentration greatly and enables a better characterization for noisy frequency-crossing signals. This contributes an effective approach to the information representation of multi-component non-stationary signals.
For the quantitative evaluation of TF analysis methods, we assess the time cost, mean absolute error (MAE), and Rényi entropy. The smaller the MAE, the closer the output is to the ideal one, and a lower Rényi entropy value indicates a more energy-concentrated TF representation, as discussed in [22]. The results are summarized in Table 3, where we apply these methods to the second two-component signal shown in Figure 8. The findings illustrate that TF networks, such as CNN and our proposed approach, increase the computational complexity of the traditional method of TF analysis. However, the proposed approach requires less time to represent the signal than CNN. Moreover, the proposed approach has lower MAE and Rényi entropy, which indicates better TF location and energy concentration than STFT, SST, and CNN.
Table 3.
Time cost, MAE, and Rényi entropy of the four TF representations in addressing the signal, where ·/step indicates the average processing time of each batch.
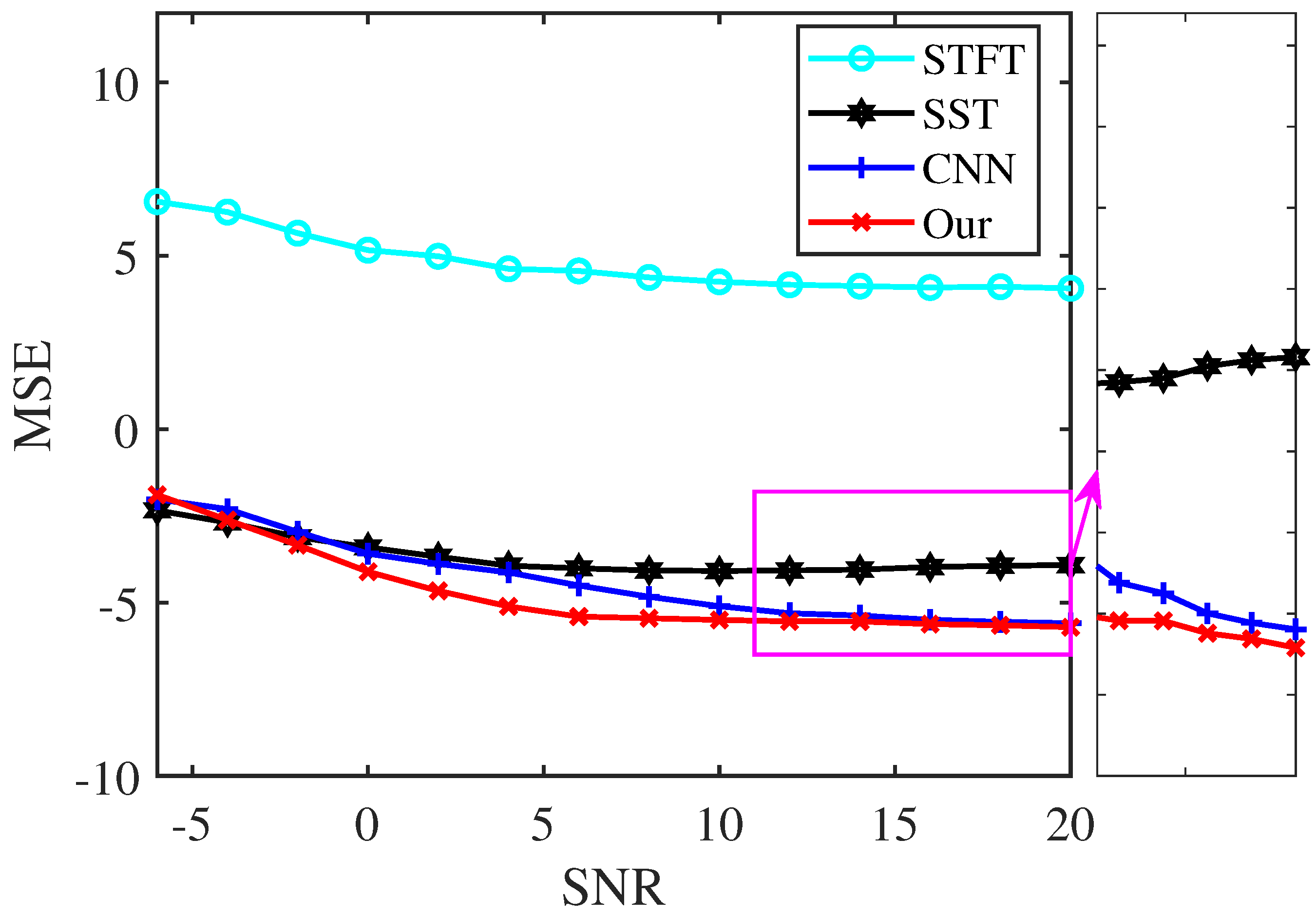
To test the noise robustness and characterization accuracy of our proposed approach, we use the MSE to compare the performance of the analysis methods under different SNRs. The test signal of the following model is processed:
The sampling frequency is 256 Hz, and the signal is over a time interval of [0, 2 s]. Figure 9 displays the logarithmic MSEs between the TF representations by the four analysis methods and the ideal one, applied to signal (6) at various noise levels. The results demonstrate that our proposed method achieves smaller MSEs than STFT, SST, and CNN within the SNR range of −4 dB to 20 dB, indicating a more accurate TF location in characterizing the signal.
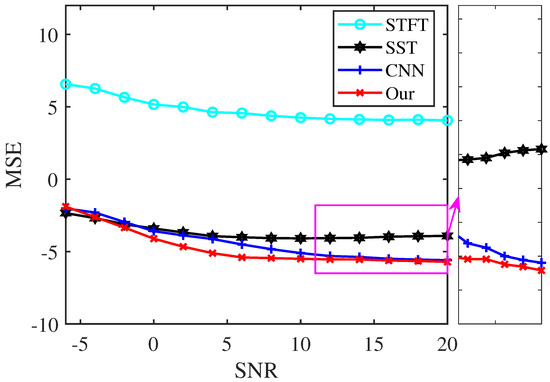
Figure 9.
MSE of the TF results of signal (6) under different noise interference.
5.3. Instantaneous Frequency Extraction Results
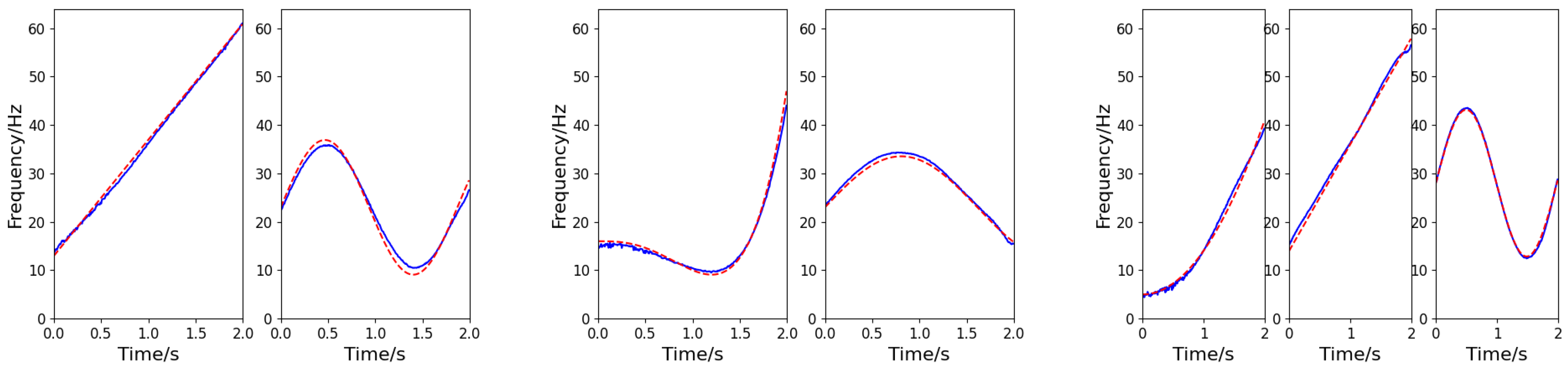
The component number discrimination network adopts the cross-entropy loss function for Adam optimization. The initial learning rate is 0.001, the batch size is 32, and there are 500 rounds of training. Based on the number of components identified by the discrimination network, a multi-branch instantaneous frequency separation and estimation network is established. The network adopts the MSE function for Adam optimization. The initial learning rate is 0.001, the training batch size is 32, and there are 300 rounds of training. The three signals exemplified in Section 5.2 are taken as example (SNR = −5 dB, 5 dB, and 10 dB for the first, second, and third signals, respectively). The output of the frequency-cross signal separation network is shown in Figure 10, in which each column corresponds to the IF information of each signal. According to the results of simulation experiment, the method developed in this paper can be used to effectively determine the number of components of multi-component cross signals and successfully extract the IFs of frequency-crossing signals, even in low SNR environment.
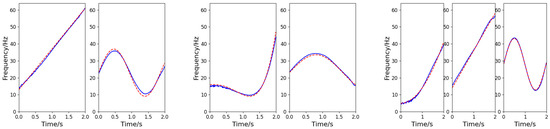
Figure 10.
IF estimation of the frequency-crossing signals (the blue solid line represents the estimated value, and the red dashed line represents the actual value).
5.4. Practical Application
To examine the effectiveness of the proposed method in handling real-world signals, we consider the open-access bat echolocation data recorded by Rice University. This signal contains 400 samples with a sampling period of 7 μs.
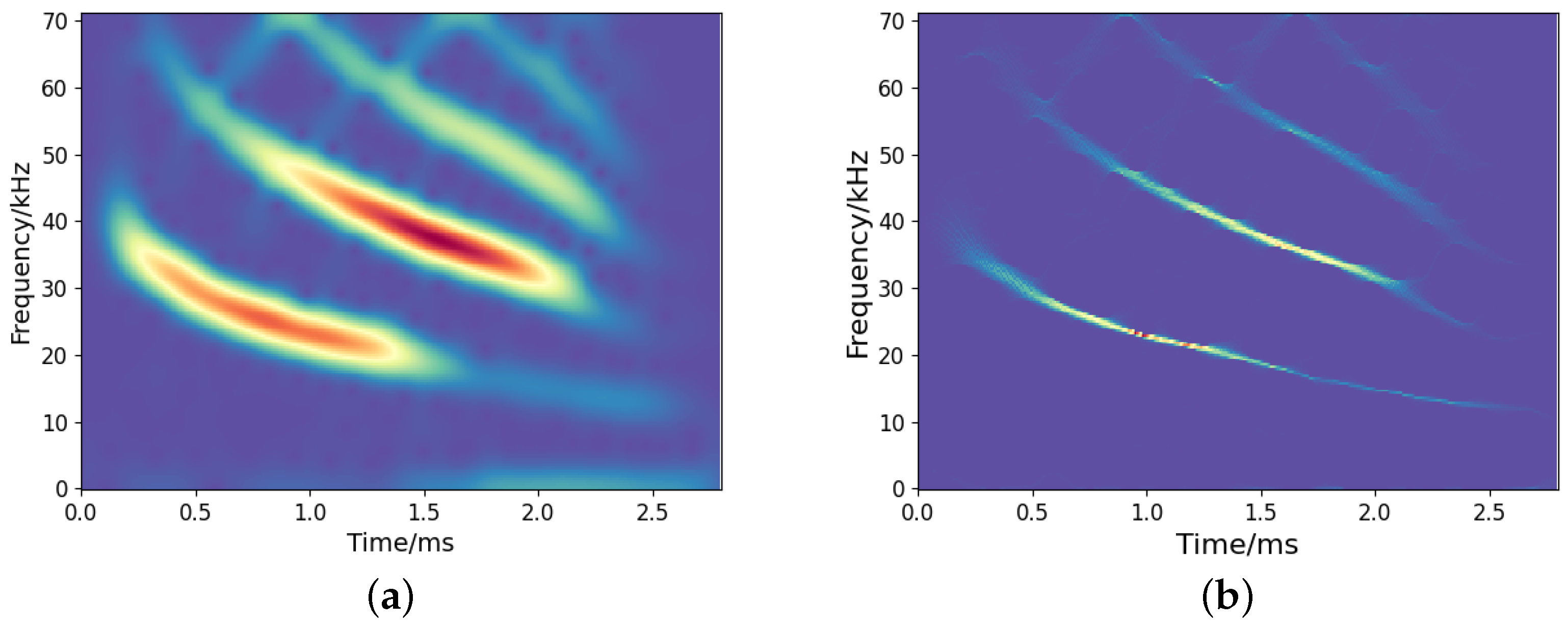
Figure 11 depicts the TF representations by the employed TF analysis methods. As presented in Figure 11a, the result of STFT is diffusive due to the limitation of uncertainty principles. SST yields a more sharpened TF representation than STFT, but there is still energy diffusion. Figure 11c,d show the TF representation by the CNN and our proposed method, which reflects a clear signal energy distribution with a high resolution. In comparison, our approach reveals more refined and detailed TF information.
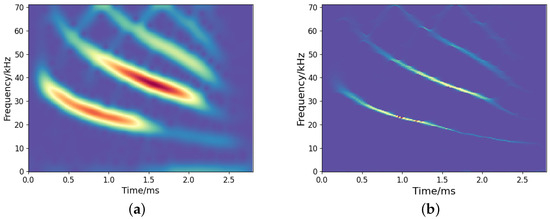
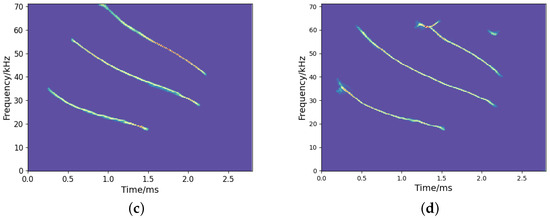
Figure 11.
Results of TF representation of bat signals: (a) STFT; (b) SST; (c) CNN; (d) Our.
6. Conclusions and Discussion
In this paper, a new high-concentration TF representation network and an instantaneous frequency separation and estimation network are proposed for analyzing and processing frequency-crossing signals. Under the effective feature extraction mode of U-net, the TF representation network can concentrate information on spectrograms of any size and achieve high-resolution TF representations of frequency-crossing signals. By implementing the component discrimination network alongside the instantaneous frequency separation and estimation network, the instantaneous frequency curves of each component signal of the frequency-crossing signal are effectively extracted. The experimental results show that the proposed method enables not only a more concentrated TF representation than STFT, SST, and CNN methods but also an accurate estimation of the time-varying law of frequency-crossing signals, highlighting the effectiveness of our approach.
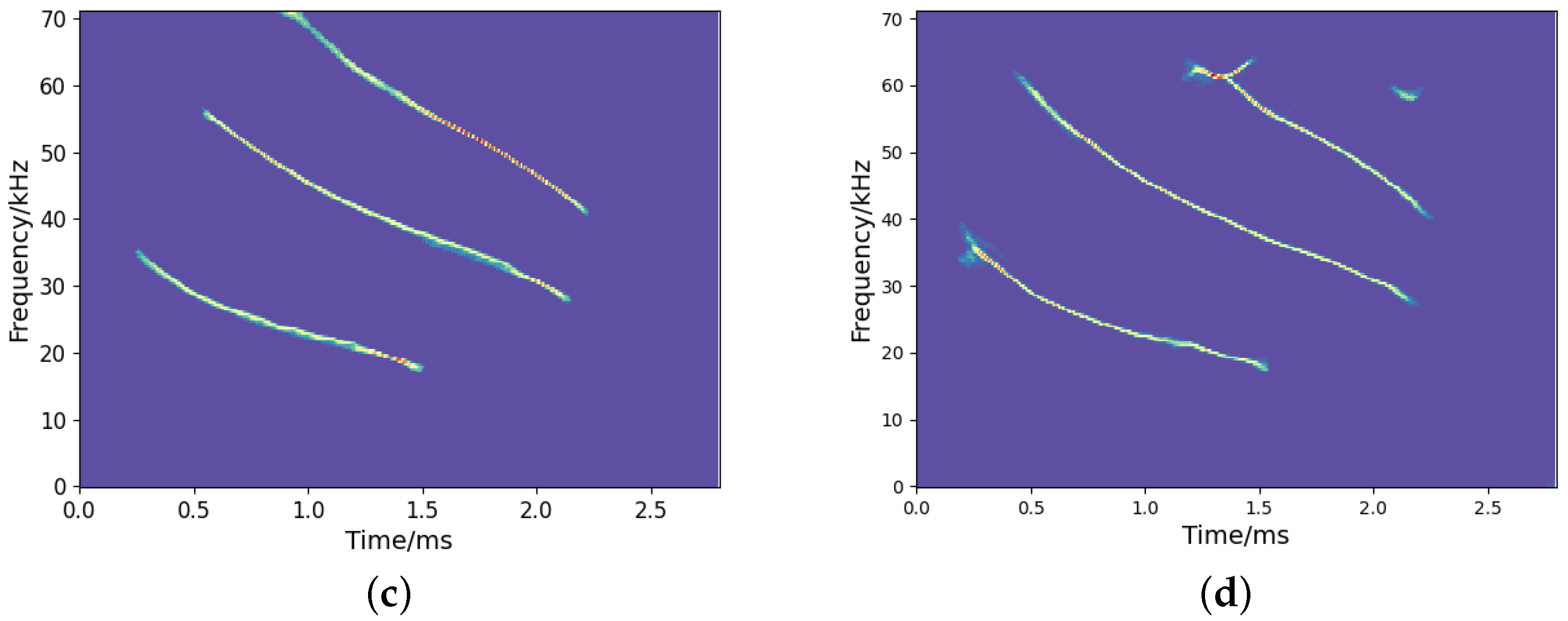
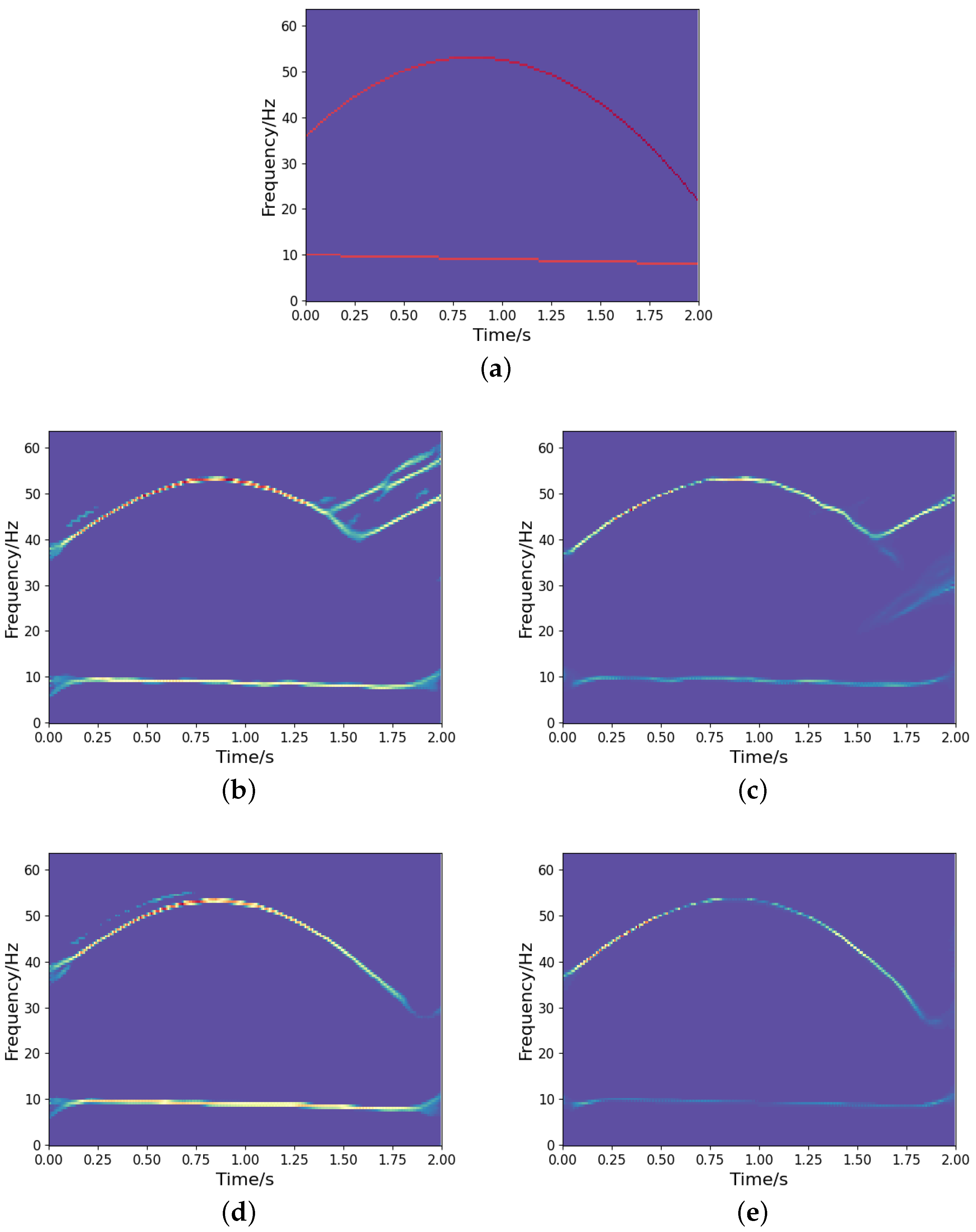
It is noted that we could implement a deeper network structure based on the proposed model, as outlined in [27]. A deeper network tends to yield a more concentrated TF representation. However, it may also result in the loss of certain signal information. Figure 12 shows the TF output by the deeper network model in [27]. We can observe that some signal information is distorted and missing compared to the ideal representation (see Figure 8a), even though it provides a more concentrated TF representation. Therefore, designing a learning network that can optimize the TF distribution of signals while fully characterizing the signal information is a crucial issue that deserves further investigation. In addition, to assess the generalization capability of the network, we test both the proposed high-resolution TF network and the CNN using frequency-uncrossed signals (its ideal TF representation is shown in Figure 13a). The experimental results are presented in Figure 13b–e. These outcomes indicate that our proposed model produces less interference than CNN; however, both networks show representation bias. Improving the generalization capability of networks remains a significant challenge for researchers. Moreover, similar to CNN and other techniques, the proposed method encounters substantial errors in estimating the IFs of frequency-crossing signals when strong noise is present. Therefore, further research is necessary to address this challenge.
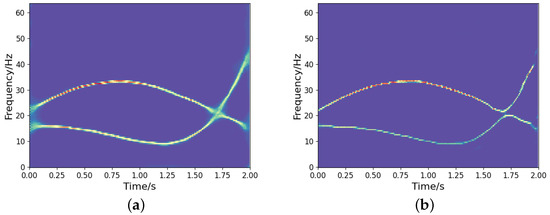
Figure 12.
The high-concentration TF representation network over a deeper network for the noisy frequency-crossing signal in Figure 3. (a) TF output by the proposed model; (b) TF output by the model in [27].
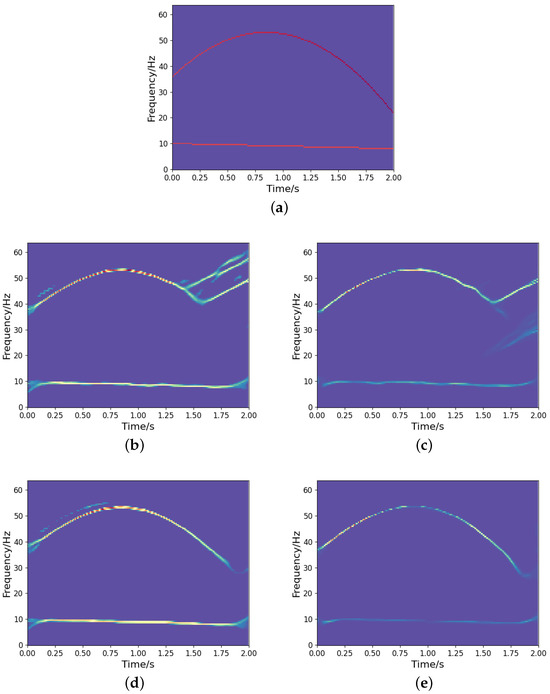
Figure 13.
The results of TF representation of a frequency-uncrossed signal: (a) Ideal TF representation; (b) CNN output under SNR dB; (c) Output from the developed approach under SNR dB; (d) CNN output under SNR dB; (e) Output from the developed approach under SNR dB.
Author Contributions
Conceptualization, H.L. and X.Z.; methodology, H.L. and X.Z.; software, H.L., X.Z. and Z.Z.; validation, Y.W. and X.C.; investigation, H.L. and Y.W.; data curation, X.Z. and X.C.; writing—original draft preparation, H.L. and X.Z.; writing—review and editing, all authors. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China under Grants No. 62471401 and 62301440, the Natural Science Foundation of Shaanxi Province under Grant No. 2023-JC-QN-0739, and the China Postdoctoral Science Foundation under Grant No. 2024M753010.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jurdana, V.; Vrankic, M.; Lopac, N.; Jadav, G.M. Method for automatic estimation of instantaneous frequency and group delay in time-frequency distributions with application in EEG seizure signals analysis. Sensors 2023, 23, 4680. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.; Ren, J.; Yang, Y.; Xiao, Z.; Yu, W.; Havyarimana, V. Object detection in large-scale remote-sensing images based on time-frequency analysis and feature optimization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Duan, H.; Chen, G.; Yu, Y.; Du, C.; Bao, Z.; Ma, D. DyGAT-FTNet: A dynamic graph attention network for multi-sensor fault diagnosis and time-frequency data fusion. Sensors 2025, 25, 810. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Hao, G.; Yu, J.; Wang, P.; Jin, Y. A novel solution for improved performance of time-frequency concentration. Mech. Syst. Signal Process. 2023, 185, 109784. [Google Scholar]
- Li, Y.; Geng, C.; Yang, Y.; Chen, S.; Feng, K.; Beer, M. Extraction of instantaneous frequencies for signals with intersecting and intermittent trajectories. Mech. Syst. Signal Process. 2025, 223, 111835. [Google Scholar]
- Chen, T.; Chen, Q.; Zheng, Q.; Li, Z.; Zhang, Z.; Xie, L.; Su, H. Adaptive multi-scale TF-net for high-resolution time-frequency representations. Signal Process. 2024, 214, 109247. [Google Scholar] [CrossRef]
- Cohen, L. Time-Frequency Analysis; Prentice Hall PTR: New York, NY, USA, 1995. [Google Scholar]
- Jurdana, V.; Baressi Šegota, S. Convolutional neural networks for local component number estimation from time-frequency distributions of multicomponent nonstationary signals. Mathematics 2024, 12, 1661. [Google Scholar] [CrossRef]
- Mann, S.; Haykin, S. The chirplet transform: Physical considerations. IEEE Trans. Signal Process. 1995, 43, 2745–2761. [Google Scholar]
- Auger, F.; Flandrin, P. Improving the readability of time-frequency and time-scale representations by the reassignment method. IEEE Trans. Signal Process. 1995, 43, 1068–1089. [Google Scholar]
- Daubechies, I.; Lu, J.; Wu, H.T. Synchrosqueezed wavelet transforms: An empirical mode decomposition-like tool. Appl. Computat. Harmon. Anal. 2011, 30, 243–261. [Google Scholar]
- Bruni, V.; Tartaglione, M.; Vitulano, D. An iterative approach for spectrogram reassignment of frequency modulated multicomponent signals. Math. Comput. Simul. 2020, 176, 96–119. [Google Scholar] [CrossRef]
- Zhu, X.X.; Zhang, Z.; Gao, J. Three-dimension extracting transform. Signal Process. 2021, 179, 107830. [Google Scholar] [CrossRef]
- Chui, C.K.; Jiang, Q.; Li, L.; Lu, J. Time-scale-chirp_rate operator for recovery of non-stationary signal components with crossover instantaneous frequency curves. Appl. Comput. Harmon. Anal. 2021, 54, 323–344. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, H.-T. Disentangling modes with crossover instantaneous frequencies by synchrosqueezed chirplet transforms, from theory to application. Appl. Comput. Harmon. Anal. 2023, 62, 84–122. [Google Scholar] [CrossRef]
- Chen, S.; Dong, X.; Xing, G.; Peng, Z.; Zhang, W.; Meng, G. Separation of overlapped nonstationary signals by ridge path regrouping and intrinsic chirp component decomposition. IEEE Sens. J. 2017, 17, 5994–6005. [Google Scholar] [CrossRef]
- Zhang, S.; Pavel, M.; Zhang, Y.D. Crossterm-free time-frequency representation exploiting deep convolutional neural network. Signal Process. 2022, 192, 108372. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, H.; Yu, L.; Hua, G. A data-driven high-resolution time-frequency distribution. IEEE Signal Process. Lett. 2022, 29, 1512–1516. [Google Scholar] [CrossRef]
- Liu, N.; Wang, J.; Yang, Y.; Li, Z.; Gao, J. WVDNet: Time-frequency analysis via semi-supervised learning. IEEE Signal Process. Lett. 2023, 30, 55–59. [Google Scholar] [CrossRef]
- Quan, D.; Ren, F.; Wang, X.; Xing, M.; Jin, N.; Zhang, D. WVD-GAN: A Wigner-Ville distribution enhancement method based on generative adversarial network. IET Radar Sonar Navig. 2024, 18, 849–865. [Google Scholar] [CrossRef]
- Pan, P.; Zhang, Y.; Deng, Z.; Fan, S.; Huang, X. TFA-Net: A deep learning-based time-frequency analysis tool. IEEE Trans. Neural Net. Learn. Syst. 2023, 34, 9274–9286. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, D.; Cui, L. CTNet: A data-driven time-frequency technique for wind turbines fault diagnosis under time-varying speeds. ISA Trans. 2024, 154, 335–351. [Google Scholar] [PubMed]
- Wang, Z.; Chen, L.; Xiao, P.; Xu, L.; Li, Z. Enhancing time-frequency resolution via deep-learning framework. IET Signal Process. 2023, e12210. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Azad, R.; Aghdam, E.; Rauland, A.; Jia, Y.; Avval, A.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.; Adeli, E.; Merhof, D. Medical image segmentation review: The success of U-Net. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 16, 10076–10095. [Google Scholar]
- Xia, X.; Yu, F.; Liu, C.; Zhao, J.; Wu, T. Time-frequency image enhancement of frequency modulation signals by using fully convolutional networks. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1472–1476. [Google Scholar]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Imag. Process. 2023, 32, 364–376. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).