
Intention Reasoning for User Action Sequences via Fusion of Object Task and Object Action Affordances Based on Dempster–Shafer Theory

Abstract
1. Introduction
- The task reasoning module in the algorithm employs CP-Logic to model and infer the relationship between object categories and task intentions. Additionally, a task probability update algorithm based on reinforcement learning is developed, enabling the model to adapt to users’ operational habits and achieve object-to-task intention reasoning.
- The action reasoning module does not rigidly define the functional parts of an object or the actions associated with them as fixed or singular. It also does not predict subsequent action intentions solely by visually detecting an object’s functional regions. Instead, we utilize CP-Logic to probabilistically model the relationships between the functional parts of an object and their potential actions, capturing the inherent flexibility and variability in object action affordances.
- We incorporate D-S theory to fuse information from the aforementioned reasoning modules, enabling the inference of action sequence intentions for target objects. This approach imposes task constraints on action reasoning, enabling more accurate and reliable prediction of operational intentions, allowing the WMRA to accurately understand users’ task intentions and, during the execution of real-world tasks, select and execute appropriate actions on functional regions of objects in a task-oriented manner.
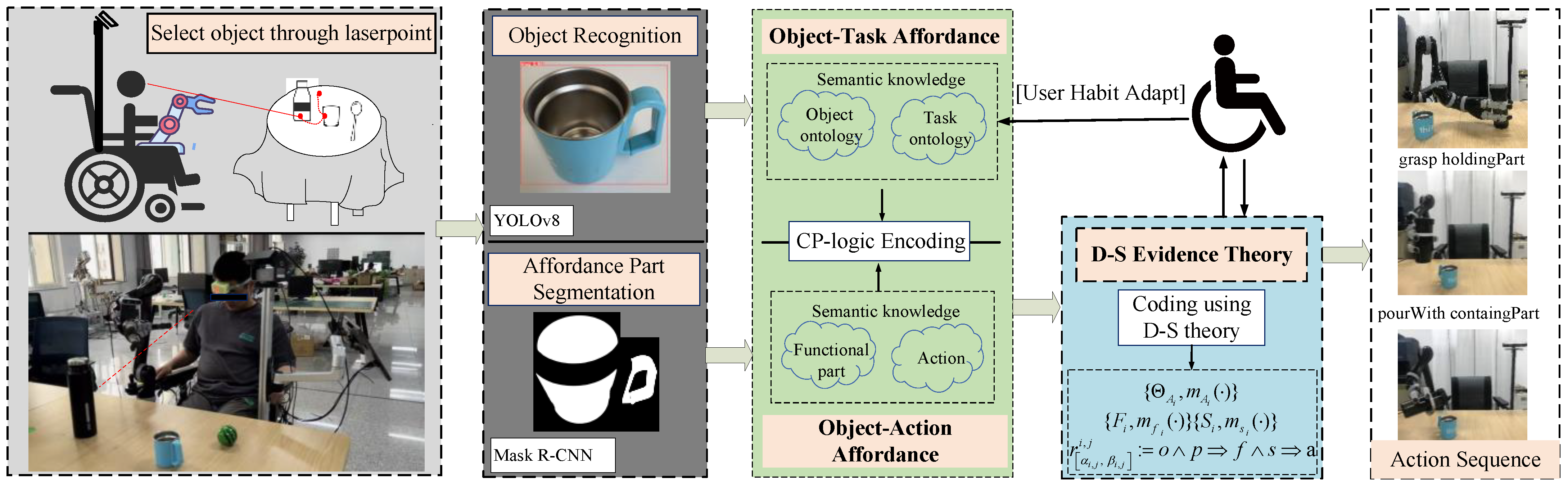
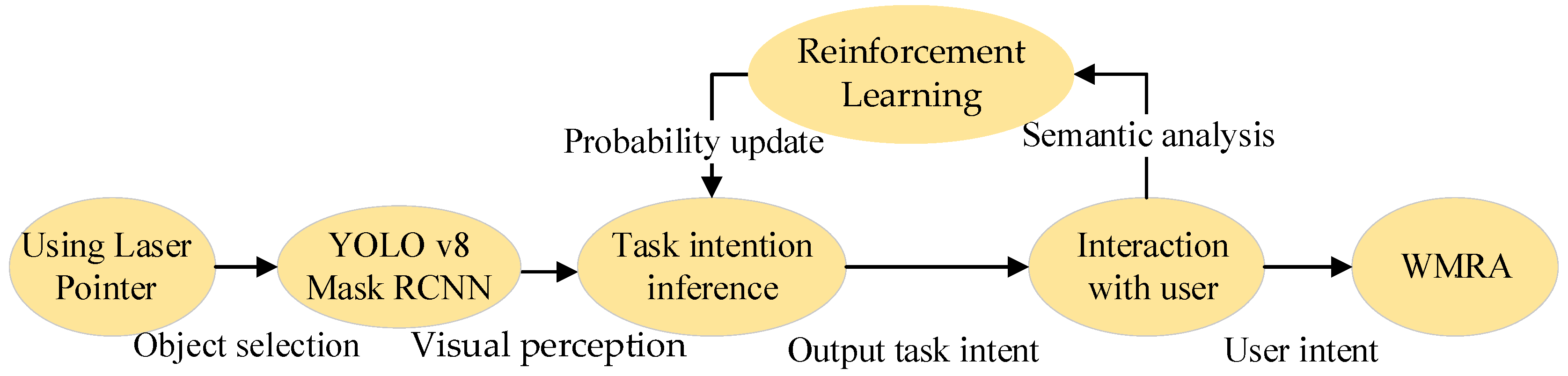
2. Intent Reasoning Framework
3. Methods
3.1. Object Task Affordance Reasoning Based on CP-Logic Encoding Principles
3.1.1. Object Recognition
3.1.2. Object and Task Ontology Construction
- (1)
- Containers that can hold objects in the home environment;
- (2)
- Tools that can be used by the WMRA to complete specific tasks;
- (3)
- Furniture commonly used in the home environment to place objects;
- (4)
- Controllers used to operate the switches of various devices in life.
3.1.3. Object Task Affordance Construction and CP-Logic Encoding
3.1.4. User Habit Adaptation Based on Reinforcement Learning
3.2. Object Action Affordance Reasoning Based on Visual Affordance Detection
3.2.1. Segmentation of Object Functional Regions
3.2.2. Object Action Affordance Construction
3.3. Action Sequence Intention Inference Based on D-S Theory
3.3.1. Introduction to D-S Theory
3.3.2. Semantic Representation of Object Task Affordance
3.3.3. Semantic Representation of Object Action Affordance
3.3.4. Semantic Representation of Action Sequence
3.3.5. Semantic Constraint Rules Model for Fusion of OT and OA Affordance
3.3.6. Action Sequence Intention Inference Under OT and OA Affordance Constraints
4. Experiments and Results
4.1. Object Recognition and Segmentation of Object Functional Regions Experiment
4.2. Task Intentions Reasoning Experiment
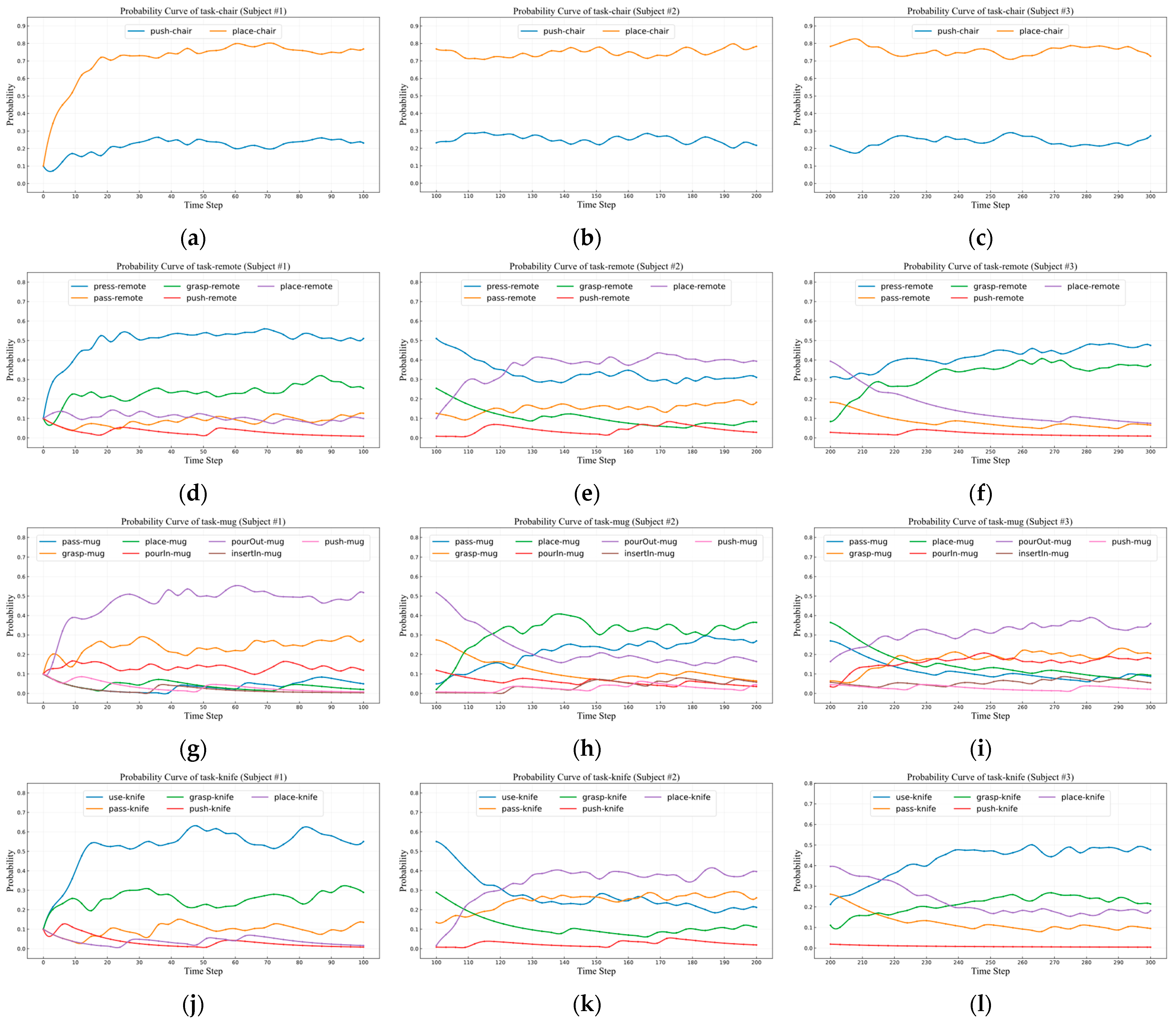
4.2.1. User Habit Adaptation Experiment
- Evaluation of User Initial Habit-Learning Ability for Single Object
- Evaluation of User Habit Switching Learning Ability for Single Object
- Evaluation of User Initial Habit-Learning Ability for Multiple Objects
- Evaluation of User Habit Switching Learning Ability for Multiple Objects
4.2.2. Task Intention Inference
4.2.3. Effect of Learning Rates on the Model’s Performance in Learning User Habits
4.3. Action Intentions Inference Experiment
4.4. Action Sequences Intention Inference Experiment
4.4.1. Action Sequence Intention Inference
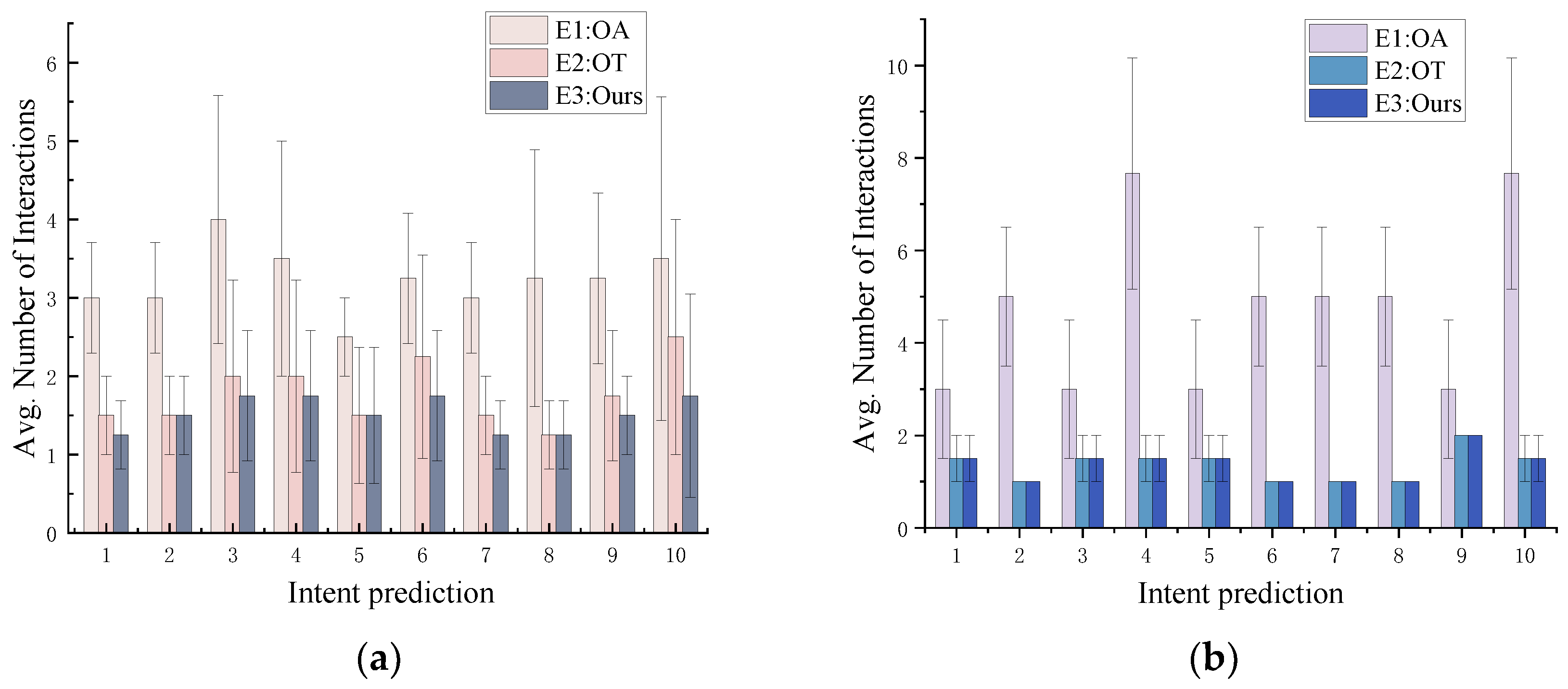
4.4.2. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Argall, B.D. Turning assistive machines into assistive robots. In Quantum Sensing and Nanophotonic Devices XII; SPIE: Bellingham, WA, USA, 2015; pp. 413–424. [Google Scholar]
- Shishehgar, M.; Kerr, D.; Blake, J. The effectiveness of various robotic technologies in assisting older adults. Health Inform. J. 2019, 25, 892–918. [Google Scholar]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Structural-RNN: Deep Learning on Spatio-Temporal Graphs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5308–5317. [Google Scholar]
- Liu, C.; Li, X.; Li, Q.; Xue, Y.; Liu, H.; Gao, Y. Robot recognizing humans intention and interacting with humans based on a multi-task model combining ST-GCN-LSTM model and YOLO model. Neurocomputing 2021, 430, 174–184. [Google Scholar]
- Ding, F.; Dong, L.; Yu, Y. Real-time Human Motion Intention Recognition for Powered Wearable Hip Exoskeleton using LSTM Networks. In Proceedings of the 2024 WRC Symposium on Advanced Robotics and Automation (WRC SARA), Beijing, China, 23 August 2024; pp. 269–273. [Google Scholar]
- Song, G.; Wang, M.-L.; Wang, Z.-J.; Ye, X.-D. A motion intent recognition method for lower limbs based on CNN-RF combined model. In Proceedings of the 2019 IEEE 5th International Conference on Mechatronics System and Robots (ICMSR), Singapore, 3–5 May 2019; pp. 49–53. [Google Scholar]
- Wang, X.; Haji Fathaliyan, A.; Santos, V.J. Toward shared autonomy control schemes for human-robot systems: Action primitive recognition using eye gaze features. Front. Neurorobot. 2020, 14, 567571. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; He, S.; Wei, X.; George, S.A. Research on an effective human action recognition model based on 3D CNN. In Proceedings of the 2022 15th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 5–7 November 2022; pp. 1–6. [Google Scholar]
- Zhang, R.; Yan, X. Video-language graph convolutional network for human action recognition. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 7995–7999. [Google Scholar]
- Muller, S.; Wengefeld, T.; Trinh, T.Q.; Aganian, D.; Eisenbach, M.; Gross, H.M. A Multi-Modal Person Perception Framework for Socially Interactive Mobile Service Robots. Sensors 2020, 20, 722. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Liang, L.; Li, X.; Wang, S.; Pan, X.; Hu, J. A Parallelized Framework for Human Action Recognition and Prediction Based on Graph Neural Networks. In Proceedings of the 2024 China Automation Congress (CAC), Qingdao, China, 1–3 November 2024; pp. 6018–6023. [Google Scholar]
- Shteynberg, G. Shared Attention. Perspect. Psychol. Sci. 2015, 10, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Quintero, C.P.; Ramirez, O.; Jagersand, M. VIBI: Assistive Vision-Based Interface for Robot Manipulation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4458–4463. [Google Scholar]
- Fuchs, S.; Belardinelli, A. Gaze-Based Intention Estimation for Shared Autonomy in Pick-and-Place Tasks. Front. Neurorobot. 2021, 15, 17. [Google Scholar] [CrossRef] [PubMed]
- Kemp, C.C.; Anderson, C.D.; Nguyen, H.; Trevor, A.J.; Xu, Z. A point-and-click interface for the real world: Laser designation of objects for mobile manipulation. In Proceedings of the 2008 3rd ACM/IEEE International Conference on Human-Robot Interaction (HRI), Amsterdam, The Netherlands, 12–15 March 2008; pp. 241–248. [Google Scholar]
- Gualtieri, M.; Kuczynski, J.; Shultz, A.M.; Pas, A.T.; Platt, R.; Yanco, H. Open world assistive grasping using laser selection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4052–4057. [Google Scholar]
- Padfield, N.; Camilleri, K.; Camilleri, T.; Fabri, S.; Bugeja, M. A Comprehensive Review of Endogenous EEG-Based BCIs for Dynamic Device Control. Sensors 2022, 22, 5802. [Google Scholar] [CrossRef] [PubMed]
- Li, S. Novel Intuitive Human-Robot Interaction Using 3D Gaze; Colorado School of Mines: Golden, Colorado, 2017. [Google Scholar]
- Gao, J.; Blair, A.; Pagnucco, M. Explainable Visual Question Answering via Hybrid Neural-Logical Reasoning. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–10. [Google Scholar]
- Smith, G.B.; Belle, V.; Petrick, R.P. Intention recognition with ProbLog. Front. Artif. Intell. 2022, 5, 806262. [Google Scholar]
- Wang, Z.; Tian, G. Task-Oriented Robot Cognitive Manipulation Planning Using Affordance Segmentation and Logic Reasoning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 12172–12185. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Li, J.; Zhang, W. Large Language Model and Knowledge Graph Entangled Logical Reasoning. In Proceedings of the 2024 IEEE International Conference on Knowledge Graph (ICKG), Abu Dhabi, United Arab Emirates, 11–12 December 2024; pp. 432–439. [Google Scholar]
- Thermos, S.; Potamianos, G.; Daras, P. Joint object affordance reasoning and segmentation in rgb-d videos. IEEE Access 2021, 9, 89699–89713. [Google Scholar] [CrossRef]
- Duncan, K.; Sarkar, S.; Alqasemi, R.; Dubey, R. Scene-Dependent Intention Recognition for Task Communication with Reduced Human-Robot Interaction. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 730–745. [Google Scholar]
- Liu, Y.; Liu, Y.; Yao, Y.; Zhong, M. Object Affordance-Based Implicit Interaction for Wheelchair-Mounted Robotic Arm Using a Laser Pointer. Sensors 2023, 23, 4477. [Google Scholar] [CrossRef] [PubMed]
- Gibson, J. The theory of affordances. In Perceiving, Acting and Knowing: Towards an Ecological Psychology; Erlbaum: Mahwah, NJ, USA, 1977. [Google Scholar]
- Cramer, M.; Cramer, J.; Kellens, K.; Demeester, E. Towards robust intention estimation based on object affordance enabling natural human-robot collaboration in assembly tasks. In Proceedings of the 6th CIRP Global Web Conference on Envisaging the Future Manufacturing, Design, Technologies and Systems in Innovation Era (CIRPe), Shantou, China, 23–25 October 2018; pp. 255–260. [Google Scholar]
- Isume, V.H.; Harada, K.; Wan, W.; Domae, Y. Using affordances for assembly: Towards a complete craft assembly system. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; pp. 2010–2014. [Google Scholar]
- Hassanin, M.; Khan, S.; Tahtali, M. Visual Affordance and Function Understanding: A Survey. ACM Comput. Surv. 2022, 54, 35. [Google Scholar] [CrossRef]
- Mandikal, P.; Grauman, K. Learning Dexterous Grasping with Object-Centric Visual Affordances. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 6169–6176. [Google Scholar]
- Deng, S.H.; Xu, X.; Wu, C.Z.; Chen, K.; Jia, K. 3D AffordanceNet: A Benchmark for Visual Object Affordance Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Virtual, 19–25 June 2021; pp. 1778–1787. [Google Scholar]
- Xu, D.F.; Mandlekar, A.; Martin-Martin, R.; Zhu, Y.K.; Savarese, S.; Li, F.F. Deep Affordance Foresight: Planning Through What Can Be Done in the Future. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 6206–6213. [Google Scholar]
- Borja-Diaz, J.; Mees, O.; Kalweit, G.; Hermann, L.; Boedecker, J.; Burgard, W. Affordance learning from play for sample-efficient policy learning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6372–6378. [Google Scholar]
- Long, X.; Beddow, L.; Hadjivelichkov, D.; Delfaki, A.M.; Wurdemann, H.; Kanoulas, D. Reinforcement Learning-Based Grasping via One-Shot Affordance Localization and Zero-Shot Contrastive Language-Image Learning. In Proceedings of the 2024 IEEE/SICE International Symposium on System Integration (SII), Ha Long, Vietnam, 8–11 January 2024; pp. 207–212. [Google Scholar]
- Do, T.-T.; Nguyen, A.; Reid, I. Affordancenet: An end-to-end deep learning approach for object affordance detection. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5882–5889. [Google Scholar]
- Sun, Y.; Ren, S.; Lin, Y. Object–object interaction affordance learning. Robot. Auton. Syst. 2014, 62, 487–496. [Google Scholar]
- Girgin, T.; Uğur, E. Multi-Object Graph Affordance Network: Goal-Oriented Planning through Learned Compound Object Affordances. IEEE Trans. Cogn. Dev. Syst. 2024. [Google Scholar] [CrossRef]
- Mo, K.; Qin, Y.; Xiang, F.; Su, H.; Guibas, L. O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning. In Proceedings of the 5th Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 1666–1677. [Google Scholar]
- Uhde, C.; Berberich, N.; Ma, H.; Guadarrama, R.; Cheng, G. Learning Causal Relationships of Object Properties and Affordances Through Human Demonstrations and Self-Supervised Intervention for Purposeful Action in Transfer Environments. IEEE Robot. Autom. Lett. 2022, 7, 11015–11022. [Google Scholar] [CrossRef]
- Nguyen, A.; Kanoulas, D.; Caldwell, D.G.; Tsagarakis, N.G. Object-based affordances detection with convolutional neural networks and dense conditional random fields. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5908–5915. [Google Scholar]
- Wu, H.; Chirikjian, G.S. Can i pour into it? robot imagining open containability affordance of previously unseen objects via physical simulations. IEEE Robot. Autom. Lett. 2020, 6, 271–278. [Google Scholar] [CrossRef]
- Zhong, M.; Zhang, Y.; Yang, X.; Yao, Y.; Guo, J.; Wang, Y.; Liu, Y. Assistive grasping based on laser-point detection with application to wheelchair-mounted robotic arms. Sensors 2019, 19, 303. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. International Classification of Functioning, Disability, and Health: Children & Youth Version: ICF-CY; World Health Organization: Geneva, Switzerland, 2007. [Google Scholar]
- Vennekens, J.; Denecker, M.; Bruynooghe, M. CP-logic: A language of causal probabilistic events and its relation to logic programming. Theory Pract. Log. Program. 2009, 9, 245–308. [Google Scholar] [CrossRef]
- Myers, A.; Teo, C.L.; Fermüller, C.; Aloimonos, Y. Affordance detection of tool parts from geometric features. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1374–1381. [Google Scholar]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 57–72. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Yager, R.R. On the Dempster-Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Núnez, R.C.; Dabarera, R.; Scheutz, M.; Briggs, G.; Bueno, O.; Premaratne, K.; Murthi, M. DS-based uncertain implication rules for inference and fusion applications. In Proceedings of the 16th International Conference on Information Fusion, Istanbul, Turkey, 9–12 July 2013; pp. 1934–1941. [Google Scholar]








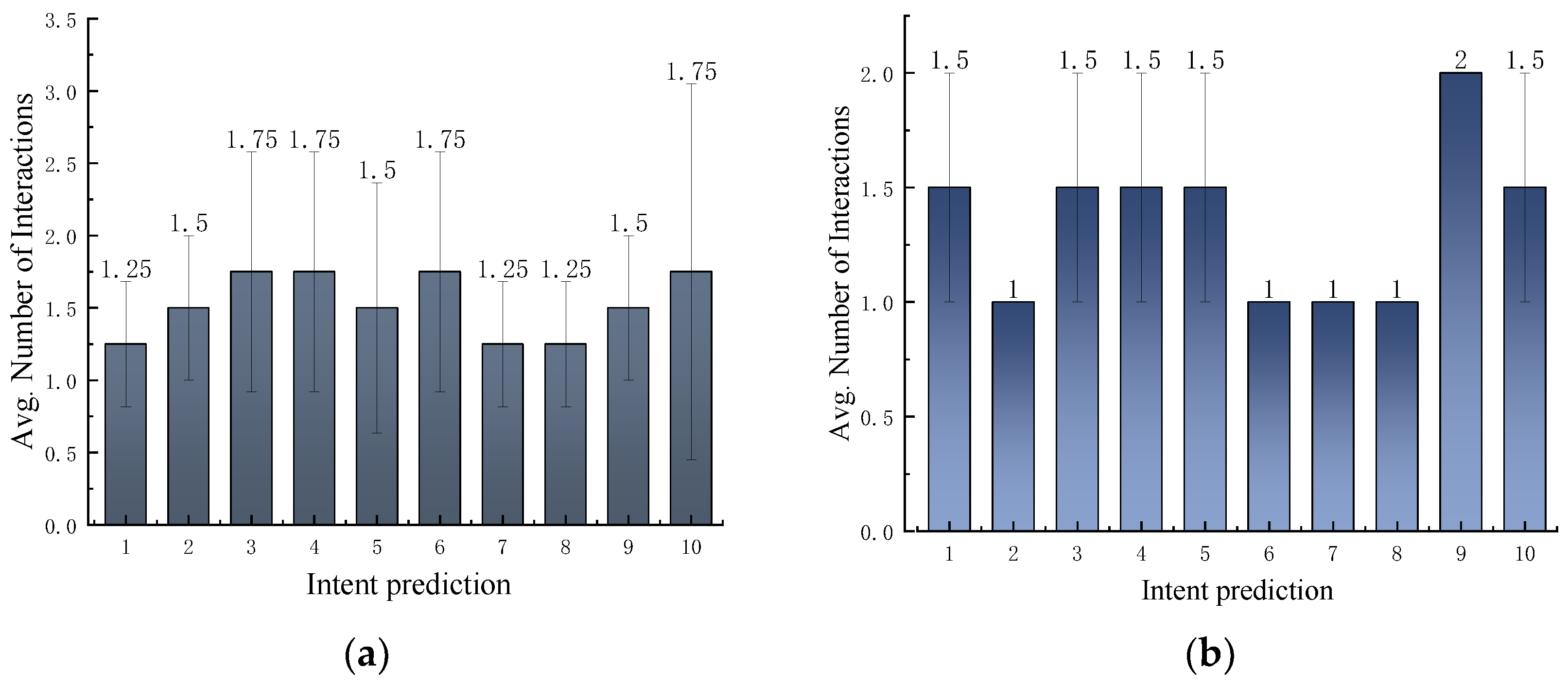

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Task Affordance | Furniture | Controller | Container | Tool | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Container | Canister | |||||||||||||
| Chair | Table | Remote | Switch | Cup | Bowl | Mug | Bottle | Can | Knife | Scoop | Toothbrush | Hammer | ||
| pass | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| use | ✓ | ✓ | ✓ | ✓ | ||||||||||
| pour | In | ✓ | ✓ | ✓ | ||||||||||
| Out | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
| grasp | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| place | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| push | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| press | ✓ | ✓ | ||||||||||||
| insertIn | ✓ | ✓ | ✓ | |||||||||||
| grasp | pourWith | placeOn | push | press | cutWith | poundWith | brushWith | scoopwith | insertInTo | |
|---|---|---|---|---|---|---|---|---|---|---|
| holdingPart | ✓ | ✓ | ||||||||
| poundingPart | ✓ | ✓ | ✓ | |||||||
| cuttingPart | ✓ | ✓ | ✓ | |||||||
| scoopingPart | ✓ | ✓ | ✓ | |||||||
| containingPart | ✓ | ✓ | ||||||||
| buttonPart | ✓ | |||||||||
| brushingPart | ✓ | ✓ | ✓ | |||||||
| supportingPart | ✓ | ✓ |
| Aspect | Semantic | Mass |
|---|---|---|
| Task(X, use, O1, O2) | ||
| Task(X, pourOut, O1, O2) | ||
| Task(X, pourIn, O1, O2) | ||
| Task(X, grasp, O) | ||
| Task(X, press, O) | ||
| Task(X, insertIn, O1, O2) | ||
| Task(X, place, O1, O2) | ||
| Task(X, push, O) | ||
| Task(X, pass, O) |
| Aspect | Semantic | Mass |
|---|---|---|
| grasp(X, O, part(O)) | ||
| push(X, O, part(O)) | ||
| press(X, O, part(O)) | ||
| cutWith (X, O, part(O)) | ||
| scoopWith (X, O, part(O)) | ||
| pourWIth(X, O, part(O)) | ||
| insertInTo(X, O, part(O)) | ||
| brushWith (X, O, part(O)) | ||
| poundWith (X, O, part(O)) | ||
| placeOn (X, O, part(O)) |
| Aspect | Semantic | Mass |
|---|---|---|
| X grasp part(O) | ||
| X push part(O) | ||
| X press part(O) | ||
| X grasp part(O) pourWith part(O) | ||
| X grasp part(O) cutWith part(O) | ||
| X grasp part(O) poundWith part(O) | ||
| X grasp part(O) brushWith part(O) | ||
| X grasp part(O) scoopWith part(O) | ||
| X grasp part(O1) placeOn part(O2) | ||
| X grasp part(O1) insertInTo part(O2) | ||
| X grasp part(O1) pourWith part(O1) |
| Chair | Remote | Mug | Knife | |
|---|---|---|---|---|
| pass | ✓ | ✓ | ✓ | |
| use | ✓ | |||
| pourOut | ✓ | |||
| grasp | ✓ | ✓ | ✓ | |
| place | ✓ | ✓ | ✓ | ✓ |
| push | ✓ | ✓ | ✓ | ✓ |
| press | ✓ | |||
| pourIn | ✓ | |||
| insertIn | ✓ |
| pass-mug | pourOut- mug | grasp- mug | place- mug | push- mug | pourIn- mug | insertIn- mug | |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| … | … | … | … | … | … | … | … |
| 108 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 109 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 110 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 2 | … | 109 | 110 | |
|---|---|---|---|---|---|
| Task(X, use, knife, table) | 0 | 0 | … | 1 | 0 |
| Task(X, place, knife, table) | 1 | 1 | … | 0 | 1 |
| Task(X, insertIn, bottle, mug) | 0 | 1 | … | 0 | 0 |
| Task(X, pourOut, bottle, mug) | 1 | 0 | … | 1 | 0 |
| Task(X, pourIn, bottle, mug) | 0 | 0 | … | 0 | 1 |
| Object | Chair | Remote | Mug | Knife | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Task | |||||||||||
| pass | ✓ | ✓ | ✓ | grasp | |||||||
| use | ✓ | cutWith | |||||||||
| pourOut | ✓ | pourWith | |||||||||
| grasp | ✓ | ✓ | ✓ | grasp | |||||||
| place | ✓ | ✓ | ✓ | ✓ | placeOn | ||||||
| push | ✓ | ✓ | ✓ | ✓ | push | ||||||
| press | ✓ | press | |||||||||
| pourIn | ✓ | pourWith | |||||||||
| insertIn | ✓ | insertInTo | |||||||||
| supporting Part | holding Part | button Part | holding Part | containing Part | holding Part | cutting Part | holding Part | Action | |||
| Part | |||||||||||
| Chair | Remote | Mug | Knife | |
|---|---|---|---|---|
| pass | r11 | r10 | r7 | |
| use | r2 | |||
| pourOut | r5 | |||
| grasp | r12 | r12 | r12 | |
| place | r29 | r30 | r30 | r30 |
| push | r20 | r20 | r21 | r23 |
| press | r26 | |||
| pourIn | r19 | |||
| insertIn | r27 |
| Task | Rule |
|---|---|
| Task(X, use, knife, table) | r30 |
| Task(X, place, knife, table) | r28 |
| Task(X, insertIn, bottle, mug) | r27 |
| Task(X, pourOut, bottle, mug) | r18 |
| Task(X, pourIn, bottle, mug) | r19 |
| Experiment | OA | OT | D-S | Avg. Number of Interactions (Single Object) | Avg. Number of Interactions (Multi-Objects) |
|---|---|---|---|---|---|
| E1 | ✓ | 1.775 | 1.350 | ||
| E2 | ✓ | 3.225 | 4.733 | ||
| E3 | ✓ | ✓ | ✓ | 1.525 | 1.350 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wang, C.; Liu, Y.; Tong, W.; Zhong, M. Intention Reasoning for User Action Sequences via Fusion of Object Task and Object Action Affordances Based on Dempster–Shafer Theory. Sensors 2025, 25, 1992. https://doi.org/10.3390/s25071992
Liu Y, Wang C, Liu Y, Tong W, Zhong M. Intention Reasoning for User Action Sequences via Fusion of Object Task and Object Action Affordances Based on Dempster–Shafer Theory. Sensors. 2025; 25(7):1992. https://doi.org/10.3390/s25071992
Chicago/Turabian StyleLiu, Yaxin, Can Wang, Yan Liu, Wenlong Tong, and Ming Zhong. 2025. "Intention Reasoning for User Action Sequences via Fusion of Object Task and Object Action Affordances Based on Dempster–Shafer Theory" Sensors 25, no. 7: 1992. https://doi.org/10.3390/s25071992
APA StyleLiu, Y., Wang, C., Liu, Y., Tong, W., & Zhong, M. (2025). Intention Reasoning for User Action Sequences via Fusion of Object Task and Object Action Affordances Based on Dempster–Shafer Theory. Sensors, 25(7), 1992. https://doi.org/10.3390/s25071992