To simulate wear and tear, three clearance levels were established: standard clearance (normal operation), twice the standard clearance (mildly faulty), and three times the standard clearance (severely faulty), as determined through consultation with experienced maintenance engineers. Each press was also configured with three different stroke rates (SPM) and stamping intensities.
The four selected press models represent diverse mechanical designs. The OCP-110 utilizes a traditional C-frame, single-crank configuration, offering simplicity and rigidity at a low cost. The G2 models (G2-110 and G2-160) incorporate a C-frame with a double-crank mechanism, enhancing stability. The ST1-110 employs a modern straight-column, single-crank architecture, providing increased rigidity and precision at a higher cost. The numerical suffixes (110 and 160) denote press capacities in tons.
This model selection allows for evaluating the impact of structural design on generalization performance, specifically comparing generalization between presses sharing a single-crank design (ST1-110 vs. OCP-110) and those sharing a C-frame structure (OCP-110 vs. G2-110/160). This comparative analysis will elucidate the influence of structural design and press capacity on model generalization effectiveness.
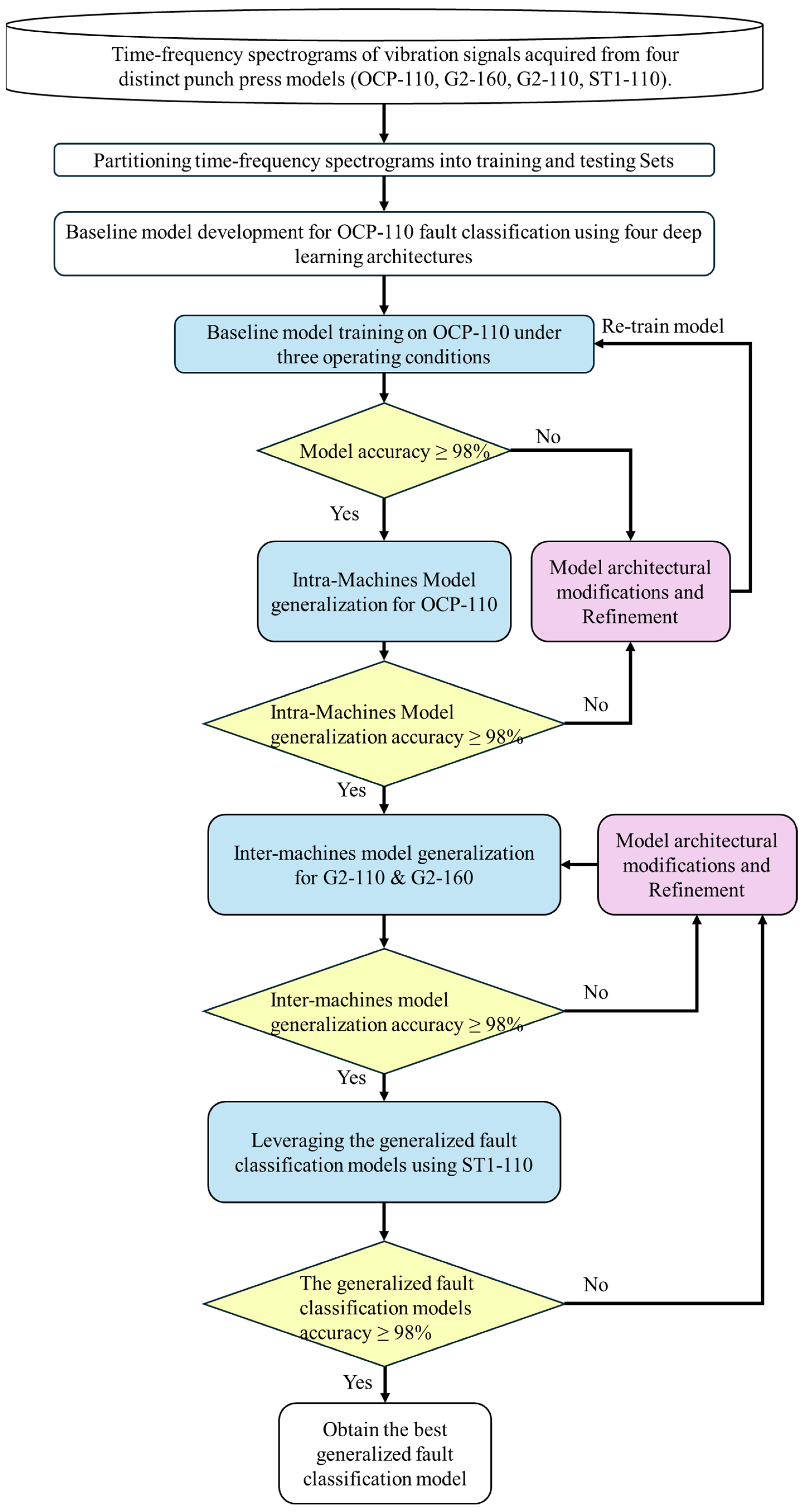
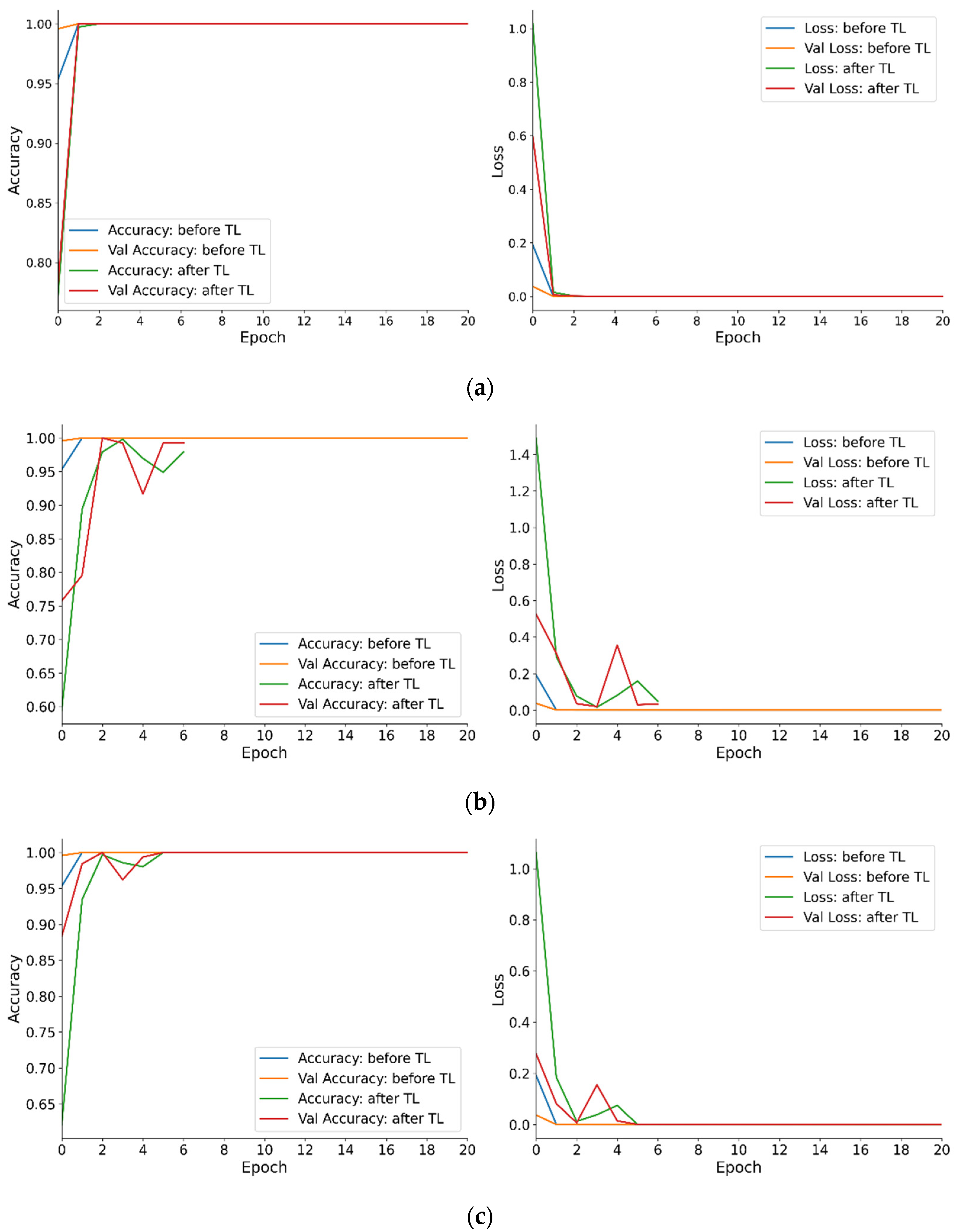
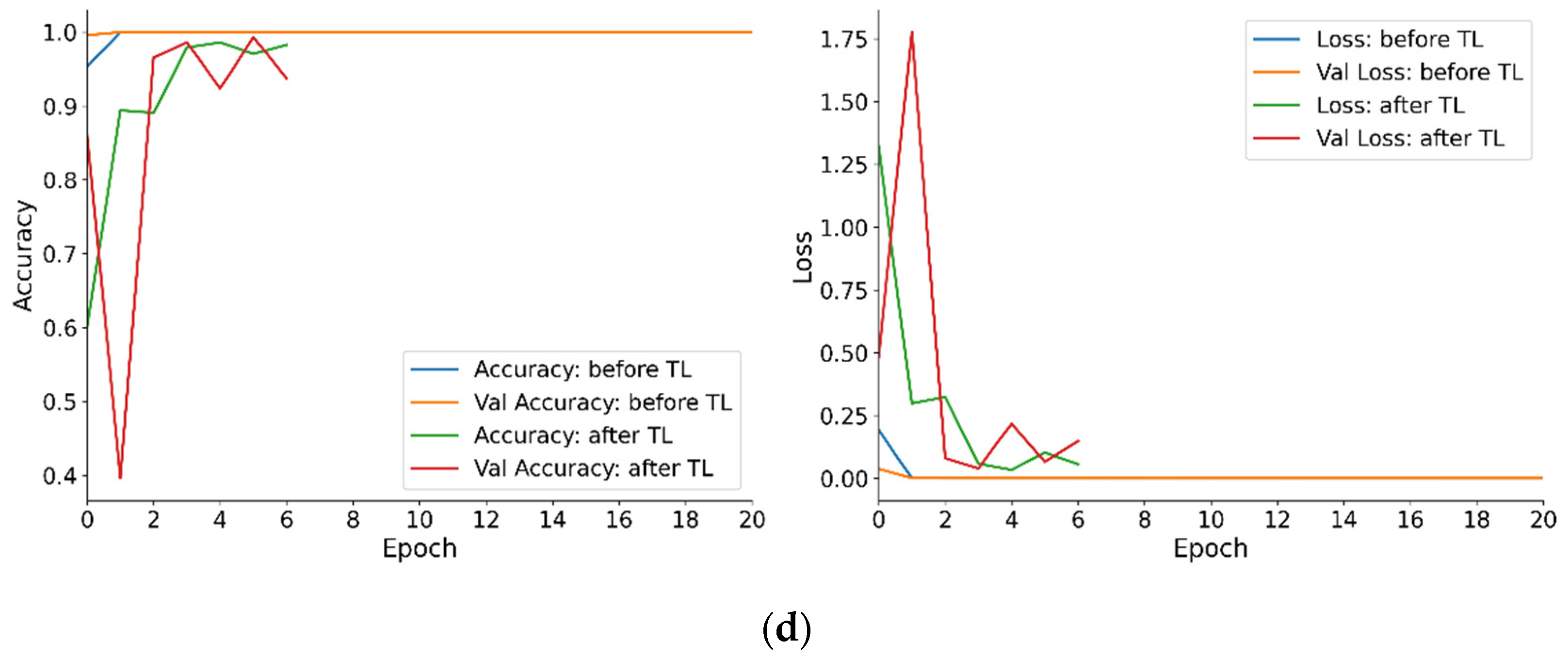
Following intra-machine model generalization, the model trained on the OCP-110 data was applied to two other press models, namely G2-110 and G2-160, to evaluate its inter-machine generalizability. The same four CNN architectures were utilized to assess the model’s generalizability across different press models.
Finally, the three best-performing models from the inter-model generalization phase were selected and further evaluated for their ability to generalize to the ST1-110 press.
3.1.1. Signal Acquisition
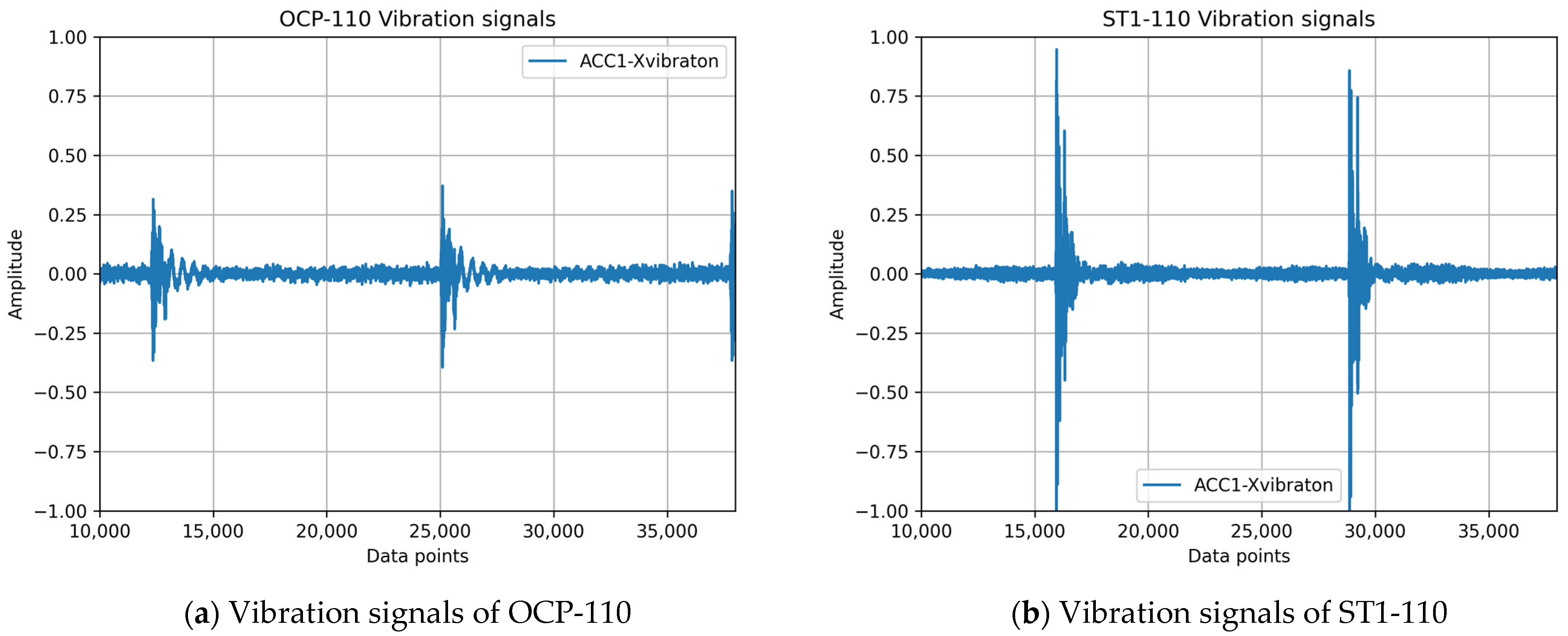
The press equipment utilized in this study consisted of commercially available servo presses manufactured by K Company in Taiwan, specifically the OCP-110, G2-110, G2-160, and ST1-110 models. Vibration data were acquired using Tongtai smart sensors (model: TiACC-01, TONGTAI MACHINE & TOOL CO., LTD., Kaohsiung, Taiwan) with a sampling rate of 6.4 kHz. Each experimental condition was monitored for a minimum duration of 3 h.
To determine the optimal sensor placement, we consulted press experts. Based on their recommendations, two vibration sensors were installed: one (Acc1) on the vertical wall of the main inner press structure and the other (Acc2) on the flywheel support bracket, as depicted in
Figure 2.
Figure 2a shows the sensor placement from the exterior of the press, while
Figure 2b provides an interior view.
Following data preprocessing, the number of samples collected for each operating condition ranged from 500 to 800. This variation in sample size is attributed to differences in the configured strokes per minute (SPM) for each operating condition, despite a consistent data acquisition period of 3 h for each experiment, and each sample containing 60 cycles of vibration signal data.
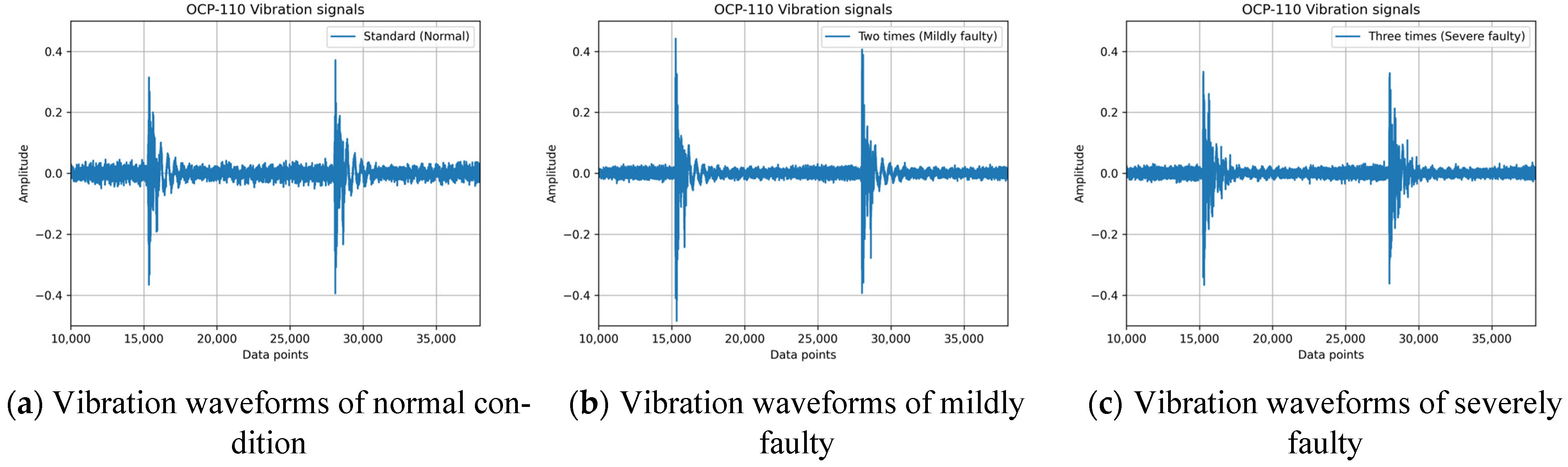
Figure 3 presents the vibration waveforms for an OCP-110 stamping press under three clearance conditions: normal clearance (normal), twice the normal clearance (mildly faulty), and three times the normal clearance (severely faulty). It is evident that three times the normal clearance correlates with increased instability in the vibration waveform, as shown in
Figure 3c. From a practical operational perspective, the normal clearance represents the manufacturer’s default setting for a new press. Over time, as the press is used, the clearance tends to increase. Typically, when the press clearance exceeds three times the normal value, the quality of the stamped products becomes unacceptable, necessitating intervention from maintenance engineers to adjust the clearance and prevent excessive scrap rates.
3.1.2. Data Preprocessing
In this study, continuous vibration signals, as depicted in
Figure 1 and
Figure 3, were subjected to preprocessing, which involved segmenting the data into smaller segments and applying the short-time Fourier transform (STFT) to convert the time-domain vibration signals into spectrograms [
16]. As illustrated in
Figure 3a, the horizontal and vertical axes of the spectrogram represent time and frequency, respectively. With prolonged press operation, the cumulative clearance gradually increases, leading to a decline in stamping quality and the corresponding changes in vibration frequencies. The conventional fast Fourier transform (FFT) is inadequate for capturing these temporal variations in frequency, thereby necessitating the use of an analysis method that provides both time and frequency information.
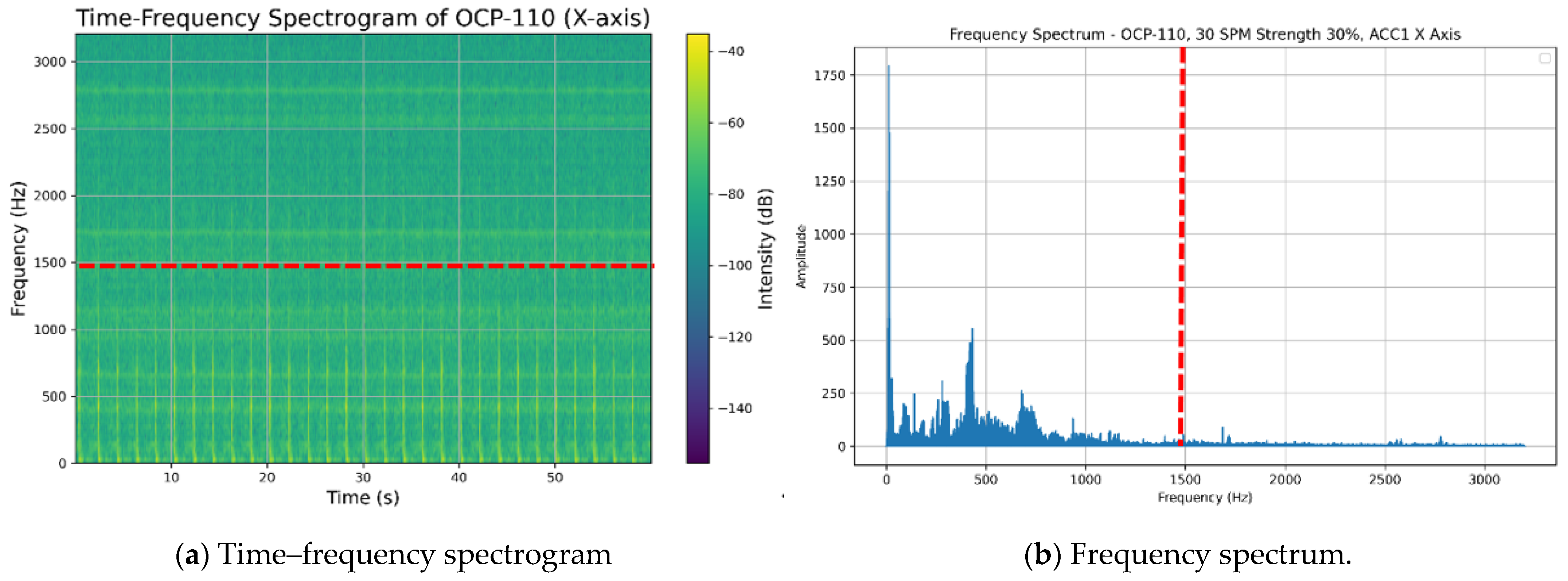
To address this limitation, the STFT employs a sliding window function to segment the signal in the time domain, subjecting each segment to a Fourier transform. This approach allows for the capture of frequency variations at different points in time, thereby generating a time–frequency spectrogram that contains both time and frequency information, as depicted in
Figure 4a. The STFT is mathematically defined as follows:
where
represents the vibration signal in the time domain,
denotes frequency, and
is the Hamming window function.
Furthermore, an analysis of the time–frequency spectrogram, depicted in
Figure 4a, revealed that the predominant characteristic signals of the punch press vibration are concentrated within the low-frequency range. Consequently, we examined the frequency spectrum above 1500 Hz and calculated the energy of the frequency band between 1500 Hz and 3200 Hz. This high-frequency band accounted for only 3.8% of the total energy across all frequencies, as illustrated in
Figure 4b.
Based on these observations, we restricted the analysis frequency range to 0–1500 Hz, effectively filtering out frequency signals above 1500 Hz. This approach facilitated the extraction of pertinent features for subsequent analyses. The proposed data preprocessing strategy not only enhanced the efficiency of model training but also established a foundation for improving the generalization performance of the fault diagnosis models.
3.1.3. Implementation of Generalized Fault Diagnosis Models for Punching Machines
To develop predictive models for differentiating faults, specifically varying clearances in punching machines, the time–frequency images generated through preprocessing were input into deep learning algorithms. Four deep learning models were used to investigate the generalization performance for fault classification: CNN-10 Layers, CNN-Res, VGG16, and ResNet50.
VGG is a deep convolutional neural network architecture [
14] developed by the Visual Geometry Group at the University of Oxford, and this architecture is renowned for its straightforward structure and exceptional performance. We used a VGG network pretrained on a dataset from the OCP-110 machine, which was then transferred to other machines. VGG is composed primarily of stacks of small 3 × 3 convolutional kernels and 2 × 2 pooling kernels that form a deep network structure. This streamlined design facilitates comprehension, implementation, modification, and expansion. By stacking multiple small convolutional kernels, VGG effectively increases network depth, thereby enhancing the model’s nonlinear expressive capacity and allowing it to learn more intricate image features. Compared to networks that employ larger convolutional kernels, VGG requires fewer parameters and exhibits higher computational efficiency at the same depth.
However, VGG16 contains a substantial number of parameters (approximately 138 M), and therefore, it needs more storage space and computational resources. Consequently, model training times are prolonged and overfitting may occur. Moreover, owing to its depth, VGG demands considerable computational power, requiring powerful GPUs for training and inference.
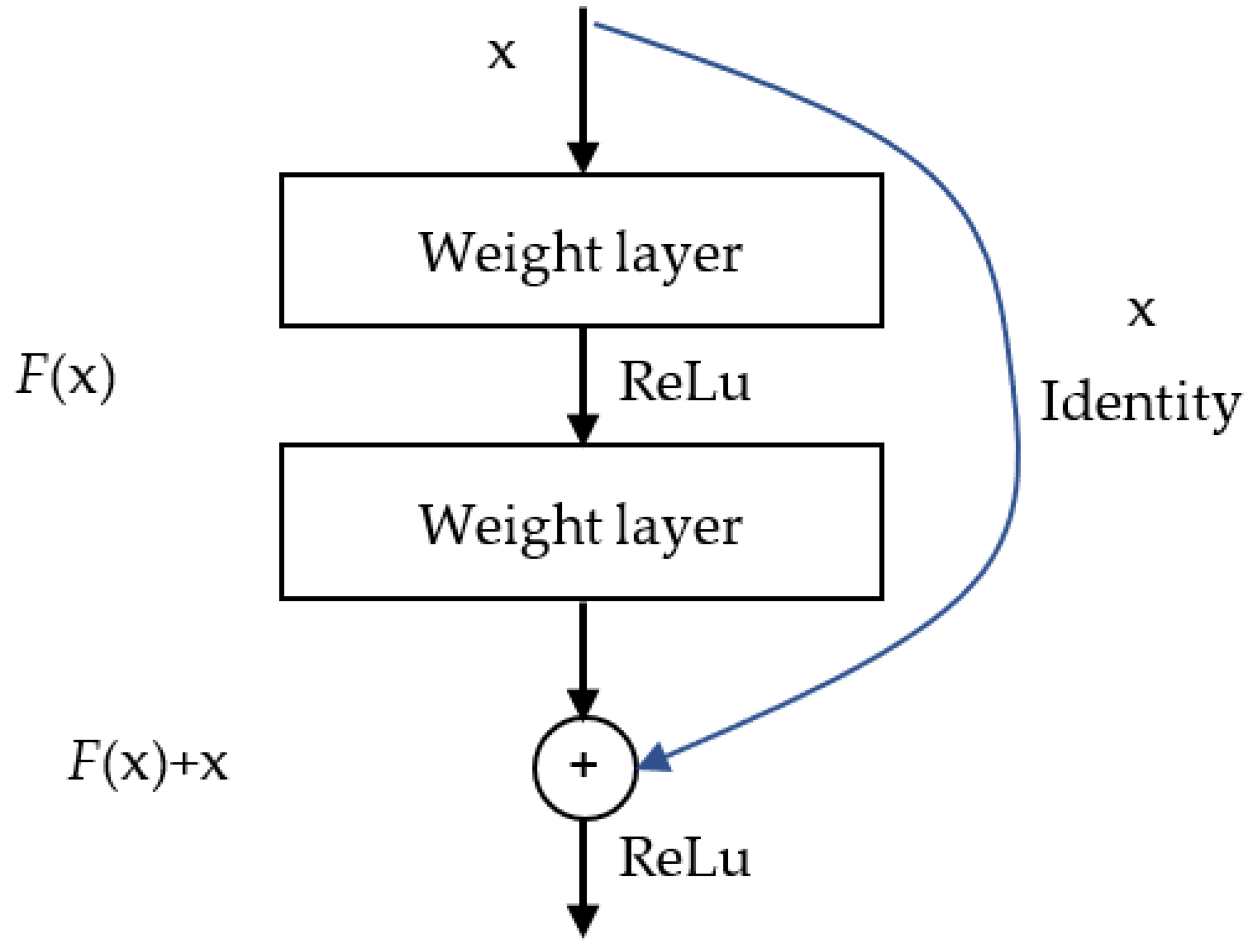
ResNet50, a variant of the deep residual network (ResNet) introduced by He et al. [
15] at Microsoft Research, is a widely used CNN architecture that has been remarkably successful in image recognition tasks. The “50” in ResNet50 denotes the 50 layers comprising the network. As illustrated in
Figure 5, the core concept underlying ResNet is the introduction of “a deep residual learning framework” to address the degradation problem commonly encountered in deep networks. Traditional deep neural networks suffer from vanishing or exploding gradients as the number of layers increases, which hinders training. ResNet’s key innovation lies in employing “residual learning” by incorporating “skip connections” between every few layers. These connections directly transmit the input to the subsequent layers, which mitigates the vanishing gradient problem.
Specifically, ResNet50 consists of 48 convolutional layers, one max-pooling layer, and one fully connected layer. The entire model is constructed by stacking multiple residual blocks, each typically containing two or three convolutional layers. These “skip connections” allow data to bypass certain layers and be passed directly to deeper layers.
A key advantage of ResNet50 is its effective balance between depth and performance. Compared to shallower networks, it can learn more complex features while maintaining a high training speed and excellent performance owing to the residual blocks. Despite being deeper than networks such as VGG16, ResNet50 has a relatively lower parameter count because of its residual block design. In this study, a ResNet50 network pretrained on an OCP-110 machine dataset was used and subsequently transferred to other machines.
In traditional CNNs, the network learns a mapping
directly from the input
. However, the introduction of residual blocks modifies this mapping to learn a residual function
. Consequently, the final output y can be expressed as follows:
where
represents the residual function learned through a series of convolutional layers. This design allows the input x to be propagated directly to the output, even when the learned residual function
is weak, which effectively mitigates the vanishing gradient problem. By adding the identity mapping
to the output of the residual function, the network can learn to approximate the residual mapping, which is often easier than learning the original mapping directly. This approach facilitates the training of deeper networks and improves overall performance.
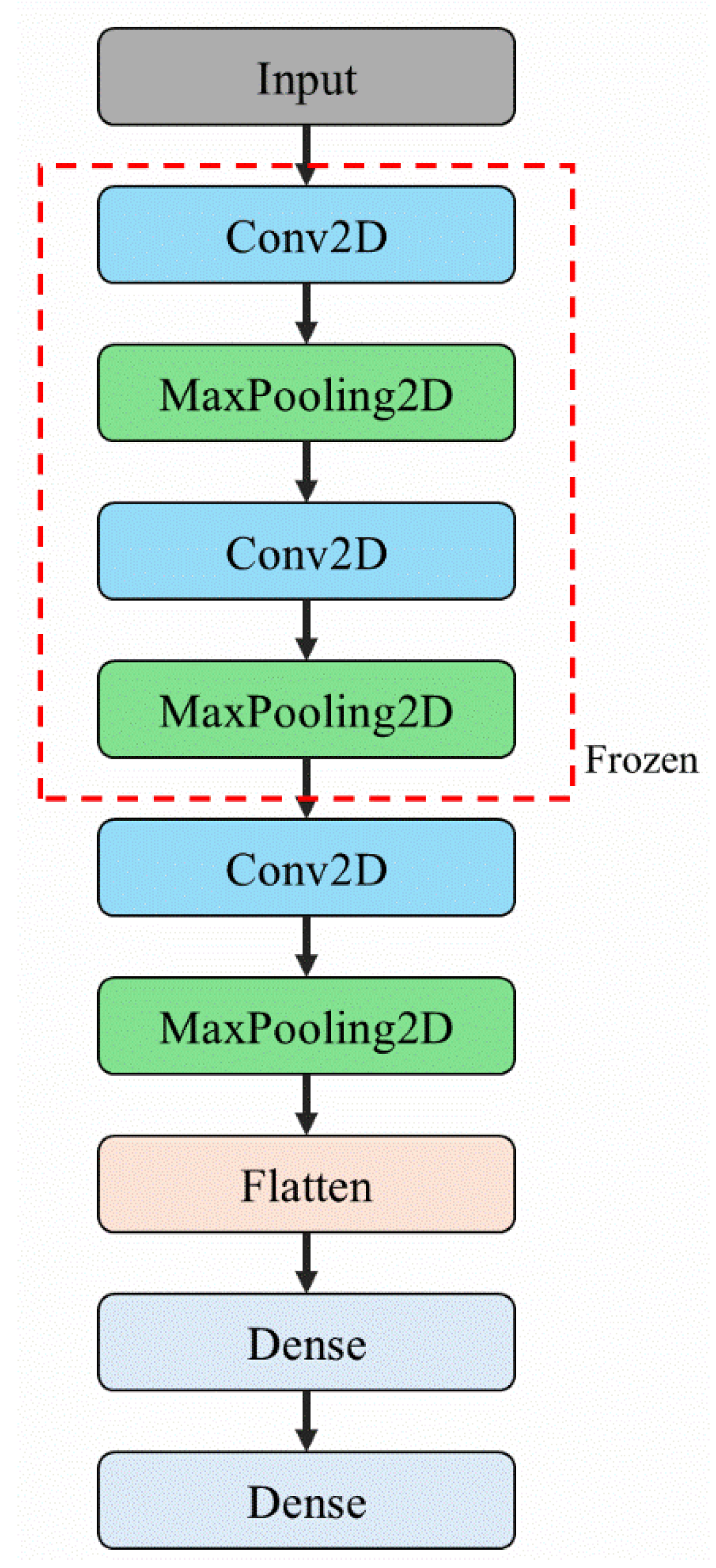
To address the high computational demands of VGG16 and ResNet50, a customized, lightweight CNN architecture—CNN-10 Layers—was developed in this study. The primary objective of this design was to maintain satisfactory image classification performance while reducing computational resource requirements, thereby enabling deployment on the industrial computers that are typically used in punching machines.
Industrial computers often have limited processing power and memory. Deploying computationally intensive deep learning models, such as VGG16, on such hardware can hinder real-time computation. To overcome this constraint and facilitate deployment on resource-constrained devices, CNN-10 Layers was derived from VGG16 through simplification. Specifically, the first, second, and last convolutional blocks were modified. The original structure, consisting of two convolutional layers followed by max-pooling, was reduced to a single convolutional layer followed by max-pooling. Additionally, sections containing three consecutive convolutional layers were removed entirely. These modifications considerably reduced the number of convolutional and fully connected layers, thereby decreasing the model’s parameter count and computational cost.
Despite its reduced depth, CNN-10 Layers retains the core design principle of VGG16, utilizing small 3 × 3 convolutional kernels for feature extraction across layers. This modification aims to effectively preserve the efficient learning of local image features while streamlining the model architecture.
Figure 6 schematically illustrates the simplification process followed to develop CNN-10 Layers.
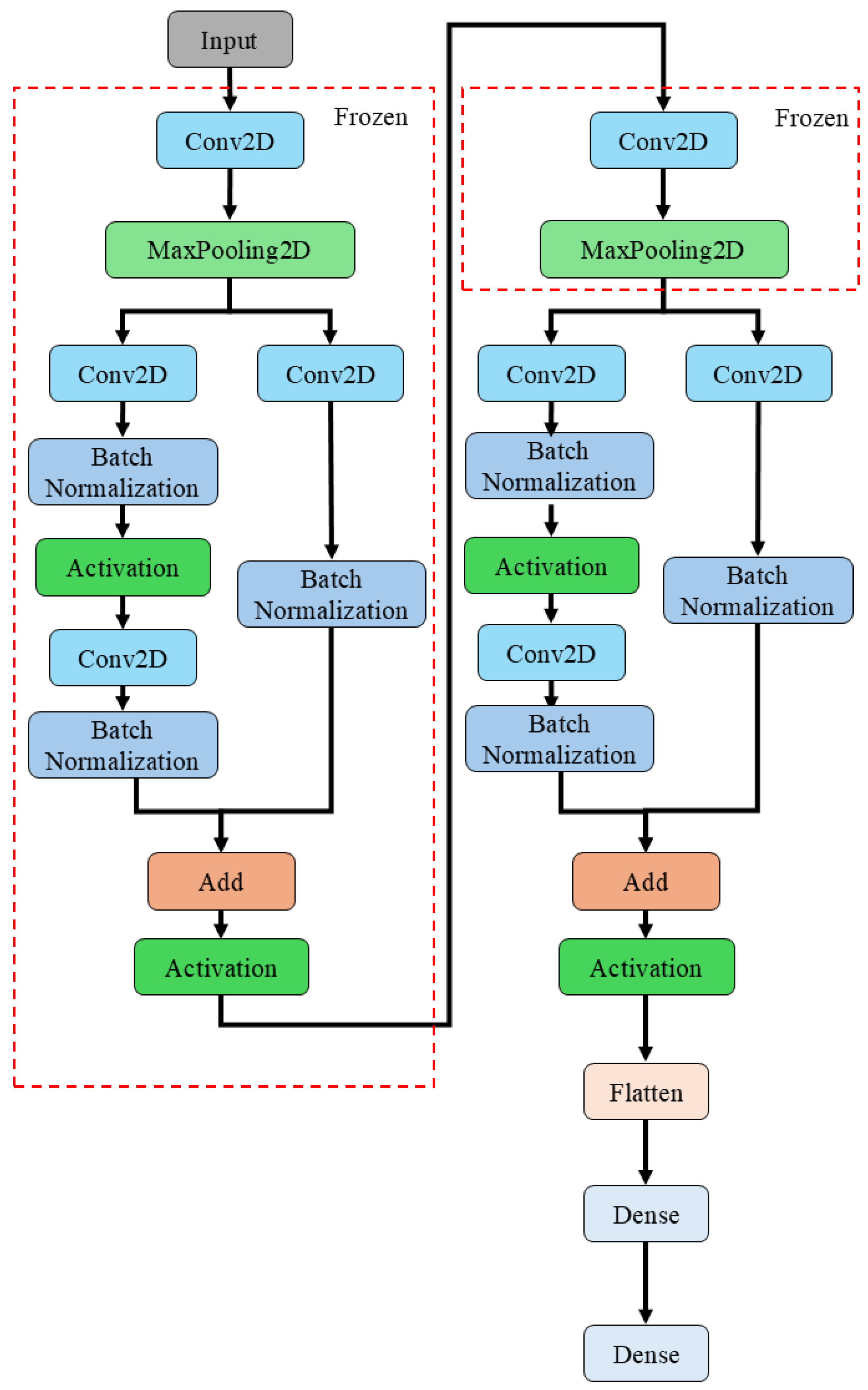
In addition to CNN-10 Layers, a custom deep learning architecture, CNN-Res, was developed. CNN-Res integrates the residual block concept from ResNet50 into the CNN-10 Layers architecture. By incorporating two ResNet50 residual blocks, the model’s performance and stability were further enhanced.
This design leverages the simplicity and computational efficiency of CNN-10 Layers while addressing the vanishing or exploding gradient problem often encountered in deep networks through the use of ResNet50′s residual learning mechanism. Specifically, the CNN-Res model introduces a residual block following the first set of convolutional and max-pooling layers in CNN-10 Layers, and another following the second set. To accommodate this added complexity, one set of convolutional and max-pooling layers is removed.
The CNN-Res architecture improves the network’s ability to learn from more complex data while maintaining computational efficiency. The residual blocks allow the input to bypass certain convolutional layers and be added directly to the output, thereby mitigating the vanishing gradient problem and enhancing the training process.
Figure 7 schematically depicts the architecture simplification process.
Model training in this study was conducted using the following hardware configuration: an Intel Core i3-9100F CPU; 24 GB of RAM; and an NVIDIA GeForce GTX 1060 (6 GB) GPU. The software environment comprised Python 3.9.19, TensorFlow-gpu 2.9.0, CUDA 11.2, and cuDNN 8.2.0.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}