
HPRT-DETR: A High-Precision Real-Time Object Detection Algorithm for Intelligent Driving Vehicles


Abstract
1. Introduction
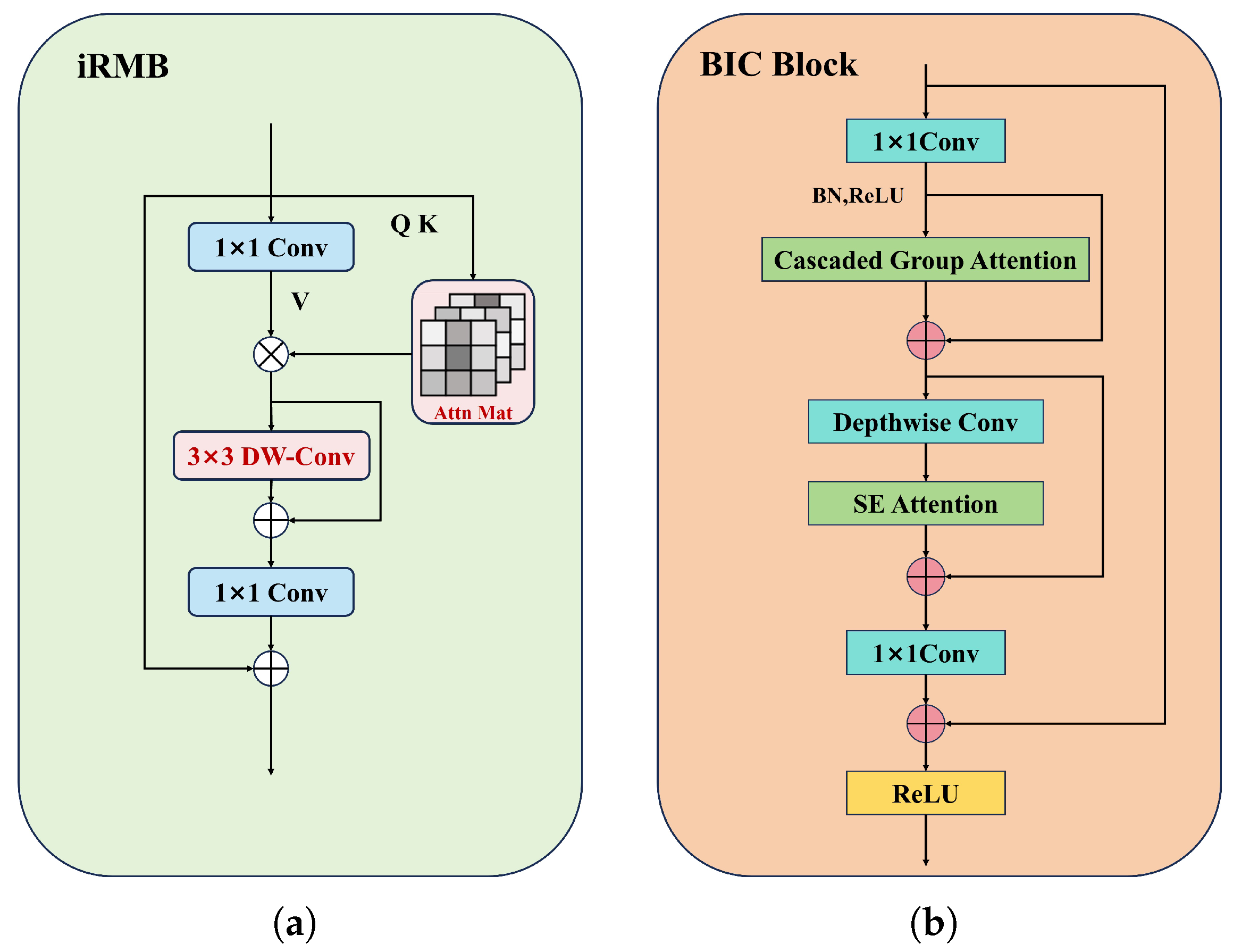
- We propose an efficient and lightweight feature extraction module for the backbone network, namely the Basic-iRMB-CGA Block (BIC Block). The network architecture design of this module is inspired by the Inverted Residual Mobile Block (iRMB). By integrating convolution operations with a Cascaded Group Attention mechanism, the module can capture local features and global contextual information, thereby significantly enhancing the model’s feature representation capability. To effectively reduce the complexity of the model, this study also incorporates depthwise separable convolutions, enabling real-time inference capabilities while maintaining a high detection accuracy.
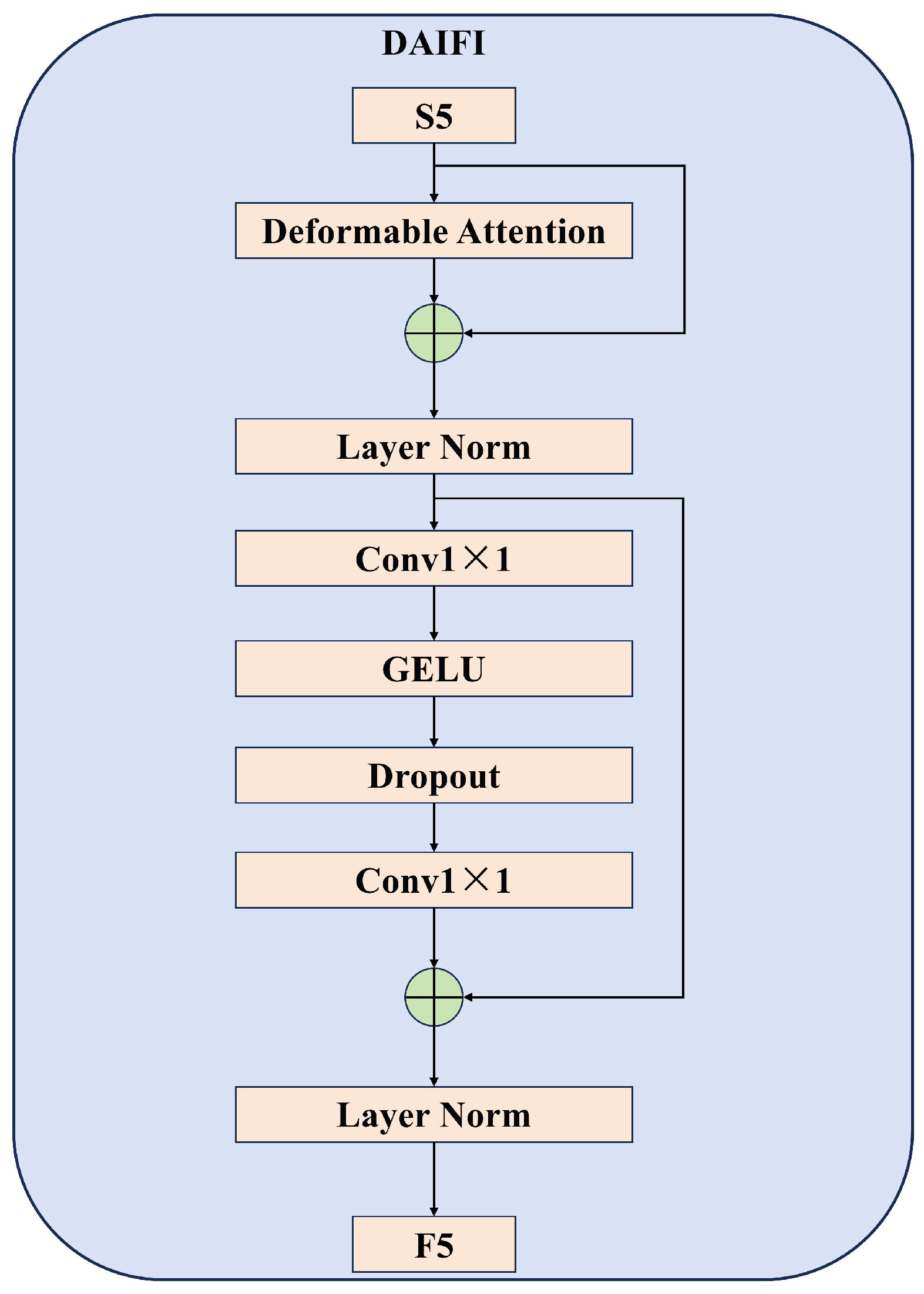
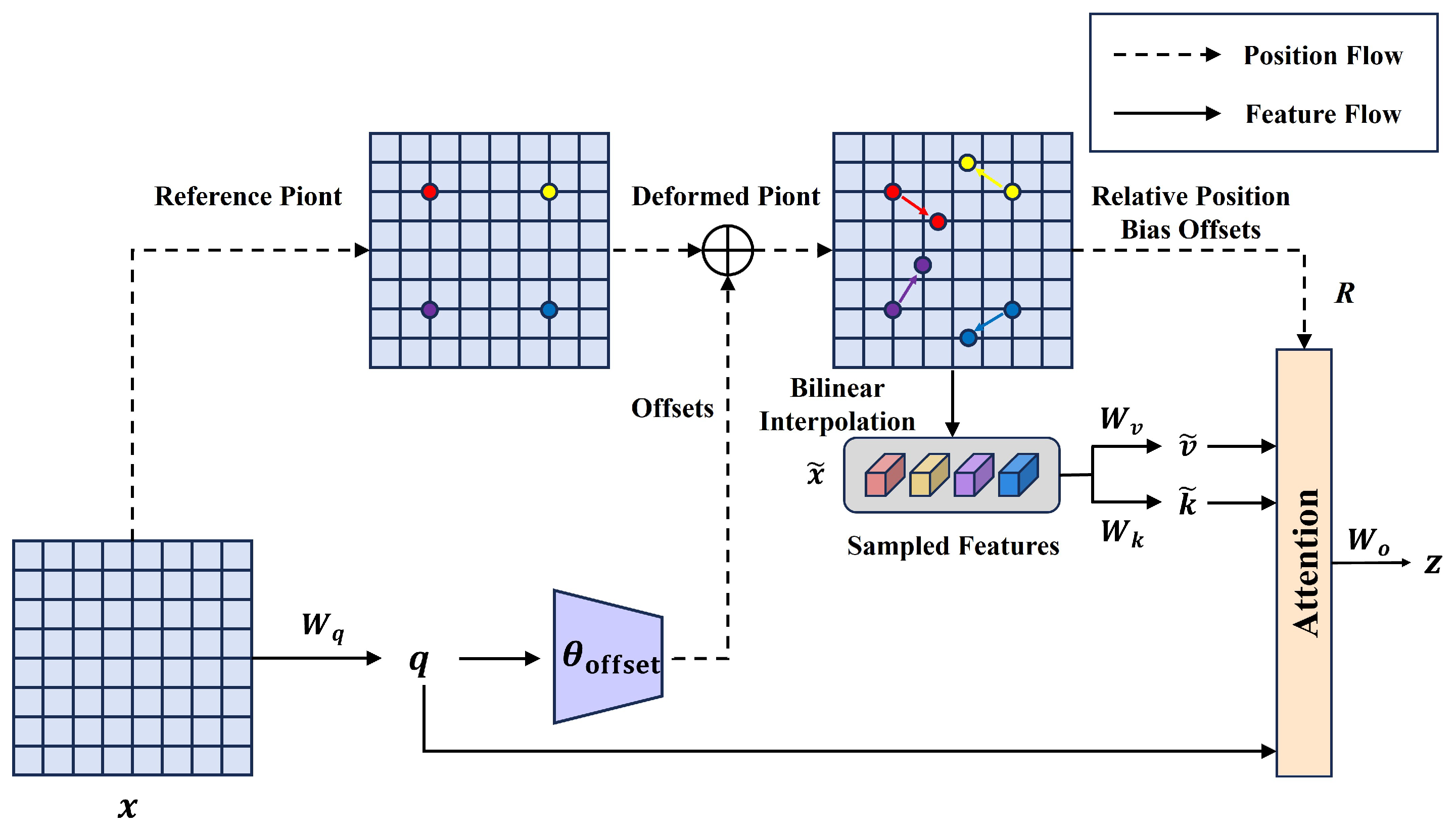
- We developed the Deformable Attention-based Intra-scale Feature Interaction (DAIFI) module, which is designed to effectively capture essential features. The Multi-head Attention in the AIFI module of RT-DETR is replaced by Deformable Attention, forming the DAIFI module. This module enhances the model’s capability to capture essential features and concentrate on critical areas in the image. As a result, it can accurately identify targets even in situations where they may be occluded.
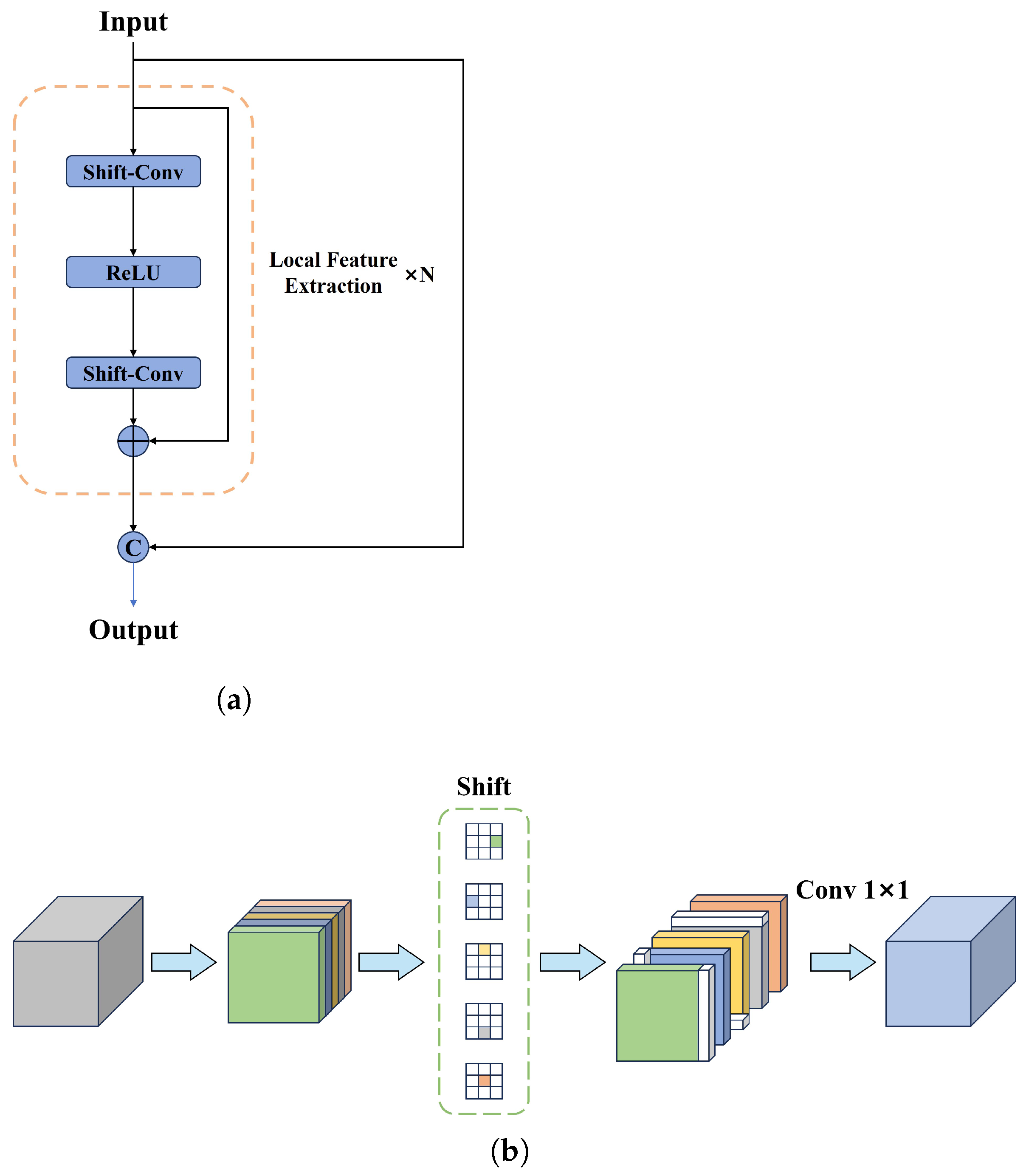
- We employed Local Feature Extraction to enhance the Fusion Block module within the CNN-based Cross-scale Feature Fusion module, thereby constructing a Local Feature Extraction Fusion (LFEF) Block that efficiently extracts local features. The shift-convolution operation in this module can provide a larger receptive field than the 1 × 1 convolution without introducing additional learnable parameters or computational burden. As a result, it can extract the local features of images efficiently and reduce the missed detection rate of small objects.
2. Related Work
3. Methods
3.1. The HPRT-DETR Model Architecture
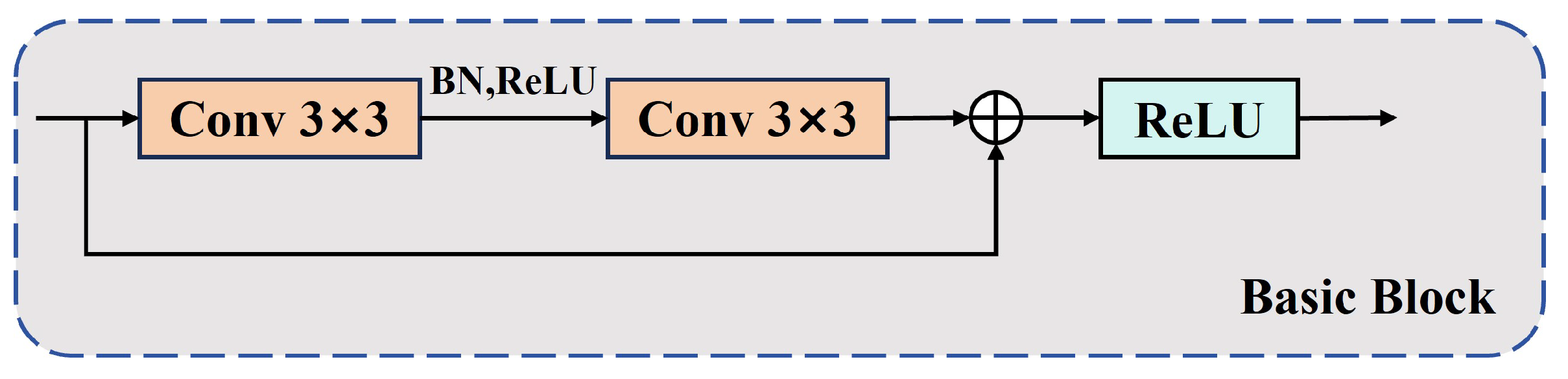
3.2. The Backbone Network Feature Extraction Module BIC Block
3.3. The DAIFI Module
3.4. LFEF Block
4. Experiment
4.1. Datasets and Experimental Settings
4.2. The Performance Comparison of Different Detection Models
4.3. Experimental Details and Discussions
4.3.1. Comparative Experiment of the Backbone Network
4.3.2. Experiment for Verifying the Effectiveness of the DAIFI Module
4.3.3. The Ablation Experiments of Different Modules
4.3.4. Model Generalization Ability Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Vaswani, A. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Li, A.; Sun, S.; Zhang, Z.; Feng, M.; Wu, C.; Li, W. A multi-scale traffic object detection algorithm for road scenes based on improved YOLOv5. Electronics 2023, 12, 878. [Google Scholar] [CrossRef]
- Wang, S.y.; Qu, Z.; Li, C.j.; Gao, L.y. BANet: Small and multi-object detection with a bidirectional attention network for traffic scenes. Eng. Appl. Artif. Intell. 2023, 117, 105504. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Zhang, L.J.; Fang, J.J.; Liu, Y.X.; Le, H.F.; Rao, Z.Q.; Zhao, J.X. CR-YOLOv8: Multiscale object detection in traffic sign images. IEEE Access 2023, 12, 219–228. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Tang, L.; Yun, L.; Chen, Z.; Cheng, F. HRYNet: A highly robust YOLO network for complex road traffic object detection. Sensors 2024, 24, 642. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Y.; Lu, Y.; Wang, Y.; Jiang, H. IDOD-YOLOV7: Image-dehazing YOLOV7 for object detection in low-light foggy traffic environments. Sensors 2023, 23, 1347. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.H.; Rizvi, S.T.R.; Dengel, A. Real-time Traffic Object Detection for Autonomous Driving. arXiv 2024, arXiv:2402.00128. [Google Scholar]
- Khan, A.H.; Nawaz, M.S.; Dengel, A. Localized semantic feature mixers for efficient pedestrian detection in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–23 June 2023; pp. 5476–5485. [Google Scholar]
- Wang, Y.; Chen, X.; Zhao, E.; Zhao, C.; Song, M.; Yu, C. An Unsupervised Momentum Contrastive Learning Based Transformer Network for Hyperspectral Target Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 9053–9068. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, Y.; Dong, Y.; Du, B. Generative Self-Supervised Learning with Spectral-Spatial Masking for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5522713. [Google Scholar] [CrossRef]
- Feng, S.; Wang, X.; Feng, R.; Xiong, F.; Zhao, C.; Li, W.; Tao, R. Transformer-Based Cross-Domain Few-Shot Learning for Hyperspectral Target Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5501716. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking mobile block for efficient attention-based models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 1389–1400. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient long-range attention network for image super-resolution. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 649–667. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Jin, P.; Zhao, S.; Golmant, N.; Gholaminejad, A.; Gonzalez, J.; Keutzer, K. Shift: A zero flop, zero parameter alternative to spatial convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9127–9135. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Han, J.; Liang, X.; Xu, H.; Chen, K.; Hong, L.; Mao, J.; Ye, C.; Zhang, W.; Li, Z.; Liang, X.; et al. Soda10m: A large-scale 2D self/semi-supervised object detection dataset for autonomous driving. arXiv 2021, arXiv:2106.11118. [Google Scholar]
- Varghese, R.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 5694–5703. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet convolutions for large receptive fields. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 363–380. [Google Scholar]
- Pan, J.; Liu, S.; Sun, D.; Zhang, J.; Liu, Y.; Ren, J.; Li, Z.; Tang, J.; Lu, H.; Tai, Y.W.; et al. Learning dual convolutional neural networks for low-level vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3070–3079. [Google Scholar]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. AKConv: Convolutional kernel with arbitrary sampled shapes and arbitrary number of parameters. arXiv 2023, arXiv:2311.11587. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Configuration | Types | Value |
|---|---|---|---|
| GPU | RTX A5000 | Learning rate | 0.0001 |
| CPU | Intel i7-12700 | Momentum | 0.9 |
| CUDA | 11.7 | Optimizer | AdamW |
| GPU Memory Size | 24 G | Batch | 4 |
| Model | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) | FPS (f/s) |
|---|---|---|---|---|---|
| YOLOv8 | 85.87 | 70.83 | 92.56 | 71.63 | 98 |
| Efficient ViT | 84.36 | 73.49 | 89.88 | 68.34 | 37 |
| Swin-Transformer | 83.19 | 72.71 | 88.64 | 67.57 | 19 |
| RT-DETR | 81.23 | 76.50 | 93.58 | 72.76 | 118 |
| RT-DETR-R50 | 88.98 | 76.28 | 94.03 | 73.12 | 108 |
| HPRT-DETR | 89.67 | 76.15 | 95.56 | 74.79 | 136 |
| Model | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) | Params (M) | GFLOPs (G) |
|---|---|---|---|---|---|---|
| Basic Block | 81.58 | 76.59 | 78.87 | 46.69 | 19.97 | 57.3 |
| Star Block | 78.56 | 74.81 | 76.44 | 48.83 | 18.76 | 53.2 |
| WTConvBlock | 86.66 | 71.68 | 77.65 | 49.34 | 17.56 | 51.7 |
| DualConvBlock | 76.80 | 74.41 | 76.14 | 48.78 | 20.86 | 59.8 |
| AKConvBlock | 83.26 | 75.64 | 77.89 | 48.98 | 16.55 | 50.4 |
| DCNv2 Block | 86.89 | 74.79 | 77.86 | 49.18 | 20.41 | 57.8 |
| BIC Block | 85.76 | 76.53 | 79.68 | 49.86 | 16.26 | 46.5 |
| Method | BIC Block | DAIFI | LFEF Block | mAP50 (%) | mAP50:95 (%) | Params (M) | GFLOPs (G) | FPS (f/s) |
|---|---|---|---|---|---|---|---|---|
| 1 (Basic) | 93.58 | 72.76 | 19.97 | 57.3 | 118 | |||
| 2 | 🗸 | 94.23 | 73.21 | 15.36 | 47.2 | 149 | ||
| 3 | 🗸 | 93.92 | 72.87 | 19.85 | 56.5 | 122 | ||
| 4 | 🗸 | 94.31 | 73.32 | 19.97 | 57.5 | 120 | ||
| 5 | 🗸 | 🗸 | 94.98 | 73.55 | 15.26 | 46.2 | 141 | |
| 6 (Ours) | 🗸 | 🗸 | 🗸 | 95.56 | 74.79 | 15.19 | 46.1 | 136 |
| Model | Precision (%) | Recall (%) | mAP50 (%) | mAP50:95 (%) | FPS (f/s) |
|---|---|---|---|---|---|
| RT-DETR | 85.72 | 76.09 | 84.63 | 63.26 | 116 |
| HPRT-DETR | 88.63 | 76.36 | 86.28 | 70.54 | 128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, X.; Fan, B.; Liu, H.; Wang, L.; Niu, J. HPRT-DETR: A High-Precision Real-Time Object Detection Algorithm for Intelligent Driving Vehicles. Sensors 2025, 25, 1778. https://doi.org/10.3390/s25061778
Song X, Fan B, Liu H, Wang L, Niu J. HPRT-DETR: A High-Precision Real-Time Object Detection Algorithm for Intelligent Driving Vehicles. Sensors. 2025; 25(6):1778. https://doi.org/10.3390/s25061778
Chicago/Turabian StyleSong, Xiaona, Bin Fan, Haichao Liu, Lijun Wang, and Jinxing Niu. 2025. "HPRT-DETR: A High-Precision Real-Time Object Detection Algorithm for Intelligent Driving Vehicles" Sensors 25, no. 6: 1778. https://doi.org/10.3390/s25061778
APA StyleSong, X., Fan, B., Liu, H., Wang, L., & Niu, J. (2025). HPRT-DETR: A High-Precision Real-Time Object Detection Algorithm for Intelligent Driving Vehicles. Sensors, 25(6), 1778. https://doi.org/10.3390/s25061778