
Enhanced Broad-Learning-Based Dangerous Driving Action Recognition on Skeletal Data for Driver Monitoring Systems



Abstract
1. Introduction
- 1.
- A Graph Spatio-Temporal Feature Representation (GSFR) method that selects the most relevant keypoints from 3D skeletal data by analyzing spatio-temporal dynamics. This approach improves detection accuracy while reducing computational complexity, ensuring real-time performance on embedded systems. The dynamic selection mechanism also enhances robustness against noisy or missing data.
- 2.
- The integration of a Broad Learning System (BLS), a lightweight neural network architecture, to process the selected features efficiently. By using sparse feature selection and Principal Component Analysis (PCA), we reduce the dimensionality of the feature space while retaining essential information, further enhancing real-time detection capabilities.
- 3.
- A dual smoothing strategy applied to the BLS output to stabilize predictions over time. This approach combines sliding window smoothing and an Exponential Moving Average (EMA), reducing sensitivity to short-term fluctuations and enhancing the reliability of detection in dynamic driving conditions.
- 4.
- Extensive experimental validation on multiple public datasets, demonstrating that the GSFR-BLS model outperforms existing methods in terms of accuracy, real-time performance, and robustness, making it suitable for deployment in real-world DMS applications.
2. Related Works
2.1. Driver Monitoring Systems
2.2. Skeleton-Based Action Recognition
2.3. Broad Learning System
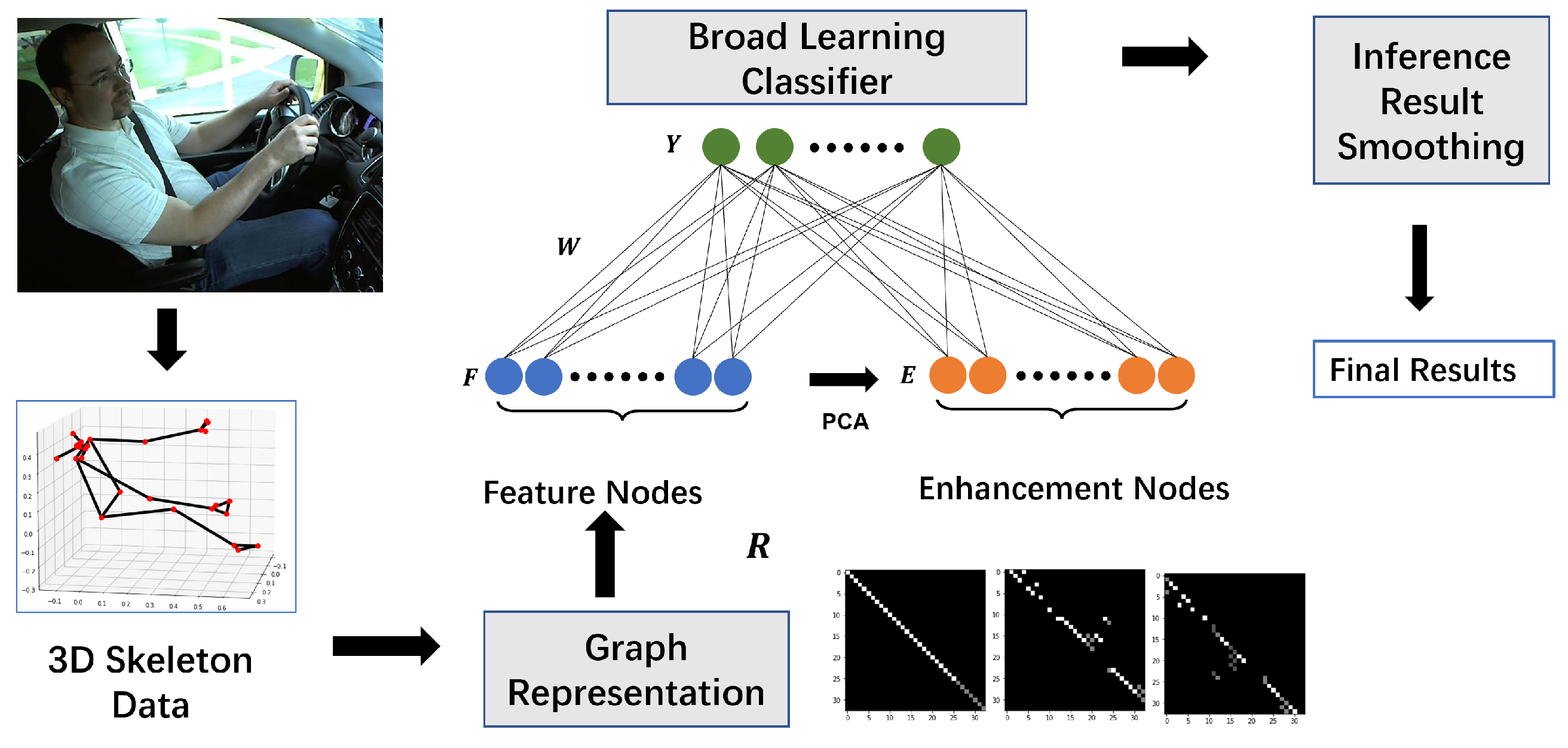
3. Technical Design of GSFR-BLS
3.1. Graph-Based Skeleton Feature Representation
| Algorithm 1: Constructing representation matrix R with spatio-temporal dynamic selection. |
 |
3.2. Broad Learning Classifier with Enhanced Feature Mapping
3.3. Inference Result Smoothing for Robust Classification
4. Experiments
4.1. Dataset
4.2. Evaluation Indicators
- Accuracy (Acc): It evaluates the accuracy of model classification, referring to the accuracy of the testing set in this study.
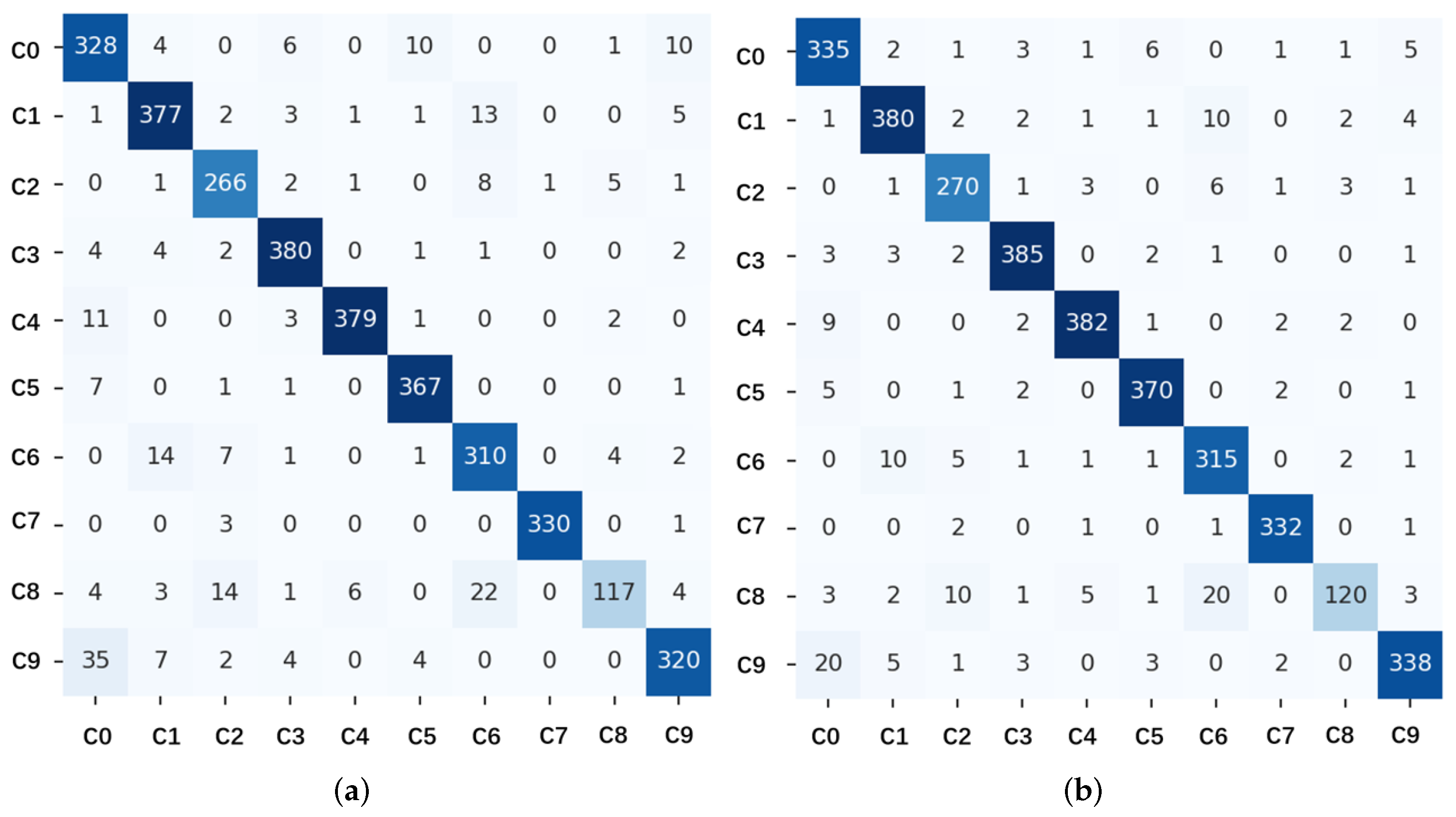
- Confusion matrix (CM): It represents the actual category and predicted category as a two-dimensional matrix, with each element showing the combination of actual and predicted categories.
- Parameters (Param): To consider the minimum number of parameters required to support model inference in practical applications, the size of the saved parameter model file as an indicator is utilized. Comparing the number of parameters with many machine learning models helps evaluate whether the model is lightweight. A smaller number of parameters signifies that the model requires less memory and computation, making it more lightweight.
- Inference time (IT): This is the time taken to infer the testing set, visually evaluating the real-time performance of model inference.
4.3. Experiment Environment
4.4. GSFR Ablation Experiment
4.5. Classification Experiment
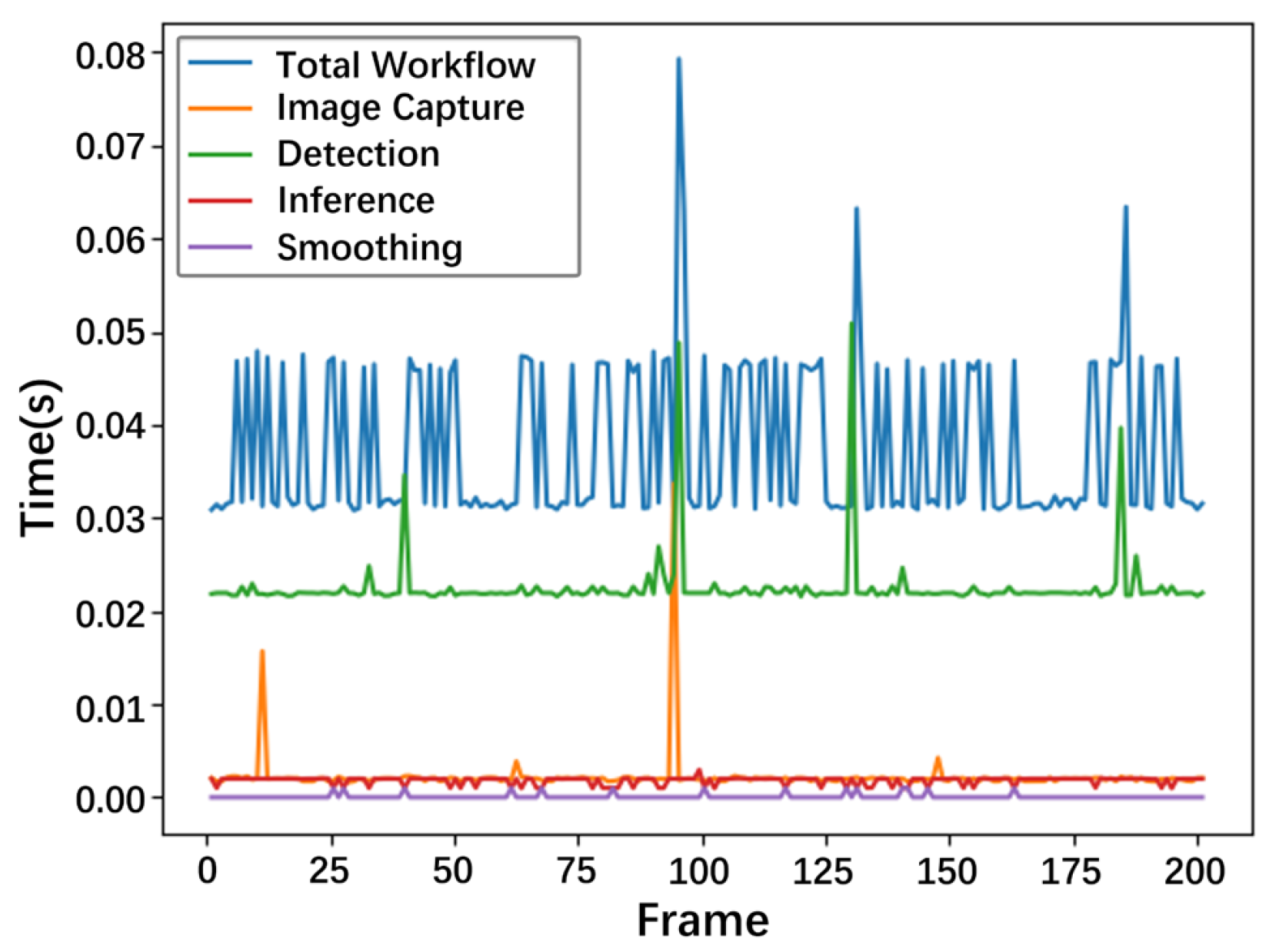
4.6. Deployment Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges, and open issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Malik, M.; Nandal, R.; Dalal, S.; Jalglan, V.; Le, D.N. Driving pattern profiling and classification using deep learning. Intell. Autom. Soft Comput. 2021, 28, 887–906. [Google Scholar] [CrossRef]
- Fink, O.; Wang, Q.; Svensen, M.; Dersin, P.; Lee, W.J.; Ducoffe, M. Potential, challenges and future directions for deep learning in prognostics and health management applications. Eng. Appl. Artif. Intell. 2020, 92, 103678. [Google Scholar] [CrossRef]
- Gao, W.; Wu, C.; Zhong, L.; Yau, K.L.A. Communication resources management based on spectrum sensing for vehicle platooning. IEEE Trans. Intell. Transp. Syst. 2022, 24, 2251–2264. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.; Huang, Z.; Chang, Y.C.; Liu, L.; Pei, Q. A Low-Cost and Lightweight Real-Time Object-Detection Method Based on UAV Remote Sensing in Transportation Systems. Remote Sens. 2024, 16, 3712. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, C.; Wang, Z.; Cong, L.; Lu, H.; Pei, Q.; Wan, S. Automated Vehicle Platooning: A Two-Stage Approach Based on Vehicle-Road Cooperation. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Kot, A.C.; Wang, G. Skeleton-based action recognition using spatio-temporal LSTM network with trust gates. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 3007–3021. [Google Scholar] [CrossRef]
- Xin, W.; Liu, R.; Liu, Y.; Chen, Y.; Yu, W.; Miao, Q. Transformer for skeleton-based action recognition: A review of recent advances. Neurocomputing 2023, 537, 164–186. [Google Scholar] [CrossRef]
- Feng, S.; Chen, C.P. Fuzzy broad learning system: A novel neuro-fuzzy model for regression and classification. IEEE Trans. Cybern. 2018, 50, 414–424. [Google Scholar] [CrossRef]
- Issa, S.; Peng, Q.; You, X. Emotion classification using EEG brain signals and the broad learning system. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 7382–7391. [Google Scholar] [CrossRef]
- Reddy, B.; Kim, Y.H.; Yun, S.; Seo, C.; Jang, J. Real-time driver drowsiness detection for embedded system using model compression of deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 121–128. [Google Scholar]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An empirical evaluation of deep learning on highway driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Behrendt, K.; Novak, L.; Botros, R. A deep learning approach to traffic lights: Detection, tracking, and classification. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1370–1377. [Google Scholar]
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2969–2978. [Google Scholar]
- Wang, P.; Wang, S.; Hou, Y.; Li, C. Skeleton-based action recognition using LSTM and CNN. In Proceedings of the IEEE International Conference on Computer Vision, Hong Kong, 10–14 July 2017. [Google Scholar]
- Su, K.; Liu, X.; Shlizerman, E. Predict & cluster: Unsupervised skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9631–9640. [Google Scholar]
- Cao, C.; Lan, C.; Zhang, Y.; Zeng, W.; Lu, H.; Zhang, Y. Skeleton-based action recognition with gated convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3247–3257. [Google Scholar] [CrossRef]
- Wu, L.; Zhang, C.; Zou, Y. SpatioTemporal focus for skeleton-based action recognition. Pattern Recognit. 2023, 136, 109231. [Google Scholar] [CrossRef]
- Chen, C.P.; Liu, Z. Broad learning system: An effective and efficient incremental learning system without the need for deep architecture. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 10–24. [Google Scholar] [CrossRef]
- Hatcher, W.G.; Yu, W. A survey of deep learning: Platforms, applications and emerging research trends. IEEE Access 2018, 6, 24411–24432. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Lavin, A.; Gilligan-Lee, C.M.; Visnjic, A.; Ganju, S.; Newman, D.; Ganguly, S.; Lange, D.; Baydin, A.G.; Sharma, A.; Gibson, A.; et al. Technology readiness levels for machine learning systems. Nat. Commun. 2022, 13, 6039. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Y.; Chen, L.; Zhao, J.; Wang, W.; Liu, Q. Incremental Bayesian broad learning system and its industrial application. Artif. Intell. Rev. 2021, 54, 3517–3537. [Google Scholar] [CrossRef]
- Li, Q.; Wen, Z.; Wu, Z.; Hu, S.; Wang, N.; Li, Y.; Liu, X.; He, B. A survey on federated learning systems: Vision, hype and reality for data privacy and protection. IEEE Trans. Knowl. Data Eng. 2021, 35, 3347–3366. [Google Scholar] [CrossRef]
- Bazarevsky, V.; Grishchenko, I.; Raveendran, K.; Zhu, T.; Zhang, F.; Grundmann, M. Blazepose: On-device real-time body pose tracking. arXiv 2020, arXiv:2006.10204. [Google Scholar]
- Ke, S.R.; Thuc, H.L.U.; Lee, Y.J.; Hwang, J.N.; Yoo, J.H.; Choi, K.H. A review on video-based human activity recognition. Computers 2013, 2, 88–131. [Google Scholar] [CrossRef]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. London Edinburgh Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Diederik, P.K. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vaegae, N.K.; Pulluri, K.K.; Bagadi, K.; Oyerinde, O.O. Design of an efficient distracted driver detection system: Deep learning approaches. IEEE Access 2022, 10, 116087–116097. [Google Scholar] [CrossRef]
- Sajid, F.; Javed, A.R.; Basharat, A.; Kryvinska, N.; Afzal, A.; Rizwan, M. An efficient deep learning framework for distracted driver detection. IEEE Access 2021, 9, 169270–169280. [Google Scholar] [CrossRef]
- Chawan, P.M.; Satardekar, S.; Shah, D.; Badugu, R.; Pawar, A. Distracted driver detection and classification. Int. J. Eng. Res. Appl. 2018, 8, 60–64. [Google Scholar]
- Huo, R.; Chen, J.; Zhang, Y.; Gao, Q. 3D skeleton aware driver behavior recognition framework for autonomous driving system. Neurocomputing 2025, 613, 128743. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, Y.; Zhang, X. Driver-skeleton: A dataset for driver action recognition. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 1509–1514. [Google Scholar]
- Wang, J.; Mu, C.; Di, L.; Li, M.; Sun, Z.; Liu, S. Recognition of Unsafe Driving Behaviours Using SC-GCN. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–8. [Google Scholar]
- Li, T.; Li, X.; Ren, B.; Guo, G. An Effective Multi-Scale Framework for Driver Behavior Recognition with Incomplete Skeletons. IEEE Trans. Veh. Technol. 2023, 73, 295–309. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support vector machine. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 101–121. [Google Scholar]
- Chen, C.; Wang, W.; Liu, Z.; Wang, Z.; Li, C.; Lu, H.; Pei, Q.; Wan, S. RLFN-VRA: Reinforcement learning-based flexible numerology V2V resource allocation for 5G NR V2X networks. IEEE Trans. Intell. Veh. 2024. early access. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Z.; Yu, Y.; Jin, F.; Han, W.; Berretti, S.; Liu, L.; Pei, Q. A Deep Learning-Based Traffic Classification Method for 5G Aerial Computing Networks. IEEE Internet Things J. 2025. early access. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action Number | Category | State Farm | Driver Skeleton |
|---|---|---|---|
| c0 | Safe driving | 1860 | 3928 |
| c1 | Texting—right | 1932 | 4118 |
| c2 | Talking on the phone—right | 1444 | 4125 |
| c3 | Texting—left | 1887 | 4201 |
| c4 | Talking on the phone—left | 1847 | 3946 |
| c5 | Operating the radio | 2011 | 3609 |
| c6 | Drinking | 1763 | 4019 |
| c7 | Reaching behind | 1608 | 3753 |
| c8 | Hair and makeup | 965 | 3533 |
| c9 | Talking to passenger | 1826 | 3860 |
| Dataset | Classifier | GSFR | Acc(%) |
|---|---|---|---|
| The State Farm dataset | BLS | ✓ | 93.639 (+1.103) |
| ✕ | 92.536 | ||
| DNN | ✓ | 93.287 (+1.253) | |
| ✕ | 92.034 | ||
| GCN | ✓ | 73.892 (+3.219) | |
| ✕ | 70.673 | ||
| The Driver Skeleton dataset | BLS | ✓ | 93.512 (+1.841) |
| ✕ | 91.671 | ||
| DNN | ✓ | 92.606 (+1.865) | |
| ✕ | 90.741 | ||
| GCN | ✓ | 74.543 (+3.114) | |
| ✕ | 71.429 |
| Dataset | Classifier | Acc (%) | IT (s) | Param (KB) |
|---|---|---|---|---|
| State Farm | Random forest | 91.372 | 0.202 | 44,439 |
| Gradient boosting | 93.564 | 0.064 | 1612 | |
| SVM | 91.112 | 3.023 | 6786 | |
| DNN | 92.034 | 0.179 | 1128 | |
| 1D-CNN | 83.834 | 2.813 | 2253 | |
| GCN | 70.673 | 1.779 | 81 | |
| BLS | 92.164 | 0.041 | 364 | |
| SC-GCN [39] | 91.45 | / | / | |
| DDDS [34] | 93.12 | / | / | |
| Proposed method | 93.639 | 0.071 | 507 | |
| Driver Skeleton | Random forest | 91.738 | 0.526 | 77,431 |
| Gradient boosting | 90.830 | 0.113 | 1641 | |
| SVM | 85.535 | 16.314 | 14,098 | |
| DNN | 90.741 | 0.432 | 1128 | |
| 1D-CNN | 83.395 | 1.481 | 809 | |
| GCN | 71.429 | 4.356 | 81 | |
| BLS | 91.671 | 0.151 | 364 | |
| 2S-GCN-TAtt [38] | 90.5 | / | / | |
| Beh-MSFNet [37] | 95.4 | / | 3614.72 | |
| Proposed method | 93.512 | 0.182 | 507 |
| Modules | Time Cost |
|---|---|
| Image Capture | 0.0022 s |
| Detection | 0.0225 s |
| Inference | 0.0018 s |
| Smoothing | s |
| Total Workflow | 0.0375 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Liu, Z.; Shan, H.; Chen, C. Enhanced Broad-Learning-Based Dangerous Driving Action Recognition on Skeletal Data for Driver Monitoring Systems. Sensors 2025, 25, 1769. https://doi.org/10.3390/s25061769
Li P, Liu Z, Shan H, Chen C. Enhanced Broad-Learning-Based Dangerous Driving Action Recognition on Skeletal Data for Driver Monitoring Systems. Sensors. 2025; 25(6):1769. https://doi.org/10.3390/s25061769
Chicago/Turabian StyleLi, Pu, Ziye Liu, Hangguan Shan, and Chen Chen. 2025. "Enhanced Broad-Learning-Based Dangerous Driving Action Recognition on Skeletal Data for Driver Monitoring Systems" Sensors 25, no. 6: 1769. https://doi.org/10.3390/s25061769
APA StyleLi, P., Liu, Z., Shan, H., & Chen, C. (2025). Enhanced Broad-Learning-Based Dangerous Driving Action Recognition on Skeletal Data for Driver Monitoring Systems. Sensors, 25(6), 1769. https://doi.org/10.3390/s25061769