
Surface Defect Detection Based on Adaptive Multi-Scale Feature Fusion


Abstract
1. Introduction
2. Data Preprocessing and Filtering
2.1. Dataset Filtered
2.2. Dataset Preprocessing
3. Proposed Methodology
3.1. Overall Architectural Design
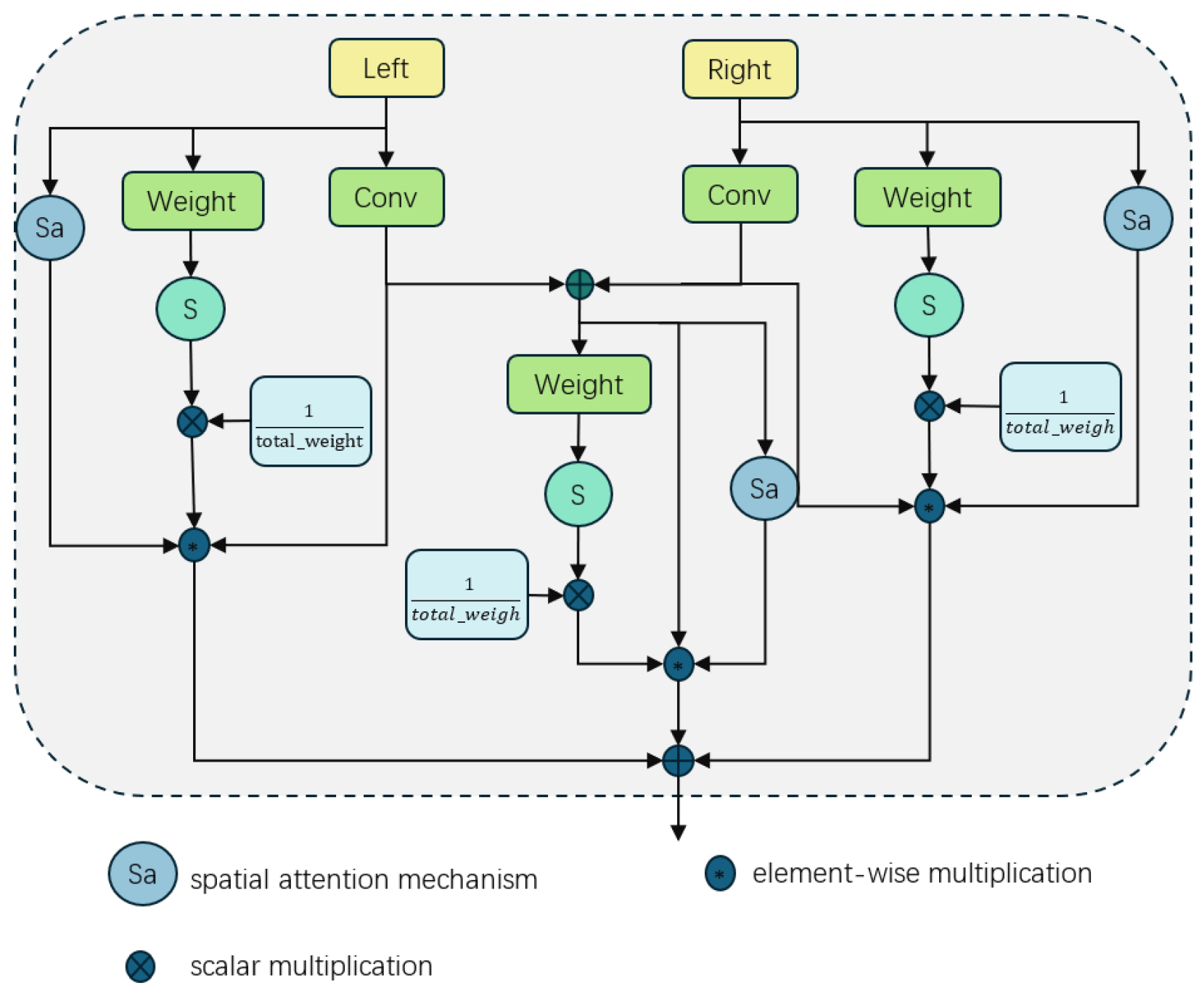
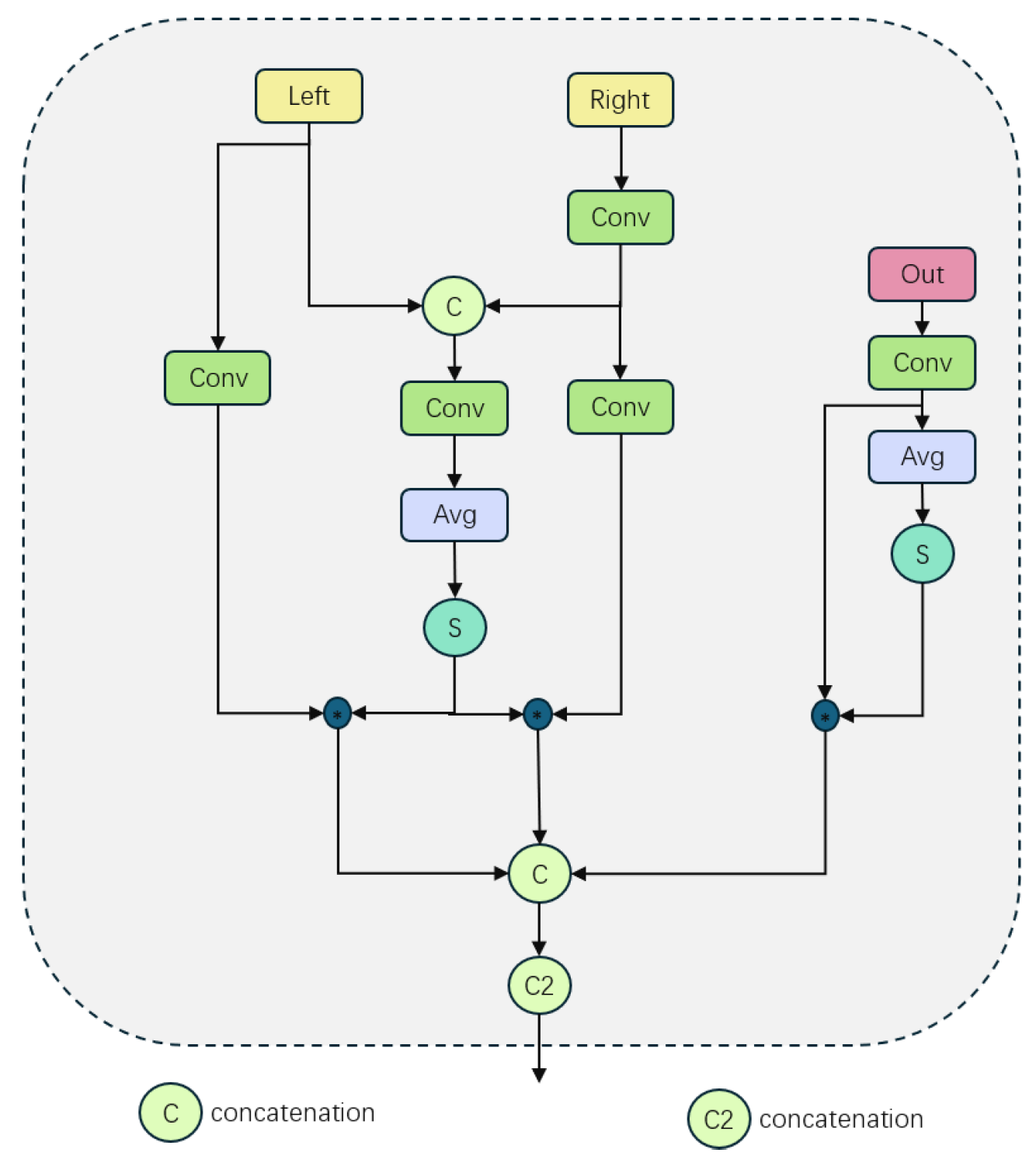
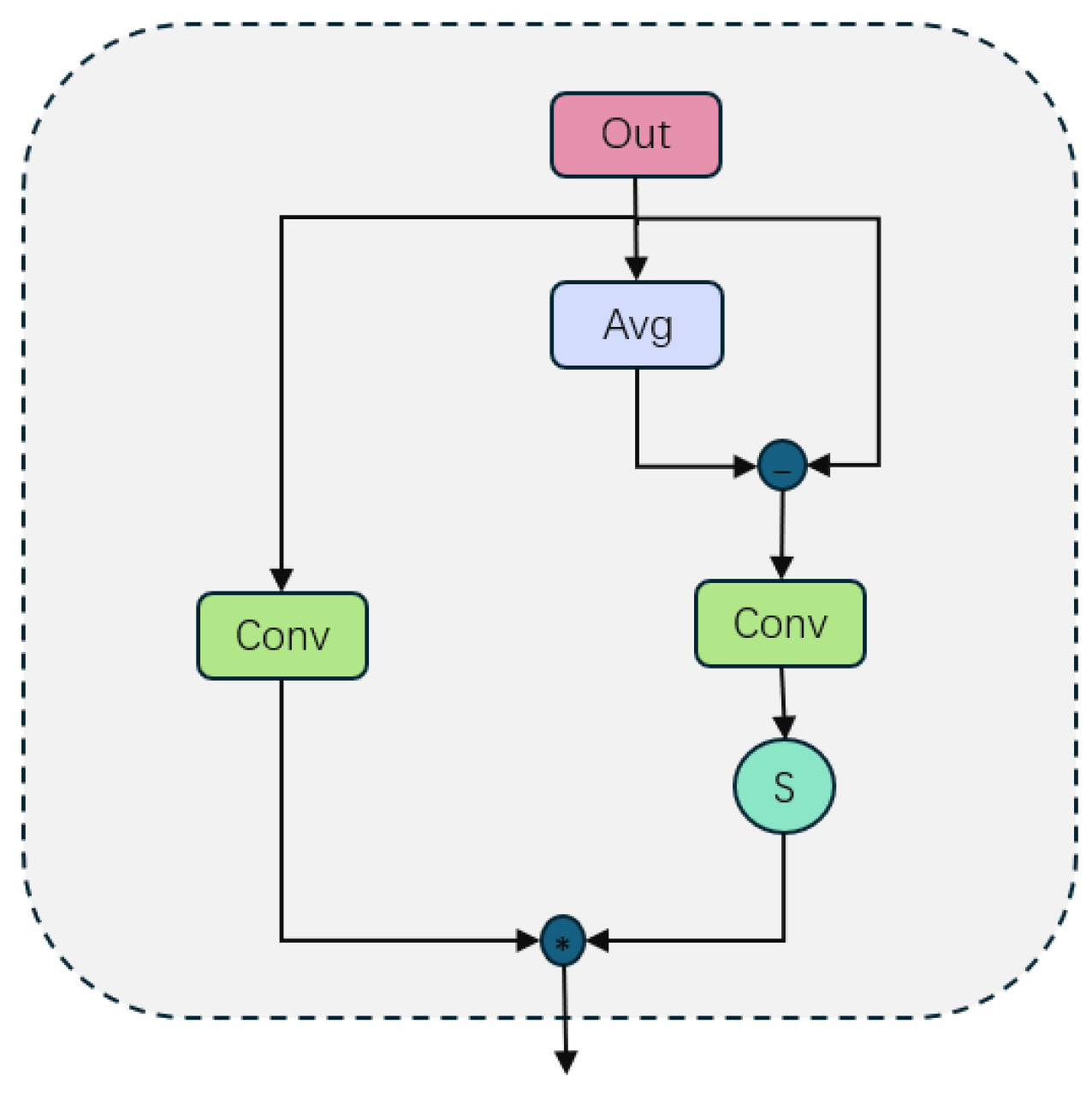
3.2. Adaptive Upsampling Fusion Module
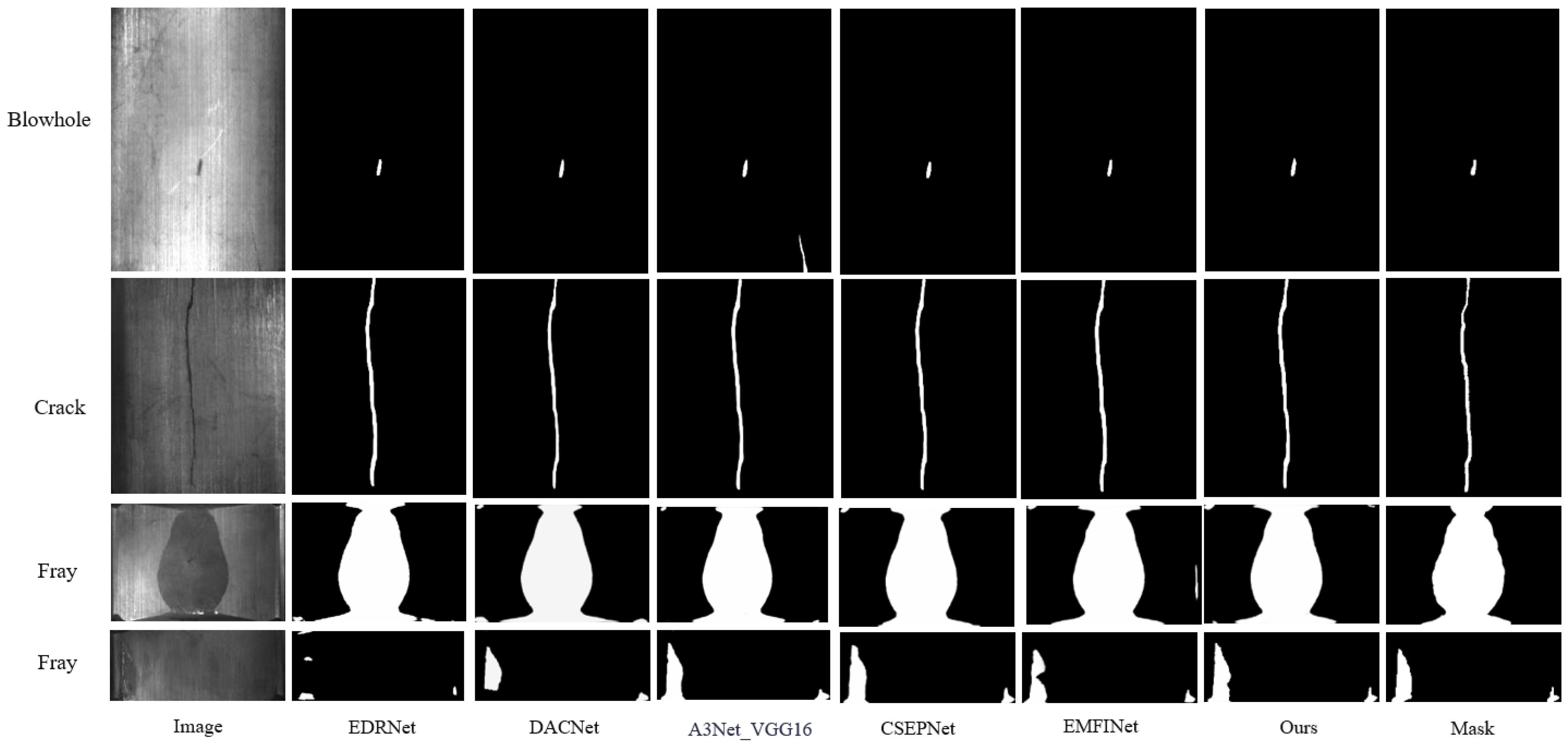
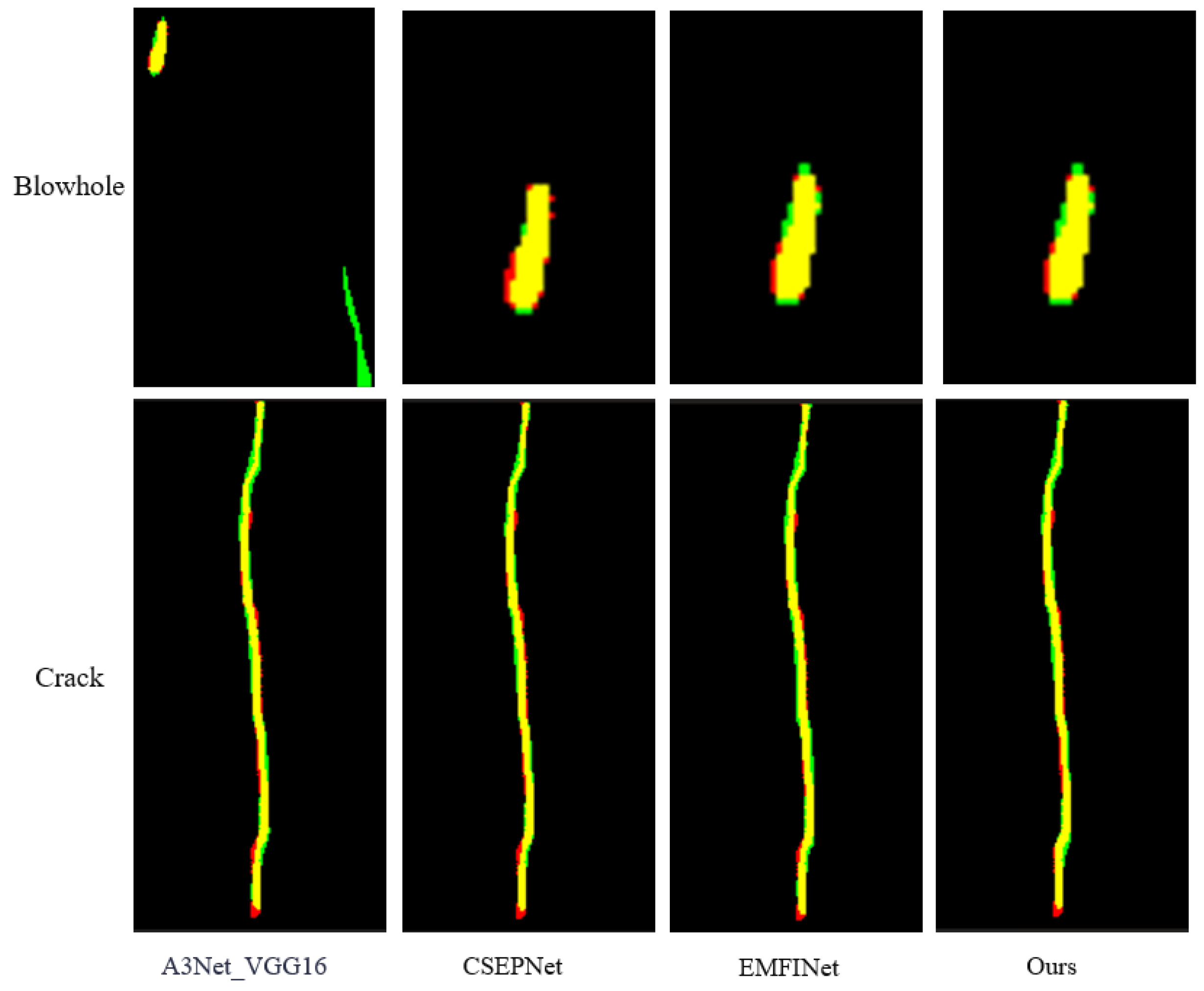
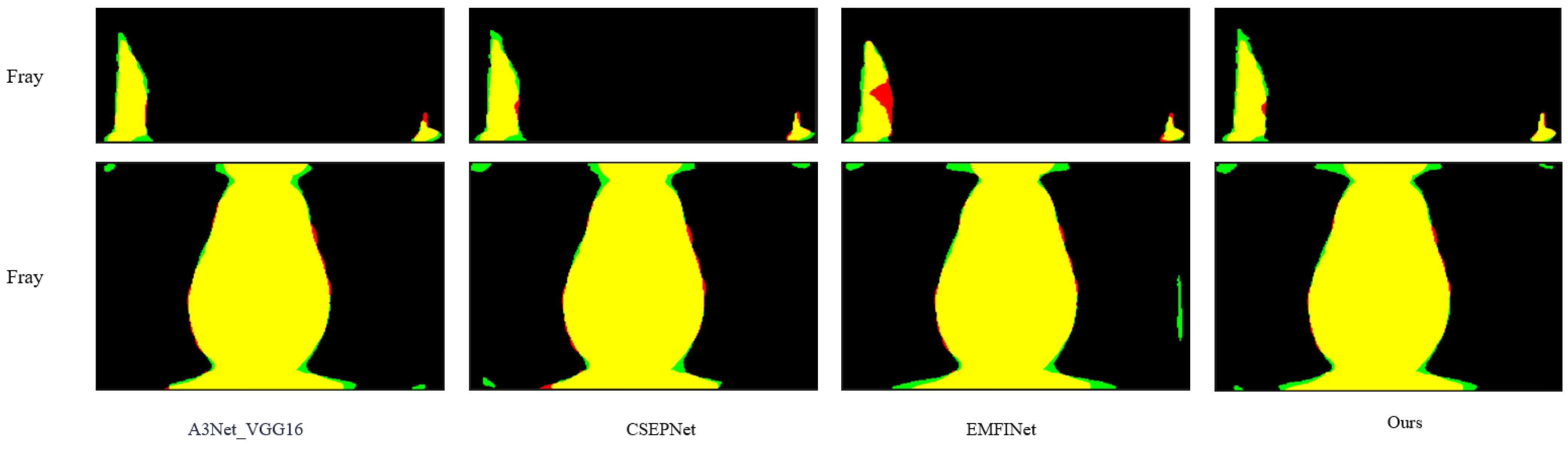
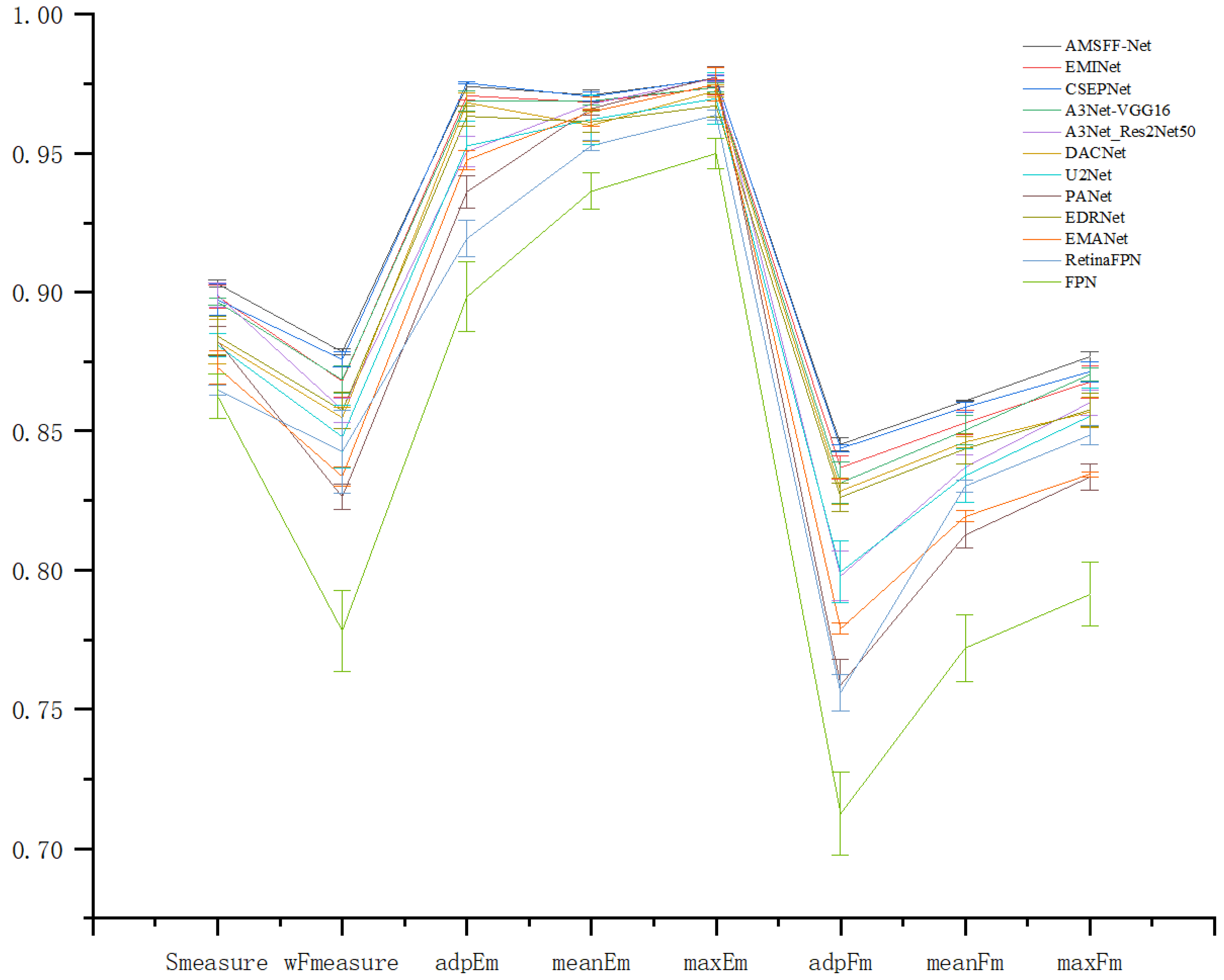
4. Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yuan, Y.; Li, C.; Kim, J.; Cai, W.; Feng, D.D. Reversion Correction and Regularized Random Walk Ranking for Saliency Detection. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2017, 27, 1311–1322. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Chang, Y.; Lu, P.; Xu, Z.; Fu, C.; Wang, Y. Contour level object detection with top-down information. Opt. Int. J. Light Electron Opt. 2014, 125, 2708–2712. [Google Scholar] [CrossRef]
- Jing, H.; Han, Q.; He, X.; Niu, X. Saliency Density and Edge Response Based Salient Object Detection. IEICE Trans. Inf. Syst. 2013, 96, 1243–1246. [Google Scholar] [CrossRef]
- Yeh, M.C.; Hsu, C.F.; Lu, C.J. Fast salient object detection through efficient subwindow search. Pattern Recognit. Lett. 2014, 46, 60–66. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Tang, B.; Chen, L.; Sun, W.; Lin, Z.K. Review of surface defect detection of steel products based on machine vision. IET Image Process. 2023, 17, 303–322. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A New Steel Defect Detection Algorithm Based on Deep Learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient detection model of steel strip surface defects based on YOLO-V7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Li, Y.; He, L.; Zhang, M.; Cheng, Z.; Liu, W.; Wu, Z. Improving the Performance of the Single Shot Multibox Detector for Steel Surface Defects with Context Fusion and Feature Refinement. Electronics 2023, 12, 2440. [Google Scholar] [CrossRef]
- Lu, K.; Wang, W.; Pan, X.; Zhou, Y.; Chen, Z.; Zhao, Y.; Wang, B. Resformer-Unet: A U-shaped Framework Combining ResNet and Transformer for Segmentation of Strip Steel Surface Defects. ISIJ Int. 2024, 64, 67–75. [Google Scholar] [CrossRef]
- Tang, B.; Song, Z.K.; Sun, W.; Wang, X.D. An end-to-end steel surface defect detection approach via Swin transformer. IET Image Process. 2023, 17, 1334–1345. [Google Scholar] [CrossRef]
- Zhao, W.; Song, K.; Wang, Y.; Liang, S.; Yan, Y. FaNet: Feature-aware network for few shot classification of strip steel surface defects. Measurement 2023, 208, 112446. [Google Scholar] [CrossRef]
- Zhang, L.; Bian, Y.; Jiang, P.; Zhang, F. A transfer residual neural network based on ResNet-50 for detection of steel surface defects. Appl. Sci. 2023, 13, 5260. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, J.; Ge, Y. Handling vanishing gradient problem using artificial derivative. IEEE Access 2021, 9, 22371–22377. [Google Scholar] [CrossRef]
- Ye, S.; Wu, J.; Jin, Y.; Cui, J. Novel variant transformer-based method for aluminum profile surface defect detection. Meas. Sci. Technol. 2024, 36, 025602. [Google Scholar] [CrossRef]
- Cui, W.; Song, K.; Feng, H.; Jia, X.; Liu, S.; Yan, Y. Autocorrelation-Aware Aggregation Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2023, 72, 5019412. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Advances in neural information processing systems. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Chintala, S.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4548–4557. [Google Scholar]
- Hodson, T.O. Root-mean-square error (RMSE) or mean absolute error (MAE): When to use them or not. Geosci. Model Dev. 2022, 15, 5481–5487. [Google Scholar] [CrossRef]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. arXiv 2018, arXiv:1805.10421. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Florida, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 1597–1604. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2015, 24, 5706–5722. [Google Scholar] [CrossRef]
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder-Decoder Residual Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense attention-guided cascaded network for salient object detection of strip steel surface defects. IEEE Trans. Instrum. Meas. 2021, 71, 5004914. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Liu, Z.; Gong, C.; Zhang, J.; Yan, C. Edge-aware multiscale feature integration network for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5634819. [Google Scholar] [CrossRef]
- Ding, T.; Li, G.; Liu, Z.; Wang, Y. Cross-Scale Edge Purification Network for salient object detection of steel defect images. Measurement 2022, 199, 111429. [Google Scholar] [CrossRef]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6399–6408. [Google Scholar]
- Li, X.; Zhong, Z.; Wu, J.; Yang, Y.; Lin, Z.; Liu, H. Expectation-maximization attention networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9167–9176. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Values | Parameter | Values |
|---|---|---|---|
| Training Cycles | 150 | Learning Rate Decay Type | Poly |
| Learning Rate | 0.0015 | Learning Rate Decay Rate | 0.9 |
| Weight Decay | Batch Size | 8 | |
| Print Frequency | 50 | Input Size | 256 × 256 |
| Momentum | 0.9 |
| Method | Backbone | Type | Module | M↓ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPN [35] | Res101 | CN. | 59.73 | 0.8550 | 0.0085 | 0.8825 | 0.9302 | 0.9485 | 0.6927 | 0.7585 | 0.7811 | 0.7594 |
| RetinaFPN [35] | Res101 | CN. | 21.35 | 0.8671 | 0.0099 | 0.9285 | 0.9522 | 0.9627 | 0.7647 | 0.8332 | 0.8492 | 0.8396 |
| EMANet [36] | Res101 | CS. | 22.41 | 0.8659 | 0.0054 | 0.9510 | 0.9689 | 0.9782 | 0.7784 | 0.8176 | 0.8336 | 0.8315 |
| EDRNet [31] | Res34 | CN. | 39.15 | 0.8806 | 0.0060 | 0.9598 | 0.9571 | 0.9623 | 0.8218 | 0.8374 | 0.8503 | 0.8510 |
| PANet [37] | Res50 | CS. | 36.18 | 0.8801 | 0.0054 | 0.9287 | 0.9696 | 0.9826 | 0.7464 | 0.8094 | 0.8341 | 0.8249 |
| U2Net [38] | Residual U-Block (RSU) | CS. | 1.13 | 0.8800 | 0.0063 | 0.9587 | 0.9689 | 0.9763 | 0.8016 | 0.8391 | 0.8609 | 0.8552 |
| DACNet [32] | Res34 | CR. | 98.39 | 0.8902 | 0.0059 | 0.9668 | 0.9641 | 0.9741 | 0.8260 | 0.8486 | 0.8615 | 0.8582 |
| A3Net_Res2Net50 [17] | Res2_50 | CS. | 31.08 | 0.8983 | 0.0049 | 0.9536 | 0.9693 | 0.9780 | 0.8019 | 0.8386 | 0.8632 | 0.8598 |
| A3Net_VGG16 [17] | VGG16 | CS. | 17.32 | 0.8981 | 0.0048 | 0.9661 | 0.9670 | 0.9717 | 0.8266 | 0.8447 | 0.8675 | 0.8633 |
| CSEPNET [34] | VGG16 | CS. | 19.36 | 0.8896 | 0.0048 | 0.9747 | 0.9704 | 0.9766 | 0.8429 | 0.8563 | 0.8677 | 0.8727 |
| EMFINet [33] | Res34 | CR. | 99.13 | 0.9007 | 0.0050 | 0.9723 | 0.9691 | 0.9743 | 0.8425 | 0.8561 | 0.8688 | 0.8725 |
| Ours | VGG16 | CS. | 17.39 | 0.9038 | 0.0048 | 0.9762 | 0.9733 | 0.9793 | 0.8445 | 0.8611 | 0.8782 | 0.8800 |
| Method | FPN | RetinaFPN | EMANet | EDRNet | PANet | U2Net | DACNet | A3Net_Res2Net50 | A3Net_VGG16 | CSEPNET | EMFINet | Ours |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Params (M) | 59.73 | 21.35 | 22.41 | 39.15 | 36.18 | 1.13 | 98.39 | 31.08 | 17.32 | 19.36 | 99.13 | 17.39 |
| Speed (FPS) | 21.75 | 14.61 | 23.85 | 5.78 | 22.89 | 12.78 | 3.80 | 22.92 | 15.40 | 12.66 | 3.58 | 15.57 |
| Settings | ↑ | M↓ | ↑ | ↑ |
|---|---|---|---|---|
| B | 0.8982 | 0.0048 | 0.9717 | 0.8633 |
| w/o aspect ratio | 0.9004 | 0.0048 | 0.9749 | 0.8755 |
| w/o random rotation | 0.8981 | 0.0045 | 0.9790 | 0.8795 |
| w/o AMSFF | 0.8934 | 0.0048 | 0.9757 | 0.8662 |
| w AMSFF | 0.8995 | 0.0048 | 0.9780 | 0.8745 |
| Ours | 0.9038 | 0.0048 | 0.9793 | 0.8800 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, G.; Cheng, L.; Yuan, H.; Li, X. Surface Defect Detection Based on Adaptive Multi-Scale Feature Fusion. Sensors 2025, 25, 1720. https://doi.org/10.3390/s25061720
Wen G, Cheng L, Yuan H, Li X. Surface Defect Detection Based on Adaptive Multi-Scale Feature Fusion. Sensors. 2025; 25(6):1720. https://doi.org/10.3390/s25061720
Chicago/Turabian StyleWen, Guochen, Li Cheng, Haiwen Yuan, and Xuan Li. 2025. "Surface Defect Detection Based on Adaptive Multi-Scale Feature Fusion" Sensors 25, no. 6: 1720. https://doi.org/10.3390/s25061720
APA StyleWen, G., Cheng, L., Yuan, H., & Li, X. (2025). Surface Defect Detection Based on Adaptive Multi-Scale Feature Fusion. Sensors, 25(6), 1720. https://doi.org/10.3390/s25061720