
Deep Learning Ensemble Approach for Predicting Expected and Confidence Levels of Signal Phase and Timing Information at Actuated Traffic Signals


Abstract
1. Introduction
1.1. Previous Studies on SPaT Prediction
1.2. Problem Statement
- The prediction is robust to missing data since the percentage of packets decreases both as the distance from the transmitter increases and as the traffic density increases.
- The prediction is most accurate when the vehicle is within the range of the transmitter: 300 m is the recommended range for DSRC communications and 4G LTE to obtain a reasonable packet delivery rate [1,17]. This distance is equivalent to 19.2 s before the signal changes at a 56 km/h (35 mi/h) speed, which is the speed limit for the Gallows Road Corridor used in this study.
- The prediction becomes more accurate the closer the time to green is.
- There is a measure of confidence in the predictions. This way, a vehicle can make a reasonable decision on whether to accelerate or decelerate, considering the level of uncertainty associated with each prediction.
1.3. Research Significance and Contribution
- According to the authors’ knowledge, nobody has used the model architecture introduced in this study, which is based on transformer encoder blocks, in SPaT predictions. The study showed that the predictive power surpasses that of previously used deep learning models.
- Using an ensemble approach, the study puts forward a novel data-oriented approach for quantifying the certainty in the model predictions. The consensus/variance between the models can be a proxy for confidence in the predictions. This approach is highly extensible and allows for eliminating model hallucinations, which is a major drawback of deep learning models.
2. Methodology
- Predicting if the phase will change within the next 20 s, because if the phase stays in the same state longer than 20 s, then it does not make a difference to the cars within the communication range of the transmitter.
- Predicting the exact changing time for phases that would change in less than 20 s in the future.
- Assigning a level of certainty to the prediction to help the receiving vehicle make a well-informed decision based on the data it receives.
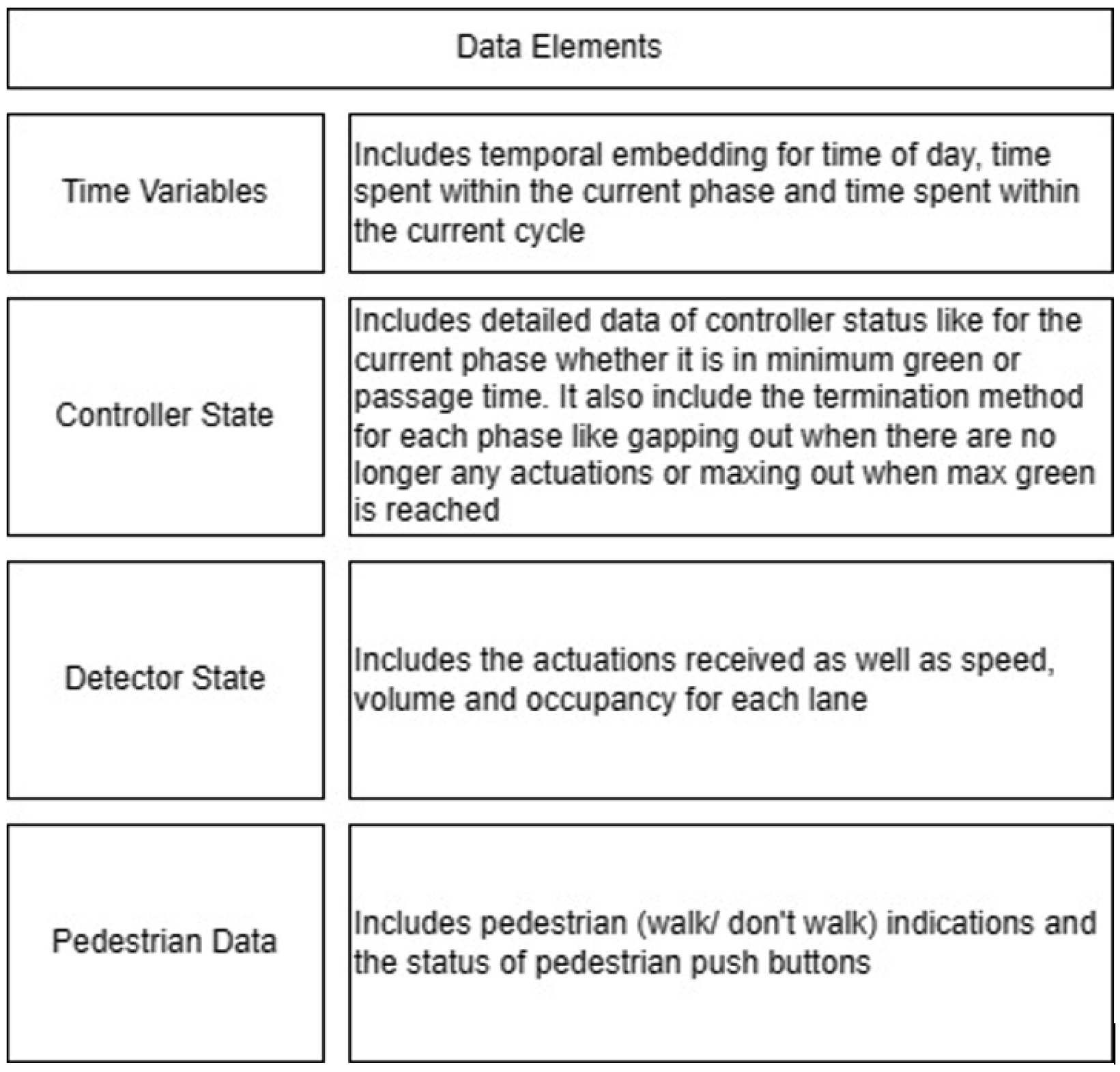
2.1. Data Description
- The sequences of data used have up to 30% missing data. This affects the overall accuracy of the predictions but is more representative of realistic infrastructure to vehicle communication streams.
- The controller logic includes significant skipping of left turn and side street phases, which makes the predictions highly stochastic, where a single arrival on the secondary road can completely alter the time to green for the primary road.
- The controller logic for all six intersections includes a setting where, for some cycles, if there are no actuations on any of the approaches, the entire cycle serves phases 2 and 6, which are the primary road through, right and permissive left movements. In this case, the time to green is extended by an entire cycle, which is difficult to predict, especially a long time in advance.
2.2. Model Development
2.2.1. Common Elements
MLP
2.2.2. LSTM
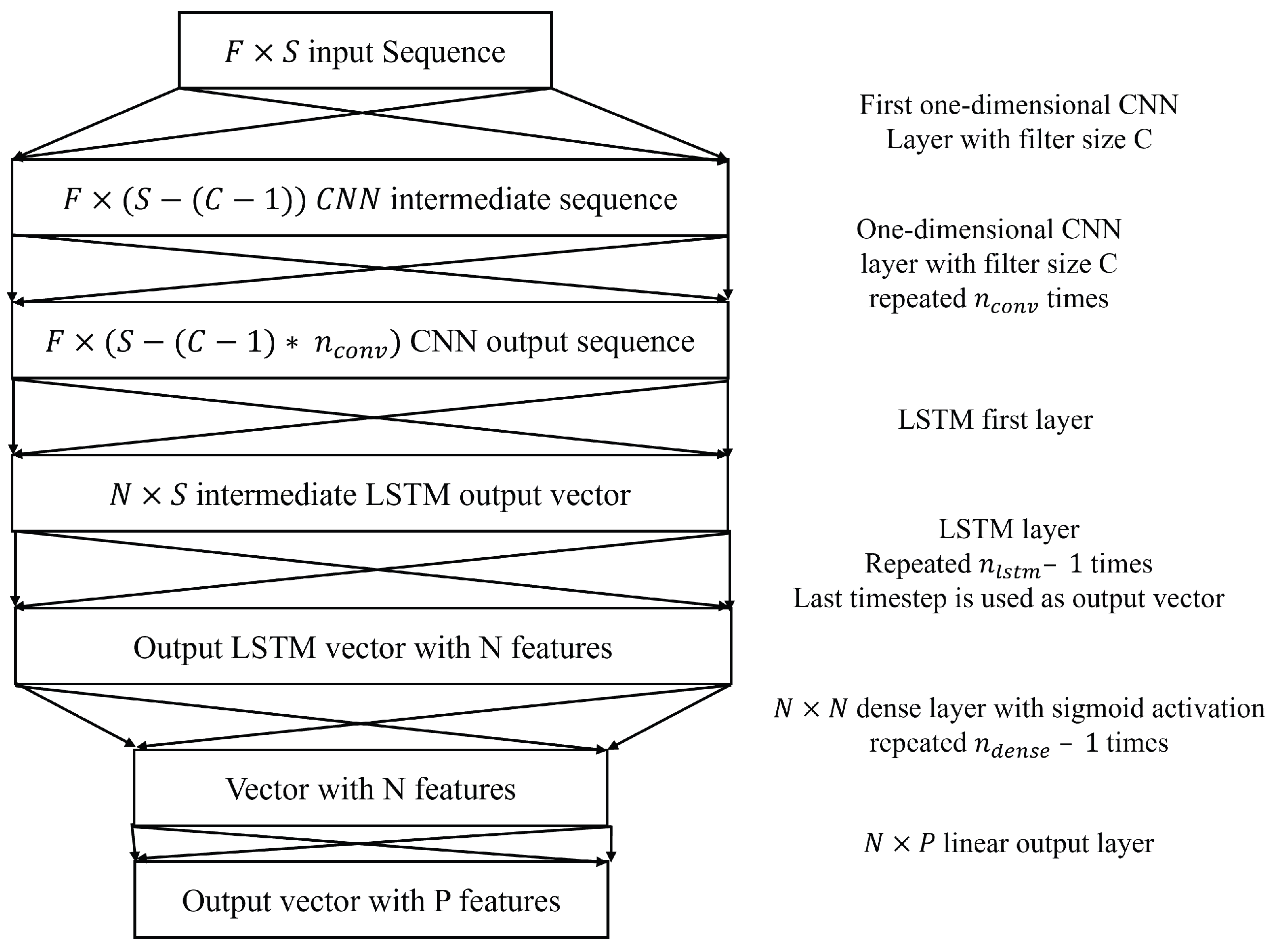
2.2.3. CNN–LSTM
2.2.4. Transformer
2.3. Ensemble Approach
- By using four different architectures, the data are subjected to different processes and logic in order to extract the relevant features and make the prediction. This variance in logic, as represented by the different model architectures, adds to the logical diversity of the model.
- For each of the four models, during hyperparameter tuning we generate multiple variants where the number of parameters used to express the model for each variant varies significantly. This means that the variation in model size and number of parameters, even for the same model architecture, allows for diversity in the complexity of the constituent models for the ensemble.
3. Results and Analysis
3.1. Task 1: Identifying Change Times Less than 20 s in the Future
3.2. Task 2: Predicting the Exact Time to Change When Less than or Equal to 20 s
3.3. Task 3: Assigning a Level of Certainty to the Prediction
3.4. Fuel Consumption
3.5. Considerations for Field Deployment of Model Ensembles
3.5.1. Data Reliability and Handling Missing Data
3.5.2. Communication Latency and Prediction Timing
4. Conclusions and Recommendation
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TSC | Traffic Signal Control |
| SPaT | Signal phase and timing |
| GLOSA | Green light optimal speed advisory |
| MLP | Multilayer perceptrons |
| LSTM | long-short-term memory neural networks |
| CNNLSTM | Convolutional long-short term memory neural networks |
| I2V | infrastructure to vehicle |
| ITS | intelligent transportation systems |
| DSRC | Dedicated short-range communications |
| LTE | Long-Term Evolution |
| MAPE | Mean Absolute Percentage Error |
| ASHA | Asynchronous Successive Halving |
| GPU | Graphics processing unit |
| NEMA | National Electrical Manufacturers Association |
| TTG | Time to green |
| TTR | Time to red |
| XGB | extreme gradient boosting |
| GRU | gated recurrent units |
References
- Abernethy, B.; Andrews, S.; Pruitt, G. Signal Phase and Timing (SPaT) Applications, Communications Requirements, Communications Technology Potential Solutions, Issues and Recommendations; Technical Report; Federal Highway Administration: Washington, DC, USA, 2012. [Google Scholar]
- Rakha, H.; Kamalanathsharma, R.K. Eco-driving at signalized intersections using V2I communication. In Proceedings of the 2011, IEEE Conference on Intelligent Transportation Systems, Proceedings, ITSC, Washington, DC, USA, 5–7 October 2011; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2011; pp. 341–346. [Google Scholar] [CrossRef]
- Shafik, A.K.; Eteifa, S.; Rakha, H.A. Optimization of Vehicle Trajectories Considering Uncertainty in Actuated Traffic Signal Timings. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7259–7269. [Google Scholar] [CrossRef]
- Rakha, H.; Ahn, K.; Kamalanathsharma, R.K. Eco-Vehicle Speed Control at Signalized Intersections Using i2v Communication; Tech. Rep.; US Department of Transportation: Washington, DC, USA, 2012. [Google Scholar]
- Kamalanathsharma, R.K.; Rakha, H.A. Multi-stage dynamic programming algorithm for eco-speed control at traffic signalized intersections. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 2094–2099. [Google Scholar]
- Chen, H.; Rakha, H.A.; Loulizi, A.; El-Shawarby, I.; Almannaa, M.H. Development and Preliminary Field Testing of an In-Vehicle Eco-Speed Control System in the Vicinity of Signalized Intersections. IFAC-PapersOnLine 2016, 49, 249–254. [Google Scholar] [CrossRef]
- Ahn, K.; Du, J.; Farag, M.; Rakha, H.A. Evaluating an Eco-Cooperative Automated Control System. Transp. Res. Rec. 2023, 2677, 1562–1578. [Google Scholar] [CrossRef]
- Yang, H.; Ala, M.V.; Rakha, H.A. Eco-Cooperative Adaptive Cruise Control at Signalized Intersections Considering Queue Effects. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1575–1585. [Google Scholar] [CrossRef]
- Bodenheimer, R.; Brauer, A.; Eckhoff, D.; German, R. Enabling GLOSA for adaptive traffic lights. In Proceedings of the 2014 IEEE Vehicular Networking Conference (VNC), Paderborn, Germany, 3–5 December 2014; pp. 167–174. [Google Scholar]
- Ibrahim, S.; Kalathil, D.; Sanchez, R.O.; Varaiya, P. Estimating phase duration for SPaT messages. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2668–2676. [Google Scholar] [CrossRef]
- Van de Vyvere, B.; D’haene, K.; D’haene, K.; Colpaert, P.; Verborgh, R. Predicting Phase Durations of Traffic Lights Using Live Open Traffic Lights Data; Technical University of Aachen: Aachen, Germany, 2019; pp. 1–7. [Google Scholar]
- Moghimi, B.; Safikhani, A.; Kamga, C.; Hao, W.; Ma, J. Short-term prediction of signal cycle on an arterial with actuated-uncoordinated control using sparse time series models. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2976–2985. [Google Scholar] [CrossRef]
- Weisheit, T.; Hoyer, R. Prediction of Switching Times of Traffic Actuated Signal Controls Using Support Vector Machines. In Advanced Microsystems for Automotive Applications 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 121–129. [Google Scholar]
- Genser, A.; Ambühl, L.; Yang, K.; Menendez, M.; Kouvelas, A. Time-to-Green predictions: A framework to enhance SPaT messages using machine learning. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Eteifa, S.; Rakha, H.A.; Eldardiry, H. Predicting coordinated actuated traffic signal change times using long short-term memory neural networks. Transp. Res. Rec. 2021, 2675, 127–138. [Google Scholar] [CrossRef]
- Islam, Z.; Abdel-Aty, M.; Mahmoud, N. Using CNN-LSTM to predict signal phasing and timing aided by High-Resolution detector data. Transp. Res. Part C Emerg. Technol. 2022, 141, 103742. [Google Scholar] [CrossRef]
- Farag, M.M.; Rakha, H.A.; Mazied, E.A.; Rao, J. Integration large-scale modeling framework of direct cellular vehicle-to-all (c-v2x) applications. Sensors 2021, 21, 2127. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Liaw, R.; Liang, E.; Nishihara, R.; Moritz, P.; Gonzalez, J.E.; Stoica, I. Tune: A research platform for distributed model selection and training. arXiv 2018, arXiv:1807.05118. [Google Scholar]
- Li, L.; Jamieson, K.; Rostamizadeh, A.; Gonina, E.; Ben-Tzur, J.; Hardt, M.; Recht, B.; Talwalkar, A. A system for massively parallel hyperparameter tuning. Proc. Mach. Learn. Syst. 2020, 2, 230–246. [Google Scholar]
- Genser, A.; Ambühl, L.; Yang, K.; Menendez, M.; Kouvelas, A. Enhancement of SPaT-messages with machine learning based time-to-green predictions. In Proceedings of the 9th Symposium of the European Association for Research in Transportation (hEART 2020), Online, 3–4 February 2021; European Association for Research in Transportation: Brussels, Belgium, 2020. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Nam, G.; Yoon, J.; Lee, Y.; Lee, J. Diversity matters when learning from ensembles. Adv. Neural Inf. Process. Syst. 2021, 34, 8367–8377. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intersection | Ring Barrier Diagram | Intersection | Ring Barrier Diagram |
|---|---|---|---|
| 650058 |  | 650064 |  |
| 650060 |  | 650065 |  |
| 650063 |  | 650075 |  |
| Intersection | Model Rank | lr | Batch Size | Neurons Per Layer | n Layers |
|---|---|---|---|---|---|
| 650058 | 1 | 0.00019 | 16 | 300 | 2 |
| 2 | 0.00029 | 16 | 240 | 2 | |
| 3 | 0.00042 | 32 | 240 | 2 | |
| 650060 | 1 | 0.00062 | 64 | 300 | 2 |
| 2 | 0.00046 | 32 | 270 | 2 | |
| 3 | 0.00026 | 16 | 240 | 2 | |
| 650063 | 1 | 0.00025 | 32 | 210 | 2 |
| 2 | 0.00035 | 16 | 150 | 2 | |
| 3 | 0.00092 | 128 | 240 | 4 | |
| 650064 | 1 | 0.00025 | 16 | 210 | 2 |
| 2 | 0.00019 | 16 | 300 | 2 | |
| 3 | 0.00046 | 32 | 270 | 2 | |
| 650065 | 1 | 0.00041 | 32 | 270 | 2 |
| 2 | 0.00045 | 64 | 210 | 2 | |
| 3 | 0.00019 | 16 | 240 | 2 | |
| 650075 | 1 | 0.00032 | 16 | 150 | 2 |
| 2 | 0.00040 | 16 | 210 | 1 | |
| 3 | 0.00105 | 64 | 180 | 2 |
| Intersection | Model Rank | lr | Batch Size | Neurons Per Layer | n Layers Lstm | n Layers Dense |
|---|---|---|---|---|---|---|
| 650058 | 1 | 0.00134 | 128 | 300 | 2 | 1 |
| 2 | 0.00135 | 128 | 210 | 2 | 1 | |
| 3 | 0.00068 | 32 | 120 | 2 | 1 | |
| 650060 | 1 | 0.00111 | 32 | 180 | 2 | 1 |
| 2 | 0.00134 | 128 | 300 | 2 | 1 | |
| 3 | 0.00168 | 64 | 180 | 2 | 1 | |
| 650063 | 1 | 0.00024 | 16 | 180 | 2 | 2 |
| 2 | 0.00040 | 32 | 180 | 2 | 1 | |
| 3 | 0.00068 | 32 | 120 | 2 | 1 | |
| 650064 | 1 | 0.00068 | 32 | 120 | 2 | 1 |
| 2 | 0.00119 | 32 | 120 | 2 | 2 | |
| 3 | 0.00120 | 32 | 150 | 1 | 1 | |
| 650065 | 1 | 0.00040 | 32 | 180 | 2 | 1 |
| 2 | 0.00139 | 32 | 150 | 2 | 1 | |
| 3 | 0.00068 | 32 | 120 | 2 | 1 | |
| 650075 | 1 | 0.00034 | 16 | 90 | 2 | 2 |
| 2 | 0.00111 | 32 | 180 | 2 | 1 | |
| 3 | 0.00068 | 32 | 120 | 2 | 1 |
| Intersection | Model Rank | lr | Batch Size | Neurons Per Layer | n Layers Lstm | n Layers Dense |
|---|---|---|---|---|---|---|
| 650058 | 1 | 0.00040 | 16 | 300 | 2 | 1 |
| 2 | 0.00101 | 32 | 240 | 2 | 1 | |
| 3 | 0.00109 | 64 | 240 | 2 | 1 | |
| 650060 | 1 | 0.00080 | 32 | 300 | 4 | 1 |
| 2 | 0.00021 | 16 | 300 | 4 | 1 | |
| 3 | 0.00040 | 16 | 300 | 2 | 1 | |
| 650063 | 1 | 0.00109 | 64 | 240 | 2 | 1 |
| 2 | 0.00061 | 16 | 120 | 4 | 1 | |
| 3 | 0.00048 | 32 | 300 | 2 | 1 | |
| 650064 | 1 | 0.00253 | 128 | 240 | 3 | 1 |
| 2 | 0.00050 | 16 | 120 | 3 | 1 | |
| 3 | 0.00230 | 128 | 210 | 4 | 1 | |
| 650065 | 1 | 0.00041 | 16 | 240 | 4 | 1 |
| 2 | 0.00121 | 128 | 150 | 4 | 1 | |
| 3 | 0.00050 | 16 | 120 | 3 | 1 | |
| 650075 | 1 | 0.00041 | 16 | 240 | 4 | 1 |
| 2 | 0.00080 | 32 | 300 | 4 | 1 | |
| 3 | 0.00168 | 64 | 120 | 2 | 1 |
| Intersection | Model Rank | lr | Batch Size | Embed Dim (N) | n Heads | n Encoder Layers | n Layers Dense |
|---|---|---|---|---|---|---|---|
| 650058 | 1 | 0.00020 | 32 | 300 | 1 | 2 | 2 |
| 2 | 0.00016 | 32 | 240 | 3 | 1 | 4 | |
| 3 | 0.00014 | 32 | 210 | 2 | 2 | 2 | |
| 650060 | 1 | 0.00018 | 16 | 60 | 3 | 2 | 2 |
| 2 | 0.00046 | 64 | 90 | 3 | 2 | 4 | |
| 3 | 0.00042 | 32 | 60 | 5 | 2 | 2 | |
| 650063 | 1 | 0.00067 | 64 | 30 | 5 | 4 | 2 |
| 2 | 0.00080 | 128 | 60 | 5 | 1 | 2 | |
| 3 | 0.00018 | 16 | 60 | 3 | 2 | 2 | |
| 650064 | 1 | 0.00014 | 32 | 210 | 2 | 2 | 2 |
| 2 | 0.00020 | 32 | 300 | 1 | 2 | 2 | |
| 3 | 0.00046 | 64 | 120 | 1 | 1 | 2 | |
| 650065 | 1 | 0.00075 | 128 | 150 | 1 | 1 | 2 |
| 2 | 0.00041 | 128 | 120 | 3 | 1 | 2 | |
| 3 | 0.00024 | 32 | 210 | 1 | 1 | 4 | |
| 650075 | 1 | 0.00029 | 32 | 120 | 1 | 1 | 4 |
| 2 | 0.00020 | 32 | 300 | 1 | 2 | 2 | |
| 3 | 0.00018 | 16 | 60 | 3 | 2 | 2 |
| Intersection | Model Rank | LSTM | MLP | CNN-LSTM | Trans-Former | Mean | Median | Vote |
|---|---|---|---|---|---|---|---|---|
| 650058 | 1 | 94.84% | 94.97% | 94.37% | 95.31% | 95.24% | 95.12% | 95.08% |
| 2 | 94.59% | 94.71% | 94.63% | 95.25% | ||||
| 3 | 94.68% | 94.82% | 94.64% | 95.14% | ||||
| 650060 | 1 | 95.20% | 95.23% | 93.47% | 95.04% | 95.53% | 95.03% | 95.17% |
| 2 | 94.40% | 95.11% | 93.22% | 95.09% | ||||
| 3 | 94.20% | 95.05% | 93.58% | 95.32% | ||||
| 650063 | 1 | 95.95% | 95.90% | 95.88% | 96.07% | 96.17% | 96.10% | 96.08% |
| 2 | 95.70% | 96.01% | 95.54% | 95.96% | ||||
| 3 | 95.87% | 95.84% | 95.91% | 96.04% | ||||
| 650064 | 1 | 94.98% | 95.84% | 94.20% | 96.59% | 96.51% | 96.04% | 96.17% |
| 2 | 95.06% | 95.81% | 93.77% | 96.24% | ||||
| 3 | 95.67% | 95.97% | 94.36% | 96.45% | ||||
| 650065 | 1 | 95.63% | 96.36% | 94.33% | 96.39% | 96.43% | 96.08% | 96.07% |
| 2 | 95.88% | 95.75% | 94.18% | 96.35% | ||||
| 3 | 95.76% | 95.92% | 94.39% | 96.08% | ||||
| 650075 | 1 | 96.01% | 96.63% | 96.01% | 96.07% | 96.73% | 96.07% | 95.86% |
| 2 | 96.08% | 96.19% | 95.54% | 96.18% | ||||
| 3 | 95.77% | 96.05% | 95.59% | 96.04% |
| Inter-Section | Model Rank | LSTM | MLP | CNN- LSTM | Trans-Former | Mean | Median |
|---|---|---|---|---|---|---|---|
| 650058 | 1 | 20.45 | 16.65 | 19.40 | 15.39 | 15.58 | 15.03 |
| 2 | 19.70 | 16.33 | 20.43 | 15.95 | |||
| 3 | 21.15 | 16.68 | 20.90 | 15.29 | |||
| 650060 | 1 | 22.64 | 19.49 | 17.80 | 18.07 | 16.72 | 15.89 |
| 2 | 20.90 | 19.12 | 17.84 | 19.01 | |||
| 3 | 21.79 | 19.29 | 20.27 | 19.03 | |||
| 650063 | 1 | 22.47 | 19.65 | 20.62 | 16.29 | 16.45 | 15.61 |
| 2 | 23.14 | 19.20 | 18.67 | 16.90 | |||
| 3 | 22.47 | 19.19 | 21.23 | 17.56 | |||
| 650064 | 1 | 22.29 | 21.28 | 21.92 | 19.88 | 18.31 | 17.60 |
| 2 | 23.08 | 21.18 | 22.43 | 18.75 | |||
| 3 | 25.07 | 22.58 | 23.09 | 19.38 | |||
| 650065 | 1 | 22.74 | 19.97 | 19.65 | 17.56 | 16.70 | 16.32 |
| 2 | 22.21 | 18.97 | 19.82 | 17.90 | |||
| 3 | 22.54 | 19.19 | 20.33 | 17.34 | |||
| 650075 | 1 | 16.38 | 15.01 | 12.95 | 11.37 | 11.94 | 10.99 |
| 2 | 17.64 | 13.68 | 14.96 | 13.25 | |||
| 3 | 17.62 | 13.64 | 16.25 | 12.94 |
| Inter-Section | Model Rank | LSTM | MLP | CNN- LSTM | Trans-Former | Mean | Median |
|---|---|---|---|---|---|---|---|
| 650058 | 1 | 1.585 | 1.456 | 1.572 | 1.345 | 1.330 | 1.309 |
| 2 | 1.509 | 1.450 | 1.707 | 1.428 | |||
| 3 | 1.636 | 1.480 | 1.614 | 1.351 | |||
| 650060 | 1 | 1.839 | 1.720 | 1.516 | 1.684 | 1.483 | 1.419 |
| 2 | 1.619 | 1.728 | 1.501 | 1.760 | |||
| 3 | 1.677 | 1.773 | 1.621 | 1.718 | |||
| 650063 | 1 | 1.785 | 1.647 | 1.711 | 1.473 | 1.446 | 1.428 |
| 2 | 1.786 | 1.695 | 1.632 | 1.511 | |||
| 3 | 1.776 | 1.662 | 1.702 | 1.573 | |||
| 650064 | 1 | 1.843 | 1.909 | 1.864 | 1.801 | 1.644 | 1.615 |
| 2 | 1.945 | 1.898 | 1.917 | 1.685 | |||
| 3 | 2.051 | 2.052 | 1.954 | 1.782 | |||
| 650065 | 1 | 1.836 | 1.659 | 1.776 | 1.605 | 1.502 | 1.496 |
| 2 | 1.757 | 1.688 | 1.811 | 1.595 | |||
| 3 | 1.821 | 1.671 | 1.762 | 1.556 | |||
| 650075 | 1 | 1.177 | 1.194 | 1.033 | 0.962 | 0.933 | 0.888 |
| 2 | 1.264 | 1.086 | 1.247 | 1.056 | |||
| 3 | 1.213 | 1.074 | 1.168 | 1.005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eteifa, S.; Shafik, A.; Eldardiry, H.; Rakha, H.A. Deep Learning Ensemble Approach for Predicting Expected and Confidence Levels of Signal Phase and Timing Information at Actuated Traffic Signals. Sensors 2025, 25, 1664. https://doi.org/10.3390/s25061664
Eteifa S, Shafik A, Eldardiry H, Rakha HA. Deep Learning Ensemble Approach for Predicting Expected and Confidence Levels of Signal Phase and Timing Information at Actuated Traffic Signals. Sensors. 2025; 25(6):1664. https://doi.org/10.3390/s25061664
Chicago/Turabian StyleEteifa, Seifeldeen, Amr Shafik, Hoda Eldardiry, and Hesham A. Rakha. 2025. "Deep Learning Ensemble Approach for Predicting Expected and Confidence Levels of Signal Phase and Timing Information at Actuated Traffic Signals" Sensors 25, no. 6: 1664. https://doi.org/10.3390/s25061664
APA StyleEteifa, S., Shafik, A., Eldardiry, H., & Rakha, H. A. (2025). Deep Learning Ensemble Approach for Predicting Expected and Confidence Levels of Signal Phase and Timing Information at Actuated Traffic Signals. Sensors, 25(6), 1664. https://doi.org/10.3390/s25061664