
Comparative Analysis of YOLO Series Algorithms for UAV-Based Highway Distress Inspection: Performance and Application Insights


Abstract
1. Introduction
2. Methods and Dataset
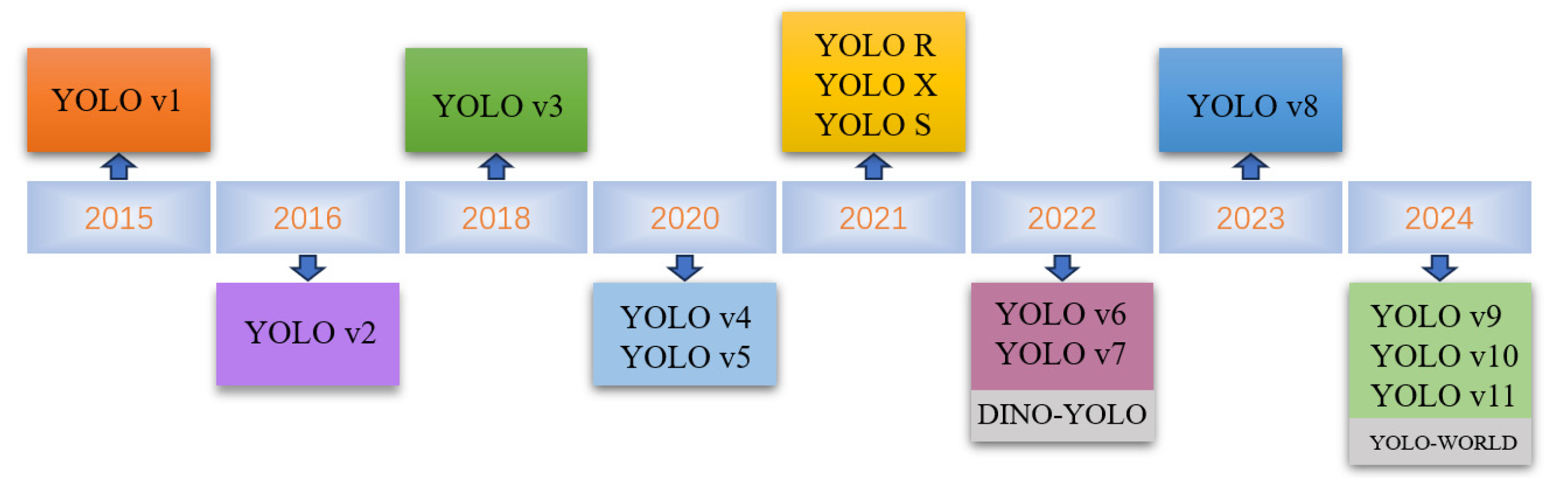
2.1. Comparison of YOLO Family
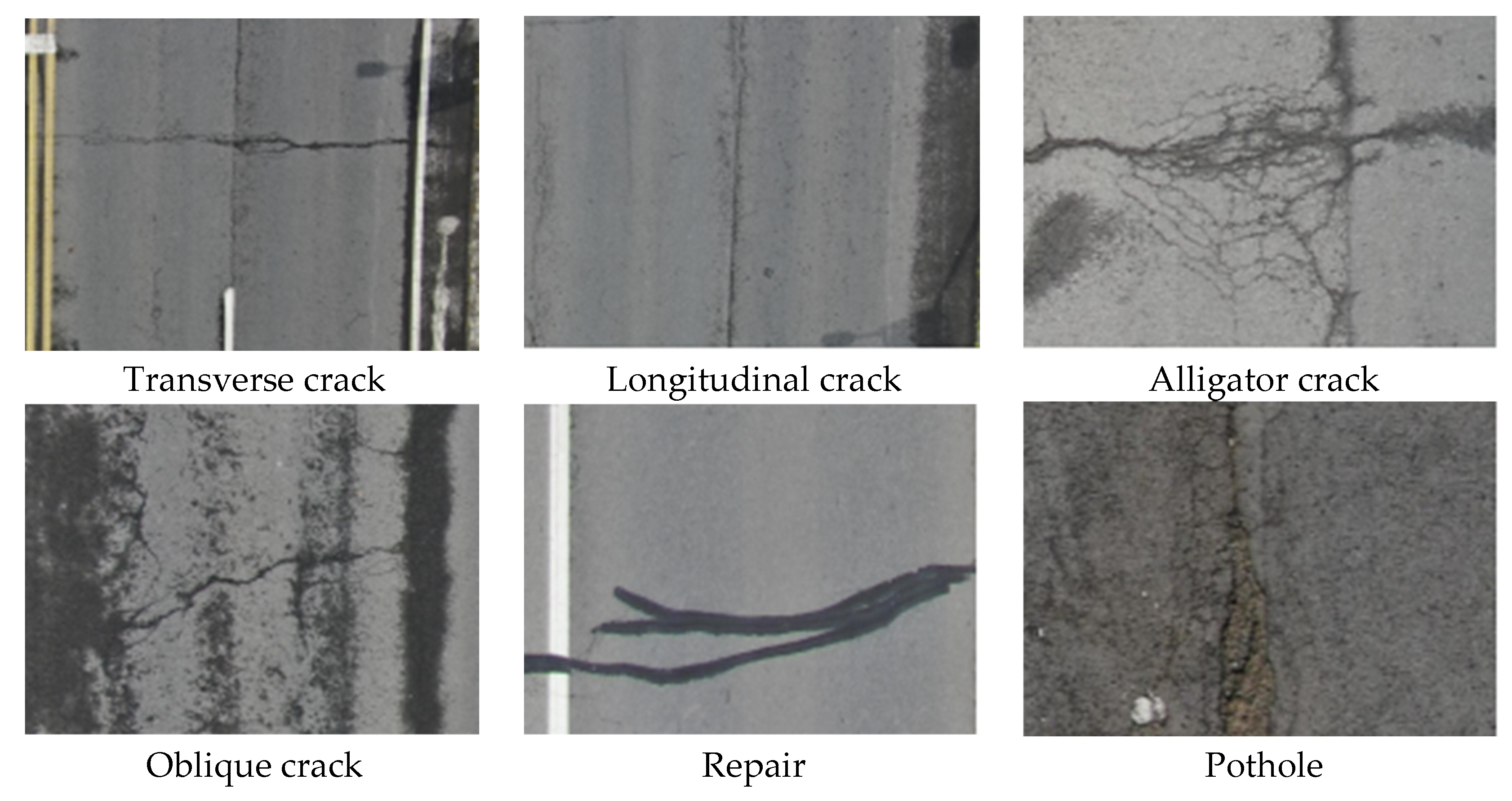
2.2. Dataset
3. Experiment Setting and Evaluation Metrics
4. Results and Discussion
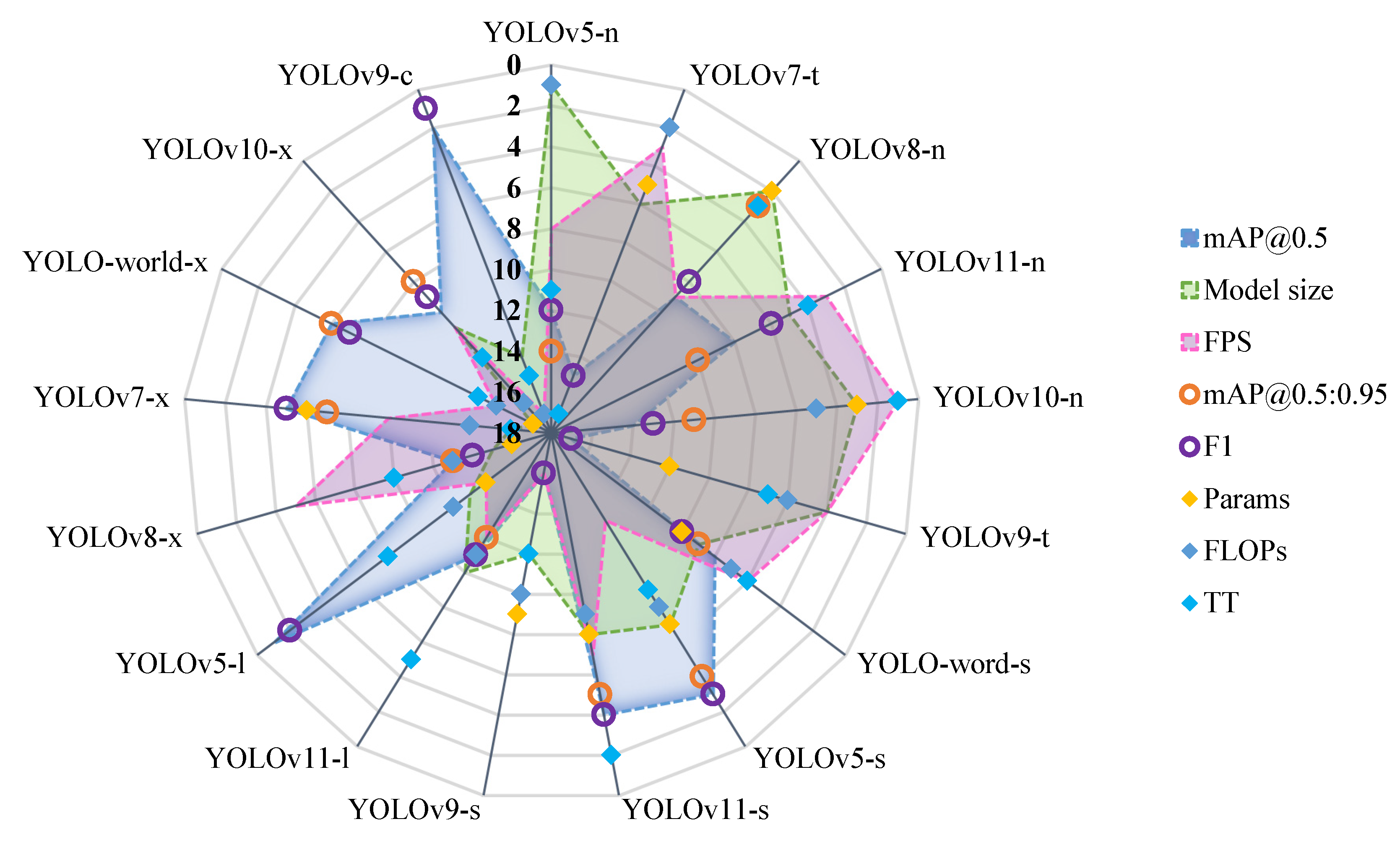
4.1. Model Comparison Results
4.2. Balance Evaluation and Application Scenarios Analysis
- (1)
- Single-Advantage Model Groups
- (2)
- Dual-Advantage Balanced Group
- (3)
- Comprehensive Excellence Group
4.3. Model Comparison Between Different Sized Models
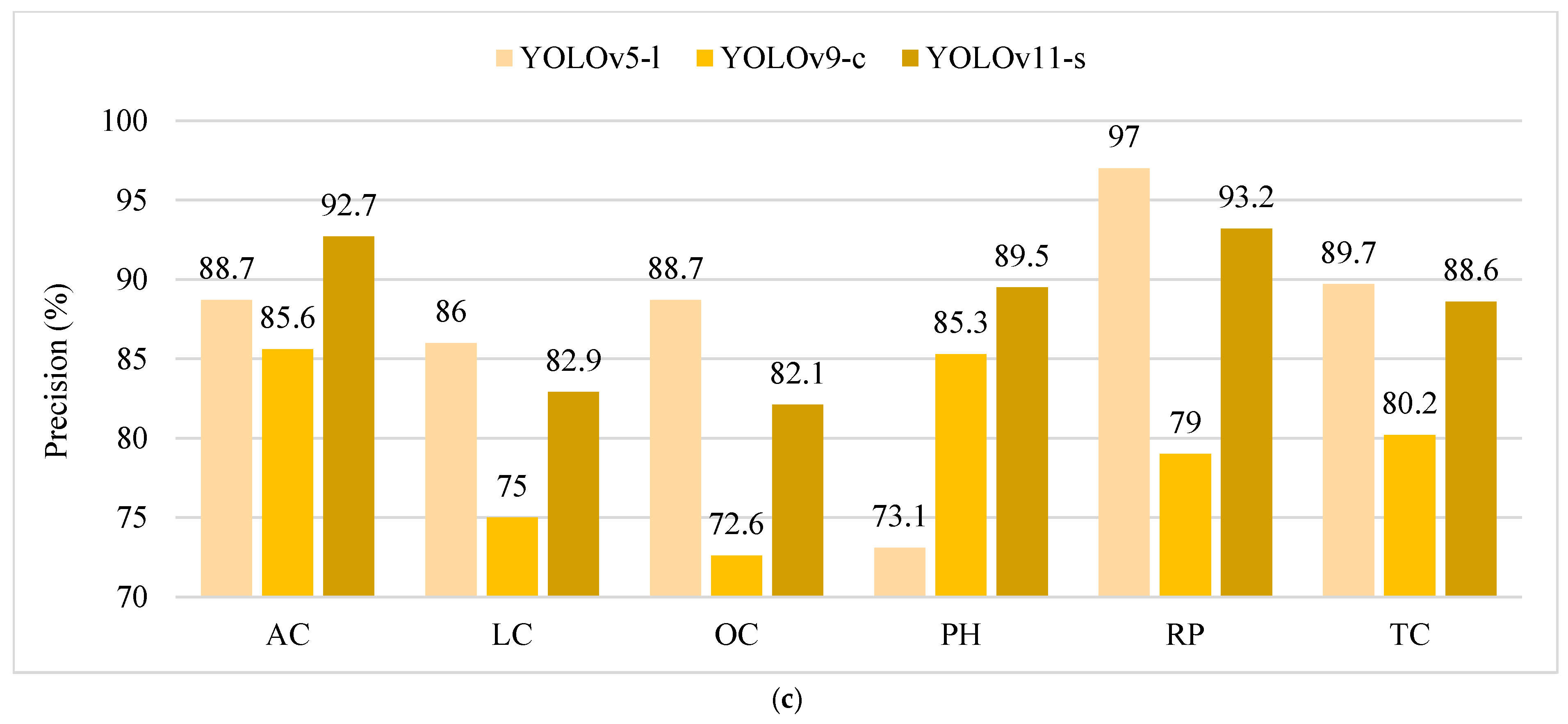
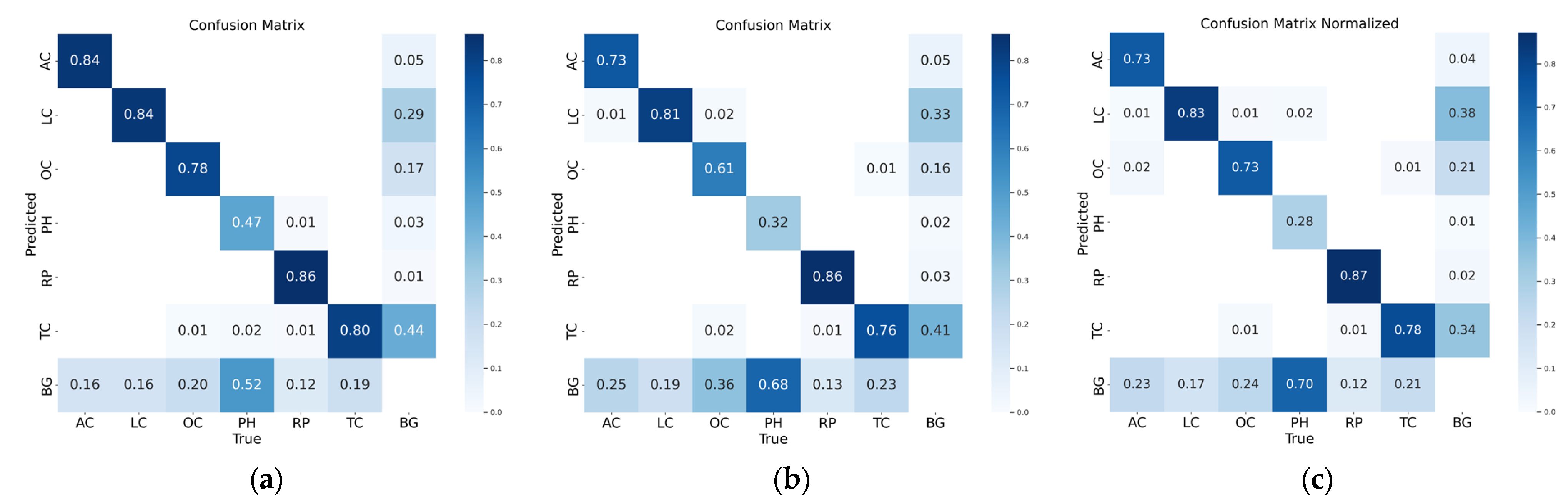
4.4. Comparison of Classification Detection Accuracy of Representative Models
5. Conclusions
- (1)
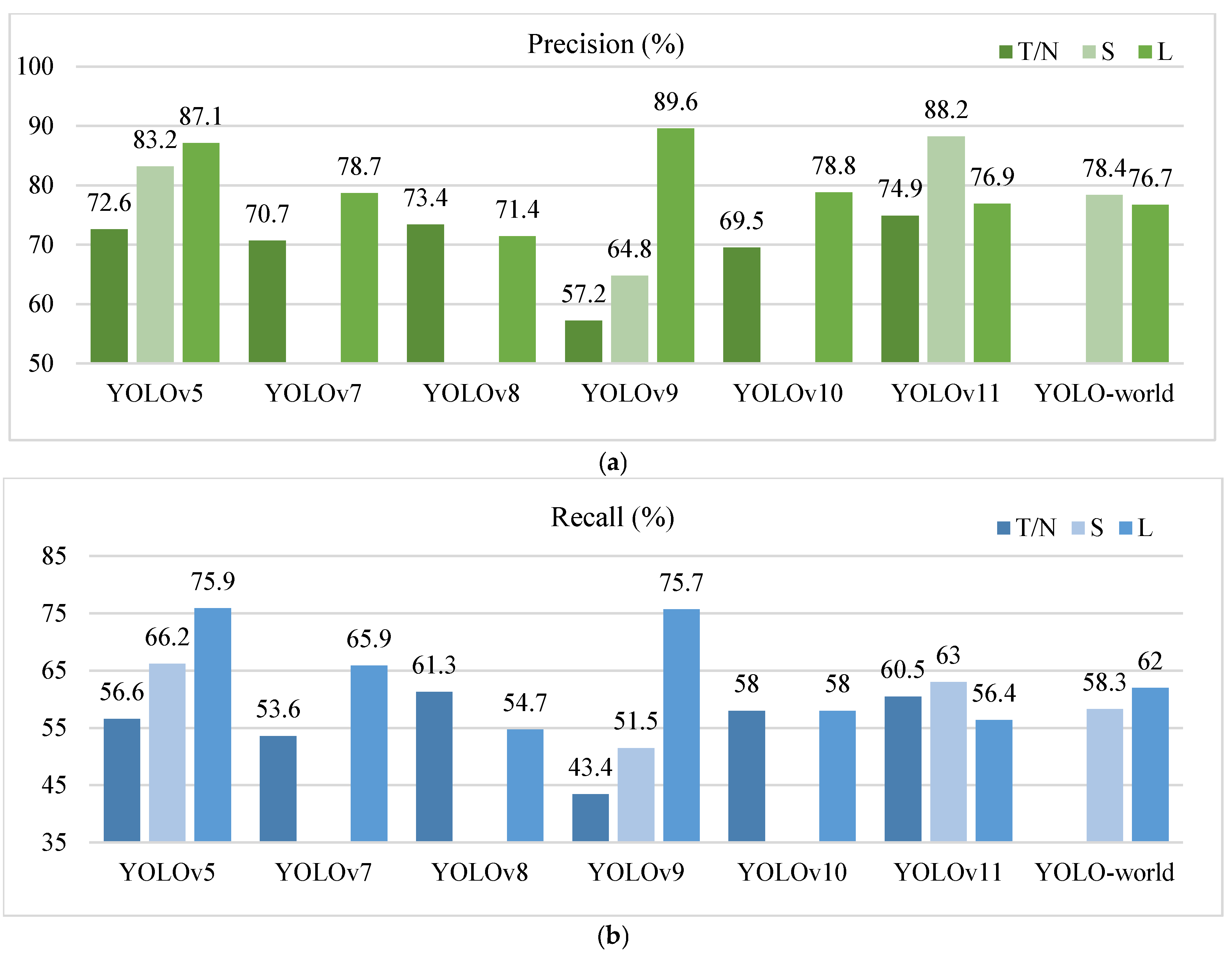
- YOLOv5-l and YOLOv9-c achieved the highest detection accuracy (mAP@0.5, mAP@0.5:0.95, F1) on UAV highway inspection data. YOLOv5-l performed well in mean and classification detection precision and recall, while YOLOv9-c performed poorly in classification precision and recall.
- (2)
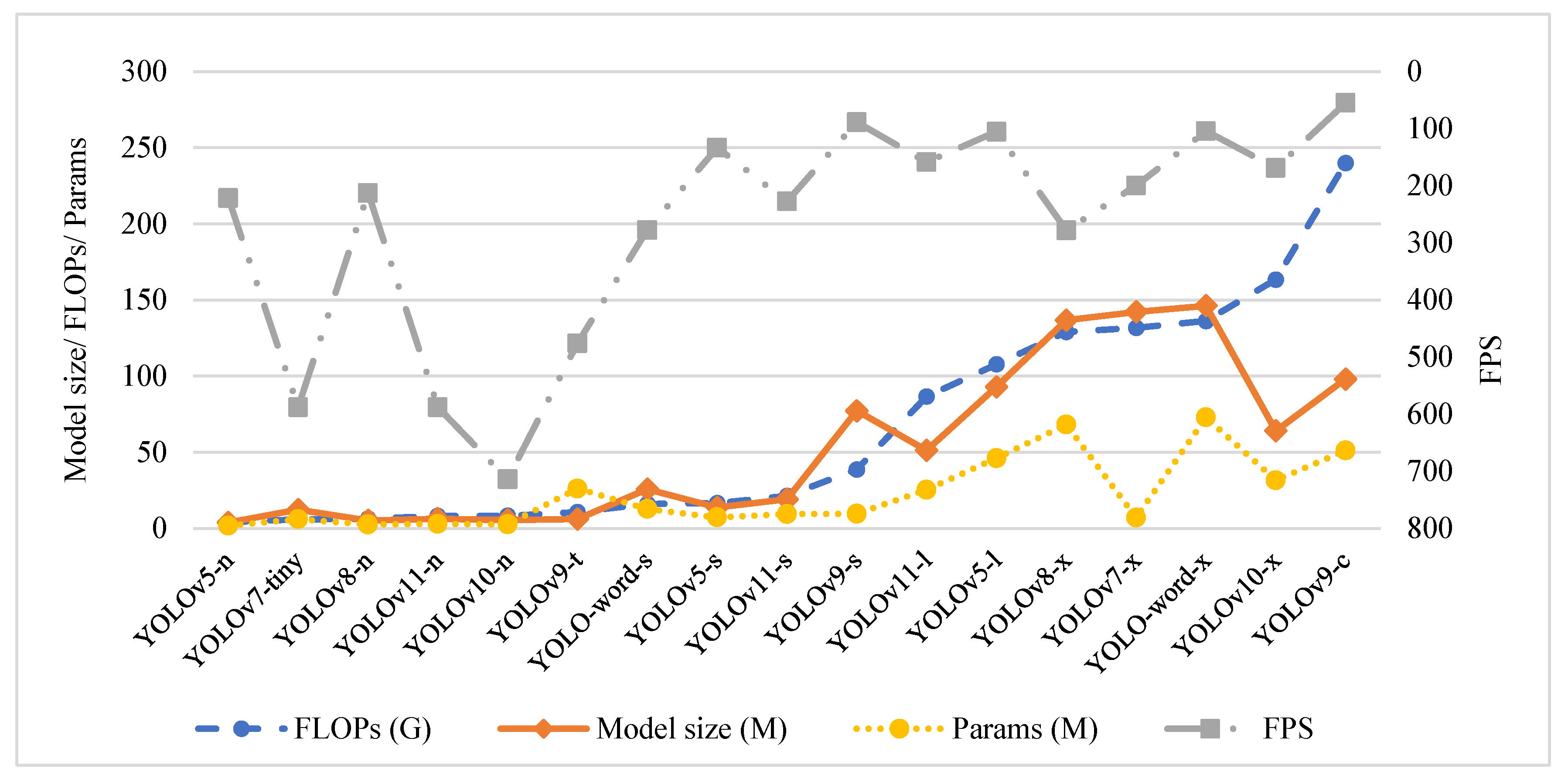
- YOLOv10-n, YOLOv7-t, and YOLOv11-n achieved the highest detection efficiency; YOLOv5-n, YOLOv8-n, and YOLOv10-n had the smallest model sizes; and YOLOv11n was the model with the best performance in terms of combined detection efficiency (FPS), model size, and computational complexity (FLOPs), which is expected to be used for embedded real-time detection.
- (3)
- It is evident that both the YOLOv5-s and the YOLOv11-s are capable of achieving a balance between the detection accuracy and the lightweight degree of the model; however, the efficiency is merely average at best. It can be concluded that the models may be considered suitable for lightweight detection platforms that have higher accuracy requirements.
- (4)
- Comparing the t/n and l/c versions, it was found that the change of the backbone network in YOLOv9 had the greatest impact on the model detection accuracy, followed by the impact of the network depth_mulltiple and width_multiple of YOLOv5; the relative compression degrees of the models of YOLOv5-n and YOLOv8-n were the highest; and YOLOv9-t achieved the greatest efficiency improvement in UAV highway detection, followed by v10-n and v11-n.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hu, X.; Assaad, R.H. The use of unmanned ground vehicles (mobile robots) and unmanned aerial vehicles (drones) in the civil infrastructure asset management sector: Applications, robotic platforms, sensors, and algorithms. Expert Syst. Appl. 2023, 232, 120897. [Google Scholar] [CrossRef]
- Chen, C.; Zheng, Z.; Xu, T.; Guo, S.; Feng, S.; Yao, W.; Lan, Y. YOLO-Based UAV Technology: A Review of the Research and Its Applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- Hou, Y.; Dong, Y.; Zhang, Y.; Zhou, Z.; Tong, X.; Wu, Q.; Qian, Z.; Li, R. The Application of a Pavement Distress Detection Method Based on FS-Net. Sustainability 2022, 14, 2715. [Google Scholar] [CrossRef]
- Ma, D.; Fang, H.; Wang, N.; Zhang, C.; Dong, J.; Hu, H. Automatic Detection and Counting System for Pavement Cracks Based on PCGAN and YOLO-MF. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22166–22178. [Google Scholar] [CrossRef]
- Zhang, Y.; Zuo, Z.; Xu, X.; Wu, J.; Zhu, J.; Zhang, H.; Wang, J.; Tian, Y. Road damage detection using UAV images based on multi-level attention mechanism. Autom. Constr. 2022, 144, 104613. [Google Scholar] [CrossRef]
- Zhu, J.; Zhong, J.; Ma, T.; Huang, X.; Zhang, W.; Zhou, Y. Pavement distress detection using convolutional neural networks with images captured via UAV. Autom. Constr. 2022, 133, 103991. [Google Scholar] [CrossRef]
- Zhu, J.; Wu, Y.; Ma, T. Multi-Object Detection for Daily Road Maintenance Inspection with UAV Based on Improved YOLOv8. IEEE Trans. Intell. Transp. Syst. 2024, 25, 16548–16560. [Google Scholar] [CrossRef]
- Zheng, L.; Xiao, J.; Wang, Y.; Wu, W.; Chen, Z.; Yuan, D.; Jiang, W. Deep learning-based intelligent detection of pavement distress. Autom. Constr. 2024, 168, 105772. [Google Scholar] [CrossRef]
- Xu, F.; Wan, Y.; Ning, Z.; Wang, H. Comparative Study of Lightweight Target Detection Methods for Unmanned Aerial Vehicle-Based Road Distress Survey. Sensors 2024, 24, 6159. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, H.; Kang, J.; Xu, Z. A Method for Surveying Road Pavement Distress Based on Front-View Image Data Using a Lightweight Segmentation Approach. J. Comput. Civ. Eng. 2024, 38, 04024026. [Google Scholar] [CrossRef]
- Li, L.; Fang, B.; Zhu, J. Performance Analysis of the YOLOv4 Algorithm for Pavement Damage Image Detection with Different Embedding Positions of CBAM Modules. Appl. Sci. 2022, 12, 10180. [Google Scholar] [CrossRef]
- Ren, M.; Zhang, X.; Chen, X.; Zhou, B.; Feng, Z. YOLOv5s-M: A deep learning network model for road pavement damage detection from urban street-view imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103335. [Google Scholar] [CrossRef]
- Ning, Z.; Wang, H.; Li, S.; Xu, Z. YOLOv7-RDD: A Lightweight Efficient Pavement Distress Detection Model. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6994–7003. [Google Scholar] [CrossRef]
- Miazzi, M.M.; Pasqualone, A.; Zammit-Mangion, M.; Savoia, M.A.; Fanelli, V.; Procino, S.; Gadaleta, S.; Aurelio, F.L.; Montemurro, C. A Glimpse into the Genetic Heritage of the Olive Tree in Malta. Agriculture 2024, 14, 495. [Google Scholar] [CrossRef]
- Lu, L.; Wang, H.; Wan, Y.; Xu, F. A Detection Transformer-Based Intelligent Identification Method for Multiple Types of Road Traffic Safety Facilities. Sensors 2024, 24, 3252. [Google Scholar] [CrossRef]
- Ažaltovič, V.; Škvareková, I.; Pecho, P.; Kandera, B. Calculation of the Ground Casualty Risk during Aerial Work of Unmanned Aerial Vehicles in the Urban Environment. Transp. Res. Procedia 2020, 44, 271–275. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, J. UAV-PDD2023: A Benchmark Dataset for Pavement Distress Detection Based on UAV Images; Zenodo: Brussel, Belgium, 2023. [Google Scholar] [CrossRef]
- Situ, Z.; Teng, S.; Liao, X.; Chen, G.; Zhou, Q. Real-time sewer defect detection based on YOLO network, transfer learning, and channel pruning algorithm. J. Civ. Struct. Health Monit. 2024, 14, 41–57. [Google Scholar] [CrossRef]
- Huang, L.; Ding, Z.; Zhang, C.; Ye, R.; Yan, B.; Zhou, X.; Xu, W.; Guo, J. YOLO-ULNet: Ultralightweight Network for Real-Time Detection of Forest Fire on Embedded Sensing Devices. IEEE Sens. J. 2024, 24, 25175–25185. [Google Scholar] [CrossRef]
- Guan, B.; Li, J. Lightweight detection network for bridge defects based on model pruning and knowledge distillation. Structures 2024, 62, 106276. [Google Scholar] [CrossRef]
- Jiang, S.; Wang, H.; Ning, Z.; Li, S. Lightweight pruning model for road distress detection using unmanned aerial vehicles. Autom. Constr. 2024, 168, 105789. [Google Scholar] [CrossRef]
- Zeng, J.; Zhong, H. YOLOv8-PD: An improved road damage detection algorithm based on YOLOv8n model. Sci. Rep. 2024, 14, 12052. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Bei, Z.; Ling, T.; Chen, Q.; Zhang, L. Research on high-precision recognition model for multi-scene asphalt pavement distresses based on deep learning. Sci. Rep. 2024, 14, 25416. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yin, C.; Lei, Y.; Zhang, J.; Yan, Y. RDD-YOLO: Road Damage Detection Algorithm Based on Improved You Only Look Once Version 8. Appl. Sci. 2024, 14, 3360. [Google Scholar] [CrossRef]
- Redmon, J. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An Incremental Improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOV7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLO, Version 8.0.0, 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 2 August 2024).
- Wang, C.Y.; Yeh, I.H.; Liao, M.H.Y. Yolov9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; Springer: Cham, Switzerland, 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA; 2024; pp. 16901–16911. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Neck | Head | Depth Multiple and Width Multiple |
|---|---|---|---|---|
| YOLOv5-n | CSPDarknet53, C3, SPPF | PANet | Conv, Upsample, Concat, Detect | 0.33, 0.25 |
| YOLOv5-s | 0.33, 0.50 | |||
| YOLOv5-l | 1.0, 1.0 | |||
| YOLOv7-tiny | Conv, Concat, Max Pooling | SPP | IDetect | 0.33, 0.5 |
| YOLOv7-x | SPPCSPC, Upsample, Concat | 1.25, 1.25 | ||
| YOLOv8-n | Conv, C2f, SPPF | Upsample, Concat, C2f | Detect | 0.33, 0.25 |
| YOLOv8-x | 1.0, 1.25 | |||
| YOLOv9-t | Conv, ELAN1, AConv, RepNCSPELAN4 | SPPELAN, Upsample, Concat operation | DualDDetect | 0.33, 0.25 |
| YOLOv9-s | 1.0, 1.0 | |||
| YOLOv9-c | Conv, Silence, ADown, RepNCSPELAN4 | 1.33, 1.25 | ||
| YOLOv10-n | Conv, C2f, SCDown, SPPF, PSA | Upsample, Concat, C2f | v10Detect | 0.33, 0.25 |
| YOLOv10-x | Conv, C2f, SCDown, C2fCIB, SPPF, PSA | Upsample, Concat, C2fCIB-module | 1.33, 1.25 | |
| YOLOv11-n | Conv, C3k2, SPPF, C2PSA | Upsample, Concat, C3k2module | Detect | 0.5, 0.25 |
| YOLOv11-s | 0.5, 0.5 | |||
| YOLOv11-l | 1.0, 1.0 | |||
| YOLO-world-s | Conv, C2f, SPPF | Upsample, Concat, C2fAttn, ImagePoolingAttn | WorldDetect | 0.33, 0.5 |
| YOLO-world-x | 1.0, 1.25 |
| Type of Guideline | Specific Indicator | Engineering Significance |
|---|---|---|
| Accuracy | Precision | The reliability of the model’s prediction results and high precision means that the model has a low rate of FP problems. |
| Recall | Reflecting the model’s ability to detect targets, a high recall rate means that it can find as many relevant targets as possible to avoid missing important information. | |
| mAP@0.5 | Comprehensive detection capabilities | |
| mAP@0.5:0.95 | A more comprehensive evaluation of the model’s efficacy under diverse precision requirements and necessitates enhanced robustness and accuracy of the model. | |
| F1 | Suitable for scenarios that require both detection accuracy and completeness. A higher F1 score indicates that the model has achieved a better balance between precision and recall. | |
| Efficiency | FPS | Real-time guarantee |
| TT | An important measure of model training efficiency. A shorter TT means that the model can converge faster, thus reducing the cost of development and iteration. | |
| Lightweight | Params | Reflects the complexity of the model; the higher the number of parameters, the more expressive the model is, but it may also lead to higher computational costs and storage requirements. |
| FLOPs | Measure of a model’s computational complexity; lower FLOPs means the model is more computationally efficient and can achieve faster inference with limited computational resources. | |
| Model size | Directly affects the deployment cost and storage requirements; smaller models are better suited to run on devices with limited memory, such as mobile devices and embedded systems. In addition, model size affects model loading time and transfer efficiency. |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | F1 (%) | Params (M) | FLOPs (G) | Model Size (M) | FPS | TT (Hours) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5-n | 63 | 31.6 | 64 | 1.8 | 4.2 | 3.8 | 221.4 | 2.3 |
| YOLOv5-s | 76.2 | 44.3 | 76 | 7.235 | 16.6 | 13.7 | 133.3 | 2.15 |
| YOLOv5-l | 89.0 | 55.7 | 80.9 | 46.135 | 107.7 | 92.9 | 105.3 | 1.736 |
| YOLOv7-t | 59.5 | 28.3 | 61 | 6.021 | 5.82 | 12.3 | 588 | 9.285 |
| YOLOv7-x | 72.5 | 41.4 | 71.8 | 7.081 | 131.7 | 142.2 | 200 | 5.880 |
| YOLOv8-n | 64.7 | 45.1 | 67 | 2.583 | 6.3 | 5.2 | 212.8 | 0.72 |
| YOLOv8-x | 61.7 | 32.8 | 61.9 | 68.129 | 128.99 | 136.7 | 278 | 2.178 |
| YOLOv9-t | 45.9 | 21.5 | 52.2 | 26.19 | 10.7 | 6.1 | 476 | 1.7 |
| YOLOv9-s | 53.6 | 26.8 | 56 | 9.601 | 38.7 | 77.2 | 88.5 | 2.38 |
| YOLOv9-c | 82.2 | 57.9 | 82 | 51.182 | 239.9 | 98.1 | 54.85 | 3.17 |
| YOLOv10-n | 61.6 | 35.7 | 63 | 2.686 | 8.2 | 5.5 | 714.3 | 0.55 |
| YOLOv10-x | 63.5 | 39.6 | 66.8 | 31.585 | 163.4 | 64.1 | 169 | 2.511 |
| YOLOv11-n | 66 | 35.9 | 69.6 | 3.01 | 8.1 | 6.3 | 588 | 0.92 |
| YOLOv11-s | 73.6 | 42.7 | 73.3 | 9.415 | 21.3 | 19.2 | 227.3 | 0.677 |
| YOLOv11-l | 63.1 | 34.4 | 65 | 25.283 | 86.6 | 51.2 | 158.7 | 1.196 |
| YOLO-word-s | 66 | 36 | 66.6 | 12.749 | 16.02 | 25.8 | 277.8 | 1.491 |
| YOLO-word-x | 67.3 | 42.5 | 68.6 | 72.856 | 136.23 | 146.2 | 104.2 | 2.525 |
| Model | ∆mAP@0.5 (%) | Params Ratio (M) | FLOPs Ratio (G) | Model Size Ratio (M) | FPS Ratio |
|---|---|---|---|---|---|
| YOLOv5 | 26 | 25.6 | 25.6 | 24.4 | 1/2 |
| YOLOv7 | 13 | 1.2 | 22.6 | 11.6 | 1/3 |
| YOLOv8 | −3 | 26.4 | 20.5 | 26.3 | 11/3 |
| YOLOv9 | 36.3 | 2.0 | 22.4 | 16.1 | 1/9 |
| YOLOv10 | 1.9 | 11.8 | 19.9 | 11.7 | 1/4 |
| YOLOv11 | −2.9 | 8.4 | 10.7 | 8.1 | 1/4 |
| YOLOv-world | 1.3 | 5.7 | 8.5 | 5.7 | 3/8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Lan, X.; Wang, H. Comparative Analysis of YOLO Series Algorithms for UAV-Based Highway Distress Inspection: Performance and Application Insights. Sensors 2025, 25, 1475. https://doi.org/10.3390/s25051475
Yang Z, Lan X, Wang H. Comparative Analysis of YOLO Series Algorithms for UAV-Based Highway Distress Inspection: Performance and Application Insights. Sensors. 2025; 25(5):1475. https://doi.org/10.3390/s25051475
Chicago/Turabian StyleYang, Ziyi, Xin Lan, and Hui Wang. 2025. "Comparative Analysis of YOLO Series Algorithms for UAV-Based Highway Distress Inspection: Performance and Application Insights" Sensors 25, no. 5: 1475. https://doi.org/10.3390/s25051475
APA StyleYang, Z., Lan, X., & Wang, H. (2025). Comparative Analysis of YOLO Series Algorithms for UAV-Based Highway Distress Inspection: Performance and Application Insights. Sensors, 25(5), 1475. https://doi.org/10.3390/s25051475