
Parameter-Efficient Adaptation of Large Vision—Language Models for Video Memorability Prediction
 , ,
, ,  and
and 
Abstract
1. Introduction
- Introducing the label pre-processing and prediction post-processing necessary for using LVLMs for regression.
- Exploring Parameter-Efficient Fine-Tuning (PEFT) of LVLMs, and more concretely Quantized Low-Rank Adaptation (QLoRA) [20] of LVLMs for memorability prediction.
- Evaluating our proposal on the Memento10k dataset, obtaining state-of-the-art performance.
2. Related Work
2.1. Traditional Approaches to Computational Memorability Prediction
2.2. LVLMs and Their Applications
2.3. LVLMs for Memorability Prediction
3. Materials and Methods
3.1. Proposal
| Listing 1. Prompt used to feed the Qwen-VL model with visual and textual information about the video as well as context about the task and a call for action. |
 |
3.2. Dataset
3.3. Experimental Setup
4. Results and Discussion
4.1. Zero-Shot Inference
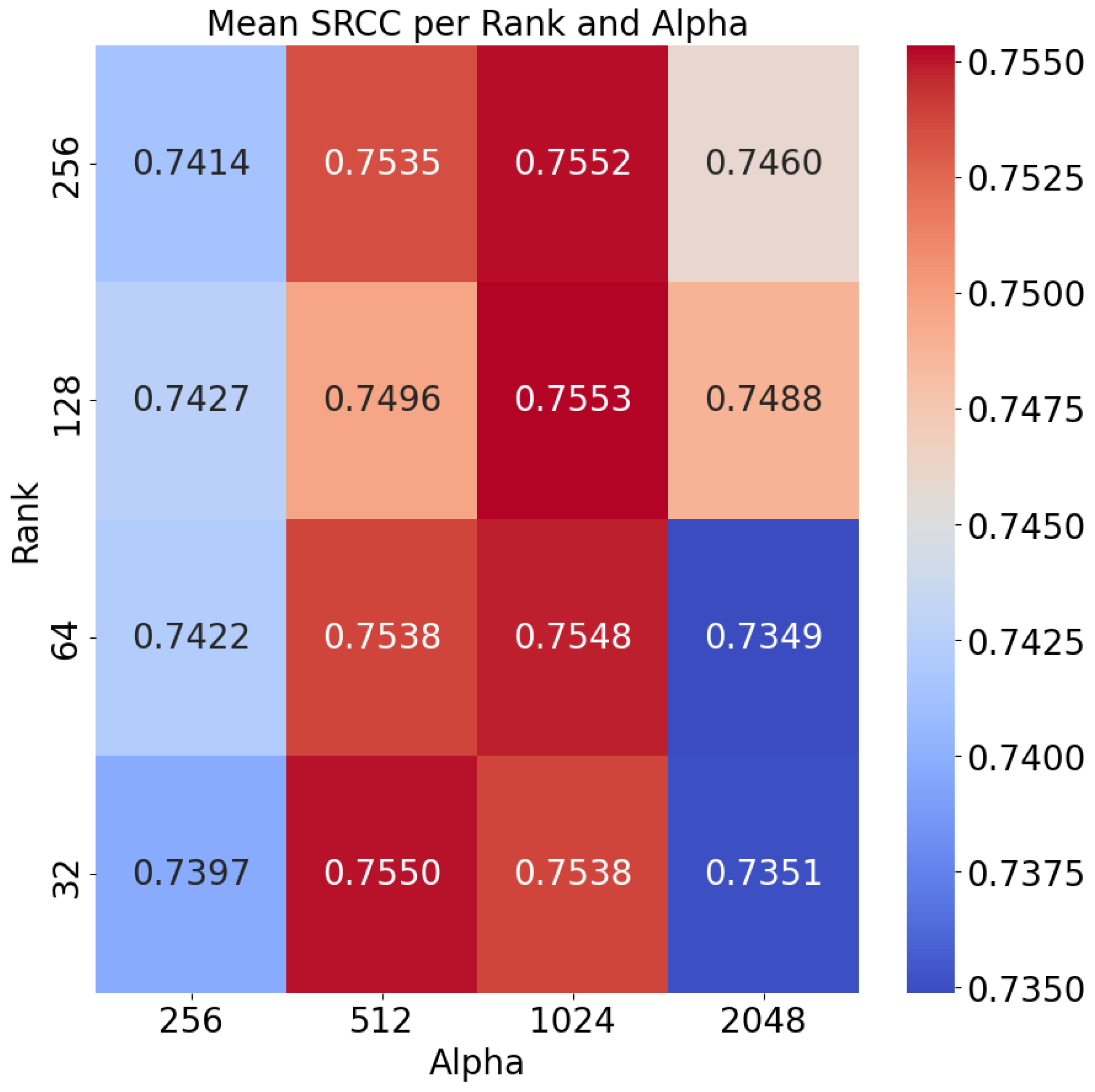
4.2. LoRA Hyperparameter Exploration
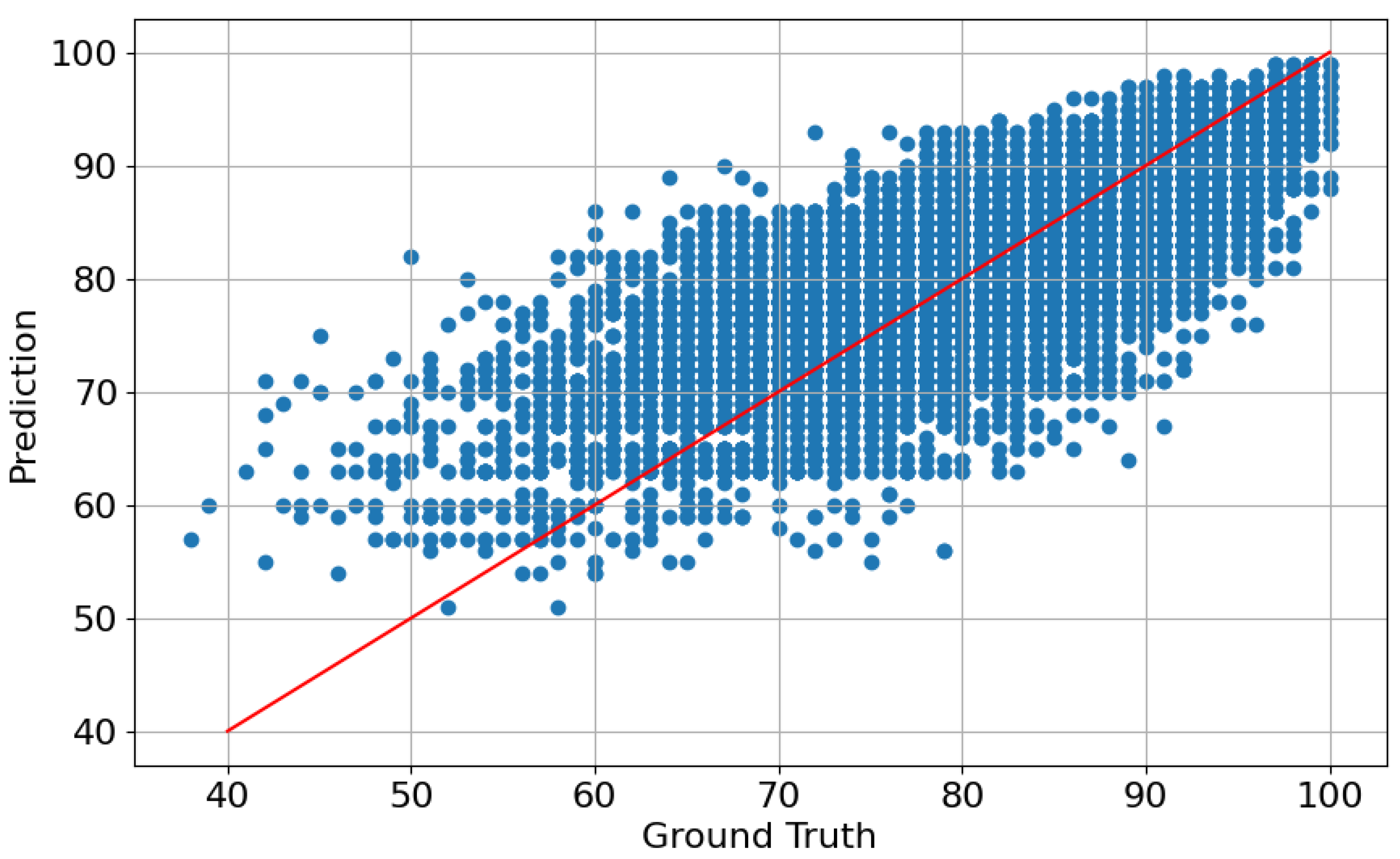
4.3. Error Analysis
4.4. Comparison Against the State of the Art
4.5. Limitations
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Memorable.io. Memorable.io: AI-Powered Memorability Prediction. 2025. Available online: https://www.memorable.io/ (accessed on 4 March 2025).
- Neosperience. Image Memorability by Neosperience. 2025. Available online: https://image.neosperience.com/ (accessed on 4 March 2025).
- Needell, C.D. Resmem: A Package that Wraps the ResMem Pytorch Model. 2021. Available online: https://github.com/Brain-Bridge-Lab/resmem (accessed on 4 March 2025).
- Bernstein, D.A.; Nash, P.W. Sensation and Perception. In Essentials of Psychology; Houghton Mifflin Company: Boston, MA, USA, 2008; pp. 84–134. [Google Scholar]
- Leder, H.; Belke, B.; Oeberst, A.; Augustin, D. A model of aesthetic appreciation and aesthetic judgments. Br. J. Psychol. 2004, 95, 489–508. [Google Scholar] [CrossRef] [PubMed]
- Bernstein, D.A.; Nash, P.W. Memory. In Essentials of Psychology; Houghton Mifflin Company: Boston, MA, USA, 2008; pp. 207–245. [Google Scholar]
- Isola, P.; Xiao, J.; Torralba, A.; Oliva, A. What makes an image memorable? In Proceedings of the CVPR 2011 IEEE, Colorado Springs, CO, USA, 20–25 June 2011; pp. 145–152. [Google Scholar]
- Isola, P.; Parikh, D.; Torralba, A.; Oliva, A. Understanding the intrinsic memorability of images. Adv. Neural Inf. Process. Syst. 2011, 24, 2429–2437. [Google Scholar]
- Lin, Q.; Yousif, S.R.; Chun, M.M.; Scholl, B.J. Visual memorability in the absence of semantic content. Cognition 2021, 212, 104714. [Google Scholar] [CrossRef] [PubMed]
- Xie, W.; Bainbridge, W.A.; Inati, S.K.; Baker, C.I.; Zaghloul, K.A. Memorability of words in arbitrary verbal associations modulates memory retrieval in the anterior temporal lobe. Nat. Hum. Behav. 2020, 4, 937–948. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Goetschalckx, L.; Newman, A.; Oliva, A. Memorability: An image-computable measure of information utility. In Human Perception of Visual Information: Psychological and Computational Perspectives; Springer: Cham, Switzerland, 2022; pp. 207–239. [Google Scholar]
- Kleinlein, R.; Luna-Jiménez, C.; Arias-Cuadrado, D.; Ferreiros, J.; Fernández-Martínez, F. Topic-Oriented Text Features Can Match Visual Deep Models of Video Memorability. Appl. Sci. 2021, 11, 7406. [Google Scholar] [CrossRef]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Lu, P.; Mishra, S.; Xia, T.; Qiu, L.; Chang, K.W.; Zhu, S.C.; Tafjord, O.; Clark, P.; Kalyan, A. Learn to explain: Multimodal reasoning via thought chains for science question answering. Adv. Neural Inf. Process. Syst. 2022, 35, 2507–2521. [Google Scholar]
- Agrawal, H.; Desai, K.; Wang, Y.; Chen, X.; Jain, R.; Johnson, M.; Batra, D.; Parikh, D.; Lee, S.; Anderson, P. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8948–8957. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 787–798. [Google Scholar]
- Newman, A.; Fosco, C.; Casser, V.; Lee, A.; McNamara, B.; Oliva, A. Multimodal memorability: Modeling effects of semantics and decay on video memorability. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Cham, Switzerland, 2020; pp. 223–240. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; Zhou, J. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv 2023, arXiv:2308.12966. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685v1. [Google Scholar]
- Shepard, R.N. Recognition memory for words, sentences, and pictures. J. Verbal Learn. Verbal Behav. 1967, 6, 156–163. [Google Scholar] [CrossRef]
- Standing, L. Learning 10,000 pictures. Q. J. Exp. Psychol. 1973, 25, 207–222. [Google Scholar] [CrossRef] [PubMed]
- Jaegle, A.; Mehrpour, V.; Mohsenzadeh, Y.; Meyer, T.; Oliva, A.; Rust, N. Population response magnitude variation in inferotemporal cortex predicts image memorability. eLife 2019, 8, e47596. [Google Scholar] [CrossRef]
- Lahner, B.; Mohsenzadeh, Y.; Mullin, C.; Oliva, A. Visual perception of highly memorable images is mediated by a distributed network of ventral visual regions that enable a late memorability response. PLoS Biol. 2024, 22, e3002564. [Google Scholar] [CrossRef] [PubMed]
- Perera, S.; Tal, A.; Zelnik-Manor, L. Is image memorability prediction solved? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Khosla, A.; Raju, A.S.; Torralba, A.; Oliva, A. Understanding and predicting image memorability at a large scale. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2390–2398. [Google Scholar]
- Cohendet, R.; Demarty, C.H.; Duong, N.Q.; Engilberge, M. VideoMem: Constructing, analyzing, predicting short-term and long-term video memorability. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2531–2540. [Google Scholar]
- Constantin, M.G.; Demarty, C.H.; Fosco, C.; Seco, A.G.; de Herrera, S.H.; Healy, G.; Ionescu, B.; Matran-Fernandez, A.; Kiziltepe, R.S.; Smeaton, A.F.; et al. Overview of The MediaEval 2023 Predicting Video Memorability Task. In Proceedings of the MediaEval ’23: Multimedia Evaluation Workshop, Amsterdam, The Netherlands, 1–2 February 2024. [Google Scholar]
- Sweeney, L.; Constantin, M.G.; Demarty, C.H.; Fosco, C.; de Herrera, A.G.S.; Halder, S.; Healy, G.; Ionescu, B.; Matran-Fernandez, A.; Smeaton, A.F.; et al. Overview of the MediaEval 2022 predicting video memorability task. arXiv 2022, arXiv:2212.06516. [Google Scholar]
- Kiziltepe, R.S.; Constantin, M.G.; Demarty, C.H.; Healy, G.; Fosco, C.; de Herrera, A.G.S.; Halder, S.; Ionescu, B.; Matran-Fernandez, A.; Smeaton, A.F.; et al. Overview of the MediaEval 2021 predicting media memorability task. arXiv 2021, arXiv:2112.05982. [Google Scholar]
- Constantin, M.G.; Ionescu, B. AIMultimediaLab at MediaEval 2022: Predicting Media Memorability Using Video Vision Transformers and Augmented Memorable Moments. In Proceedings of the MediaEval ’23: Multimedia Evaluation Workshop, Bergen, Norway, 13–15 January 2023. [Google Scholar]
- Martín-Fernández, I.; Kleinlein, R.; Luna-Jiménez, C.; Gil-Martín, M.; Fernández-Martínez, F. Video Memorability Prediction From Jointly-learnt Semantic and Visual Features. In Proceedings of the 20th International Conference on Content-Based Multimedia Indexing, New York, NY, USA, 20–22 September 2023; pp. 178–182. [Google Scholar] [CrossRef]
- Agarla, M.; Celona, L.; Schettini, R. Predicting Video Memorability Using a Model Pretrained with Natural Language Supervision. In Proceedings of the MediaEval Multimedia Benchmark Workshop Working Notes, Bergen, Norway and Online, 12–13 January 2023; Volume 1. [Google Scholar]
- Kleinlein, R.; Luna-Jiménez, C.; Fernández-Martínez, F. THAU-UPM at MediaEval 2021: From Video Semantics To Memorability Using Pretrained Transformers. In Proceedings of the MediaEval Multimedia Benchmark Workshop Working Notes, Online, 13–15 December 2021. [Google Scholar]
- Dumont, T.; Hevia, J.S.; Fosco, C.L. Modular memorability: Tiered representations for video memorability prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10751–10760. [Google Scholar]
- Li, J.; Guo, X.; Yue, F.; Xue, F.; Sun, J. Adaptive Multi-Modal Ensemble Network for Video Memorability Prediction. Appl. Sci. 2022, 12, 8599. [Google Scholar] [CrossRef]
- Kumar, P.; Khandelwal, E.; Tapaswi, M.; Sreekumar, V. Seeing Eye to AI: Comparing Human Gaze and Model Attention in Video Memorability. arXiv 2024, arXiv:2311.16484. [Google Scholar]
- Elkins, K.; Chun, J. Can GPT-3 pass a Writer’s turing test? J. Cult. Anal. 2020, 5, 1–16. [Google Scholar] [CrossRef]
- Kosinski, M. Theory of mind may have spontaneously emerged in large language models. arXiv 2023, arXiv:2302.02083. [Google Scholar]
- Yukun, Z.; Xu, L.; Huang, Z.; Peng, K.; Seligman, M.; Li, E.; Yu, F. AI Chatbot Responds to Emotional Cuing. PsyArXiv 2023, preprint. [Google Scholar] [CrossRef]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Newry, UK, 2017; Volume 30. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Yang, A.; Yang, B.; Hui, B.; Zheng, B.; Yu, B.; Zhou, C.; Li, C.; Li, C.; Liu, D.; Huang, F.; et al. Qwen2 Technical Report. arXiv 2024, arXiv:2407.10671. [Google Scholar]
- Anthropic. Claude 3.5 Sonnet Model Card Addendum; Anthropic: San Francisco, CA, USA, 2024. [Google Scholar]
- Team, G.; Riviere, M.; Pathak, S.; Sessa, P.G.; Hardin, C.; Bhupatiraju, S.; Hussenot, L.; Mesnard, T.; Shahriari, B.; Ramé, A.; et al. Gemma 2: Improving open language models at a practical size. arXiv 2024, arXiv:2408.00118. [Google Scholar]
- Qwen Team. Qwen2.5 Technical Report. arXiv 2025, arXiv:2412.15115. [Google Scholar]
- Meta. Llama 3.2 Model Card. 2024. Available online: https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md (accessed on 25 November 2024).
- Beyer, L.; Steiner, A.; Pinto, A.S.; Kolesnikov, A.; Wang, X.; Salz, D.; Neumann, M.; Alabdulmohsin, I.; Tschannen, M.; Bugliarello, E.; et al. Paligemma: A versatile 3b vlm for transfer. arXiv 2024, arXiv:2407.07726. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. In Proceedings of the NeurIPS, New Orleans, LA, USA, 10–16 December 2024. [Google Scholar]
- Liu, H.; Li, C.; Li, Y.; Lee, Y.J. Improved Baselines with Visual Instruction Tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle WA, USA, 17–21 June 2024. [Google Scholar]
- de Zarzà, I.; de Curtò, J.; Roig, G.; Calafate, C.T. LLM Multimodal Traffic Accident Forecasting. Sensors 2023, 23, 9225. [Google Scholar] [CrossRef]
- Ghosh, A.; Acharya, A.; Saha, S.; Jain, V.; Chadha, A. Exploring the frontier of vision-language models: A survey of current methodologies and future directions. arXiv 2024, arXiv:2404.07214. [Google Scholar]
- Singh, S.; Si, H.; Singla, Y.K.; Baths, V.; Shah, R.R.; Chen, C.; Krishnamurthy, B. LLaVA Finds Free Lunch: Teaching Human Behavior Improves Content Understanding Abilities Of LLMs. arXiv 2024, arXiv:2405.00942. [Google Scholar]
- au2, H.S.I.; Singh, S.; Singla, Y.K.; Bhattacharyya, A.; Baths, V.; Chen, C.; Shah, R.R.; Krishnamurthy, B. Long-Term Ad Memorability: Understanding and Generating Memorable Ads. arXiv 2024, arXiv:2309.00378. [Google Scholar]
- Sun, Q.; Fang, Y.; Wu, L.; Wang, X.; Cao, Y. Eva-clip: Improved training techniques for clip at scale. arXiv 2023, arXiv:2303.15389. [Google Scholar]
- Nguyen, M.Q.; Trinh, M.H.; Bui, H.G.; Vo, K.T.; Tran, M.T.; Tran, T.P.; Nguyen, H.D. SELAB-HCMUS at MediaEval 2023: A cross-domain and subject-centric approach towards the memorability prediction task. In Proceedings of the MediaEval Multimedia Benchmark Workshop Working Notes, Bergen, Norway and Online, 12–13 January 2023. [Google Scholar]
- Usmani, M.M.A.; Zahid, S.; Tahir, M.A. Modelling of Video Memorability using Ensemble Learning and Transformers. In Proceedings of the MediaEval’22: Multimedia Evaluation Workshop, Bergen, Norway, 13–15 January 2023. [Google Scholar]
- Azzakhnini, S.; Ahmed, O.B.; Fernandez-Maloigne, C. Video Memorability Prediction using Deep Features and Loss-based Memorability Distribution Estimation. In Proceedings of the MediaEval’22: Multimedia Evaluation Workshop, Bergen, Norway, 13–15 January 2023. [Google Scholar]
- Sweeney, L.; Smeaton, A.; Healy, G. Memories in the Making: Predicting Video Memorability with Encoding Phase EEG. In Proceedings of the 20th International Conference on Content-Based Multimedia Indexing, Orleans, France, 20–22 September 2023; pp. 183–187. [Google Scholar]
- Esteban-Romero, S.; Bellver-Soler, J.; Martın-Fernández, I.; Gil-Martın, M.; D’Haro, L.F.; Fernández-Martınez, F. THAU-UPM at EmoSPeech-IberLEF2024: Efficient Adaptation of Mono-modal and Multi-modal Large Language Models for Automatic Speech Emotion Recognition. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2024), Co-Located with the 40th Conference of the Spanish Society for Natural Language Processing (SEPLN 2024), CEUR-WS. org. Conference of the Spanish Society for Natural Language Processing (SEPLN 2024), Castilla y León, Spain, 24 September 2024. [Google Scholar]
- Esteban-Romero, S.; Martín-Fernández, I.; Gil-Martín, M.; Fernández-Martínez, F. Synthesizing Olfactory Understanding: Multimodal Language Models for Image-Text Smell Matching. 2024. Available online: https://ssrn.com/abstract=4912100 (accessed on 4 March 2025).
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. QLoRA: Efficient Finetuning of Quantized LLMs. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; Curran Associates, Inc.: Newry, UK, 2023; Volume 36, pp. 10088–10115. [Google Scholar]
- Li, K.; Yang, Z.; Chen, L.; Yang, Y.; Xiao, J. CATR: Combinatorial-Dependence Audio-Queried Transformer for Audio-Visual Video Segmentation. In Proceedings of the 31st ACM International Conference on Multimedia, New York, NY, USA, 20–22 September 2023; pp. 1485–1494. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, G.; Li, X.; Wang, W.; Yang, Y. DoraemonGPT: Toward Understanding Dynamic Scenes with Large Language Models (Exemplified as A Video Agent). In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; Salakhutdinov, R., Kolter, Z., Heller, K., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F., Eds.; Volume 235, pp. 55976–55997. [Google Scholar]
- Xiong, H.; Yang, Z.; Yu, J.; Zhuge, Y.; Zhang, L.; Zhu, J.; Lu, H. Streaming Video Understanding and Multi-round Interaction with Memory-enhanced Knowledge. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Total Parameters | Number of Trained Parameters (% Total) | SRCC (95% CI) |
|---|---|---|---|
| Human Consistency [18] | - | - | 0.730 |
| SemanticMemNet [18] | 13 M | 13 M (100%) | 0.663 (0.634, 0.690) |
| Constantin, Ionescu [31] | 57.7 M | 57.7 M (100%) | 0.665 (0.636, 0.692) |
| M3-S [35] | 110 M | 110 M (100%) | 0.670 (0.641, 0.697) |
| Kumar et al. 1 [37] | N/A | N/A | 0.713 (0.687, 0.737) |
| Qwen-VL (QLoRA) (Ours) | 9.6 B | 67.1 M (0.7%) | 0.744 (0.721, 0.766) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martín-Fernández, I.; Esteban-Romero, S.; Fernández-Martínez, F.; Gil-Martín, M. Parameter-Efficient Adaptation of Large Vision—Language Models for Video Memorability Prediction. Sensors 2025, 25, 1661. https://doi.org/10.3390/s25061661
Martín-Fernández I, Esteban-Romero S, Fernández-Martínez F, Gil-Martín M. Parameter-Efficient Adaptation of Large Vision—Language Models for Video Memorability Prediction. Sensors. 2025; 25(6):1661. https://doi.org/10.3390/s25061661
Chicago/Turabian StyleMartín-Fernández, Iván, Sergio Esteban-Romero, Fernando Fernández-Martínez, and Manuel Gil-Martín. 2025. "Parameter-Efficient Adaptation of Large Vision—Language Models for Video Memorability Prediction" Sensors 25, no. 6: 1661. https://doi.org/10.3390/s25061661
APA StyleMartín-Fernández, I., Esteban-Romero, S., Fernández-Martínez, F., & Gil-Martín, M. (2025). Parameter-Efficient Adaptation of Large Vision—Language Models for Video Memorability Prediction. Sensors, 25(6), 1661. https://doi.org/10.3390/s25061661