
Classification and Recognition of Soybean Quality Based on Hyperspectral Imaging and Random Forest Methods

Abstract
1. Introduction
2. Materials and Methods
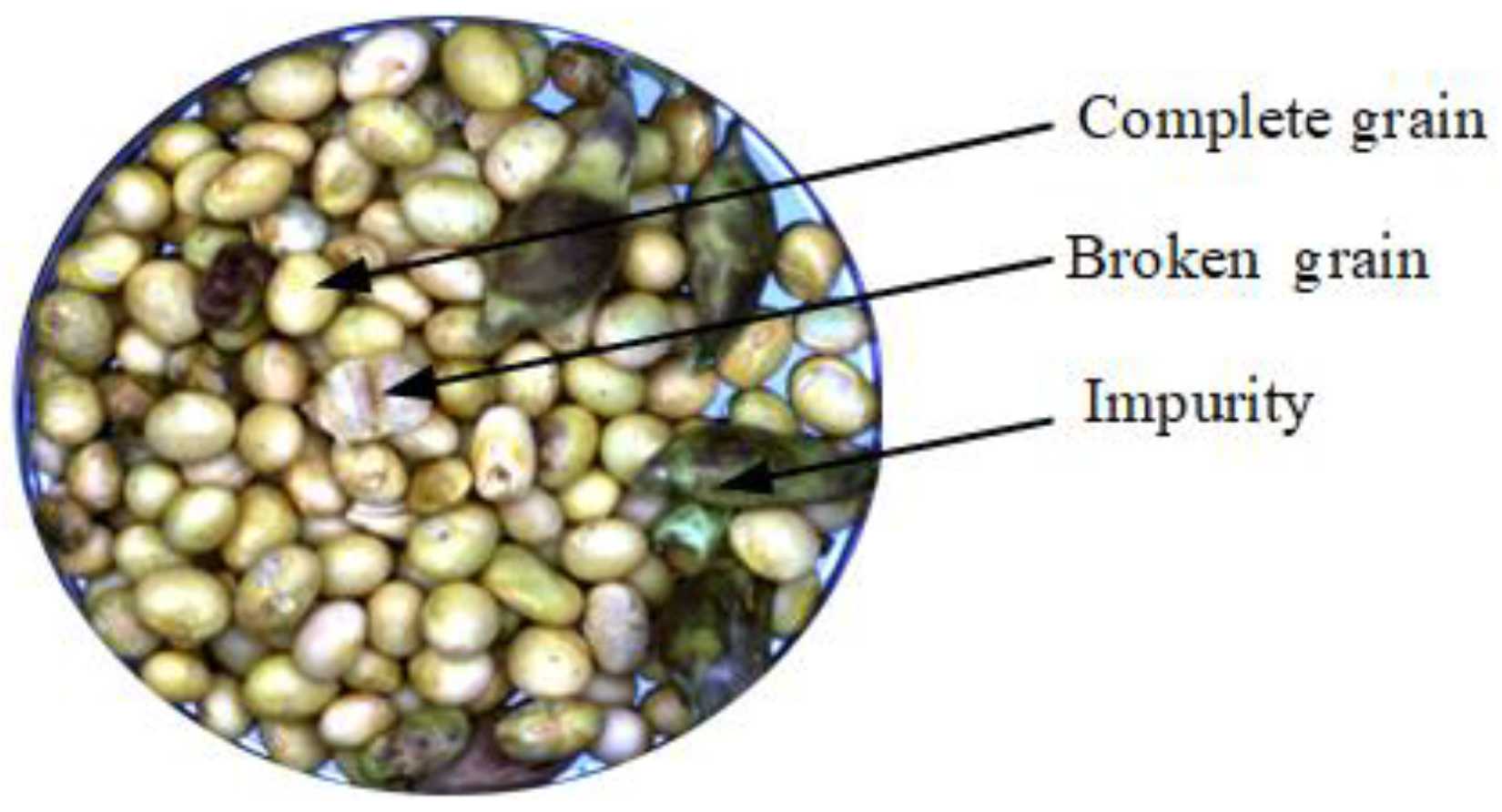
2.1. Samples and Component Classification
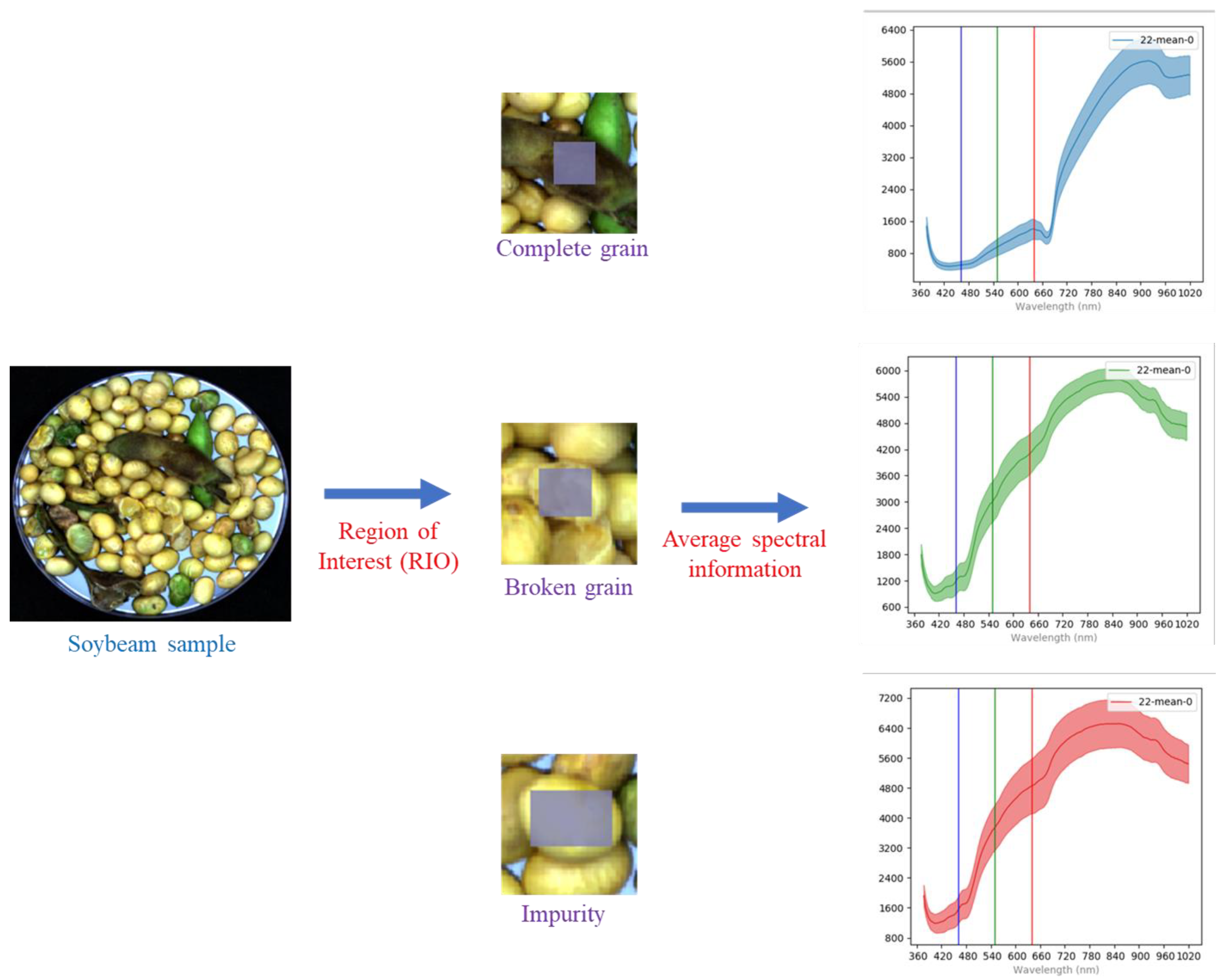
2.2. Spectral Image Information Collection
2.3. Feature Spectrum Extraction
2.4. Sample Data Preprocessing Methods
2.5. Soybean Component Classification Method Based on Spectral Information
2.6. Accuracy Validation
3. Results and Discussion
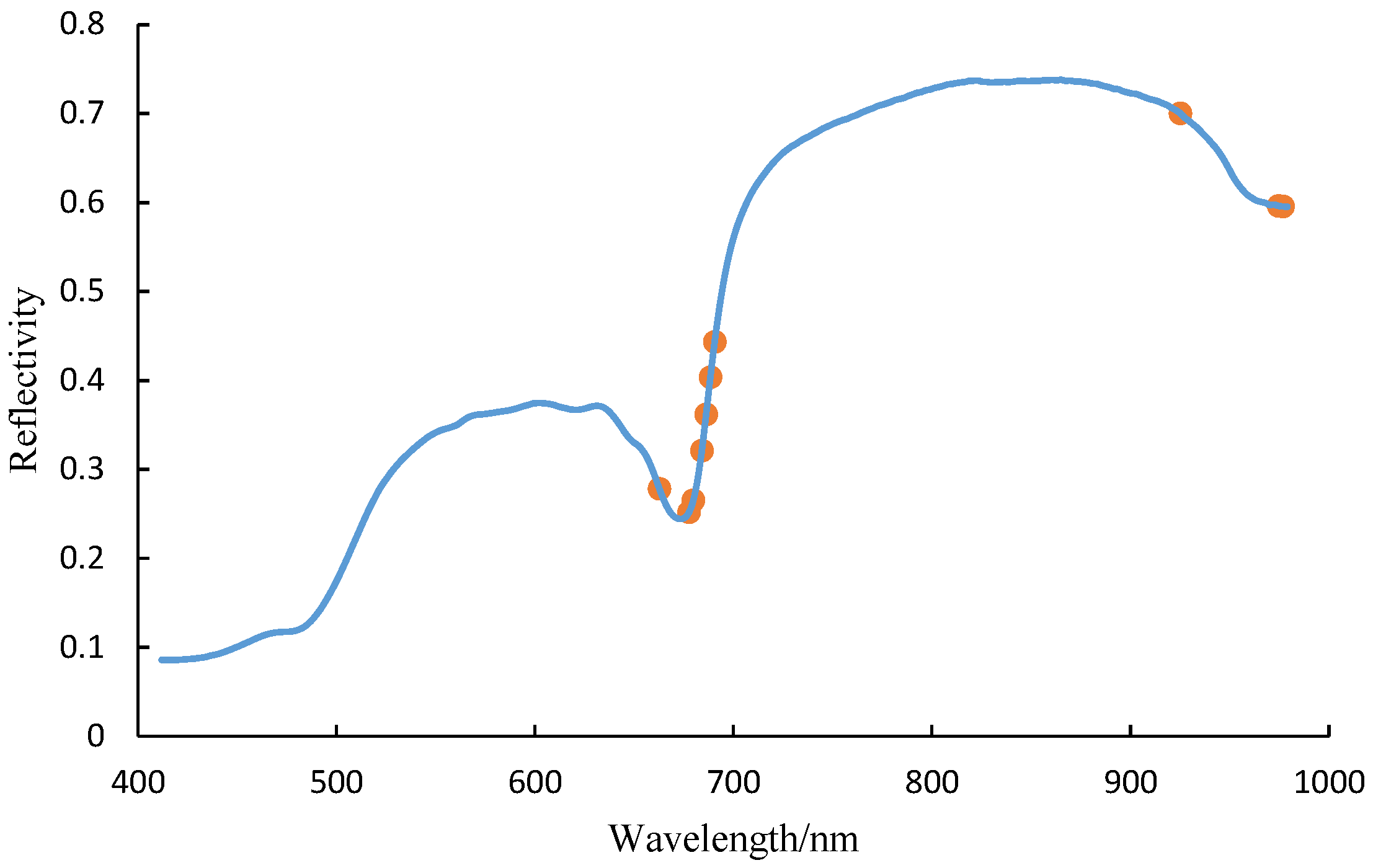
3.1. Spectral Data Preprocessing
3.2. Feature Wavelength Extraction
3.2.1. Successive Projections Algorithm
3.2.2. Competitive Adaptive Reweighted Sampling Algorithm
3.2.3. Component Recognition Based on Feature Wavelengths
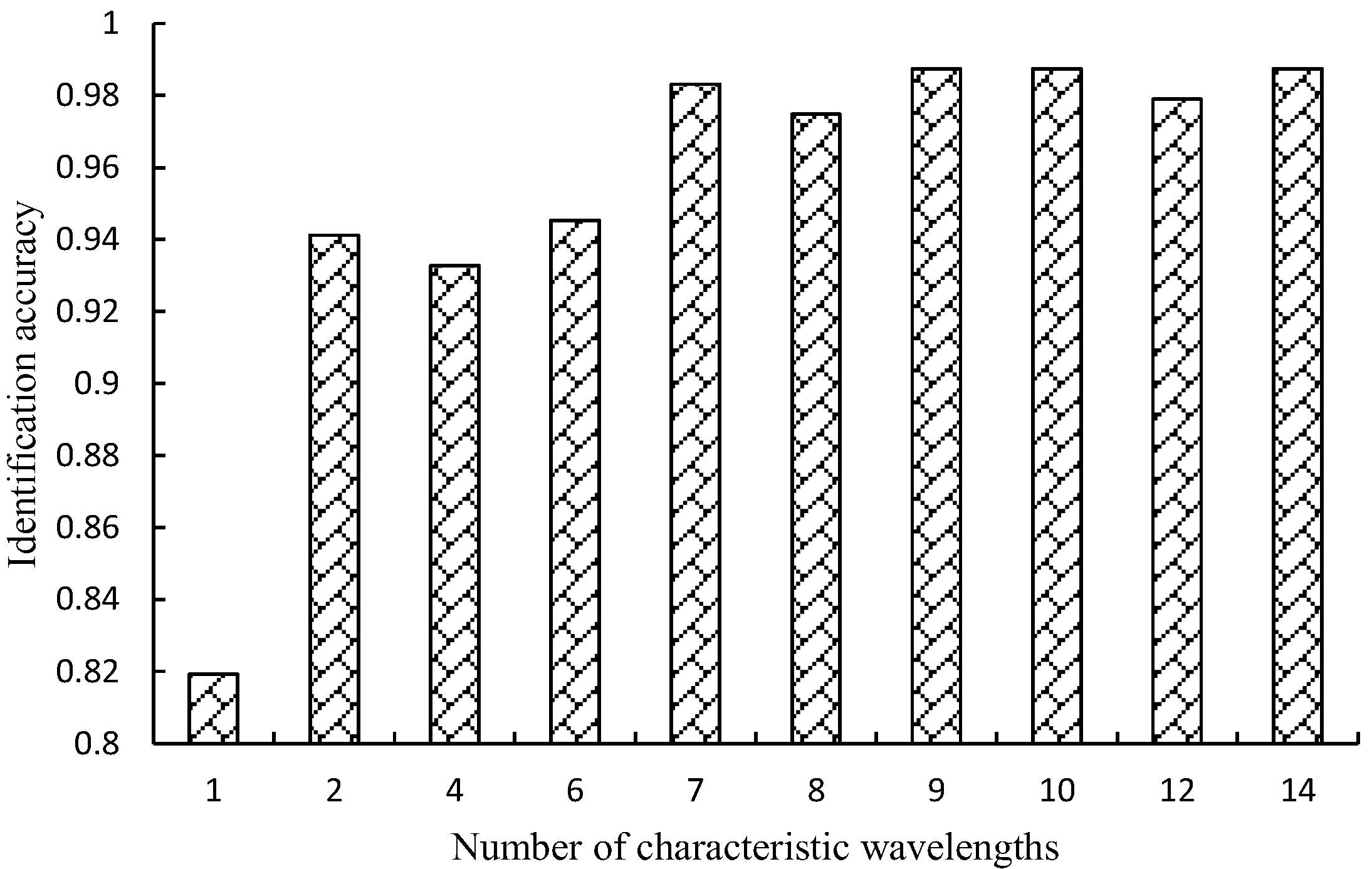
3.3. Hyperparameter Optimization
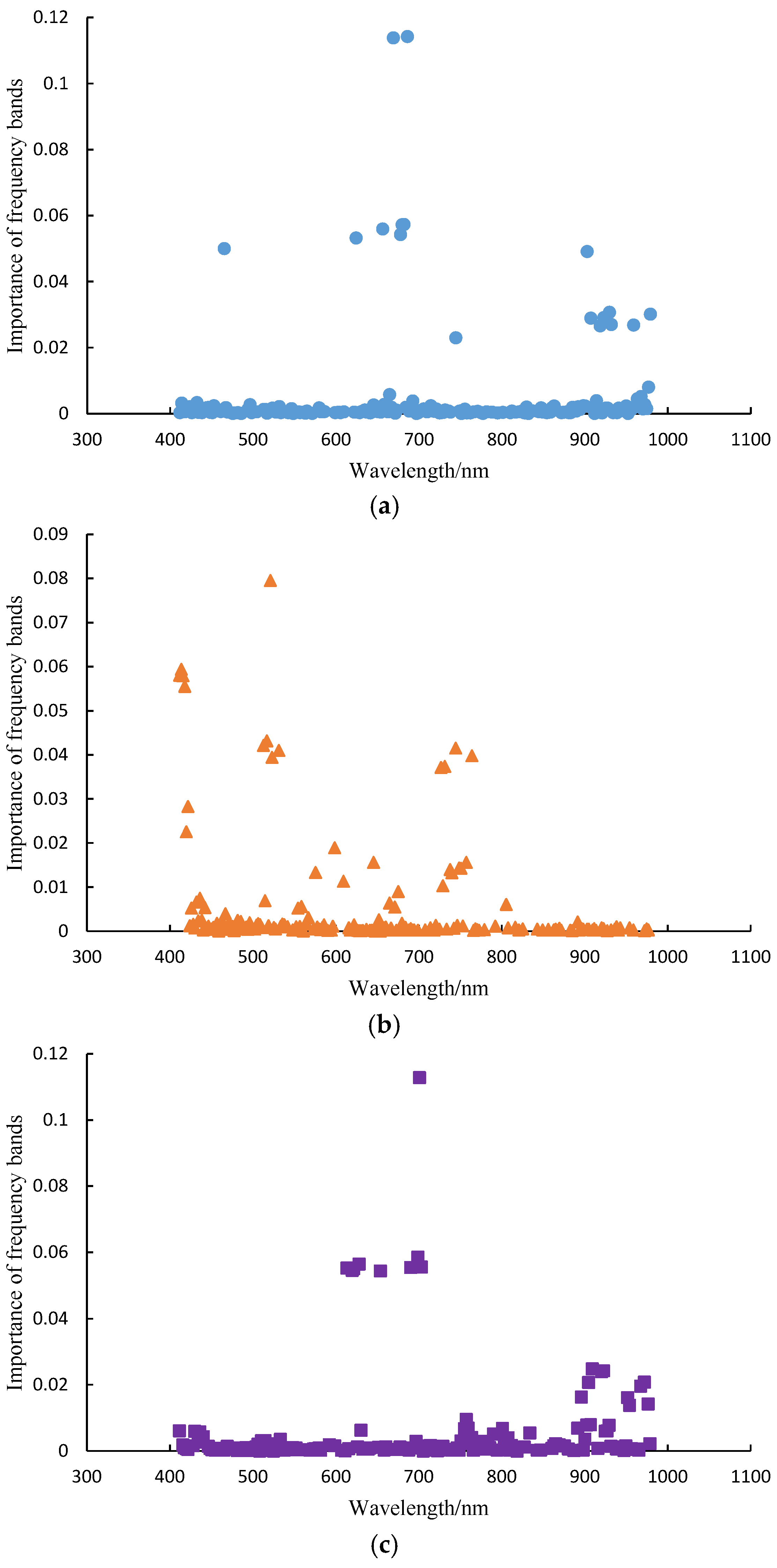
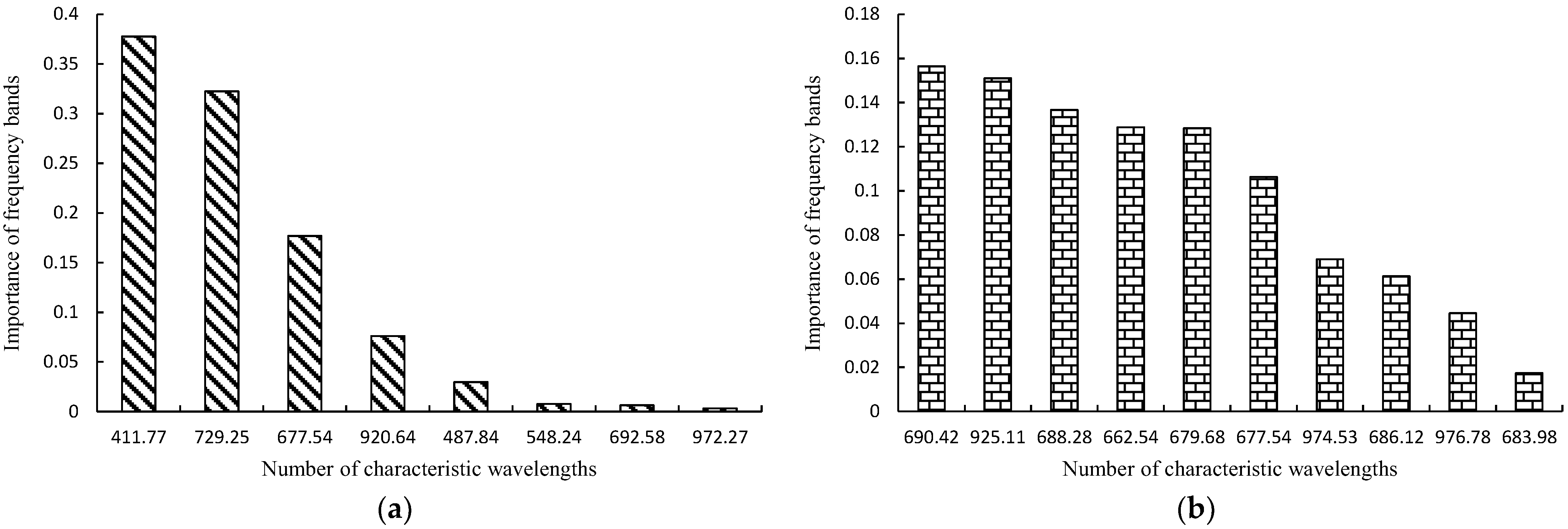
3.4. Feature Wavelength Importance
3.5. Recognition Effectiveness of Different Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, Y.J.; Chen, Y.F.; Wu, Z.L. Global supply chain risk assessment and resilience measurement: Taking soybean as an example. Acta Geogr. Sin. 2024, 79, 2651–2669. [Google Scholar] [CrossRef]
- Li, H.H.; Liu, C.Y.; Zhang, H.W.; Wang, X.J.; Tang, Q.L.; Wang, Y.H. Global Genetically Modified Crop Industrialization Trends in 2022. J. Agric. Sci. Technol. 2023, 25, 6–16. [Google Scholar] [CrossRef]
- Wang, M.; Fu, Q.; Hou, R.J.; Li, T.X.; Xue, P. Effects of cultivation modes and straw returning on soil phosphorus composition and soybean yield in the Songnen Plain of China. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2024, 40, 114–126. [Google Scholar] [CrossRef]
- Liu, C.; Wu, D.D.; Wang, N.; Wang, R.Y.; Wang, L.Q.; Liu, F.; Yu, D.Y. Two-dimensional correlation infrared spectroscopy for rapid analysis of the effect of pH on the secondary structure content of soybean protein isolate. Food Sci. 2024, 45, 26–34. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, H.L.; Wu, D.D.; Wang, W.N.; Wang, L.Q.; Luo, S.N.; Yu, D.Y. Fast quantification of phosphorus in crude soybean oil by near-infrared spectroscopy. Food Sci. 2023, 44, 316–322. [Google Scholar] [CrossRef]
- Chen, S.Y.; Zhu, H.Y.; Wang, J.F.; Yu, T.; Wang, Z.X.; Liu, C.S. Abnormal soybean grains recognition based on opt-mobilenetv3. Trans. Chin. Soc. Agric. Mach. 2021, 37, 235–241. [Google Scholar]
- Gui, J.S.; He, J.; Fu, X.P. Hyperspectral detection of soybean heart-eating insect pests based on image retrieval. Spectrosc. Spectr. Anal. 2022, 42, 2931–2934. [Google Scholar] [CrossRef]
- Guo, X.Y.; Li, J.S.; Zheng, L.H.; Zhang, M.; Wang, M.J. Acquiring soybean phenotypic parameters using Re-YOLOv5 and area search algorithm. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 186–194. [Google Scholar] [CrossRef]
- Momin, M.A.; Yamamoto, K.; Miyamoto, M.; Kondo, N.; Grift, T. Machine vision based soybean quality evaluation. Comput. Electron. Agric. 2017, 140, 452–460. [Google Scholar] [CrossRef]
- Li, B.; Sun, J.; Liu, Y.; Shi, L.; Zhong, Y.H.; Wu, P.C. Multi-level data fusion strategy based on spectral and image information for identifying varieties of soybean seeds. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2024, 322, 124815. [Google Scholar] [CrossRef]
- Li, W.; Shu, L.; Zhong, W.B.; Lu, W.; Ma, D.Y.; Meng, Y.Z. Online classification of soybean seeds based on deep learning. Eng. Appl. Artif. Intell. 2023, 123, 106434. [Google Scholar] [CrossRef]
- Song, C.X.; Yu, C.Y.; Xing, Y.C.; Li, S.M.; He, H.; Yu, H.; Feng, X.Z. Algorith for acquiring multi-phenotype parameters of soybean seed based on OpenCV. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 156–163. [Google Scholar] [CrossRef]
- Chen, M.; Xu, J.S.; Jin, C.Q.; Zhang, G.Y.; Ni, Y.L. Inversion model of soybean impurity rate based on hyperspectral. J. China Agric. Univ. 2019, 24, 160–167. [Google Scholar]
- Luo, W.; Peng, D.L.; Liu, J.X.; Xu, J.F.; Lou, Z.H.; Liu, G.H.; Gao, S.; Yu, L.; Wang, F.M. Soybean identification and extraction method based on spectral characteristics of Sentinel-2 time-series images. Natl. Remote Sens. Bull. 2024, 28, 2513–2524. [Google Scholar] [CrossRef]
- Li, W.; Tan, F.; Zhang, W.; Gao, L.S.; Li, J.S. Application of Improved Random Frog Algorithm in Fast Identification of Soybean Varieties. Spectrosc. Spectr. Anal. 2023, 43, 3763–3769. [Google Scholar]
- Ni, Y.L.; Jin, C.Q.; Wang, T.E.; Zhou, L.; Liu, Z. Design and experiments of the 4LZ-1.5 soybean combine harvester. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 1–11. [Google Scholar] [CrossRef]
- Zhang, T.; Jin, X.; Rao, Y.; Luo, Q.; Li, S.W.; Wang, L.L.; Zhang, X.D. Inversing photosynthesis quantum yield of the soybean flag leaf using a UAV-carrying multispectral camera. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 150–157. [Google Scholar] [CrossRef]
- Tang, Z.J.; Zhang, W.; Huang, X.Y.; Xiang, Y.Z.; Zhang, F.C.; Chen, J.Y. Soybean seed yield estimation model based on ground hyperspectral remote sensing technology. Trans. Chin. Soc. Agric. Mach. 2024, 55, 145–153+240. [Google Scholar]
- Xiang, Y.Z.; An, J.Q.; Zhao, X.; Jin, L.; Li, Z.J.; Zhang, F.C. Soybean growth parameters and yield estimation based on uav multispectral remote sensing. Trans. Chin. Soc. Agric. Mach. 2023, 54, 230–239. [Google Scholar]
- Xiang, Y.Z.; Wang, X.; An, J.Q.; Tang, Z.J.; Li, W.Y.; Shi, H.Z. Estimation of leaf area index of soybean based on fractional order differentiation and optimal spectral index. Trans. Chin. Soc. Agric. Mach. 2023, 54, 329–342. [Google Scholar]
- Gao, L.; Yang, G.J.; Wang, B.S.; Yu, H.Y.; Xu, B.; Feng, H.K. Soybean leaf area index retrieval with UAV (unmanned aerial vehicle) remote sensing imagery. Chin. J. Eco-Agric. 2015, 23, 868–876. [Google Scholar] [CrossRef]
- Gao, S.J.; Guan, H.O.; Ma, X.D.; Wang, Y.H. Soybean Canopy Extraction Method Based on Multispectral Image Processing. Spectrosc. Spectr. Anal. 2022, 42, 3568–3574. [Google Scholar]
- Liu, S.; Yu, H.Y.; Sui, Y.Y.; Kong, L.J.; Yu, Z.D.; Guo, J.J.; Qiao, J.L. Hyperspectral data analysis for classification of soybean leaf diseases. Spectrosc. Spectr. Anal. 2023, 43, 1550–1555. [Google Scholar]
- Zhang, H.; Yao, C.N.; Jiang, M.M.; Ji, Y.H.; Li, H.J. Research on Wheat Seed Classification and Recognition Based on Hyperspectral Imaging. J. Triticeae Crops 2019, 39, 96–104. [Google Scholar] [CrossRef]
- Xu, D.; Pan, J.; Jiang, L.J.; Cao, Y. Typical feature classification and identification method based on hyperspectral data. Eur. Conf. Comput. Vis. 2023, 60, 1530002. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Model | Pretreatment | Modeling Band | Complete Grain | Broken Grain | Impurity | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | RPrecision | RRecal | F1 | ||||
| RF | No | 177 | 0.9867 | 0.9801 | 0.9834 | 0.9375 | 0.9574 | 0.9474 | 1.0000 | 1.0000 | 1.0000 | 0.9790 |
| BC | 173 | 0.9896 | 1.0000 | 0.9948 | 1.0000 | 0.9722 | 0.9859 | 1.0000 | 1.0000 | 1.0000 | 0.9958 | |
| MA | 186 | 0.9805 | 0.9934 | 0.9869 | 0.9778 | 0.9362 | 0.9565 | 1.0000 | 1.0000 | 1.0000 | 0.9832 | |
| SGD | 185 | 0.9934 | 0.9934 | 0.9934 | 0.9787 | 0.9787 | 0.9787 | 1.0000 | 1.0000 | 1.0000 | 0.9916 | |
| Normalization | 162 | 0.9938 | 1.0000 | 0.9969 | 1.0000 | 0.9773 | 0.9885 | 1.0000 | 1.0000 | 1.0000 | 0.9958 | |
| SNV | 184 | 0.9664 | 1.0000 | 0.9829 | 1.0000 | 0.8649 | 0.9275 | 1.0000 | 1.0000 | 1.0000 | 0.9790 | |
| MSC | 189 | 0.9809 | 1.0000 | 0.9904 | 1.0000 | 0.9268 | 0.962 | 1.0000 | 1.0000 | 1.0000 | 0.9874 | |
| DS | 153 | 0.9756 | 0.9756 | 0.9756 | 0.9677 | 0.9677 | 0.9677 | 1.0000 | 1.0000 | 1.0000 | 0.9916 | |
| SGS | 183 | 0.9805 | 0.9934 | 0.9869 | 0.9783 | 0.9375 | 0.9574 | 1.0000 | 1.0000 | 1.0000 | 0.9832 | |
| Classification Model | Feature Wavelength Extraction Method | Pretreatment | Complete Grain | Broken Grain | Impurity | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | RPrecision | RRecal | F1 | ||||
| RF | SPA | No | 0.9934 | 0.9934 | 0.9934 | 0.9787 | 0.9787 | 0.9787 | 1.0000 | 1.0000 | 1.0000 | 0.9916 |
| BC | 1.0000 | 0.9899 | 0.9979 | 0.9714 | 1.000 | 0.9855 | 1.0000 | 1.0000 | 1.0000 | 0.9958 | ||
| Normalization | 0.9874 | 0.9812 | 0.9843 | 0.9302 | 0.9524 | 0.9412 | 1.0000 | 1.0000 | 1.0000 | 0.9790 | ||
| CARS | No | 0.9933 | 0.9868 | 0.99 | 0.9583 | 0.9787 | 0.9684 | 1.0000 | 1.0000 | 1.0000 | 0.9874 | |
| BC | 0.8713 | 0.898 | 0.8844 | 0.7436 | 0.6905 | 0.716 | 1.0000 | 1.0000 | 1.0000 | 0.9034 | ||
| Normalization | 0.9758 | 0.9699 | 0.9728 | 0.9038 | 0.9216 | 0.9126 | 1.0000 | 1.0000 | 1.0000 | 0.9622 | ||
| Classification Model | Parameter Tuning Method | Feature Wavelength Extraction Method | Pretreatment | Training for Optimal Prediction Accuracy | Validation Set | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Complete Grain | Broken Grain | Impurity | Overall Accuracy | |||||||||||
| RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | ||||||
| RF | PSO | SPA | BC | 1.0000 | 1.0000 | 0.9798 | 0.9898 | 0.9444 | 1.0000 | 0.9714 | 1.0000 | 1.0000 | 1.0000 | 0.9916 |
| CARS | No | 0.9916 | 0.9936 | 0.981 | 0.9873 | 0.9464 | 0.9815 | 0.9636 | 1.0000 | 1.0000 | 1.0000 | 0.9832 | ||
| DE | SPA | BC | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| CARS | No | 0.9916 | 1.000 | 0.9873 | 0.9936 | 0.9643 | 1.0000 | 0.9818 | 1.0000 | 1.0000 | 1.0000 | 0.9916 | ||
| Classification Model | Pretreatment | Modeling Band | Complete Grain | Broken Grain | Impurity | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | RPrecision | RRecal | F1 | ||||
| RF | No | 690.42, 925.11, 688.28 | 0.9688 | 0.9810 | 0.9748 | 0.9455 | 0.9123 | 0.9286 | 1.0000 | 1.0000 | 1.0000 | 0.9664 |
| BC | 411.77, 729.25, 677.54 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Classification Model | Pretreatment | Modeling Band | Complete Grain | Broken Grain | Impurity | Overall Accuracy | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPrecision | RRecall | F1 | RPrecision | RRecall | F1 | RPrecision | RRecal | F1 | ||||
| KNN | BC | 411.77, 729.25, 677.54 | 1.0000 | 0.9873 | 0.9936 | 0.9643 | 1.0000 | 0.9818 | 1.0000 | 1.0000 | 1.0000 | 0.9916 |
| SVM | BC | 411.77, 729.25, 677.54 | 1.0000 | 0.9937 | 0.9968 | 0.9818 | 1.0000 | 0.9908 | 1.0000 | 1.0000 | 1.0000 | 0.9958 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Chang, Z.; Jin, C.; Cheng, G.; Wang, S.; Ni, Y. Classification and Recognition of Soybean Quality Based on Hyperspectral Imaging and Random Forest Methods. Sensors 2025, 25, 1539. https://doi.org/10.3390/s25051539
Chen M, Chang Z, Jin C, Cheng G, Wang S, Ni Y. Classification and Recognition of Soybean Quality Based on Hyperspectral Imaging and Random Forest Methods. Sensors. 2025; 25(5):1539. https://doi.org/10.3390/s25051539
Chicago/Turabian StyleChen, Man, Zhichang Chang, Chengqian Jin, Gong Cheng, Shiguo Wang, and Youliang Ni. 2025. "Classification and Recognition of Soybean Quality Based on Hyperspectral Imaging and Random Forest Methods" Sensors 25, no. 5: 1539. https://doi.org/10.3390/s25051539
APA StyleChen, M., Chang, Z., Jin, C., Cheng, G., Wang, S., & Ni, Y. (2025). Classification and Recognition of Soybean Quality Based on Hyperspectral Imaging and Random Forest Methods. Sensors, 25(5), 1539. https://doi.org/10.3390/s25051539