
Contrastive Mask Learning for Self-Supervised 3D Skeleton-Based Action Recognition

Abstract
1. Introduction
- We propose a novel self-supervised skeleton 3D skeleton action representation learning scheme, the contrastive mask learning (CML) paradigm.
- The mask learning mechanism is introduced into contrastive learning, forming a mutually beneficial learning scheme from both contrastive learning and masked skeleton reconstruction.
- A multi-level contrast paradigm is leveraged to learn both inter-instance and intra-instance consistency of the skeleton action.
2. Related Works
2.1. Self-Supervised Contrastive Learning
2.2. Self-Supervised 3D Action Recognition
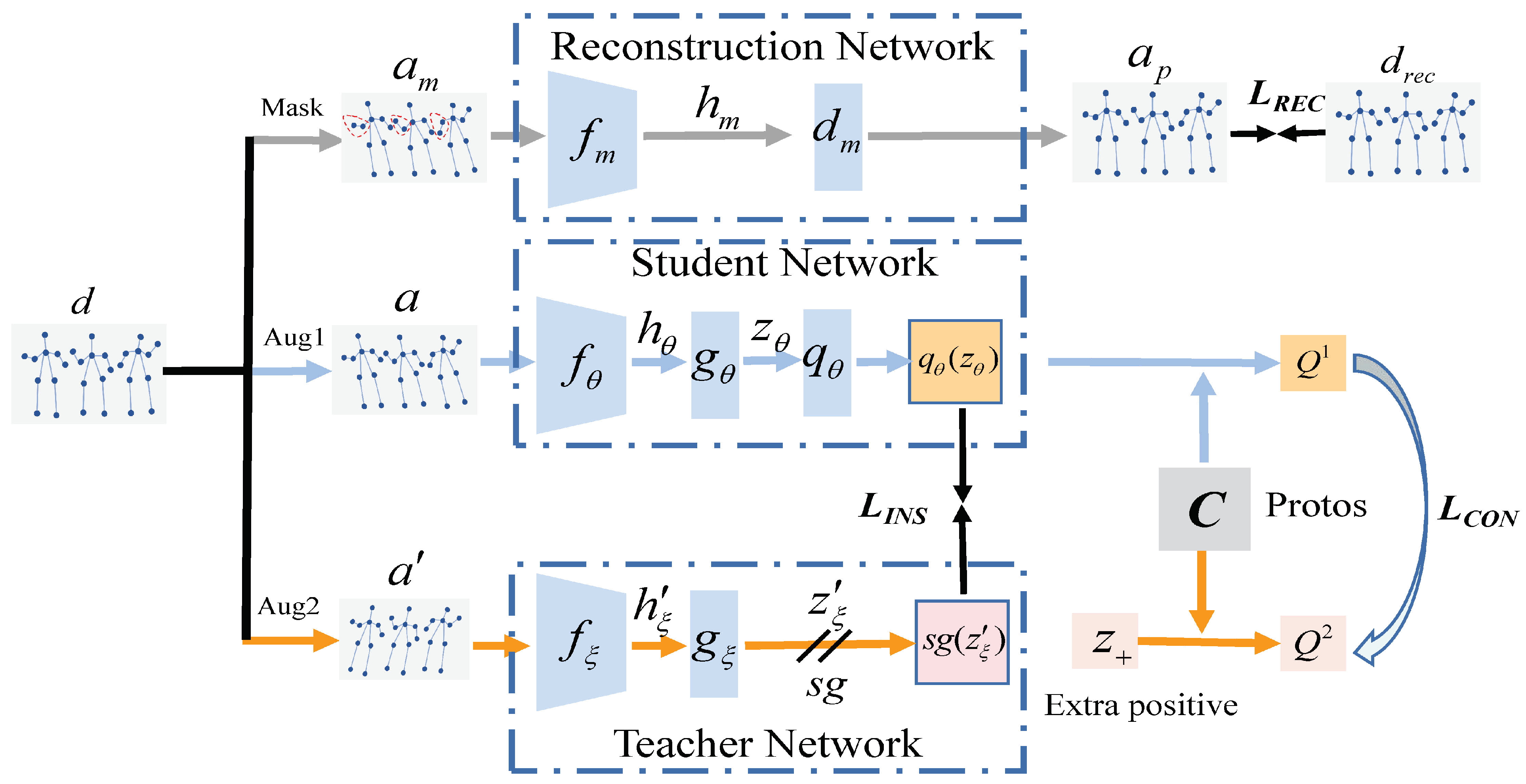
3. Proposed Method
3.1. Basic Framework
3.2. Masked Skeleton Modeling
3.3. Multi-Level Contrast
3.4. Mutual Learning Scheme
4. Results
4.1. Dataset
- Cross-Subject (X-Sub): 40,320 training samples are segregated from 16,560 test samples by distinct performer groups, ensuring subject independence between training and evaluation sets.
- Cross-View (X-View): 37,920 training samples from camera Views 2–3 and 18,960 evaluation samples from View 1 are utilized to test viewpoint generalization capabilities.
- Cross-Subject (X-Sub): 63,026 training samples and 50,919 test samples are employed with strict subject separation.
- Cross-Setup (X-Set): temporal generalization is challenged through setup ID partitioning using 54,468 training samples and 59,477 test samples.
4.2. Implementation Details
4.3. Experimental Results and Analysis
4.4. Ablation Study
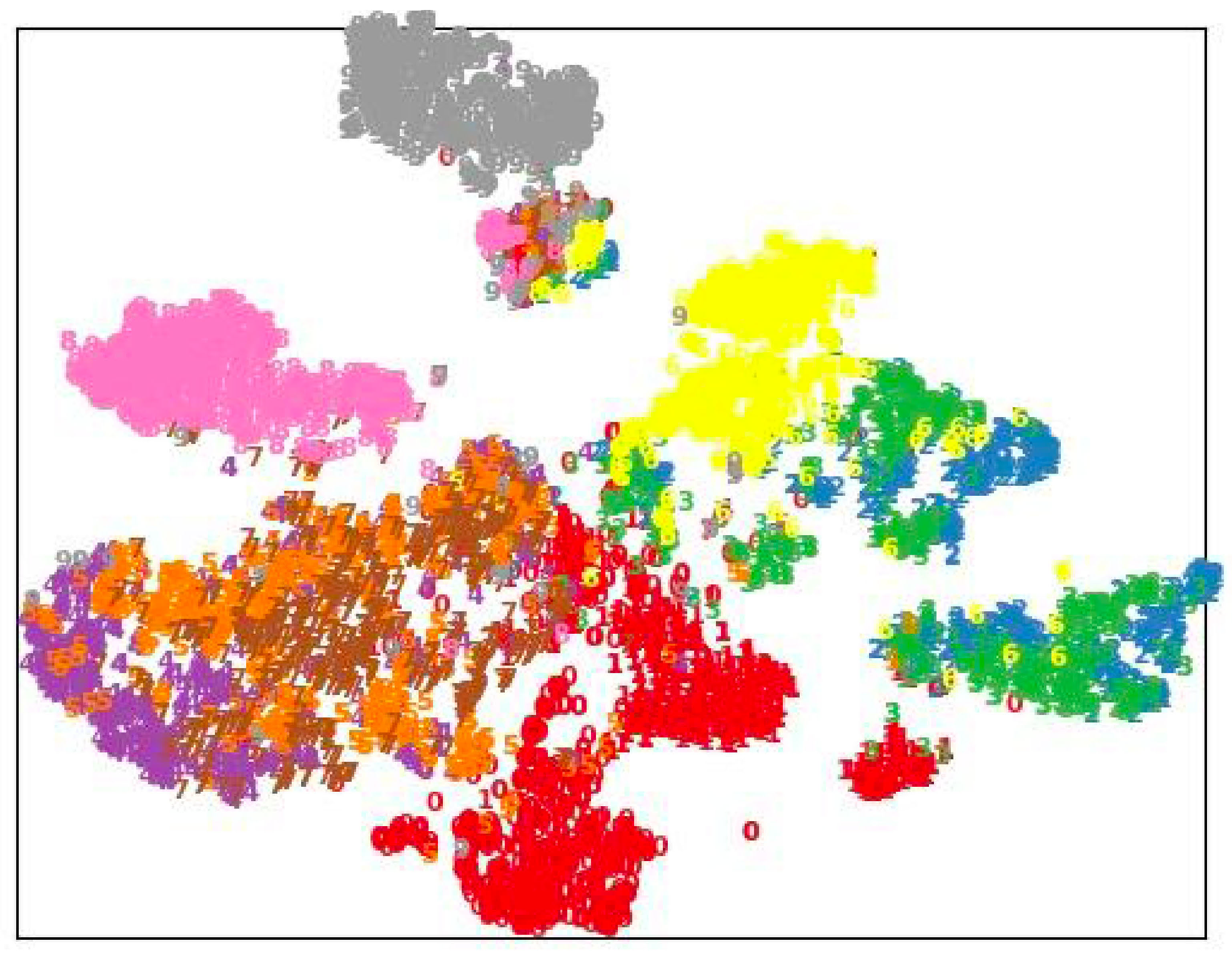
4.5. Visualization Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Berretti, S.; Daoudi, M.; Turaga, P.; Basu, A. Representation, analysis, and recognition of 3D humans: A survey. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 16. [Google Scholar] [CrossRef]
- Singh, T.; Vishwakarma, D.K. A deeply coupled ConvNet for human activity recognition using dynamic and RGB images. Neural Comput. Appl. 2021, 33, 469–485. [Google Scholar] [CrossRef]
- Liu, Z.; Li, Z.; Wang, R.; Zong, M.; Ji, W. Spatiotemporal saliency-based multi-stream networks with attention-aware LSTM for action recognition. Neural Comput. Appl. 2020, 32, 14593–14602. [Google Scholar] [CrossRef]
- Jing, C.; Wei, P.; Sun, H.; Zheng, N. Spatiotemporal neural networks for action recognition based on joint loss. Neural Comput. Appl. 2020, 32, 4293–4302. [Google Scholar] [CrossRef]
- Wang, P.; Li, W.; Gao, Z.; Zhang, Y.; Tang, C.; Ogunbona, P. Scene flow to action map: A new representation for rgb-d based action recognition with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 595–604. [Google Scholar]
- Zheng, N.; Wen, J.; Liu, R.; Long, L.; Dai, J.; Gong, Z. Unsupervised representation learning with long-term dynamics for skeleton based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Lin, L.; Song, S.; Yang, W.; Liu, J. Ms2l: Multi-task self-supervised learning for skeleton based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Virtual Event, 12–16 October 2020; pp. 2490–2498. [Google Scholar]
- Rao, H.; Xu, S.; Hu, X.; Cheng, J.; Hu, B. Augmented skeleton based contrastive action learning with momentum lstm for unsupervised action recognition. Inf. Sci. 2021, 569, 90–109. [Google Scholar] [CrossRef]
- Su, K.; Liu, X.; Shlizerman, E. Predict & cluster: Unsupervised skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9631–9640. [Google Scholar]
- Li, L.; Wang, M.; Ni, B.; Wang, H.; Yang, J.; Zhang, W. 3D Human Action Representation Learning via Cross-View Consistency Pursuit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4741–4750. [Google Scholar]
- Cheng, S.; Zhuang, Y.; Kahouadji, L.; Liu, C.; Chen, J.; Matar, O.K.; Arcucci, R. Multi-domain encoder–decoder neural networks for latent data assimilation in dynamical systems. Comput. Methods Appl. Mech. Eng. 2024, 430, 117201. [Google Scholar] [CrossRef]
- Cheng, S.; Chen, J.; Anastasiou, C.; Angeli, P.; Matar, O.K.; Guo, Y.K.; Pain, C.C.; Arcucci, R. Generalised latent assimilation in heterogeneous reduced spaces with machine learning surrogate models. J. Sci. Comput. 2023, 94, 11. [Google Scholar] [CrossRef]
- Yang, D.; Wang, Y.; Dantcheva, A.; Garattoni, L.; Francesca, G.; Brémond, F. View-invariant Skeleton Action Representation Learning via Motion Retargeting. Int. J. Comput. Vis. 2024, 132, 2351–2366. [Google Scholar] [CrossRef]
- Zhang, H. Attention-guided mask learning for self-supervised 3D action recognition. Complex Intell. Syst. 2024, 10, 7487–7496. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Song, S.; Liu, C.; Li, Y.; Hu, Y. A benchmark dataset and comparison study for multi-modal human action analytics. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–24. [Google Scholar] [CrossRef]
- Gutmann, M.U.; Hyvärinen, A. Noise-Contrastive Estimation of Unnormalized Statistical Models, with Applications to Natural Image Statistics. J. Mach. Learn. Res. 2012, 13, 307–361. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- Luo, Z.; Peng, B.; Huang, D.A.; Alahi, A.; Fei-Fei, L. Unsupervised learning of long-term motion dynamics for videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2203–2212. [Google Scholar]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Unsupervised learning of view-invariant action representations. arXiv 2018, arXiv:1809.01844. [Google Scholar]
- Thoker, F.M.; Doughty, H.; Snoek, C.G. Skeleton-Contrastive 3D Action Representation Learning. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 1655–1663. [Google Scholar]
- Zhang, H.; Hou, Y.; Zhang, W.; Li, W. Contrastive positive mining for unsupervised 3d action representation learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 36–51. [Google Scholar]
- Li, D.; Tang, Y.; Zhang, Z.; Zhang, W. Cross-stream contrastive learning for self-supervised skeleton-based action recognition. Image Vis. Comput. 2023, 135, 104689. [Google Scholar] [CrossRef]
- Dong, J.; Sun, S.; Liu, Z.; Chen, S.; Liu, B.; Wang, X. Hierarchical contrast for unsupervised skeleton-based action representation learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 525–533. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Neural Inf. Process. Syst. 2020, 33, 9912–9924. [Google Scholar]
- Huang, Z.; Jin, X.; Lu, C.; Hou, Q.; Cheng, M.M.; Fu, D.; Shen, X.; Feng, J. Contrastive masked autoencoders are stronger vision learners. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 2506–2517. [Google Scholar] [CrossRef]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- You, Y.; Gitman, I.; Ginsburg, B. Large batch training of convolutional networks. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Caetano, C.; Brémond, F.; Schwartz, W.R. Skeleton image representation for 3d action recognition based on tree structure and reference joints. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–31 October 2019; pp. 16–23. [Google Scholar]
- Zhang, W.; Hou, Y.; Zhang, H. Unsupervised skeleton-based action representation learning via relation consistency pursuit. Neural Comput. Appl. 2022, 34, 20327–20339. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Architecture | NTU-60 (%) | NTU-120 (%) | PKU-MMD (%) | |||
|---|---|---|---|---|---|---|
| X-Sub | X-View | X-Sub | X-Set | Part I | Part II | |
| Supervised | ||||||
| C-CNN + MTLN [37] | 79.6 | 84.8 | - | - | - | - |
| TSRJI [38] | 73.3 | 80.3 | 67.9 | 62.8 | - | - |
| ST-GCN [32] | 81.5 | 88.3 | 70.7 | 73.2 | 84.1 | 48.2 |
| Self-supervised | ||||||
| LongT GAN [6] | 39.1 | 48.1 | - | - | 67.7 | 27.0 |
| ASCAL [8] | 58.5 | 64.8 | 48.6 | 49.2 | - | - |
| MS2L [7] | 52.6 | - | - | - | 64.9 | 27.6 |
| P&C [9] | 50.7 | 76.3 | - | - | - | - |
| ISC [27] | 76.3 | 85.2 | 67.9 | 67.1 | 80.9 | 36.0 |
| CrosSCLR (3S) [10] | 77.8 | 83.4 | 67.9 | 66.7 | 84.9 | - |
| CPM (3S) [39] | 83.2 | 87.0 | 73.0 | 74.0 | 90.7 | 51.5 |
| CSCLR (3S) [29] | 80.1 | 85.2 | 69.2 | 70.2 | 89.3 | 45.1 |
| HiCo [30] | 81.4 | 88.6 | 73.7 | 74.5 | 89.4 | 54.7 |
| ViA [13] | 78.1 | 85.8 | 69.2 | 66.9 | - | - |
| AML(3S) [14] | 84.9 | 89.7 | 75.3 | 77.3 | 93.2 | 58.0 |
| CML (3S) | 86.8 | 91.1 | 77.5 | 78.9 | 93.5 | 58.6 |
| Architecture | Label Fraction (%) | X-Sub (%) | X-View (%) |
|---|---|---|---|
| ISC [27] | 1 | 35.7 | 38.1 |
| SRCL [39] | 1 | 50.7 | 49.7 |
| HiCo [30] | 1 | 54.4 | 54.8 |
| CPM [28] | 1 | 56.7 | 57.5 |
| CSCLR [29] | 1 | 55.4 | 57.1 |
| AML [14] | 1 | 58.9 | 59.7 |
| CML | 1 | 59.1 | 60.2 |
| ISC [27] | 10 | 65.9 | 72.5 |
| SRCL [39] | 10 | 69.3 | 73.6 |
| CPM [28] | 10 | 73.0 | 77.1 |
| HiCo [30] | 10 | 73.0 | 78.3 |
| CSCLR [29] | 10 | 78.6 | 81.8 |
| AML [14] | 10 | 79.0 | 82.3 |
| CML | 10 | 80.1 | 83.4 |
| Architecture | NTU-60 (%) | NTU-120 (%) | ||
|---|---|---|---|---|
| X-Sub | X-View | X-Sub | X-Set | |
| C-CNN + MTLN [37] | 79.6 | 84.8 | - | - |
| TSRJI [38] | 73.3 | 80.3 | 67.9 | 62.8 |
| ST-GCN [32] | 81.5 | 88.3 | 70.7 | 73.2 |
| CML | 87.0 | 93.9 | 79.2 | 79.8 |
| Architecture | X-View (%) |
|---|---|
| CML (w/o. MSL) | 83.4 |
| CML | 87.6 |
| Architecture | X-View (%) |
|---|---|
| CML (w/o. ins) | 77.4 |
| CML (w/o. clu) | 75.8 |
| CML | 83.4 |
| Architecture | X-View (%) |
|---|---|
| CML (w/o. ML) | 80.3 |
| CML | 83.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H. Contrastive Mask Learning for Self-Supervised 3D Skeleton-Based Action Recognition. Sensors 2025, 25, 1521. https://doi.org/10.3390/s25051521
Zhang H. Contrastive Mask Learning for Self-Supervised 3D Skeleton-Based Action Recognition. Sensors. 2025; 25(5):1521. https://doi.org/10.3390/s25051521
Chicago/Turabian StyleZhang, Haoyuan. 2025. "Contrastive Mask Learning for Self-Supervised 3D Skeleton-Based Action Recognition" Sensors 25, no. 5: 1521. https://doi.org/10.3390/s25051521
APA StyleZhang, H. (2025). Contrastive Mask Learning for Self-Supervised 3D Skeleton-Based Action Recognition. Sensors, 25(5), 1521. https://doi.org/10.3390/s25051521