



DQRNet: Dynamic Quality Refinement Network for 3D Reconstruction from a Single Depth View

Abstract
1. Introduction
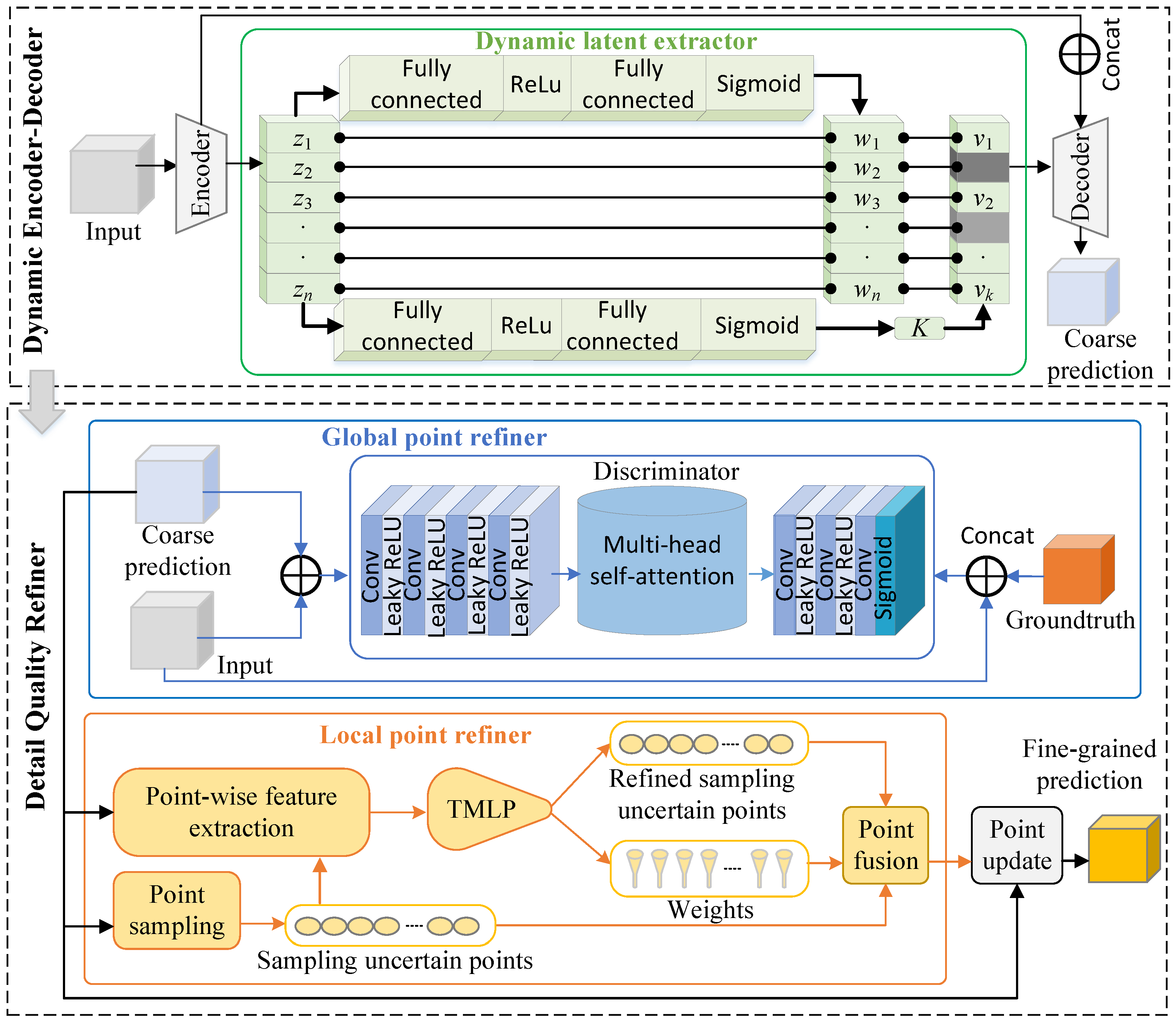
- DQRNet introduces a dynamic encoder–decoder, which adopts a dynamic latent extractor to select the most valuable latent information. This can reduce noise and enhance robustness.
- DQRNet introduces a detail quality refiner to enhance the predictions, which consists of global point refiner and local point refiner. The global refiner employs a discriminator based on multi-head self-attention to update global information. The local refiner combines the pre- and post-judgments by weighted fusion, which helps to refine the details at the boundaries.
- DQRNet improves the average IoU by 2.09% and average CE by 2.88% on the ShapeNet dataset.
2. Related Work
3. DQRNet
3.1. Overview
3.2. Dynamic Encoder–Decoder
3.2.1. Encoder–Decoder
3.2.2. Dynamic Latent Extractor
| Algorithm 1: Dynamic latent extractor |
| Input : Latent vector from the encoder Output: Latent vector //Step 1: Predict the weights 1 Initialization: 2 //Step 2: Predict a threshold to retain the top k latent features 3 //Step 3: Generate binary masks by retaining the top k dimensions 4 //Obtain the kth value among the top k values in the descending sorted 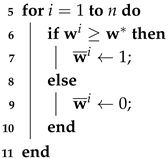 //Step 4: Refine the latent vector by element-wise multiplication 12 by Equation (2) //Preserve the original positional mapping 13 return |
3.3. Detail Quality Refiner
3.3.1. Global Point Refiner
3.3.2. Local Point Refiner
| Algorithm 2: Local point refiner |
 |
4. Loss Function
5. Experimental Results
5.1. Dataset
5.2. Experimental Setup
5.3. Metrics
5.4. Comparisons with State-of-the-Art Methods
5.5. Ablation Study
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Q.; Su, H.; Duanmu, Z.; Liu, W.; Wang, Z. Perceptual Quality Assessment of Colored 3D Point Clouds. IEEE Trans. Vis. Comput. Graph. 2023, 29, 3642–3655. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 722–739. [Google Scholar] [CrossRef]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12786–12796. [Google Scholar]
- Ye, S.; Chen, D.; Han, S.; Wan, Z.; Liao, J. Meta-PU: An Arbitrary-Scale Upsampling Network for Point Cloud. IEEE Trans. Vis. Comput. Graph. 2022, 28, 3206–3218. [Google Scholar] [CrossRef]
- Lei, N.; Li, Z.; Xu, Z.; Li, Y.; Gu, X. What’s the Situation with Intelligent Mesh Generation: A Survey and Perspectives. IEEE Trans. Vis. Comput. Graph. 2023, 30, 4997–5017. [Google Scholar] [CrossRef]
- Zhang, L.; Li, H.; Liu, R.; Wang, X.; Wu, X. Quality guided metric learning for domain adaptation person re-identification. IEEE Trans. Consum. Electron. 2024, 70, 6023–6030. [Google Scholar] [CrossRef]
- Yi, X.; Deng, J.; Sun, Q.; Hua, X.S.; Lim, J.H.; Zhang, H. Invariant Training 2D-3D Joint Hard Samples for Few-Shot Point Cloud Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 14463–14474. [Google Scholar]
- Zeng, G.; Li, H.; Wang, X.; Li, N. Point cloud up-sampling network with multi-level spatial local feature aggregation. Comput. Electr. Eng. 2021, 94, 107337. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Li, N. MeshLink: A surface structured mesh generation framework to facilitate automated data linkage. Adv. Eng. Softw. 2024, 194, 103661. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Wu, X.; Li, N. MTGNet: Multi-label mesh quality evaluation using topology-guided graph neural network. Eng. Comput. 2024, 1–13. [Google Scholar] [CrossRef]
- Alhamazani, F.; Lai, Y.K.; Rosin, P.L. 3DCascade-GAN: Shape completion from single-view depth images. Comput. Graph. 2023, 115, 412–422. [Google Scholar] [CrossRef]
- Zheng, Y.; Zeng, G.; Li, H.; Cai, Q.; Du, J. Colorful 3D reconstruction at high resolution using multi-view representation. J. Vis. Commun. Image Represent. 2022, 85, 103486. [Google Scholar] [CrossRef]
- Liu, C.; Kong, D.; Wang, S.; Li, J.; Yin, B. A Spatial Relationship Preserving Adversarial Network for 3D Reconstruction from a Single Depth View. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 110. [Google Scholar] [CrossRef]
- Li, H.; Zheng, Y.; Cao, J.; Cai, Q. Multi-view-based siamese convolutional neural network for 3D object retrieval. Comput. Electr. Eng. 2019, 78, 11–21. [Google Scholar] [CrossRef]
- Li, H.; Sun, L.; Dong, S.; Zhu, X.; Cai, Q.; Du, J. Efficient 3d object retrieval based on compact views and hamming embedding. IEEE Access 2018, 6, 31854–31861. [Google Scholar] [CrossRef]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. Acm Trans. Graph. (ToG) 2013, 32, 1–13. [Google Scholar] [CrossRef]
- Dai, A.; Ruizhongtai Qi, C.; Niessner, M. Shape Completion Using 3D-Encoder-Predictor CNNs and Shape Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5868–5877. [Google Scholar]
- Li, H.; Zhao, T.; Li, N.; Cai, Q.; Du, J. Feature Matching of Multi-view 3D Models Based on Hash Binary Encoding. Neural Netw. World 2017, 27, 95–105. [Google Scholar] [CrossRef]
- Mittal, P.; Cheng, Y.C.; Singh, M.; Tulsiani, S. AutoSDF: Shape Priors for 3D Completion, Reconstruction and Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 306–315. [Google Scholar]
- Rao, Y.; Nie, Y.; Dai, A. PatchComplete: Learning Multi-Resolution Patch Priors for 3D Shape Completion on Unseen Categories. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 34436–34450. [Google Scholar]
- Xu, M.; Wang, Y.; Liu, Y.; He, T.; Qiao, Y. CP3: Unifying Point Cloud Completion by Pretrain-Prompt-Predict Paradigm. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9583–9594. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Liu, Y.S.; Gao, Y.; Shi, K.; Fang, Y.; Han, Z. LP-DIF: Learning Local Pattern-Specific Deep Implicit Function for 3D Objects and Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 21856–21865. [Google Scholar]
- Wu, Y.; Yan, Z.; Chen, C.; Wei, L.; Li, X.; Li, G.; Li, Y.; Cui, S.; Han, X. SCoDA: Domain Adaptive Shape Completion for Real Scans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 17630–17641. [Google Scholar]
- Yang, B.; Rosa, S.; Markham, A.; Trigoni, N.; Wen, H. Dense 3D Object Reconstruction from a Single Depth View. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2820–2834. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Wu, X.; Li, N. Surface Structured Quadrilateral Mesh Generation Based on Topology Consistent-Preserved Patch Segmentation. Int. J. Numer. Methods Eng. 2025, 126, e7644. [Google Scholar] [CrossRef]
- Kanazawa, A.; Tulsiani, S.; Efros, A.A.; Malik, J. Learning Category-Specific Mesh Reconstruction from Image Collections. In Proceedings of the European Conferenceon Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 386–402. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the European Conferenceon Computer Vision (European Conferenceon Computer Vision (ECCV)), Tel Aviv, Israel, 23–27 October 2022; pp. 55–71. [Google Scholar]
- Xu, Q.; Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A Point Set Generation Network for 3D Object Reconstruction From a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Navaneet, K.L.; Mathew, A.; Kashyap, S.; Hung, W.C.; Jampani, V.; Babu, R.V. From Image Collections to Point Clouds With Self-Supervised Shape and Pose Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1132–1140. [Google Scholar]
- Wu, C.Y.; Johnson, J.; Malik, J.; Feichtenhofer, C.; Gkioxari, G. Multiview Compressive Coding for 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 9065–9075. [Google Scholar]
- Lin, C.H.; Wang, C.; Lucey, S. SDF-SRN: Learning Signed Distance 3D Object Reconstruction from Static Images. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 11453–11464. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 4460–4470. [Google Scholar]
- Alwala, K.V.; Gupta, A.; Tulsiani, S. Pre-Train, Self-Train, Distill: A Simple Recipe for Supersizing 3D Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 3773–3782. [Google Scholar]
- Jia, D.; Ruan, X.; Xia, K.; Zou, Z.; Wang, L.; Tang, W. Analysis-by-Synthesis Transformer for Single-View 3D Reconstruction. In Proceedings of the European Conferenceon Computer Vision (ECCV), Milan, Italy, 29 Septembe –4 October 2024; pp. 259–277. [Google Scholar]
- Lee, J.J.; Benes, B. RGB2Point: 3D Point Cloud Generation from Single RGB Images. arXiv 2024, arXiv:2407.14979. [Google Scholar]
- Han, X.; Li, Z.; Huang, H.; Kalogerakis, E.; Yu, Y. High-resolution shape completion using deep neural networks for global structure and local geometry inference. In Proceedings of the IEEE International Conference on Computer vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 85–93. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic Scene Completion From a Single Depth Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1746–1754. [Google Scholar]
- Wang, W.; Huang, Q.; You, S.; Yang, C.; Neumann, U. Shape inpainting using 3D generative adversarial network and recurrent convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2298–2306. [Google Scholar]
- Liu, C.; Kong, D.; Wang, S.; Li, J.; Yin, B. Latent Feature-Aware and Local Structure-Preserving Network for 3D Completion from a Single Depth View. In Proceedings of the Artificial Neural Networks and Machine Learning, Bratislava, Slovakia, 14–17 September 2021; pp. 67–79. [Google Scholar]
- Zhao, M.; Xiong, G.; Zhou, M.; Shen, Z.; Wang, F.Y. 3D-RVP: A method for 3D object reconstruction from a single depth view using voxel and point. Neurocomputing 2021, 430, 94–103. [Google Scholar] [CrossRef]
- Aboukhadra, A.T.; Malik, J.; Robertini, N.; Elhayek, A.; Stricker, D. ShapeGraFormer: GraFormer-Based Network for Hand-Object Reconstruction from a Single Depth Map. arXiv 2023, arXiv:2310.11811. [Google Scholar] [CrossRef]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3d point clouds. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Zheng, X.; Liu, Y.; Wang, P.; Tong, X. SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation. Comput. Graph. Forum 2022, 41, 52–63. [Google Scholar] [CrossRef]
- Li, H.; Zheng, Y.; Wu, X.; Cai, Q. 3D model generation and reconstruction using conditional generative adversarial network. Int. J. Comput. Intell. Syst. 2019, 12, 697–705. [Google Scholar] [CrossRef]
- Liu, C.; Chen, Y.; Zhu, M.; Hao, C.; Li, H.; Wang, X. DEGAN: Detail-Enhanced Generative Adversarial Network for Monocular Depth-Based 3D Reconstruction. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 365. [Google Scholar] [CrossRef]
- Gao, L.; Wu, T.; Yuan, Y.J.; Lin, M.X.; Lai, Y.K.; Zhang, H. TM-NET: Deep generative networks for textured meshes. Acm Trans. Graph. (ToG) 2021, 40, 263. [Google Scholar] [CrossRef]
- Kim, J.; Yoo, J.; Lee, J.; Hong, S. SetVAE: Learning Hierarchical Composition for Generative Modeling of Set-Structured Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15059–15068. [Google Scholar]
- Tan, Q.; Gao, L.; Lai, Y.K.; Xia, S. Variational Autoencoders for Deforming 3D Mesh Models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5841–5850. [Google Scholar]
- Yang, G.; Huang, X.; Hao, Z.; Liu, M.Y.; Belongie, S.; Hariharan, B. Pointflow: 3d point cloud generation with continuous normalizing flows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4541–4550. [Google Scholar]
- Sun, Y.; Wang, Y.; Liu, Z.; Siegel, J.; Sarma, S.E. PointGrow: Autoregressively Learned Point Cloud Generation with Self-Attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Village, CO, USA, 1–5 March 2020; pp. 61–70. [Google Scholar]
- Xie, J.; Xu, Y.; Zheng, Z.; Zhu, S.C.; Wu, Y.N. Generative pointnet: Deep energy-based learning on unordered point sets for 3D generation, reconstruction and classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14976–14985. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Luo, S.; Hu, W. Diffusion Probabilistic Models for 3D Point Cloud Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2837–2845. [Google Scholar]
- Zheng, X.Y.; Pan, H.; Wang, P.S.; Tong, X.; Liu, Y.; Shum, H.Y. Locally attentional sdf diffusion for controllable 3d shape generation. Acm Trans. Graph. (ToG) 2023, 42, 1–13. [Google Scholar] [CrossRef]
- Cheng, Y.C.; Lee, H.Y.; Tulyakov, S.; Schwing, A.G.; Gui, L.Y. SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 4456–4465. [Google Scholar]
- Li, Y.; Dou, Y.; Chen, X.; Ni, B.; Sun, Y.; Liu, Y.; Wang, F. Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 16784–16794. [Google Scholar]
- Vahdat, A.; Williams, F.; Gojcic, Z.; Litany, O.; Fidler, S.; Kreis, K. Lion: Latent point diffusion models for 3D shape generation. Adv. Neural Inf. Process. Syst. 2022, 35, 10021–10039. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. ICLR (Poster) 2015, 5. [Google Scholar]
- Varley, J.; DeChant, C.; Richardson, A.; Ruales, J.; Allen, P. Shape completion enabled robotic grasping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2442–2447. [Google Scholar]
- Zhou, H.; Cao, Y.; Chu, W.; Zhu, J.; Lu, T.; Tai, Y.; Wang, C. SeedFormer: Patch Seeds Based Point Cloud Completion with Upsample Transformer. In Proceedings of the European Conferenceon Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 416–432. [Google Scholar]
- Xiang, P.; Wen, X.; Liu, Y.S.; Cao, Y.P.; Wan, P.; Zheng, W.; Han, Z. Snowflake Point Deconvolution for Point Cloud Completion and Generation with Skip-Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6320–6338. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | IoU ↑ | CE ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| Bench | Chair | Couch | Table | Bench | Chair | Couch | Table | |
| 3D-EPN [17] | 0.423 | 0.488 | 0.631 | 0.508 | 0.087 | 0.105 | 0.144 | 0.101 |
| Varley [62] | 0.227 | 0.317 | 0.544 | 0.233 | 0.111 | 0.157 | 0.195 | 0.191 |
| SeedFormer [63] | 0.553 | 0.618 | 0.740 | 0.656 | 0.038 | 0.065 | 0.069 | 0.044 |
| SnowflakeNet [64] | 0.562 | 0.631 | 0.745 | 0.659 | 0.037 | 0.063 | 0.068 | 0.043 |
| 3D-RecGAN++ [24] | 0.580 | 0.647 | 0.753 | 0.679 | 0.034 | 0.060 | 0.066 | 0.040 |
| 3D-RVP [41] | 0.598 | 0.668 | 0.760 | 0.696 | 0.032 | 0.060 | 0.067 | 0.039 |
| DQRNet | 0.613 | 0.672 | 0.765 | 0.705 | 0.030 | 0.055 | 0.066 | 0.038 |
| Methods | IoU ↑ | CE ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| Bench | Chair | Couch | Table | Bench | Chair | Couch | Table | |
| 3D-EPN [17] | 0.408 | 0.446 | 0.572 | 0.482 | 0.086 | 0.112 | 0.163 | 0.103 |
| Varley [62] | 0.185 | 0.278 | 0.475 | 0.187 | 0.108 | 0.171 | 0.210 | 0.186 |
| SeedFormer [63] | 0.508 | 0.578 | 0.628 | 0.603 | 0.046 | 0.080 | 0.120 | 0.056 |
| SnowflakeNet [64] | 0.518 | 0.589 | 0.637 | 0.623 | 0.045 | 0.079 | 0.118 | 0.055 |
| 3D-RecGAN++ [24] | 0.531 | 0.594 | 0.646 | 0.618 | 0.041 | 0.074 | 0.111 | 0.053 |
| 3D-RVP [41] | 0.554 | 0.621 | 0.643 | 0.656 | 0.037 | 0.074 | 0.138 | 0.047 |
| DQRNet | 0.575 | 0.630 | 0.655 | 0.668 | 0.036 | 0.068 | 0.124 | 0.044 |
| Methods | IoU ↑ | CE ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| Bench | Chair | Couch | Table | Bench | Chair | Couch | Table | |
| 3D-EPN [17] | 0.428 | 0.484 | 0.634 | 0.506 | 0.087 | 0.107 | 0.138 | 0.102 |
| Varley [62] | 0.234 | 0.317 | 0.543 | 0.236 | 0.103 | 0.132 | 0.197 | 0.170 |
| SeedFormer [63] | 0.542 | 0.613 | 0.727 | 0.628 | 0.036 | 0.054 | 0.066 | 0.045 |
| SnowflakeNet [64] | 0.548 | 0.624 | 0.736 | 0.633 | 0.035 | 0.053 | 0.064 | 0.043 |
| 3D-RecGAN++ [24] | 0.581 | 0.640 | 0.745 | 0.667 | 0.030 | 0.051 | 0.063 | 0.039 |
| 3D-RVP [41] | 0.596 | 0.655 | 0.750 | 0.687 | 0.029 | 0.050 | 0.062 | 0.035 |
| DQRNet | 0.613 | 0.667 | 0.755 | 0.699 | 0.028 | 0.050 | 0.063 | 0.037 |
| Methods | IoU ↑ | CE ↓ | ||||||
|---|---|---|---|---|---|---|---|---|
| Bench | Chair | Couch | Table | Bench | Chair | Couch | Table | |
| 3D-EPN [17] | 0.415 | 0.452 | 0.531 | 4.477 | 0.091 | 0.115 | 0.147 | 0.111 |
| Varley [62] | 0.201 | 0.283 | 0.480 | 0.199 | 0.105 | 0.143 | 0.207 | 0.174 |
| SeedFormer [63] | 0.532 | 0.583 | 0.629 | 0.609 | 0.040 | 0.069 | 0.097 | 0.052 |
| SnowflakeNet [64] | 0.534 | 0.586 | 0.631 | 0.612 | 0.039 | 0.068 | 0.095 | 0.050 |
| 3D-RecGAN++ [24] | 0.540 | 0.594 | 0.643 | 0.621 | 0.038 | 0.061 | 0.091 | 0.048 |
| 3D-RVP [41] | 0.545 | 0.617 | 0.661 | 0.643 | 0.035 | 0.058 | 0.093 | 0.043 |
| DQRNet | 0.574 | 0.632 | 0.671 | 0.662 | 0.034 | 0.058 | 0.092 | 0.043 |
| DLE | LPR | GPR | IoU ↑ | CE ↓ |
|---|---|---|---|---|
| × | × | × | 0.580 | 0.034 |
| ✓ | × | × | 0.593 | 0.032 |
| ✓ | ✓ | × | 0.605 | 0.030 |
| ✓ | × | ✓ | 0.596 | 0.031 |
| ✓ | ✓ | ✓ | 0.613 | 0.030 |
| u | e > 0.8 | e > 0.9 | ||
|---|---|---|---|---|
| IoU ↑ | CE ↓ | IoU ↑ | CE ↓ | |
| 0.20 | 0.613 | 0.032 | 0.613 | 0.030 |
| 0.25 | 0.614 | 0.032 | 0.613 | 0.030 |
| 0.30 | 0.613 | 0.033 | 0.614 | 0.031 |
| 0.35 | 0.608 | 0.034 | 0.613 | 0.031 |
| 0.40 | 0.599 | 0.035 | 0.612 | 0.031 |
| u | Bench | Chair | Couch | Table |
|---|---|---|---|---|
| 0.20 | 0.612 | 0.664 | 0.753 | 0.694 |
| 0.25 | 0.613 | 0.666 | 0.754 | 0.697 |
| 0.30 | 0.613 | 0.667 | 0.755 | 0.699 |
| 0.35 | 0.612 | 0.666 | 0.755 | 0.699 |
| 0.40 | 0.610 | 0.663 | 0.755 | 0.698 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Zhu, M.; Li, H.; Wei, X.; Liang, J.; Yao, Q. DQRNet: Dynamic Quality Refinement Network for 3D Reconstruction from a Single Depth View. Sensors 2025, 25, 1503. https://doi.org/10.3390/s25051503
Liu C, Zhu M, Li H, Wei X, Liang J, Yao Q. DQRNet: Dynamic Quality Refinement Network for 3D Reconstruction from a Single Depth View. Sensors. 2025; 25(5):1503. https://doi.org/10.3390/s25051503
Chicago/Turabian StyleLiu, Caixia, Minhong Zhu, Haisheng Li, Xiulan Wei, Jiulin Liang, and Qianwen Yao. 2025. "DQRNet: Dynamic Quality Refinement Network for 3D Reconstruction from a Single Depth View" Sensors 25, no. 5: 1503. https://doi.org/10.3390/s25051503
APA StyleLiu, C., Zhu, M., Li, H., Wei, X., Liang, J., & Yao, Q. (2025). DQRNet: Dynamic Quality Refinement Network for 3D Reconstruction from a Single Depth View. Sensors, 25(5), 1503. https://doi.org/10.3390/s25051503