
DCAN: Dynamic Channel Attention Network for Multi-Scale Distortion Correction



Abstract
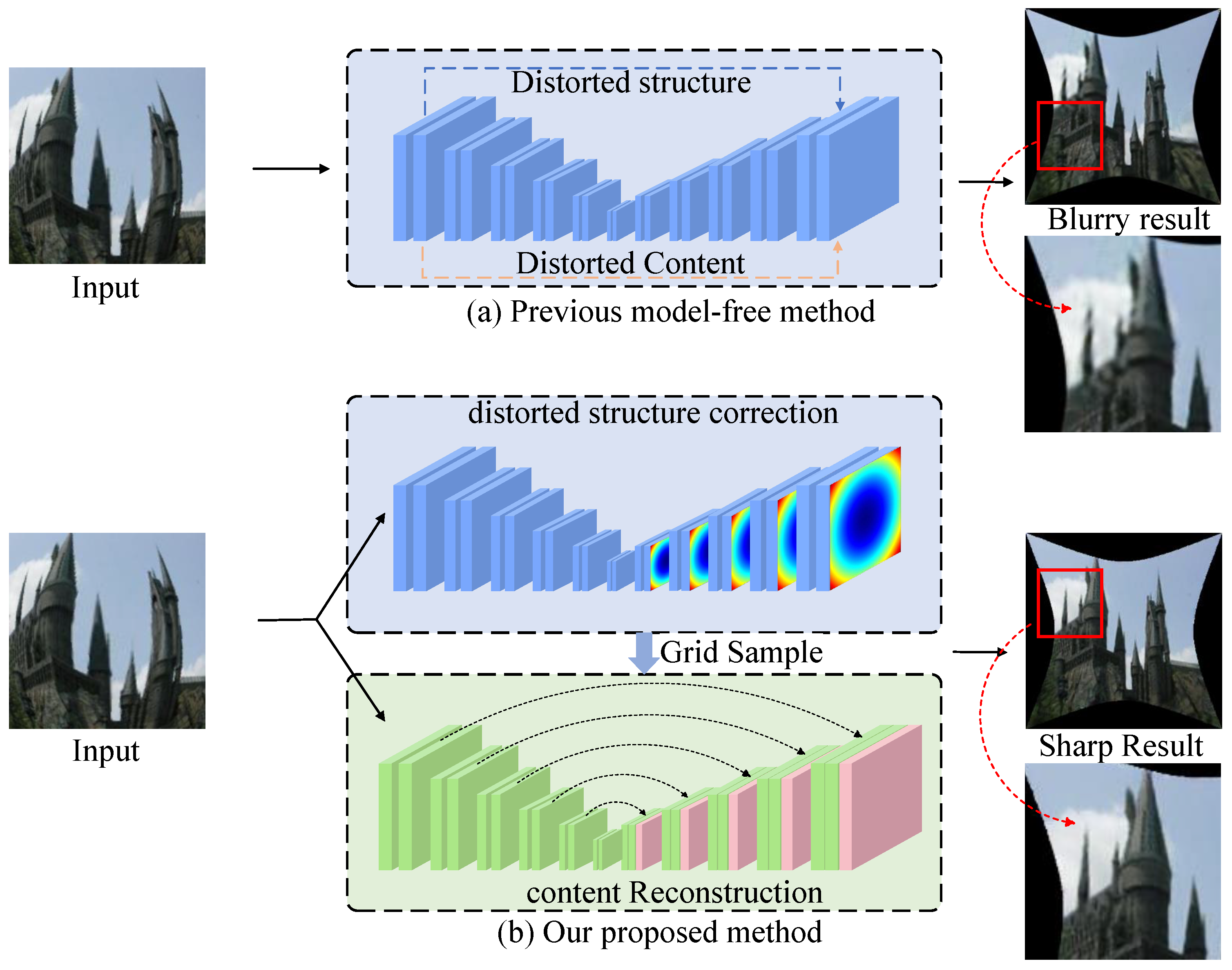
1. Introduction
- We propose the dynamic channel attention network (DCAN), which leverages a multi-path progressive complementary mechanism to effectively address the challenge of balancing global structural consistency and local detail preservation under varying distortion levels.
- We introduce the channel attention and fusion selective module (CAFSM), which dynamically prioritizes critical features and integrates multi-scale information, enhancing adaptability and feature representation of the network.
- We design a comprehensive loss function incorporating structural similarity loss (SSIM Loss) to ensure fine detail preservation and structural consistency, improving visual fidelity in the corrected images.
2. Related Work
2.1. GAN-Based Distortion Correction Methods
2.2. Attention-Based Distortion Correction Methods
2.3. Integration of Channel Attention and Fusion Selective
3. Proposed Method
3.1. Flow Network
3.2. Resample Network
3.3. Correction Module
3.4. Training and Loss Function
4. Experimental Procedure and Results
4.1. Comparison Results
4.2. Ablation Study
5. Conclusions
Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar] [CrossRef]
- Eichenseer, A.; Bätz, M.; Kaup, A. Motion estimation for fisheye video with an application to temporal resolution enhancement. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2376–2390. [Google Scholar] [CrossRef]
- Abu Alhaija, H.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2018, 126, 961–972. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Wei, X.; Zhou, M.; Jia, W. 360° Streaming. IEEE Trans. Ind. Inform. 2022, 19, 6326–6336. [Google Scholar] [CrossRef]
- Lin, H.S.; Chang, C.C.; Chang, H.Y.; Chuang, Y.Y.; Lin, T.L.; Ouhyoung, M. A low-cost portable polycamera for stereoscopic 360 imaging. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 915–929. [Google Scholar] [CrossRef]
- Courbon, J.; Mezouar, Y.; Eckt, L.; Martinet, P. A generic fisheye camera model for robotic applications. In Proceedings of the 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 1683–1688. [Google Scholar]
- Courbon, J.; Mezouar, Y.; Martinet, P. Evaluation of the unified model of the sphere for fisheye cameras in robotic applications. Adv. Robot. 2012, 26, 947–967. [Google Scholar] [CrossRef]
- Zhang, Y.; You, S.; Gevers, T. Automatic calibration of the fisheye camera for egocentric 3D human pose estimation from a single image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 1772–1781. [Google Scholar]
- Aso, K.; Hwang, D.H.; Koike, H. Portable 3D human pose estimation for human-human interaction using a chest-mounted fisheye camera. In Proceedings of the Augmented Humans International Conference 2021, Rovaniemi, Finland, 22–24 February 2021; pp. 116–120. [Google Scholar]
- Xie, C.; Luo, J.; Li, K.; Yan, Z.; Li, F.; Jia, X.; Wang, Y. Image-Based Bolt-Loosening Detection Using a Checkerboard Perspective Correction Method. Sensors 2024, 24, 3271. [Google Scholar] [CrossRef] [PubMed]
- Blott, G.; Takami, M.; Heipke, C. Semantic segmentation of fisheye images. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 1–15. [Google Scholar]
- Deng, L.; Yang, M.; Qian, Y.; Wang, C.; Wang, B. CNN based semantic segmentation for urban traffic scenes using fisheye camera. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 231–236. [Google Scholar]
- Kumar, V.R.; Klingner, M.; Yogamani, S.; Milz, S.; Fingscheidt, T.; Mader, P. Syndistnet: Self-supervised monocular fisheye camera distance estimation synergized with semantic segmentation for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 61–71. [Google Scholar]
- Joseph, K.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards open world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5830–5840. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Julia, A.; Iguernaissi, R.; Michel, F.J.; Matarazzo, V.; Merad, D. Distortion Correction and Denoising of Light Sheet Fluorescence Images. Sensors 2024, 24, 2053. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Toepfer, C.; Ehlgen, T. A unifying omnidirectional camera model and its applications. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–5. [Google Scholar]
- Yin, W.; Zang, X.; Wu, L.; Zhang, X.; Zhao, J. A Distortion Correction Method Based on Actual Camera Imaging Principles. Sensors 2024, 24, 2406. [Google Scholar] [CrossRef] [PubMed]
- Barreto, J.P.; Daniilidis, K. Fundamental matrix for cameras with radial distortion. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–20 October 2005; Volume 1, pp. 625–632. [Google Scholar]
- Geiger, A.; Moosmann, F.; Car, Ö.; Schuster, B. Automatic camera and range sensor calibration using a single shot. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 3936–3943. [Google Scholar]
- Thormählen, T.; Broszio, H.; Wassermann, I. Robust line-based calibration of lens distortion from a single view. In Proceedings of the Mirage 2003, Rocquencourt, France, 10–12 March 2003; pp. 105–112. [Google Scholar]
- Wang, A.; Qiu, T.; Shao, L. A simple method of radial distortion correction with centre of distortion estimation. J. Math. Imaging Vis. 2009, 35, 165–172. [Google Scholar] [CrossRef]
- Bukhari, F.; Dailey, M.N. Automatic radial distortion estimation from a single image. J. Math. Imaging Vis. 2013, 45, 31–45. [Google Scholar] [CrossRef]
- Rong, J.; Huang, S.; Shang, Z.; Ying, X. Radial lens distortion correction using convolutional neural networks trained with synthesized images. In Proceedings of the Computer Vision—ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part III 13. Springer: Berlin/Heidelberg, Germany, 2017; pp. 35–49. [Google Scholar]
- Bogdan, O.; Eckstein, V.; Rameau, F.; Bazin, J.C. DeepCalib: A deep learning approach for automatic intrinsic calibration of wide field-of-view cameras. In Proceedings of the 15th ACM SIGGRAPH European Conference on Visual Media Production, London, UK, 13–14 December 2018; pp. 1–10. [Google Scholar]
- Yin, X.; Wang, X.; Yu, J.; Zhang, M.; Fua, P.; Tao, D. Fisheyerecnet: A multi-context collaborative deep network for fisheye image rectification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 469–484. [Google Scholar]
- Liao, K.; Lin, C.; Liao, L.; Zhao, Y.; Lin, W. Multi-level curriculum for training a distortion-aware barrel distortion rectification model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4389–4398. [Google Scholar]
- Yang, S.; Lin, C.; Liao, K.; Zhao, Y. Dual diffusion architecture for fisheye image rectification: Synthetic-to-real generalization. arXiv 2023, arXiv:2301.11785. [Google Scholar]
- Xu, H.; Yuan, J.; Ma, J. Murf: Mutually reinforcing multi-modal image registration and fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12148–12166. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Feng, H.; Zhou, W.; Liao, Z.; Li, H. Model-aware pre-training for radial distortion rectification. IEEE Trans. Image Process. 2023, 32, 5764–5778. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, B.; Sander, P.V.; Liao, J. Blind geometric distortion correction on images through deep learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4855–4864. [Google Scholar]
- Liao, K.; Lin, C.; Zhao, Y.; Gabbouj, M. DR-GAN: Automatic radial distortion rectification using conditional GAN in real-time. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 725–733. [Google Scholar] [CrossRef]
- Chao, C.H.; Hsu, P.L.; Lee, H.Y.; Wang, Y.C.F. Self-supervised deep learning for fisheye image rectification. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2248–2252. [Google Scholar]
- Yang, S.; Lin, C.; Liao, K.; Zhang, C.; Zhao, Y. Progressively complementary network for fisheye image rectification using appearance flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6348–6357. [Google Scholar]
- Guo, P.; Liu, C.; Hou, X.; Qian, X. QueryCDR: Query-based Controllable Distortion Rectification Network for Fisheye Images. In Computer Vision—ECCV 2024, Proceedings of the 18th European Conference, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024. [Google Scholar]
- Feng, H.; Wang, W.; Deng, J.; Zhou, W.; Li, L.; Li, H. Simfir: A simple framework for fisheye image rectification with self-supervised representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 12418–12427. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Advances in Neural Information Processing Systems, Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Curran Associates Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | PSNR ↑ | ||||||
| Avg | |||||||
| SimFIR [39] | 22.58 | 22.32 | 21.84 | 21.75 | 21.71 | 21.68 | 21.98 |
| DeepCalib [28] | 19.73 | 18.68 | 19.33 | 19.81 | 19.76 | 19.72 | 19.51 |
| DR-GAN [35] | 17.41 | 17.12 | 16.96 | 16.77 | 16.90 | 16.86 | 17.00 |
| PCN [37] | 22.48 | 22.32 | 21.88 | 21.59 | 21.73 | 21.71 | 21.95 |
| QueryCDR [38] | 23.32 | 22.96 | 22.87 | 22.79 | 22.95 | 22.86 | 22.96 |
| DCAN | 24.64 | 24.58 | 24.43 | 24.47 | 24.52 | 24.41 | 24.51 |
| Methods | SSIM↑ | ||||||
| Avg | |||||||
| SimFIR [39] | 0.8735 | 0.8562 | 0.8411 | 0.8331 | 0.8325 | 0.8319 | 0.8447 |
| DeepCalib [28] | 0.8102 | 0.7285 | 0.7132 | 0.7565 | 0.7553 | 0.7541 | 0.7530 |
| DR-GAN [35] | 0.6996 | 0.6514 | 0.6389 | 0.6278 | 0.6331 | 0.6322 | 0.6472 |
| PCN [37] | 0.8837 | 0.8588 | 0.8496 | 0.8511 | 0.8552 | 0.8538 | 0.8587 |
| QueryCDR [38] | 0.8896 | 0.8312 | 0.7997 | 0.7983 | 0.7881 | 0.7895 | 0.8161 |
| DCAN | 0.9199 | 0.9159 | 0.9191 | 0.9195 | 0.9189 | 0.9186 | 0.9187 |
| Methods | FID↓ | ||||||
| Avg | |||||||
| SimFIR [39] | 30.6 | 32.8 | 33.1 | 33.5 | 33.7 | 33.8 | 32.9 |
| DeepCalib [28] | 71.7 | 78.9 | 80.1 | 80.4 | 80.6 | 80.9 | 78.8 |
| DR-GAN [35] | 60.1 | 62.4 | 62.6 | 63.1 | 62.9 | 63.2 | 62.4 |
| PCN [37] | 29.4 | 30.8 | 31.2 | 31.3 | 31.1 | 30.9 | 30.8 |
| QueryCDR [38] | 28.3 | 28.9 | 29.9 | 30.1 | 31.2 | 30.9 | 29.9 |
| DCAN | 27.7 | 27.8 | 28.1 | 28.0 | 28.2 | 28.6 | 28.1 |
| Methods | SimFIR [39] | DeepCalib [28] | DR-GAN [35] | PCN [37] | QueryCDR [38] | DCAN |
|---|---|---|---|---|---|---|
| Flops (G) | 2.98 | 8.33 | 12.86 | 12.31 | 12.35 | 12.34 |
| Parameters (M) | 11.64 | 22.06 | 54.43 | 35.63 | 43.24 | 36.75 |
| Time (s) | 0.58 | 0.43 | 0.70 | 0.55 | 0.53 | 0.49 |
| Methods | PSNR ↑ | SSIM ↑ | FID ↓ | |
|---|---|---|---|---|
| Network Module | w/o FNM | 15.88 | 0.4713 | 198.7 |
| w/o DCM | 17.96 | 0.6434 | 163.5 | |
| w/o CAFSM | 22.36 | 0.8779 | 32.7 | |
| Loss Function | w/o EHL and MSL and SSL | 22.38 | 0.8688 | 31.9 |
| w/o SSL | 23.11 | 0.8772 | 31.5 | |
| w/o EHL and MSL | 23.87 | 0.8801 | 29.1 | |
| DCAN | all | 24.59 | 0.9110 | 28.6 |
| Methods | PSNR ↑ | SSIM ↑ | FID ↓ |
|---|---|---|---|
| w/o CAFSM (1) | 23.12 | 0.8600 | 30.6 |
| w/o CAFSM (3) | 23.76 | 0.8713 | 30.4 |
| w/o CAFSM (5) | 23.95 | 0.8971 | 29.9 |
| w/o CAFSM (1,2) | 22.98 | 0.8598 | 31.2 |
| w/o CAFSM (4,5) | 23.78 | 0.8801 | 30.0 |
| w/o CAFSM (1,2,3) | 22.41 | 0.8581 | 31.5 |
| w/o CAFSM (3,4,5) | 23.85 | 0.8771 | 29.1 |
| w/o CAFSM (all) | 22.36 | 0.8779 | 32.7 |
| DCAN | 24.59 | 0.9110 | 28.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Peng, S.; Liu, J.; Guo, A. DCAN: Dynamic Channel Attention Network for Multi-Scale Distortion Correction. Sensors 2025, 25, 1482. https://doi.org/10.3390/s25051482
Zhang J, Peng S, Liu J, Guo A. DCAN: Dynamic Channel Attention Network for Multi-Scale Distortion Correction. Sensors. 2025; 25(5):1482. https://doi.org/10.3390/s25051482
Chicago/Turabian StyleZhang, Jianhua, Saijie Peng, Jingjing Liu, and Aiying Guo. 2025. "DCAN: Dynamic Channel Attention Network for Multi-Scale Distortion Correction" Sensors 25, no. 5: 1482. https://doi.org/10.3390/s25051482
APA StyleZhang, J., Peng, S., Liu, J., & Guo, A. (2025). DCAN: Dynamic Channel Attention Network for Multi-Scale Distortion Correction. Sensors, 25(5), 1482. https://doi.org/10.3390/s25051482