

Recent Advances in Deep Learning-Based Spatiotemporal Fusion Methods for Remote Sensing Images


 , ,
, ,
Abstract
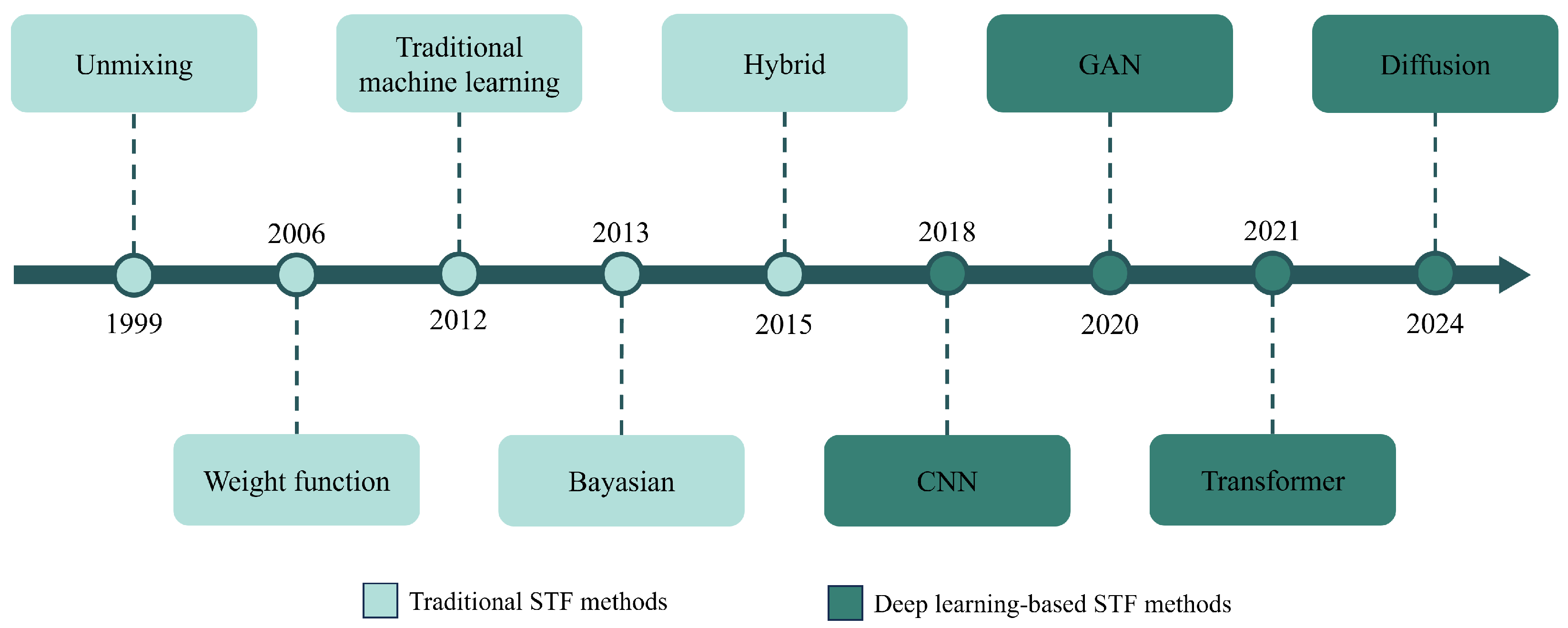
1. Introduction
2. Deep Learning-Based Spatiotemporal Fusion Methods
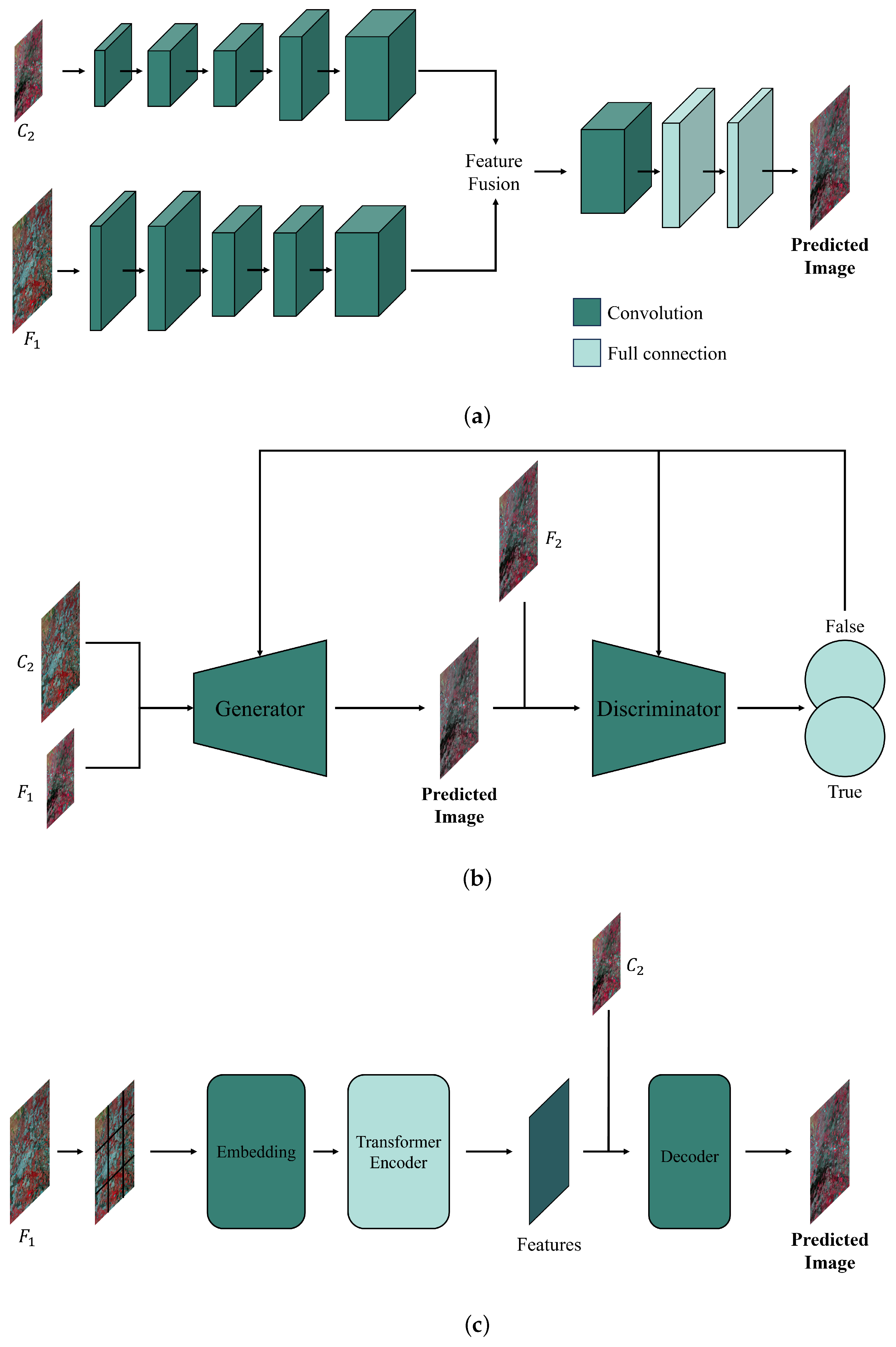
2.1. CNN-Based Fusion Methods
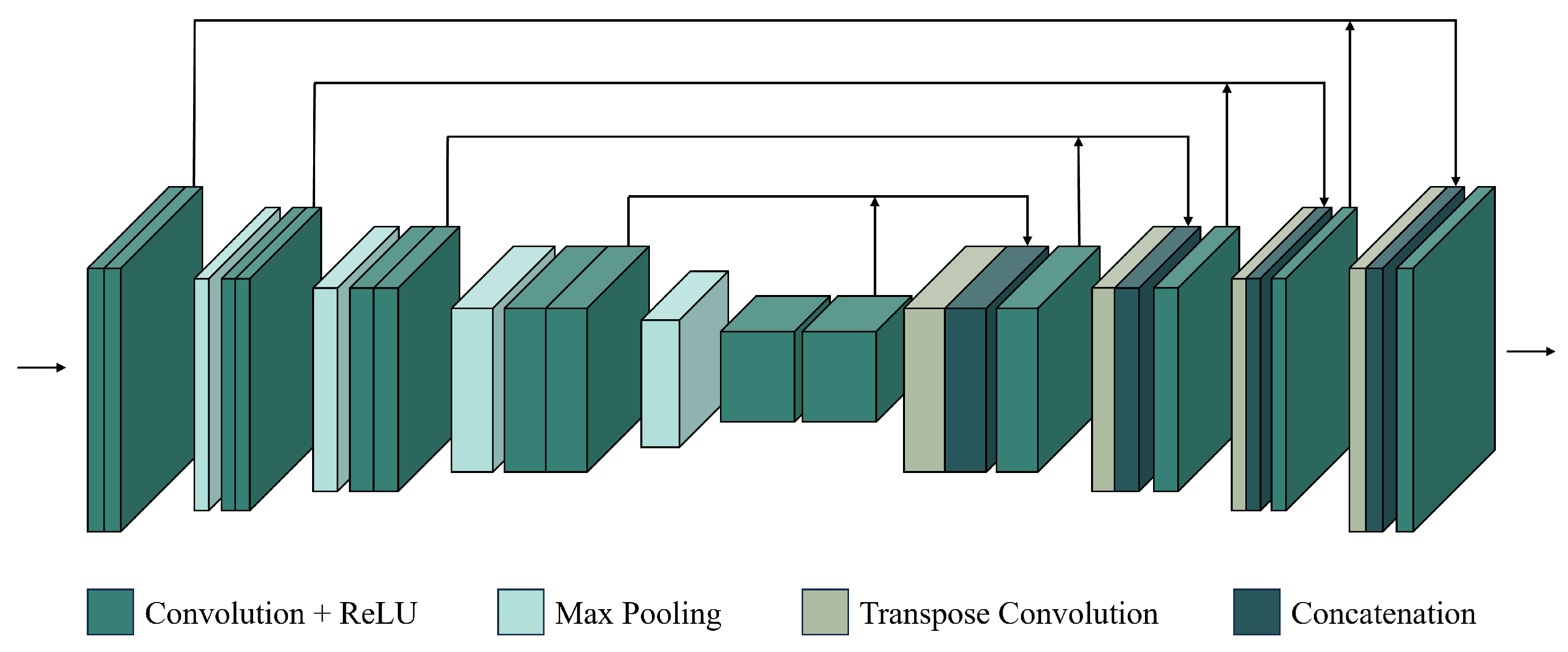
2.1.1. Conventional CNN Methods
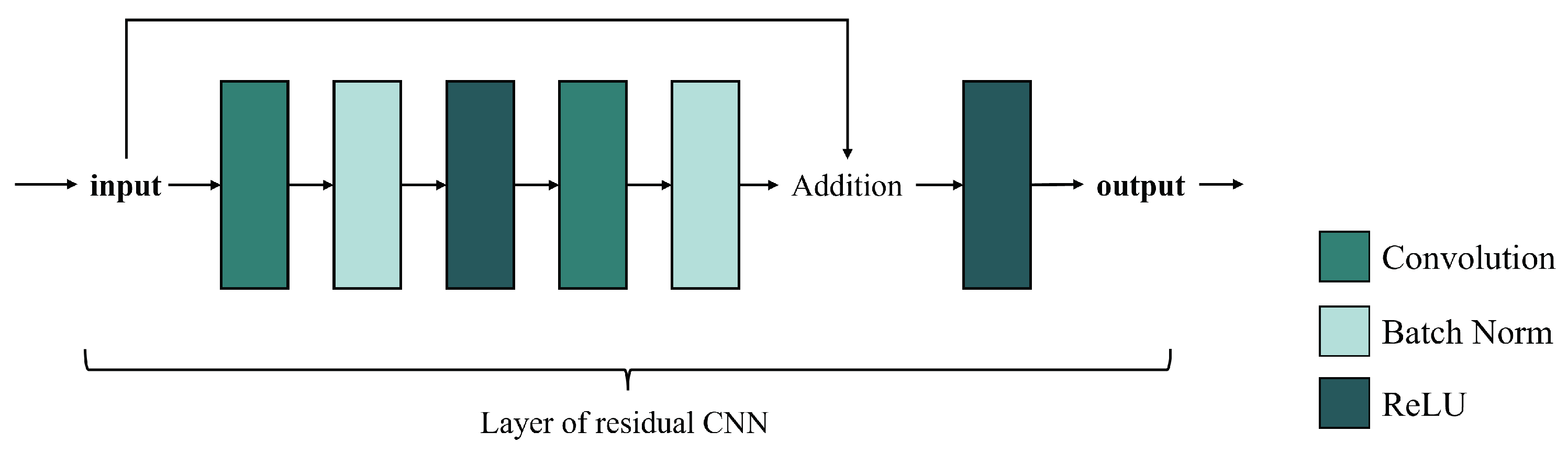
2.1.2. Residual-Based CNN Methods
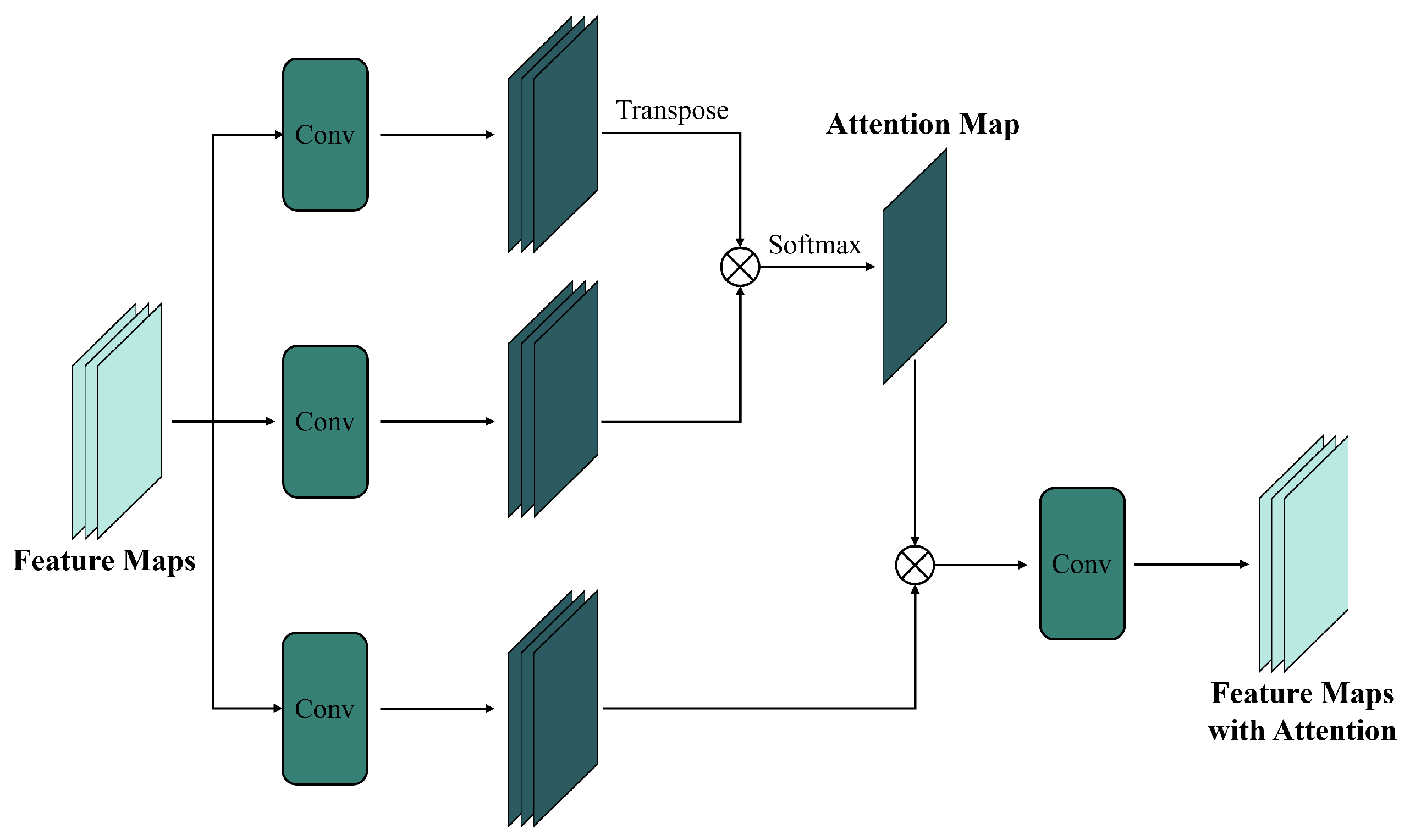
2.1.3. Attention-Based CNN Methods
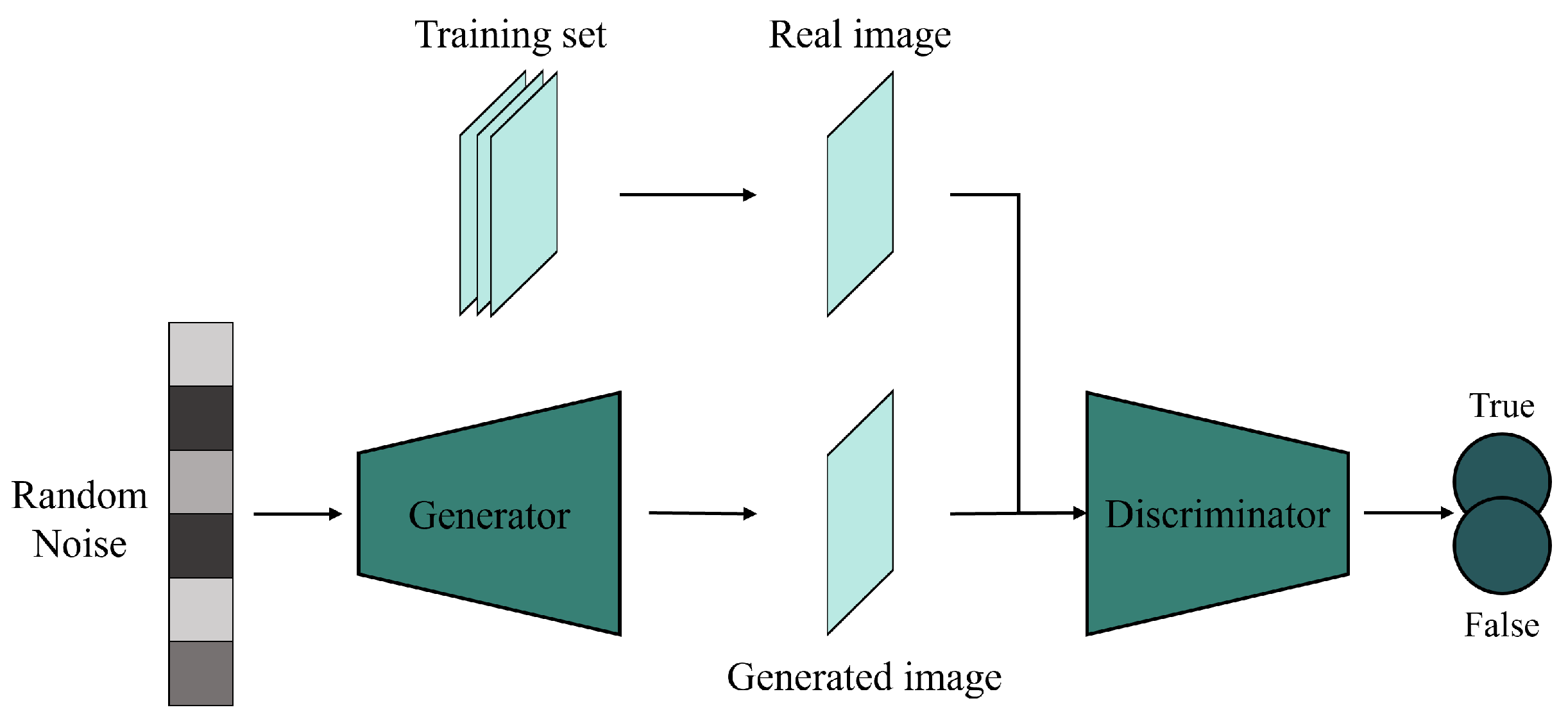
2.2. GAN-Based Fusion Methods
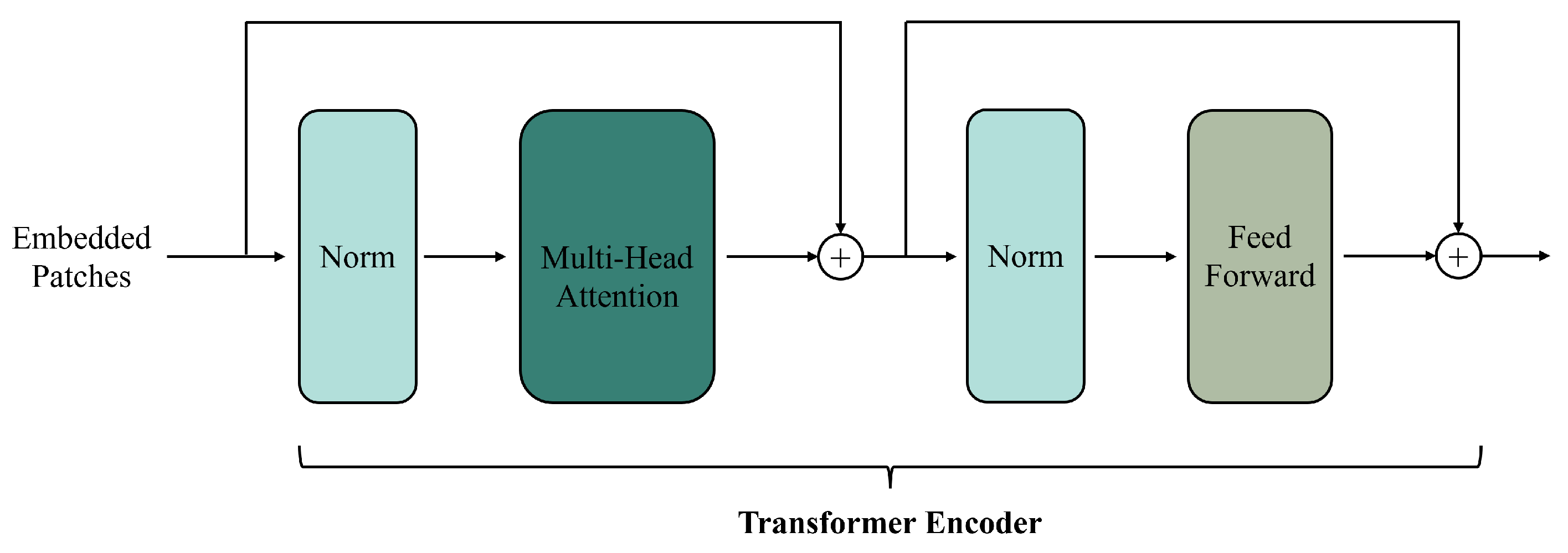
2.3. Transformer-Based Fusion Methods
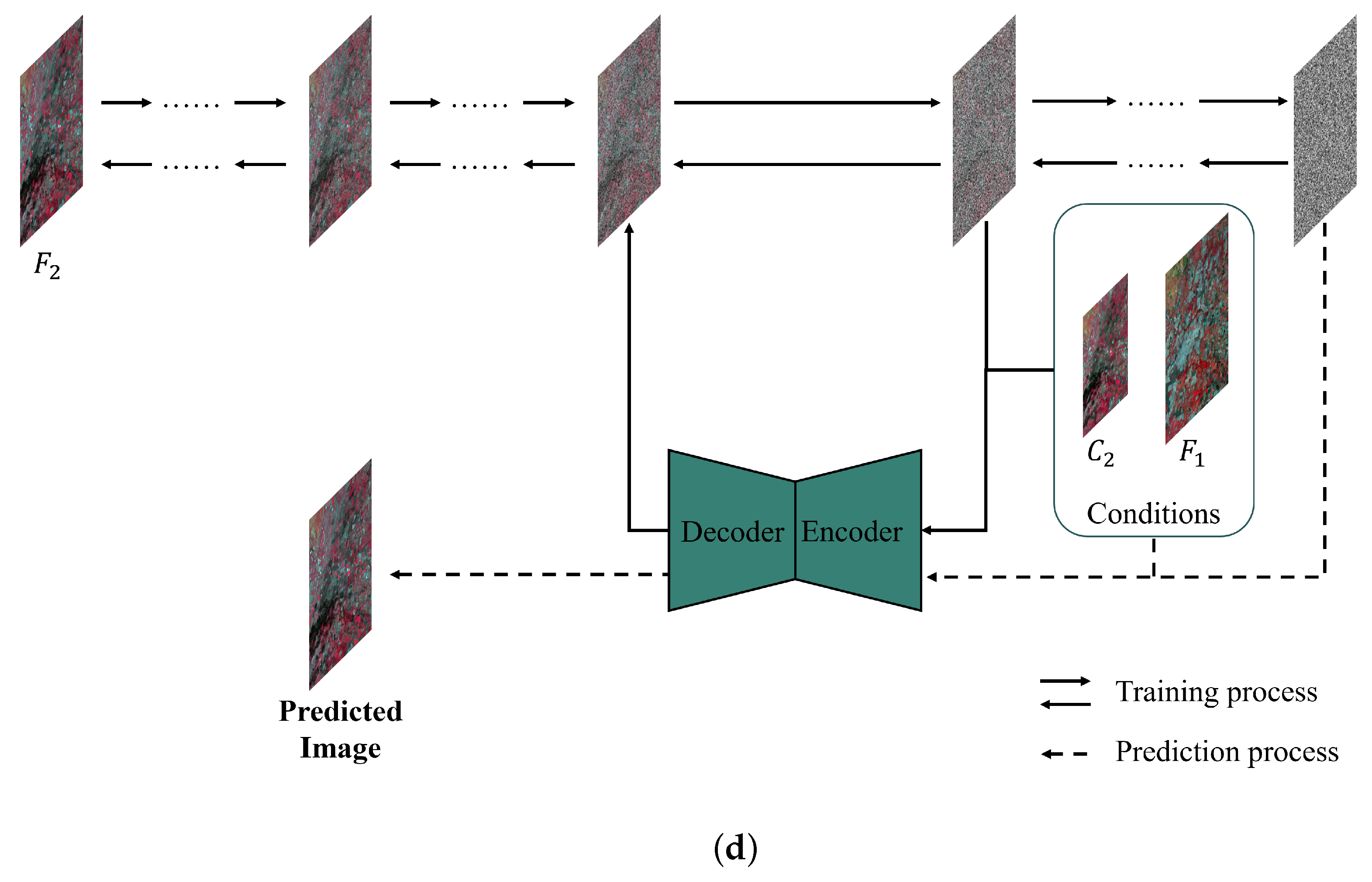
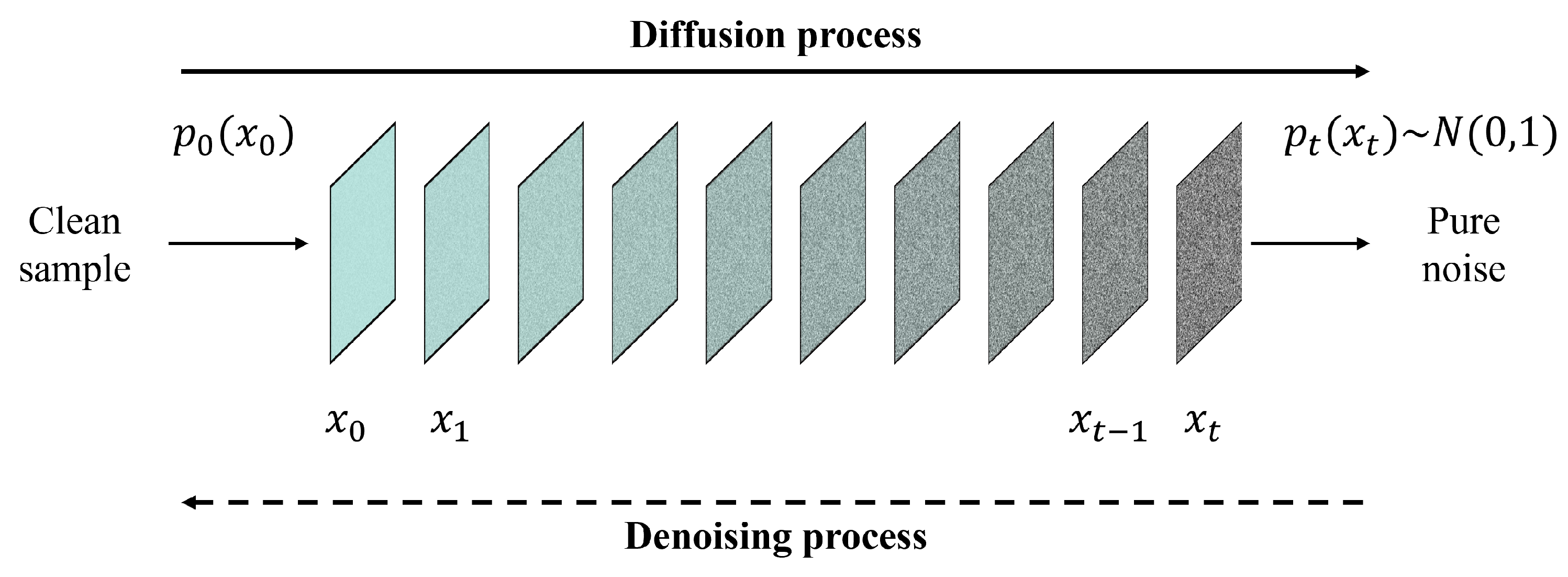
2.4. Diffusion-Based Fusion Methods
3. Evaluations and Applications
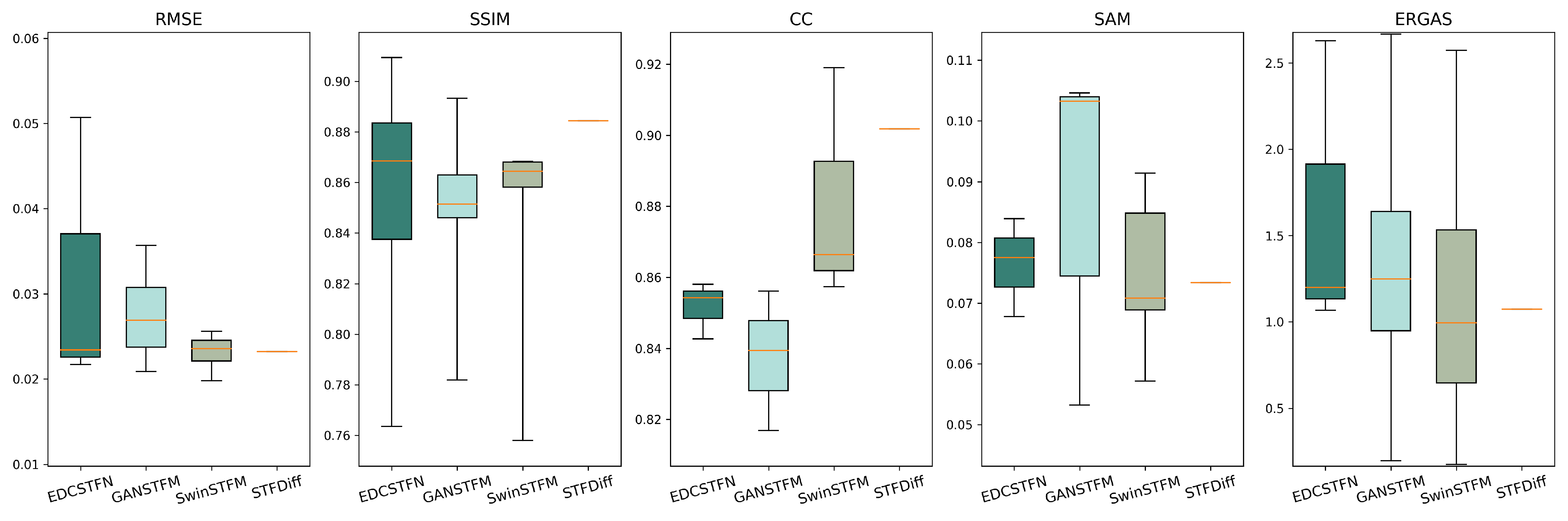
3.1. Method Comparisons
3.1.1. Performance Evaluation
3.1.2. Computational Efficiency
3.2. Model Applicability
3.2.1. Feasibility for Different Scenarios
3.2.2. Impact of Data Heterogeneity
3.3. Practical Applications
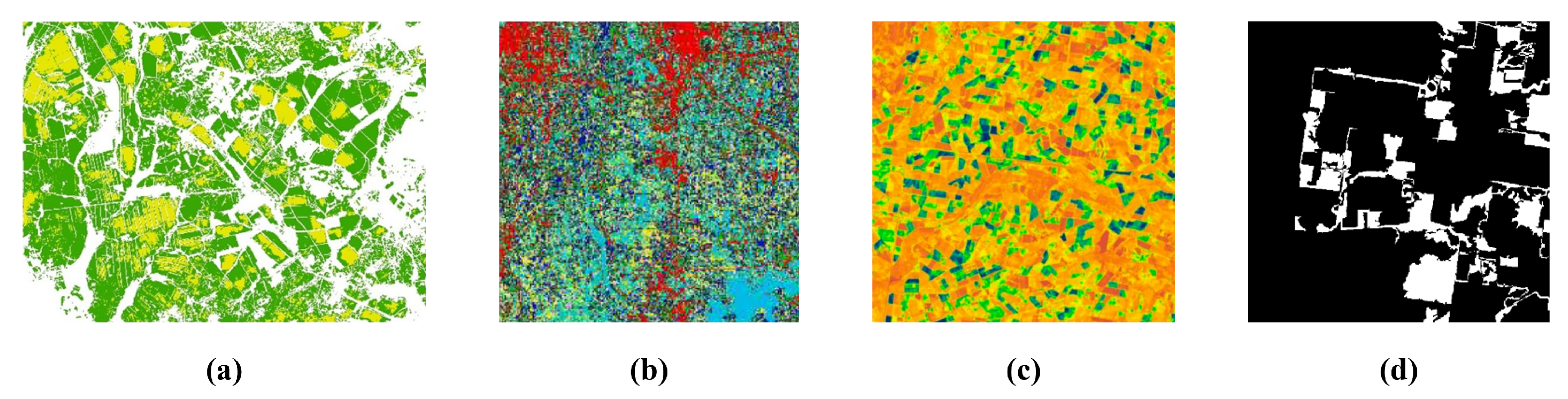
3.3.1. Crop Classification
3.3.2. Land-Cover Classification
3.3.3. Vegetation Monitoring
3.3.4. Change Detection
4. Current Issues and Future Directions
4.1. Land-Cover Changes
4.2. Sensor Differences
4.3. Datasets and Assessment Metrics
4.4. Efficiency and Uncertainty
5. Conclusions
- This paper provides a detailed classification of existing deep learning-based spatiotemporal fusion methods based on network structures and categorizes them into four main types: convolutional neural network-based methods, generative adversarial network-based methods, Transformer-based methods, and diffusion-based methods. This paper analyzes and compares the different principles, advantages, and disadvantages of each deep learning-based method and outlines the evolution and development of research in this area. As neural network models are increasingly being applied in spatiotemporal fusion, the comprehensive analysis and summary presented in this paper serve as a helpful resource for future research on deep learning-based spatiotemporal fusion methods.
- This paper provides an in-depth exploration of deep learning-based spatiotemporal fusion methods, presenting application examples, performance evaluations, and method comparisons to assess their effectiveness and computational efficiency. By evaluating four deep learning-based fusion models from CNN-based, GAN-based, Transformer-based, and diffusion-based methods, this paper offers valuable insights into the strengths and limitations of various approaches, considering different scenarios and the impact of data heterogeneity. The analysis highlights the importance of model adaptability, computational efficiency, and robustness to data variations, providing a solid foundation for improving the performance and scalability of deep learning-based spatiotemporal fusion methods.
- This paper identifies four challenges currently faced in deep learning-based spatiotemporal fusion studies. Difficulties in recognizing land-cover changes and the insufficient consideration of sensor differences are common obstacles for deep learning-based fusion models. The limited data scale, the lack of variety in spatiotemporal fusion datasets, the incompleteness and redundancy of evaluation metrics, and the low computational efficiency and uncertainty of deep learning-based models are important issues that future studies need to tackle. In response to these challenges, this paper proposes several potential solutions and provides useful references for subsequent research and applications of deep learning-based spatiotemporal fusion methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mewes, B.; Schumann, A.H. An agent-based extension for object-based image analysis for the delineation of irrigated agriculture from remote sensing data. Int. J. Remote Sens. 2019, 40, 4623–4641. [Google Scholar] [CrossRef]
- Sun, Y.; Luo, J.; Xia, L.; Wu, T.; Gao, L.; Dong, W.; Hu, X.; Hai, Y. Geo-parcel-based crop classification in very-high-resolution images via hierarchical perception. Int. J. Remote Sens. 2020, 41, 1603–1624. [Google Scholar] [CrossRef]
- Aneece, I.; Thenkabail, P.S.; McCormick, R.; Alifu, H.; Foley, D.; Oliphant, A.J.; Teluguntla, P. Machine Learning and New-Generation Spaceborne Hyperspectral Data Advance Crop Type Mapping. Photogramm. Eng. Remote Sens. 2024, 90, 687–698. [Google Scholar] [CrossRef]
- Liang, L.; Tan, B.; Li, S.; Kang, Z.; Liu, X.; Wang, L. Identifying the Driving Factors of Urban Land Surface Temperature. Photogramm. Eng. Remote Sens. 2022, 88, 233–242. [Google Scholar] [CrossRef]
- Al-Doski, J.; Hassan, F.M.; Mossa, H.A.; Najim, A.A. Incorporation of digital elevation model, normalized difference vegetation index, and Landsat-8 data for land use land cover mapping. Photogramm. Eng. Remote Sens. 2022, 88, 507–516. [Google Scholar] [CrossRef]
- Lakshmi Priya, G.; Chandra Mouli, P.; Domnic, S.; Chemmalar Selvi, G.; Cho, B.K. Hyperspectral image classification using Walsh Hadamard transform-based key band selection and deep convolutional neural networks. Int. J. Remote Sens. 2024, 45, 1220–1249. [Google Scholar] [CrossRef]
- Byerlay, R.A.; Nambiar, M.K.; Nazem, A.; Nahian, M.R.; Biglarbegian, M.; Aliabadi, A.A. Measurement of land surface temperature from oblique angle airborne thermal camera observations. Int. J. Remote Sens. 2020, 41, 3119–3146. [Google Scholar] [CrossRef]
- Alpers, W.; Kong, W.; Zeng, K.; Chan, P.W. On the physical mechanism causing strongly enhanced radar backscatter in C-Band SAR images of convective rain over the ocean. Int. J. Remote Sens. 2024, 45, 3827–3845. [Google Scholar] [CrossRef]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T. Spatiotemporal Fusion of Multisource Remote Sensing Data: Literature Survey, Taxonomy, Principles, Applications, and Future Directions. Remote Sens. 2018, 10, 527. [Google Scholar] [CrossRef]
- Zhukov, B.; Oertel, D.; Lanzl, F.; Reinhackel, G. Unmixing-based multisensor multiresolution image fusion. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1212–1226. [Google Scholar] [CrossRef]
- Wu, M.; Wu, C.; Huang, W.; Niu, Z.; Wang, C.; Li, W.; Hao, P. An improved high spatial and temporal data fusion approach for combining Landsat and MODIS data to generate daily synthetic Landsat imagery. Inf. Fusion 2016, 31, 14–25. [Google Scholar] [CrossRef]
- Gao, F.; Masek, J.; Schwaller, M.; Hall, F. On the blending of the Landsat and MODIS surface reflectance: Predicting daily Landsat surface reflectance. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2207–2218. [Google Scholar] [CrossRef]
- Zhu, X.; Chen, J.; Gao, F.; Chen, X.; Masek, J.G. An enhanced spatial and temporal adaptive reflectance fusion model for complex heterogeneous regions. Remote Sens. Environ. 2010, 114, 2610–2623. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Linke, J.; McDermid, G.; Masek, J.G.; Gao, F.; White, J.C. A new data fusion model for high spatial- and temporal-resolution mapping of forest disturbance based on Landsat and MODIS. Remote Sens. Environ. 2009, 113, 1613–1627. [Google Scholar] [CrossRef]
- Li, A.; Bo, Y.; Zhu, Y.; Guo, P.; Bi, J.; He, Y. Blending multi-resolution satellite sea surface temperature (SST) products using Bayesian maximum entropy method. Remote Sens. Environ. 2013, 135, 52–63. [Google Scholar] [CrossRef]
- Huang, B.; Song, H. Spatiotemporal Reflectance Fusion via Sparse Representation. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3707–3716. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gao, F.; Liu, D.; Chen, J.; Lefsky, M.A. A flexible spatiotemporal method for fusing satellite images with different resolutions. Remote Sens. Environ. 2016, 172, 165–177. [Google Scholar] [CrossRef]
- Moosavi, V.; Talebi, A.; Mokhtari, M.H.; Shamsi, S.R.F.; Niazi, Y. A wavelet-artificial intelligence fusion approach (WAIFA) for blending Landsat and MODIS surface temperature. Remote Sens. Environ. 2015, 169, 243–254. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Wang, S.; Huang, G.B.; Zhao, B.; Lauren, P. Fast and Accurate Spatiotemporal Fusion Based Upon Extreme Learning Machine. IEEE Geosci. Remote Sensing Lett. 2016, 13, 2039–2043. [Google Scholar] [CrossRef]
- Fung, C.H.; Wong, M.S.; Chan, P.W. Spatio-Temporal Data Fusion for Satellite Images Using Hopfield Neural Network. Remote Sens. 2019, 11, 2077. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Belgiu, M.; Stein, A. Spatiotemporal Image Fusion in Remote Sensing. Remote Sens. 2019, 11, 818. [Google Scholar] [CrossRef]
- Tan, Z.; Yue, P.; Di, L.; Tang, J. Deriving High Spatiotemporal Remote Sensing Images Using Deep Convolutional Network. Remote Sens. 2018, 10, 1066. [Google Scholar] [CrossRef]
- Tan, Z.; Gao, M.; Li, X.; Jiang, L. A Flexible Reference-Insensitive Spatiotemporal Fusion Model for Remote Sensing Images Using Conditional Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Li, W.; Cao, D.; Peng, Y.; Yang, C. MSNet: A Multi-Stream Fusion Network for Remote Sensing Spatiotemporal Fusion Based on Transformer and Convolution. Remote Sens. 2021, 13, 3724. [Google Scholar] [CrossRef]
- Huang, H.; He, W.; Zhang, H.; Xia, Y.; Zhang, L. STFDiff: Remote sensing image spatiotemporal fusion with diffusion models. Inf. Fusion 2024, 111, 102505. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Song, H.; Liu, Q.; Wang, G.; Hang, R.; Huang, B. Spatiotemporal Satellite Image Fusion Using Deep Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 821–829. [Google Scholar] [CrossRef]
- Li, W.; Yang, C.; Peng, Y.; Zhang, X. A Multi-Cooperative Deep Convolutional Neural Network for Spatiotemporal Satellite Image Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10174–10188. [Google Scholar] [CrossRef]
- Zheng, Y.; Song, H.; Sun, L.; Wu, Z.; Jeon, B. Spatiotemporal Fusion of Satellite Images via Very Deep Convolutional Networks. Remote Sens. 2019, 11, 2701. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, L.; Sun, X.; Cen, Y.; Zhao, X. A Synchronous Long Time-Series Completion Method Using 3-D Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Shao, Z.; Cai, J.; Fu, P.; Hu, L.; Liu, T. Deep learning-based fusion of Landsat-8 and Sentinel-2 images for a harmonized surface reflectance product. Remote Sens. Environ. 2019, 235, 111425. [Google Scholar] [CrossRef]
- Qin, P.; Huang, H.; Tang, H.; Wang, J.; Liu, C. MUSTFN: A spatiotemporal fusion method for multi-scale and multi-sensor remote sensing images based on a convolutional neural network. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103113. [Google Scholar] [CrossRef]
- Liu, X.; Deng, C.; Chanussot, J.; Hong, D.; Zhao, B. StfNet: A Two-Stream Convolutional Neural Network for Spatiotemporal Image Fusion. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6552–6564. [Google Scholar] [CrossRef]
- Wang, X.; Shao, Z.; Huang, X.; Li, D. Spatiotemporal Temperature Fusion Based on a Deep Convolutional Network. Photogramm Eng Remote Sens. 2022, 88, 93–101. [Google Scholar] [CrossRef]
- Jia, D.; Song, C.; Cheng, C.; Shen, S.; Ning, L.; Hui, C. A Novel Deep Learning-Based Spatiotemporal Fusion Method for Combining Satellite Images with Different Resolutions Using a Two-Stream Convolutional Neural Network. Remote Sens. 2020, 12, 698. [Google Scholar] [CrossRef]
- You, M.; Meng, X.; Liu, Q.; Shao, F.; Fu, R. CIG-STF: Change Information Guided Spatiotemporal Fusion for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; He, L.; Chen, J.; Plaza, A. A new sensor bias-driven spatio-temporal fusion model based on convolutional neural networks. Sci. China Inf. Sci. 2020, 63, 140302. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Liang, S.; Li, M. A New Spatial–Temporal Depthwise Separable Convolutional Fusion Network for Generating Landsat 8-Day Surface Reflectance Time Series over Forest Regions. Remote Sens. 2022, 14, 2199. [Google Scholar] [CrossRef]
- Tan, Z.; Di, L.; Zhang, M.; Guo, L.; Gao, M. An Enhanced Deep Convolutional Model for Spatiotemporal Image Fusion. Remote Sens. 2019, 11, 2898. [Google Scholar] [CrossRef]
- Li, W.; Wu, F.; Cao, D. Dual-Branch Remote Sensing Spatiotemporal Fusion Network Based on Selection Kernel Mechanism. Remote Sens. 2022, 14, 4282. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Yan, L.; Li, J.; Plaza, A.; Li, B. A New Spatio-Temporal Fusion Method for Remotely Sensed Data Based on Convolutional Neural Networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 835–838. [Google Scholar] [CrossRef]
- Hoque, M.R.U.; Wu, J.; Kwan, C.; Koperski, K.; Li, J. ArithFusion: An Arithmetic Deep Model for Temporal Remote Sensing Image Fusion. Remote Sens. 2022, 14, 6160. [Google Scholar] [CrossRef]
- Li, W.; Zhang, X.; Peng, Y.; Dong, M. DMNet: A Network Architecture Using Dilated Convolution and Multiscale Mechanisms for Spatiotemporal Fusion of Remote Sensing Images. IEEE Sensors J. 2020, 20, 12190–12202. [Google Scholar] [CrossRef]
- Jia, D.; Cheng, C.; Shen, S.; Ning, L. Multitask Deep Learning Framework for Spatiotemporal Fusion of NDVI. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Peng, M.; Zhang, L.; Sun, X.; Cen, Y.; Zhao, X. A Fast Three-Dimensional Convolutional Neural Network-Based Spatiotemporal Fusion Method (STF3DCNN) Using a Spatial-Temporal-Spectral Dataset. Remote Sens. 2020, 12, 3888. [Google Scholar] [CrossRef]
- Xiong, S.; Du, S.; Zhang, X.; Ouyang, S.; Cui, W. Fusing Landsat-7, Landsat-8 and Sentinel-2 surface reflectance to generate dense time series images with 10m spatial resolution. Int. J. Remote. Sens. 2022, 43, 1630–1654. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X. Spatiotemporal Fusion of Remote Sensing Image Based on Deep Learning. J. Sens. 2020, 2020, 8873079. [Google Scholar] [CrossRef]
- Fang, S.; Meng, S.; Zhang, J.; Cao, Y. Two-stream spatiotemporal image fusion network based on difference transformation. J. Appl. Remote Sens. 2022, 16, 038506. [Google Scholar] [CrossRef]
- Jia, D.; Cheng, C.; Song, C.; Shen, S.; Ning, L.; Zhang, T. A Hybrid Deep Learning-Based Spatiotemporal Fusion Method for Combining Satellite Images with Different Resolutions. Remote Sens. 2021, 13, 645. [Google Scholar] [CrossRef]
- Cai, J.; Huang, B.; Fung, T. Progressive spatiotemporal image fusion with deep neural networks. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102745. [Google Scholar] [CrossRef]
- Htitiou, A.; Boudhar, A.; Benabdelouahab, T. Deep Learning-Based Spatiotemporal Fusion Approach for Producing High-Resolution NDVI Time-Series Datasets. Can. J. Remote. Sens. 2021, 47, 182–197. [Google Scholar] [CrossRef]
- Wei, J.; Yang, H.; Tang, W.; Li, Q. Spatiotemporal-Spectral Fusion for Gaofen-1 Satellite Images. IEEE Geosci. Remote Sensing Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wei, J.; Tang, W.; He, C. Enblending Mosaicked Remote Sensing Images with Spatiotemporal Fusion of Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5891–5902. [Google Scholar] [CrossRef]
- Erdem, F.; Avdan, U. STFRDN: A residual dense network for remote sensing image spatiotemporal fusion. Int. J. Remote Sens. 2023, 44, 3259–3277. [Google Scholar] [CrossRef]
- Wang, J.; Chen, F.; Zhang, M.; Yu, B. ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images. Remote Sens. 2021, 13, 5091. [Google Scholar] [CrossRef]
- Xiao, J.; Aggarwal, A.K.; Rage, U.K.; Katiyar, V.; Avtar, R. Deep Learning-Based Spatiotemporal Fusion of Unmanned Aerial Vehicle and Satellite Reflectance Images for Crop Monitoring. IEEE Access 2023, 11, 85600–85614. [Google Scholar] [CrossRef]
- Bai, Y.; Wu, W.; Yang, Z.; Yu, J.; Zhao, B.; Liu, X.; Yang, H.; Mas, E.; Koshimura, S. Enhancement of Detecting Permanent Water and Temporary Water in Flood Disasters by Fusing Sentinel-1 and Sentinel-2 Imagery Using Deep Learning Algorithms: Demonstration of Sen1Floods11 Benchmark Datasets. Remote Sens. 2021, 13, 2220. [Google Scholar] [CrossRef]
- Zeng, Y.; Gao, B.; Liu, P.; Zhao, X. Spatiotemporal Fusion for Nighttime Light Remote Sensing Images With Multivariate Activation Function. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Yin, Z.; Wu, P.; Foody, G.M.; Wu, Y.; Liu, Z.; Du, Y.; Ling, F. Spatiotemporal Fusion of Land Surface Temperature Based on a Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1808–1822. [Google Scholar] [CrossRef]
- Fu, R.; Hu, H.; Wu, N.; Liu, Z.; Jin, W. Spatiotemporal fusion convolutional neural network: Tropical cyclone intensity estimation from multisource remote sensing images. J. Appl. Remote Sens. 2024, 18, 018501. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, K.; Ge, Y.; Zhou, Y. Spatiotemporal Remote Sensing Image Fusion Using Multiscale Two-Stream Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Li, W.; Zhang, X.; Peng, Y.; Dong, M. Spatiotemporal Fusion of Remote Sensing Images using a Convolutional Neural Network with Attention and Multiscale Mechanisms. Int. J. Remote. Sens. 2021, 42, 1973–1993. [Google Scholar] [CrossRef]
- Wu, J.; Lin, L.; Li, T.; Cheng, Q.; Zhang, C.; Shen, H. Fusing Landsat 8 and Sentinel-2 data for 10-m dense time-series imagery using a degradation-term constrained deep network. Int. J. Appl. Earth Obs. Geoinf. 2022, 108, 102738. [Google Scholar] [CrossRef]
- Ao, Z.; Sun, Y.; Xin, Q. Constructing 10-m NDVI Time Series From Landsat 8 and Sentinel 2 Images Using Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1461–1465. [Google Scholar] [CrossRef]
- Wang, S.; Cui, D.; Wang, L.; Peng, J. Applying deep-learning enhanced fusion methods for improved NDVI reconstruction and long-term vegetation cover study: A case of the Danjiang River Basin. Ecol. Indic. 2023, 155, 111088. [Google Scholar] [CrossRef]
- Li, W.; Yang, C.; Peng, Y.; Du, J. A Pseudo-Siamese Deep Convolutional Neural Network for Spatiotemporal Satellite Image Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1205–1220. [Google Scholar] [CrossRef]
- Lin, L.; Shen, Y.; Wu, J.; Nan, F. CAFE: A Cross-Attention Based Adaptive Weighting Fusion Network for MODIS and Landsat Spatiotemporal Fusion. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Sun, H.; Xiao, W. Similarity Weight Learning: A New Spatial and Temporal Satellite Image Fusion Framework. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Cai, Z.; Hu, Q.; Zhang, X.; Yang, J.; Wei, H.; Wang, J.; Zeng, Y.; Yin, G.; Li, W.; You, L.; et al. Improving agricultural field parcel delineation with a dual branch spatiotemporal fusion network by integrating multimodal satellite data. ISPRS J. Photogramm. Remote. Sens. 2023, 205, 34–49. [Google Scholar] [CrossRef]
- Cheng, F.; Fu, Z.; Tang, B.; Huang, L.; Huang, K.; Ji, X. STF-EGFA: A Remote Sensing Spatiotemporal Fusion Network with Edge-Guided Feature Attention. Remote Sens. 2022, 14, 3057. [Google Scholar] [CrossRef]
- Ran, Q.; Wang, Q.; Zheng, K.; Li, J. Multiscale Attention Spatiotemporal Fusion Model Based on Pyramidal Network Constraints. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Lei, D.; Huang, Z.; Zhang, L.; Li, W. SCRNet: An efficient spatial channel attention residual network for spatiotemporal fusion. J. Appl. Remote Sens. 2022, 16, 036512. [Google Scholar] [CrossRef]
- Zhang, X.; Li, S.; Tan, Z.; Li, X. Enhanced wavelet based spatiotemporal fusion networks using cross-paired remote sensing images. ISPRS J. Photogramm. Remote Sens. 2024, 211, 281–297. [Google Scholar] [CrossRef]
- Cao, H.; Luo, X.; Peng, Y.; Xie, T. MANet: A Network Architecture for Remote Sensing Spatiotemporal Fusion Based on Multiscale and Attention Mechanisms. Remote Sens. 2022, 14, 4600. [Google Scholar] [CrossRef]
- Cui, D.; Wang, S.; Zhao, C.; Zhang, H. A Novel Remote Sensing Spatiotemporal Data Fusion Framework Based on the Combination of Deep-Learning Downscaling and Traditional Fusion Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7957–7970. [Google Scholar] [CrossRef]
- Yang, Z.; Diao, C.; Li, B. A Robust Hybrid Deep Learning Model for Spatiotemporal Image Fusion. Remote Sens. 2021, 13, 5005. [Google Scholar] [CrossRef]
- Zhan, W.; Luo, F.; Luo, H.; Li, J.; Wu, Y.; Yin, Z.; Wu, Y.; Wu, P. Time-Series-Based Spatiotemporal Fusion Network for Improving Crop Type Mapping. Remote Sens. 2024, 16, 235. [Google Scholar] [CrossRef]
- Wei, J.; Chen, L.; Chen, Z.; Huang, Y. An Experimental Study of the Accuracy and Change Detection Potential of Blending Time Series Remote Sensing Images with Spatiotemporal Fusion. Remote Sens. 2023, 15, 3763. [Google Scholar] [CrossRef]
- Zheng, X.; Feng, R.; Fan, J.; Han, W.; Yu, S.; Chen, J. MSISR-STF: Spatiotemporal Fusion via Multilevel Single-Image Super-Resolution. Remote Sens. 2023, 15, 5675. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Zhou, J.; He, Z.; Song, Y.N.; Wang, H.; Yang, X.; Lian, W.; Dai, H.N. Precious Metal Price Prediction Based on Deep Regularization Self-Attention Regression. IEEE Access 2020, 8, 2178–2187. [Google Scholar] [CrossRef]
- Talbi, F.; Chikr Elmezouar, M.; Boutellaa, E.; Alim, F. Vector-Quantized Variational AutoEncoder for pansharpening. Int. J. Remote Sens. 2023, 44, 6329–6349. [Google Scholar] [CrossRef]
- Chen, J.; Wang, L.; Feng, R.; Liu, P.; Han, W.; Chen, X. CycleGAN-STF: Spatiotemporal Fusion via CycleGAN-Based Image Generation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5851–5865. [Google Scholar] [CrossRef]
- Tan, Z.; Gao, M.; Yuan, J.; Jiang, L.; Duan, H. A Robust Model for MODIS and Landsat Image Fusion Considering Input Noise. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Ma, Y.; Wei, J.; Tang, W.; Tang, R. Explicit and stepwise models for spatiotemporal fusion of remote sensing images with deep neural networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102611. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.; Li, X.; Gao, F.; Jiang, T.; Ren, R. An Improved Spatiotemporal Fusion Algorithm for Monitoring Daily Snow Cover Changes with High Spatial Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Liu, H.; Yang, G.; Deng, F.; Qian, Y.; Fan, Y. MCBAM-GAN: The Gan Spatiotemporal Fusion Model Based on Multiscale and CBAM for Remote Sensing Images. Remote Sens. 2023, 15, 1583. [Google Scholar] [CrossRef]
- Zhang, H.; Song, Y.; Han, C.; Zhang, L. Remote Sensing Image Spatiotemporal Fusion Using a Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4273–4286. [Google Scholar] [CrossRef]
- Pan, X.; Deng, M.; Ao, Z.; Xin, Q. An Adaptive Multiscale Generative Adversarial Network for the Spatiotemporal Fusion of Landsat and MODIS Data. Remote Sens. 2023, 15, 5128. [Google Scholar] [CrossRef]
- Fang, S.; Guo, Q.; Cao, Y.; Zhang, J. A Two-Layers Super-Resolution Based Generation Adversarial Spatiotemporal Fusion Model. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 891–894. [Google Scholar] [CrossRef]
- Sun, W.; Li, J.; Jiang, M.; Yuan, Q. Supervised and self-supervised learning-based cascade spatiotemporal fusion framework and its application. ISPRS J. Photogramm. Remote. Sens. 2023, 203, 19–36. [Google Scholar] [CrossRef]
- Jiang, M.; Shen, H.; Li, J. Deep-Learning-Based Spatio-Temporal-Spectral Integrated Fusion of Heterogeneous Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Wu, Y.; Feng, S.; Huang, M. An enhanced spatiotemporal fusion model with degraded fine-resolution images via relativistic generative adversarial networks. Geocarto Int. 2023, 38, 2153931. [Google Scholar] [CrossRef]
- Liu, Q.; Meng, X.; Shao, F.; Li, S. PSTAF-GAN: Progressive Spatio-Temporal Attention Fusion Method Based on Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wu, Y.; Li, Y.; Huang, M.; Feng, S. Multiresolution generative adversarial networks with bidirectional adaptive-stage progressive guided fusion for remote sensing image. Int. J. Digit. Earth 2023, 16, 2962–2997. [Google Scholar] [CrossRef]
- Ma, Y.; Wei, J.; Huang, X. Balancing Colors of Nonoverlapping Mosaicking Images with Generative Adversarial Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liu, S.; Liu, J.; Tan, X.; Chen, X.; Chen, J. A Hybrid Spatiotemporal Fusion Method for High Spatial Resolution Imagery: Fusion of Gaofen-1 and Sentinel-2 over Agricultural Landscapes. J. Remote Sens. 2024, 4, 0159. [Google Scholar] [CrossRef]
- Shang, C.; Li, X.; Yin, Z.; Li, X.; Wang, L.; Zhang, Y.; Du, Y.; Ling, F. Spatiotemporal Reflectance Fusion Using a Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Sun, W.; Ren, K.; Meng, X.; Yang, G.; Liu, Q.; Zhu, L.; Peng, J.; Li, J. Generating high-resolution hyperspectral time series datasets based on unsupervised spatial-temporal-spectral fusion network incorporating a deep prior. Inf. Fusion 2024, 111, 102499. [Google Scholar] [CrossRef]
- Song, B.; Liu, P.; Li, J.; Wang, L.; Zhang, L.; He, G.; Chen, L.; Liu, J. MLFF-GAN: A Multilevel Feature Fusion With GAN for Spatiotemporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Weng, C.; Zhan, Y.; Gu, X.; Yang, J.; Liu, Y.; Guo, H.; Lian, Z.; Zhang, S.; Wang, Z.; Zhao, X. The Spatially Seamless Spatiotemporal Fusion Model Based on Generative Adversarial Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 12760–12771. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, H.; Huang, H.; Zhang, L. Remote Sensing Image Spatiotemporal Fusion via a Generative Adversarial Network With One Prior Image Pair. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Yang, G.; Qian, Y.; Liu, H.; Tang, B.; Qi, R.; Lu, Y.; Geng, J. MSFusion: Multistage for Remote Sensing Image Spatiotemporal Fusion Based on Texture Transformer and Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4653–4666. [Google Scholar] [CrossRef]
- Chen, G.; Jiao, P.; Hu, Q.; Xiao, L.; Ye, Z. SwinSTFM: Remote Sensing Spatiotemporal Fusion Using Swin Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Wang, Z.; Fang, S.; Zhang, J. Spatiotemporal Fusion Model of Remote Sensing Images Combining Single-Band and Multi-Band Prediction. Remote Sens. 2023, 15, 4936. [Google Scholar] [CrossRef]
- Li, W.; Cao, D.; Xiang, M. Enhanced Multi-Stream Remote Sensing Spatiotemporal Fusion Network Based on Transformer and Dilated Convolution. Remote Sens. 2022, 14, 4544. [Google Scholar] [CrossRef]
- Benzenati, T.; Kallel, A.; Kessentini, Y. STF-Trans: A two-stream spatiotemporal fusion transformer for very high resolution satellites images. Neurocomputing 2024, 563, 126868. [Google Scholar] [CrossRef]
- Qian, Z.; Yue, L.; Xie, X.; Yuan, Q.; Shen, H. A Dual-Perspective Spatiotemporal Fusion Model for Remote Sensing Images by Discriminative Learning of the Spatial and Temporal Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 12505–12520. [Google Scholar] [CrossRef]
- Liu, H.; Qian, Y.; Yang, G.; Jiang, H. Super-Resolution Reconstruction Model of Spatiotemporal Fusion Remote Sensing Image Based on Double Branch Texture Transformers and Feedback Mechanism. Electronics 2022, 11, 2497. [Google Scholar] [CrossRef]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Moser, B.B.; Shanbhag, A.S.; Raue, F.; Frolov, S.; Palacio, S.; Dengel, A. Diffusion Models, Image Super-Resolution and Everything: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–21. [Google Scholar] [CrossRef]
- Kulikov, V.; Yadin, S.; Kleiner, M.; Michaeli, T. Sinddm: A single image denoising diffusion model. In Proceedings of the International Conference on Machine Learning, PMLR, Seattle, WA, USA, 30 November–1 December 2023; pp. 17920–17930. [Google Scholar]
- Li, X.; Ren, Y.; Jin, X.; Lan, C.; Wang, X.; Zeng, W.; Wang, X.; Chen, Z. Diffusion Models for Image Restoration and Enhancement—A Comprehensive Survey. arXiv 2023, arXiv:2308.09388. [Google Scholar]
- Ma, Y.; Wang, Q.; Wei, J. Spatiotemporal Fusion via Conditional Diffusion Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Wei, J.; Gan, L.; Tang, W.; Li, M.; Song, Y. Diffusion models for spatio-temporal-spectral fusion of homogeneous Gaofen-1 satellite platforms. Int. J. Appl. Earth Obs. Geoinf. 2024, 128, 103752. [Google Scholar] [CrossRef]
- Han, W.; Li, J.; Wang, S.; Zhang, X.; Dong, Y.; Fan, R.; Zhang, X.; Wang, L. Geological Remote Sensing Interpretation Using Deep Learning Feature and an Adaptive Multisource Data Fusion Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Elizar, E.; Zulkifley, M.A.; Muharar, R.; Zaman, M.H.M.; Mustaza, S.M. A Review on Multiscale-Deep-Learning Applications. Sensors 2022, 22, 7384. [Google Scholar] [CrossRef]
- Swain, R.; Paul, A.; Behera, M.D. Spatio-temporal fusion methods for spectral remote sensing: A comprehensive technical review and comparative analysis. Trop. Ecol. 2023, 65, 356–375. [Google Scholar] [CrossRef]
- Xue, J.; Leung, Y.; Fung, T. A Bayesian Data Fusion Approach to Spatio-Temporal Fusion of Remotely Sensed Images. Remote Sens. 2017, 9, 1310. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, J.; Chen, X.; Zhu, X.; Qiu, Y.; Song, H.; Rao, Y.; Zhang, C.; Cao, X.; Cui, X. Sensitivity of six typical spatiotemporal fusion methods to different influential factors: A comparative study for a normalized difference vegetation index time series reconstruction. Remote Sens. Environ. 2021, 252, 112130. [Google Scholar] [CrossRef]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep learning in multimodal remote sensing data fusion: A comprehensive review. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102926. [Google Scholar] [CrossRef]
- Zhu, X.; Zhan, W.; Zhou, J.; Chen, X.; Liang, Z.; Xu, S.; Chen, J. A novel framework to assess all-round performances of spatiotemporal fusion models. Remote Sens. Environ. 2022, 274, 113002. [Google Scholar] [CrossRef]
- Guo, D.; Shi, W.; Qian, F.; Wang, S.; Cai, C. Monitoring the spatiotemporal change of Dongting Lake wetland by integrating Landsat and MODIS images, from 2001 to 2020. Ecol. Inform. 2022, 72, 101848. [Google Scholar] [CrossRef]
- Emelyanova, I.V.; McVicar, T.R.; Van Niel, T.G.; Li, L.T.; Van Dijk, A.I. Assessing the accuracy of blending Landsat—MODIS surface reflectances in two landscapes with contrasting spatial and temporal dynamics: A framework for algorithm selection. Remote Sens. Environ. 2013, 133, 193–209. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; He, L.; Chen, J.; Plaza, A. Spatio-temporal fusion for remote sensing data: An overview and new benchmark. Sci. China Inf. Sci. 2020, 63, 140301. [Google Scholar] [CrossRef]
- Guo, D.; Shi, W. Object-Level Hybrid Spatiotemporal Fusion: Reaching a Better Tradeoff Among Spectral Accuracy, Spatial Accuracy, and Efficiency. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8007–8021. [Google Scholar] [CrossRef]
- Tasar, O.; Tarabalka, Y.; Alliez, P. Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3524–3537. [Google Scholar] [CrossRef]
- Yin, M.; Chen, Z.; Zhang, C. A CNN-Transformer Network Combining CBAM for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 2406. [Google Scholar] [CrossRef]





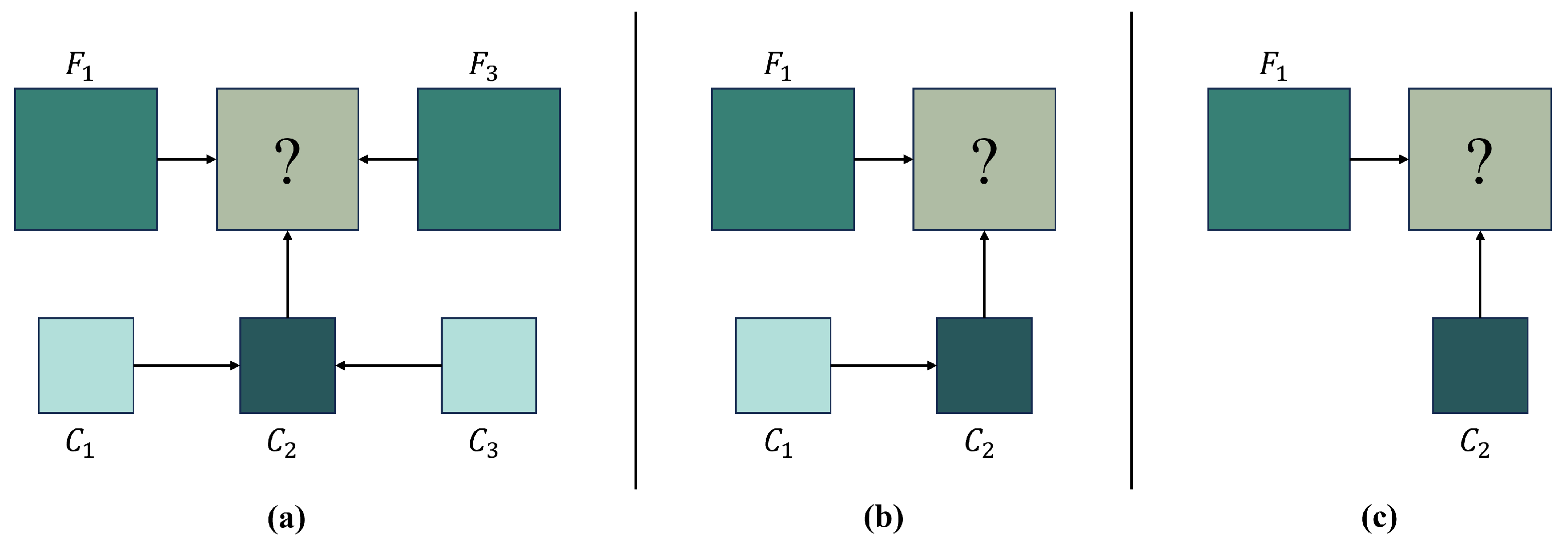




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Method | Year | Method | |
|---|---|---|---|---|
| Conventional CNN-based | 2018 | STFDCNN [33] | 2021 | MCDNet [34] |
| 2019 | VDCN [35] | 2022 | LTSC3D [36] | |
| 2019 | ESRCNN [37] | 2022 | MUSTFN [38] | |
| 2019 | StfNet [39] | 2022 | MSTTIFN [40] | |
| 2020 | DL-SDFM [41] | 2024 | CIG-STF [42] | |
| 2020 | BiaSTF [43] | |||
| Residual CNN-based | 2019 | DCSTFN [26] | 2022 | STFDSC [44] |
| 2019 | EDCSTFN [45] | 2022 | Li et al. [46] | |
| 2019 | Li et al. [47] | 2022 | Hoque et al. [48] | |
| 2020 | DMNet [49] | 2022 | MTDL-STF [50] | |
| 2020 | STF3DCNN [51] | 2022 | ERDN [52] | |
| 2020 | ResStf [53] | 2022 | TSDTSF [54] | |
| 2021 | HDLSFM [55] | 2022 | DPSTFN [56] | |
| 2021 | Htitiou et al. [57] | 2022 | Wei et al. [58] | |
| 2021 | MOST [59] | 2023 | STFRDN [60] | |
| 2021 | ACFNet [61] | 2023 | UAV-Net [62] | |
| 2021 | BASNet [63] | 2024 | Zeng et al. [64] | |
| 2021 | STTFN [65] | 2024 | STFNet [66] | |
| 2022 | STFMCNN [67] | |||
| Attentional CNN-based | 2021 | AMNet [68] | 2022 | DSTFN [69] |
| 2021 | ASRCNN [70] | 2023 | RCAN [71] | |
| 2022 | PDCNN [72] | 2023 | CAFE [73] | |
| 2022 | SL-STIF [74] | 2023 | DSTFNet [75] | |
| 2022 | STF-EGFA [76] | 2024 | SIFnet [77] | |
| 2022 | SCRnet [78] | 2024 | ECPW-STFN [79] | |
| 2022 | MANet [80] | 2024 | RCAN-FSDAF [81] |
| Year | Method | Year | Method |
|---|---|---|---|
| 2020 | CycleGAN -STF [89] | 2022 | RSFN [90] |
| 2021 | SSTSTF [91] | 2022 | SMPG [92] |
| 2021 | GANSTFM [27] | 2023 | MCBAM-GAN [93] |
| 2021 | STFGAN [94] | 2023 | AMS-STF [95] |
| 2021 | TLSRSTF [96] | 2023 | DSFN [97] |
| 2022 | DRCGAN [98] | 2023 | EDRGAN-STF [99] |
| 2022 | PSTAF-GAN [100] | 2023 | BPF-MGAN [101] |
| 2022 | MOSTGAN [102] | 2024 | StarFusion [103] |
| 2022 | GASTFN [104] | 2024 | Sun et al. [105] |
| 2022 | MLFF-GAN [106] | 2024 | Weng et al. [107] |
| 2022 | OPGAN [108] |
| Year | Method | Year | Method |
|---|---|---|---|
| 2021 | MSNet [28] | 2022 | MSFusion [111] |
| 2022 | SwinSTFM [112] | 2023 | SMSTFM [113] |
| 2022 | EMSNet [114] | 2024 | STF-Trans [115] |
| 2022 | DBTT-FM [100] | 2024 | STM-STFNet [116] |
| Year | Method |
|---|---|
| 2024 | STFDiff [29] |
| 2024 | DiffSTF [122] |
| 2024 | DiffSTSF [123] |
| Type | Method | Link |
|---|---|---|
| CNN-based | EDCSTFN | https://github.com/theonegis/edcstfn (accessed on 11 February 2025) |
| GAN-based | GANSTFM | https://github.com/theonegis/ganstfm (accessed on 11 February 2025) |
| Transformer-based | SwinSTFM | https://github.com/LouisChen0104/swinstfm (accessed on 11 February 2025) |
| Diffusion-based | STFDiff | https://github.com/prowDIY/STF (accessed on 11 February 2025) |
| EDCSTFN | GANSTFM | SwinSTFM | STFDiff | ||
|---|---|---|---|---|---|
| RMSE | Min | 0.0217 | 0.0209 | 0.0198 | 0.0232 |
| Max | 0.0507 | 0.0357 | 0.0256 | ||
| Avg | 0.0319 | 0.0276 | 0.0231 | ||
| SSIM | Min | 0.7936 | 0.7818 | 0.7579 | 0.8844 |
| Max | 0.9094 | 0.8933 | 0.8683 | ||
| Avg | 0.8525 | 0.8471 | 0.8434 | ||
| CC | Min | 0.8427 | 0.8169 | 0.8574 | 0.9018 |
| Max | 0.8580 | 0.8562 | 0.9190 | ||
| Avg | 0.8517 | 0.8375 | 0.8809 | ||
| SAM | Min | 0.0678 | 0.0532 | 0.0572 | 0.0734 |
| Max | 0.0839 | 0.1046 | 0.0914 | ||
| Avg | 0.0764 | 0.0879 | 0.0746 | ||
| ERGAS | Min | 1.0677 | 0.1955 | 0.1754 | 1.0732 |
| Max | 2.6280 | 2.6675 | 2.5728 | ||
| Avg | 1.6315 | 1.3399 | 1.1842 |
| EDCSTFN | GANSTFM | SwinSTFM | STFDiff | ||
|---|---|---|---|---|---|
| RMSE | Min | 0.0168 | 0.0167 | 0.0174 | 0.0169 |
| Max | 0.0359 | 0.0319 | 0.0280 | ||
| Avg | 0.0279 | 0.0258 | 0.0222 | ||
| SSIM | Min | 0.7585 | 0.6290 | 0.7470 | 0.9429 |
| Max | 0.9585 | 0.8972 | 0.8997 | ||
| Avg | 0.8228 | 0.7984 | 0.8336 | ||
| CC | Min | 0.7993 | 0.7517 | 0.8065 | 0.9286 |
| Max | 0.9195 | 0.8395 | 0.9412 | ||
| Avg | 0.8612 | 0.7956 | 0.8630 | ||
| SAM | Min | 0.0515 | 0.0593 | 0.0539 | 0.0536 |
| Max | 0.1382 | 0.1769 | 0.1474 | ||
| Avg | 0.1064 | 0.1275 | 0.1043 | ||
| ERGAS | Min | 0.8180 | 0.1336 | 0.1310 | 0.7258 |
| Max | 3.2709 | 3.3205 | 3.1502 | ||
| Avg | 1.6504 | 1.6581 | 1.4844 |
| Method | Parameters |
|---|---|
| EDCSTFN | 280,000 |
| GANSTFM | 4,180,000 |
| SwinSTFM | 39,665,893 |
| STFDiff | 4,590,000 |
| Datasets | Year | Data Source | Citations |
|---|---|---|---|
| CIA [132] | 2013 | Landsat-7|MODIS | 77 |
| LGC [132] | Landsat-5|MODIS | 73 | |
| AHB [133] | 2020 | Landsat-8|MODIS | 12 |
| DX [133] | 6 | ||
| TJ [133] | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, Z.; Zhan, Y.; Zhang, W.; Wang, Z.; Liu, W.; Huang, X. Recent Advances in Deep Learning-Based Spatiotemporal Fusion Methods for Remote Sensing Images. Sensors 2025, 25, 1093. https://doi.org/10.3390/s25041093
Lian Z, Zhan Y, Zhang W, Wang Z, Liu W, Huang X. Recent Advances in Deep Learning-Based Spatiotemporal Fusion Methods for Remote Sensing Images. Sensors. 2025; 25(4):1093. https://doi.org/10.3390/s25041093
Chicago/Turabian StyleLian, Zilong, Yulin Zhan, Wenhao Zhang, Zhangjie Wang, Wenbo Liu, and Xuhan Huang. 2025. "Recent Advances in Deep Learning-Based Spatiotemporal Fusion Methods for Remote Sensing Images" Sensors 25, no. 4: 1093. https://doi.org/10.3390/s25041093
APA StyleLian, Z., Zhan, Y., Zhang, W., Wang, Z., Liu, W., & Huang, X. (2025). Recent Advances in Deep Learning-Based Spatiotemporal Fusion Methods for Remote Sensing Images. Sensors, 25(4), 1093. https://doi.org/10.3390/s25041093