
SPS-RCNN: Semantic-Guided Proposal Sampling for 3D Object Detection from LiDAR Point Clouds


Abstract
1. Introduction
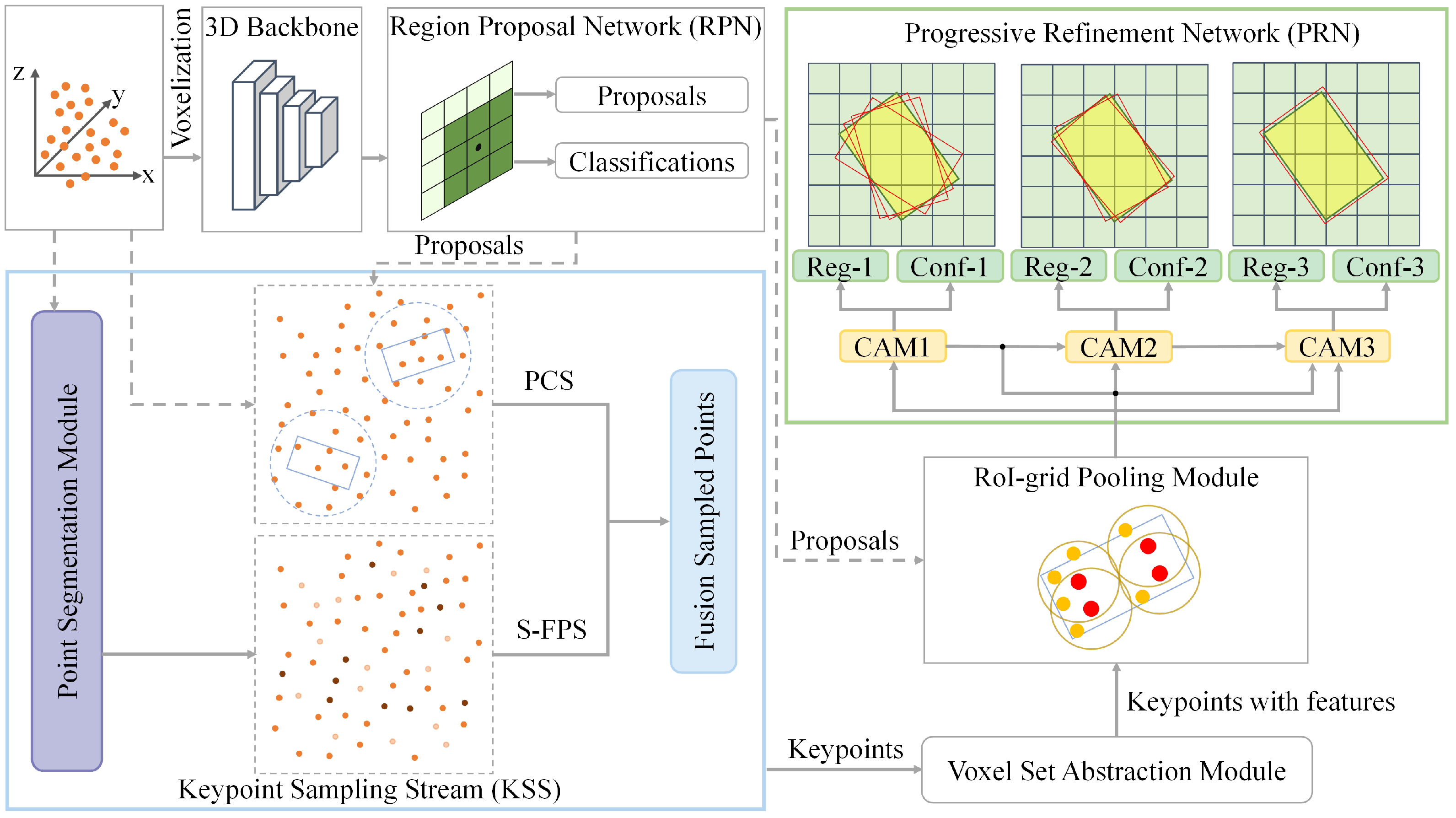
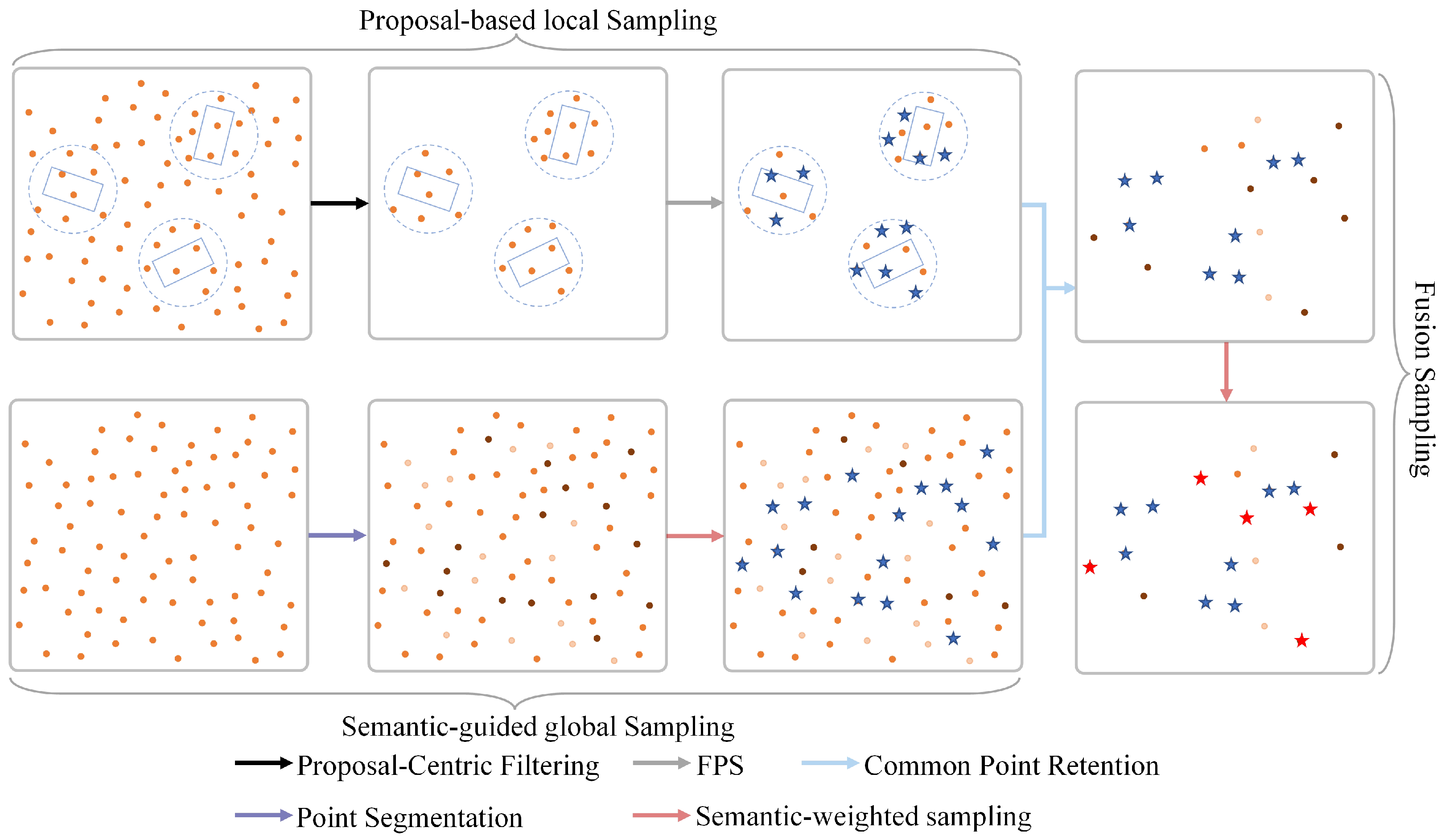
- In the downsampling stage, we propose semantic-guided proposal sampling (SPS), which integrates global and local sampling methods. For global sampling, distance values weighted by semantic information enhance the representativeness of keypoints, while local sampling refines FPS within the region around the proposal. Through global–local multilevel fusion sampling, SPS achieves a balanced and highly expressive keypoint distribution.
- In the proposal refinement stage, we introduce CAM to aggregate multi-stage object features. This module enhances proposal refinement accuracy by progressively improving the proposal quality at each stage.
2. Related Work
2.1. Point-Based Sampling Algorithm
2.2. Point/Voxel-Based 3D Object Detection
2.3. Multistage Network for Object Detection
3. Methods
3.1. Overview
3.2. Three-Dimensional Backbone for Proposal Generation
3.3. Semantic-Guided Proposal Sampling
3.4. Progressive Refinement Network
3.5. Training Losses
4. Experiments
4.1. Dataset and Evaluation Metrics
4.2. Implementation Details
4.3. Evaluation on the KITTI Dataset
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, Z.; Liu, L.; Jia, F.; Luo, Y.; Jia, C.; Zhang, G.; Yang, L.; Wang, L. Robustness-aware 3d object detection in autonomous driving: A review and outlook. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15407–15436. [Google Scholar] [CrossRef]
- Ma, X.; Ouyang, W.; Simonelli, A.; Ricci, E. 3d object detection from images for autonomous driving: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 46, 3537–3556. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Hu, Q.; Xu, K.; Wan, J.; Guo, Y. V2P-SSD: Single-stage 3-D object detection with voxel-to-point transformation. IEEE Geosci. Remote. Sens. Lett. 2023, 20, 6500805. [Google Scholar] [CrossRef]
- Yang, H.; Wang, W.; Chen, M.; Lin, B.; He, T.; Chen, H.; He, X.; Ouyang, W. Pvt-ssd: Single-stage 3d object detector with point-voxel transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13476–13487. [Google Scholar]
- Tong, G.; Li, Z.; Peng, H.; Wang, Y. Multi-source features fusion single stage 3D object detection with transformer. IEEE Robot. Autom. Lett. 2023, 8, 2062–2069. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, Y.; Zhao, D.; Xiao, L.; Dai, B.; Min, C.; Zhang, J.; Nie, Y.; Lu, D. MT-SSD: Single-Stage 3D Object Detector Based on Magnification Transformation. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Koo, I.; Lee, I.; Kim, S.H.; Kim, H.S.; Jeon, W.J.; Kim, C. PG-RCNN: Semantic surface point generation for 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 18142–18151. [Google Scholar]
- Feng, C.; Xiang, C.; Xie, X.; Zhang, Y.; Yang, M.; Li, X. HPV-RCNN: Hybrid Point–Voxel Two-Stage Network for LiDAR Based 3-D Object Detection. IEEE Trans. Comput. Soc. Syst. 2023, 10, 3066–3076. [Google Scholar] [CrossRef]
- Sun, F.; Tong, G.; Song, Y. Efficient flexible voxel-based two-stage network for 3D object detection in autonomous driving. Appl. Soft Comput. 2024, 2024, 111856. [Google Scholar] [CrossRef]
- Tao, M.; Zhao, C.; Wang, J.; Tang, M. ImFusion: Boosting Two-stage 3D Object Detection via Image Candidates. IEEE Signal Process. Lett. 2023, 31, 241–245. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, Y.; Zheng, Z.; Hu, H.; Chen, D. HybridPillars: Hybrid Point-Pillar Network for Real-time Two-stage 3D Object Detection. IEEE Sens. J. 2024, 24, 38318–38328. [Google Scholar] [CrossRef]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Z.; Zhang, J.; Tao, D. Sasa: Semantics-augmented set abstraction for point-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 221–229. [Google Scholar]
- Fan, B.; Zhang, K.; Tian, J. Hcpvf: Hierarchical cascaded point-voxel fusion for 3D object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 8997–9009. [Google Scholar] [CrossRef]
- Cai, Q.; Pan, Y.; Yao, T.; Mei, T. 3d cascade rcnn: High quality object detection in point clouds. arXiv 2022, arXiv:2211.08248. [Google Scholar] [CrossRef]
- Wu, H.; Deng, J.; Wen, C.; Li, X.; Wang, C.; Li, J. CasA: A cascade attention network for 3-D object detection from LiDAR point clouds. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5704511. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Shi, G.; Wang, K.; Li, R.; Ma, C. Real-time point cloud object detection via voxel-point geometry abstraction. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5971–5982. [Google Scholar] [CrossRef]
- Zheng, Z.; Huang, Z.; Zhao, J.; Hu, H.; Chen, D. DTSSD: Dual-channel transformer-based network for point-based 3D object detection. IEEE Signal Process. Lett. 2023, 30, 798–802. [Google Scholar] [CrossRef]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3d object detection with pointformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7463–7472. [Google Scholar]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not all points are equal: Learning highly efficient point-based detectors for 3D lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18953–18962. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Chen, Y.; Yan, F.; Yin, Z.; Nie, L.; Tao, B.; Miao, M.; Zheng, N.; Zhang, P.; Zeng, J. Robust LiDAR-Camera 3D Object Detection with Object-level Feature Fusion. IEEE Sens. J. 2024, 24, 29108–29120. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, Y.; Wen, J.; Wang, P.; Cai, X. An object detection algorithm combining semantic and geometric information of the 3D point cloud. Adv. Eng. Inform. 2023, 56, 101971. [Google Scholar] [CrossRef]
- He, X.; Wang, Z.; Lin, J.; Nai, K.; Yuan, J.; Li, Z. DO-SA&R: Distant Object Augmented Set Abstraction and Regression for Point-Based 3D Object Detection. IEEE Trans. Image Process. 2023, 32, 5852–5864. [Google Scholar]
- Dong, S.; Kong, X.; Pan, X.; Tang, F.; Li, W.; Chang, Y.; Dong, W. Semantic-context graph network for point-based 3D object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6474–6486. [Google Scholar] [CrossRef]
- Wang, H.; Shi, S.; Yang, Z.; Fang, R.; Qian, Q.; Li, H.; Schiele, B.; Wang, L. Rbgnet: Ray-based grouping for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1110–1119. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- An, P.; Duan, Y.; Huang, Y.; Ma, J.; Chen, Y.; Wang, L.; Yang, Y.; Liu, Q. Sp-det: Leveraging saliency prediction for voxel-based 3D object detection in sparse point cloud. IEEE Trans. Multimed. 2023, 26, 2795–2808. [Google Scholar] [CrossRef]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Wu, P.; Gu, L.; Yan, X.; Xie, H.; Wang, F.L.; Cheng, G.; Wei, M. PV-RCNN++: Semantical point-voxel feature interaction for 3D object detection. Vis. Comput. 2023, 39, 2425–2440. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Wang, T.; Borji, A.; Wei, G.; Lu, H. A multistage refinement network for salient object detection. IEEE Trans. Image Process. 2020, 29, 3534–3545. [Google Scholar] [CrossRef]
- Ye, M.; Ke, L.; Li, S.; Tai, Y.W.; Tang, C.K.; Danelljan, M.; Yu, F. Cascade-DETR: Delving into high-quality universal object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6704–6714. [Google Scholar]
- Meng, Q.; Wang, W.; Zhou, T.; Shen, J.; Jia, Y.; Van Gool, L. Towards a weakly supervised framework for 3D point cloud object detection and annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4454–4468. [Google Scholar] [CrossRef] [PubMed]
- Lu, B.; Sun, Y.; Yang, Z.; Song, R.; Jiang, H.; Liu, Y. HRNet: 3D object detection network for point cloud with hierarchical refinement. Pattern Recognit. 2024, 149, 110254. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, T.; Li, B.; Chen, X.; Wang, X.; Bai, X. Epnet++: Cascade bi-directional fusion for multi-modal 3D object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 8324–8341. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 12697–12705. [Google Scholar]
- Vaswani, A. Attention is all you need. In Advances in Neural Information Processing Systems; Curran Associates: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Chen, Y.; Li, Y.; Zhang, X.; Sun, J.; Jia, J. Focal sparse convolutional networks for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5428–5437. [Google Scholar]
- OD Team. Openpcdet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. OD Team. 2020. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 28 October 2024).
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3D object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11677–11684. [Google Scholar]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.W. Cia-ssd: Confident iou-aware single-stage object detector from point cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 3555–3562. [Google Scholar]
- Li, B.; Chen, J.; Li, X.; Xu, R.; Li, Q.; Cao, Y.; Wu, J.; Qu, L.; Li, Y.; Diniz, P.S. VFL3D: A Single-Stage Fine-Grained Lightweight Point Cloud 3D Object Detection Algorithm Based on Voxels. IEEE Trans. Intell. Transp. Syst. 2024, 25, 12034–12048. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3D object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–52. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 720–736. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1711–1719. [Google Scholar]
- Noh, J.; Lee, S.; Ham, B. Hvpr: Hybrid voxel-point representation for single-stage 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14605–14614. [Google Scholar]
- Jiang, T.; Song, N.; Liu, H.; Yin, R.; Gong, Y.; Yao, J. VIC-Net: Voxelization information compensation network for point cloud 3D object detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13408–13414. [Google Scholar]
- Qian, R.; Lai, X.; Li, X. BADet: Boundary-aware 3D object detection from point clouds. Pattern Recognit. 2022, 125, 108524. [Google Scholar] [CrossRef]
- He, Q.; Wang, Z.; Zeng, H.; Zeng, Y.; Liu, Y. Svga-net: Sparse voxel-graph attention network for 3d object detection from point clouds. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 870–878. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Specification |
|---|---|
| CPU | Intel® Xeon(R) Silver 4210R CPU |
| GPU | NVIDIA RTX 3090 × 2 |
| GPU Memory | 48 G |
| Operating System | Ubuntu 20.04 |
| Deep Learning Framework | PyTorch 1.8.1 |
| Python Version | 3.8 |
| CUDA Version | 11.1 |
| cuDNN Version | 8.0 |
| Code Editor | Visual Studio Code |
| Library | OpenPCDet |
| Method | Reference | Car 3D AP (%) | ||
|---|---|---|---|---|
| Easy | Moderate | Hard | ||
| SECOND [41] | Sensors 2018 | 88.61 | 78.62 | 77.22 |
| PointPillars [42] | CVPR 2019 | 86.62 | 76.06 | 68.91 |
| PointRCNN [31] | CVPR 2019 | 88.88 | 78.63 | 77.38 |
| 3DSSD [24] | CVPR 2020 | 89.71 | 79.45 | 78.67 |
| Part-A2 [47] | TPAMI 2020 | 89.47 | 79.47 | 78.54 |
| TANet [48] | AAAI 2020 | 87.52 | 76.64 | 73.86 |
| Voxel-RCNN [33] | AAAI 2021 | 89.41 | 84.52 | 78.93 |
| CIA-SSD [49] | AAAI 2021 | 89.59 | 80.28 | 72.87 |
| MFT-SSD [5] | RAL 2023 | 89.35 | 84.46 | 78.55 |
| VFL3D [50] | TITS 2024 | 89.10 | 84.50 | 78.63 |
| PV-RCNN [19] | CVPR 2020 | 89.35 | 83.90 | 78.70 |
| SPS-RCNN | - | 89.87 | 85.96 | 79.13 |
| Improvement (baseline) | +0.52 | +2.06 | +0.43 | |
| Method | Reference | Car 3D AP (%) | Cyc. 3D AP (%) | ||||
|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | ||
| LIDAR + RGB | |||||||
| MV3D [51] | CVPR 2017 | 74.97 | 63.63 | 54.00 | - | - | - |
| F-PointNet [52] | CVPR 2018 | 82.19 | 69.79 | 60.59 | 72.27 | 56.12 | 49.01 |
| UberATG-MMF [53] | CVPR 2019 | 88.40 | 77.43 | 70.22 | - | - | - |
| EPNet [54] | ECCV 2020 | 89.81 | 79.28 | 74.59 | - | - | - |
| 3D-CVF [55] | ECCV 2020 | 89.20 | 80.05 | 73.11 | - | - | - |
| LIDAR | |||||||
| SECOND [41] | Sensors 2018 | 83.34 | 72.55 | 65.82 | 75.83 | 60.82 | 53.67 |
| PointPillars [42] | CVPR 2019 | 82.58 | 74.31 | 68.99 | 77.10 | 58.65 | 51.92 |
| PointRCNN [31] | CVPR 2019 | 86.96 | 75.64 | 70.70 | 74.96 | 58.82 | 52.53 |
| 3DSSD [24] | CVPR 2020 | 88.36 | 79.57 | 74.55 | - | - | - |
| Point-GNN [56] | CVPR 2020 | 88.33 | 79.47 | 72.29 | 78.60 | 63.48 | 57.08 |
| Part-A2 [47] | TPAMI 2020 | 87.81 | 78.49 | 73.51 | 79.17 | 63.52 | 56.93 |
| TANet [48] | AAAI 2021 | 83.81 | 75.38 | 67.66 | 75.70 | 59.44 | 52.53 |
| CIA-SSD [49] | AAAI 2021 | 89.59 | 80.28 | 72.87 | - | - | - |
| Voxel-RCNN [33] | AAAI 2021 | 90.90 | 81.62 | 77.06 | - | - | - |
| HVPR [57] | CVPR 2021 | 86.38 | 77.92 | 73.04 | - | - | - |
| VIC-Net [58] | ICRA 2021 | 88.25 | 80.61 | 75.83 | 78.29 | 63.65 | 57.27 |
| BADet [59] | PR 2022 | 89.28 | 81.61 | 76.58 | - | - | - |
| SVGA-Net [60] | AAAI 2022 | 87.33 | 80.47 | 75.91 | 78.58 | 62.28 | 54.88 |
| IA-SSD [23] | CVPR 2022 | 88.87 | 80.32 | 75.10 | 80.78 | 66.01 | 58.12 |
| PV-RCNN [19] | CVPR 2020 | 90.25 | 81.43 | 76.82 | 78.60 | 63.71 | 57.65 |
| SPS-RCNN | - | 89.60 | 81.97 | 77.21 | 80.66 | 64.32 | 59.68 |
| Improvement (baseline) | −0.65 | +0.54 | +0.39 | +2.06 | +0.61 | +2.03 | |
| Methods | AP3D (%) | ||
|---|---|---|---|
| Easy | Mod. | Hard | |
| PV-RCNN | 92.57 | 84.83 | 82.69 |
| PV-RCNN + PCS | 91.95 | 84.85 | 82.60 |
| PV-RCNN + S-FPS | 92.67 | 85.26 | 83.12 |
| PV-RCNN + SPS | 92.79 | 85.49 | 83.19 |
| Stages | AP3D (%) | ||
|---|---|---|---|
| Easy | Mod. | Hard | |
| 1 | 89.83 | 84.53 | 81.97 |
| 2 | 92.12 | 85.96 | 83.04 |
| 3 | 91.78 | 86.01 | 83.26 |
| FPS | SPS | CAM | AP3D (%) | #Params | Runtime |
|---|---|---|---|---|---|
| ✓ | 84.83 | 6.58 M | 48 ms | ||
| ✓ | 85.49 | 6.72 M | 55 ms | ||
| ✓ | ✓ | 86.01 | 7.14 M | 62 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Yang, L.; Zhao, S.; Tao, S.; Tian, X.; Liu, K. SPS-RCNN: Semantic-Guided Proposal Sampling for 3D Object Detection from LiDAR Point Clouds. Sensors 2025, 25, 1064. https://doi.org/10.3390/s25041064
Xu H, Yang L, Zhao S, Tao S, Tian X, Liu K. SPS-RCNN: Semantic-Guided Proposal Sampling for 3D Object Detection from LiDAR Point Clouds. Sensors. 2025; 25(4):1064. https://doi.org/10.3390/s25041064
Chicago/Turabian StyleXu, Hengxin, Lei Yang, Shengya Zhao, Shan Tao, Xinran Tian, and Kun Liu. 2025. "SPS-RCNN: Semantic-Guided Proposal Sampling for 3D Object Detection from LiDAR Point Clouds" Sensors 25, no. 4: 1064. https://doi.org/10.3390/s25041064
APA StyleXu, H., Yang, L., Zhao, S., Tao, S., Tian, X., & Liu, K. (2025). SPS-RCNN: Semantic-Guided Proposal Sampling for 3D Object Detection from LiDAR Point Clouds. Sensors, 25(4), 1064. https://doi.org/10.3390/s25041064