1. Introduction
Climate change, urbanization, fossil fuel energy consumption, and other factors have exacerbated air pollution and related public health issues [
1,
2]. Effective Air Quality (AQ) monitoring is vital for safeguarding public health, especially in densely populated urban areas where pollution levels are often higher. Traditional high-cost, high-maintenance AQ monitoring systems, while accurate, are often limited in geographic coverage and flexibility, making comprehensive AQ monitoring and surveillance challenging. Recent advancements in sensor technology and manufacturing have seen a rise in the application of low-cost sensors (LCSs), which offer broader geographic coverage.
The advent of LCSs presents a transformative challenge and opportunity to enhance AQ monitoring. Purple Air (PA) sensors, one type of low-cost sensor, have gained prominence due to their affordability, ease of deployment, and timely readings [
3]. However, the practical utilization of these sensors is significantly compromised by their low accuracy and reliability under different environmental and manmade conditions [
3], and they often require calibration to match the accuracy of traditional systems [
4].
PA sensors operate using an optical sensing principle, specifically, laser-based light scattering. Each sensor contains a low-cost laser particle counter that detects airborne particulate matter by illuminating these particles with a laser and measuring the intensity of the scattered light [
5]. Specifically, PA sensors utilize the PMS*003 series laser particle sensor, which, unlike many commercial sensors, can measure particulate matter (PM) in three size ranges: PM
1.0 (particles with a diameter of less than 1.0 μm), PM
2.5 (less than 2.5 μm) and PM
10 (less than 10 μm). Their detection range is 0.3–10 µm, with a resolution of 0.3 µm. The performance can also be affected by high humidity, and they record environmental variables such as temperature, humidity, and pressure for further processing. These sensors also include dual laser systems, allowing for cross-validation and improved data quality.
For this study, we focused on PM
2.5, particulate matter with a diameter of less than 2.5 μm, which can penetrate deep into the respiratory tract and enter the bloodstream, causing health risks, including respiratory, cardiovascular, and neurological diseases [
6]. However, the AI/ML approach will not be applicable in instances where particle sizes are smaller than 300 nm, as this is a physical limitation of existing sensor technologies. Monitoring PM
2.5 is necessary for assessing exposure and implementing strategies to mitigate public health impacts. Large amounts of PA data are available, and previous studies have proved the potential of machine learning (ML) approaches to improve accuracy [
7]. Calibration is one of the first investigated methods that has been using AI/ML to correct inherent sensor biases and ensure the comparability of data across different sensors and environments. However, the challenge with PM
2.5 calibration lies in its sensitivity to ambient environmental changes, such as relative humidity and temperature, which can negatively impact sensor performance and accuracy [
8]. Although previous studies (such as [
4,
9]) have explored ML models for sensor calibration, none has yet provided a comprehensive comparison across as many models and environment variables as this study proposes, nor covered entire sensor networks over a large geographic area.
In this study, fine-tuning refers to the process of making adjustments to ensure correct readings from devices, while calibration is defined as the preliminary step of establishing the relationship between a measured value and a device’s indicated value. Calibration is a preliminary step before tuning. Although we focused on fine-tuning to achieve accurate PM2.5 measurements, we refer to this process as calibration, in alignment with the existing literature.
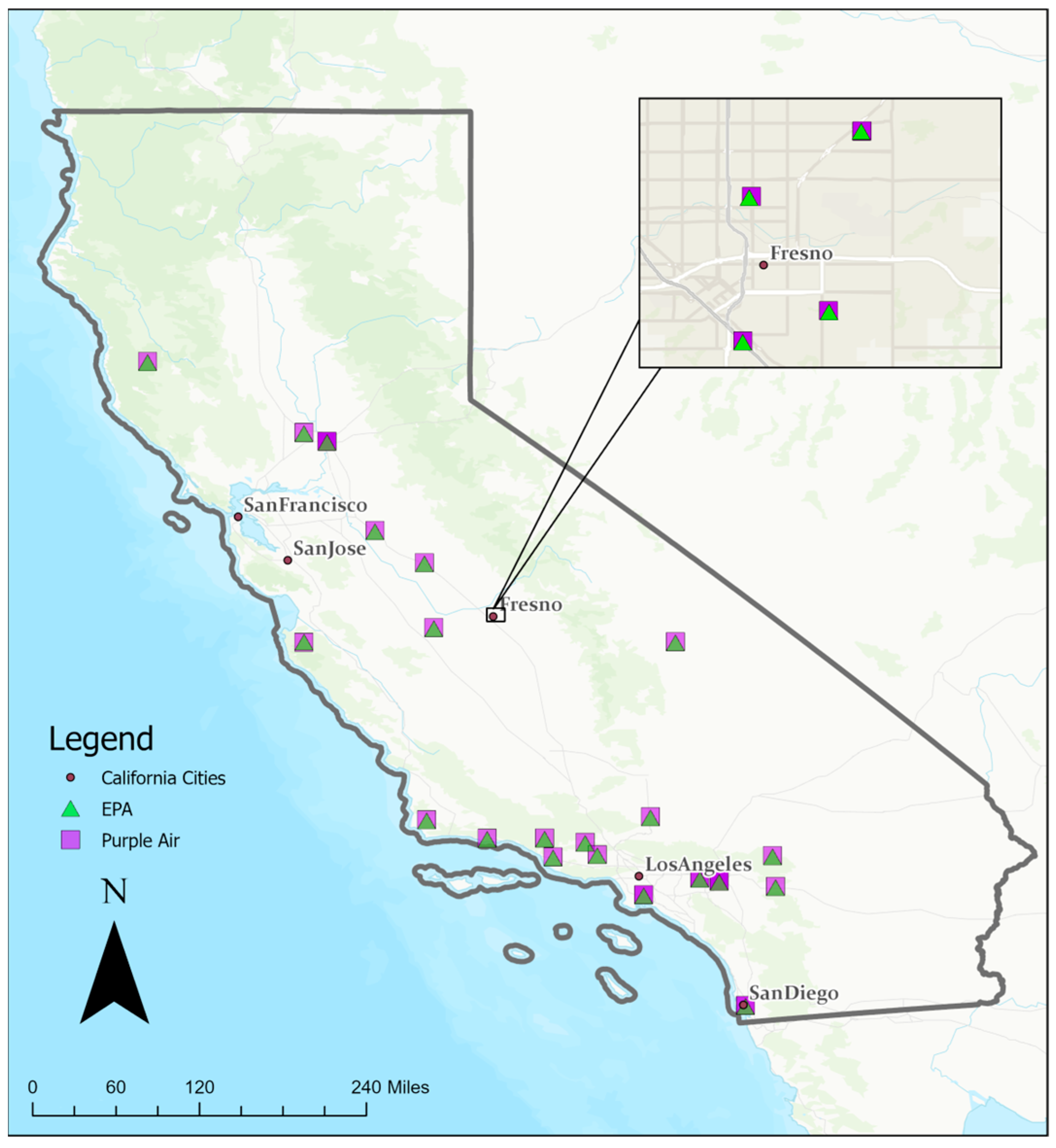
This study focused on the Los Angeles region, selected due to its high density of PA sensors compared to other regions. This area encompasses a mixture of urban, industrial, and residential zones, providing a diverse range of air quality conditions for a more comprehensive evaluation of sensor performance across different environmental settings.
In general, this study sought to bridge the gap between the affordability of LCS and the precision required for scientific and regulatory purposes. Our objective was to systematically evaluate AI/ML models and software packages to identify the most effective model and software package for improving the accuracy of low-cost sensor (LCS) measurements. Each of the AI/ML models was tested to identify the optimal model and package. In total, 64 pairs of Purple Air (LCS) and EPA sensors were used in this study, with the validated EPA measurements as ground truth. Eleven regression models were systematically considered across four Python-based software packages: XGBoost, Scikit-learn, TensorFlow, and PyTorch, as well as a fifth R-based IDE, RStudio. The models in this study included Decision Tree Regressor (DTR), Random Forest (RF), K-Nearest Neighbor, XGBRegressor, Support Vector Regression (SVR), Simple Neural Network (SNN), Deep Neural Network (DNN), Long Short-Term Memory (LSTM) neural network, Recurrent Neural Network (RNN), Ordinary Least Square Regression (OLS), and Least Absolute Shrinkage and Selection Operator (Lasso) regression. The details are provided in the following five sections:
Section 2 reviews existing calibration methods conducted using both traditional calibration techniques (field and laboratory methods) and recent advancements involving empirical and geophysical ML models.
Section 3 introduces the study area, data, and pre-processing for the PA sensors.
Section 4 reports the experimental results.
Section 5 presents the results and
Section 6 discusses the reasons for model performance differences, comparisons with existing studies, limitations, and future research directions.
3. Data and Methodology
3.1. Training Data Preparation
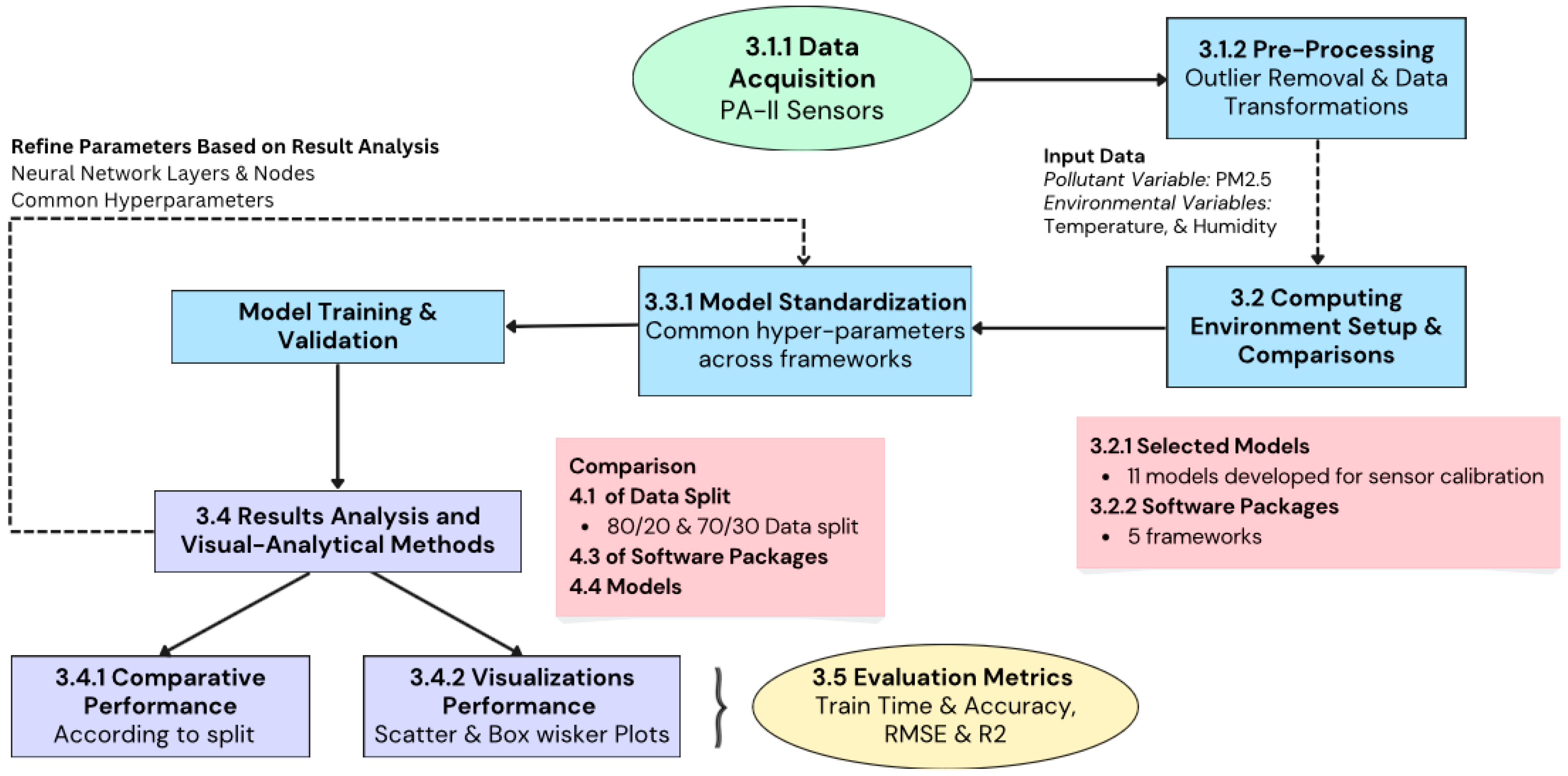
Figure 1 illustrates a detailed workflow of our study, starting from data acquisition and pre-processing, through model standardization and training, to results analysis and visualization. After step 3.4, where metrics were produced by the different software packages across computing environments, visualizations were produced using RStudio’s ggplot2 library. These visualizations enabled a thorough comparative performance analysis according to different splits, software packages, and models.
3.1.1. Data Acquisition
We downloaded the PA-II sensor data (PMS-5003) and relevant pressure, temperature, and humidity data (AQMD, 2016). Data were kept on two database tables: a sensor table and a reading table. We also utilized data from the U.S. Environmental Protection Agency (EPA) as a benchmark to ensure the accuracy and reliability of our study [
44]. EPA sensors utilize Federal Reference Methods (FRMs) and Federal Equivalent Methods (FEMs) [
45] to ensure accurate and reliable measurements of PM. These methods involve stringent quality assurance and control (QA/QC) protocols, gravimetric analysis, regular calibration, and strict adherence to regulatory standards. The EPA’s monitoring stations continuously collect data that undergo rigorous validation before being used to determine compliance with National Ambient Air Quality Standards (NAAQS) [
45]. Given these processes, EPA data are often considered the gold standard, making them an essential reference for comparing non-regulated sensors.
Data were kept on two database tables: a sensor table and a reading table. The sensor table included metadata including hardware component information, unique sensor ID, geographic location, and indoor/outdoor placement. The reading table stored continuous time series data for each sensor, with sensor IDs as primary keys to link the records in both tables. The date attribute was set in UTC for all measurements including pollutant and environmental variables. The table included two types of PM variables: ATM (where Calibration Factor = Atmosphere) and CF_1 (where Calibration Factor = 1) for three target pollutants: PM
1.0, PM
2.5, and PM
10. CF_1 used the “average particle density” for indoor PM and CF_ATM used the “average particle density” for outdoor PM. The PA sensors utilized in this study were outdoor sensors. We identified 64 sensor pairs across California for a total of 876,831 data entries from 10 July 2017 to 1 September 2022 (
Figure 2). These 64 sensor pairs consisted of 64 unique PA sensors and 25 unique EPA sensors; these sensors were paired based on their proximity to one another. These sensor pairs were mostly within 10 m of one another, and the furthest distance was below 100 m.
3.1.2. Data Pre-Processing
Data preprocessing utilized a threshold of >0.7 Pearson correlation coefficient between “epa_pm25” and “pm25_cf_1” to ensure a strong linear relationship. Next, data were aggregated from a two-minute temporal resolution into an hourly resolution and adjusted for local time zones. Sensor malfunctions such as readings exceeding 500 were removed, as were data records with missing information from either the “pm25_cf_1_a” or “pm25_cf_1_b” columns. Additionally, readings with a zero 5 h moving standard deviation in either channel were removed as this indicated potential sensor issues. Finally, we applied a dual-channel agreement criterion grouped by year and month. The data were then reduced to the following columns: “datetime”, “pm25_cf_1”, “humidity”, and “temperature”, which composed the training data.
For the LSTM and RNN models, we created sequences using the previous 23 h of data for each sensor. For all models, we then split the data into training and testing sets and scaled them using a standard scaler in a random fashion.
3.2. Computing Environmental Setups and Comparisons
For this study, we tested 11 ML models across 5 different packages: Scikit (1.3.2), XGBoost (2.0.2), Pytorch (1.13.1), TensorFlow (2.13), and RStudio (2023.09.1 running R4.3.2). These packages were chosen for their respective strengths and popularity in the academic community. We utilized the same training data and models across each package, all on a consistent machine configuration featuring Microsoft Windows 11 Enterprise OS, a 13th gen Intel(R) Core (TM) i7-13700 at 2100 MHz, 16 cores, 24 logical processors, and 32 GB of RAM. After a thorough analysis and literature review of models supported by each package, we selected 11 AI/ML models suitable for the calibration task (
Table 1).
3.2.1. Selected Models
The 11 regression and ML models (detailed in
Appendix A as DTR, RF, kNN, XGBRegressor, SVR, SNN, DNN, LSTM, RNN, OLS, and Lasso) that supported calibration required two types of independent and target variables represented by X and Y, respectively, with the goal of mapping a function such that y = f(x_n) + ε, where ε is the degree of error and x_n encapsulates more than one independent variable (e.g., temperature and relative humidity). The strong correlation between temperature and relative humidity could introduce multicollinearity into the model, which could complicate the estimation of the individual effects of these variables on the target outcome. In traditional regression models, this multicollinearity can lead to the inflated variance of the coefficient estimates, potentially resulting in less reliable predictions. However, in the context of the 11 ML models, they were designed to handle such correlations more robustly, either by regularization techniques, e.g., Lasso regression, or by leveraging the complex interrelationships among the variables, e.g., RF, XGBoost, thus minimizing the adverse effects of multicollinearity on the calibration process. We applied regression algorithms to develop similar functions that described the impact of the input variables (measurements) from in situ PA sensors against the measurements aligning with the EPA readings.
3.3. Software Packages
The five packages included XGBoost, Scikit-Learn, TensorFlow, PyTorch, and RStudio, as detailed in
Appendix B.
Each of the five packages offers unique strengths and limitations, and each available model in the five packages was used to identify the best-suited model and package for PM2.5 calibration. For our systematic study, the packages, models, and training data were tested to obtain comprehensive analyses. The training process was repeated 10 times for each experiment, and we calculated an average value for the performance metrics (R2 and RMSE).
Note: How PyTorch and TensorFlow implemented the OLS Model:
PyTorch and TensorFlow employed an SNN to define the OLS regression model. Neural networks process simple sequences of feed-forward layers [
46]. However, these two packages differ in how they define the model and add layers. TensorFlow utilizes a sequential API for model definition, while PyTorch uses a class-based approach [
47]. Moreover, in TensorFlow, the computational graph is a static computation graph, while PyTorch uses a dynamic computation graph. The performance gap between the two packages may stem from differences in these computation graph implementations. Nodes represent the neutral network layers, while edges carry the data as tensors [
48].
Model Configuration Standardization Across Packages
For comparability across packages and models, we standardize model configuration and hyperparameters for each model. For neural network architectures, we standardized the number and type of layers and the number of nodes of each layer across packages compatible with each model. For several models, such as XGBoost and DTRs, it was not possible to completely standardize models across packages because each software and associated package utilized different hyperparameters. In these cases, we used default hyperparameters unique to each package and ensured that common hyperparameter values across packages were the same. Each model can have dozens of hyper-parameters, we only include those hyper-parameters which were common across packages (
Table 2).
The model configuration standardization used the hyperparameters displayed in
Table 2 and included the following four aspects:
Model Configuration: Each model was configured using the default hyperparameter settings provided in their documentation to ensure that they were consistent across all packages. In cases where there were no default hyperparameter settings listed, we set hyperparameters to be equal to the most frequently occurring hyperparameter for that setting. This approach ensured consistency across implementations while maintaining the integrity of each model’s intended configuration. For neural network models, the number and type of layers, the number of nodes per layer, activation functions, and optimization methods were standardized. For tree-based models and regressions, parameters like tree depth, learning rates, and regularization terms were kept consistent.
Data Preparation: Data input into each model were prepared using a standard preprocessing pipeline. This involved scaling features, handling missing data, and transforming temporal data into sequences for time series models like LSTM models.
Training and Test Splits: The data were split into training and testing sets, using both 80/20 and 70/30 splits to ensure consistency across all experiments.
Computation Environment: All models were trained on a consistent hardware setup to eliminate variations in computing resources.
3.4. Results and Visual–Analytical Methods
3.4.1. Comparative Performance Across Models and Packages
We evaluated each model and package based on two key criteria: time to train and accuracy (RMSE and R2). Averaging the performance metrics (R2 and RMSE) from 10 runs of each model provided insight into which packages delivered higher accuracy and reliability. This allowed us to consider both the ability of a particular configuration to accurately calibrate LCS and their suitability for various applications. We identified which models offered the best trade-off between training time and predictive accuracy.
We also considered the influence of the package (e.g., RStudio) and model (e.g., LSTM) on results. These factors were highly intertwined, and the performance of a particular setup depended on both the package and ML model. As such, we took a two-pronged approach to analyze the results. First, we assessed the average performance of a model across all packages or a package across all models. Then, we assessed the effect that package choice had by comparing each model’s relative performance across all packages. By considering each model individually and comparing the difference in results when training in one package or another, we could better analyze the influence of package and model choice.
3.4.2. Visual–Analytical Methods
To succinctly convey our findings, we employed several visual–analytical methods using the “ggplot2” package in RStudio:
Line and bar graphs were used to plot the performance metrics for the 70/30 and 80/20 splits across all models and packages, illustrating the differences and their consistency.
A series of box and whisker plots were used to depict the range and distribution of performance scores within each package. This visualization highlighted the internal variability and helped identify packages that generally over- or underperformed.
Model-specific performance was displayed using both box and whisker plots and point charts. The box plots provided a clear view of variability within each model category, while the point charts detailed how model performance correlated with package choice, effectively illustrating package compatibility and model robustness.
These visual analytics together with the model evaluations can help to refine the selection process for future modeling efforts and ensure that the most effective model/package is chosen for AQ calibration tasks.
3.5. Evaluation Metrics
This study utilized the evaluation metrics Root Mean Square Error (RMSE) and Coefficient of Determination (R2) to evaluate the fit of the PM2.5 calibration models against the EPA data used as a benchmark.
The
RMSE was calculated using the formula
where
yi represents the actual PM
2.5 values from the EPA data, ŷ
i denotes the predicted calibrated PM
2.5 values from the model, and
n is the number of spatiotemporal data points. This metric measured the average magnitude of the errors between the model’s predictions and the actual benchmark EPA data. A lower
RMSE value indicated a model with higher accuracy, reflecting a closer fit to the benchmark.
The Coefficient of Determination, denoted as
R2, was given by
In this formula, RSS is the sum of the squares of residuals—the difference between the actual and predicted values—and TSS is the total sum of the squares—the difference between the actual values and their mean value. R2 represents the proportion of variance in the observed EPA PM2.5 levels that was predictable from the models. An R2 value close to 1 suggested that the model had a high degree of explanatory power, aligning well with the variability observed in the EPA dataset.
For a comprehensive understanding of the model’s performance, the RMSE and R2 were obtained. The RMSE provided a direct measure of prediction accuracy, while the R2 offered insight into how well the model captured the overall variance in the EPA dataset. Together, these metrics were crucial for validating the effectiveness of the calibrated PM2.5 models in replicating the benchmark data. The RMSE was more resistant to systematic adjustment errors than R2 and, as such, was used as the primary metric.
Furthermore, we investigated the training time for different models to identify “sweet spots”—models that were exceptionally accurate compared to their training time. This analysis is crucial for optimizing model selection in practical scenarios where both time and accuracy are critical constraints.
4. Experiments and Results
To obtain a comprehensive result, we implemented a series of experiments to compare the impacts of training/testing data splits, packages, and ML models on accuracy and computing time.
4.1. Training and Testing Data Splits
The popular training data splits of 80/20 and 70/30 were examined. The choice of an 80/20 vs. a 70/30 split was found to have minimal impact across models and packages where splits were random, while there was a 2.2% difference in R
2 performance and a 3% difference in RMSE performance in the 80/20 vs. the 70/30 LSTM model where splits were sequential. The mean difference between the two splits in RMSE across all models and packages was 0.051 µg/m
3 and the mean difference in R
2 was 0.00381; there was a mean percent difference of 1.55% for RMSE and a mean percent difference of 0.745% for R
2 across all packages and models (
Figure 3).
The largest difference between the 70/30 and 80/20 splits in terms of RMSE was for DNNs in PyTorch, with an absolute difference of 0.51 µg/m
3; the largest difference in terms of R
2 was 0.020 for SNN in PyTorch. This translated to percent differences of 9.75% and 2.83%, respectively. Of the 35 model/package combinations tested, 29 had a difference below 2% for RMSE and 33 had a percent difference below 2% for R
2 (
Figure 3).
While the differences between splits were minimal (
Figure 3), the 80/20 split (mean R
2 = 0.750, mean RMSE = 5.46 µg/m
3) slightly outperformed the 70/30 split (mean R
2 = 0.746, mean RMSE = 5.51 µg/m
3) on average. Therefore, we used the 80/20 split to compare the packages and models.
4.2. Software Package Comparison
When considering the performance of all models (
Figure 4), TensorFlow (mean R
2 = 0.773) and RStudio (mean R
2 = 0.756) outperformed the other packages, none of which had an average R
2 above 0.736. This success was driven in part by the strong performance of LSTM in these packages. Apart from RNN, the top-performing packages across models in terms of maximum R
2 were RStudio and TensorFlow. PyTorch produced the best model for RNN (R
2 = 0.7658), slightly edging out TensorFlow (R
2 = 0.7657). Conversely, XGBoost and Scikit-Learn did not produce the best results for any of the models tested. TensorFlow emerged as a package particularly well-suited to the calibration task because every model that TensorFlow supported produced either the best or second-best R
2 (
Figure 3).
However, it is important to note that in cases where a model was compatible with several different packages, the difference in performance between the best and second-best packages was negligible. When considering only models that were compatible with three or more packages, the average percent difference in R2 between the top-performing package and the worst-performing package across all models was 6.09%. However, the percentage difference between the top-performing packages and the second-best packages was only 0.96%.
This suggests that while packages did have a significant effect on performance, for each model, multiple potential packages could produce effective results.
Because not every model was available for every package, comparing overall performance did not fully capture the variation between packages. By considering the relative performance of individual models between packages, we could better elucidate which model and package combination was best suited to the calibration task. While many of the models were consistent across packages, there were some notable outliers. OLS regression displayed the largest difference in performance across packages in terms of R
2, with a percentage difference of 10.06% between the best-performing package (TensorFlow) and the worst-performing package (PyTorch). This difference could be attributed to the different methods that these packages used to calculate linear regression, as discussed in
Section 3.2. DTR, LSTM, and SNN all saw a percentage absolute difference of 9% to 10% for R
2 between the best-performing and worst-performing models. Other models had a percentage absolute difference between 1% and 5% across packages (
Table 3).
The effect of package choice was even more pronounced when considering the RMSE. For example, the absolute percent difference between LSTM when training in the worst-performing package, PyTorch, and in the best-performing package, TensorFlow, was 19.3% (
Table 4). In certain cases, like LSTM, the selection of packages could have a significant effect on performance, even when the same model was selected. The best performing model is highlighted in bold in
Table 4.
While LSTM produced the best results in all packages that supported the model, it was significantly more accurate when trained in RStudio and TensorFlow than in PyTorch (
Table 3 and
Table 4). It is unsurprising that RStudio and TensorFlow exhibited notably similar performances because LSTM in RStudio was powered by TensorFlow.
The time and performance differences between PyTorch and TensorFlow may have been the result of the different ways that the two packages implemented the models. TensorFlow incorporates parameters within the model compilation process through Keras. In contrast, in PyTorch parameters are instantiated as variables and incorporated into custom training loops, as opposed to the more streamlined .fit() method utilized in TensorFlow [
49]. Furthermore, PyTorch employs a dynamic computation graph for the seamless tracking of operations, while the TensorFlow static computational graph requires explicit directives [
47]. PyTorch leverages an automatic differentiation engine to compute derivatives and gradients of computations. Moreover, PyTorch’s DataLoader class offers a way to load and preprocess data, thus reducing the time required for data loading.
4.3. Model Comparison
Each model’s performance was determined by the model itself and the supporting package. However, the model chosen had a greater overall effect on accuracy than which package was selected. Certain models generally outperformed or underperformed regardless of package.
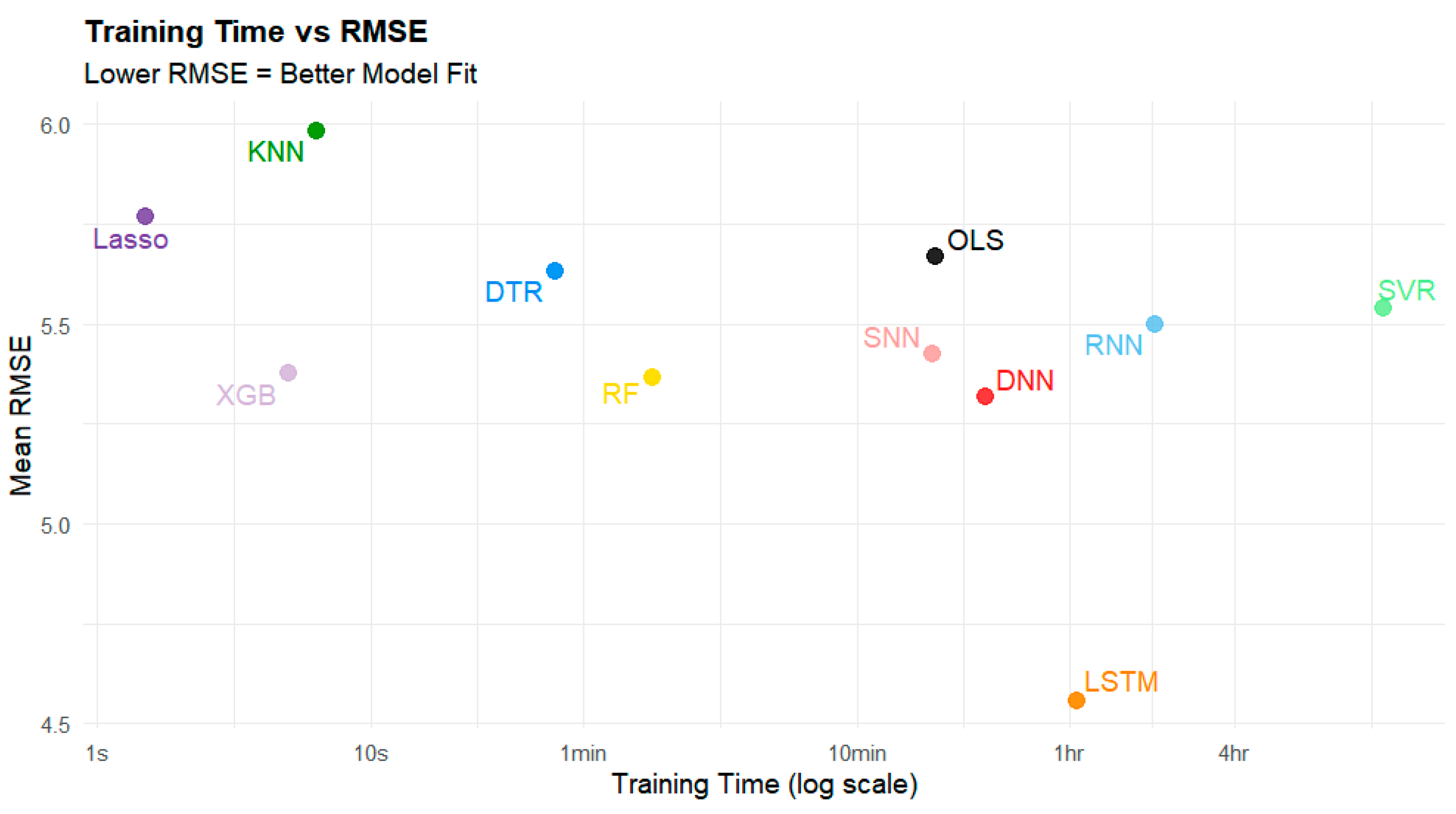
The top-performing model by average R
2 and RMSE across software packages was LSTM, which outperformed all other models by a large margin (R
2 = 0.832, RMSE = 4.55 µg/m
3) (
Table 3 and
Table 4). LSTM and RNN are a type of neural network specifically designed for time series modeling and incorporate past data to support predictions of future sensor values [
50].
Compared to LSTM, all other models significantly underperformed. Variation in performance among the remaining models was relatively minor (
Figure 5). In fact, the gap in mean R
2 (0.07) between LSTM and the second-best model, RF, was larger than the gap between RF to the worst-performing model, KNN (0.06) (
Table 3). The same pattern held true for the RMSE. The gap between LSTM and the second-best model in terms of mean RMSE, DNN, was 0.76 µg/m
3. The difference between DNN and KNN was 0.66 µg/m
3.
Table 4 and
Table 5 summarize the percentage difference in R
2 and RMSE between models when considering the best-performing packages for each model. The percentage difference between each model’s best performer compared to the median performer, SNN, and the worst performer, KNN, is included. While LSTM outperformed the median by 11.48% in terms of R
2, none of the other models was more than 7% different from the median. In fact, 8 of the 11 models had an R
2 within 3% of the median performance. When comparing models to the worst performer, the same trend was evident. While LSTM had an R
2 18.46% higher than the worst performer, no other model outperformed the minimum by more than 9.1%. The same pattern held true for the RMSE, although there was slightly more variance between the models. LSTM again was by far the best performer, with a 23% lower RMSE value than the median model (DNN by this metric). All other models were within 10.6% of the median, and 8 of the 11 models were within 5% of the median value (
Table 6).
While these models displayed a relatively minor difference in performance in terms of R
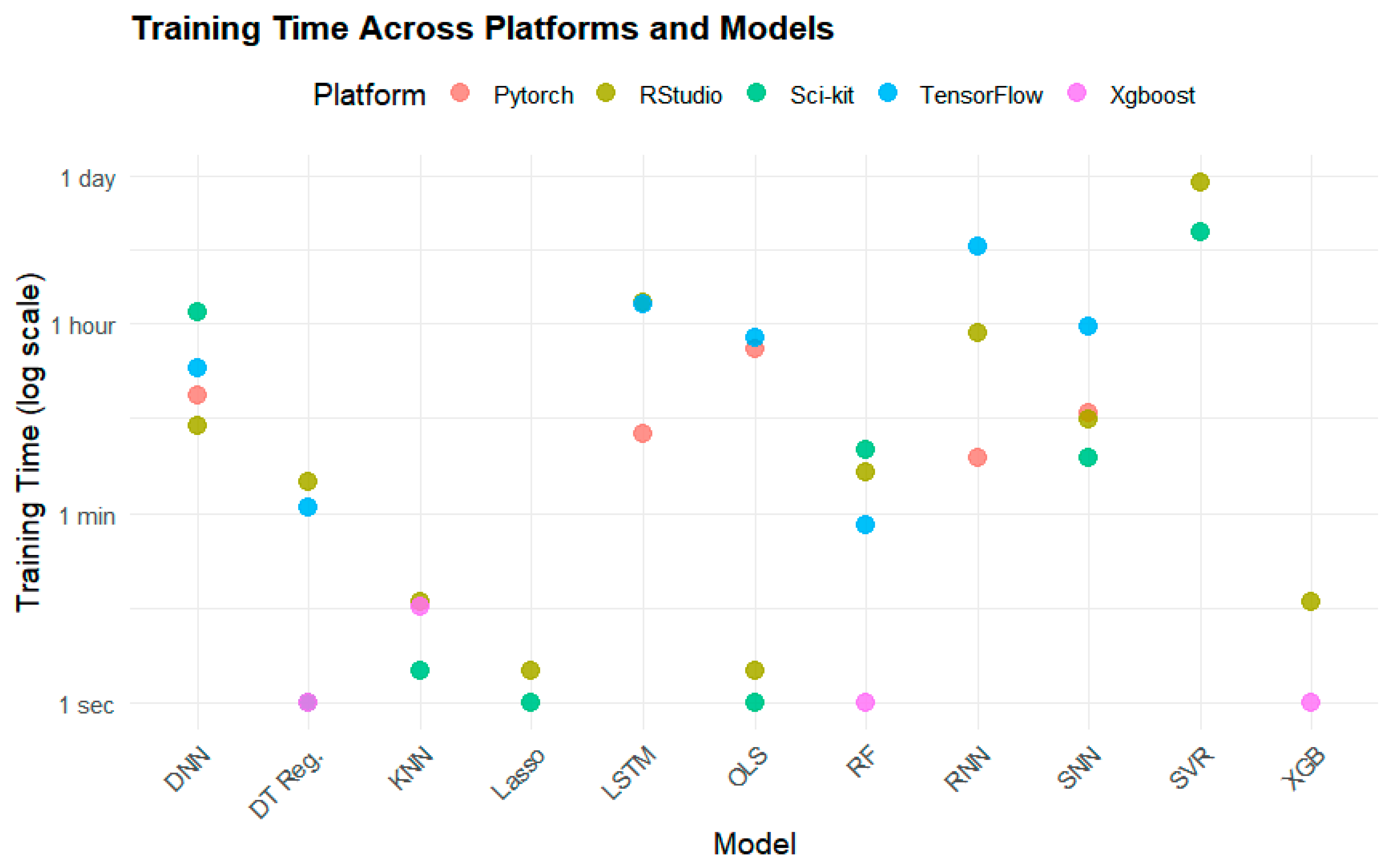
2 and RMSE, their training time was vastly different.
Figure 6 demonstrates the elapsed training time across these models. For example, XGBoost took only 5 s to train on average, while SVR took 13 h, 45 min, and 17 s to train (
Table 7).
While LSTM produced a high R
2 value, it took significantly longer to train than most other models (
Figure 6,
Table 7, where NA means not applicable). The fastest models to train were DTR, XGBoost, RF, KNN, and Lasso, all of which took less than two minutes to train. Among these models, XGBoost (0.7612, 5.377 µg/m
3) and RF (0.7632, 5.366 µg/m
3) performed the best in terms of R
2 and RMSE (
Figure 7).
These results indicate that the LSTM model in TensorFlow and RStudio provided the highest accuracy, making it suitable for real-time AQ monitoring applications, where high precision is crucial.
6. Conclusions
This paper reported a systematic investigation of the suitability of five popular software packages and 11 ML models for LCS AQ data calibration. Our investigation revealed that the choice of training/testing split—80/20 vs. 70/30—had minimal impact on the performance across various models and packages. The percentage difference between the model split performance (R2) averaged as 0.745% and, therefore, we focused on the 80/20 split for a detailed comparison in subsequent analyses.
In the package comparison, RStudio and TensorFlow were the top performers, particularly excelling with LSTM models. Their performance showed R2 scores of 0.8578 and 0.857 and low RMSEs of 4.2518 µg/m3 and 4.26 µg/m3, respectively. Their strong ability to process high-volume data and capture complex relationships with neural network models such as LSTM was evident. However, while RStudio outperformed TensorFlow by 0.09% for LSTM, TensorFlow typically outperformed RStudio for every other model by 1.7%, averaging an R2 of 0.773 in TensorFlow and 0.756 in RStudio.
The choice of packages affected the outcomes when the same models were implemented across different packages. For example, the performance discrepancies in OLS regression across packages underscored the influence of software-specific implementations on model efficacy. When averaging across all models, R2 scores varied by 6.09% between the most and least accurate packages.
This study also highlighted the importance of selecting the appropriate combination of model and package based on the specific requirements of the task. While some packages showed a broad range in performance, packages like Scikit-Learn showed less variability, indicating a more consistent handling of the models. While the choice of model generally had a greater impact on performance than the package, the nuances in how each package processed and trained the models could lead to significant variations in both accuracy and efficiency. For example, while LSTMs generally performed well, their implementation in TensorFlow consistently outperformed that in PyTorch. This highlights the differences in how these packages manage computation graphs.
In conclusion, the detailed insights gained from this research advocate for a context-driven approach in the selection of ML packages and models, ensuring that both model and package choices are optimally aligned to the specific needs and constraints of the predictive task. Across all experiments, two optimal approaches emerged. The overall best-performing model in terms of RMSE and R2 was clearly LSTM. However, LSTM algorithms are particularly time-intensive to train, each taking over one hour and thirty minutes to train a single model. In addition, preparing sequential training data is a somewhat computationally expensive process. LSTM’s computational demands may make it too slow or expensive to train for certain applications, such as those with large study areas or applications that require model training on the fly. The high computational load of LSTM models is particularly important to consider for in-depth explorations, such as hyperparameter tuning. The hyperparameter tuning of these models can require hundreds of training runs, leading to long calculation times. The results also suggest a second potential approach, indicated by the relatively high performance of tree-boosted models in comparison to their training time. XGBoost in RStudio and RF in TensorFlow both exhibited R2 values above 0.77, RMSE values below 5.3 µg/m3, and a time to train below one minute. In cases where computational resources are low or models need to be trained quickly on the fly, models such as RF and XGBRegressor may be more applicable than the top-performing time series models.
6.1. Limitations
We have presented a systematic calibration study for PM2.5 sensors with promising results. There are some limitations that can guide interpretations of the findings and future research. These limitations span the geographic and technological scope of sensor deployment, the pollutant species, computational constraints, and the limited available meteorological variables.
Sensor Pair Distribution: The current study utilized 64 sensor pairs from California, incorporating data from 25 unique EPA sensors. This limited geographic and technological scope may limit the broader applicability of the models, particularly for nationwide or larger-scale contexts. Further research could be conducted to determine the optimal scope and effectiveness of the trained models across diverse regions.
Pollutant Species: This calibration study was exclusively focused on PM2.5 and did not extend its methodology to other pollutants. The generalizability of the approach to additional pollutants, such as ozone or nitrogen dioxide, could be investigated through similar calibration efforts.
Sensor Technology: This study was confined to data collected from EPA and Purple Air sensors. While these sensors are widely used, the approach should be repeated when translating to other types of PM2.5 sensors or to sensors measuring different pollutants. Future studies should explore the calibration and performance of alternative sensor technologies to enhance this study’s applicability.
Computational Constraints: The calibration process was conducted using CPU-based processing, which required approximately one month of continuous runtime. This computational limitation suggests that further studies could benefit significantly from leveraging GPU-based processing to reduce runtime [
68]. Additionally, adopting containerization technologies such as Docker could streamline setup and configuration, thereby improving efficiency and reproducibility.
Meteorological Constraints: While this study accounted for the impact of temperature and humidity on sensor calibration, it did not consider other potentially influential meteorological factors, such as wind speed, wind direction, and atmospheric pressure. These features were either found to have marginal impacts in the case of pressure or were unavailable in the dataset such as in cases of wind speed and direction. Further studies with sensors that measure these variables could potentially further improve model accuracy.
6.2. Future Work
Though this study is extensive and systematic, four aspects need further investigation to best leverage AI/ML for air quality studies on various pollutants, data analytical components, and further improvements of accuracy for calibration:
Hyperparameter tuning should be able to further improve accuracy and reduce uncertainty but will require significant computing power and long durations of model training to investigate different combinations. LSTM emerged as the best-performing model in this study. We plan to further explore the application of this model, including detailed hyperparameter tuning/model optimization.
The incorporation of a broader set of evaluation metrics, including MAPE and additional robustness measures, could provide a more comprehensive assessment of model performance across conditions.
Different species of air pollutants may have different patterns so a systematic study on each of them might be needed for, e.g., NO
2 and ozone or methane, within various events such as wildfire and wars [
5,
79]. In situ sensors offer comprehensive temporal coverage but lack continuous geographic coverage; introducing the satellite retrieval of pollutants could complement air pollution detection.
Further exploration of other analytics such as data downscaling, upscaling, interoperation, and fusion to best replicate air pollution status is needed for overall air pollutants data integration.
To better facilitate systematic studies and extensive AI/ML model runs, an adaptable ML toolkit and potential Python package could be developed and packaged to speed up AQ and forecasting research.
Additionally, future studies should apply this methodology to datasets from various regions with different climates and pollution levels, as geographic location can significantly impact air quality patterns and model performance. This would help to validate the robustness and generalizability of the models under diverse conditions.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}