1. Introduction
In wireless communication systems, signals are transmitted from the source and received by a receiver sensor after passing through a communication channel. However, the presence of diverse forms of noise and fading in the channel introduces distortions, leading to disparities between the received signal and the originally transmitted signal. To address this issue, channel-coding techniques have been developed to detect and rectify errors in the transmitted data.
Convolutional codes, constituting one of the most crucial and extensive channel-coding schemes in digital communication systems [
1], assume a pivotal role in enhancing data transmission reliability over noisy and fading channels. Due to the indispensable nature of channel coding, the blind recognition of channel codes has found extensive application in fields such as electronic countermeasures [
2,
3] and adaptive modulation and coding (AMC) [
4,
5,
6]. Especially in non-cooperative scenarios, such as in electronic warfare, military, spectrum monitoring, signals intelligence, and communications intelligence systems, the receiver possesses limited knowledge regarding the coding type and parameters used by the sender [
7]. The blind estimation of the interception sequence is therefore necessary to determine the coding type and parameters accurately.
The transmission of convolutional codes is performed in a serial manner, enabling a more efficient utilization of storage space during the encoding process. However, the theoretical analysis of convolutional codes poses significantly greater challenges compared to linear block codes. Convolutional codes typically possess good error-correction capabilities, but error propagation may occur if the decoder incorrectly selects a wrong code or decoding path. The complexities highlighted here emphasize the significance of the precise recognition of convolutional codes. Convolutional code recognition and parameter estimation methods have predominantly relied on the Galois field GF(2). Hard decision-based convolutional code recognition methods have been extensively developed, enabling the recognition of various convolutional codes without necessitating prior knowledge [
8,
9]. Nevertheless, these approaches generally demonstrate limited resilience to noise.
Due to the suboptimal performance of convolutional code recognition under a low signal-to-noise ratio (SNR), there has been a shift towards parameter identification of convolutional codes using soft-decision signals, an area which is currently receiving more attention.
The analysis algorithm proposed in Reference [
10] utilizes soft bit information and investigates its efficacy on standard convolutional codes. However, the coding rates explored in the paper are somewhat limited, making it challenging to handle complex real-world environments. Reference [
11] presents a blind-recognition algorithm that utilizes soft information from the received sequence to estimate the posterior probability of syndromes. However, this approach encounters challenges in establishing a robust detection threshold.
With the rapid expansion in the amount of real-time data and the growing necessity for immediate decision-making, there has been an increased demand for efficient management and access to diverse, heterogeneous data [
12]. The advent of deep learning has provided new opportunities to address this demand, enabling the automation and optimization of various tasks in signal processing. For instance, it has been used to design adaptive filters [
13] and automatic noise reduction [
14], enhancing the robustness of communication systems. In channel coding, deep learning can perform channel code recognition by leveraging the information obtained from the demodulation output. Various deep neural networks, such as TextCNN [
15,
16], have been proposed for channel code recognition. The types of recognition involved, however, are significantly limited, and the accuracy is relatively low, particularly under low-SNR conditions. Additionally, a deep learning method based on deep residual networks [
17] has been proposed for blind recognition of convolutional code parameters from a given soft-decision sequence. However, this method fails to consider the possibility that the received encoded sequence may not start from the beginning of a complete codeword, which could impact the model’s recognition performance, especially in the presence of channel noise or other disturbances. To mitigate the issue of low accuracy associated with single-type neural networks, a novel channel recognition algorithm based on bi-directional long short-term memory (BiLSTM) and convolutional neural networks (CNN) has been proposed [
7]. However, it solely discriminates among specific types of convolutional codes, LDPC codes, and polar codes.
Table 1 summarizes the strengths and weaknesses of the various methods.
To enhance the recognition performance of channel coding, we implement an improved model architecture. The main contributions of this paper are as follows:
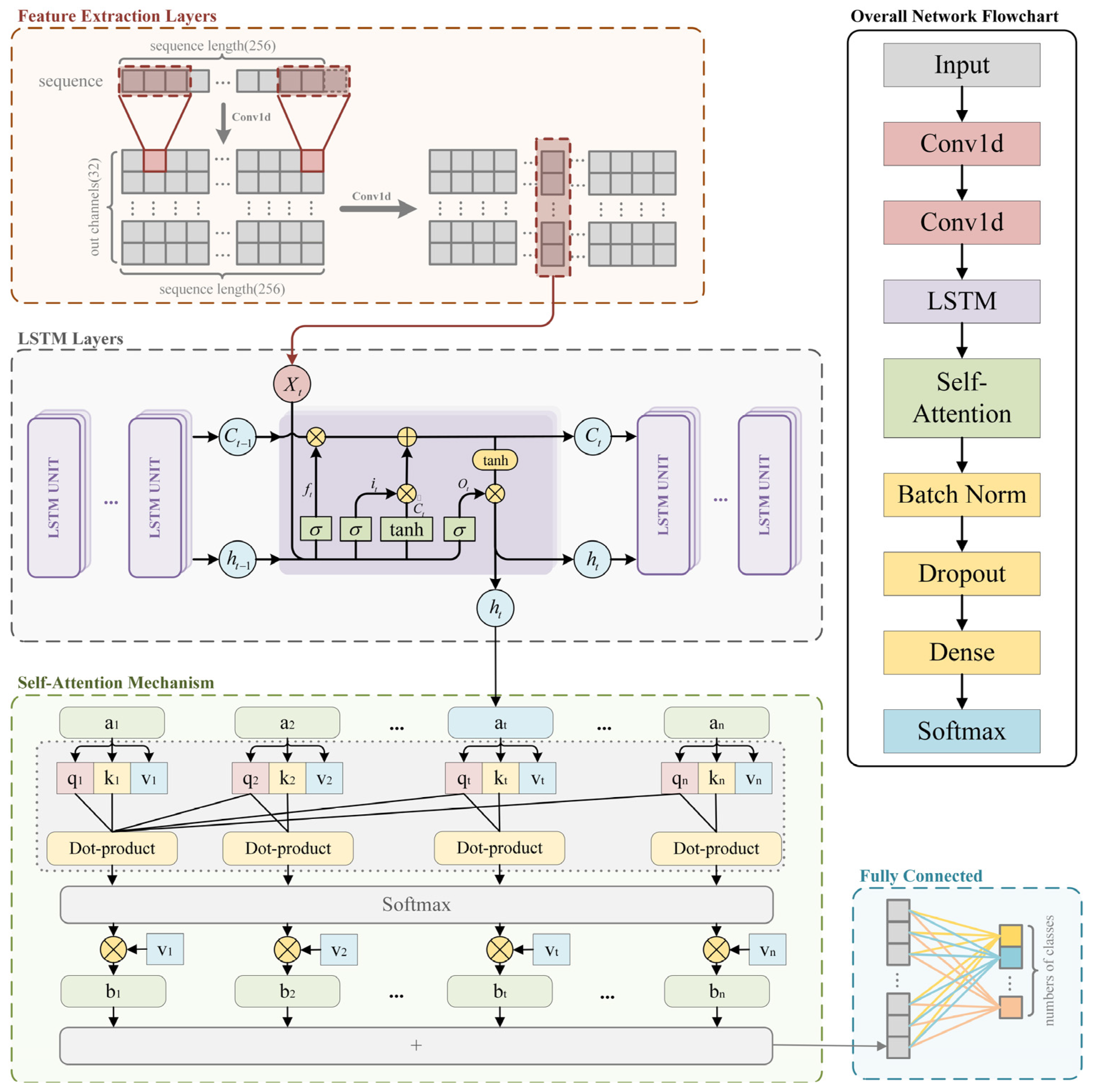
The ConvLSTM-TFN model is proposed, which seamlessly integrates convolutional layers [
18], LSTM networks [
19], and self-attention mechanisms [
20]. By synergistically leveraging the strengths of these deep learning modules, our model exhibits enhanced capability in capturing channel-coding features, making it applicable to a wider range of coding types.
We investigate the influence of input length, decision type (soft/hard), and constraint length on the accuracy of channel-coding recognition, utilizing convolutional codes as a case study. The advantages of soft-decision decoding and the broad applicability of this study within the field of coding are clarified.
A dataset is generated encompassing 17 distinct convolutional code parameters that include both soft- and hard-decision sequences, along with randomly assigned encoding starting positions. This approach offers a potential avenue for the development of channel-coding datasets.
The remaining sections of this paper are organized as follows.
Section 2 introduces the structure of a deep learning-based convolutional code blind-recognition system, along with an explanation of the basic theory of deep learning.
Section 3 describes the dataset used for the experiments and explores the application of a deep neural network for blind recognition of convolutional codes. In
Section 4, we analyze how different parameters affect the performance of our model in blind recognition on convolutional codes. Finally,
Section 5 concludes this paper and discusses future works.
2. System Model
In this study, we propose a signal transmission system specifically designed for the identification of channel-coding parameters.
Figure 1 illustrates the basic framework of a wireless communication system, wherein data undergo encoding, modulation, and transmission within the transmitting system. Subsequently, the dataset traverses a noisy wireless channel before being received at the other end, where it is demodulated and decoded. The channel code recognition module, highlighted in purple, constitutes a pivotal element within this system, as it assumes a central role in the identification of channel code types under non-cooperative communication settings.
In the following sections, we will explain the details of the transmitting and receiving systems, including the encoding scheme (convolutional coding) and modulation (BPSK), and the specific channel conditions assumed in this study (AWGN).
The message to be transmitted,
M = (
m1,
m2, …,
mk), is initially encoded into codewords
c = (
c1,
c2, …,
ck) with
n bits (
k <
n), using a convolutional coding scheme. The codeword
c is formed based on the generator matrix
G as follows:
Convolutional codes can be represented by a generator matrix. For a convolutional code
C(
n,
k,
l), the generator matrix typically takes the following form:
where
D represents a delay operator (commonly denoted as a shift register), and the generator polynomials, which consist of shift registers and modulo-2 addition.
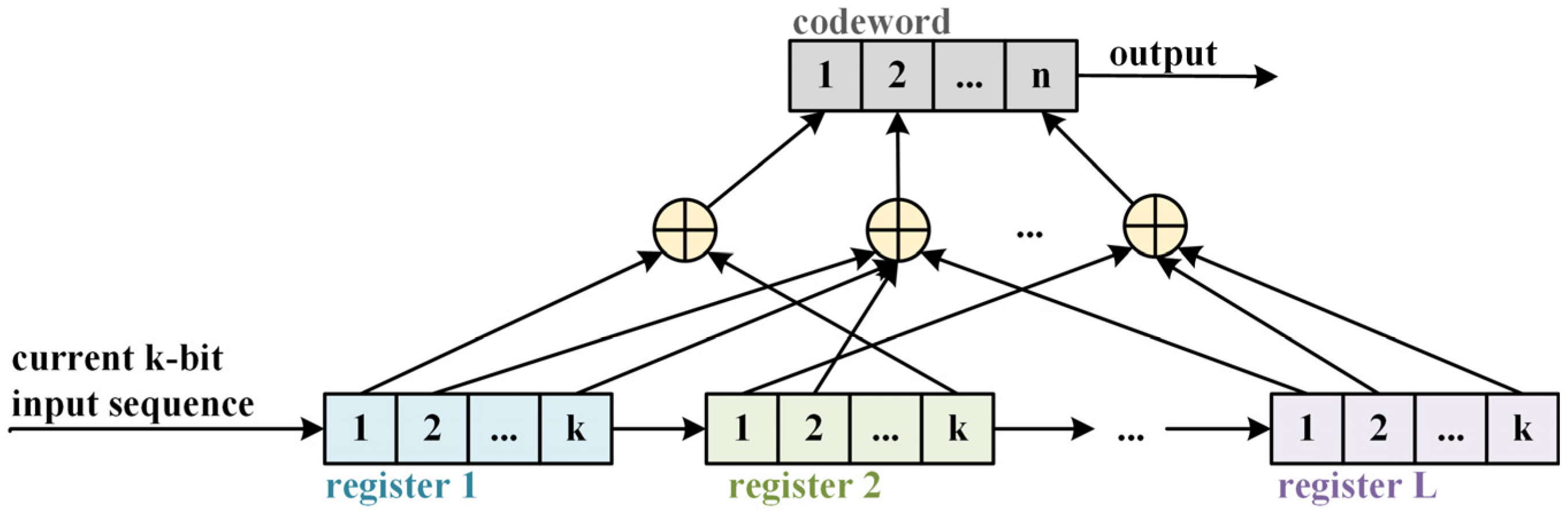
Figure 2 illustrates the structure of a convolutional code. The diagram depicts the register structure of the convolutional encoder, showing how the input bits are processed through a series of shift registers and modulo-2 adders to generate the output codeword.
In the figure, a convolutional encoder is depicted with L levels of information bits, where k input bits are processed at each time step, resulting in a total of k*L bits. At each step, n output bits are produced. It is evident that the output of these n bits depends not only on the current k input bits but also on the preceding L-1 groups of input information bits. Hence, convolutional codes exhibit memory characteristics with a memory depth of L.
After encoding, the modulation scheme employed is binary phase shift keying (BPSK), while the communication channel exhibits addictive white Gaussian noise (AWGN). The presence of AWGN introduces distortions to the received signal, thereby augmenting the probability of errors and posing challenges in accurately decoding the transmitted data.
At the receiver, due to the imperfections in the channel, transmitter, and receiver sensors, the received signal s′ is disturbed, resulting in the difference between the decoded information M′ and the original information M. Channel coding is one of the key methods used to mitigate these distortions. In low-SNR environments, achieving reliable demodulation often requires manually setting thresholds for optimal decision-making, which is a challenging task. Therefore, by utilizing soft decision rather than the hard decision results c′, we can automate the threshold adjustment, effectively improving the system’s robustness and enhancing its recognition accuracy. Simultaneously, we consider the situation in which the received encoded sequence is incomplete, a which implies that it may not start at the actual starting position of the encoded sequence. This adds complexity to the recognition of encoding types.
In this paper, we propose a method based on the ConvLSTM-TFN, which effectively addresses the task of identifying channel code parameters under low-SNR conditions. Our study specifically focuses on convolutional codes as the predefined channel-coding scheme and conducts parameter identification under an AWGN channel with BPSK modulation. Importantly, our proposed method is versatile and can be applied to identify parameters under different channels, modulation schemes, and coding methods. While we have chosen conditions specific to a single-channel code parameter identification task, our approach exhibits generalizability and potential for broader applications.
4. Experiment Evaluation
4.1. Experimental Environment and Evaluation Metrics
In this paper, the proposed model is developed and trained using PyTorch 2.0.1. The specific hyperparameters of the deep learning model are detailed in
Table 2. The model is trained and tested on a computer equipped with an AMD Ryzen 9 5950X 16-core processor, 32 threads, 32 GB of RAM, and an NVIDIA GeForce RTX 3090 Ti GPU.
For each experiment, we perform five runs and calculate the average of the results. The evaluation metrics include OA (overall accuracy), precision, and the F1 score, which provide a comprehensive assessment of the model’s performance across different aspects. These metrics are widely used for performance evaluation and can be computed using standard formulas, as outlined in [
25]. Since our dataset is evenly distributed, OA is equivalent to the recall value. Therefore, we do not include recall as a separate evaluation metric.
4.2. Impact of Data Characteristics
4.2.1. Impact of Sample Length on Performance
The length of input samples plays a critical role in the blind recognition of convolutional codes, as increasing the sequence length significantly increases both computational complexity and training time. To analyze the impact of sample length on model performance, we extended the dataset described in
Section 3.2 by incorporating samples with lengths ranging from 64 to 512 bits and trained them using the ConvLSTM-TFN model.
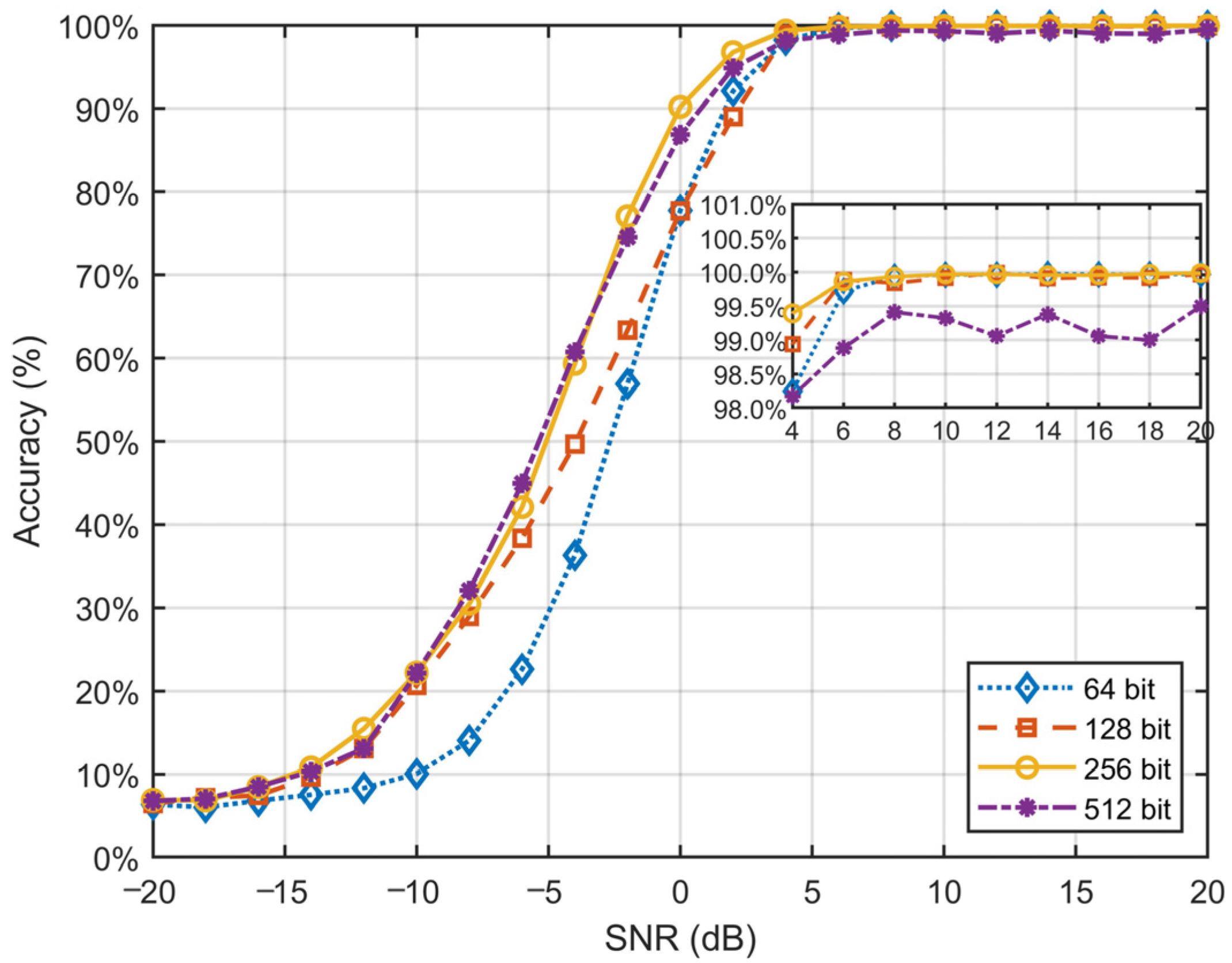
The experimental results in
Table 4 demonstrate that the model’s recognition accuracy improves as sample lengths increase. However, beyond a certain threshold, the rate of accuracy improvement diminishes noticeably. As shown in
Figure 4, in the low-SNR range (SNR < 0 dB), longer sequences offer limited advantages, with only marginal improvements found in accuracy compared to shorter sequences. Specifically, 64-bit and 128-bit sequences perform poorly in this region, while the difference in performance between 256-bit and 512-bit sequences is negligible. These findings suggest that, under extreme noise conditions, further increasing sequence length has limited effectiveness in enhancing model performance.
In the high-SNR range (SNR > 10 dB), classification accuracy for all sequence lengths converges to near-perfect levels, ultimately approaching 100%. This suggests that, in high-SNR conditions, signal information is sufficient for accurate classification, rendering sequence length variations nearly irrelevant to performance. Notably, the longer sequences of 512 bits exhibit slightly lower performance than shorter sequences in high-SNR conditions, likely due to increased model complexity and redundant information.
Overall, the results indicate that extending sequence length does not consistently result in significant improvements in classification accuracy, especially in low- and moderate-SNR ranges. Although longer sequences provide additional information, their effectiveness may be limited by the presence of noise and the model’s processing capability. Moreover, longer sequences considerably augment computational complexity and training time, imposing greater demands on model design and resource consumption. Considering the trade-off between classification performance and computational cost, we select 256-bit sequences as the primary training samples to strike a balance between efficiency and effectiveness.
4.2.2. Pre-Class Performance
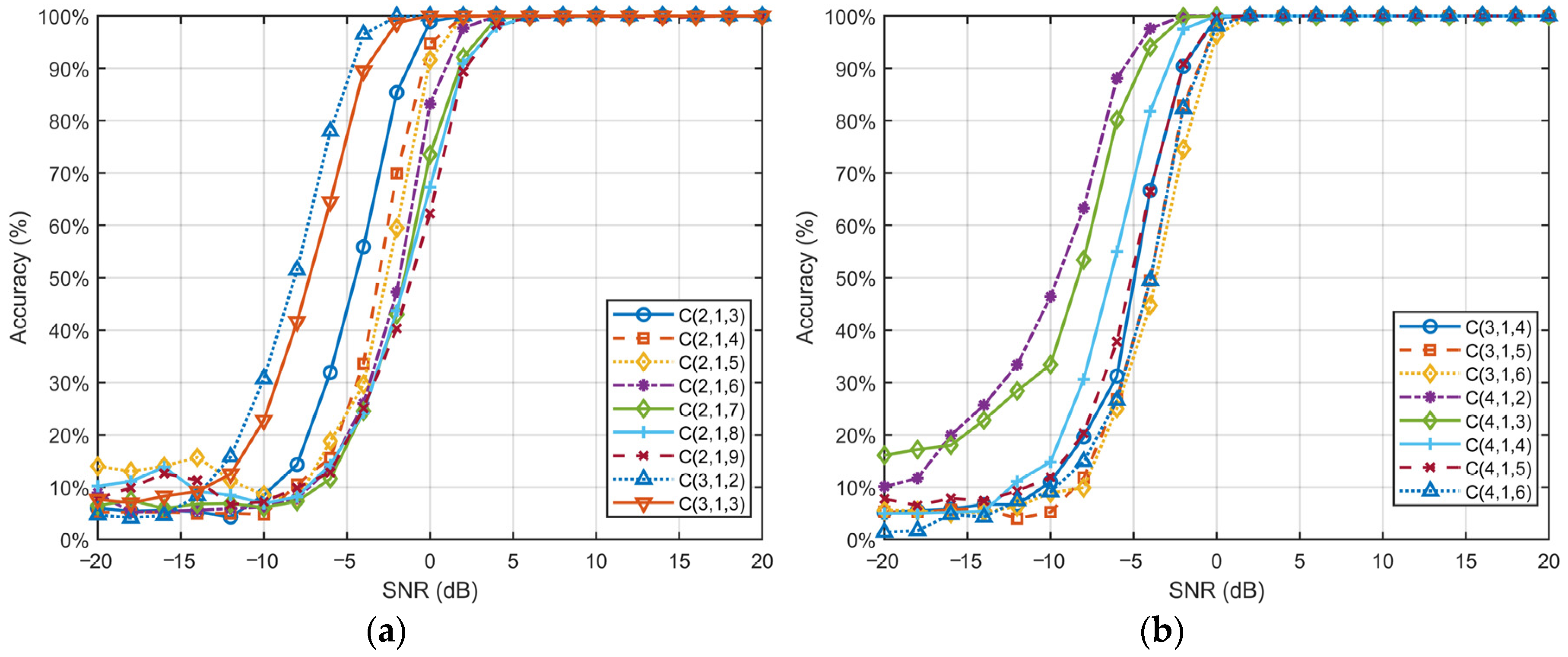
Figure 5 illustrates the variation in recognition accuracy for each type of convolutional code versus SNR under the ConvLSTM-TFN model.
The recognition accuracy for all convolutional code types approaches nearly 100% when the SNR is greater than or equal to 6 dB, indicating the remarkable efficacy of the proposed method in identifying convolutional codes under typical channel conditions.
Additionally, the performance of the classification model is significantly influenced by the constraint length l of convolutional codes. Under low-SNR conditions, shorter constraint lengths (e.g., l = 2, l = 3) demonstrate greater robustness. These shorter codes typically exhibit a faster improvement in accuracy, with performance “breakpoints” occurring at lower SNR values (e.g., around −2 dB). In contrast, convolutional codes with longer constraint lengths (e.g., C(2, 1, 9)) tend to perform less effectively in low-SNR environments but maintain excellent classification accuracy under high-SNR conditions.
The findings suggest that the complexity of convolutional codes exhibits different strengths across varying SNR levels. This observation suggests that models must strike a balance between robustness and complexity to adapt to dynamic noise environments. Notably, our proposed ConvLSTM-TFN network effectively captures and leverages the intricate relationships between signal features, enabling reliable classification, even under challenging conditions. By combining feature extraction, sequential modeling, and self-attention mechanisms, our network demonstrates exceptional adaptability across diverse SNR levels. Shorter constraint lengths benefit from the network’s robustness in noisy conditions, while longer constraint lengths leverage the network’s capacity to extract detailed features in high-quality channels. These findings underscore the capability of our method to generalize effectively while maintaining high classification performance, proving its suitability for real-world signal processing tasks.
4.3. Impacts of LSTM Depth and Hidden Size on Performance
The number of LSTM layers and the hidden size have significant impacts on the system’s blind-recognition performance. We analyzed the effects of different hidden sizes with a four-layer LSTM architecture, as well as the impact of a 256 hidden size across multiple LSTM layers.
The results presented in
Table 5 indicate that increasing the hidden size generally enhances model performance; however, this improvement exhibits diminishing returns beyond a certain threshold. When LSTM layers are fixed at four, the model achieves its highest OA, at 65.57%, and F1 score, at 65.84%, with a hidden size of 1024. In contrast, a hidden size of 768 provides nearly identical results (65.03% OA and 65.86% F1) while incurring lower computational cost. This finding suggests that a hidden size of 768 strikes an effective balance between performance and efficiency.
In comparing various configurations of LSTM layers, we observe that an increase in the number of layers does not necessarily correlate with improved overall performance. Specifically, when utilizing two layers, the model performs significantly worse, achieving only 62.79% OA and a 63.81% F1 score. This indicates that deeper architectures may be advantageous for this particular task. Conversely, expanding the layers to six (with a hidden size of 768) yields the highest precision, at 67.01%, yet results in a decrease in OA to 63.46%, which suggests potential overfitting issues. In contrast, employing four LSTM layers strikes the best overall balance, consistently delivering robust performance across all evaluated metrics.
Based on preliminary observations, a hidden size of 768 achieves the optimal balance between performance and computational efficiency. Current experimental trends indicate that larger hidden sizes yield diminishing returns, rendering it unnecessary to exhaustively test all potential configurations.
From these results, it is evident that while a hidden size of 1024 achieves slightly superior outcomes, the difference is minimal when compared to a hidden size of 768. The latter represents a more practical choice due to its reduced computational complexity. Additionally, increasing the number of LSTM layers beyond four does not enhance either the OA or F1 score and may even lead to overfitting. Therefore, we conclude that an optimal configuration consists of four LSTM layers and a hidden size of 768, effectively balancing accuracy, precision, and efficiency.
4.4. Performance Comparison Across Models
In our experiments, we compared the proposed ConvLSTM-TFN against DRN [
17], CCR-Net [
26], 1-D CNN, and TextCNN. Among these networks, DRN and CCR-Net are specifically designed for channel-coding recognition tasks, demonstrating exceptional performance in this domain and serving as representative works among the existing methods. In contrast, 1-D CNN and TextCNN are general-purpose networks, each with a wide range of applications. A comparison with these networks effectively highlights the advanced capabilities of our proposed network in the realm of channel-coding blind recognition. The dataset used for evaluation is the one generated in
Section 3.2, along with a hard-decision counterpart generated under identical conditions. Each sample in the dataset contains a noisy version of the input signal as well as the corresponding coding information.
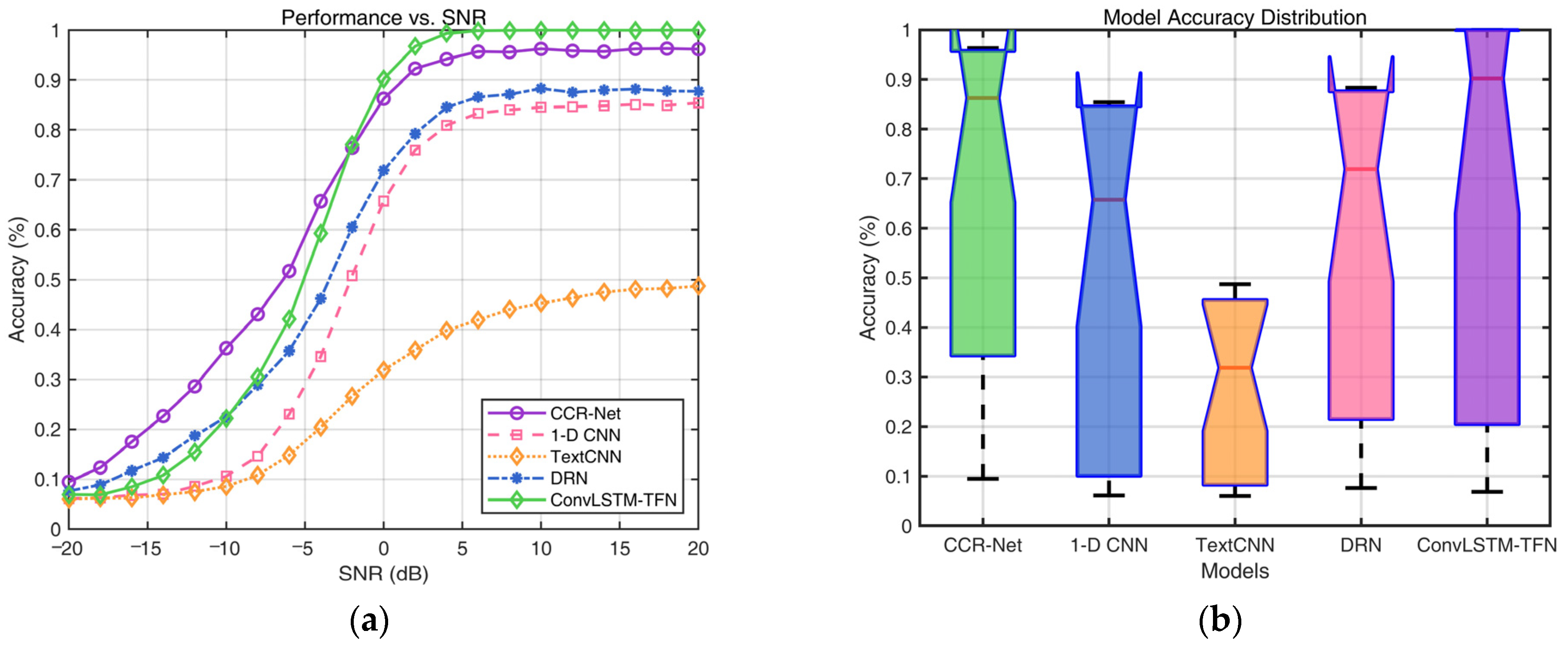
Figure 6a depicts the accuracy curves of each network under different decision schemes and varying SNR conditions. When the SNR > −2 dB, our network significantly outperforms all other models, demonstrating its robustness and efficiency. Although CCR-Net exhibits slightly superior performance, compared to our network, in extremely low-SNR conditions, resulting in an OA 1.86% higher than ConvLSTM-TFN, it fails to maintain this advantage across the entire SNR range. This is also evident in the median line of the box plot presented in
Figure 6b, where ConvLSTM-TFN demonstrates the best performance in convolutional code blind recognition. Statistical analysis indicates that ConvLSTM-TFN achieves an accuracy exceeding 90% under practical channel conditions, with an SNR above 0 dB. Within the SNR range of 0–20 dB, the average blind-recognition accuracy of ConvLSTM-TFN reaches an impressive 98.7%. In contrast, our network excels under higher-SNR conditions, significantly outperforming other models and highlighting its superior capability in handling complex environments.
Table 6 compares the accuracy across all networks under both soft-decision and hard-decision scenarios. Under soft-decision conditions, channel-coding recognition demonstrates overall superior performance compared to hard-decision conditions, with an approximate increase of 2% in OA for soft decision. Soft decision provides richer signal details, enabling complex networks to extract more comprehensive features and achieve higher classification accuracy. However, for simpler network architectures, such as TextCNN, the limited feature-extraction capability makes hard decision more advantageous for structured feature extraction, leading to higher OA in certain cases. Additionally, for basic networks like 1-D CNN, the decline in recognition performance is relatively modest as the SNR decreases, suggesting that lower-complexity networks can only partially leverage the benefits of soft-decision information.
In summary, the experiment’s results validate the advantages of soft decision in channel-coding recognition while highlighting the trade-off between network complexity and the type of input features.
Figure 7 illustrates the confusion matrices of each network under conditions where SNR ≥ 0 dB. It can be observed that although all networks exhibit high accuracy for certain coding types, there still remains a degree of confusion between different coding types. This confusion is particularly evident in some networks, where misclassifications occur more frequently among two or more coding types, significantly affecting the reliability of the decisions. However, in the ConvLSTM-TFN model, this confusion is markedly reduced, further validating the superior performance and robustness of our network in the coding classification task.
Moreover, considering that SNR ≥ 0 dB typically corresponds to the prevailing transmission conditions in practical communication systems, our network demonstrates reliable decision-making in this environment, thereby minimizing misclassifications and showcasing enhanced reliability and applicability. These results underscore the proficiency of our network in accurately classifying diverse coding types while effectively mitigating confusion, rendering it highly suitable for real-world applications.
In summary, the experimental results demonstrate the superior performance and robustness of the ConvLSTM-TFN network in channel-coding classification tasks. By effectively mitigating confusion between coding types, particularly under typical communication conditions (SNR ≥ 0 dB), our model achieves enhanced reliability and classification accuracy compared to other networks. This emphasizes the practical applicability of our approach and its potential for deployment in real-world communication systems. Additionally, the results underscore the significance of balancing network complexity and robustness to optimize classification performance across diverse conditions.
4.5. Ablation Study
Table 7 presents a comparison of performance between the baseline model (which comprises only the backbone network) and the ConvLSTM-TFN model, which incorporates a self-attention mechanism. The results indicate that the integration of self-attention consistently enhances all evaluation metrics.
Specifically, the OA shows an increase from 64.28% to 65.03%, indicating a modest yet meaningful improvement in overall classification performance. Notably, the most substantial improvements are observed in precision and F1 score. The precision value rises from 61.32% to 66.73%, indicating that the model utilizing self-attention generates fewer false positive predictions and achieves higher reliability in its positive classifications. Similarly, the F1 score improves from 62.77% to 65.86%, reflecting a more favorable balance between precision and recall in the enhanced model.
These results indicate that the self-attention mechanism primarily enhances the model’s capacity to distinguish complex backgrounds and easily confused categories. The introduction of self-attention effectively bolsters feature extraction and sequence modeling, leading to notable improvements in precision and model robustness. Although the overall accuracy improvement is relatively modest, there has been a significant increase in both the model’s precision and its overall performance. Consequently, when compared to the baseline model, the ConvLSTM-TFN integrated with the self-attention mechanism exhibits superior performance and represents a more effective configuration for modeling tasks.
5. Conclusions
In this study, we propose a novel channel-coding recognition network, referred to as ConvLSTM-TFN. This method integrates convolutional layers, LSTM networks, and a self-attention mechanism to effectively capture and distinguish the characteristics of various channel-coding types. The hybrid model addresses limitations associated with single-component approaches and demonstrates superior performance by utilizing soft-decision sequences. The model demonstrates a blind-recognition accuracy for convolutional codes exceeding 90% when the SNR is greater than 0 dB. Furthermore, it achieves an average accuracy of 98.7% within the SNR range of 0 to 20 dB. Experimental results demonstrate the superiority of our network compared to existing models, while also indicating significant reductions in inter-type confusion.
In future research, our primary object will be to prioritize the enhancement of performance under low-SNR conditions and expand the model’s capability to handle a wider variety of coding types, ensuring clear differentiation across diverse categories. We plan to further innovate in order to improve accuracy in noisy environments and validate the adaptability of the ConvLSTM-TFN model across an expanded range of channel-coding types.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}