
Research on Mobile Robot Path Planning Based on MSIAR-GWO Algorithm


Abstract
1. Introduction
- (1)
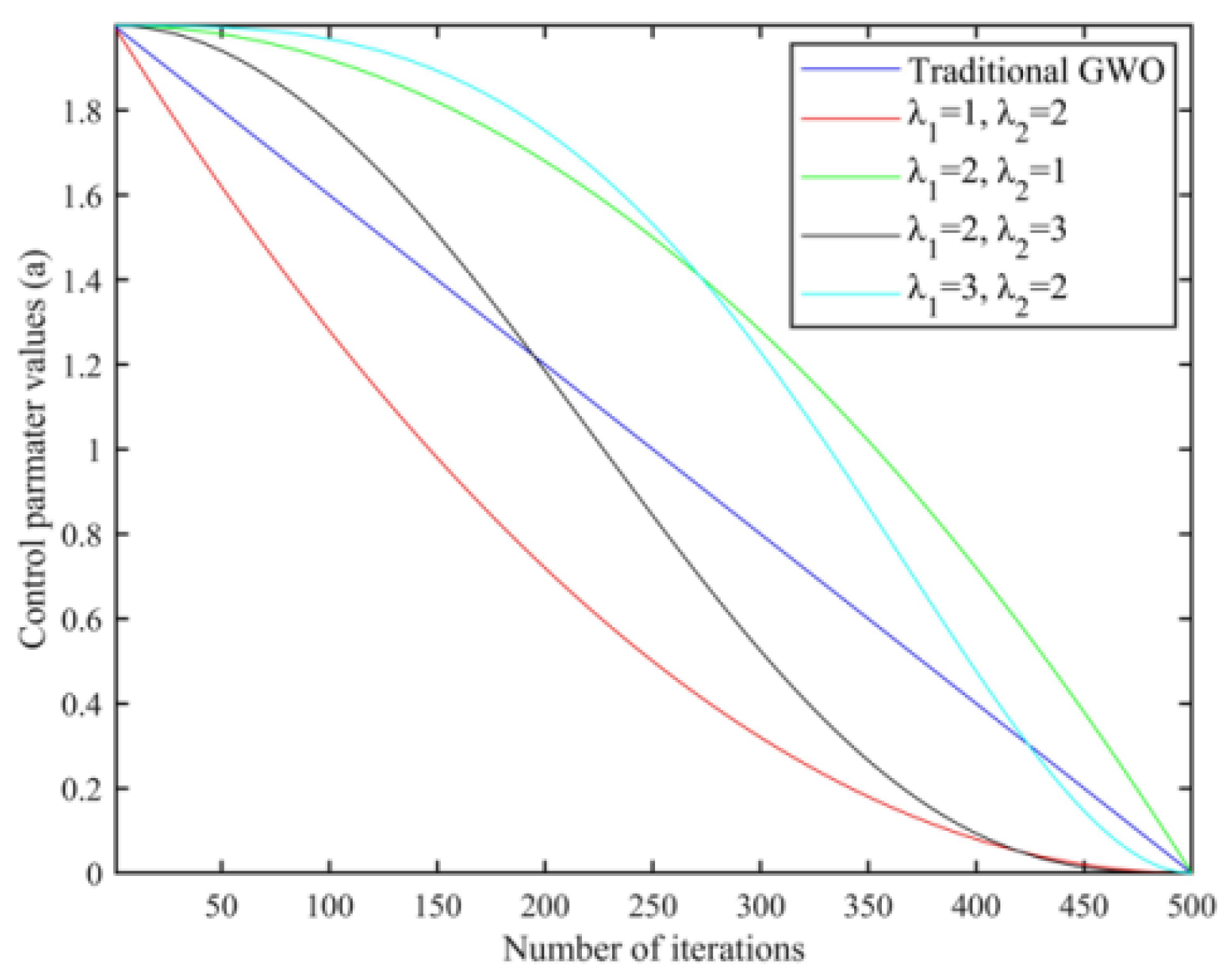
- A new nonlinear convergence factor is proposed, and adjustable parameters are intelligently selected through reinforcement learning to adapt to specific variants of the gray wolf optimization algorithm based on the improvement of different strategies, which enables the optimization process to find a balance between exploration and exploitation. Intelligent configuration of adjustable parameters through reinforcement learning can reduce human intervention and improve the robustness and adaptability of the algorithm.
- (2)
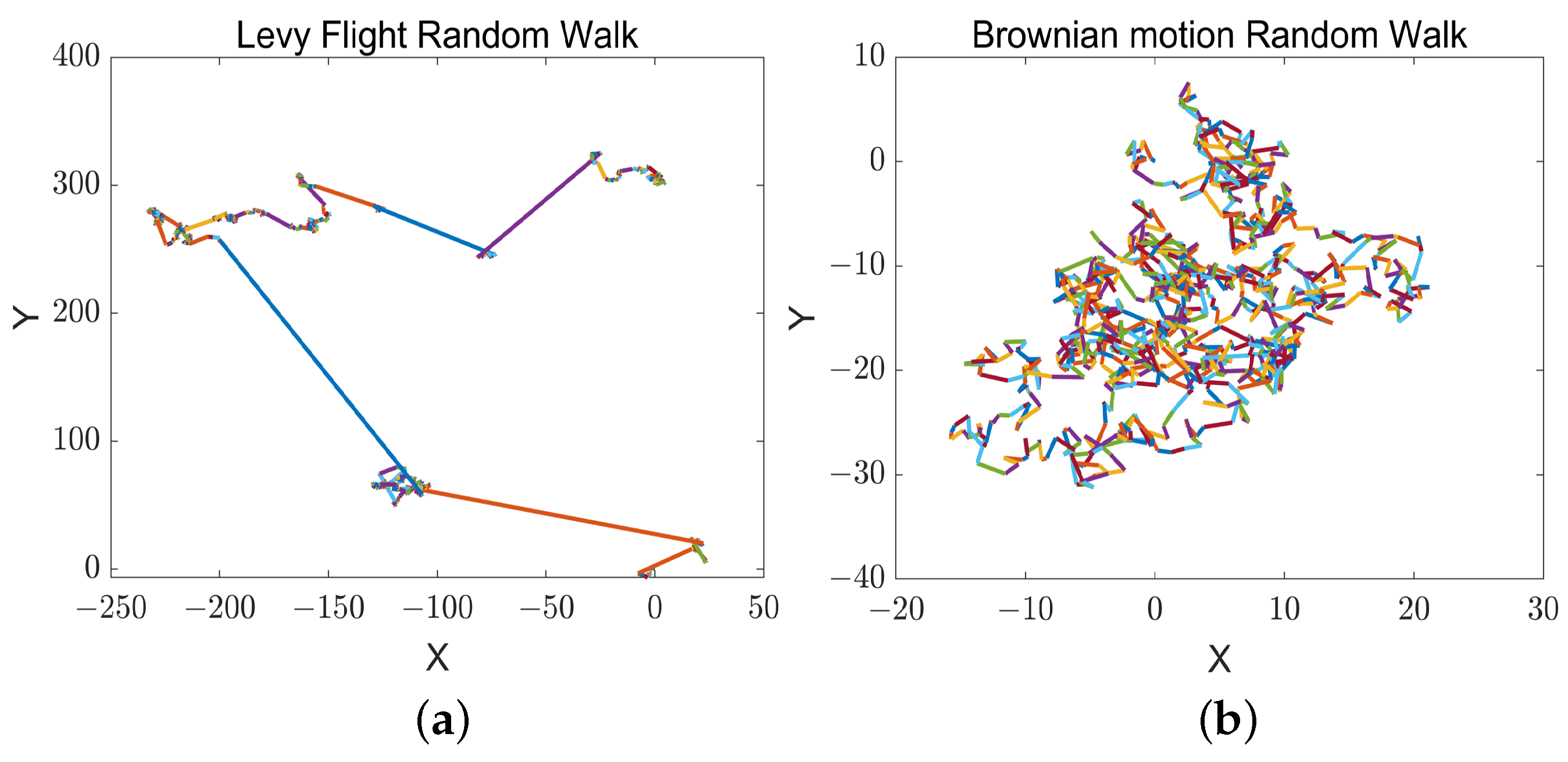
- A new adaptive position-updating strategy based on detour foraging and dynamic weights is proposed. Dynamic weights can be dynamically assigned in the iterative process according to the change in the adaptation value characterizing the size of the role played by different types of gray wolves in the leadership, increasing the weights of the more optimal individuals and accelerating the convergence speed of the algorithm as a whole. At the same time, an adaptive position-update mechanism is added to ensure that the diversity of the wolf pack can still be maintained when the wolf pack gathers to the leadership in the late iterations. Since the position-update mechanism of the traditional gray wolf optimization algorithm mainly relies on the guidance of the leader wolf, the whole optimization process lacks information sharing and collaboration among individuals, which to some extent affects the algorithm’s search diversity and global optimization ability. For this reason, we further add the detour foraging mechanism of the artificial rabbit optimization algorithm to the position-updating strategy of the gray wolf optimization algorithm, and we add Levy flight strategy or a Brownian motion strategy to the detour foraging mechanism of the artificial rabbit algorithm according to the energy factor. This enhances the information sharing of individuals in the population and then enriches the path diversity among individuals so that the algorithm has a significant advantage in solving complex optimization problems.
- (3)
- We introduce an elimination and relocation strategy based on stochastic center-of-gravity dynamic reverse learning for the inferior individuals in the population to improve the search range of wolf individuals and keep the algorithm from falling into local optimum.
2. Basic Theory
2.1. Overview of the Gray Wolf Optimization Algorithm
2.1.1. Surround the Prey
2.1.2. Hunting
2.1.3. Attacking Prey
2.2. Fundamentals of the Detour Foraging Strategy of the Artificial Rabbit Optimization Algorithm
3. Multi-Strategy Improved Gray Wolf Optimization Algorithm Based on Reinforcement Learning (MSIAR-GWO)
3.1. Nonlinear Convergence Factors for Optimization Based on Reinforcement Learning Algorithms
3.2. Adaptive Position-Update Strategy Based on Detour Foraging and Dynamic Weighting
3.3. Stochastic Center-of-Gravity-Based Dynamic Reverse Learning for Elimination and Relocation Strategy
3.4. Flowchart of MSIAR-GWO Algorithm
4. Experimental Verification
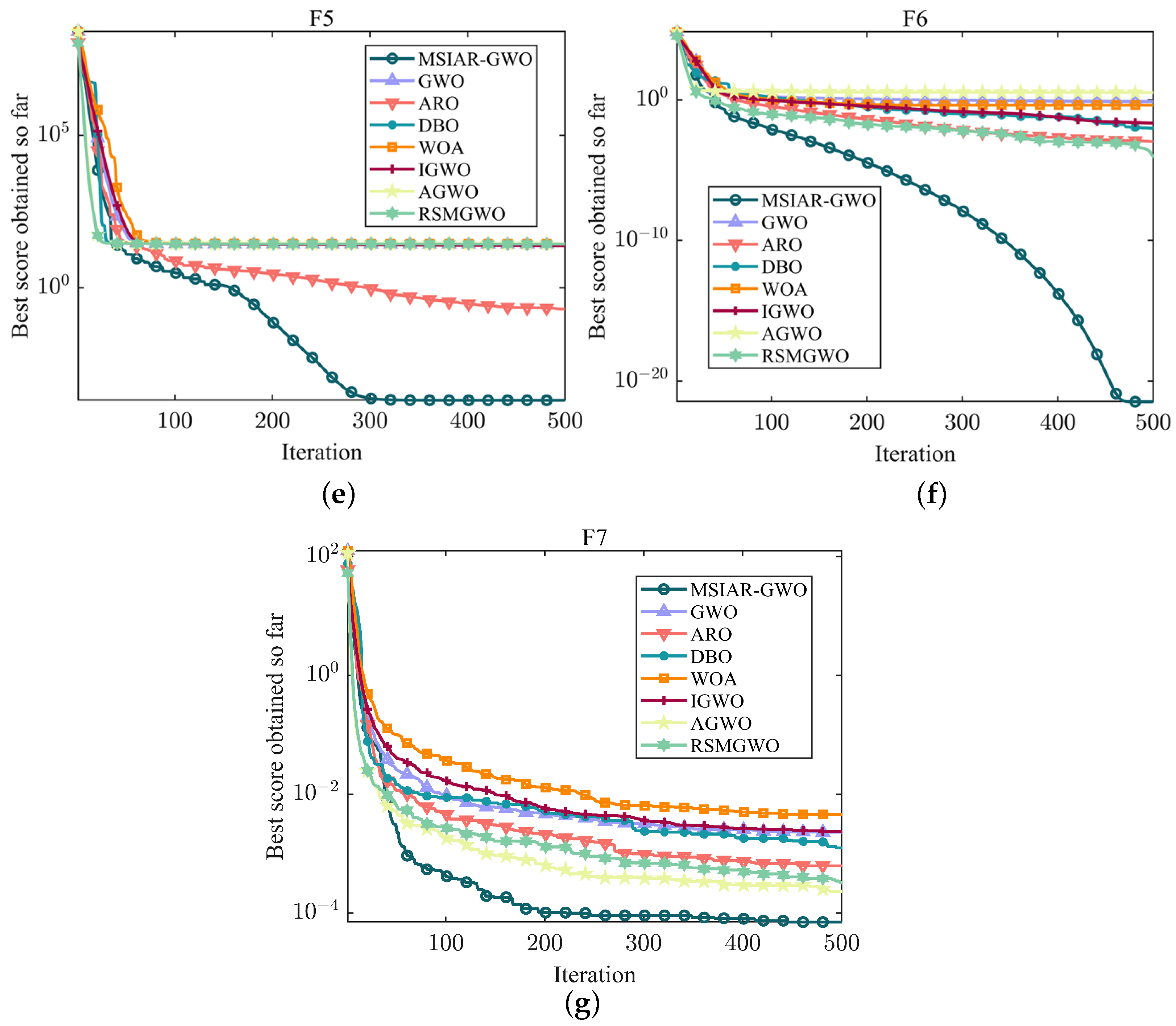
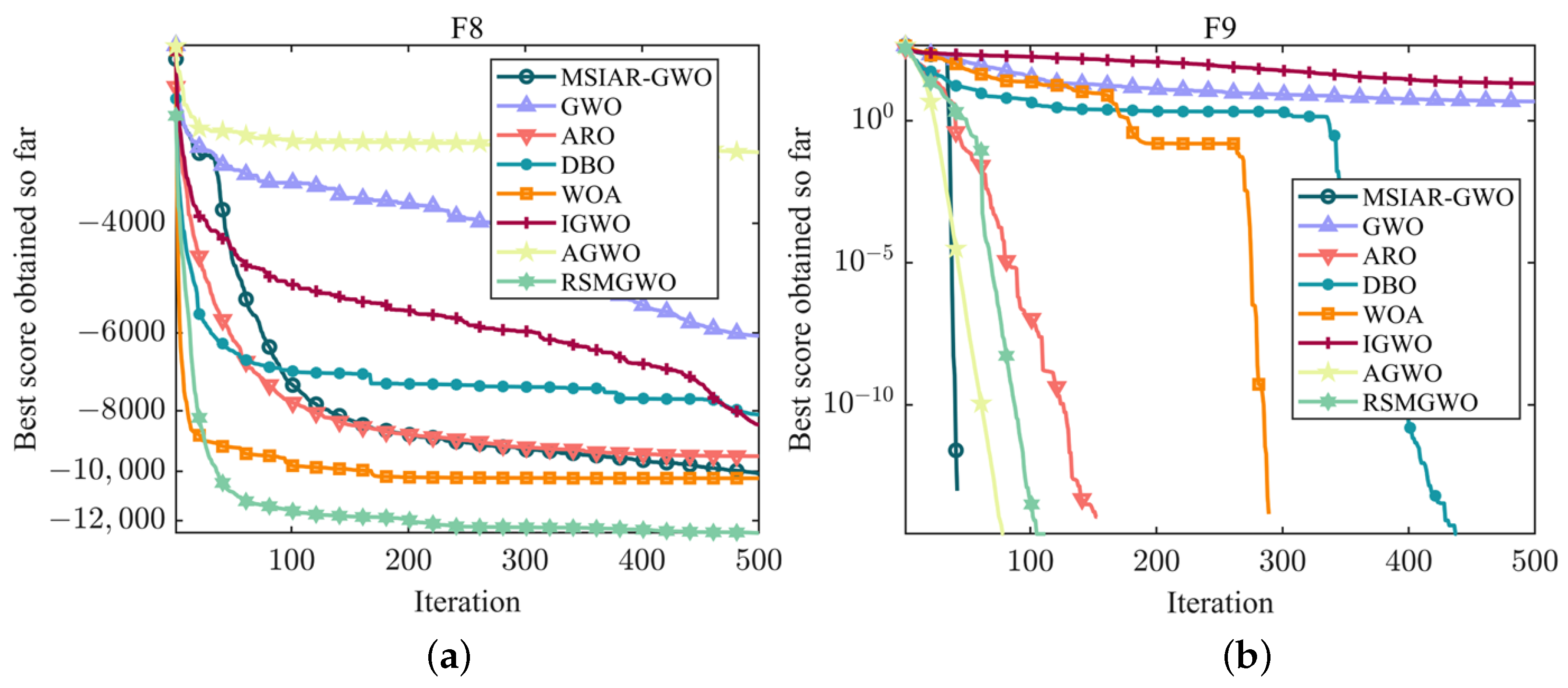
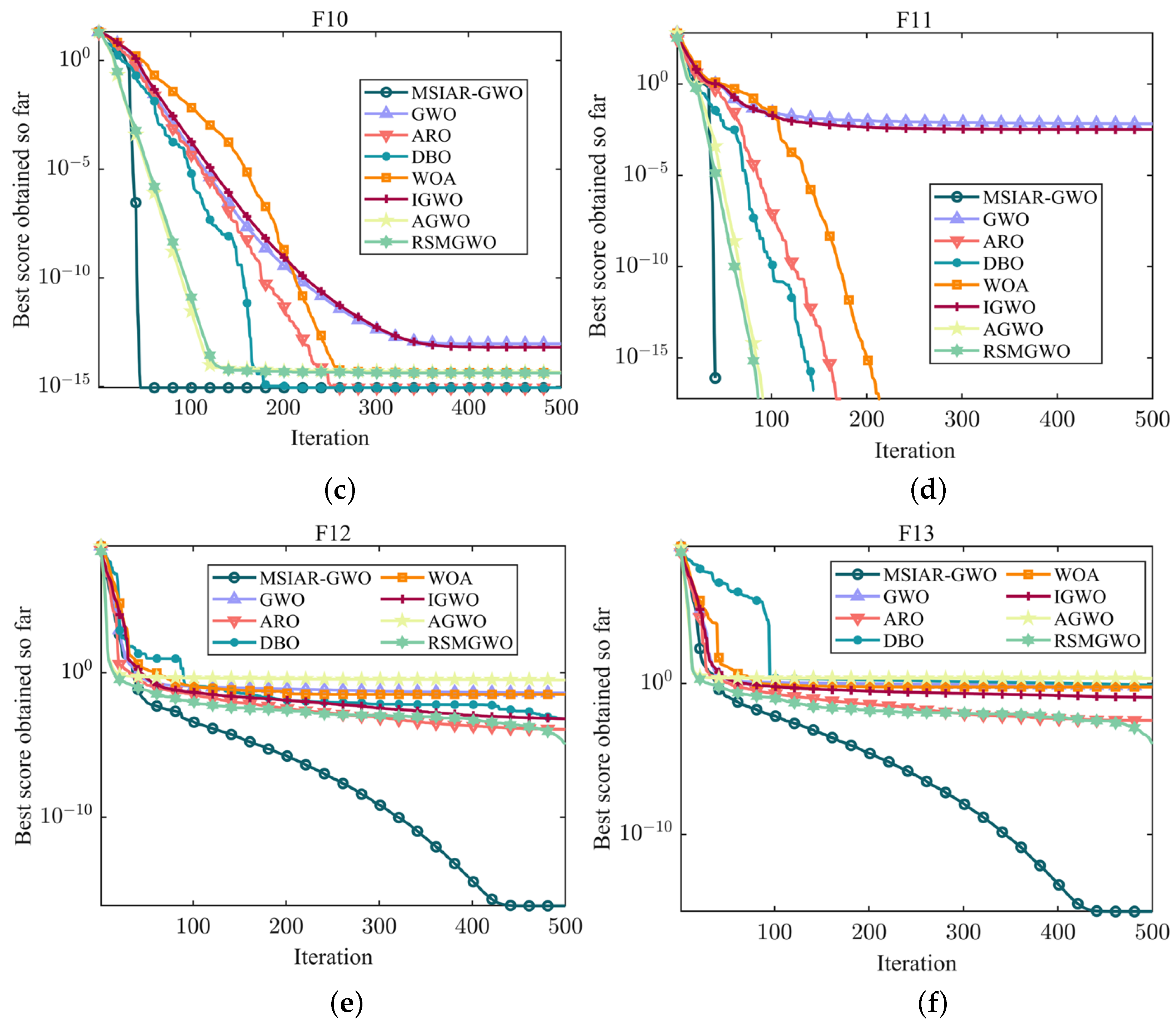
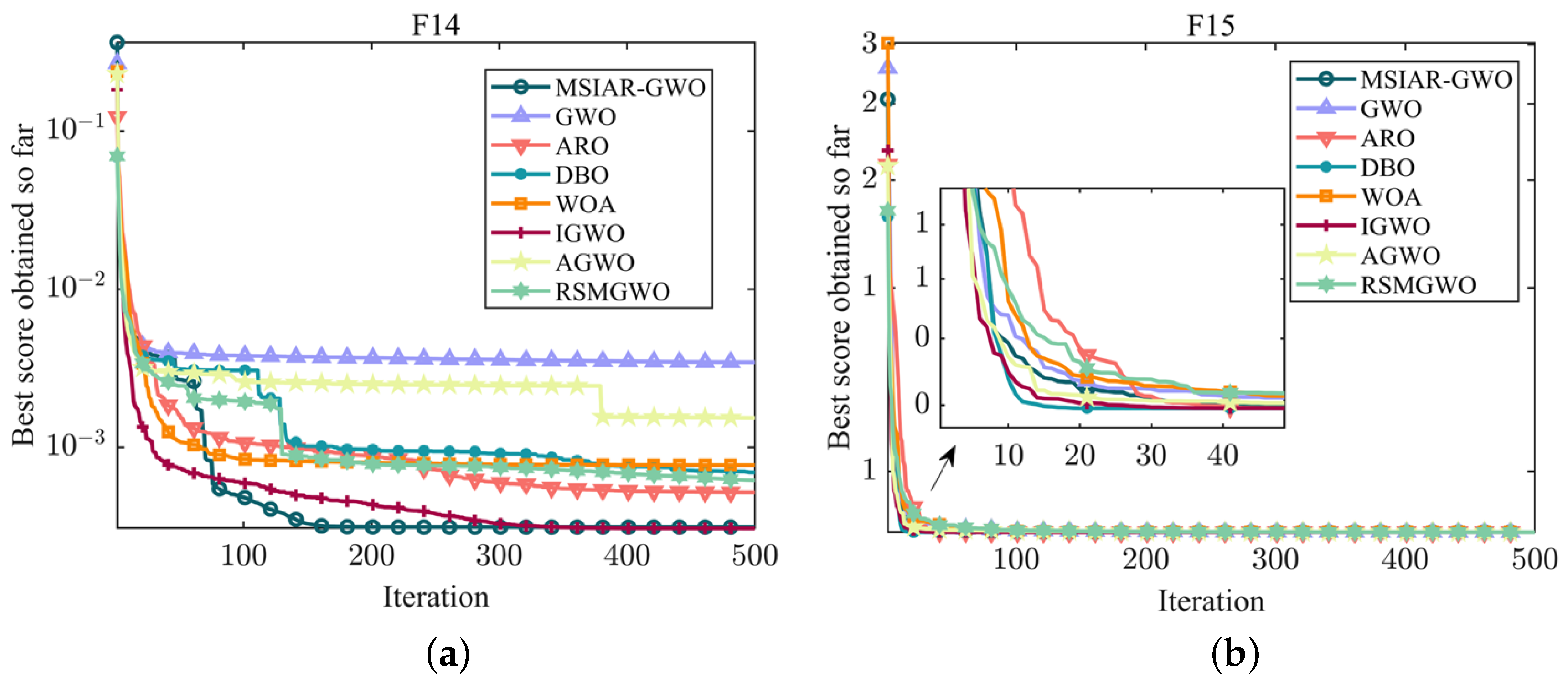
4.1. Benchmarking Function Optimization and Result Analysis
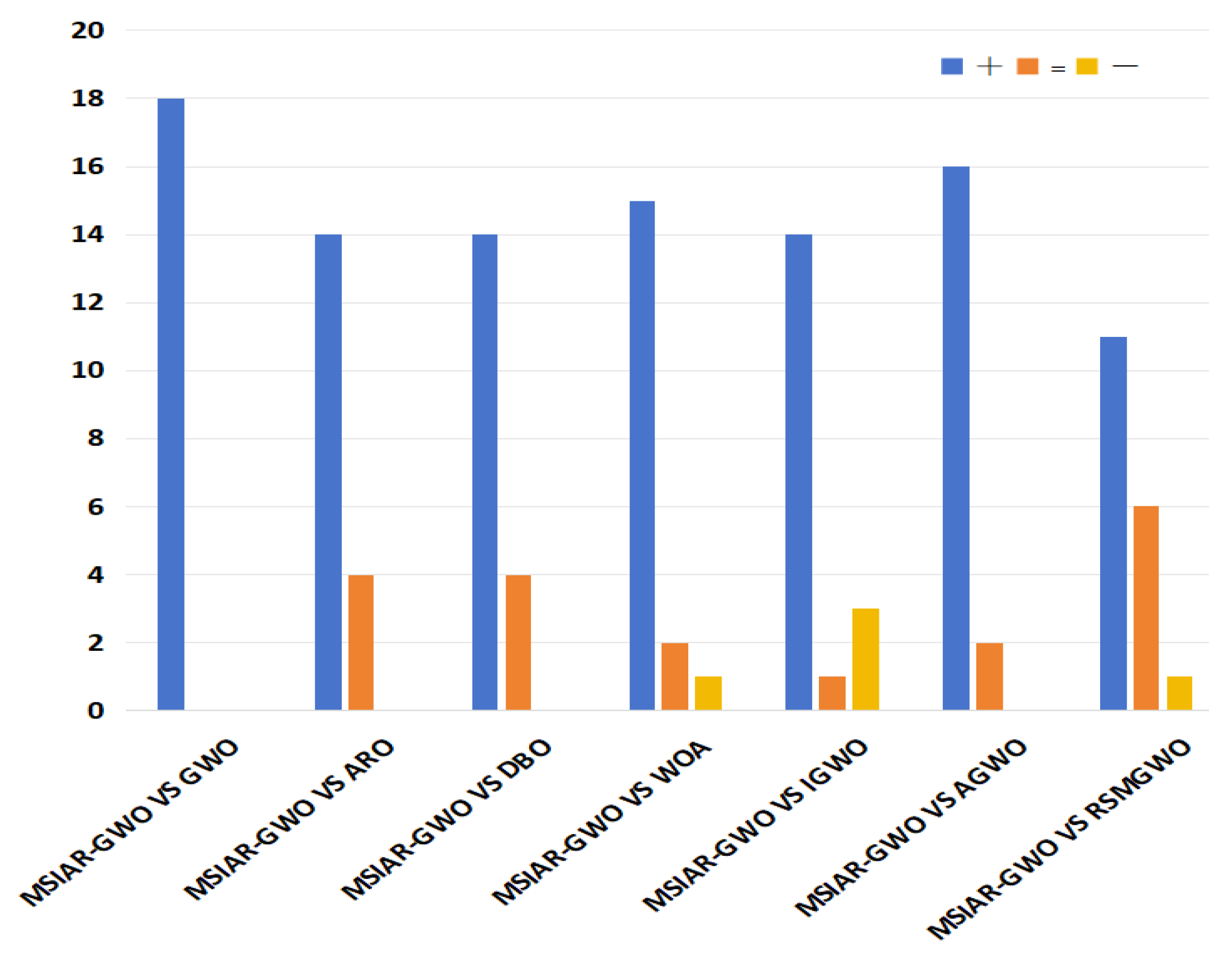
4.2. Wilcoxon Rank Sum Test
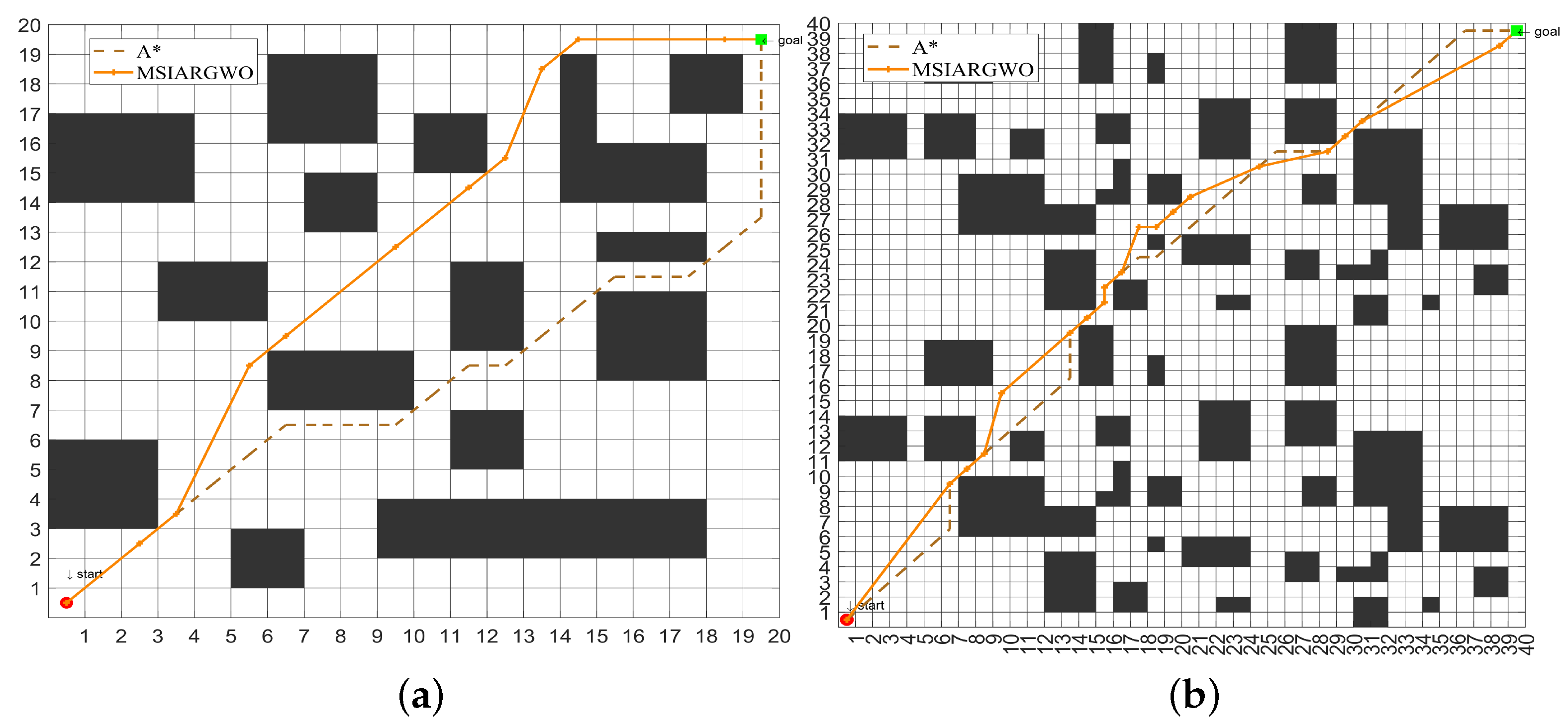
4.3. Mathematical Model and Simulation Results of Global Path Planning for Mobile Robots
4.3.1. Environment Modeling
- (1)
- Obtain an initial path consisting of a series of nodes.
- (2)
- Starting from the beginning of the path, connect to other nodes one by one by line segments.
- (3)
- Check whether the connecting line between the latter node and the former node is free of obstacles. If the area through which the connecting line passes is free of obstacles, remove all intermediate nodes between the two nodes.
- (4)
- After evaluating the first node and all subsequent nodes, repeat steps (2) and (3) starting from the next node until all pairs of nodes in the path have been checked.
- (1)
- Set the map environment parameters such as size, start position, and end position as well as the MSIAR-GWO algorithm parameters, population size, and maximum iteration number.
- (2)
- Initialize the population, calculate the fitness value corresponding to the individual gray wolf according to Equation (32), and select the leader gray wolf according to the fitness. Determine the path planning initial shortest path and the path shortest planning information.
- (3)
- (4)
- (5)
- Through Equation (30), the inferior individuals are eliminated and their positioning is re-updated by using stochastic gravity dynamic opposition-based learning.
- (6)
- Calculate the path fitness function value to update the leader gray wolf, and update the path shortest length and path shortest planning information.
- (7)
- Determine whether the iteration termination condition is satisfied. If so, output the global shortest path length and path shortest planning information; otherwise, return to step 3 to continue optimization.
- (8)
- The algorithm ends and the best path planning result is output.
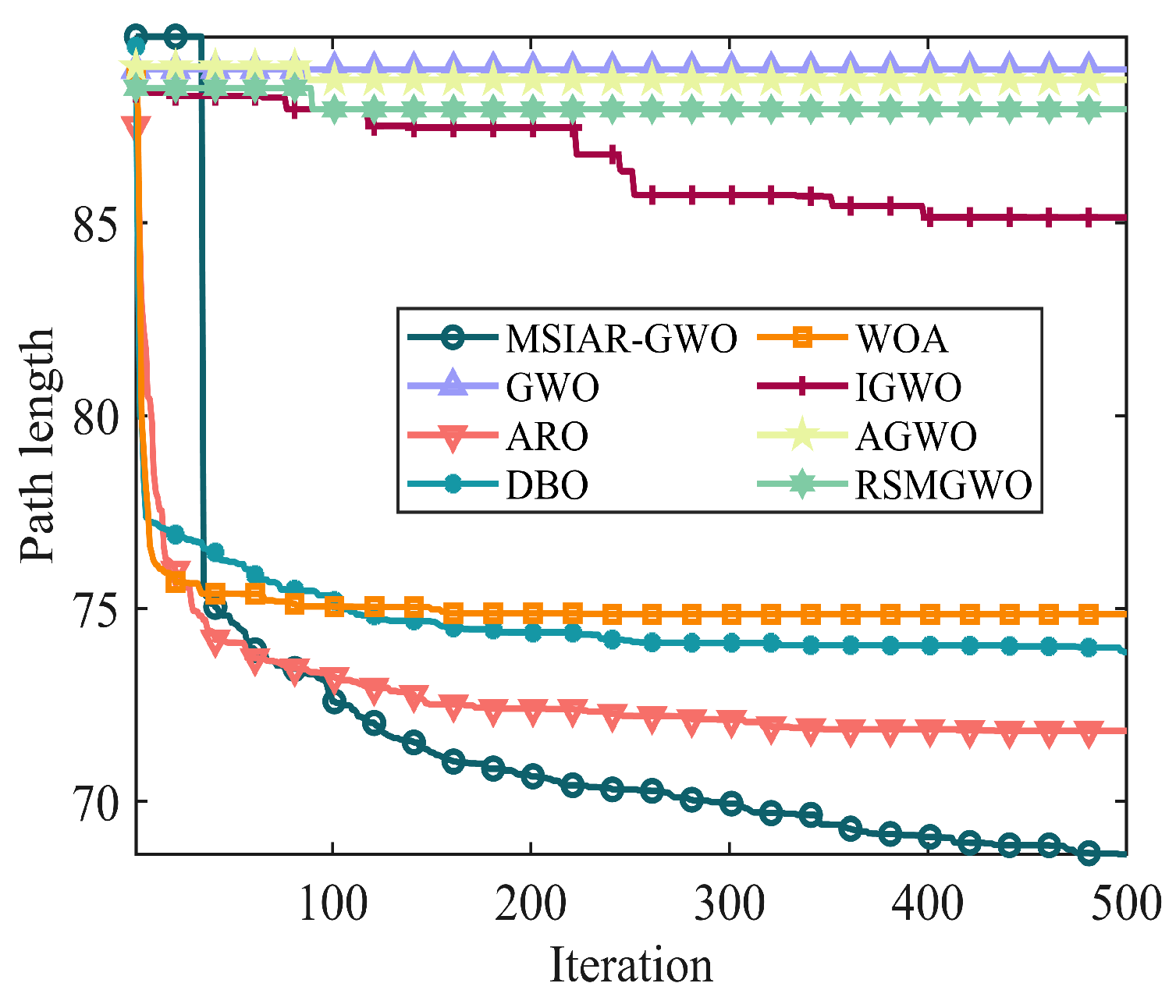
4.3.2. Experimental Results
5. Conclusions and Prospects
Author Contributions
Funding
Conflicts of Interest
References
- Øvsthus, Ø.; Robsrud, D.N.; Muggerud, L.; Amendola, J.; Cenkeramaddi, L.R.; Tyapin, I.; Jha, A. Mobile Robotic Manipulator Based Autonomous Warehouse Operations. In Proceedings of the 2023 11th International Conference on Control, Mechatronics and Automation (ICCMA), Grimstad, Norway, 1–3 November 2023. [Google Scholar]
- Xie, P.; Wang, H.; Huang, Y.; Gao, Q.; Bai, Z.; Zhang, L.; Ye, Y. LiDAR-Based Negative Obstacle Detection for Unmanned Ground Vehicles in Orchards. Sensors 2024, 24, 7929. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, B.; Tang, H.; Wei, X.; Wang, J. Research on Autonomous Navigation of a Disinfection Robot for Hospital Based on ROS. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 26–28 May 2023; Volume 3, pp. 706–710. [Google Scholar]
- Janani, K.; Gobhinath, S.; Kumar, K.V.S.; Roshni, S.; Rajesh, A. Vision Based Surveillance Robot for Military Applications. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; Volume 1, pp. 462–466. [Google Scholar]
- Hao, M.; Yuan, X.; Ren, J.; Bi, Y.; Ji, X.; Zhao, S.; Wu, M.; Shen, Y. Research on Downhole MTATBOT Positioning and Autonomous Driving Strategies Based on Odometer-Assisted Inertial Measurement. Sensors 2024, 24, 7935. [Google Scholar] [CrossRef]
- Hewawasam, H.S.; Ibrahim, M.Y.; Appuhamillage, G.K. Past, Present and Future of Path-Planning Algorithms for Mobile Robot Navigation in Dynamic Environments. IEEE Open J. Ind. Electron. Soc. 2022, 3, 353–365. [Google Scholar] [CrossRef]
- Abdulsaheb, J.A.; Kadhim, D.J. Classical and Heuristic Approaches for Mobile Robot Path Planning: A Survey. Robotics 2023, 12, 93. [Google Scholar] [CrossRef]
- Loganathan, A.; Ahmad, N.S. A systematic review on recent advances in autonomous mobile robot navigation. Eng. Sci. Technol. Int. J. 2023, 40, 101343. [Google Scholar] [CrossRef]
- Paliwal, P. A Survey of A-Star Algorithm Family for Motion Planning of Autonomous Vehicles. In Proceedings of the 2023 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 18–19 February 2023; pp. 1–6. [Google Scholar]
- Yang, J.; Cai, B.; Li, X.; Ge, R. Optimal path planning for electric vehicle travel time based on Dijkstra. In Proceedings of the 2023 35th Chinese Control and Decision Conference (CCDC), Yichang, China, 20–22 May 2023; pp. 721–726. [Google Scholar]
- Qiao, L.; Luo, X.; Luo, Q. An Optimized Probabilistic Roadmap Algorithm for Path Planning of Mobile Robots in Complex Environments with Narrow Channels. Sensors 2022, 22, 8983. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Lian, X.; Gui, Z. Research on Global Path Planning System of Driverless Car Based on Improved RRT Algorithm. In Proceedings of the 2023 International Conference on Data Science & Informatics (ICDSI), Bhubaneswar, India, 12–13 August 2023; pp. 260–263. [Google Scholar]
- Ren, J.; Huang, X. Dynamic Programming Inspired Global Optimal Path Planning for Mobile Robots. In Proceedings of the 2021 IEEE 4th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 24–26 September 2021; pp. 461–465. [Google Scholar]
- Liang, Y.; Juntong, Q.; Xiao, J.; Xia, Y. A literature review of UAV 3D path planning. In Proceeding of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; pp. 2376–2381. [Google Scholar]
- Chen, Q.; He, Q.; Zhang, D. UAV Path Planning Based on an Improved Chimp Optimization Algorithm. Axioms 2023, 12, 702. [Google Scholar] [CrossRef]
- Karur, K.; Sharma, N.; Dharmatti, C.; Siegel, J.E. A Survey of Path Planning Algorithms for Mobile Robots. Vehicles 2021, 3, 448–468. [Google Scholar] [CrossRef]
- Tao, Q.Y.; Sang, H.Y.; Guo, H.W.; Wang, P. Improved Particle Swarm Optimization Algorithm for AGV Path Planning. IEEE Access 2021, 9, 33522–33531. [Google Scholar]
- Song, J.; Pu, Y.; Xu, X. Adaptive Ant Colony Optimization with Sub-Population and Fuzzy Logic for 3D Laser Scanning Path Planning. Sensors 2024, 24, 1098. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, X.; Li, J. Intelligent Path Planning with an Improved Sparrow Search Algorithm for Workshop UAV Inspection. Sensors 2024, 24, 1104. [Google Scholar] [CrossRef]
- Xu, L.; Cao, M.; Song, B. A new approach to smooth path planning of mobile robot based on quartic Bezier transition curve and improved PSO algorithm. Neurocomputing 2022, 473, 98–106. [Google Scholar] [CrossRef]
- Huo, F.; Zhu, S.; Dong, H.; Ren, W. A new approach to smooth path planning of Ackerman mobile robot based on improved ACO algorithm and B-spline curve. Robot. Auton. Syst. 2024, 175, 104655. [Google Scholar] [CrossRef]
- Cheng, Y.; Jiang, W. AUV 3D Path Planning Based on Improved Sparrow Search Algorithm. In Proceedings of the 2024 7th International Conference on Advanced Algorithms and Control Engineering (ICAACE), Shanghai, China, 1–3 March 2024; pp. 1592–1595. [Google Scholar]
- Zhang, H.; Cai, Z.; Xiao, L.; Heidari, A.A.; Chen, H.; Zhao, D.; Wang, S.; Zhang, Y. Face Image Segmentation Using Boosted Grey Wolf Optimizer. Biomimetics 2023, 8, 484. [Google Scholar] [CrossRef]
- Hosseini-Hemati, S.; Derafshi Beigvand, S.; Abdi, H.; Rastgou, A. Society-based Grey Wolf Optimizer for large scale Combined Heat and Power Economic Dispatch problem considering power losses. Appl. Soft Comput. 2022, 117, 108351. [Google Scholar] [CrossRef]
- Mafarja, M.; Thaher, T.; Too, J.; Chantar, H.; Turabieh, H.; Houssein, E.H.; Emam, M.M. An efficient high-dimensional feature selection approach driven by enhanced multi-strategy grey wolf optimizer for biological data classification. Neural Comput. Appl. 2023, 35, 1749–1775. [Google Scholar] [CrossRef]
- Chen, R.; Yang, B.; Li, S.; Wang, S.; Cheng, Q. An Effective Multi-population Grey Wolf Optimizer based on Reinforcement Learning for Flow Shop Scheduling Problem with Multi-machine Collaboration. Comput. Ind. Eng. 2021, 162, 107738. [Google Scholar] [CrossRef]
- Liu, L.; Li, L.; Nian, H.; Lu, Y.; Zhao, H.; Chen, Y. Enhanced Grey Wolf Optimization Algorithm for Mobile Robot Path Planning. Electronics 2023, 12, 4026. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, Y. Adaptive dynamic self-learning grey wolf optimization algorithm for solving global optimization problems and engineering problems. Math. Biosci. Eng. 2024, 21, 3910–3943. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, I.; Qayum, F.; Rahman, S.U.; Srivastava, G. Using Improved Hybrid Grey Wolf Algorithm Based on Artificial Bee Colony Algorithm Onlooker and Scout Bee Operators for Solving Optimization Problems. Int. J. Comput. Intell. Syst. 2024, 17, 111. [Google Scholar] [CrossRef]
- Tu, B.; Wang, F.; Huo, Y.; Wang, X. A hybrid algorithm of grey wolf optimizer and harris hawks optimization for solving global optimization problems with improved convergence performance. Sci. Rep. 2023, 13, 22909. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Cai, G.; Wang, Y.; Li, X. Path Planning of Obstacle-Crossing Robot Based on Golden Sine Grey Wolf Optimizer. Appl. Sci. 2024, 14, 1129. [Google Scholar] [CrossRef]
- Soloklo, H.N.; Bigdeli, N. Fast-Dynamic Grey Wolf Optimizer for solving model order reduction of bilinear systems based on multi-moment matching technique. Appl. Soft Comput. 2022, 130, 109730. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Q.; Zhang, Z.; Mirjalili, S.; Zhao, W. Artificial rabbits optimization: A new bio-inspired meta-heuristic algorithm for solving engineering optimization problems. Eng. Appl. Artif. Intell. 2022, 114, 105082. [Google Scholar] [CrossRef]
- Singh, S.; Bansal, J.C. Mutation-driven grey wolf optimizer with modified search mechanism. Expert Syst. Appl. 2022, 194, 116450. [Google Scholar] [CrossRef]
- Yu, X.; Xu, W.; Li, C. Opposition-based learning grey wolf optimizer for global optimization. Knowl.-Based Syst. 2021, 226, 107139. [Google Scholar] [CrossRef]
- Tizhoosh, H.R. Opposition-based learning: A new scheme for machine intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; Volume 1, pp. 695–701. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Dim | Range | |
|---|---|---|---|
| 30 | [−100, 100] | 0 | |
| 30 | [−10, 10] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−30, 30] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−1.28, 1.28] | 0 |
| Function | Dim | Range | |
|---|---|---|---|
| 30 | [−500, 500] | ||
| 30 | [−5.12, 5.12] | 0 | |
| 30 | [−32, 32] | 0 | |
| 30 | [−600, 600] | 0 | |
| 30 | [−50, 50] | 0 | |
| 30 | [−50, 50] | 0 |
| Function | Dim | Range | |
|---|---|---|---|
| 4 | [−5, 5] | 0.0003 | |
| 2 | [−5, 5] | 0.398 | |
| 2 | [−2, 2] | 3 | |
| 6 | [0, 1] | −3.32 | |
| 4 | [0, 10] | −10.5363 |
| Function | Algorithm | Best | Mean | Worst | St. dev |
|---|---|---|---|---|---|
| F1 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | 0 | 0 | 0 | 0 | |
| F2 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | 0 | 0 | 0 | 0 | |
| F3 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | 0 | 0 | 0 | 0 | |
| F4 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | 0 | 0 | 0 | 0 | |
| F5 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F6 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F7 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO |
| Function | Algorithm | Best | Mean | Worst | St. dev |
|---|---|---|---|---|---|
| F8 | MSIAR-GWO | − | − | − | |
| GWO | − | − | − | ||
| ARO | − | − | − | ||
| DBO | − | − | − | ||
| WOA | − | − | − | ||
| IGWO | − | − | − | ||
| AGWO | − | − | − | ||
| RSMGWO | − | − | − | ||
| F9 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | |||||
| ARO | 0 | 0 | 0 | 0 | |
| DBO | 0 | 0 | 0 | 0 | |
| WOA | 0 | 0 | 0 | 0 | |
| IGWO | |||||
| AGWO | 0 | 0 | 0 | 0 | |
| RSMGWO | 0 | 0 | 0 | 0 | |
| F10 | MSIAR-GWO | 0 | |||
| GWO | |||||
| ARO | 0 | ||||
| DBO | 0 | ||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F11 | MSIAR-GWO | 0 | 0 | 0 | 0 |
| GWO | 0 | ||||
| ARO | 0 | 0 | 0 | 0 | |
| DBO | 0 | 0 | 0 | 0 | |
| WOA | 0 | 0 | 0 | 0 | |
| IGWO | 0 | ||||
| AGWO | 0 | 0 | 0 | 0 | |
| RSMGWO | 0 | 0 | 0 | 0 | |
| F12 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F13 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO |
| Function | Algorithm | Best | Mean | Worst | St. dev |
|---|---|---|---|---|---|
| F14 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F15 | MSIAR-GWO | 0 | |||
| GWO | |||||
| ARO | 0 | ||||
| DBO | 0 | ||||
| WOA | |||||
| IGWO | 0 | ||||
| AGWO | |||||
| RSMGWO | |||||
| F16 | MSIAR-GWO | ||||
| GWO | |||||
| ARO | |||||
| DBO | |||||
| WOA | |||||
| IGWO | |||||
| AGWO | |||||
| RSMGWO | |||||
| F17 | MSIAR-GWO | − | − | − | |
| GWO | − | − | − | ||
| ARO | − | − | − | ||
| DBO | − | − | − | ||
| WOA | − | − | − | ||
| IGWO | − | − | − | ||
| AGWO | − | − | − | ||
| RSMGWO | − | − | − | ||
| F18 | MSIAR-GWO | − | − | − | |
| GWO | − | − | − | ||
| ARO | − | − | − | ||
| DBO | − | − | − | ||
| WOA | − | − | − | ||
| IGWO | − | − | − | ||
| AGWO | − | − | − | ||
| RSMGWO | − | − | − |
| Function | GWO | ARO | DBO | WOA | IGWO | AGWO | RSMGWO |
|---|---|---|---|---|---|---|---|
| P/R | P/R | P/R | P/R | P/R | P/R | P/R | |
| F1 | NAN | ||||||
| F2 | NAN | ||||||
| F3 | NAN | ||||||
| F4 | NAN | ||||||
| F5 | |||||||
| F6 | |||||||
| F7 | |||||||
| F8 | |||||||
| F9 | NAN | NAN | NAN | NAN | NAN | ||
| F10 | NAN | NAN | |||||
| F11 | NAN | NAN | NAN | NAN | NAN | ||
| F12 | |||||||
| F13 | |||||||
| F14 | |||||||
| F15 | NAN | NAN | NAN | ||||
| F16 | |||||||
| F17 | |||||||
| F18 | |||||||
| +/=/− | 18/0/0 | 14/4/0 | 14/4/0 | 15/2/1 | 14/1/3 | 16/2/0 | 11/6/1 |
| Algorithm | MSIAR-GWO | A* | |
|---|---|---|---|
| Map Dimensions | |||
| 20 × 20 | 29.1038 | 30.3848 | |
| 40 × 40 | 57.7521 | 59.2548 | |
| Map Dimensions | Algorithm | The Optimal Length | Average Length of Path | Path Standard Deviation |
|---|---|---|---|---|
| 20 × 20 | MSIAR-GWO | 28.0192 | 28.5610 | 0.5917 |
| GWO | 28.0285 | 29.8550 | 1.4466 | |
| ARO | 28.0192 | 28.7696 | 0.7939 | |
| DBO | 28.0285 | 29.8079 | 1.4803 | |
| WOA | 29.3782 | 32.2861 | 1.9639 | |
| IGWO | 28.0285 | 28.7271 | 0.5717 | |
| AGWO | 28.0285 | 30.5612 | 2.0611 | |
| RSMGWO | 28.0285 | 29.6183 | 0.9251 |
| Map Dimensions | Algorithm | The Optimal Length | Average Length of Path | Path Standard Deviation |
|---|---|---|---|---|
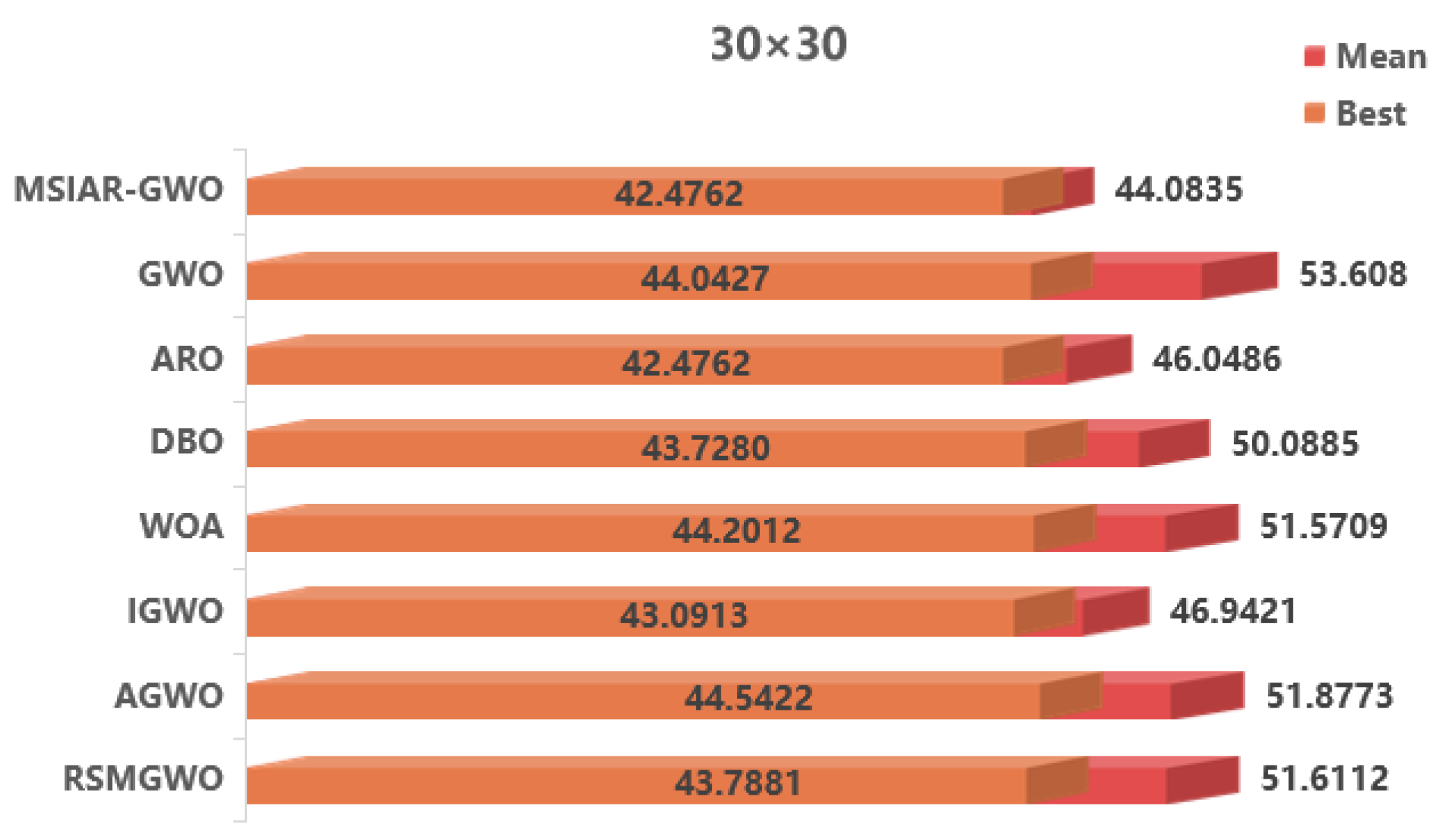
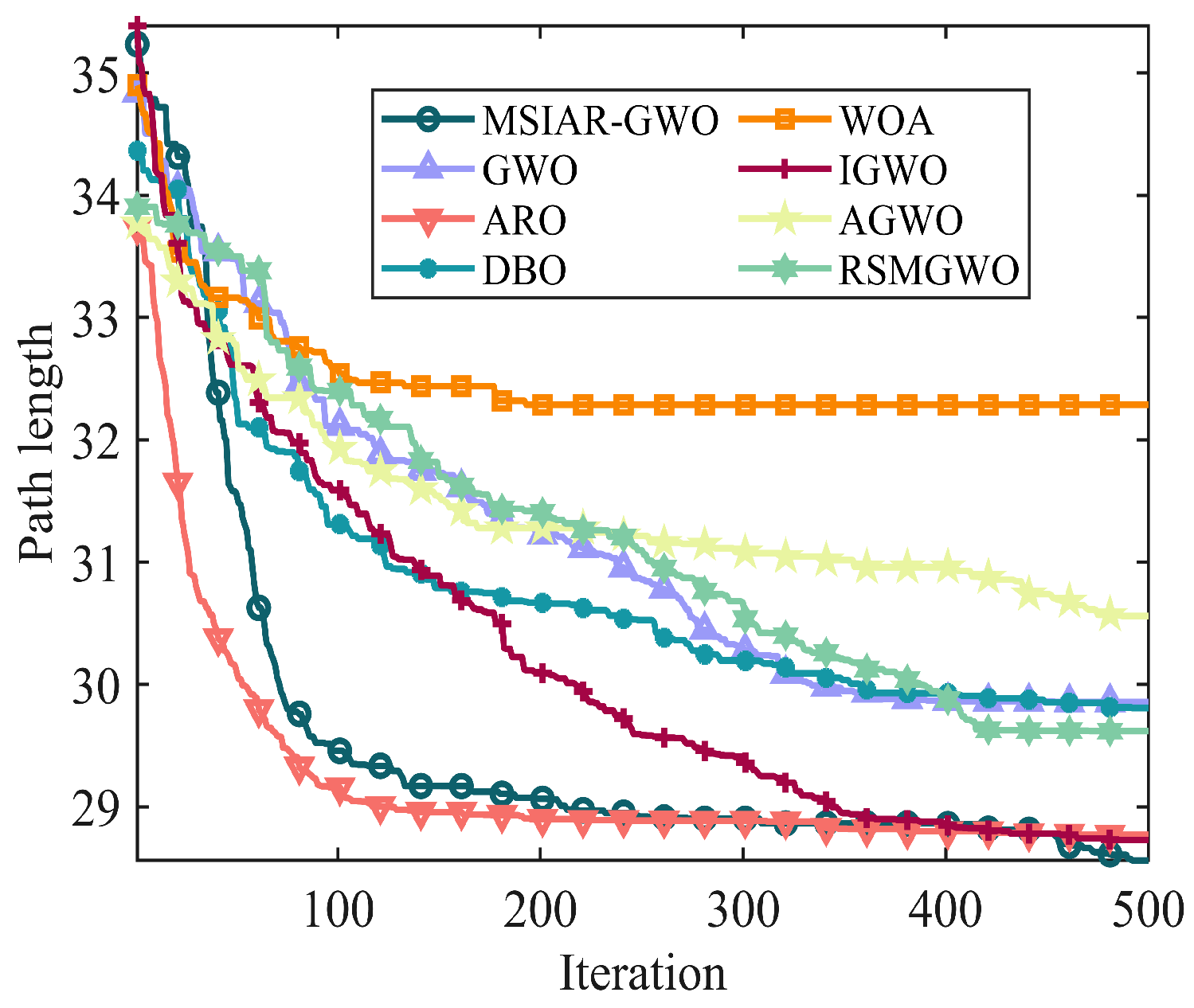
| 30 × 30 | MSIAR-GWO | 42.4762 | 44.0835 | 2.1519 |
| GWO | 44.0427 | 53.6080 | 5.0156 | |
| ARO | 42.4762 | 46.0486 | 3.3236 | |
| DBO | 43.7280 | 50.0885 | 3.8749 | |
| WOA | 44.2012 | 51.5709 | 3.9140 | |
| IGWO | 43.0913 | 46.9421 | 2.9170 | |
| AGWO | 44.5422 | 51.8773 | 4.9659 | |
| RSMGWO | 43.7881 | 51.6112 | 4.5937 |
| Map Dimensions | Algorithm | The Optimal Length | Average Length of Path | Path Standard Deviation |
|---|---|---|---|---|
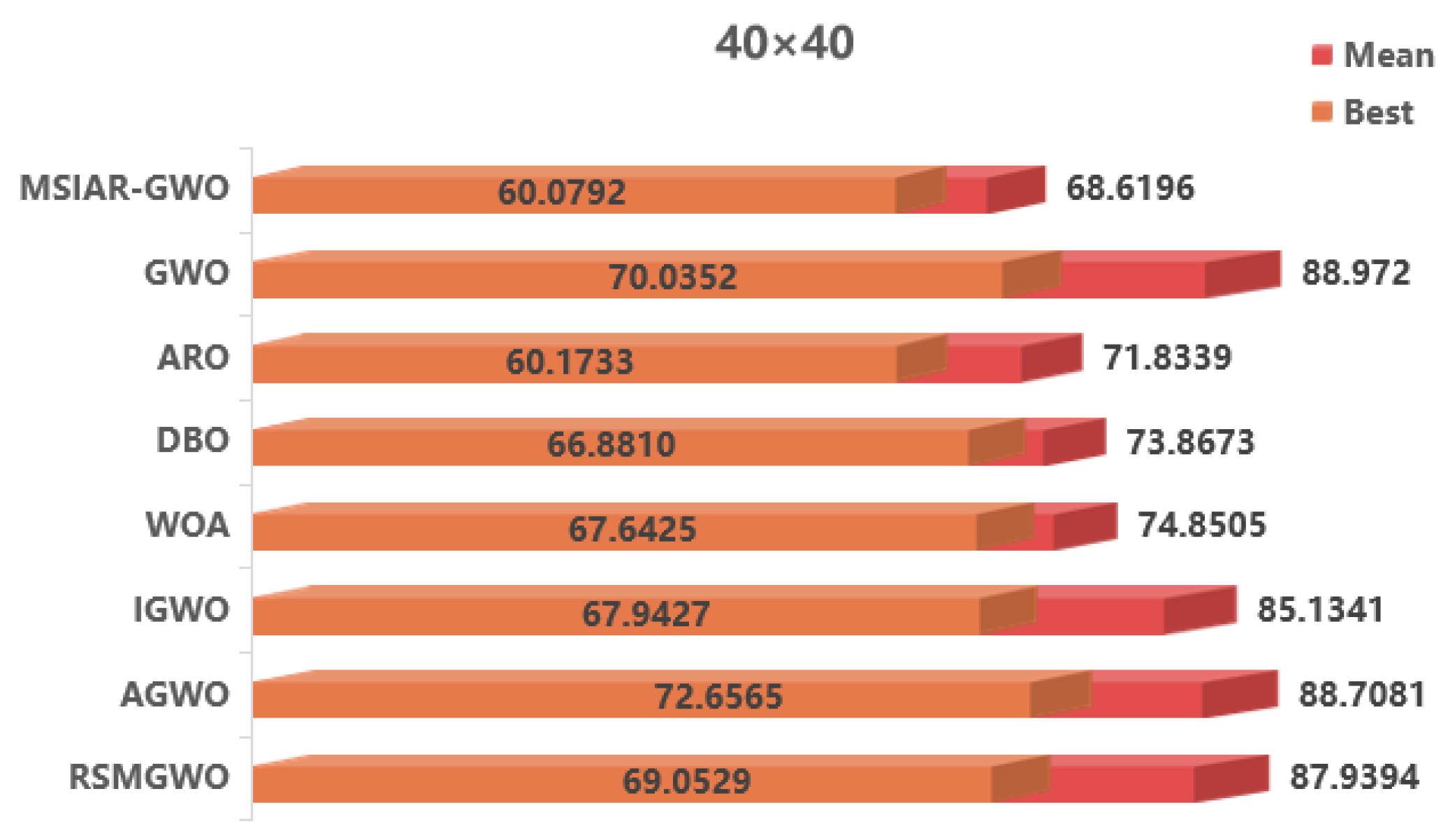
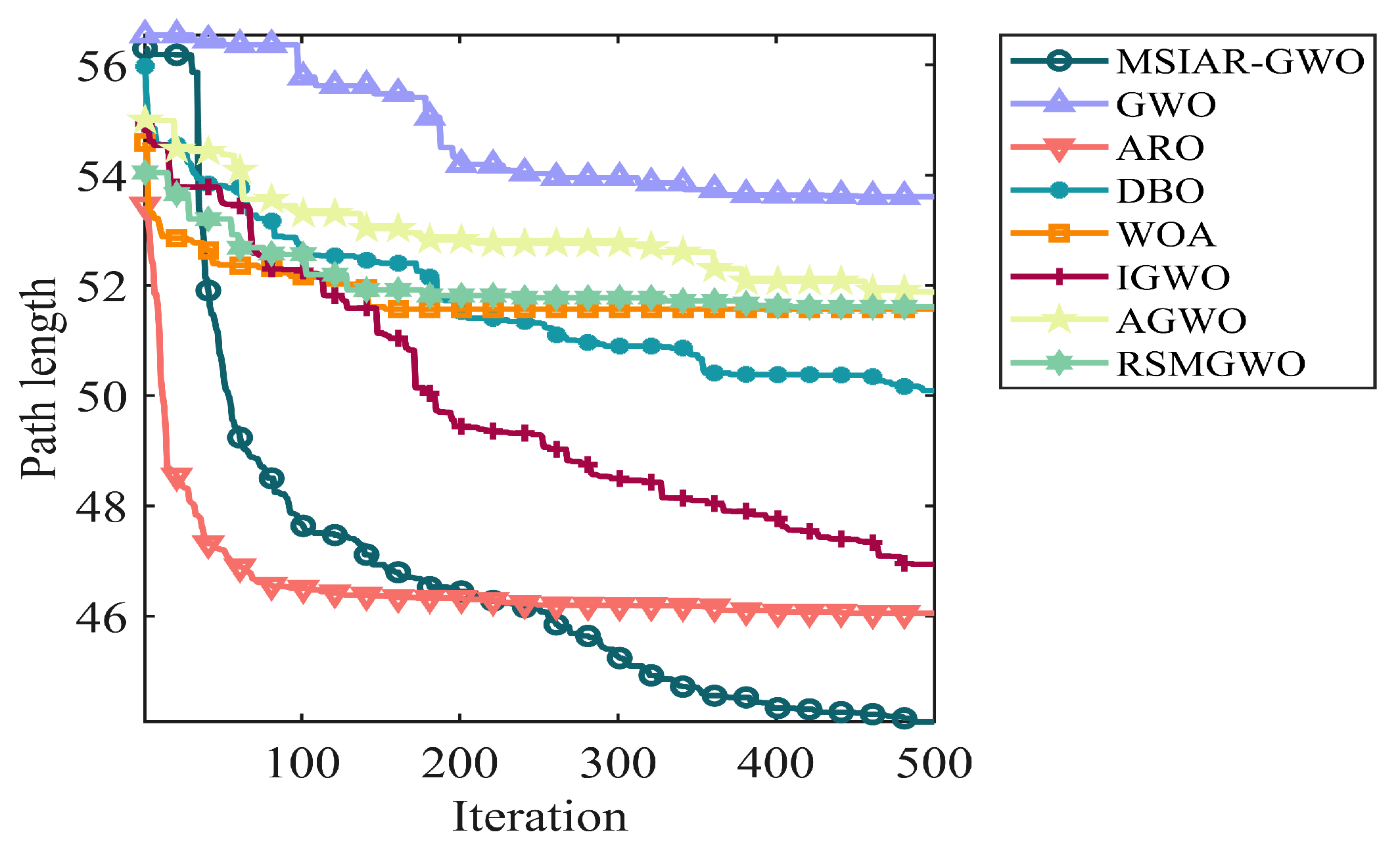
| 40 × 40 | MSIAR-GWO | 60.0792 | 68.6196 | 4.0058 |
| GWO | 70.0352 | 88.9720 | 11.7363 | |
| ARO | 60.1733 | 71.8339 | 6.2240 | |
| DBO | 66.8810 | 73.8673 | 2.5526 | |
| WOA | 67.6425 | 74.8505 | 2.7714 | |
| IGWO | 67.9427 | 85.1341 | 9.8011 | |
| AGWO | 72.6565 | 88.7081 | 10.6476 | |
| RSMGWO | 69.0529 | 87.9394 | 7.4126 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, D.; Liu, J.; Li, T.; He, J.; Chen, Y.; Zhu, W. Research on Mobile Robot Path Planning Based on MSIAR-GWO Algorithm. Sensors 2025, 25, 892. https://doi.org/10.3390/s25030892
Chen D, Liu J, Li T, He J, Chen Y, Zhu W. Research on Mobile Robot Path Planning Based on MSIAR-GWO Algorithm. Sensors. 2025; 25(3):892. https://doi.org/10.3390/s25030892
Chicago/Turabian StyleChen, Danfeng, Junlang Liu, Tengyun Li, Jun He, Yong Chen, and Wenbo Zhu. 2025. "Research on Mobile Robot Path Planning Based on MSIAR-GWO Algorithm" Sensors 25, no. 3: 892. https://doi.org/10.3390/s25030892
APA StyleChen, D., Liu, J., Li, T., He, J., Chen, Y., & Zhu, W. (2025). Research on Mobile Robot Path Planning Based on MSIAR-GWO Algorithm. Sensors, 25(3), 892. https://doi.org/10.3390/s25030892