
A Review of Embodied Grasping

Abstract
1. Introduction
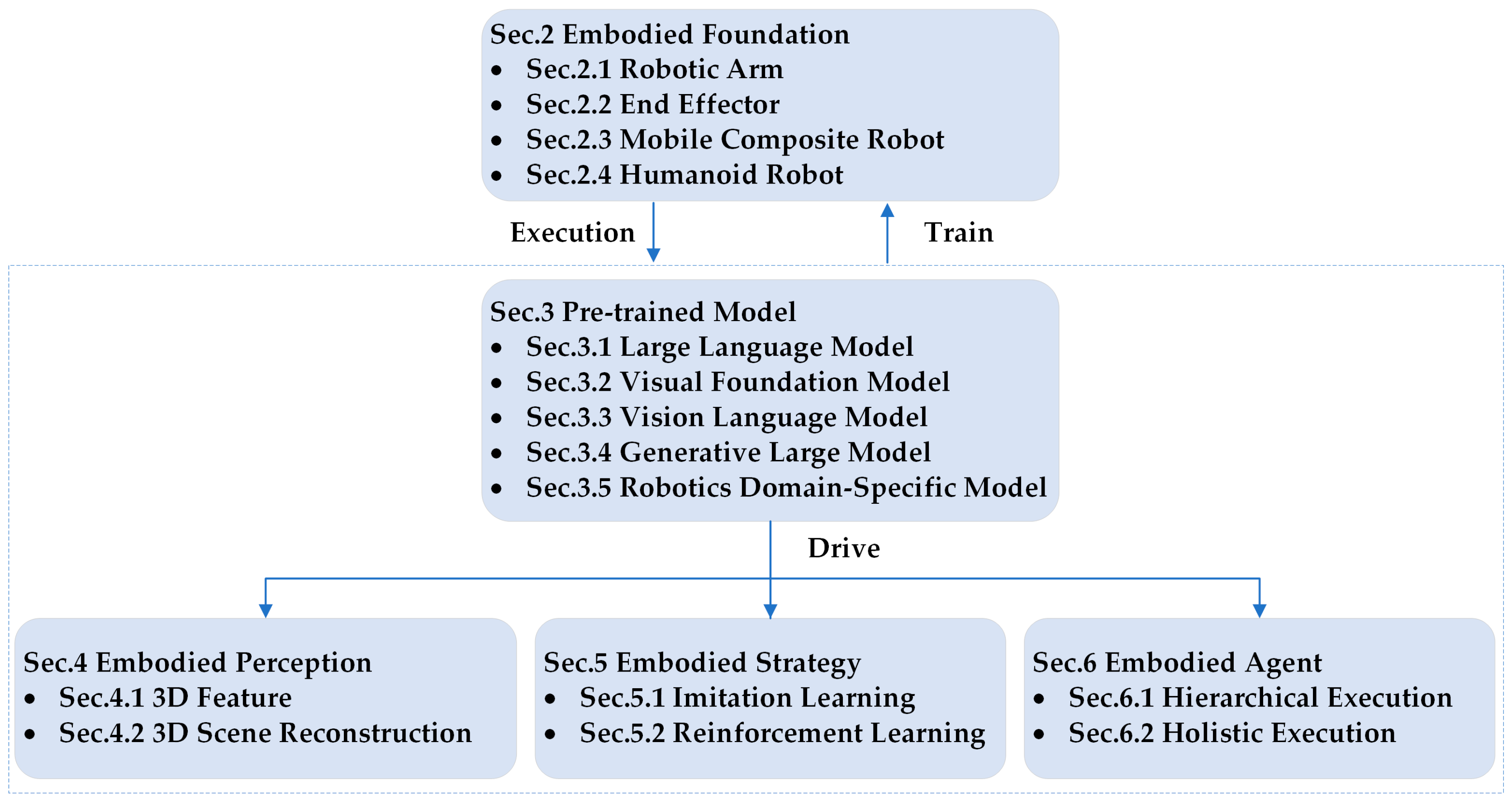
2. Embodied Foundation
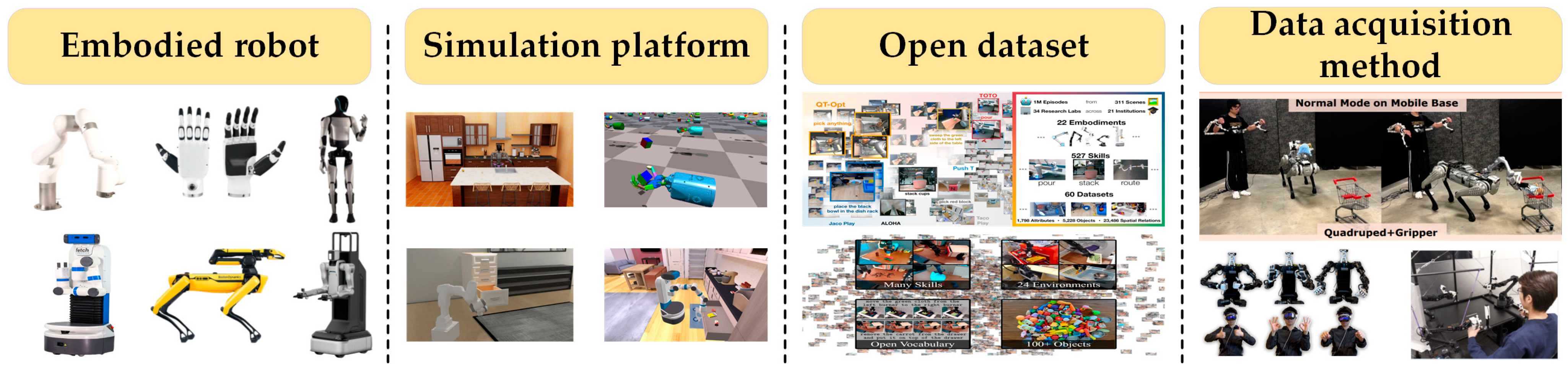
2.1. Robotic Arm
2.2. End Effector
2.3. Mobile Composite Robot
2.4. Humanoid Robot
3. Pre-Trained Model
3.1. Large Language Model
3.2. Visual Foundation Model
3.3. Visual–Language Model
3.4. Generative Large Model
3.5. Robotics Domain-Specific Model
4. Embodied Perception
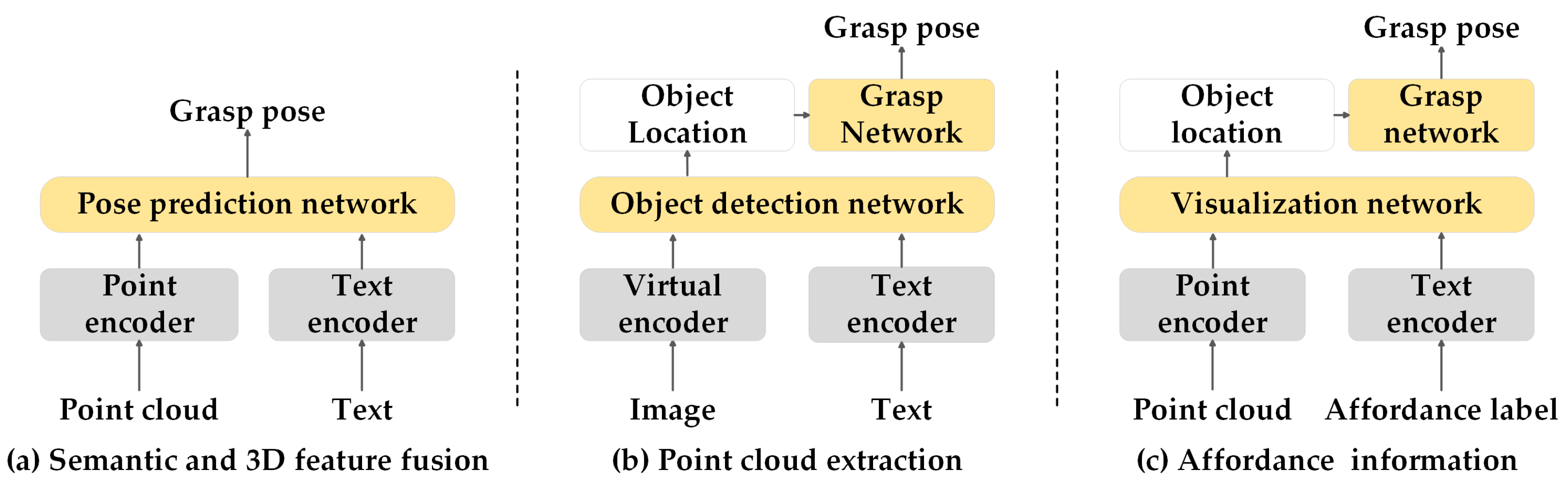
4.1. Three-Dimensional Feature
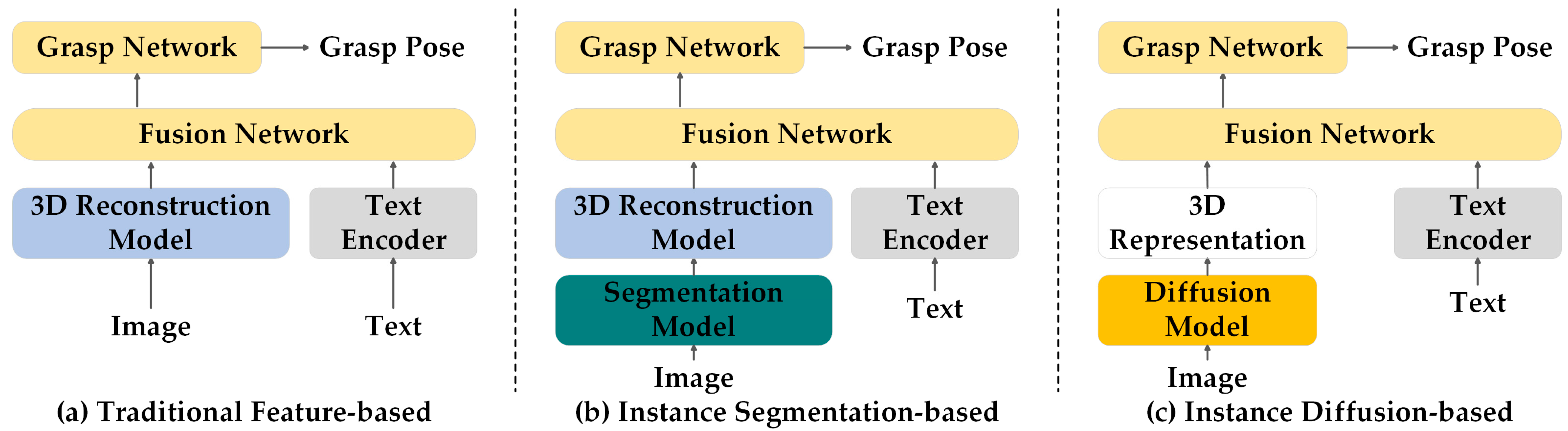
4.2. Three-Dimensional Scene Reconstruction
5. Embodied Strategy
5.1. Imitation Learning
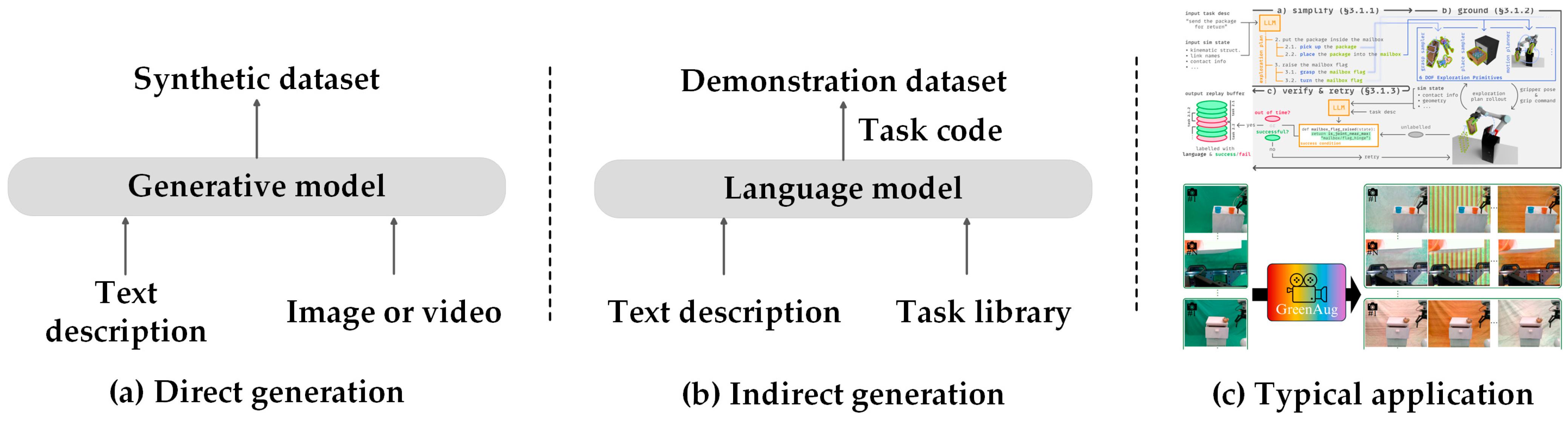
5.1.1. Data Augmentation
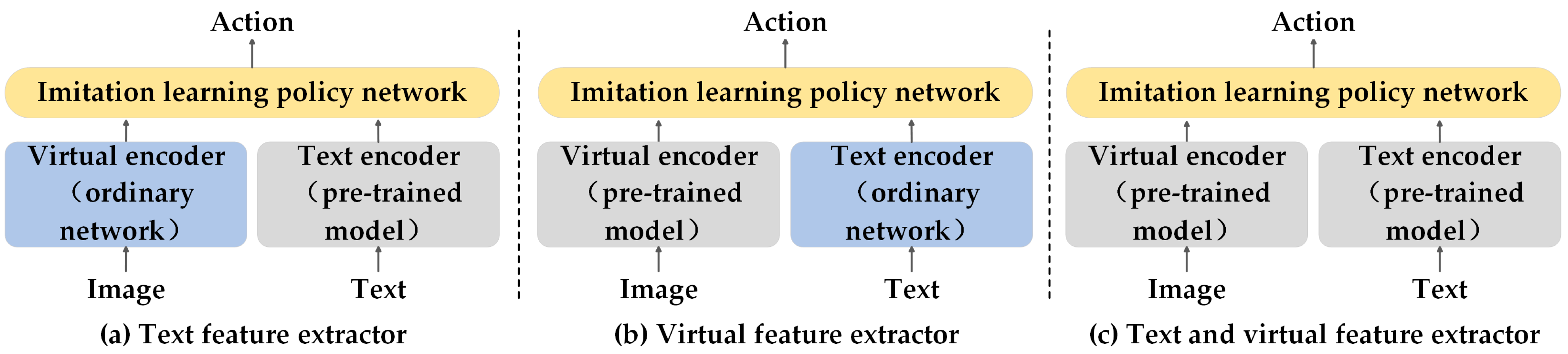
5.1.2. Feature Extractor
5.2. Reinforcement Learning
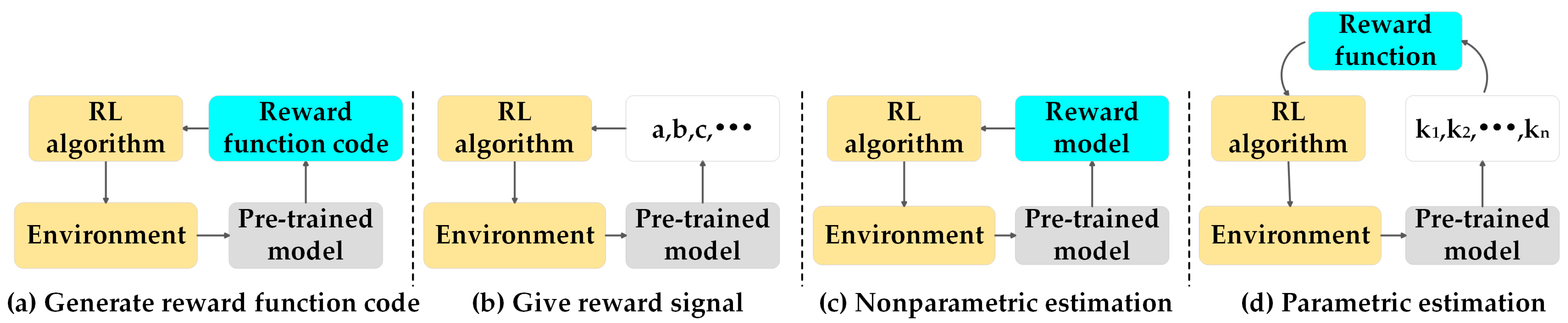
5.2.1. Reward Function Calculation
5.2.2. Reward Function Estimation
6. Embodied Agent
6.1. Hierarchical Execution
6.1.1. Low-Level Control Strategy
6.1.2. Skills Library
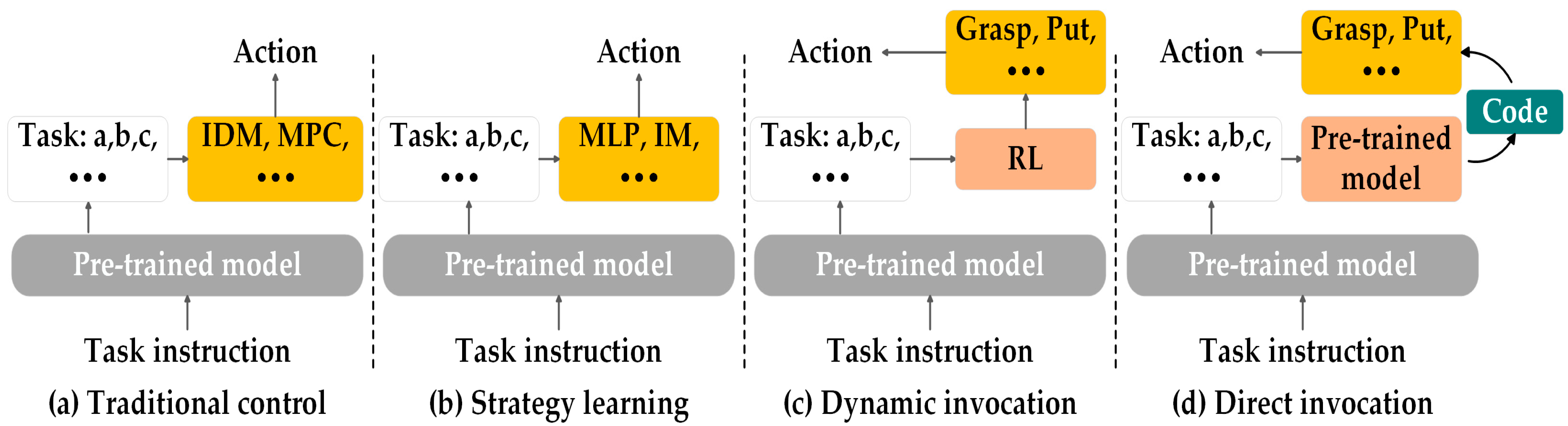
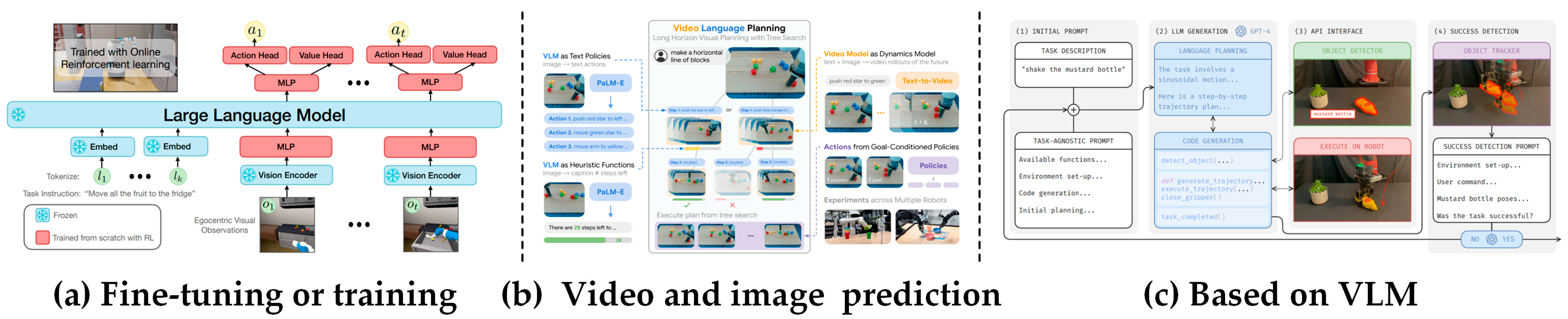
6.2. Holistic Execution
7. Challenges and Prospects
7.1. Problems with Dataset Acquisition
7.2. Adaptation Problems in Realistic Tasks of Models
7.3. Problem of Generalization of Strategies
7.4. Problems in Executing Long Sequence Tasks
7.5. Interpretability Problem
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Baruah, T.; Mojumder, S.A.; Dong, S.; Gong, X.; Treadway, S.; Bao, Y.; Hance, S.; McCardwell, C.; Zhao, V. Mgpusim: Enabling Multi-Gpu Performance Modeling and Optimization. In Proceedings of the 46th International Symposium on Computer Architecture, Phoenix, AZ, USA, 22–26 June 2019. [Google Scholar]
- Jouppi, N.; Kurian, G.; Li, S.; Ma, P.; Nagarajan, R.; Nai, L.; Patil, N.; Subramanian, S.; Swing, A.; Towles, B. Tpu V4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Los Angeles, CA, USA, 18–22 June 2023. [Google Scholar]
- Mining, W.I.D. Data Mining: Concepts and Techniques. Morgan Kaufinann 2006, 10, 4. [Google Scholar]
- Chen, X.; Hsieh, C.-J.; Gong, B. When Vision Transformers Outperform Resnets without Pre-Training or Strong Data Augmentations. arXiv 2021, arXiv:2106.01548. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, Y. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. Gpt-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Li, C. Large Multimodal Models: Notes on Cvpr 2023 Tutorial. arXiv 2023, arXiv:2306.14895. [Google Scholar]
- Xiao, T.; Radosavovic, I.; Darrell, T.; Malik, J. Masked Visual Pre-Training for Motor Control. arXiv 2022, arXiv:2203.06173. [Google Scholar]
- Nguyen, N.; Vu, M.N.; Huang, B.; Vuong, A.; Le, N.; Vo, T.; Nguyen, A. Lightweight Language-Driven Grasp Detection Using Conditional Consistency Model. arXiv 2024, arXiv:2407.17967. [Google Scholar]
- Seo, Y.; Uruç, J.; James, S. Continuous Control with Coarse-to-Fine Reinforcement Learning. arXiv 2024, arXiv:2407.07787. [Google Scholar]
- Sharma, M.; Fantacci, C.; Zhou, Y.; Koppula, S.; Heess, N.; Scholz, J.; Aytar, Y. Lossless Adaptation of Pretrained Vision Models for Robotic Manipulation. arXiv 2023, arXiv:2304.06600. [Google Scholar]
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Zhong, S.; Yin, B.; Hu, X. Harnessing the Power of Llms in Practice: A Survey on Chatgpt and Beyond. ACM Trans. Knowl. Discov. Data 2024, 18, 1–32. [Google Scholar] [CrossRef]
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A Survey on Large Language Model (Llm) Security and Privacy: The Good, the Bad, and the Ugly. High-Confid. Comput. 2024, 4, 100211. [Google Scholar] [CrossRef]
- Yang, S.; Nachum, O.; Du, Y.; Wei, J.; Abbeel, P.; Schuurmans, D. Foundation Models for Decision Making: Problems, Methods, and Opportunities. arXiv 2023, arXiv:2303.04129. [Google Scholar]
- Hu, Y.; Xie, Q.; Jain, V.; Francis, J.; Patrikar, J.; Keetha, N.; Kim, S.; Xie, Y.; Zhang, T.; Fang, H.-S. Toward General-Purpose Robots Via Foundation Models: A Survey and Meta-Analysis. arXiv 2023, arXiv:2312.08782. [Google Scholar]
- Xiao, X.; Liu, J.; Wang, Z.; Zhou, Y.; Qi, Y.; Cheng, Q.; He, B.; Jiang, S. Robot Learning in the Era of Foundation Models: A Survey. arXiv 2023, arXiv:2311.14379. [Google Scholar]
- Zheng, Y.; Yao, L.; Su, Y.; Zhang, Y.; Wang, Y.; Zhao, S.; Zhang, Y.; Chau, L.-P. A Survey of Embodied Learning for Object-Centric Robotic Manipulation. arXiv 2024, arXiv:2408.11537. [Google Scholar]
- Ma, S.; Tang, T.; You, H.; Zhao, Y.; Ma, X.; Wang, J. An Robotic Arm System for Automatic Welding of Bars Based on Image Denoising. In Proceedings of the 2021 3rd International Conference on Robotics and Computer Vision (ICRCV), Guangzhou, China, 19–21 November 2021. [Google Scholar]
- Li, M.; Wu, F.; Wang, F.; Zou, T.; Li, M.; Xiao, X. Cnn-Mlp-Based Configurable Robotic Arm for Smart Agriculture. Agriculture 2024, 14, 1624. [Google Scholar] [CrossRef]
- Haddadin, S.; Parusel, S.; Johannsmeier, L.; Golz, S.; Gabl, S.; Walch, F.; Sabaghian, M.; Jähne, C.; Hausperger, L.; Haddadin, S. The Franka Emika Robot: A Reference Platform for Robotics Research and Education. IEEE Robot. Autom. Mag. 2022, 29, 46–64. [Google Scholar] [CrossRef]
- Feng, Y.; Hansen, N.; Xiong, Z.; Rajagopalan, C.; Wang, X. Finetuning Offline World Models in the Real World. arXiv 2023, arXiv:2310.16029. [Google Scholar]
- Raviola, A.; Guida, R.; Bertolino, A.C.; De Martin, A.; Mauro, S.; Sorli, M. A Comprehensive Multibody Model of a Collaborative Robot to Support Model-Based Health Management. Robotics 2023, 12, 71. [Google Scholar] [CrossRef]
- Humphreys, J.; Peers, C.; Li, J.; Wan, Y.; Sun, J.; Richardson, R.; Zhou, C. Teleoperating a Legged Manipulator through Whole-Body Control. In Proceedings of the Annual Conference Towards Autonomous Robotic Systems, Manchester, UK, 12–14 July 2022. [Google Scholar]
- Koenig, N.; Howard, A. Design and Use Paradigms for Gazebo, an Open-Source Multi-Robot Simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004. [Google Scholar]
- Coumans, E.; Bai, Y. Pybullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning. 2016. Available online: http://pybullet.org (accessed on 16 November 2024).
- Xiang, F.; Qin, Y.; Mo, K.; Xia, Y.; Zhu, H.; Liu, F.; Liu, M.; Jiang, H.; Yuan, Y.; Wang, H. Sapien: A Simulated Part-Based Interactive Environment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhu, Y.; Wong, J.; Mandlekar, A.; Martín-Martín, R.; Joshi, A.; Nasiriany, S.; Zhu, Y. Robosuite: A Modular Simulation Framework and Benchmark for Robot Learning. arXiv 2020, arXiv:2009.12293. [Google Scholar]
- Mu, T.; Ling, Z.; Xiang, F.; Yang, D.; Li, X.; Tao, S.; Huang, Z.; Jia, Z.; Su, H. Maniskill: Generalizable Manipulation Skill Benchmark with Large-Scale Demonstrations. arXiv 2021, arXiv:2107.14483. [Google Scholar]
- Gu, J.; Xiang, F.; Li, X.; Ling, Z.; Liu, X.; Mu, T.; Tang, Y.; Tao, S.; Wei, X.; Yao, Y. Maniskill2: A Unified Benchmark for Generalizable Manipulation Skills. arXiv 2023, arXiv:2302.04659. [Google Scholar]
- Nasiriany, S.; Maddukuri, A.; Zhang, L.; Parikh, A.; Lo, A.; Joshi, A.; Mandlekar, A.; Zhu, Y. Robocasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. arXiv 2024, arXiv:2406.02523. [Google Scholar]
- Zhou, Z.; Song, J.; Xie, X.; Shu, Z.; Ma, L.; Liu, D.; Yin, J.; See, S. Towards Building Ai-Cps with Nvidia Isaac Sim: An Industrial Benchmark and Case Study for Robotics Manipulation. In Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice, Madrid, Spain, 29 May–2 June 2024. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020. [Google Scholar]
- Walke, H.R.; Black, K.; Zhao, T.Z.; Vuong, Q.; Zheng, C.; Hansen-Estruch, P.; He, A.W.; Myers, V.; Kim, M.J.; Du, M. Bridgedata V2: A Dataset for Robot Learning at Scale. In Proceedings of the Conference on Robot Learning, New York, NY, USA, 13–15 October 2023. [Google Scholar]
- Fang, H.-S.; Fang, H.; Tang, Z.; Liu, J.; Wang, J.; Zhu, H.; Lu, C. Rh20t: A Robotic Dataset for Learning Diverse Skills in One-Shot. In Proceedings of the RSS 2023 Workshop on Learning for Task and Motion Planning, New York, NY, USA, 13–15 October 2023. [Google Scholar]
- O’Neill, A.; Rehman, A.; Gupta, A.; Maddukuri, A.; Gupta, A.; Padalkar, A.; Lee, A.; Pooley, A.; Gupta, A.; Mandlekar, A. Open X-Embodiment: Robotic Learning Datasets and Rt-X Models. arXiv 2023, arXiv:2310.08864. [Google Scholar]
- Chen, X.; Ye, Z.; Sun, J.; Fan, Y.; Hu, F.; Wang, C.; Lu, C. Transferable Active Grasping and Real Embodied Dataset. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020. [Google Scholar]
- Zhang, H.; Yang, D.; Wang, H.; Zhao, B.; Lan, X.; Ding, J.; Zheng, N. Regrad: A Large-Scale Relational Grasp Dataset for Safe and Object-Specific Robotic Grasping in Clutter. IEEE Robot. Autom. Lett. 2022, 7, 2929–2936. [Google Scholar] [CrossRef]
- Fang, H.-S.; Wang, C.; Gou, M.; Lu, C. Graspnet-1billion: A Large-Scale Benchmark for General Object Grasping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Vuong, A.D.; Vu, M.N.; Le, H.; Huang, B.; Huynh, B.; Vo, T.; Kugi, A.; Nguyen, A. Grasp-Anything: Large-Scale Grasp Dataset from Foundation Models. arXiv 2023, arXiv:2309.09818. [Google Scholar]
- Kim, J.; Jeon, M.-H.; Jung, S.; Yang, W.; Jung, M.; Shin, J.; Kim, A. Transpose: Large-Scale Multispectral Dataset for Transparent Object. Int. J. Robot. Res. 2024. [Google Scholar] [CrossRef]
- Obrist, J.; Zamora, M.; Zheng, H.; Hinchet, R.; Ozdemir, F.; Zarate, J.; Katzschmann, R.K.; Coros, S. Pokeflex: A Real-World Dataset of Deformable Objects for Robotics. arXiv 2024, arXiv:2410.07688. [Google Scholar]
- Zhou, B.; Zhou, H.; Liang, T.; Yu, Q.; Zhao, S.; Zeng, Y.; Lv, J.; Luo, S.; Wang, Q.; Yu, X. Clothesnet: An Information-Rich 3d Garment Model Repository with Simulated Clothes Environment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 27 October–2 November 2023. [Google Scholar]
- Cartucho, J.; Weld, A.; Tukra, S.; Xu, H.; Matsuzaki, H.; Ishikawa, T.; Kwon, M.; Jang, Y.E.; Kim, K.-J.; Lee, G. Surgt Challenge: Benchmark of Soft-Tissue Trackers for Robotic Surgery. Med. Image Anal. 2024, 91, 102985. [Google Scholar] [CrossRef]
- Chi, C.; Xu, Z.; Pan, C.; Cousineau, E.; Burchfiel, B.; Feng, S.; Tedrake, R.; Song, S. Universal Manipulation Interface: In-the-Wild Robot Teaching without in-the-Wild Robots. arXiv 2024, arXiv:2402.10329. [Google Scholar]
- Zhao, T.Z.; Kumar, V.; Levine, S.; Finn, C. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. arXiv 2023, arXiv:2304.13705. [Google Scholar]
- Wu, P.; Shentu, Y.; Yi, Z.; Lin, X.; Abbeel, P. Gello: A General, Low-Cost, and Intuitive Teleoperation Framework for Robot Manipulators. arXiv 2023, arXiv:2309.13037. [Google Scholar]
- Aldaco, J.; Armstrong, T.; Baruch, R.; Bingham, J.; Chan, S.; Draper, K.; Dwibedi, D.; Finn, C.; Florence, P.; Goodrich, S. Aloha 2: An Enhanced Low-Cost Hardware for Bimanual Teleoperation. arXiv 2024, arXiv:2405.02292. [Google Scholar]
- Dhat, V.; Walker, N.; Cakmak, M. Using 3d Mice to Control Robot Manipulators. In Proceedings of the 2024 ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 11–14 March 2024. [Google Scholar]
- Mandlekar, A.; Booher, J.; Spero, M.; Tung, A.; Gupta, A.; Zhu, Y.; Garg, A.; Savarese, S.; Fei-Fei, L. Scaling Robot Supervision to Hundreds of Hours with Roboturk: Robotic Manipulation Dataset through Human Reasoning and Dexterity. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Freiberg, R.; Qualmann, A.; Vien, N.A.; Neumann, G. Diffusion for Multi-Embodiment Grasping. arXiv 2024, arXiv:2410.18835. [Google Scholar] [CrossRef]
- Chen, C.-C.; Lan, C.-C. An Accurate Force Regulation Mechanism for High-Speed Handling of Fragile Objects Using Pneumatic Grippers. IEEE Trans. Autom. Sci. Eng. 2017, 15, 1600–1608. [Google Scholar] [CrossRef]
- Pham, H.; Pham, Q.-C. Critically Fast Pick-and-Place with Suction Cups. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- D’Avella, S.; Tripicchio, P.; Avizzano, C.A. A Study on Picking Objects in Cluttered Environments: Exploiting Depth Features for a Custom Low-Cost Universal Jamming Gripper. Robot. Comput.-Integr. Manuf. 2020, 63, 101888. [Google Scholar] [CrossRef]
- Li, X.; Li, N.; Tao, G.; Liu, H.; Kagawa, T. Experimental Comparison of Bernoulli Gripper and Vortex Gripper. Int. J. Precis. Eng. Manuf. 2015, 16, 2081–2090. [Google Scholar] [CrossRef]
- Peng, H.-S.; Liu, C.-Y.; Chen, C.-L. Dynamic Performance Analysis and Design of Vortex Array Grippers. Actuators 2022, 11, 137. [Google Scholar] [CrossRef]
- Guo, J.; Elgeneidy, K.; Xiang, C.; Lohse, N.; Justham, L.; Rossiter, J. Soft Pneumatic Grippers Embedded with Stretchable Electroadhesion. Smart Mater. Struct. 2018, 27, 055006. [Google Scholar] [CrossRef]
- Manes, L.; Fichera, S.; Fakhruldeen, H.; Cooper, A.I.; Paoletti, P. A Soft Cable Loop Based Gripper for Robotic Automation of Chemistry. Sci. Rep. 2024, 14, 8899. [Google Scholar] [CrossRef] [PubMed]
- Sinatra, N.R.; Teeple, C.B.; Vogt, D.M.; Parker, K.K.; Gruber, D.F.; Wood, R.J. Ultragentle Manipulation of Delicate Structures Using a Soft Robotic Gripper. Sci. Robot. 2019, 4, eaax5425. [Google Scholar] [CrossRef] [PubMed]
- Patni, S.P.; Stoudek, P.; Chlup, H.; Hoffmann, M. Evaluating Online Elasticity Estimation of Soft Objects Using Standard Robot Grippers. arXiv 2024, arXiv:2401.08298. [Google Scholar]
- Dai, H.; Lu, Z.; He, M.; Yang, C. Novel Gripper-Like Exoskeleton Design for Robotic Grasping Based on Learning from Demonstration. In Proceedings of the 2022 27th International Conference on Automation and Computing (ICAC), Manchester, UK, 7–9 September 2022. [Google Scholar]
- Song, D.; Ek, C.H.; Huebner, K.; Kragic, D. Embodiment-Specific Representation of Robot Grasping Using Graphical Models and Latent-Space Discretization. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Wang, X.; Geiger, F.; Niculescu, V.; Magno, M.; Benini, L. Smarthand: Towards Embedded Smart Hands for Prosthetic and Robotic Applications. In Proceedings of the 2021 IEEE Sensors Applications Symposium (SAS), Virtual Event, 22–24 February 2021. [Google Scholar]
- Moore, C.H.; Corbin, S.F.; Mayr, R.; Shockley, K.; Silva, P.L.; Lorenz, T. Grasping Embodiment: Haptic Feedback for Artificial Limbs. Front. Neurorobotics 2021, 15, 662397. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, A.; Uppal, S.; Shaw, K.; Pathak, D. Dexterous Functional Grasping. In Proceedings of the 7th Annual Conference on Robot Learning, New York, NY, USA, 13–15 October 2023. [Google Scholar]
- Attarian, M.; Asif, M.A.; Liu, J.; Hari, R.; Garg, A.; Gilitschenski, I.; Tompson, J. Geometry Matching for Multi-Embodiment Grasping. In Proceedings of the Conference on Robot Learning, New York, NY, USA, 13–15 October 2023. [Google Scholar]
- Li, Y.; Liu, B.; Geng, Y.; Li, P.; Yang, Y.; Zhu, Y.; Liu, T.; Huang, S. Grasp Multiple Objects with One Hand. IEEE Robot. Autom. Lett. 2024, 9, 4027–4034. [Google Scholar] [CrossRef]
- Shaw, K.; Agarwal, A.; Pathak, D. Leap Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning. arXiv 2023, arXiv:2309.06440. [Google Scholar]
- Makoviychuk, V.; Wawrzyniak, L.; Guo, Y.; Lu, M.; Storey, K.; Macklin, M.; Hoeller, D.; Rudin, N.; Allshire, A.; Handa, A. Isaac Gym: High Performance Gpu-Based Physics Simulation for Robot Learning. arXiv 2021, arXiv:2108.10470. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. Mujoco: A Physics Engine for Model-Based Control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012. [Google Scholar]
- Wang, C.; Shi, H.; Wang, W.; Zhang, R.; Fei-Fei, L.; Liu, C.K. Dexcap: Scalable and Portable Mocap Data Collection System for Dexterous Manipulation. arXiv 2024, arXiv:2403.07788. [Google Scholar]
- Qin, Y.; Yang, W.; Huang, B.; Van Wyk, K.; Su, H.; Wang, X.; Chao, Y.-W.; Fox, D. Anyteleop: A General Vision-Based Dexterous Robot Arm-Hand Teleoperation System. arXiv 2023, arXiv:2307.04577. [Google Scholar]
- Xu, Y.; Wan, W.; Zhang, J.; Liu, H.; Shan, Z.; Shen, H.; Wang, R.; Geng, H.; Weng, Y.; Chen, J. Unidexgrasp: Universal Robotic Dexterous Grasping Via Learning Diverse Proposal Generation and Goal-Conditioned Policy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 18–24 June 2023. [Google Scholar]
- Chao, Y.-W.; Paxton, C.; Xiang, Y.; Yang, W.; Sundaralingam, B.; Chen, T.; Murali, A.; Cakmak, M.; Fox, D. Handoversim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Rajeswaran, A.; Kumar, V.; Gupta, A.; Vezzani, G.; Schulman, J.; Todorov, E.; Levine, S. Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. arXiv 2017, arXiv:1709.10087. [Google Scholar]
- Jauhri, S.; Lueth, S.; Chalvatzaki, G. Active-Perceptive Motion Generation for Mobile Manipulation. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 20–24 May 2024. [Google Scholar]
- Ulloa, C.C.; Domínguez, D.; Barrientos, A.; del Cerro, J. Design and Mixed-Reality Teleoperation of a Quadruped-Manipulator Robot for Sar Tasks. In Proceedings of the Climbing and Walking Robots Conference, Virtual Event, 7–9 September 2022. [Google Scholar]
- Gu, J.; Chaplot, D.S.; Su, H.; Malik, J. Multi-Skill Mobile Manipulation for Object Rearrangement. arXiv 2022, arXiv:2209.02778. [Google Scholar]
- Shafiullah, N.M.M.; Rai, A.; Etukuru, H.; Liu, Y.; Misra, I.; Chintala, S.; Pinto, L. On Bringing Robots Home. arXiv 2023, arXiv:2311.16098. [Google Scholar]
- Bharadhwaj, H.; Mottaghi, R.; Gupta, A.; Tulsiani, S. Track2act: Predicting Point Tracks from Internet Videos Enables Diverse Zero-Shot Robot Manipulation. arXiv 2024, arXiv:2405.01527. [Google Scholar]
- Zhang, J.; Gireesh, N.; Wang, J.; Fang, X.; Xu, C.; Chen, W.; Dai, L.; Wang, H. Gamma: Graspability-Aware Mobile Manipulation Policy Learning Based on Online Grasping Pose Fusion. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 20–24 May 2024. [Google Scholar]
- Shen, B.; Xia, F.; Li, C.; Martín-Martín, R.; Fan, L.; Wang, G.; Pérez-D’Arpino, C.; Buch, S.; Srivastava, S.; Tchapmi, L. Igibson 1.0: A Simulation Environment for Interactive Tasks in Large Realistic Scenes. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Li, C.; Xia, F.; Martín-Martín, R.; Lingelbach, M.; Srivastava, S.; Shen, B.; Vainio, K.; Gokmen, C.; Dharan, G.; Jain, T. Igibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks. arXiv 2021, arXiv:2108.03272. [Google Scholar]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J. Habitat: A Platform for Embodied Ai Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Szot, A.; Clegg, A.; Undersander, E.; Wijmans, E.; Zhao, Y.; Turner, J.; Maestre, N.; Mukadam, M.; Chaplot, D.S.; Maksymets, O. Habitat 2.0: Training Home Assistants to Rearrange Their Habitat. Adv. Neural Inf. Process. Syst. 2021, 34, 251–266. [Google Scholar]
- Kolve, E.; Mottaghi, R.; Han, W.; VanderBilt, E.; Weihs, L.; Herrasti, A.; Deitke, M.; Ehsani, K.; Gordon, D.; Zhu, Y. Ai2-Thor: An Interactive 3d Environment for Visual Ai. arXiv 2017, arXiv:1712.05474. [Google Scholar]
- Fu, Z.; Zhao, T.Z.; Finn, C. Mobile Aloha: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation. arXiv 2024, arXiv:2401.02117. [Google Scholar]
- Marew, D.; Perera, N.; Yu, S.; Roelker, S.; Kim, D. A Biomechanics-Inspired Approach to Soccer Kicking for Humanoid Robots. arXiv 2024, arXiv:2407.14612. [Google Scholar]
- Bertrand, S.; Penco, L.; Anderson, D.; Calvert, D.; Roy, V.; McCrory, S.; Mohammed, K.; Sanchez, S.; Griffith, W.; Morfey, S. High-Speed and Impact Resilient Teleoperation of Humanoid Robots. arXiv 2024, arXiv:2409.04639. [Google Scholar]
- Guo, Y.; Wang, Y.-J.; Zha, L.; Jiang, Z.; Chen, J. Doremi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment. arXiv 2023, arXiv:2307.00329. [Google Scholar]
- Malik, A.A.; Masood, T.; Brem, A. Intelligent Humanoids in Manufacturing to Address Worker Shortage and Skill Gaps: Case of Tesla Optimus. arXiv 2023, arXiv:2304.04949. [Google Scholar]
- Feng, S.; Whitman, E.; Xinjilefu, X.; Atkeson, C.G. Optimization Based Full Body Control for the Atlas Robot. In Proceedings of the 2014 IEEE-RAS International Conference on Humanoid Robots, Madrid, Spain, 18–20 November 2014. [Google Scholar]
- Cheng, X.; Ji, Y.; Chen, J.; Yang, R.; Yang, G.; Wang, X. Expressive Whole-Body Control for Humanoid Robots. arXiv 2024, arXiv:2402.16796. [Google Scholar]
- Yang, S.; Chen, H.; Fu, Z.; Zhang, W. Force-Feedback Based Whole-Body Stabilizer for Position-Controlled Humanoid Robots. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Zeng, F.; Gan, W.; Wang, Y.; Liu, N.; Yu, P.S. Large Language Models for Robotics: A Survey. arXiv 2023, arXiv:2311.07226. [Google Scholar]
- Chernyadev, N.; Backshall, N.; Ma, X.; Lu, Y.; Seo, Y.; James, S. Bigym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark. arXiv 2024, arXiv:2407.07788. [Google Scholar]
- Mahmood, N.; Ghorbani, N.; Troje, N.F.; Pons-Moll, G.; Black, M.J. Amass: Archive of Motion Capture as Surface Shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019. [Google Scholar]
- Yang, S.; Liu, M.; Qin, Y.; Ding, R.; Li, J.; Cheng, X.; Yang, R.; Yi, S.; Wang, X. Ace: A Cross-Platform Visual-Exoskeletons System for Low-Cost Dexterous Teleoperation. arXiv 2024, arXiv:2408.11805. [Google Scholar]
- Cheng, X.; Li, J.; Yang, S.; Yang, G.; Wang, X. Open-Television: Teleoperation with Immersive Active Visual Feedback. arXiv 2024, arXiv:2407.01512. [Google Scholar]
- Fu, Z.; Zhao, Q.; Wu, Q.; Wetzstein, G.; Finn, C. Humanplus: Humanoid Shadowing and Imitation from Humans. arXiv 2024, arXiv:2406.10454. [Google Scholar]
- Devlin, J. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 30 October 2024).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S. Palm: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Massey, P.A.; Montgomery, C.; Zhang, A.S. Comparison of Chatgpt–3.5, Chatgpt-4, and Orthopaedic Resident Performance on Orthopaedic Assessment Examinations. JAAOS-J. Am. Acad. Orthop. Surg. 2023, 31, 1173–1179. [Google Scholar] [CrossRef] [PubMed]
- Hu, H.; Shang, Y.; Xu, G.; He, C.; Zhang, Q. Can Gpt-O1 Kill All Bugs? arXiv 2024, arXiv:2409.10033. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf (accessed on 30 October 2024). [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3d Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Lyu, H.; Sha, N.; Qin, S.; Yan, M.; Xie, Y.; Wang, R. Advances in Neural Information Processing Systems. Adv. Neural Inf. Process. Syst. 2019, 32. Available online: https://par.nsf.gov/servlets/purl/10195511 (accessed on 30 October 2024).
- Dosovitskiy, A. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 14–19 June 2020. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. Oneformer: One Transformer to Rule Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A. Dinov2: Learning Robust Visual Features without Supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment Anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023. [Google Scholar]
- Ravi, N.; Gabeur, V.; Hu, Y.-T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L. Sam 2: Segment Anything in Images and Videos. arXiv 2024, arXiv:2408.00714. [Google Scholar]
- Ranzinger, M.; Heinrich, G.; Kautz, J.; Molchanov, P. Am-Radio: Agglomerative Model—Reduce All Domains into One. arXiv 2023, arXiv:2312.06709. [Google Scholar]
- Shang, J.; Schmeckpeper, K.; May, B.B.; Minniti, M.V.; Kelestemur, T.; Watkins, D.; Herlant, L. Theia: Distilling Diverse Vision Foundation Models for Robot Learning. arXiv 2024, arXiv:2407.20179. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.-T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.-H.; Li, Z.; Duerig, T. Scaling up Visual and Vision-Language Representation Learning with Noisy Text Supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021. [Google Scholar]
- Girdhar, R.; El-Nouby, A.; Liu, Z.; Singh, M.; Alwala, K.V.; Joulin, A.; Misra, I. Imagebind: One Embedding Space to Bind Them All. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–23 June 2023. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- Alayrac, J.-B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Mensch, A.; Millican, K.; Reynolds, M. Flamingo: A Visual Language Model for Few-Shot Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23716–23736. [Google Scholar]
- Wang, J.; Yang, Z.; Hu, X.; Li, L.; Lin, K.; Gan, Z.; Liu, Z.; Liu, C.; Wang, L. Git: A Generative Image-to-Text Transformer for Vision and Language. arXiv 2022, arXiv:2205.14100. [Google Scholar]
- Su, Y.; Lan, T.; Li, H.; Xu, J.; Wang, Y.; Cai, D. Pandagpt: One Model to Instruction-Follow Them All. arXiv 2023, arXiv:2305.16355. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. Minigpt-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F. Llama: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Peng, Z.; Wang, W.; Dong, L.; Hao, Y.; Huang, S.; Ma, S.; Wei, F. Kosmos-2: Grounding Multimodal Large Language Models to the World. arXiv 2023, arXiv:2306.14824. [Google Scholar]
- Ge, C.; Cheng, S.; Wang, Z.; Yuan, J.; Gao, Y.; Song, J.; Song, S.; Huang, G.; Zheng, B. Convllava: Hierarchical Backbones as Visual Encoder for Large Multimodal Models. arXiv 2024, arXiv:2405.15738. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat Gans on Image Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Epstein, D.; Jabri, A.; Poole, B.; Efros, A.; Holynski, A. Diffusion Self-Guidance for Controllable Image Generation. Adv. Neural Inf. Process. Syst. 2023, 36, 16222–16239. [Google Scholar]
- Clark, K.; Jaini, P. Text-to-Image Diffusion Models Are Zero Shot Classifiers. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/b87bdcf963cad3d0b265fcb78ae7d11e-Paper-Conference.pdf (accessed on 30 October 2024).
- Li, R.; Li, W.; Yang, Y.; Wei, H.; Jiang, J.; Bai, Q. Swinv2-Imagen: Hierarchical Vision Transformer Diffusion Models for Text-to-Image Generation. Neural Comput. Appl. 2023, 36, 17245–17260. [Google Scholar] [CrossRef]
- Reddy, M.D.M.; Basha, M.S.M.; Hari, M.M.C.; Penchalaiah, M.N. Dall-E: Creating Images from Text. UGC Care Group I J. 2021, 8, 71–75. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with Clip Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Gafni, O.; Polyak, A.; Ashual, O.; Sheynin, S.; Parikh, D.; Taigman, Y. Make-a-Scene: Scene-Based Text-to-Image Generation with Human Priors. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T. Photorealistic text-to-Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36479–36494. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Jin, Y.; Sun, Z.; Xu, K.; Chen, L.; Jiang, H.; Huang, Q.; Song, C.; Liu, Y.; Zhang, D.; Song, Y. Video-Lavit: Unified Video-Language Pre-Training with Decoupled Visual-Motional Tokenization. arXiv 2024, arXiv:2402.03161. [Google Scholar]
- Brooks, T.; Peebles, B.; Holmes, C.; DePue, W.; Guo, Y.; Jing, L.; Schnurr, D.; Taylor, J.; Luhman, T.; Luhman, E. Video Generation Models as World Simulators. 2024. Available online: https://openai.com/index/video-generation-models-as-world-simulators (accessed on 1 November 2024).
- Nair, S.; Rajeswaran, A.; Kumar, V.; Finn, C.; Gupta, A. R3m: A Universal Visual Representation for Robot Manipulation. arXiv 2022, arXiv:2203.12601. [Google Scholar]
- Ma, Y.J.; Sodhani, S.; Jayaraman, D.; Bastani, O.; Kumar, V.; Zhang, A. Vip: Towards Universal Visual Reward and Representation Via Value-Implicit Pre-Training. arXiv 2022, arXiv:2210.00030. [Google Scholar]
- Majumdar, A.; Yadav, K.; Arnaud, S.; Ma, J.; Chen, C.; Silwal, S.; Jain, A.; Berges, V.-P.; Wu, T.; Vakil, J. Where Are We in the Search for an Artificial Visual Cortex for Embodied Intelligence? Adv. Neural Inf. Process. Syst. 2023, 36, 655–677. [Google Scholar]
- Karamcheti, S.; Nair, S.; Chen, A.S.; Kollar, T.; Finn, C.; Sadigh, D.; Liang, P. Language-Driven Representation Learning for Robotics. arXiv 2023, arXiv:2302.12766. [Google Scholar]
- Wu, H.; Jing, Y.; Cheang, C.; Chen, G.; Xu, J.; Li, X.; Liu, M.; Li, H.; Kong, T. Unleashing Large-Scale Video Generative Pre-Training for Visual Robot Manipulation. arXiv 2023, arXiv:2312.13139. [Google Scholar]
- Cheang, C.-L.; Chen, G.; Jing, Y.; Kong, T.; Li, H.; Li, Y.; Liu, Y.; Wu, H.; Xu, J.; Yang, Y. Gr-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation. arXiv 2024, arXiv:2410.06158. [Google Scholar]
- Lin, X.; So, J.; Mahalingam, S.; Liu, F.; Abbeel, P. Spawnnet: Learning Generalizable Visuomotor Skills from Pre-Trained Network. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Cham, Switzerland, 2014. [Google Scholar]
- Grauman, K.; Westbury, A.; Byrne, E.; Chavis, Z.; Furnari, A.; Girdhar, R.; Hamburger, J.; Jiang, H.; Liu, M.; Liu, X. Ego4d: Around the World in 3,000 Hours of Egocentric Video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W. The Epic-Kitchens Dataset: Collection, Challenges and Baselines. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4125–4141. [Google Scholar] [CrossRef] [PubMed]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A Short Note on the Kinetics-700 Human Action Dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. arXiv 2017, arXiv:1703.09312. [Google Scholar]
- Guo, D.; Sun, F.; Liu, H.; Kong, T.; Fang, B.; Xi, N. A Hybrid Deep Architecture for Robotic Grasp Detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, Singapore, 29 May–3 June 2017. [Google Scholar]
- Zhou, X.; Lan, X.; Zhang, H.; Tian, Z.; Zhang, Y.; Zheng, N. Fully Convolutional Grasp Detection Network with Oriented Anchor Box. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Zhu, X.; Sun, L.; Fan, Y.; Tomizuka, M. 6-Dof Contrastive Grasp Proposal Network. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Zhu, X.; Zhou, Y.; Fan, Y.; Sun, L.; Chen, J.; Tomizuka, M. Learn to Grasp with Less Supervision: A Data-Efficient Maximum Likelihood Grasp Sampling Loss. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Chisari, E.; Heppert, N.; Welschehold, T.; Burgard, W.; Valada, A. Centergrasp: Object-Aware Implicit Representation Learning for Simultaneous Shape Reconstruction and 6-Dof Grasp Estimation. IEEE Robot. Autom. Lett. 2024, 9, 5094–5101. [Google Scholar] [CrossRef]
- Chen, S.; Tang, W.; Xie, P.; Yang, W.; Wang, G. Efficient Heatmap-Guided 6-Dof Grasp Detection in Cluttered Scenes. IEEE Robot. Autom. Lett. 2023, 8, 4895–4902. [Google Scholar] [CrossRef]
- Ma, H.; Shi, M.; Gao, B.; Huang, D. Generalizing 6-Dof Grasp Detection Via Domain Prior Knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- Lu, Y.; Deng, B.; Wang, Z.; Zhi, P.; Li, Y.; Wang, S. Hybrid Physical Metric for 6-Dof Grasp Pose Detection. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Ma, H.; Huang, D. Towards Scale Balanced 6-Dof Grasp Detection in Cluttered Scenes. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Zhai, G.; Huang, D.; Wu, S.-C.; Jung, H.; Di, Y.; Manhardt, F.; Tombari, F.; Navab, N.; Busam, B. Monograspnet: 6-Dof Grasping with a Single Rgb Image. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Shi, J.; Yong, A.; Jin, Y.; Li, D.; Niu, H.; Jin, Z.; Wang, H. Asgrasp: Generalizable Transparent Object Reconstruction and 6-Dof Grasp Detection from Rgb-D Active Stereo Camera. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Ichnowski, J.; Avigal, Y.; Kerr, J.; Goldberg, K. Dex-Nerf: Using a Neural Radiance Field to Grasp Transparent Objects. arXiv 2021, arXiv:2110.14217. [Google Scholar]
- Dai, Q.; Zhu, Y.; Geng, Y.; Ruan, C.; Zhang, J.; Wang, H. Graspnerf: Multiview-Based 6-Dof Grasp Detection for Transparent and Specular Objects Using Generalizable Nerf. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023. [Google Scholar]
- Tung, H.-Y.F.; Cheng, R.; Fragkiadaki, K. Learning Spatial Common Sense with Geometry-Aware Recurrent Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Tung, H.-Y.F.; Xian, Z.; Prabhudesai, M.; Lal, S.; Fragkiadaki, K. 3d-Oes: Viewpoint-Invariant Object-Factorized Environment Simulators. arXiv 2020, arXiv:2011.06464. [Google Scholar]
- Chen, S.; Garcia, R.; Schmid, C.; Laptev, I. Polarnet: 3d Point Clouds for Language-Guided Robotic Manipulation. arXiv 2023, arXiv:2309.15596. [Google Scholar]
- Guhur, P.-L.; Chen, S.; Pinel, R.G.; Tapaswi, M.; Laptev, I.; Schmid, C. Instruction-Driven History-Aware Policies for Robotic Manipulations. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Shridhar, M.; Manuelli, L.; Fox, D. Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Tang, C.; Huang, D.; Ge, W.; Liu, W.; Zhang, H. Graspgpt: Leveraging Semantic Knowledge from a Large Language Model for Task-Oriented Grasping. IEEE Robot. Autom. Lett. 2023, 8, 7551–7558. [Google Scholar] [CrossRef]
- Guo, D.; Xiang, Y.; Zhao, S.; Zhu, X.; Tomizuka, M.; Ding, M.; Zhan, W. Phygrasp: Generalizing Robotic Grasping with Physics-Informed Large Multimodal Models. arXiv 2024, arXiv:2402.16836. [Google Scholar]
- Lu, Y.; Fan, Y.; Deng, B.; Liu, F.; Li, Y.; Wang, S. Vl-Grasp: A 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023. [Google Scholar]
- Meng, L.; Qi, Z.; Shuchang, L.; Chunlei, W.; Yujing, M.; Guangliang, C.; Chenguang, Y. Ovgnet: A Unified Visual-Linguistic Framework for Open-Vocabulary Robotic Grasping. arXiv 2024, arXiv:2407.13175. [Google Scholar]
- Nguyen, T.; Vu, M.N.; Vuong, A.; Nguyen, D.; Vo, T.; Le, N.; Nguyen, A. Open-Vocabulary Affordance Detection in 3d Point Clouds. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023. [Google Scholar]
- Ju, Y.; Hu, K.; Zhang, G.; Zhang, G.; Jiang, M.; Xu, H. Robo-Abc: Affordance Generalization Beyond Categories Via Semantic Correspondence for Robot Manipulation. arXiv 2024, arXiv:2401.07487. [Google Scholar]
- Kuang, Y.; Ye, J.; Geng, H.; Mao, J.; Deng, C.; Guibas, L.; Wang, H.; Wang, Y. Ram: Retrieval-Based Affordance Transfer for Generalizable Zero-Shot Robotic Manipulation. arXiv 2024, arXiv:2407.04689. [Google Scholar]
- Wang, Q.; Zhang, H.; Deng, C.; You, Y.; Dong, H.; Zhu, Y.; Guibas, L. Sparsedff: Sparse-View Feature Distillation for One-Shot Dexterous Manipulation. arXiv 2023, arXiv:2310.16838. [Google Scholar]
- Shen, W.; Yang, G.; Yu, A.; Wong, J.; Kaelbling, L.P.; Isola, P. Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation. arXiv 2023, arXiv:2308.07931. [Google Scholar]
- Shorinwa, O.; Tucker, J.; Smith, A.; Swann, A.; Chen, T.; Firoozi, R.; Kennedy, M.D.; Schwager, M. Splat-Mover: Multi-Stage, Open-Vocabulary Robotic Manipulation Via Editable Gaussian Splatting. In Proceedings of the 8th Annual Conference on Robot Learning, Munich, Germany, 6–9 November 2024. [Google Scholar]
- Rashid, A.; Sharma, S.; Kim, C.M.; Kerr, J.; Chen, L.Y.; Kanazawa, A.; Goldberg, K. Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping. In Proceedings of the 7th Annual Conference on Robot Learning, London, UK, 5–8 November 2023. [Google Scholar]
- Li, Y.; Pathak, D. Object-Aware Gaussian Splatting for Robotic Manipulation. In Proceedings of the ICRA 2024 Workshop on 3D Visual Representations for Robot Manipulation, Yokohama, Japan, 17 May 2024. [Google Scholar]
- Zheng, Y.; Chen, X.; Zheng, Y.; Gu, S.; Yang, R.; Jin, B.; Li, P.; Zhong, C.; Wang, Z.; Liu, L. Gaussiangrasper: 3d Language Gaussian Splatting for Open-Vocabulary Robotic Grasping. arXiv 2024, arXiv:2403.09637. [Google Scholar] [CrossRef]
- Ze, Y.; Yan, G.; Wu, Y.-H.; Macaluso, A.; Ge, Y.; Ye, J.; Hansen, N.; Li, L.E.; Wang, X. Gnfactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Lu, G.; Zhang, S.; Wang, Z.; Liu, C.; Lu, J.; Tang, Y. Manigaussian: Dynamic Gaussian Splatting for Multi-Task Robotic Manipulation. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025. [Google Scholar]
- Zhang, T.; McCarthy, Z.; Jow, O.; Lee, D.; Chen, X.; Goldberg, K.; Abbeel, P. Deep Imitation Learning for Complex Manipulation Tasks from Virtual Reality Teleoperation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018. [Google Scholar]
- Zhu, X.; Wang, D.; Su, G.; Biza, O.; Walters, R.; Platt, R. On Robot Grasp Learning Using Equivariant Models. Auton. Robot. 2023, 47, 1175–1193. [Google Scholar] [CrossRef]
- Torabi, F.; Warnell, G.; Stone, P. Behavioral Cloning from Observation. arXiv 2018, arXiv:1805.01954. [Google Scholar]
- Fang, H.; Fang, H.-S.; Wang, Y.; Ren, J.; Chen, J.; Zhang, R.; Wang, W.; Lu, C. Airexo: Low-Cost Exoskeletons for Learning Whole-Arm Manipulation in the Wild. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Wen, C.; Lin, X.; So, J.; Chen, K.; Dou, Q.; Gao, Y.; Abbeel, P. Any-Point Trajectory Modeling for Policy Learning. arXiv 2023, arXiv:2401.00025. [Google Scholar]
- Chi, C.; Xu, Z.; Feng, S.; Cousineau, E.; Du, Y.; Burchfiel, B.; Tedrake, R.; Song, S. Diffusion Policy: Visuomotor Policy Learning Via Action Diffusion. Int. J. Robot. Res. 2023. [Google Scholar] [CrossRef]
- Pearce, T.; Rashid, T.; Kanervisto, A.; Bignell, D.; Sun, M.; Georgescu, R.; Macua, S.V.; Tan, S.Z.; Momennejad, I.; Hofmann, K. Imitating Human Behaviour with Diffusion Models. arXiv 2023, arXiv:2301.10677. [Google Scholar]
- Dass, S.; Ai, W.; Jiang, Y.; Singh, S.; Hu, J.; Zhang, R.; Stone, P.; Abbatematteo, B.; Martin-Martin, R. Telemoma: A Modular and Versatile Teleoperation System for Mobile Manipulation. arXiv 2024, arXiv:2403.07869. [Google Scholar]
- Mandlekar, A.; Nasiriany, S.; Wen, B.; Akinola, I.; Narang, Y.; Fan, L.; Zhu, Y.; Fox, D. Mimicgen: A Data Generation System for Scalable Robot Learning Using Human Demonstrations. arXiv 2023, arXiv:2310.17596. [Google Scholar]
- Teoh, E.; Patidar, S.; Ma, X.; James, S. Green Screen Augmentation Enables Scene Generalisation in Robotic Manipulation. arXiv 2024, arXiv:2407.07868. [Google Scholar]
- Chen, Z.; Kiami, S.; Gupta, A.; Kumar, V. Genaug: Retargeting Behaviors to Unseen Situations Via Generative Augmentation. arXiv 2023, arXiv:2302.06671. [Google Scholar]
- Liu, L.; Wang, W.; Han, Y.; Xie, Z.; Yi, P.; Li, J.; Qin, Y.; Lian, W. Foam: Foresight-Augmented Multi-Task Imitation Policy for Robotic Manipulation. arXiv 2024, arXiv:2409.19528. [Google Scholar]
- Niu, H.; Chen, Q.; Liu, T.; Li, J.; Zhou, G.; Zhang, Y.; Hu, J.; Zhan, X. Xted: Cross-Domain Policy Adaptation Via Diffusion-Based Trajectory Editing. arXiv 2024, arXiv:2409.08687. [Google Scholar]
- Ha, H.; Florence, P.; Song, S. Scaling up and Distilling Down: Language-Guided Robot Skill Acquisition. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Wang, L.; Ling, Y.; Yuan, Z.; Shridhar, M.; Bao, C.; Qin, Y.; Wang, B.; Xu, H.; Wang, X. Gensim: Generating Robotic Simulation Tasks Via Large Language Models. arXiv 2023, arXiv:2310.01361. [Google Scholar]
- Hua, P.; Liu, M.; Macaluso, A.; Lin, Y.; Zhang, W.; Xu, H.; Wang, L. Gensim2: Scaling Robot Data Generation with Multi-Modal and Reasoning Llms. arXiv 2024, arXiv:2410.03645. [Google Scholar]
- Lynch, C.; Sermanet, P. Language Conditioned Imitation Learning over Unstructured Data. arXiv 2020, arXiv:2005.07648. [Google Scholar]
- Mees, O.; Hermann, L.; Burgard, W. What Matters in Language Conditioned Robotic Imitation Learning over Unstructured Data. IEEE Robot. Autom. Lett. 2022, 7, 11205–11212. [Google Scholar] [CrossRef]
- Li, J.; Gao, Q.; Johnston, M.; Gao, X.; He, X.; Shakiah, S.; Shi, H.; Ghanadan, R.; Wang, W.Y. Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-Task Fine-Tuning. arXiv 2023, arXiv:2310.09676. [Google Scholar]
- Bousmalis, K.; Vezzani, G.; Rao, D.; Devin, C.; Lee, A.X.; Bauza, M.; Davchev, T.; Zhou, Y.; Gupta, A.; Raju, A. Robocat: A Self-Improving Foundation Agent for Robotic Manipulation. arXiv 2023, arXiv:2306.11706. [Google Scholar]
- Bharadhwaj, H.; Vakil, J.; Sharma, M.; Gupta, A.; Tulsiani, S.; Kumar, V. Roboagent: Generalization and Efficiency in Robot Manipulation Via Semantic Augmentations and Action Chunking. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Khazatsky, A.; Pertsch, K.; Nair, S.; Balakrishna, A.; Dasari, S.; Karamcheti, S.; Nasiriany, S.; Srirama, M.K.; Chen, L.Y.; Ellis, K. Droid: A Large-Scale in-the-Wild Robot Manipulation Dataset. arXiv 2024, arXiv:2403.12945. [Google Scholar]
- Khandelwal, A.; Weihs, L.; Mottaghi, R.; Kembhavi, A. Simple but Effective: Clip Embeddings for Embodied Ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Lin, F.; Hu, Y.; Sheng, P.; Wen, C.; You, J.; Gao, Y. Data Scaling Laws in Imitation Learning for Robotic Manipulation. arXiv 2024, arXiv:2410.18647. [Google Scholar]
- Yenamandra, S.; Ramachandran, A.; Yadav, K.; Wang, A.; Khanna, M.; Gervet, T.; Yang, T.-Y.; Jain, V.; Clegg, A.W.; Turner, J. Homerobot: Open-Vocabulary Mobile Manipulation. arXiv 2023, arXiv:2306.11565. [Google Scholar]
- Jain, V.; Attarian, M.; Joshi, N.J.; Wahid, A.; Driess, D.; Vuong, Q.; Sanketi, P.R.; Sermanet, P.; Welker, S.; Chan, C. Vid2robot: End-to-End Video-Conditioned Policy Learning with Cross-Attention Transformers. arXiv 2024, arXiv:2403.12943. [Google Scholar]
- Shridhar, M.; Manuelli, L.; Fox, D. Cliport: What and Where Pathways for Robotic Manipulation. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022. [Google Scholar]
- Jiang, Y.; Gupta, A.; Zhang, Z.; Wang, G.; Dou, Y.; Chen, Y.; Fei-Fei, L.; Anandkumar, A.; Zhu, Y.; Fan, L. Vima: General Robot Manipulation with Multimodal Prompts. arXiv 2022, arXiv:2210.03094. [Google Scholar]
- Ehsani, K.; Gupta, T.; Hendrix, R.; Salvador, J.; Weihs, L.; Zeng, K.-H.; Singh, K.P.; Kim, Y.; Han, W.; Herrasti, A. Spoc: Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024. [Google Scholar]
- Zeng, J.; Bu, Q.; Wang, B.; Xia, W.; Chen, L.; Dong, H.; Song, H.; Wang, D.; Hu, D.; Luo, P. Learning Manipulation by Predicting Interaction. arXiv 2024, arXiv:2406.00439. [Google Scholar]
- Gupta, G.; Yadav, K.; Gal, Y.; Batra, D.; Kira, Z.; Lu, C.; Rudner, T.G. Pre-Trained Text-to-Image Diffusion Models Are Versatile Representation Learners for Control. arXiv 2024, arXiv:2405.05852. [Google Scholar]
- Liu, S.; Wu, L.; Li, B.; Tan, H.; Chen, H.; Wang, Z.; Xu, K.; Su, H.; Zhu, J. Rdt-1b: A Diffusion Foundation Model for Bimanual Manipulation. arXiv 2024, arXiv:2410.07864. [Google Scholar]
- Zakka, K.; Wu, P.; Smith, L.; Gileadi, N.; Howell, T.; Peng, X.B.; Singh, S.; Tassa, Y.; Florence, P.; Zeng, A. Robopianist: Dexterous Piano Playing with Deep Reinforcement Learning. arXiv 2023, arXiv:2304.04150. [Google Scholar]
- Lillicrap, T. Continuous Control with Deep Reinforcement Learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Mnih, V. Asynchronous Methods for Deep Reinforcement Learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Han, M.; Zhang, L.; Wang, J.; Pan, W. Actor-Critic Reinforcement Learning for Control with Stability Guarantee. IEEE Robot. Autom. Lett. 2020, 5, 6217–6224. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.P.; Levine, S. Deep Reinforcement Learning for Robotic Manipulation. arXiv 2016, arXiv:1610.00633. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Yuan, H.; Zhou, B.; Fu, Y.; Lu, Z. Cross-Embodiment Dexterous Grasping with Reinforcement Learning. arXiv 2024, arXiv:2410.02479. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P. Soft Actor-Critic Algorithms and Applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Zeng, A.; Song, S.; Welker, S.; Lee, J.; Rodriguez, A.; Funkhouser, T. Learning Synergies between Pushing and Grasping with Self-Supervised Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Berscheid, L.; Meißner, P.; Kröger, T. Robot Learning of Shifting Objects for Grasping in Cluttered Environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, SAR, China, 3–8 November 2019. [Google Scholar]
- Zuo, Y.; Qiu, W.; Xie, L.; Zhong, F.; Wang, Y.; Yuille, A.L. Craves: Controlling Robotic Arm with a Vision-Based Economic System. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bıyık, E.; Losey, D.P.; Palan, M.; Landolfi, N.C.; Shevchuk, G.; Sadigh, D. Learning Reward Functions from Diverse Sources of Human Feedback: Optimally Integrating Demonstrations and Preferences. Int. J. Robot. Res. 2022, 41, 45–67. [Google Scholar] [CrossRef]
- Cabi, S.; Colmenarejo, S.G.; Novikov, A.; Konyushkova, K.; Reed, S.; Jeong, R.; Zolna, K.; Aytar, Y.; Budden, D.; Vecerik, M. A Framework for Data-Driven Robotics. arXiv 2019, arXiv:1909.12200. [Google Scholar]
- Ibarz, B.; Leike, J.; Pohlen, T.; Irving, G.; Legg, S.; Amodei, D. Reward Learning from Human Preferences and Demonstrations in Atari. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/8cbe9ce23f42628c98f80fa0fac8b19a-Paper.pdf (accessed on 30 October 2024).
- Xie, T.; Zhao, S.; Wu, C.H.; Liu, Y.; Luo, Q.; Zhong, V.; Yang, Y.; Yu, T. Text2reward: Reward Shaping with Language Models for Reinforcement Learning. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Ma, Y.J.; Liang, W.; Wang, G.; Huang, D.-A.; Bastani, O.; Jayaraman, D.; Zhu, Y.; Fan, L.; Anandkumar, A. Eureka: Human-Level Reward Design Via Coding Large Language Models. arXiv 2023, arXiv:2310.12931. [Google Scholar]
- Zhao, X.; Weber, C.; Wermter, S. Agentic Skill Discovery. arXiv 2024, arXiv:2405.15019. [Google Scholar]
- Xiong, H.; Mendonca, R.; Shaw, K.; Pathak, D. Adaptive Mobile Manipulation for Articulated Objects in the Open World. arXiv 2024, arXiv:2401.14403. [Google Scholar]
- Zhang, Z.; Li, Y.; Bastani, O.; Gupta, A.; Jayaraman, D.; Ma, Y.J.; Weihs, L. Universal Visual Decomposer: Long-Horizon Manipulation Made Easy. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Yang, J.; Mark, M.S.; Vu, B.; Sharma, A.; Bohg, J.; Finn, C. Robot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Liu, F.; Fang, K.; Abbeel, P.; Levine, S. Moka: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting. arXiv 2024, arXiv:2403.03174. [Google Scholar]
- Ye, W.; Zhang, Y.; Weng, H.; Gu, X.; Wang, S.; Zhang, T.; Wang, M.; Abbeel, P.; Gao, Y. Reinforcement Learning with Foundation Priors: Let Embodied Agent Efficiently Learn on Its Own. In Proceedings of the 8th Annual Conference on Robot Learning, Munich, Germany, 6–9 November 2024. [Google Scholar]
- Seo, Y.; Hafner, D.; Liu, H.; Liu, F.; James, S.; Lee, K.; Abbeel, P. Masked World Models for Visual Control. In Proceedings of the Conference on Robot Learning, Atlanta, GA, USA, 6–9 November 2023. [Google Scholar]
- Huang, W.; Wang, C.; Zhang, R.; Li, Y.; Wu, J.; Fei-Fei, L. Voxposer: Composable 3d Value Maps for Robotic Manipulation with Language Models. arXiv 2023, arXiv:2307.05973. [Google Scholar]
- Ma, Y.J.; Kumar, V.; Zhang, A.; Bastani, O.; Jayaraman, D. Liv: Language-Image Representations and Rewards for Robotic Control. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Wang, Y.; Sun, Z.; Zhang, J.; Xian, Z.; Biyik, E.; Held, D.; Erickson, Z. Rl-Vlm-F: Reinforcement Learning from Vision Language Foundation Model Feedback. arXiv 2024, arXiv:2402.03681. [Google Scholar]
- Yu, W.; Gileadi, N.; Fu, C.; Kirmani, S.; Lee, K.-H.; Arenas, M.G.; Chiang, H.-T.L.; Erez, T.; Hasenclever, L.; Humplik, J. Language to Rewards for Robotic Skill Synthesis. arXiv 2023, arXiv:2306.08647. [Google Scholar]
- Adeniji, A.; Xie, A.; Sferrazza, C.; Seo, Y.; James, S.; Abbeel, P. Language Reward Modulation for Pretraining Reinforcement Learning. arXiv 2023, arXiv:2308.12270. [Google Scholar]
- Zeng, Y.; Mu, Y.; Shao, L. Learning Reward for Robot Skills Using Large Language Models Via Self-Alignment. arXiv 2024, arXiv:2405.07162. [Google Scholar]
- Fu, Y.; Zhang, H.; Wu, D.; Xu, W.; Boulet, B. Furl: Visual-Language Models as Fuzzy Rewards for Reinforcement Learning. arXiv 2024, arXiv:2406.00645. [Google Scholar]
- Escontrela, A.; Adeniji, A.; Yan, W.; Jain, A.; Peng, X.B.; Goldberg, K.; Lee, Y.; Hafner, D.; Abbeel, P. Video Prediction Models as Rewards for Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/d9042abf40782fbce28901c1c9c0e8d8-Paper-Conference.pdf (accessed on 30 October 2024).
- Huang, T.; Jiang, G.; Ze, Y.; Xu, H. Diffusion Reward: Learning Rewards Via Conditional Video Diffusion. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Ding, Y.; Zhang, X.; Paxton, C.; Zhang, S. Task and Motion Planning with Large Language Models for Object Rearrangement. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, Michigan, USA, 1–5 October 2023. [Google Scholar]
- Ajay, A.; Han, S.; Du, Y.; Li, S.; Gupta, A.; Jaakkola, T.; Tenenbaum, J.; Kaelbling, L.; Srivastava, A.; Agrawal, P. Compositional Foundation Models for Hierarchical Planning. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/46a126492ea6fb87410e55a58df2e189-Paper-Conference.pdf (accessed on 30 October 2024).
- Bu, Q.; Zeng, J.; Chen, L.; Yang, Y.; Zhou, G.; Yan, J.; Luo, P.; Cui, H.; Ma, Y.; Li, H. Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation. arXiv 2024, arXiv:2409.09016. [Google Scholar]
- Liang, J.; Xia, F.; Yu, W.; Zeng, A.; Arenas, M.G.; Attarian, M.; Bauza, M.; Bennice, M.; Bewley, A.; Dostmohamed, A. Learning to Learn Faster from Human Feedback with Language Model Predictive Control. arXiv 2024, arXiv:2402.11450. [Google Scholar]
- Liu, P.; Orru, Y.; Paxton, C.; Shafiullah, N.M.M.; Pinto, L. Ok-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics. arXiv 2024, arXiv:2401.12202. [Google Scholar]
- Wang, Z.; Cai, S.; Chen, G.; Liu, A.; Ma, X.; Liang, Y. Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents. arXiv 2023, arXiv:2302.01560. [Google Scholar]
- Dalal, M.; Chiruvolu, T.; Chaplot, D.; Salakhutdinov, R. Plan-Seq-Learn: Language Model Guided Rl for Solving Long Horizon Robotics Tasks. arXiv 2024, arXiv:2405.01534. [Google Scholar]
- Mu, Y.; Zhang, Q.; Hu, M.; Wang, W.; Ding, M.; Jin, J.; Wang, B.; Dai, J.; Qiao, Y.; Luo, P. Embodiedgpt: Vision-Language Pre-Training Via Embodied Chain of Thought. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/4ec43957eda1126ad4887995d05fae3b-Paper-Conference.pdf (accessed on 30 October 2024).
- Myers, V.; Zheng, B.C.; Mees, O.; Levine, S.; Fang, K. Policy Adaptation Via Language Optimization: Decomposing Tasks for Few-Shot Imitation. arXiv 2024, arXiv:2408.16228. [Google Scholar]
- Shi, L.X.; Hu, Z.; Zhao, T.Z.; Sharma, A.; Pertsch, K.; Luo, J.; Levine, S.; Finn, C. Yell at Your Robot: Improving on-the-Fly from Language Corrections. arXiv 2024, arXiv:2403.12910. [Google Scholar]
- Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Fu, C.; Gopalakrishnan, K.; Hausman, K. Do as I Can, Not as I Say: Grounding Language in Robotic Affordances. arXiv 2022, arXiv:2204.01691. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Tompson, J.; Vuong, Q.; Yu, T. Palm-E: An Embodied Multimodal Language Model. arXiv 2023, arXiv:2303.03378. [Google Scholar]
- Padmanabha, A.; Yuan, J.; Gupta, J.; Karachiwalla, Z.; Majidi, C.; Admoni, H.; Erickson, Z. Voicepilot: Harnessing Llms as Speech Interfaces for Physically Assistive Robots. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, Pittsburgh, PA, USA, 13–16 October 2024. [Google Scholar]
- Vemprala, S.H.; Bonatti, R.; Bucker, A.; Kapoor, A. Chatgpt for Robotics: Design Principles and Model Abilities. IEEE Access 2024, 12, 55682–55696. [Google Scholar] [CrossRef]
- Jin, Y.; Li, D.; Yong, A.; Shi, J.; Hao, P.; Sun, F.; Zhang, J.; Fang, B. Robotgpt: Robot Manipulation Learning from Chatgpt. IEEE Robot. Autom. Lett. 2024, 9, 2543–2550. [Google Scholar] [CrossRef]
- Wake, N.; Kanehira, A.; Sasabuchi, K.; Takamatsu, J.; Ikeuchi, K. Gpt-4v (Ision) for Robotics: Multimodal Task Planning from Human Demonstration. IEEE Robot. Autom. Lett. 2024, 9, 10567–10574. [Google Scholar] [CrossRef]
- Zhi, P.; Zhang, Z.; Han, M.; Zhang, Z.; Li, Z.; Jiao, Z.; Jia, B.; Huang, S. Closed-Loop Open-Vocabulary Mobile Manipulation with Gpt-4v. arXiv 2024, arXiv:2404.10220. [Google Scholar]
- Chu, K.; Zhao, X.; Weber, C.; Li, M.; Lu, W.; Wermter, S. Large Language Models for Orchestrating Bimanual Robots. arXiv 2024, arXiv:2404.02018. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Dabis, J.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Hsu, J. Rt-1: Robotics Transformer for Real-World Control at Scale. arXiv 2022, arXiv:2212.06817. [Google Scholar]
- Huang, J.; Yong, S.; Ma, X.; Linghu, X.; Li, P.; Wang, Y.; Li, Q.; Zhu, S.-C.; Jia, B.; Huang, S. An Embodied Generalist Agent in 3d World. arXiv 2023, arXiv:2311.12871. [Google Scholar]
- Brohan, A.; Brown, N.; Carbajal, J.; Chebotar, Y.; Chen, X.; Choromanski, K.; Ding, T.; Driess, D.; Dubey, A.; Finn, C. Rt-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv 2023, arXiv:2307.15818. [Google Scholar]
- Szot, A.; Schwarzer, M.; Agrawal, H.; Mazoure, B.; Metcalf, R.; Talbott, W.; Mackraz, N.; Hjelm, R.D.; Toshev, A.T. Large Language Models as Generalizable Policies for Embodied Tasks. In Proceedings of the Twelfth International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Kim, M.J.; Pertsch, K.; Karamcheti, S.; Xiao, T.; Balakrishna, A.; Nair, S.; Rafailov, R.; Foster, E.; Lam, G.; Sanketi, P. Openvla: An Open-Source Vision-Language-Action Model. arXiv 2024, arXiv:2406.09246. [Google Scholar]
- Li, X.; Mata, C.; Park, J.; Kahatapitiya, K.; Jang, Y.S.; Shang, J.; Ranasinghe, K.; Burgert, R.; Cai, M.; Lee, Y.J. Llara: Supercharging Robot Learning Data for Vision-Language Policy. arXiv 2024, arXiv:2406.20095. [Google Scholar]
- Parekh, A.; Vitsakis, N.; Suglia, A.; Konstas, I. Investigating the Role of Instruction Variety and Task Difficulty in Robotic Manipulation Tasks. arXiv 2024, arXiv:2407.03967. [Google Scholar]
- Yue, Y.; Wang, Y.; Kang, B.; Han, Y.; Wang, S.; Song, S.; Feng, J.; Huang, G. Deer-Vla: Dynamic Inference of Multimodal Large Language Models for Efficient Robot Execution. arXiv 2024, arXiv:2411.02359. [Google Scholar]
- Du, Y.; Yang, M.; Florence, P.; Xia, F.; Wahid, A.; Ichter, B.; Sermanet, P.; Yu, T.; Abbeel, P.; Tenenbaum, J.B. Video Language Planning. arXiv 2023, arXiv:2310.10625. [Google Scholar]
- Ko, P.-C.; Mao, J.; Du, Y.; Sun, S.-H.; Tenenbaum, J.B. Learning to Act from Actionless Videos through Dense Correspondences. arXiv 2023, arXiv:2310.08576. [Google Scholar]
- Liang, J.; Liu, R.; Ozguroglu, E.; Sudhakar, S.; Dave, A.; Tokmakov, P.; Song, S.; Vondrick, C. Dreamitate: Real-World Visuomotor Policy Learning Via Video Generation. arXiv 2024, arXiv:2406.16862. [Google Scholar]
- Du, Y.; Yang, S.; Dai, B.; Dai, H.; Nachum, O.; Tenenbaum, J.; Schuurmans, D.; Abbeel, P. Learning Universal Policies Via Text-Guided Video Generation. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/file/1d5b9233ad716a43be5c0d3023cb82d0-Paper-Conference.pdf (accessed on 30 October 2024).
- Li, P.; Wu, H.; Huang, Y.; Cheang, C.; Wang, L.; Kong, T. Gr-Mg: Leveraging Partially Annotated Data Via Multi-Modal Goal Conditioned Policy. arXiv 2024, arXiv:2408.14368. [Google Scholar] [CrossRef]
- Kwon, T.; Di Palo, N.; Johns, E. Language Models as Zero-Shot Trajectory Generators. IEEE Robot. Autom. Lett. 2024, 9, 6728–6735. [Google Scholar] [CrossRef]
- Xia, W.; Wang, D.; Pang, X.; Wang, Z.; Zhao, B.; Hu, D.; Li, X. Kinematic-Aware Prompting for Generalizable Articulated Object Manipulation with Llms. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Chen, H.; Yao, Y.; Liu, R.; Liu, C.; Ichnowski, J. Automating Robot Failure Recovery Using Vision-Language Models with Optimized Prompts. arXiv 2024, arXiv:2409.03966. [Google Scholar]
- Di Palo, N.; Johns, E. Keypoint Action Tokens Enable in-Context Imitation Learning in Robotics. arXiv 2024, arXiv:2403.19578. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Embodied robots | Robotic arms | Franka [24] xArm series [25] UR series [26] ViperX [27] |
| End Effectors | Robotiq 2F-85 [63] Franka Emika Gripper [64] Allegro [69] Shadow [70] Leap [71] | |
| Mobile composite robots | Fetch Robotics [81] Hello Robot Stretch [82] Spot Arm [83] B1 and Z1 [84] | |
| Humanoid robots | Optimus [94] Atlas [95] H1 [96] Walker series [97] Expedition series [98] | |
| Simulation platforms | Gazebo [28] PyBullet [29] SAPIEN [30] RoboSuite [31] ManiSkill series [32,33] RoboCasa [34] Isaac Sim [35] Isaac Gym [72] Mujoco [73] iGibson series [85,86] Habitat series [87,88] AI2-THOR [89] BiGym [99] | |
| Datasets | BridgeData V2 [37] RH20T [38] Open-X [39] RED [40] REGRAD [41] GraspNet-1Billion [42] Grasp-Anything [43] Transpose [44] PokeFlex [45] ClothesNet [46] SurgT [47] UniDexGrasp [76] Handversim [77] DAPG [78] AMASS [100] | |
| Data acquisition methods | Self-made Equipment [48,49,50,51,90] 3D SpaceMouse [52] RoboTurk [53] Data Gloves [74] Camera [75,103] Exoskeleton System [101] VR [102] | |
| Date | LLM | VFM | VLM | GLM | RDSM |
|---|---|---|---|---|---|
| 2018 | BERT [104] GPT [105] | ||||
| 2019 | T5 [106] | ||||
| 2020 | |||||
| 2021 | DINO [117] | CLIP [8] | DALL-E [139] GLIDE [141] | ||
| 2022 | PaLM [107] GPT-3.5 [108] | BLIP [126] Flamingo [127] GIT [128] | DALL-E 2 [140] Make-A-Scene [142] IMAGEN [143] Parti [144] | MVP [12] R3M [147] VIP [148] | |
| 2023 | GPT-4 [9] | DINOv2 [118] SAM [120] Am-radio [122] | BLIP-2 [10] PandaGPT [129] MiniGPT-4 [130] LLaVA [131] LLaVA2 [132] KOSMOS-2 [133] ConvLLaVA [134] | Video LaVIT [145] | VC-1 [149] Voltron [150] GR-1 [151] |
| 2024 | GPT-o1 [109] | SAM2 [121] Theia [123] | Sora [146] | GR-2 [152] SpawnNet [153] |
| 3D feature | Semantic and 3D feature fusion | Polarnet [175] Hiveformer [176] PERACT [177] GraspGPT [178] PhyGrasp [179] |
| Point cloud extraction | VL-Grasp [180] OVGNet [181] | |
| Affordance information | OpenAD [182] Robo-abc [183] Ram [184] | |
| 3D scene reconstruction | Based on traditional feature | SPARSEDFF [185] F3RM [186] Splat-MOVER [187] LERF-TOGO [188] |
| Based on instance segmentation | Object-Aware [189] GaussianGrasper [190] | |
| Based on diffusion model | GNFactor [191] ManiGaussian [192] |
| Imitation learning | Data augmentation | Direct generation | GreenAug [202] GenAug [203] FoAM [204] xTED [205] |
| Indirect generation | SUaDD [206] GenSim [207] GenSim2 [208] | ||
| Feature extractor | Text feature extractor | MCIL [209] HULC [210] MIDAS [211] RoboCat [212] RoboAgent [213] DROID [214] | |
| Visual feature extractor | EmbCLIP [215] UMI [48] DSL [216] HomeRobot [217] Vid2robot [218] | ||
| Text and visual feature extractor | CLIPORT [219] VIMA [220] Open-TeleVision [102] SPOC [221] MPI [222] SCR [223] RDT [224] | ||
| Reinforcement learning | Reward function calculation | Generate reward function code | Text2Reward [239] Eureka [240] ASD [241] |
| Provide reward signal | ALF [242] UVD [243] ROBOFUME [244] MOKA [245] RLFP [246] | ||
| Reward function estimation | Non-parametric estimation | MWM [247] VoxPoser [248] LIV [249] RL-VLM-F [250] | |
| Parametric estimation | CenterGrasp [251] LAMP [252] SARU [253] FuRL [254] VIPER [255] Diffusion Reward [256] |
| Hierarchical execution | Low-level control strategy | Traditional control | LLM-GROP [257] HIP [258] CLOVER [259] LMPC [260] OK-Robot [261] |
| Strategy learning | DEPS [262] PSL [263] EmbodiedGPT [264] PALO [265] YAY Robot [266] | ||
| Skills library | Dynamic invocation | SayCan [267] PaLM-E [268] | |
| Direct invocation | VoicePilot [269] ChatGPT for Robotics [270] RobotGPT [271] G4R [272] COME-robot [273] LABOR[274] | ||
| Holistic execution | Fine-tuning or training | RT-1 [275] LEO [276] RT-2 [277] LLaRP [278] OpenVLA [279] LLARA [280] CoGeLoT [281] DeeR-VLA [282] | |
| Video and image prediction | VLP [283] DrM [284] Dreamitate [285] UniPi [286] GR-MG [287] | ||
| Based on VLM | ZSTG [288] KaP [289] Chen et al. [290] KAT [291] | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Mao, P.; Kong, L.; Wang, J. A Review of Embodied Grasping. Sensors 2025, 25, 852. https://doi.org/10.3390/s25030852
Sun J, Mao P, Kong L, Wang J. A Review of Embodied Grasping. Sensors. 2025; 25(3):852. https://doi.org/10.3390/s25030852
Chicago/Turabian StyleSun, Jianghao, Pengjun Mao, Lingju Kong, and Jun Wang. 2025. "A Review of Embodied Grasping" Sensors 25, no. 3: 852. https://doi.org/10.3390/s25030852
APA StyleSun, J., Mao, P., Kong, L., & Wang, J. (2025). A Review of Embodied Grasping. Sensors, 25(3), 852. https://doi.org/10.3390/s25030852