
Cross-Domain Generalization for LiDAR-Based 3D Object Detection in Infrastructure and Vehicle Environments

 , ,
, ,  and
and 
Abstract
1. Introduction
- (1)
- A 3D object detection model designed explicitly for V2X perception using roadside LiDAR point clouds is introduced to effectively address performance disparities caused by point cloud heterogeneity at both data and feature levels.
- (2)
- A novel data-level downsampling and calibration module, named Voxel-Based Weighted Centroid Downsampling (VWCD), is designed to enable adaptive information fusion between heterogeneous agents.
- (3)
- A novel Cross-Perspective Feature Synergization Module (CPSyM) that leverages both range-view and bird’s-eye-view perspectives is proposed, using a Squeeze-and-Excitation (SE) attention mechanism and Atrous Spatial Pyramid Pooling (ASPP) to fuse multi-view features and enhance the performance of 3D object detectors.
2. Related Works
2.1. LiDAR-Based 3D Object Detection
2.2. V2X Perception and Roadside Perception
3. Problem Statement
- (1)
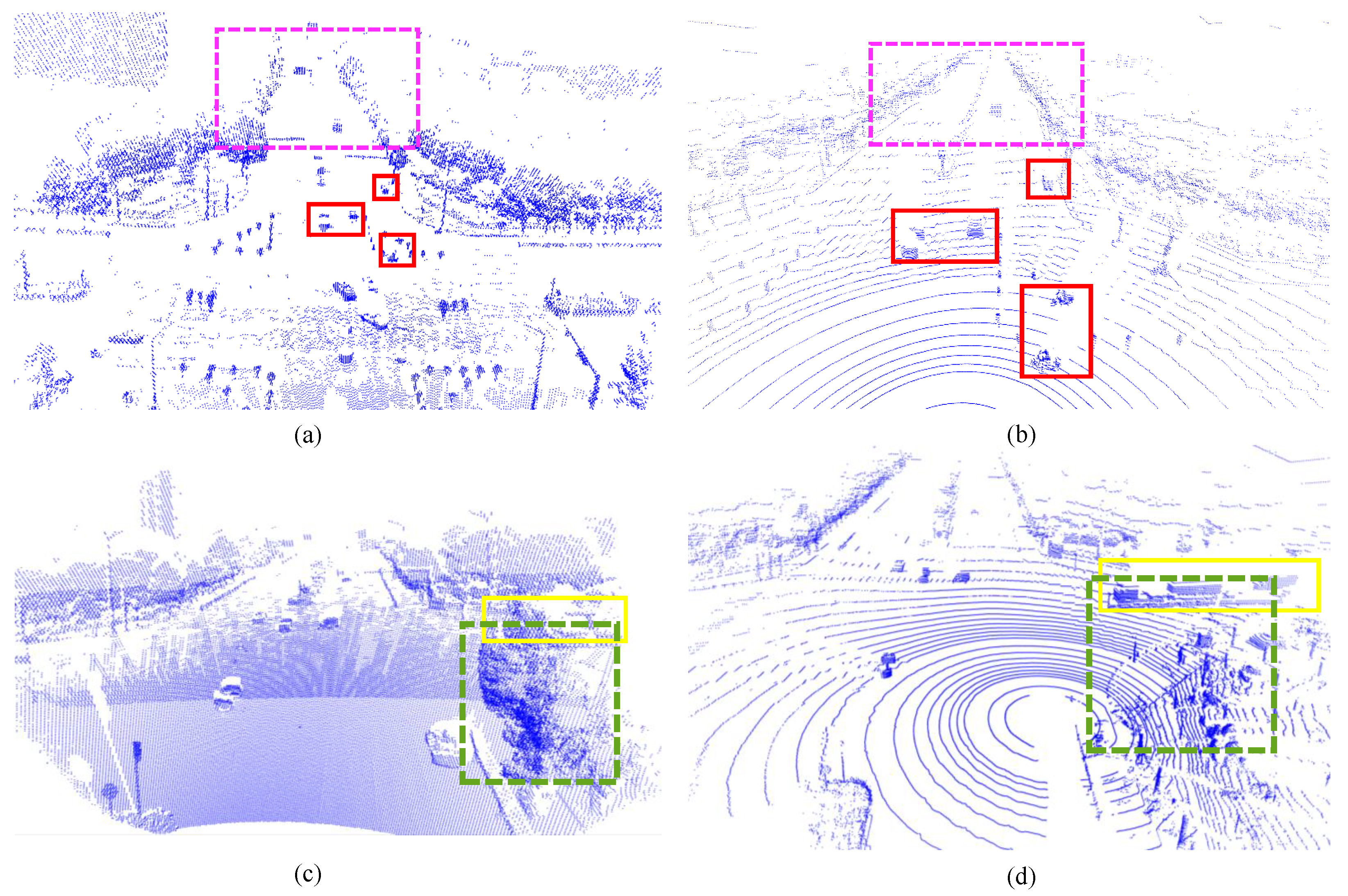
- Occlusions: Roadside LiDAR, positioned at a higher vantage point, is more prone to being obstructed by fixed objects such as buildings and trees. For instance, these structures may block roadside sensors at an intersection, limiting their ability to scan objects around corners and resulting in missing point cloud data in certain areas. As shown in Figure 1c,d, the green boxes in both the vehicle-side and roadside views illustrate that objects like trees do not obstruct the vehicle in the green box from the vehicle’s perspective, as they do in the roadside view. Consequently, the vehicle in the yellow box remains undetected due to occlusion by surrounding objects.
- (2)
- Viewpoint, Position, and Point Cloud Density: Vehicle-mounted LiDAR captures more detailed road-level information, as it is closer to the center of the road or driving path. In contrast, roadside LiDAR, positioned at a higher vantage point, provides a broader field of view, allowing it to capture more significant scenes. However, roadside LiDAR tends to produce sparser point clouds, especially at greater distances, where the density decreases even with additional laser beams. As a result, while roadside LiDAR offers a broader perspective, point cloud data are often less detailed and less dense than vehicle-mounted LiDAR, particularly in distant regions. As shown in Figure 1a,b, the target outlines captured by the roadside LiDAR are less distinct and can easily be confused with surrounding objects.
- (3)
- Environmental Conditions and Reflectivity: Roadside LiDAR, with its broader coverage, is more vulnerable to changes in ambient light, weather conditions, and the reflectivity of objects, as shown in the pink boxes in Figure 1a,b. These factors can adversely affect the quality of the point cloud data in specific regions.
4. Method
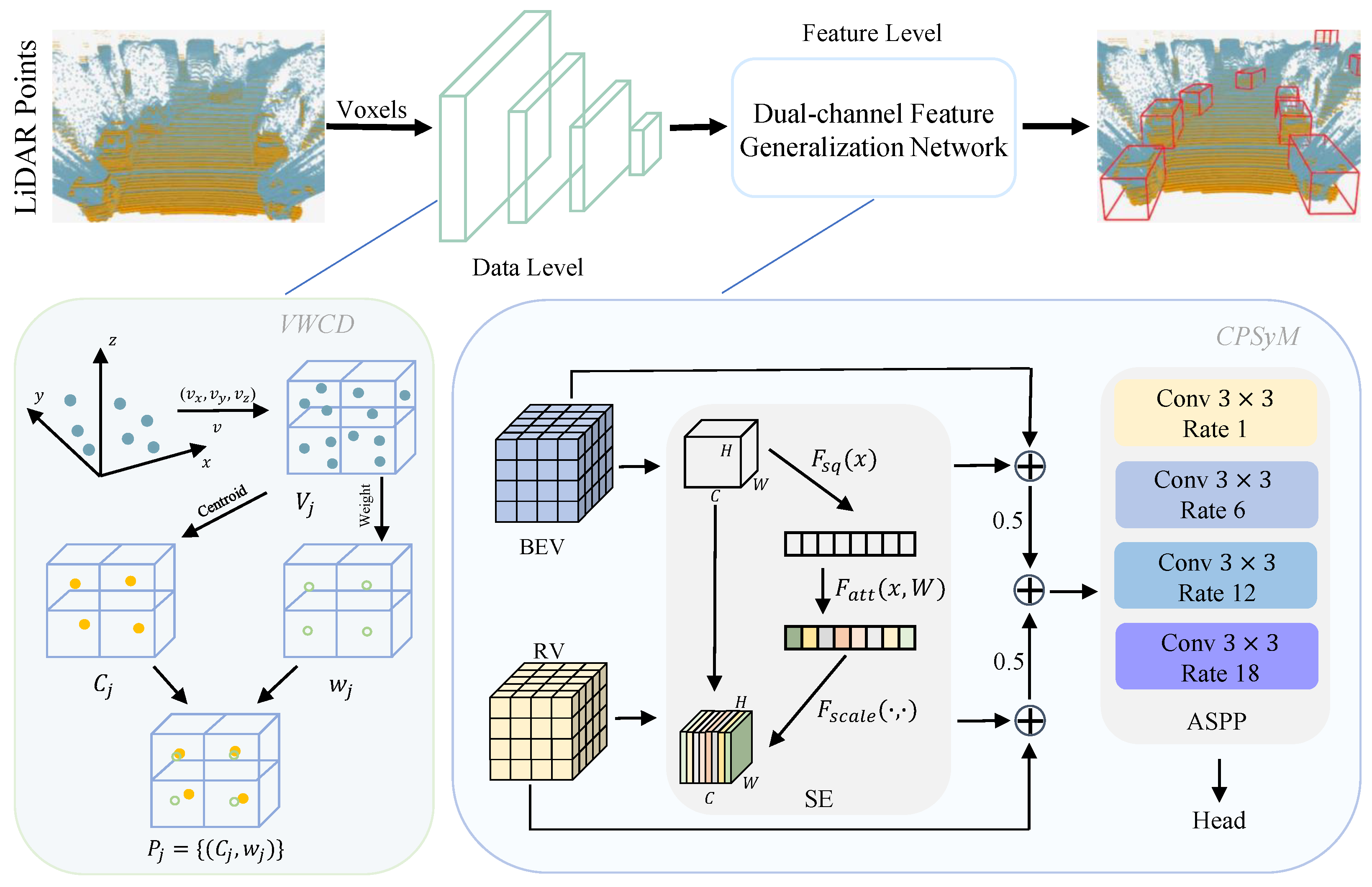
4.1. Overall Architecture
4.2. VWCD
| Algorithm 1 Voxel partitioning of a point cloud |
|
4.3. CPSyM
- A dilation rate of 1 yields standard convolution, focusing on local fine-grained details crucial for object recognition.
- A dilation rate of 6 extends the receptive field to capture mid-range contextual information.
- Higher dilation rates of 12 and 18 further broaden the receptive field, allowing the module to aggregate spatial information from a broader context and enabling a more comprehensive understanding of the scene.
5. Experimental Results
5.1. Dataset
5.2. Settings
5.3. Performance Evaluation and Comparison
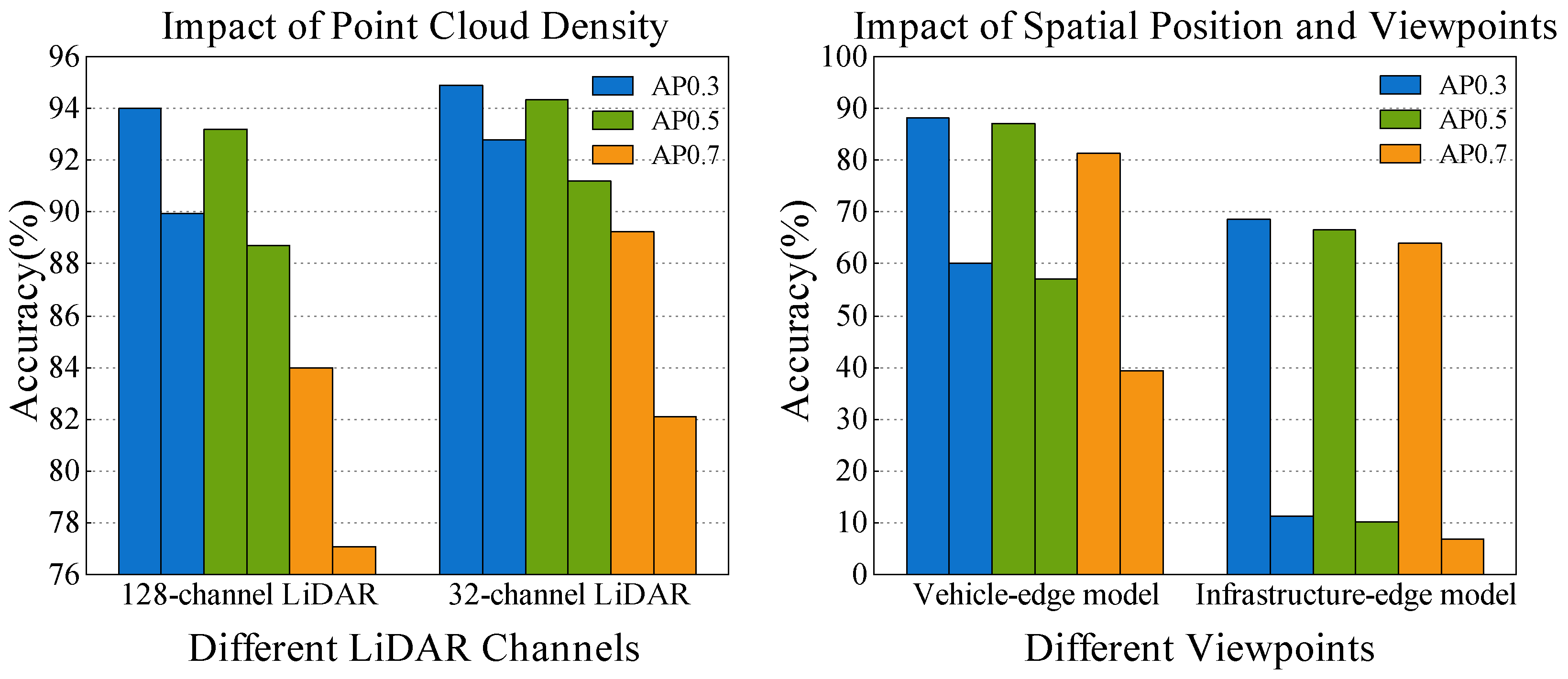
5.4. Ablation Experiments
6. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, X.; Li, H.; Xu, W.; Liu, Z.; Yao, L.; Dai, F. Artificial intelligence for edge service optimization in Internet of Vehicles: A survey. Tsinghua Sci. Technol. 2022, 27, 270–287. [Google Scholar] [CrossRef]
- Dong, J.; Wu, W.; Gao, Y.; Wang, X.; Si, P. Deep reinforcement learning based worker selection for distributed machine learning enhanced edge intelligence in internet of vehicles. Intell. Converg. Netw. 2020, 1, 234–242. [Google Scholar] [CrossRef]
- Cui, M.; Han, D.; Wang, J.; Li, K.C.; Chang, C.C. ARFV: An Efficient Shared Data Auditing Scheme Supporting Revocation for Fog-Assisted Vehicular Ad-Hoc Networks. IEEE Trans. Veh. Technol. 2020, 69, 15815–15827. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, R.; Liang, W.; Li, K.C.; Gu, K.; Li, X.; Huang, J. A Privacy-Preserving Data Aggregation Protocol for Internet of Vehicles with Federated Learning. IEEE Trans. Intell. Veh. 2024. [Google Scholar] [CrossRef]
- Xia, C.; Li, X.; Gao, X.; Ge, B.; Li, K.C.; Fang, X.; Zhang, Y.; Yang, K. PCDR-DFF: Multi-modal 3D object detection based on point cloud diversity representation and dual feature fusion. Neural Comput. Appl. 2024, 36, 9329–9346. [Google Scholar] [CrossRef]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision Transformer. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Lu, Y.; Hu, Y.; Zhong, Y.; Wang, D.; Wang, Y.; Chen, S. An Extensible Framework for Open Heterogeneous Collaborative Perception. In Proceedings of the ICLR, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 21–24 June 2022; pp. 21329–21338. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Charles, Q.R.; Li, Y.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11037–11045. [Google Scholar]
- Pan, X.; Xia, Z.; Song, S.; Li, L.E.; Huang, G. 3D Object Detection with Pointformer. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7459–7468. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12689–12697. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Luo, C.; Wang, X.; Zhao, Z.; Zheng, S. Voxel Transformer with Shifted Windows for 3D Object Detection. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17–19 November 2023; pp. 2717–2721. [Google Scholar]
- Liang, Z.; Zhang, M.; Zhang, Z.; Zhao, X.; Pu, S. RangeRCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representation. arXiv 2020, arXiv:2009.00206. [Google Scholar]
- Fan, L.; Xiong, X.; Wang, F.; Wang, N.; Zhang, Z. RangeDet: In Defense of Range View for LiDAR-based 3D Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2898–2907. [Google Scholar]
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; García, F.; De La Escalera, A. BirdNet: A 3D Object Detection Framework from LiDAR Information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar]
- Barrera, A.; Guindel, C.; Beltrán, J.; García, F. BirdNet+: End-to-End 3D Object Detection in LiDAR Bird’s Eye View. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H.M. Complex-YOLO: An Euler-Region-Proposal for Real-Time 3D Object Detection on Point Clouds. In Proceedings of the ECCV 2018 Workshops. ECCV 2018, Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2019; Volume 11129. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Zhou, H.; Wang, W.; Liu, G.; Zhou, Q. PointGAT: Graph attention networks for 3D object detection. Intell. Converg. Netw. 2022, 3, 204–216. [Google Scholar] [CrossRef]
- Zarzar, J.; Giancola, S.; Ghanem, B. PointRGCN: Graph Convolution Networks for 3D Vehicles Detection Refinement. arXiv 2019, arXiv:1911.12236. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1708–1716. [Google Scholar]
- Zhang, Y.; Huang, D.; Wang, Y. PC-RGNN: Point Cloud Completion and Graph Neural Network for 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Yang, H.; Liu, Z.; Wu, X.; Wang, W.; Qian, W.; He, X.; Cai, D. Graph R-CNN: Towards Accurate 3D Object Detection with Semantic-Decorated Local Graph. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 662–679. [Google Scholar]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar]
- Arnold, E.; Dianati, M.; de Temple, R.; Fallah, S. Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1852–1864. [Google Scholar] [CrossRef]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Hu, Y.; Fang, S.; Lei, Z.; Zhong, Y.; Chen, S. Where2comm: Communication-efficient collaborative perception via spatial confidence maps. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Liu, Y.-C.; Tian, J.; Glaser, N.; Kira, Z. When2com: Multi-Agent Perception via Communication Graph Grouping. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4105–4114. [Google Scholar]
- Lu, Y.; Li, Q.; Liu, B.; Dianati, M.; Feng, C.; Chen, S. Robust Collaborative 3D Object Detection in Presence of Pose Errors. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 4812–4818. [Google Scholar]
- Wang, T.-H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2VNet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 605–621. [Google Scholar]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Shi, S.; Cui, J.; Jiang, Z.; Yan, Z.; Xing, G.; Niu, J.; Ouyang, Z. VIPS: Real-time perception fusion for infrastructure-assisted autonomous driving. In Proceedings of the 28th Annual International Conference on Mobile Computing and Networking, Sydney, NSW, Australia, 17–21 October 2022. [Google Scholar]
- Fu, C.; Dong, C.; Mertz, C.; Dolan, J.M. Depth completion via inductive fusion of planar LIDAR and monocular camera. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar]
- Chen, D.; Krahenbuhl, P. Learning from all vehicles. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, L.; Yu, K.; Tang, T.; Li, J.; Yuan, K.; Wang, L.; Zhang, X.; Chen, P. BEVHeight: A Robust Framework for Vision-based Roadside 3D Object Detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 21611–21620. [Google Scholar]
- Deng, S.; Liang, Z.; Sun, L.; Jia, K. VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8448–8457. [Google Scholar]
- Zhou, Y.; Sun, P.; Zhang, Y.; Anguelov, D.; Gao, J.; Ouyang, T.; Guo, J.; Ngiam, J.; Vasudevan, V. End-to-end multi-view fusion for 3D object detection in lidar point clouds. In Proceedings of the Conference on Robot Learning, Virtual, 16–18 November 2020. [Google Scholar]
- Li, J.; Xu, R.; Liu, X.; Li, B.; Zou, Q.; Ma, J.; Yu, H. S2R-ViT for multi-agent cooperative perception: Bridging the gap from simulation to reality. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 16374–16380. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Model | mAP | ||
|---|---|---|---|---|
| AP30 | AP50 | AP70 | ||
| vehicle-side | PointPillars | 65.29 | 61.68 | 48.74 |
| DCGNN | 67.15 (↑ 1.86%) | 63.19 (↑ 1.51%) | 49.21 (↑ 0.47%) | |
| infrastructure-side | PointPillars | 15.59 | 14.85 | 11.31 |
| DCGNN | 21.16 (↑ 5.57%) | 19.72 (↑ 4.87%) | 13.85 (↑ 2.54%) | |
| Training Set | Testing Set | Model | mAP | ||
|---|---|---|---|---|---|
| AP30 | AP50 | AP70 | |||
| 128-channel LiDAR | 128-channel LiDAR | PointPillars | 93.71 | 92.62 | 84.53 |
| DCGNN | 95.04 | 93.35 | 86.45 | ||
| 32-channel LiDAR | PointPillars | 90.93 | 89.88 | 80.25 | |
| DCGNN | 91.82 | 91.10 | 84.13 | ||
| 32-channel LiDAR | 128-channel LiDAR | PointPillars | 90.92 | 90.47 | 83.44 |
| DCGNN | 90.93 | 91.10 | 84.13 | ||
| 32-channel LiDAR | PointPillars | 93.02 | 92.63 | 88.45 | |
| DCGNN | 95.52 | 94.60 | 87.30 | ||
| Infrastructure-Side | mAP | ||||
|---|---|---|---|---|---|
| VWCD | SE | ASPP | AP30 | AP50 | AP70 |
| 15.59 | 14.85 | 11.31 | |||
| ✓ | 17.78 | 16.68 | 12.14 | ||
| ✓ | 16.40 | 15.58 | 11.91 | ||
| ✓ | 19.49 | 18.46 | 13.09 | ||
| ✓ | ✓ | 17.39 | 16.52 | 12.44 | |
| ✓ | ✓ | 18.16 | 17.25 | 12.49 | |
| ✓ | ✓ | 18.04 | 17.30 | 12.80 | |
| ✓ | ✓ | ✓ | 21.16 | 19.72 | 13.85 |
| Vehicle-Side | mAP | ||||
|---|---|---|---|---|---|
| VWCD | SE | ASPP | AP30 | AP50 | AP70 |
| 65.29 | 61.68 | 48.74 | |||
| ✓ | 65.91 | 62.27 | 48.62 | ||
| ✓ | 66.48 | 62.82 | 48.79 | ||
| ✓ | 65.81 | 62.30 | 48.44 | ||
| ✓ | ✓ | 65.81 | 62.30 | 50.20 | |
| ✓ | ✓ | 66.46 | 62.81 | 48.80 | |
| ✓ | ✓ | 67.14 | 63.17 | 49.17 | |
| ✓ | ✓ | ✓ | 67.15 | 63.19 | 49.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhi, P.; Jiang, L.; Yang, X.; Wang, X.; Li, H.-W.; Zhou, Q.; Li, K.-C.; Ivanović, M. Cross-Domain Generalization for LiDAR-Based 3D Object Detection in Infrastructure and Vehicle Environments. Sensors 2025, 25, 767. https://doi.org/10.3390/s25030767
Zhi P, Jiang L, Yang X, Wang X, Li H-W, Zhou Q, Li K-C, Ivanović M. Cross-Domain Generalization for LiDAR-Based 3D Object Detection in Infrastructure and Vehicle Environments. Sensors. 2025; 25(3):767. https://doi.org/10.3390/s25030767
Chicago/Turabian StyleZhi, Peng, Longhao Jiang, Xiao Yang, Xingzheng Wang, Hung-Wei Li, Qingguo Zhou, Kuan-Ching Li, and Mirjana Ivanović. 2025. "Cross-Domain Generalization for LiDAR-Based 3D Object Detection in Infrastructure and Vehicle Environments" Sensors 25, no. 3: 767. https://doi.org/10.3390/s25030767
APA StyleZhi, P., Jiang, L., Yang, X., Wang, X., Li, H.-W., Zhou, Q., Li, K.-C., & Ivanović, M. (2025). Cross-Domain Generalization for LiDAR-Based 3D Object Detection in Infrastructure and Vehicle Environments. Sensors, 25(3), 767. https://doi.org/10.3390/s25030767