1. Introduction
Wearable physiological measurement technology has advanced the field of affective computing by enabling natural and unobtrusive tracking of individuals’ affective states [
1]. These developments offer new opportunities for applications in human–computer interaction, personalized mental health treatment, and adaptive learning systems. However, detecting affective states in everyday contexts remains challenging, due to the dynamic and transient nature of emotions, as well as the noise and variability inherent in long-term physiological recordings from real-world environments.
One major challenge lies in managing the continuous and dynamic physiological data collected during daily activities [
2,
3]. Signals such as heart rate, skin conductance, and electroencephalogram (EEG) exhibit complicated temporal patterns and interdependencies that are difficult to predict in uncontrolled, real-world settings. Another challenge is handling the complexities of multi-modal signals, as each modality provides distinct yet complementary information about affective states. Traditional machine learning methods, such as support vector machines [
4] and random forests [
5], have been employed for affective state recognition. However, these approaches often fail to capture intricate temporal dynamics and cross-signal relationships [
6], primarily because they focus on features from independent signals, while neglecting their interdependencies. Advances in deep learning technology have partially addressed these limitations. Methods such as convolutional neural networks (CNN) and recurrent neural networks (RNN) have been developed to model sequential and spatial patterns in physiological data [
7,
8,
9,
10,
11] and have been made to integrate complementary signals, such as autonomic activity from skin conductance and cardiac patterns, for affective state recognition [
12,
13,
14]. Novel Transformer models [
15] have successfully addressed similar challenges, such as long-term dependencies and cross-modal interactions, in fields like natural language processing and computer vision, yet their potential for real-world affective state recognition remains unexplored.
This paper presents a Transformer-based algorithm designed to address the challenges of real-world affective state recognition. Transformer models demonstrate remarkable efficacy in capturing long-term dependencies and cross-modal interactions, making them highly suitable for analyzing multi-modal physiological data in everyday settings. Our proposed framework leverages self-attention mechanisms to focus on the relevant features of each physiological signal, while capturing their complex interrelationships over time.
Utilizing the Daily Ambulatory Psychological and Physiological recording for Emotion Research (DAPPER) dataset [
16], comprising five days of uninterrupted wrist-worn recordings of heart rate, skin conductance, and triaxial acceleration from 88 subjects, our Transformer-based methodology demonstrates the effectiveness of leveraging multi-modal wearable data for accurate affective state recognition in daily settings. The model’s performance in both binary and multi-class affective state classification highlights the potential of Transformer-based approaches as a promising tool for affective computing in real-world scenarios.
The primary contributions of this study are as follows:
Implementation of an Innovative Architecture for Affective State Recognition: We propose a Transformer-based model specifically designed for multi-modal, long-term physiological data and optimized for affective state recognition.
Evaluation Using Real-World Data: The proposed model underwent an extensive assessment utilizing the DAPPER dataset, which includes multi-day recordings of physiological signals from a varied cohort of subjects. The evaluation covered both binary and multi-class classification tasks for affective states, demonstrating the model’s robustness and adaptability.
Potential Applications: Our findings highlight the feasibility of implementing Transformer-based affective computing systems in real-world settings. This work emphasizes the potential of affective state recognition using wearable sensors, enabling practical applications in everyday life.
3. Materials and Methods
3.1. Dataset Description
We used the DAPPER dataset [
16], which recorded the daily dynamic psychological and physiological records of 88 subjects for five consecutive days.
We used experience sampling method (ESM) data for further experiments. Each ESM questionnaire consisted of 20 items, including basic information about daily events, a five-item TIPI-C inventory for self-assessment of personality state, followed by a ten-item positive and negative affect Schedule (PANAS) [
48], as well as affective valence and arousal ratings. The ten items selected were upset, hostile, alert, ashamed, inspired, nervous, determined, attentive, afraid, and active. Each item was associated with a 5-point scale.
We also used physiological recordings over five days for analysis, which included the following signals:
Photoplethysmography (PPG) data. The PPG technique employs green light at a wavelength of 532 nm, with the reflected light intensity measured at a sampling rate of 20 Hz.
Galvanic skin response (GSR) signals. GSR was measured at the wrist by surface electrodes with conductive gels at a sampling rate of 40 Hz and with a resolution of 0.01 S.
Three-axis acceleration data. Three-axis acceleration data were recorded at a sampling rate of 20 Hz.
Data Statistics
In the 5-class classification experiment, arousal and valence scores ranging from 1 to 5 corresponded to distinct categories. The distribution of valence and arousal categories is shown in
Table 1. We divided the dataset into five classes, ranging from Class 1 (ESM score = 1) to Class 5 (ESM score = 5). The “ESM_Valence” and “ESM_Arousal” rows show the number and proportion of ESM responses falling within each class.
In the binary classification task for the PANAS category, the scores of positive affective items (including inspired, active, determined, and attentive) were added as the total positive score, whereas the scores of negative affective items (including upset, hostile, alert, ashamed, nervous, and afraid) were summed as the total negative score [
48]. The category with the higher absolute value between the total positive score and the total negative score was the PANAS category of the instance.
Table 2 shows the distributions of the PANAS positive category (Class 1) and the negative (Class 0) category.
3.2. Data Preprocessing
We performed the following calculation and preprocessing operations on the multi-modal signals.
Figure 1 shows a flow chart of the raw signal and the preprocessed signal for the HR, GSR, and ACCEL signals.
The magnitude of acceleration (ACCEL) was calculated as the square root of the sum of squares of the acceleration in the three orthogonal directions, reflecting the overall motion intensity, with a precision of 1/2048 g (unit of gravity acceleration). The HR signal was derived from the PPG raw data using a joint sparse spectrum reconstruction algorithm [
49], implemented in the HuiXin software package (version 201708). The resulting HR data were organized at a 1 Hz sampling rate [
50,
51]. To ensure relative uniformity across the different signal modalities, the GSR and ACCEL signals were downsampled to match the 1 Hz sampling rate of the HR signal. Specifically, a simple downsampling method was applied, where every 40th sample (for GSR signals) and every 20th sample (for ACCEL signals) was retained from the original signals [
52].
For noise reduction, we implemented an adaptive noise cancellation method based on the least mean square algorithm, to handle residual noise that could have interfered with the affective state recognition [
53]. Specifically, the algorithm iteratively adjusted the filter coefficients to minimize the mean square error, dynamically reducing the noise in the input signal. The filtered signals were then smoothed using a moving median filter with a kernel size of 3 [
54]. The preprocessed signals showed a consistent pattern, as suggested by previous studies [
55]. As shown in
Figure 1, the signals demonstrated reduced abnormal activities for all signal modalities, as well as reduced high-frequency variations for HR and GSR.
The first 30 min of the physiological data prior to each ESM entry were extracted by matching the timestamps of the ESM with those from the physiological recordings. A total of 3789 segments were extracted, each with both five-class labels and binary labels, for arousal and valence.
3.3. Transformer-Based Framework for Multi-Modal Wearable Data
This section will introduce our main framework. Our model aims to effectively capture multi-modal physiological signals to accurately classify affective states. This architecture is based on the Transformer model. The following steps illustrate the construction of our model.
3.3.1. Feature Extraction and Embedding
For each physiological signal, we constructed a separate CNN-based feature extraction network. Presuming that the time series of the input HR signal, GSR signal, and ACCEL signal are , , and respectively. Among these, T represents the number of time steps; and , , and represent the feature dimensions of each data modality. The extracted features can be represented as , and , , and and represent the feature expressions of signals.
3.3.2. Multi-Modal Embedding and Concatenation
In multi-modal affective state recognition tasks, the fusion between different signals is important. We concatenated the embedded vectors of HR, GSR, and ACCEL data. These features were then input into the Transformer encoder for joint processing of multi-modal features. Firstly, concatenate
,
, and
along the feature dimension to obtain the fused multi-modal input representation:
Positional encoding
P is added to
to introduce temporal order to the embeddings:
where the positional encoding
P is defined as per the sinusoidal function introduced by Vaswani et al. [
15]:
where
i is the time step,
j is the embedding dimension, and
d is the dimensionality of the embeddings.
3.3.3. Transformer Encoder for Multi-Modal Fusion
The Transformer is a model architecture that exclusively utilizes an attention mechanism to establish the global interdependence between input and output. Like most sequence-to-sequence models, Transformer is also an encoder–decoder architecture. However, as physiological recording signals do not have a standard translation, we only use the encoder part.
Figure 2 shows the detailed technological process of our Transformer model. The fused input embeddings are passed through a series of Transformer encoder layers, where each layer includes multi-head self-attention and feed-forward layers. The purpose of this module is to learn complex temporal and cross-modal dependencies that contribute to affective state classification. The output from the multi-head attention module undergoes processing by a feed-forward network.
Among these,
represents the input of
l layer. Each attention head calculates attention scores to capture relevant temporal patterns within and across modalities. For each query
Q, key
K, and value
V, the attention mechanism is defined as
where
denotes the dimensionality of the keys. Multi-head attention allows the model to attend to different aspects of the signal simultaneously, enhancing the ability to capture diverse patterns. The output from each attention head is concatenated and passed through a linear transformation, represented as
where
is the weight matrix of the output projections.
3.3.4. Classification Layer
The encoded output from the final Transformer layer is input into a classification head, which associates the representations with the affective state labels. This procedure entails a linear layer succeeded by a softmax function to forecast class probabilities:
where
and
are the weights and bias of the output layer. The predicted label
is then compared to the true label
y using a categorical cross-entropy loss function:
where
C is the number of the affective state classes (binary or multi-class).
3.3.5. Evaluation Metrics
We used common classification metrics, including
Accuracy: The proportion of correct predictions across all classes.
Precision: The proportion of true positives among the samples predicted as positive.
Macro Averaged F1 Score: The harmonic mean of precision and recall, providing a balanced measure of accuracy and robustness.
3.4. Experiment Settings
We conducted all experiments on eight NVIDIA 1080 GPUs (NVIDIA, Santa Clara, CA, USA), which allowed us to process data efficiently and train the model within a reasonable timeframe. The model was optimized using the Adam optimizer with parameters , , and . This optimizer was chosen due to its adaptability in handling sparse gradients and its effectiveness in convergence. The learning rate was initialized at 1 and followed a linear decay schedule to ensure gradual and stable convergence as the training progressed. We set the batch size to 64, which balanced the computational efficiency and stability of the gradient estimates, making it suitable for our dataset. Our model was trained for a total of 100 epochs, with an early stopping criterion applied if the validation performance did not improve over 10 consecutive epochs. This approach mitigated overfitting. To further address overfitting, we applied a dropout rate of 0.2 in the network and introduced L2 regularization with a coefficient of 1 in the optimizer.
We employed a CNN for feature extraction, utilizing a hidden size of 128, generating a 512-dimensional feature vector as input for the Transformer model. In our experiments, we divided the entire dataset into training and testing sets, with an 8:2 ratio. To avoid possible cross-influence among the different time periods within the same subjects, all data in the training and testing sets were separated by subjects. Our study focused on two main tasks: binary classification based on PANAS scores, and five-class classification based on valence and arousal scores.
In addition, we choose random forest [
56], SVM [
57] (RBF as kernel function, C = 1.0, gamma = 0.1), AlexNet [
58] (5 Convolutional layers and ReLU function), ResNet34 [
59], and RNN [
60] (128 hidden units) as comparison models.
4. Results
The results presented in
Table 3 illustrate the binary classification performance based on PANAS score across the different data modalities: HR, GSR, ACCEL, and all three modalities. The accuracy, F1 score, and precision results indicate that the proposed model surpassed the other classifiers within each modality. Notably, the proposed model achieved the highest accuracy and F1 score, reaching an accuracy of 71.50% and an F1 score of 70.38% when using multi-modal data. When using a single data modality, the accuracy of the HR modality was better than the GSR and ACCEL modality data.
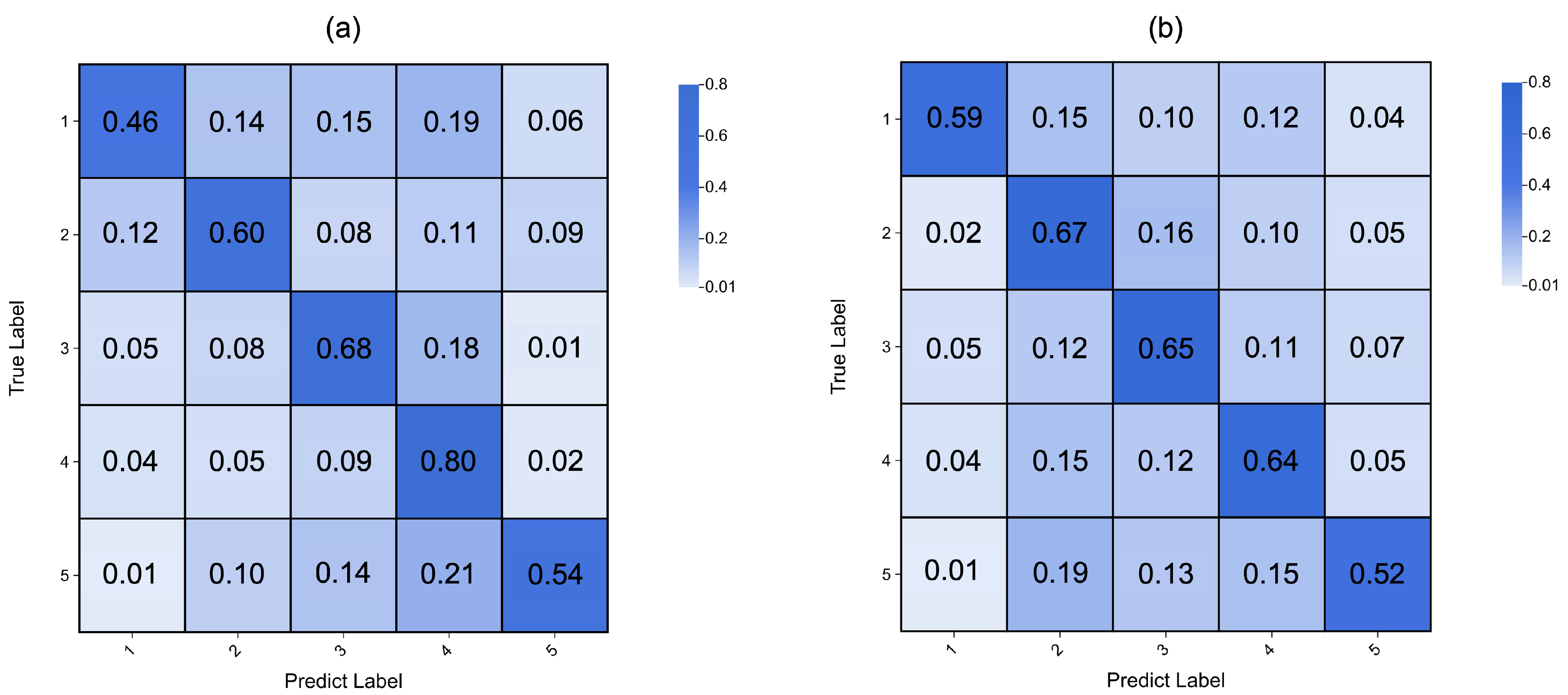
The confusion matrices presented in
Figure 3 illustrate the classification performance for valence and arousal across the five classes. The horizontal axis represents the predicted labels, the vertical axis represents the true labels, and the number in each cell represents the proportion of each true label being classified into the different categories. In both matrices, diagonal numbers indicate that the model accurately predicted the true label. For the valence classification, which is shown in
Figure 3a, and the arousal dimension, which is shown in
Figure 3b, a similar trend is observed, but there was still confusion between some adjacent categories. This suggests that the model could capture the general feature of affective states.
The performance results of the 5-class classification based on valence scores are shown in
Table 4. The proposed model with multi-modal data performed the best across all metrics, reaching an accuracy of 60.29% and F1 score of 59.24%, and demonstrating the potential of multi-modal signal fusion. Compared to single-modal data, the RF, SVM, AlexNet, ResNet, and RNN models all showed improvements using multi-modal data.
Table 5 presents the performance of the 5-class classification based on arousal scores. For HR data, our proposed model achieved an accuracy of 50.02%, with an F1 score of 49.31%. For GSR data, it reached an accuracy of 49.35%, with an F1 score of 48.42%. For ACCEL data, the accuracy was 43.52%, with an F1 score of 42.90%. In comparison, the best-performing traditional models, such as RNN, achieved accuracies between 41.18% and 46.78% using single-modal data. When utilizing multi-modal data, the proposed model achieved an accuracy of 61.55% and an F1 score of 60.89%. This highlights the potential of multi-modal data fusion in enhancing affective state recognition.
The results shown in
Table 6 display the model results across the various hyperparameter setups. As batch size and inner dimension increase, performance is often enhanced for both arousal and valence classification tasks. The optimal accuracy and F1 scores for valence classification were attained with a batch size of 32 and an inner dimension of 8. The PANAS classification task achieved the best performance when the batch size and inner dimension were equal to 16.
Table 7 compares the performance of the various modality combinations for the arousal, valence, and PANAS classification tasks. The findings illustrate the benefit of employing various modalities for the affective state recognition tasks and that the single modality exhibited a lower performance. Specifically, for the arousal and valence score classification task, the model achieved accuracies of 61.55% and 60.29% separately, which increased by 20.84% and 16.77% compared to using only the ACCEL modality. Pairwise combinations attained better performance, particularly the combination of HR and GSR, achieving an 56.64% accuracy for arousal and 58.93% accuracy for valence. All three tasks achieved the best results when using multi-modal data.
5. Discussion and Conclusions
This study shows the feasibility of applying Transformer-based models on multi-modal physiological data (DAPPER) for affective state recognition in everyday situations. The proposed model achieved a binary PANAS classification accuracy of 71.5% and five-class classification accuracies of 60.29% and 61.55% for valence and arousal scores, respectively. The experiments underscored the importance of hyperparameter optimization, including the batch size and inner dimensions. The choice of batch size and inner dimensions influences model training stability and performance. Larger batch sizes may facilitate smoother gradient updates, while the inner dimension settings directly impact the model’s capacity to learn cross-modal relationships. Furthermore, the incorporation of a multi-modal approach surpassed the single-modal performance. This work demonstrates the effectiveness of the Transformer model for practical affective state recognition tasks and highlights the advantages of multi-modal data fusion in improving the performance of wearable affective state recognition systems.
We obtained promising results in the PANAS score classification task. Our model achieved a 71.5% accuracy in binary PANAS categorization, confirming its ability to handle noisy, real-world inputs. Prior works have often been carried out under strictly controlled laboratory conditions. For instance, Nur et al. [
61] attained accuracies of 76.33% for differentiating happy, neutral, and sad using PANAS scores in a controlled experimental setting. Chen et al. [
62] reported binary classification accuracies varying from 30% to 87.36%, contingent upon the number of features (ranging from 1 to 39) collected during experiments. These works were performed in laboratory settings with minimal noise and multiple sensors, whereas DAPPER was continuously collected in real-world environments, providing a more authentic representation of daily affective states through three data modalities. Although the accuracy scores in our study may not have surpassed those from more controlled experiments, our research demonstrates the effectiveness of Transformer-based patterns in intricate real-world contexts.
The classification results for arousal and valence further demonstrate the potential for reliable affective state recognition in everyday contexts. To allow a more direct comparison with previous binary classification results, we further reorganized our results into a binary version by treating classes 1–3 as one category and 4–5 as the other category for both valence and arousal ratings. The re-organized results yielded an accuracy of 78.6% for valence and 75.85% for arousal, which was overall better and more balanced than the previous results (62.9% and 63.9% for valence and arousal in [
35] and 82.75% and 61.55% in [
36]). Notably, our five-class classification performance represents an advancement, as this task had not been previously explored with the same approach. Our five-class accuracy of 61.55% and 60.29% based on arousal and valence scored demonstrates a clear improvement, particularly in capturing fine-grained affective states, the strength of our Transformer-based method in handling temporal dependencies and cross-modal data interactions. This choice of five-class classification allowed for better differentiation of subjects’ affective states and represents an important step toward more precise affective state recognition, essential for real-world applications. The findings underscore the efficiency of Transformer-based models as a powerful and novel method for recognizing affective states in everyday situations, especially for managing intricate multi-class tasks that require nuanced affective differentiations.
The experiments with multi-modal data also showed that multi-modal signals, such as HR, GSR, and ACCEL data, made the model work much better than with a single-modal input. Previous studies have shown that single-modal methods do not always capture important affective cues. As an example, Mocanu et al. [
63] showed that the accuracy of identifying an affective state rose from 76.42% for a single modality to 87.85% for multi modalities. Although the tasks are different, using multi-modal data can improve classification performance. This is especially true in real life, where feelings are shown through a variety of physiological channels [
14]. Our proposed model effectively captures richer affective information by combining multi-modal data, demonstrating the reliability and utility of such an approach for a wide range of affective state recognition tasks.
Despite these promising results, the dataset size and model structure remain limiting factors for large Transformer models. Expanding sample sizes and subject diversity will be crucial for building more promising and generalizable models [
64]. The fusion strategy used in this study, based on concatenation, provides a promising baseline. However, more complex fusion strategies [
65], such as feature-level fusion or decision-level fusion, could be further explored. In addition, future work could explore more complex feature extraction methods and attention mechanisms, such as cross-attention [
66], enabling the model to dynamically prioritize the most relevant modalities and time frames, thereby enhancing its sensitivity to subtle differences between adjacent affective categories. Emerging techniques, such as time-series Transformers and graph convolutional networks [
67], could be explored to capture the complex interactions among multi-modal features. Additionally, refining Transformer architectures, particularly with large-scale pre-trained models optimized for multi-modal data [
68], could improve the granularity and accuracy of affective state recognition. Furthermore, the integration of emerging sensor technologies, such as wearable EEG or advanced skin sensors, could further expand the diversity of affective signal types.
This method holds great potential for future integration into mental health monitoring and the provision of personalized recommendations. The reliable recognition of affective states in everyday contexts, based on wearable measurements, enables convenient and continuous tracking of affective states in daily life. This approach provides richer and more nuanced individualized data for the clinical diagnosis of mental health issues such as depression and anxiety [
69,
70]. Wearable devices also facilitate the support of individuals in conducting affective regulation and other types of mental health intervention training in more accessible settings, such as at home [
71,
72]. Furthermore, the continuous affective recognition of individuals in specific scenarios, such as watching movies or visiting museums, could introduce a new paradigm for user experience evaluation and personalized recommendations [
73,
74]. By capturing the affective responses in these contexts, we could better understand user engagement and tailor experiences to meet individual needs, enhancing both quality of life and the effectiveness of mental health support.







{kind=link}
{kind=link}
{kind=link}