1. Introduction
Industrial automation thrives on precise and reliable measurements. Ultrasonic sensors have emerged as a cornerstone technology for diverse tasks, from meticulously gauging liquid levels in tanks to measuring material thickness and determining object proximity with high accuracy. Their operation revolves around emitting high-frequency sound waves and measuring the time it takes for echoes to return. This allows for precise distance calculations and characterization of material properties. Some notable achievements include the development of advanced ultrasonic imaging techniques and the integration of ultrasonic sensors with automated control systems to enhance process efficiency.
Beyond these sensor advancements, machine learning is playing a crucial role in enhancing the performance of industrial measurements using ultrasonic sensors. By analyzing the complex data generated by these sensors, machine learning can identify subtle patterns and trends that would be difficult to discern with traditional methods [
1]. Techniques such as neural networks, support vector machine (SVM), and decision trees have been employed to optimize measurement accuracy and detect anomalies. Furthermore, machine learning models can be trained to predict equipment wear and tear based on sensor data, allowing for scheduled maintenance and preventing unplanned downtime.
This research delves into the exciting realm of data-driven approaches, specifically by leveraging machine learning within a digital twin framework. Digital twins are virtual representations of physical assets and systems that integrate real-time data from sensors and other sources. Traditionally, these systems relied on physical-based models to describe the behaviors of sensors and actuators. These models rely on engineering principles and require significant upfront knowledge of the system dynamics. However, a recent shift is happening in the state-of-the-art of digital twins. There is growing interest in data-driven approaches that leverage real-world data to describe sensor and actuator behavior [
2]. This study proposes exploring data-driven approaches within a digital twin framework, aiming to investigate on improving the overall performance and reliability of digital twins across various industrial applications.
The digital twin was constructed within the TIA Portal (V17, Siemens AG) software [
3] using the Festo MPS PA Didactic System. TIA Portal’s WinCC Runtime Advanced serves as the development environment for the PLC program controlling the station, including DAQ from the dosing tank’s ultrasonic sensor. This research aims to develop an SVR model for predicting future liquid levels using this sensor data. Data will be collected through the TIA Portal and undergo pre-processing to ensure quality for model training. The SVR model will be trained and evaluated using metrics like Mean-squared error (MSE) and R-squared, with hyperparameter tuning employed to optimize prediction accuracy. Importantly, this research explores the potential for real-time control by integrating the trained SVR model within the digital twin. This could allow for using predicted water levels to adjust process parameters in real-time, such as regulating pump operation or valve positions, ultimately optimizing dosing tank liquid levels.
Previous research has explored the application of machine learning techniques in various industrial settings, including predictive maintenance, quality control, and process optimization. For example, developing digital twins to present the framework and workflow of the data-driven models for wind turbines [
4] and using digital twin technology for production optimization in the petrochemical industry [
5]. However, the integration of machine learning with digital twins to enhance sensor-based predictions and process control within industrial automation training systems remains a relatively unexplored area. This study aims to contribute to this emerging field by demonstrating the potential of SVR models in predicting liquid levels and exploring the creation of a digital twin framework for the Festo MPS PA bottling station.
The study achieved promising initial results. The SVR model integrated within the Festo MPS PA Didactic System and TIA Portal showed potential for effectively predicting liquid level. Additionally, exploring a data-driven, sensor-agnostic prediction approach and a virtual entity framework within the TIA Portal suggests promising future developments in digital twin technology for industrial automation training systems.
2. Related Work
Digital twins have emerged as a critical technology for enhancing industrial processes through cyber–physical integration. A comprehensive review by Tao et al. [
6] provides a comparative analysis of cyber–physical systems (CPS) and digital twins, highlighting the subtle yet important differences between these two concepts. While both technologies aim to achieve seamless interaction between the physical and digital worlds, the study emphasizes the distinct capabilities and applications of digital twins in smart manufacturing. The current research aligns with this analysis by utilizing a digital twin framework, specifically tailored for predictive modeling in process automation, thus extending the scope of digital twin applications beyond traditional CPS.
Kammerer et al. [
7] applied digital twins for anomaly detection in manufacturing systems, focusing on real-time data analysis to enhance predictive maintenance strategies. Although this approach effectively identified performance deviations, it did not incorporate machine learning models for continuous variable prediction, such as water levels. By integrating SVR to predict the RoC of water levels, the current study addresses this gap, particularly in mitigating error accumulation over time.
Chryssolouris et al. [
8] explored digital twin technology for estimating the remaining useful life (RUL) of manufacturing equipment, leveraging physics-based simulation models. This method provided accurate predictions without disrupting operations, showcasing the potential of digital twins in predictive maintenance. However, the approach remained reliant on traditional simulations, whereas the current study adopts a data-driven methodology using radial basis function (RBF) SVR, which enhances prediction accuracy through parameter optimization.
Similarly, Putawa et al. [
9] investigated the use of digital twins for visualizing and controlling energy efficiency in manufacturing environments. While effective in system control, the study focused primarily on visualization rather than predictive analytics. The current research shifts towards predictive capabilities, employing SVR within a digital twin framework to forecast water levels accurately, thereby enhancing process control and monitoring.
In summary, this research advances the application of digital twins by integrating RBF SVR for RoC prediction and optimizing SVR parameters to minimize error accumulation, thereby addressing specific challenges in process automation and control. This approach not only builds upon existing studies, but also contributes to the broader field of digital twin technology in industrial settings.
3. Methodology
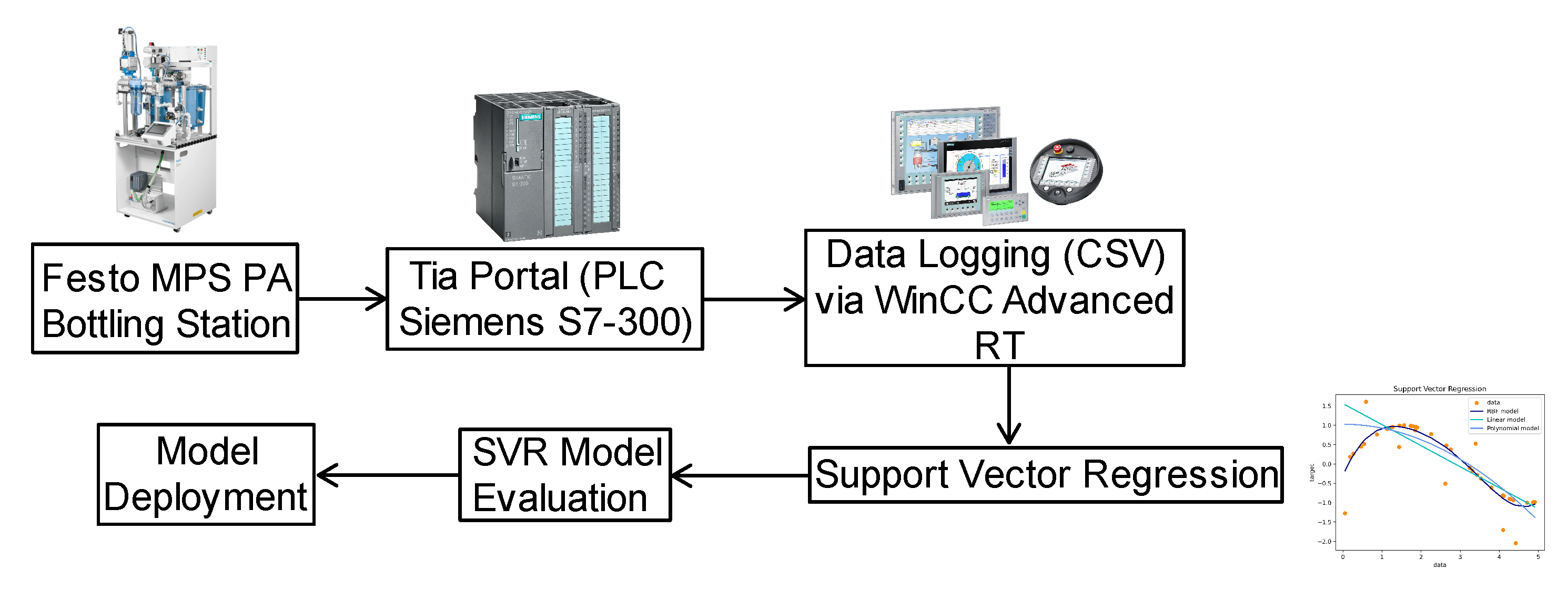
This research employs the Festo MPS-PA Didactic Complete System’s bottling station (Esslingen, Germany) and SVR to establish a machine learning framework. The primary objective of this framework is to predict the water level in the tank, a measurement typically acquired via an installed ultrasonic sensor. An overview of the system setup is illustrated in
Figure 1, providing a detailed visual representation of the configuration.
3.1. Festo MPS PA Bottling Station
The Festo MPS PA system comprises four stations: Filtration, Mixing, Reactor, and Bottling. These stations simulate the water filtration process, providing students with practical knowledge in Process automation and Control theory. This is achieved by controlling multiple variables, including pressure, flow rate, temperature, and water level. This study focuses on the bottling station, which houses the ultrasonic sensor. The aim is to develop a digital twin of this sensor. Further details of the experimental setup will be discussed in
Section 4.
3.2. Human–Machine Interface
The human–machine interface (HMI), designed using Siemens’ WinCC Runtime Advanced, enables operators to control processes and monitor real-time data. It also collects operational data, including timestamps, sensor readings, and actuator values. While a DAQ device can directly obtain these values, the standard in process automation is to use the HMI. This study adheres to these industrial standards, ensuring its applicability in real-world scenarios.
3.3. Support Vector Regression
In this study, SVR is implemented as the machine learning technique to forecast the output of an ultrasonic sensor. The accurate prediction serves as an early warning system for potential failures, which are indicated by discrepancies between actual and predicted values [
10]. SVR, a robust supervised machine learning algorithm, is specifically designed for regression tasks [
11]. It generates predictions based on a set of input data points. Unlike conventional regression methods that strive to minimize the total error between predicted and actual values, SVR constructs a hyperplane in a high-dimensional space that maximizes the error margin around the most influential data points, referred to as support vectors [
11]. This focus on margin minimization reduces the influence of outliers, rendering SVR particularly suitable for applications involving noisy sensor data, such as ultrasonic sensor measurements in industrial settings.
For this study, an RBF kernel was chosen for the SVR model due to its effectiveness in handling non-linear relationships that might exist between sensor readings and water level. The model development utilized the Scikit-learn library [
12]. The pre-processed sensor data obtained from the HMI were divided into training and testing sets. The training set was used to train the model, while the testing set evaluated the model’s ability to generalize to unseen data. Hyperparameter tuning, employing a grid search technique, was conducted to identify the optimal combination of parameters that minimize the MSE on the validation set by using 3 nested for loops to run through all the possible combinations of hyper-parameter for the best result. The performance of the trained model was subsequently evaluated using metrics like MSE and R-squared on the testing set [
13].
Explanation of Hyperparameters
Cost (C): Controls the trade-off between maximizing the margin and minimizing the training error. A higher C value allows less margin violation, leading to a more complex model.
Gamma (): Influences the width of the RBF kernel function. A smaller gamma results in a wider kernel, leading to smoother decision boundaries.
Epsilon (): Defines the width of the insensitive zone within the epsilon-SVR formulation. Points within this zone are not penalized in the loss function.
By carefully tuning these hyperparameters, the optimal SVR model for predicting water level was determined.
4. Experiment Setup and Implementation
4.1. Festo MPS PA Bottling Station
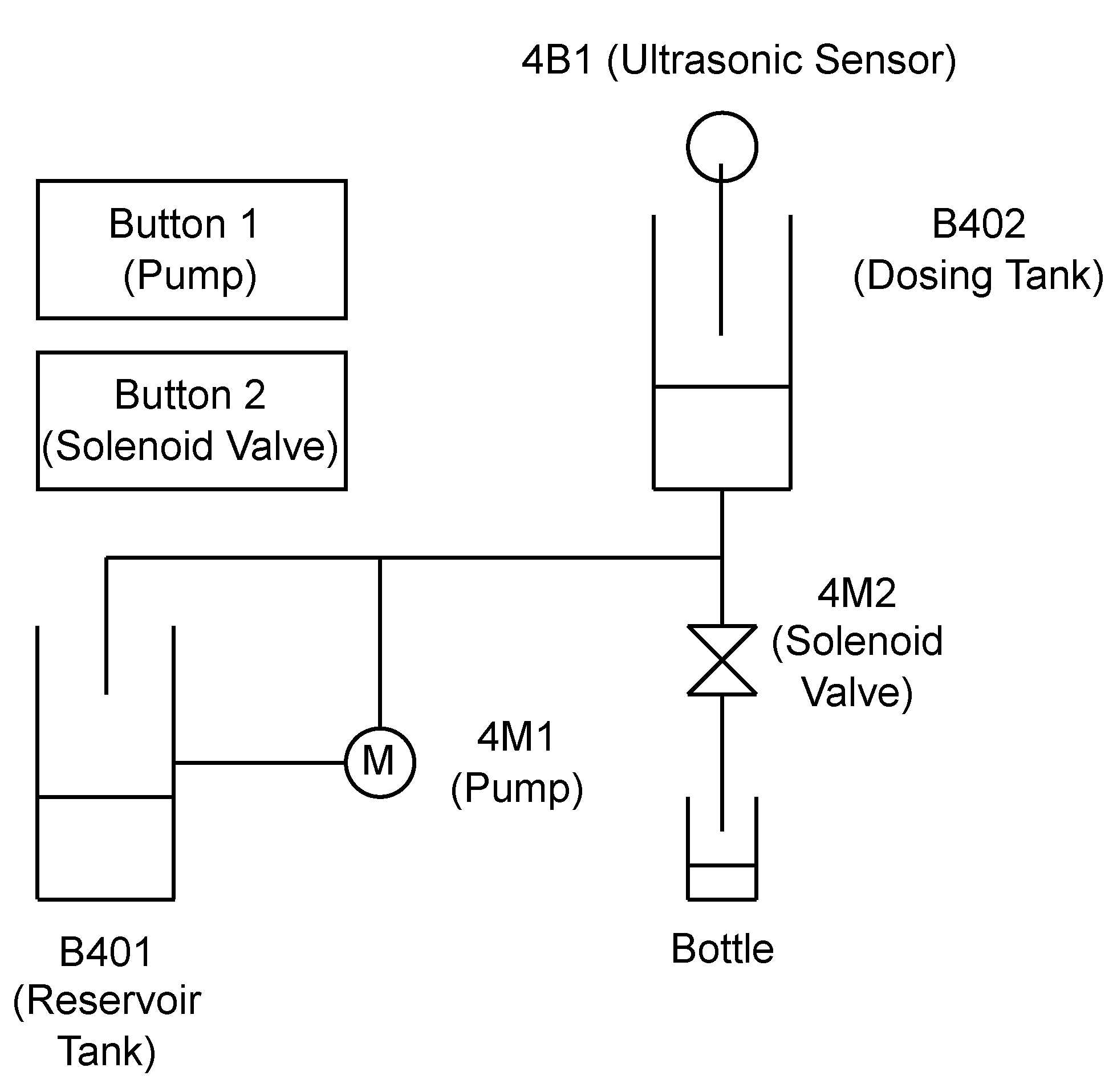
The Festo MPS PA bottling station serves as a valuable training tool in educational settings, specifically designed to introduce students to the intricacies of industrial bottling processes. While not a full-fledged industrial system itself, it effectively simulates the steps involved in filling bottles with liquid. It features the following essential components that mimic a real bottling line (
Figure 2):
Reservoir tank (Area , Height ): This tank functions as the primary storage container for the liquid to be bottled. It has a larger capacity compared to the dosing tank and is refilled periodically to maintain a stable liquid supply.
Dosing tank (Top diameter: , Mid-diameter: , Bottom diameter: , Height ): This tank acts as a container between the reservoir tank and the bottling line. It has a smaller capacity than the reservoir tank and integrates with an ultrasonic sensor to precisely measure the liquid level in the tank.
Pepperl+Fuchs Ultrasonic Sensor 3RG6232-3JS00-PF (Mannheim, Germany): This sensor leverages ultrasonic technology to achieve continuous, non-contact measurement of the liquid level within the dosing tank. The acquired data play a critical role in the bottling process by enabling real-time monitoring and control, directly contributing to consistent product volume in the filled bottles by preventing overflows or underfills.
Johnson CM30P7-1 Pump (SPX Flow, Charlotte, NC, USA): The Festo MPS PA bottling station employs the Johnson CM30P7-1, a compact and efficient centrifugal pump, to ensure a smooth flow of liquids within the system. This pump leverages a rotating impeller to generate centrifugal force, effectively propelling the liquid through the pump housing.
Gemü 524D114124DCU solenoid valve (Ingelfingen, Germany): This solenoid valve is utilized for controlled liquid dispensing during the bottling process, and facilitates precise filling through a potential adjustable flow rate mechanism and material compatibility with the processed liquid. An anti-drip design is incorporated to minimize drips or spills after dispensing, promoting cleanliness and reducing product waste.
Siemens S7-300 CPU 314C-2PN/DP (Munich, Germany): The Siemens S7-300 programmable logic controller (PLC) plays a central role in automating the Festo MPS PA bottling station. It receives signals (buttons) and controls actuators (pump, valve) based on its program. The PLC makes the bottling process automated and flexible.
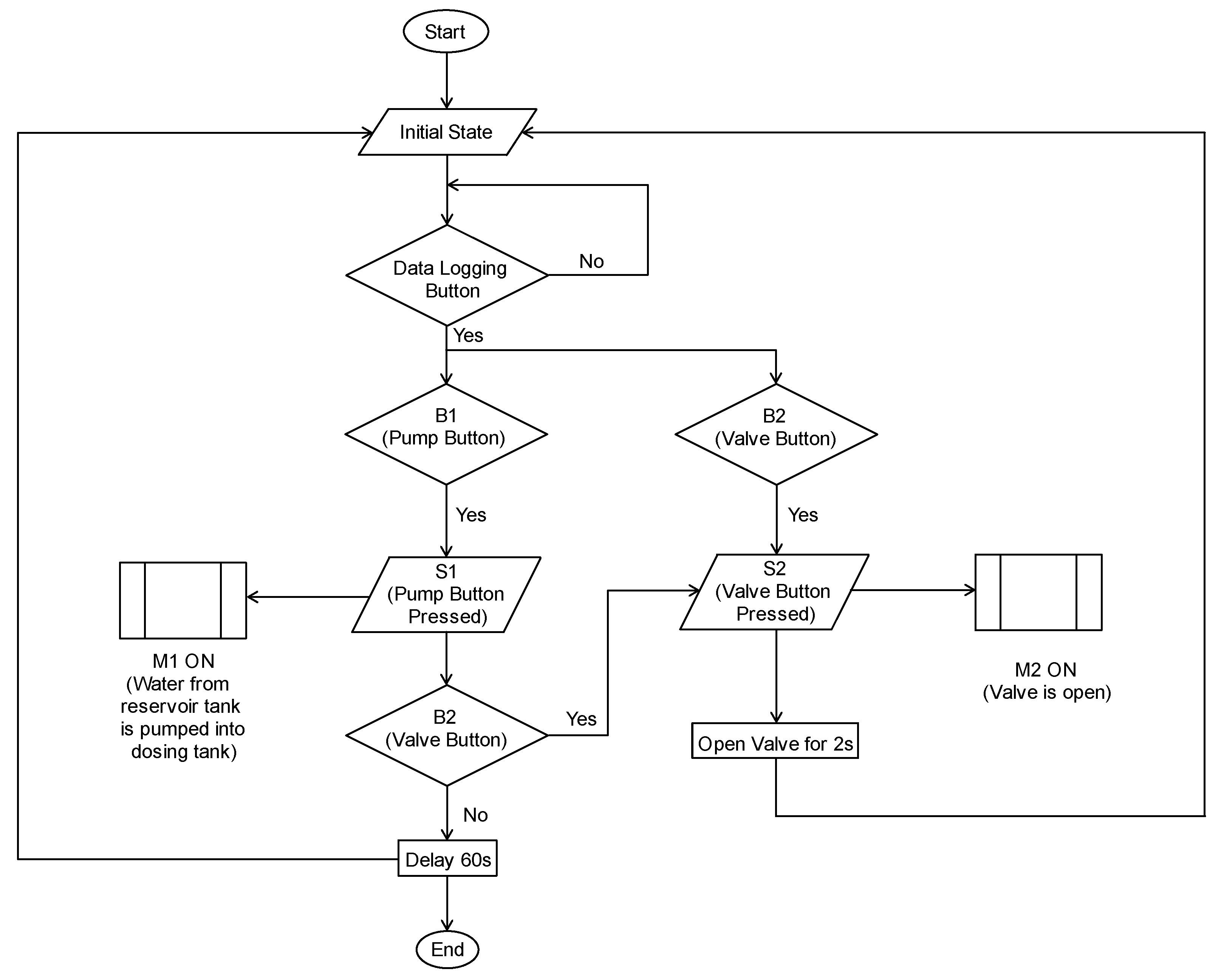
4.2. Test Cases and Experiment Settings
This section details the design and evaluation procedures employed to assess the SVR model’s performance for water prediction in the Festo MPS PA bottling station simulation (
Figure 3).
4.2.1. Scenarios
The test cases mimicked real-world bottling conditions by simulating various water level fluctuations that might occur during the filling process. These scenarios involved manipulating the two buttons (pump and solenoid valve) and the DAQ button to represent diverse operational conditions.
Filling cycle variations: Test cases included different button press combinations and duration for the pump and valve buttons. This simulated variations in water transfer volumes between tanks and diverse filling operations.
DAQ: Users could define the time interval between data points logged in the CSV file via the DAQ button. This allowed for customization based on the desired data granularity for model training.
4.2.2. Settings
The experiment setup involved a two-pronged approach:
TIA Portal Program: The operation logic and communication between components were programmed within the TIA Portal. This program included functions for:
- –
Button control: Responding to user interaction with the pump and valve buttons, triggering virtual button presses within the WinCC environment.
- –
Sensor communication: Establishing communication with the ultrasonic sensor to retrieve real-time water level readings.
- –
Data transfer: Potentially transferring the collected water level data to WinCC for further processing or visualization.
WinCC Advanced Runtime Environment: WinCC Advanced RT provided the platform for controlling the experiment, acquiring data, and triggering data logging scripts. The functionalities within WinCC were achieved through the Visual basic (VB) scripts.
4.2.3. SCADA Design and Data Logging Using VB Script
The experiment leveraged a supervisory control and data acquisition (SCADA) design approach within WinCC Advanced Runtime to control the simulation and acquire data for model development. VB scripts played a vital role in this SCADA design, acting as the interface between the HMI and the physical components.
4.3. Format of Data
The VB scripts generated a CSV file for model training and evaluation. This file offers a well-defined format for efficient processing by the SVR model. Each column of data is separated by a semicolon (;) delimiter. The data format includes:
Timestamps: Captures the time of each data point (e.g., YYYY-MM-DD HH:MM:SS) for time-based analysis.
Water Level Reading: Represents the real-time water level measurement (milliliters)—the target variable for prediction.
Input Features of the VB screen in WinCC:
- –
Pump: Toggle the ON and OFF state of the 4M1 Pump;
- –
Valve: Toggle the ON and OFF state of the 4M2 Valve;
- –
Start data logging: Start the VB script that logs the data on the WinCC server side;
- –
Other input data are controlled by directly modifying the values in TIA Portal’s HMI tag table.
By adhering to this structured format with semicolon delimiters, the CSV file provides a well-organized dataset suitable for machine learning model training and evaluation.
5. Model Development
5.1. Lagrange Duality
Lagrange duality is a fundamental concept in convex optimization and plays an important role in an SVR algorithm [
14]. An optimization often has a standard form as follows:
A Lagrangian approach is to optimize Equation (
2) instead:
where
,
.
Equation (
2) is referred to as the Primal Lagrangian equation. The second alternative to the Primal function is the Dual Form equation:
where
.
5.2. Support Vector Machine with Linear Kernel
Given a linear kernel, a regression line will have a general linear function in the form of Equation (
4).
The objective of SVR is to determine the vector
such that the resulting linear function ensures most of the data points
remain within a specified
tolerance.
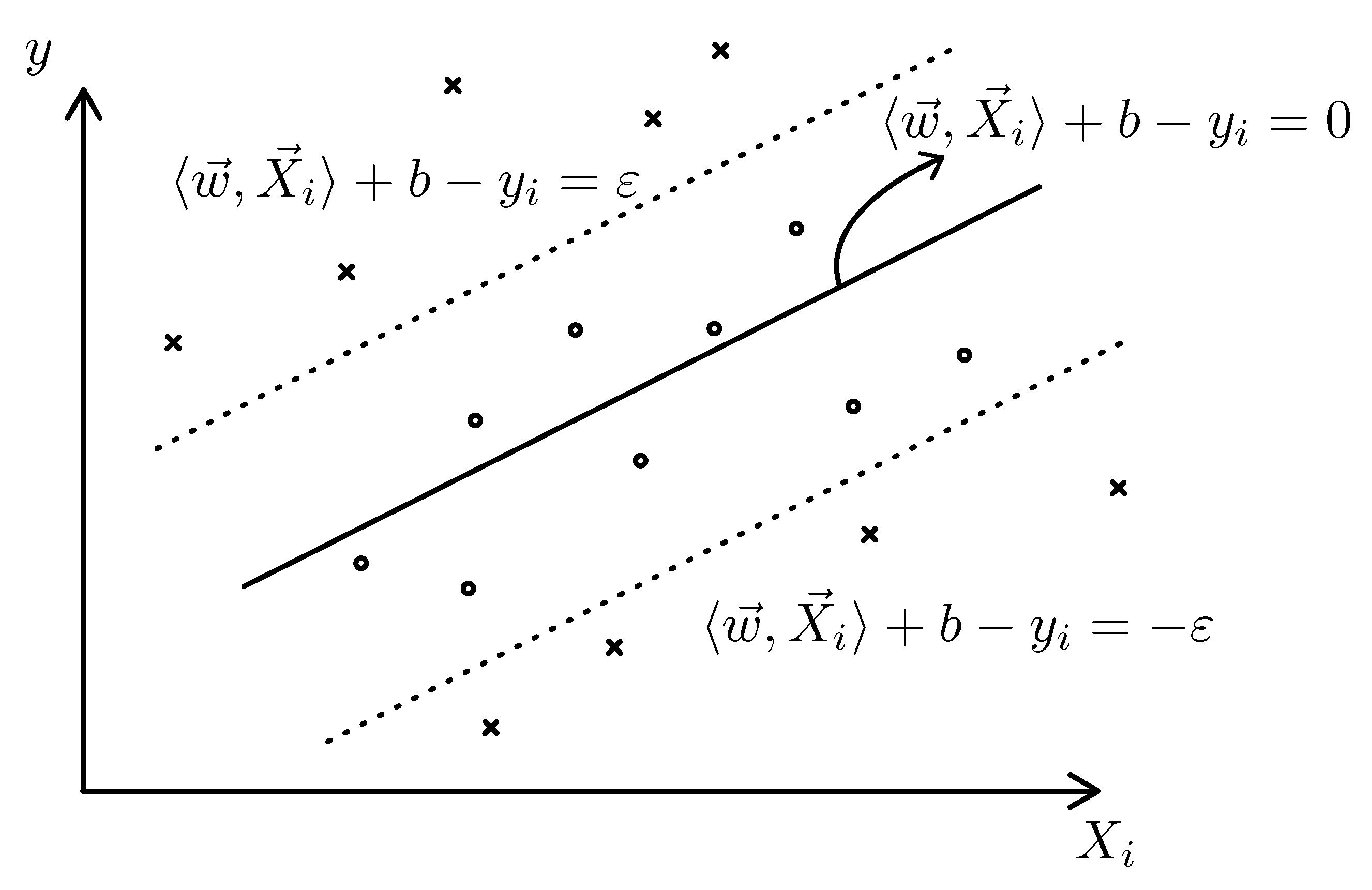
Figure 4 shows the general presentation of the kernel in the case that
and
only have one dimension, but in application, both of these vectors can have much higher dimensions that cannot be represented in a Cartesian coordinate.
The aim of SVR now becomes Equation (
5)
Equation (
5) assumes that the convex optimization for a linear kernel function
with an error of
is feasible. Sometimes, this may not be the case and some amount of errors needs to be taken into account. Hence, the slack variables
and
need to be used [
11].
The parameter
C determines the trade-off between the flatness of
f and determines how much amount of deviation from the target error
is tolerated [
11].
5.3. Gaussian Kernel
RBF kernel regression, or sometimes called Gaussian kernel regression, is a popular algorithm that is widely used in SVM tasks or, in this case, SVR [
15].
The kernel function for two sets of parameters is defined in Equation (
7)
where
, and
is the standard deviation parameter of the Gaussian curve, which also determines the width of the Gaussian kernel [
15].
The weight
used in support vector regression is determined based on the similarity between the kernel
K of data
i and the rest of the data points.
Implementing the kernel into an SVM system, Equation (
9) is obtained
5.4. Hyperparameters Explanation
The
C parameter is a scalar that controls the penalty for the values that deviate from the predicted regression curve. The higher the value
C is, the more noticeable the error is [
12]. In contrast, a smaller value of
C allows for a larger margin and more tolerance for errors, which can lead to a simpler model with potentially higher bias but lower variance.
The
value controls the width of the Gaussian kernel function used for the regression process. This parameter defines the extent to which a single training example influences the model’s decision boundary [
12]. A lower
results in a wider influence, making each training example affect a larger area of feature spaces.
is the margin of tolerance around the predicted curve. If a data point is positioned within this margin, the point will have 0 error penalty [
12]. This margin will act as an error threshold. Similar to the
C parameter, a larger
will result in a higher bias and lower variance predicted curve.
5.5. Model Explanation
Based on the experimental setup illustrated in
Figure 3, the network’s input layer comprises six variables, as detailed in
Table 1.
Upon initial observation using Microsoft Excel 365 (Version 2312, Microsoft) [
16] graphing tool, utilizing the RoC of the water level as training data rather than the water level itself appears to be more effective for the labeling process. This is due to the direct correlation observed between the valve state (0 and 1), Button and Pump values, and the RoC of the water level.
The discrete RoC of the parameter is calculated as follows:
The
Time variable is relabeled manually with respect to
Button1 (
Figure 5) to make the learning process more effective. This is due to Button1 having the most influence over the predicted data. Each time
Button1 goes from 0 to 1 and to 0 again, the
Time variable is reset to 0, creating an ON and OFF cycle, which is equal to splitting one dataset into many smaller datasets for better pattern recognition.
6. Model Evaluation and Chosen Hyperparameters
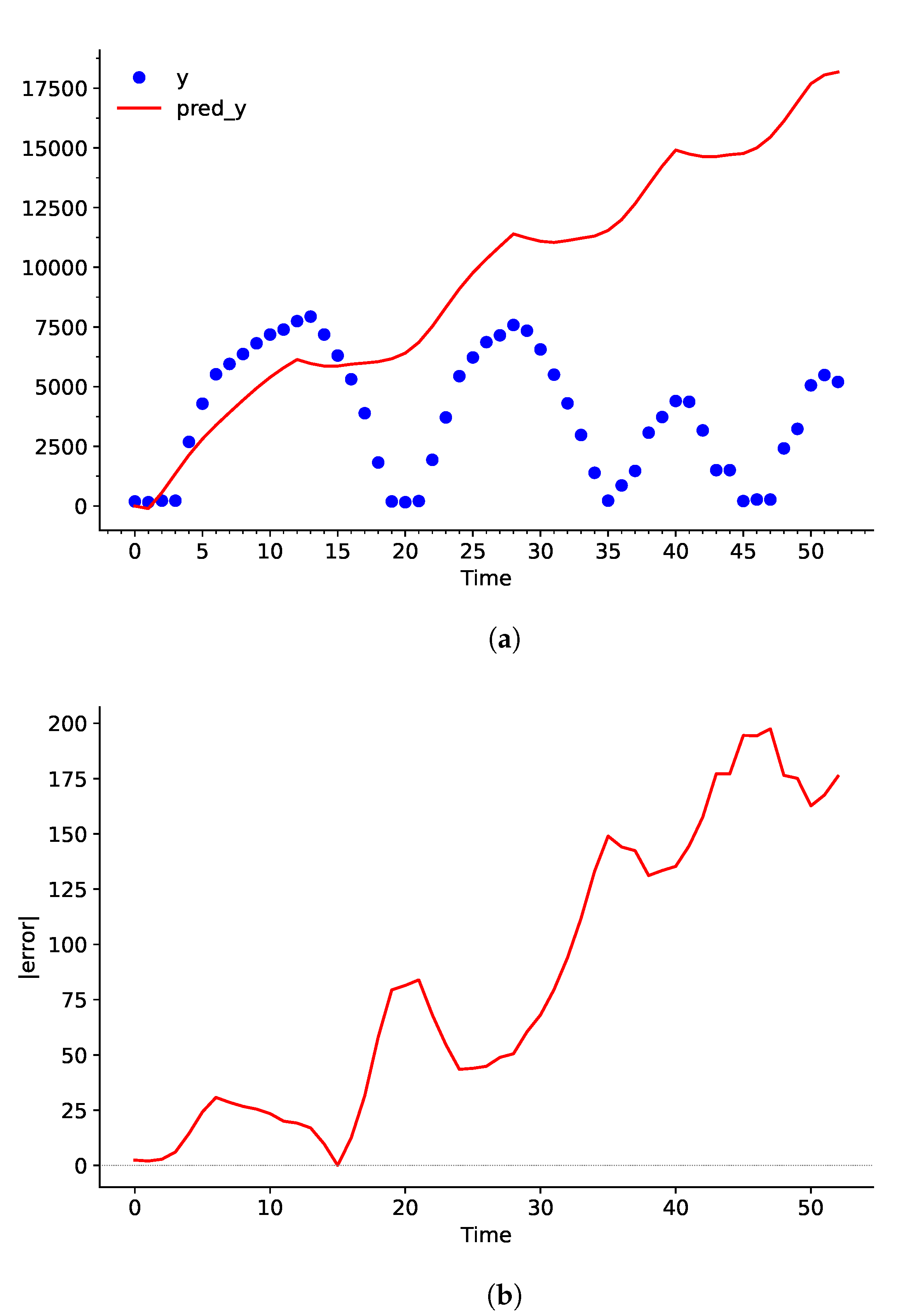
In this experiment, the true water level measured using the ultrasonic sensor will be assigned to Y, and the water level predicted by the algorithm will be stored to pred_Y. Similarly, the RoC of the water level derived from Y is stored in dY, and the predicted RoC of the water level (which will be used to calculate pred_Y) is assigned to pred_dY. The experiment was performed five times and produced no significant difference (less than ) for each set of hyperparameter C, , and .
When the predicted curve undergoes the integration process later on in the network, any slight deviation between
dY and
pred_dY will stack up overtime. Evidently, even though the error is not observed to be a problem in
Figure 6, the difference between
Y and
pred_dY keeps increasing continuously in
Figure 7.
This makes it more effective to use a higher
C and lower
value for the training process. Lowering
will decrease the tolerance margin for the error value, and increasing the
C will increase the penalty of each predicted value that deviates further from the
-margin. This will force
pred_dY to be much closer to the value of
dY. In turn, this will also increase the variance of
pred_dY, as discussed in
Section 5.4. This should not be a problem in this particular use case because the integration process will smooth out most of the variance as long as
does not change rapidly from positive to negative values.
The chosen hyperparameters for the problem are: , , .
Upon comparison between
Figure 6 and
Figure 8, it becomes clear that the adjusted
C,
, and
values have greatly decreased the bias between the dataset and the predicted curve. Particularly, values from
have a larger influence over
pred_dY. This helps largely reduce the deviation in the integration process, as shown in
Figure 9.
pred_dY may have high variation, but a large or small positive value still results in an increase in
dY. Similarly, a large or small value of negative
pred_dY will result in a decrease in
dY. This characteristic can be demonstrated by taking the average error of
Figure 8b and b. Even though the SVR model showed an average
error rate for predicting RoC of the water level, it only showed an average
error rate for predicting the actual water level after integration.
7. Conclusions
In conclusion, the evaluation of the sensor output prediction model, the optimization of hyperparameters, and the utilization of derivation and integration have provided an increase in accuracy for the sensor behavior predictions.
Subsequent to this experiment, it is advised to integrate more parameters into the system. Specifically, the application of simulation coupling could optimize computational resources and reduce inference time [
17]. This addition would introduce another layer to the network and alleviate the drifting error that occasionally cannot be eradicated solely by predicting the derivative [
18]. Furthermore, the incorporation of sensor fusion algorithms, such as the Kalman filter, could significantly enhance the model’s precision by consolidating data from diverse sources [
19]. This strategy offers a more resilient and precise prediction model for future applications.
Lastly, to visualize and analyze the system holistically, a digital twin representation can be constructed using CAD software like Siemens’ NX for the ultrasonic sensor and a three-dimensional visualization engine like Tecnomatix Plant Simulation for the entire Festo MPS PA system. This approach could serve as a foundation for digitizing various manufacturing processes [
20].
Author Contributions
Conceptualization, C.D.L.; methodology, T.M.D. and D.N.D.; software, T.M.D., D.N.D. and K.H.V.N.; validation, T.M.D.; formal analysis, T.M.D.; investigation, T.M.D. and D.N.D.; resources, K.H.V.N.; data curation, T.M.D. and D.N.D.; writing—original draft preparation, T.M.D. and D.N.D.; writing—review and editing, R.A.d.M.A., C.D.L. and K.H.V.N.; visualization, T.M.D.; supervision, C.D.L.; project administration, K.H.V.N.; funding acquisition, K.H.V.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research is funded by the Vietnamese–German University Research Funding under grant number DTCS-2023-002.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Dataset available on request from the authors.
Acknowledgments
During the preparation of this manuscript, the authors utilized ChatGPT (OpenAI, GPT-4o) to assist in correcting grammatical and spelling errors. The authors have reviewed and edited the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SVR | Support Vector Regression |
| SVM | Support Vector Machine |
| RBF | Radial Basis Function |
| DT | Digital Twin |
| RUL | Remaining Useful Life |
| CPS | Cyber–Physical Systems |
| RoC | Rate of Change |
| HMI | Human–Machine Interface |
| DAQ | Data Acquisition |
| MSE | Mean-Squared Error |
| PLC | Programmable Logic Controller |
| VB | Visual Basic |
| SCADA | Supervisory Control and Data Acquisition |
| CAD | Computer-Assisted Design |
References
- Kaneko, H.; Funatsu, K. Application of online support vector regression for soft sensors. AIChE J. 2013, 60, 600–612. [Google Scholar] [CrossRef]
- Ayadi, R.; El-Aziz, R.M.A.; Taloba, A.I.; Aljuaid, H.; Hamed, N.O.; Khder, M.A. Deep Learning–Based soft sensors for improving the flexibility for automation of industry. Wirel. Commun. Mob. Comput. 2022, 2022, 1–10. [Google Scholar] [CrossRef]
- TIA Portal; V17; Siemens AG: Munich, Germany, 2021.
- Hu, W.; Zhang, T.; Deng, X.; Liu, Z.; Tan, J. Digital twin: A state-of-the-art review of its enabling technologies, applications and challenges. J. Intell. Manuf. Spec. Equip. 2021, 1, 21–23. [Google Scholar] [CrossRef]
- Thelen, A.; Zhang, X.; Fink, O.; Lu, Y.; Ghosh, S.; Youn, B.D.; Todd, M.D.; Mahadevan, S.; Hu, C.; Hu, Z. A comprehensive review of digital twin—Part 1: Modeling and twinning enabling technologies. Struct. Multidiscip. Optim. 2022, 65, 354. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q.; Wang, L.; Nee, A. Digital Twins and Cyber–Physical Systems toward Smart Manufacturing and Industry 4.0: Correlation and Comparison. Engineering 2019, 5, 653–661. [Google Scholar] [CrossRef]
- Kammerer, K.; Hoppenstedt, B.; Pryss, R.; Stökler, S.; Allgaier, J.; Reichert, M. Anomaly Detections for Manufacturing Systems Based on Sensor Data—Insights into Two Challenging Real-World Production Settings. Sensors 2019, 19, 5370. [Google Scholar] [CrossRef] [PubMed]
- Aivaliotis, P.; Georgoulias, K.; Chryssolouris, G. The use of Digital Twin for predictive maintenance in manufacturing. Int. J. Comput. Integr. Manuf. 2019, 32, 1067–1080. [Google Scholar] [CrossRef]
- Putawa, R.A.; Wardana, A.N.I.; Tenggara, A.P. Metaverse-based water level simulator for the Festo MPS PA workstation. J. Phys. Conf. Ser. 2023, 2673, 012008. [Google Scholar] [CrossRef]
- Grinblat, G.L.; Uzal, L.C.; Verdes, P.F.; Granitto, P.M. Nonstationary regression with support vector machines. Neural Comput. Appl. 2014, 26, 641–649. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Frost, J. Regression Analysis: An Intuitive Guide for Using and Interpreting Linear Models; Statistics by Jim Publishing: State College, PA, USA, 2020. [Google Scholar]
- Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004; Volume 51, p. 1859. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Microsoft Excel; version 2312; Microsoft: Richmond, WA, USA, 2024.
- Edtmayer, H.; Brandl, D.; Mach, T.; Schlager, E.; Gursch, H.; Lugmair, M.; Hochenauer, C. Modelling virtual sensors for real-time indoor comfort control. J. Build. Eng. 2023, 67, 106040. [Google Scholar] [CrossRef]
- Shacham, M.; Brauner, N. Minimizing the Effects of Collinearity in Polynomial Regression. Ind. Eng. Chem. Res. 1997, 36, 4405–4412. [Google Scholar] [CrossRef]
- Petersen, C.D.; Fraanje, R.; Cazzolato, B.S.; Zander, A.C.; Hansen, C.H. A Kalman filter approach to virtual sensing for active noise control. Mech. Syst. Signal Process. 2008, 22, 490–508. [Google Scholar] [CrossRef]
- Lyu, Z.; Fridenfalk, M. Digital twins for building industrial metaverse. J. Adv. Res. 2023, 66, 31–38. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}