1. Introduction
The aircraft engines are the core component of an aircraft and their health status directly influences the safety of flight operations [
1]. The prediction of RUL is one of the cores of Prognostics and Health Management (PHM) technology, which not only forecasts the future health status of the engines but also provides reasonable maintenance strategies for their health management [
2]. The maintenance costs of aircraft engines are high. Premature maintenance can result in economic losses, while delayed maintenance can lead to accidents. Therefore, in order to ensure the safety and reliability of aero-engine operations, it is crucial to accurately predict the engines’ RUL.
The methods of RUL prediction can be divided into knowledge-based approaches, physical model-based approaches, and data-driven approaches [
3]. Knowledge-based models predict RUL by knowledge and experience, providing interpretable results. However, it is challenging to obtain accurate knowledge from experience and the sources of knowledge are limited [
3]. When the system complexity is low, physical model-based methods can establish accurate mathematical and physical models of the engines to predict their RUL, with high prediction accuracy [
4]. The drawback of this approach is that the internal structure, operational mechanisms, and degradation principles of the engines need to be understood. Due to the fact that aero-engines have a complex structure and numerous components, it is challenging to develop accurate models and the precision of life prediction can be influenced.
In contrast, data-driven methods do not require in-depth knowledge of the device’s degradation mechanisms [
5], but only need the internal state data of the equipment. Through machine learning methods, large amounts of historical data can be utilized to establish models for RUL prediction. RUL prediction methods based on data are mainly divided into shallow model-based approaches and deep learning-based approaches [
6]. There has been considerable research on RUL based on shallow models, such as Khelif et al. [
7], who used support vector regression to establish the relationship between sensor values and health indicators, estimating RUL at any point in the degradation process. Chen et al. [
8] introduced a life prediction method using Lasso feature selection and random forest regression. While RUL methods based on shallow models have achieved certain results, it is difficult for their predictive performance to significantly improve beyond a certain stage due to the limitations of the learning capabilities of shallow models.
In recent years, with the continuous development of deep learning technology, it has become the mainstream and cutting-edge method in the field of RUL prediction due to its superior predictive performance. Heimes [
9] used recurrent neural networks (RNNs) to predict the RUL of aircraft engines. However, it is difficult for RNNs to effectively capture long-term dependencies in processing long sequence data due to their insufficient memory capacity. To address this issue, researchers have proposed variants of RNNs such as Long Short-Term Memory networks (LSTM) and Gated Recurrent Units (GRUs). For instance, Li et al. [
10] employed principal component analysis for dimensionality reduction to obtain the correlation of sensor data, followed by using LSTM to extract temporal features for predicting the RUL of aero-engines. Boujamz et al. [
11] introduced an attention mechanism-enhanced LSTM method, improving the prediction capability of engines. Qin et al. [
12] proposed a gated recurrent neural network with attention gates for the prediction of the RUL of bearing. To obtain capabilities of more robust feature extraction, researchers have utilized autoencoders in RUL prediction. For example, Fan et al. [
13] first used a bidirectional LSTM autoencoder to extract basic features and then further predicted RUL through a transformer encoder. Ren et al. [
14] used a deep autoencoder and deep neural network to achieve a good RUL prediction efficiency of bearing. On the other hand, to fully extract RUL features, researchers have also utilized convolutional neural network (CNN) methods in RUL prediction. Li et al. [
15] constructed a deep CNN with convolutional kernels of different size for feature extraction to predict the RUL of engines. Lan et al. [
16] proposed an aero-engine RUL method combining attention mechanisms with residual deep separable convolutional networks. Che et al. [
17] used 1D convolutional network for degradation regression analysis, followed by a Bidirectional Long Short-Term Memory (Bi-LSTM) neural network for time series prediction, obtaining future degradation trends. Zhang [
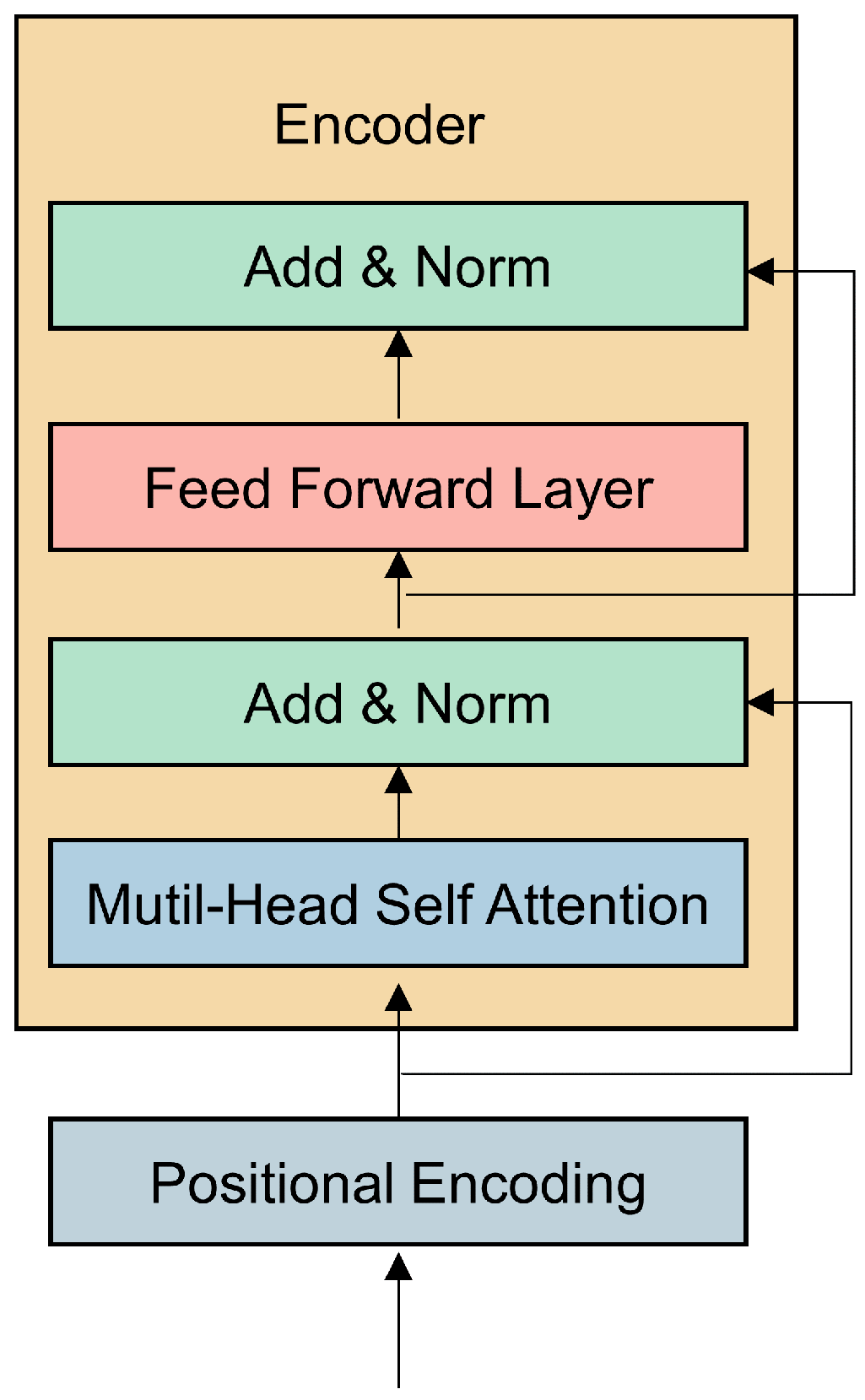
18] employed CNN for feature extraction, Bi-LSTM for capturing long-term dependencies in features and attention mechanisms to highlight important parts of features, enhancing the prediction accuracy of the model. RNNs and their variants have been widely applied in RUL prediction, but they use the last time node for feature prediction, ignoring the feature information from other historical nodes. Moreover, they cannot perform parallel inference and have poor interpretability. One-dimensional convolutional neural networks require that the time series is segmented into fixed-size time windows, necessitating significant computational resources and large amounts of data for RUL prediction, and are prone to overfitting. In contrast, the transformer model can perform parallel computations on input data, calculating global dependencies across the entire input sequence through self-attention, thereby capturing more comprehensive contextual information [
19]. Zhou et al. [
20] used transformer to mine the mapping relationship between features and RUL for the RUL prediction of bearing. Zhang et al. [
21] employed dual encoders to extract respectively features of different sensors and time steps, making it more effective for processing long data sequences. Ma et al. [
22] proposed a multi-encoder feature fusion method using transformer, selecting input data with two different time lengths, using permutation entropy to analyze relationships among sensors, independently extracting features from operational condition data. Zhang et al. [
23] introduced an adaptive optimal lightweight transformer with pruning to reduce model redundancy and improve prediction accuracy. Additionally, some researchers have adopted methods based on patch-segmented transformer models. For instance, Fan et al. [
24] utilized a hierarchical encoder–decoder structure to integrate multi-scale information, achieving hierarchical prediction. Ren et al. [
25] proposed a dynamic length transformer that can adaptively learn sequence representations of varying lengths. Mamba is built on state space models, which can selectively process time series input information and is simpler in structure. It has also been applied to RUL prediction. For example, Shi [
26] proposed MambaLithium to capture the complex aging and charging dynamics of lithium-ion batteries, with advantages in terms of predicting battery health.
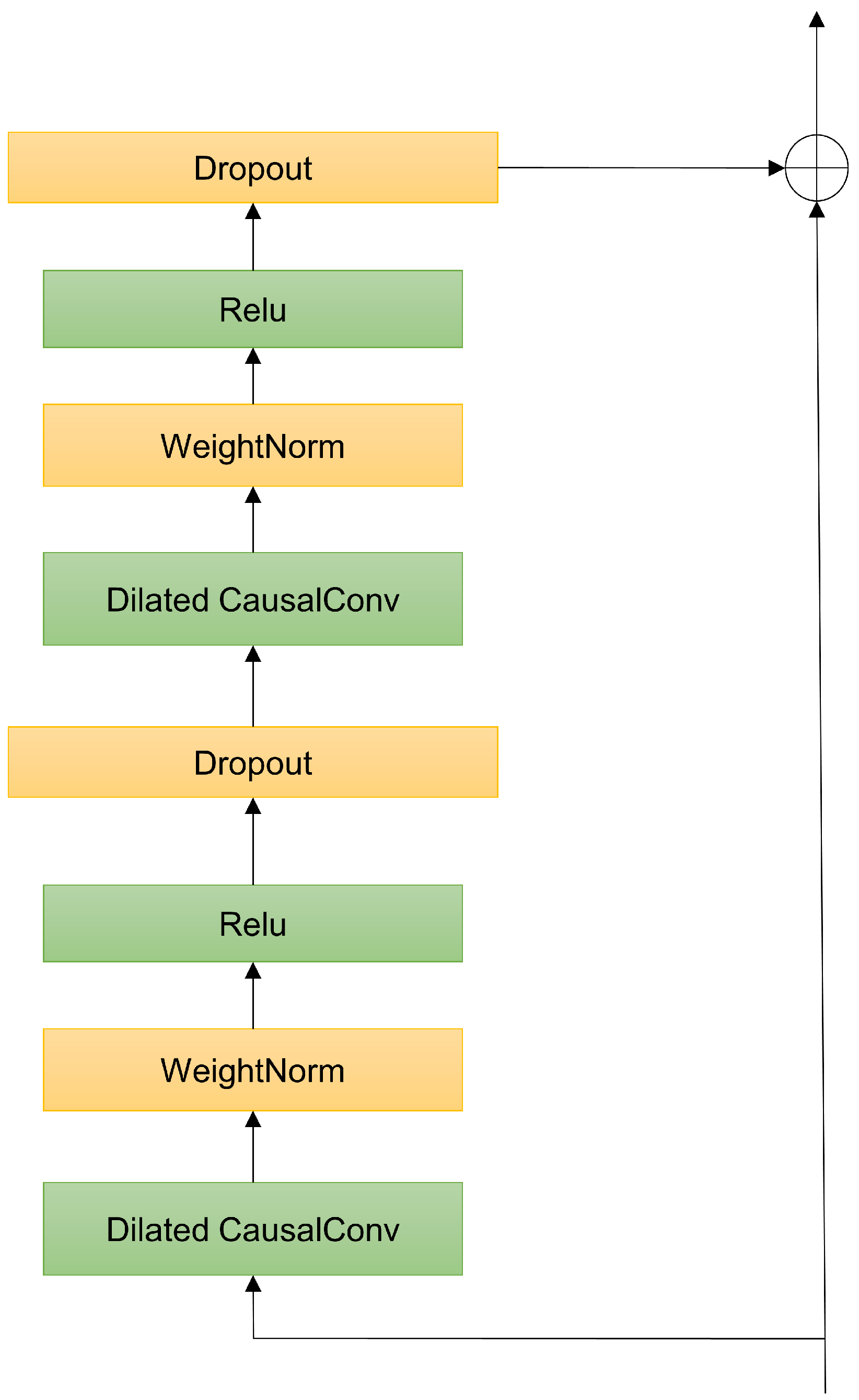
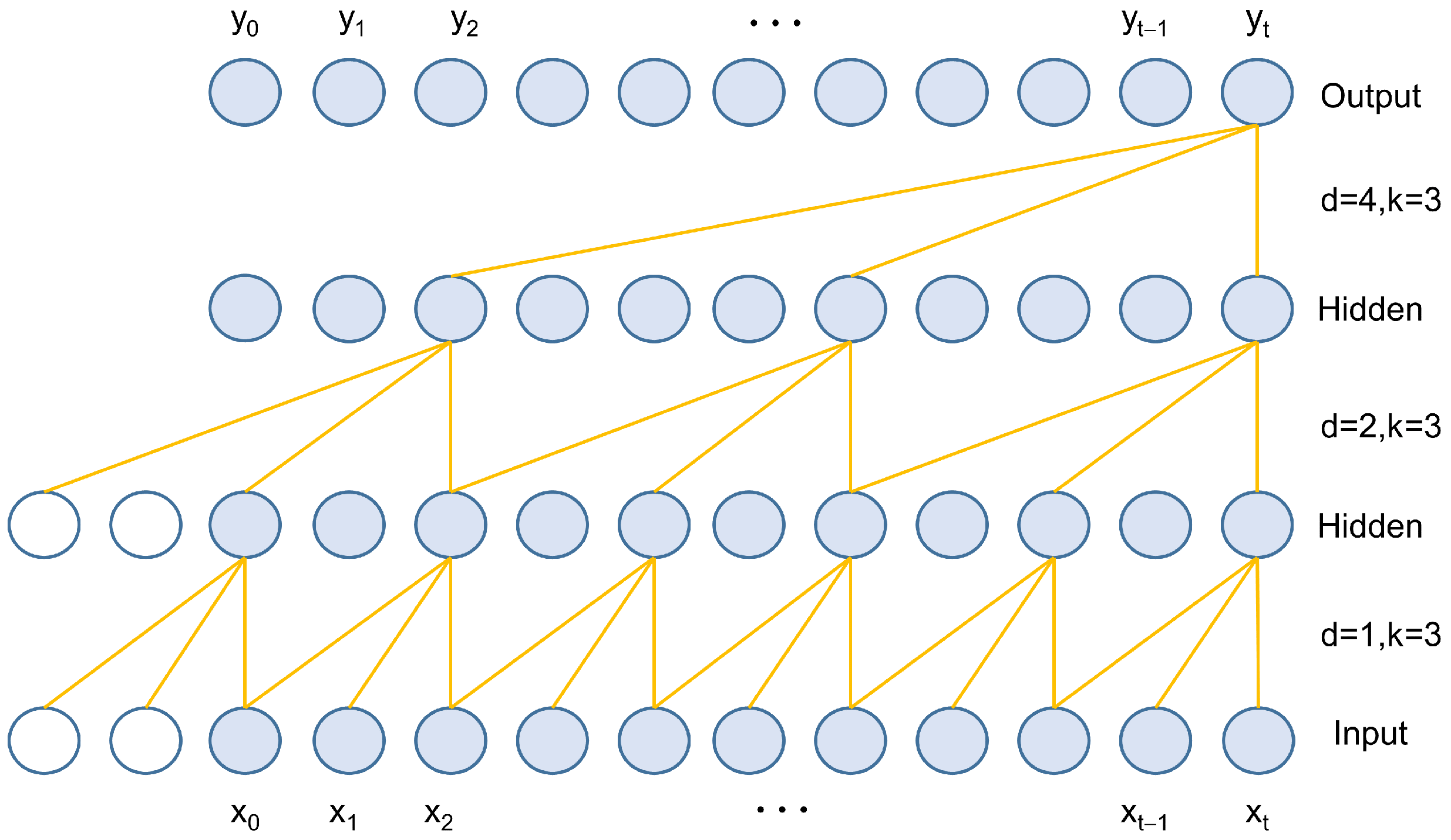
The transformer can capture global features of time series but is insensitive to local information. Aero-engines operate in high-speed, high-load, high-temperature, and harsh environments, where their operational data are characterized by high noise, high dimensionality, and indistinct states. Local information can significantly impact the accuracy of life prediction models. For multi-dimensional time series, the transformer processes variables of different dimensions equally, but these variables contain varying amounts of degradation information. TCN [
27] is a stable network that can parallelly compute data across all time steps, with strong long-term dependency modeling capabilities and fewer parameters. Zhang et al. [
28] proposed an RUL prediction method combining TCN with attention, assigning different weights to different sensor features and time steps through attention mechanisms. However, for long time series, TCN can easily lose information and fixed-length convolutional kernels cannot flexibly handle time series of varying lengths. In some cases, the transformer may also fail to effectively capture sparse features in the data.
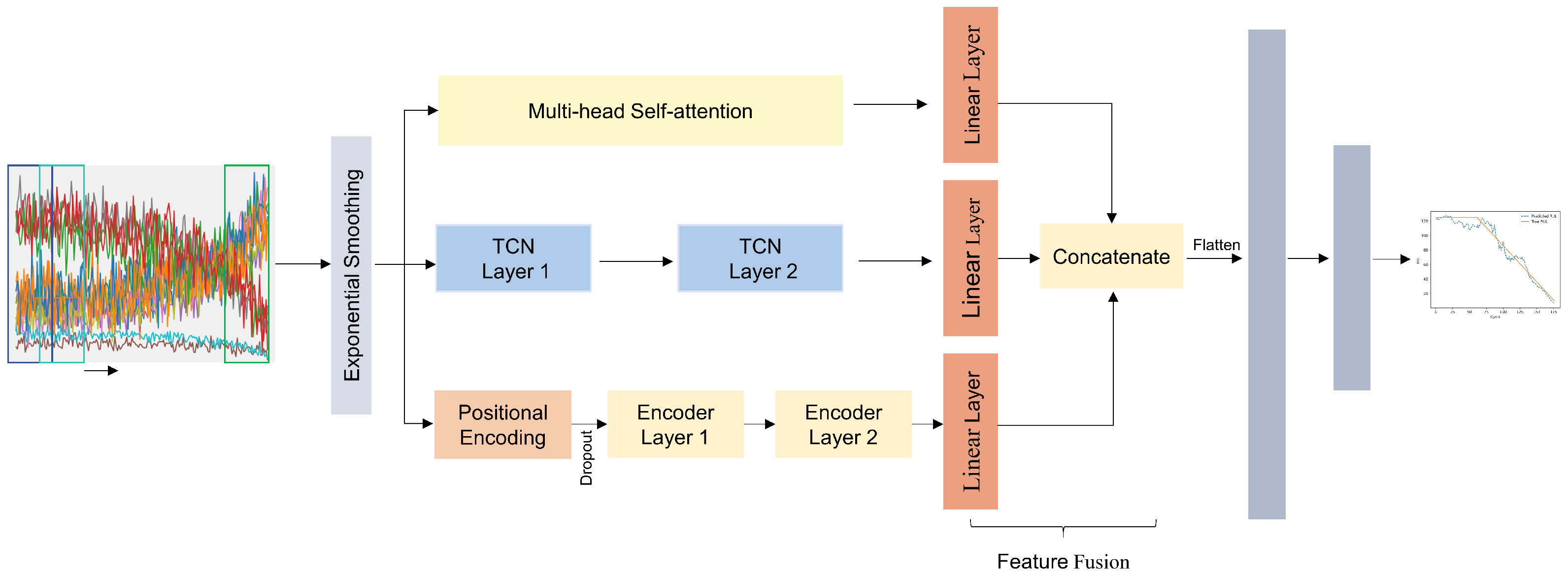
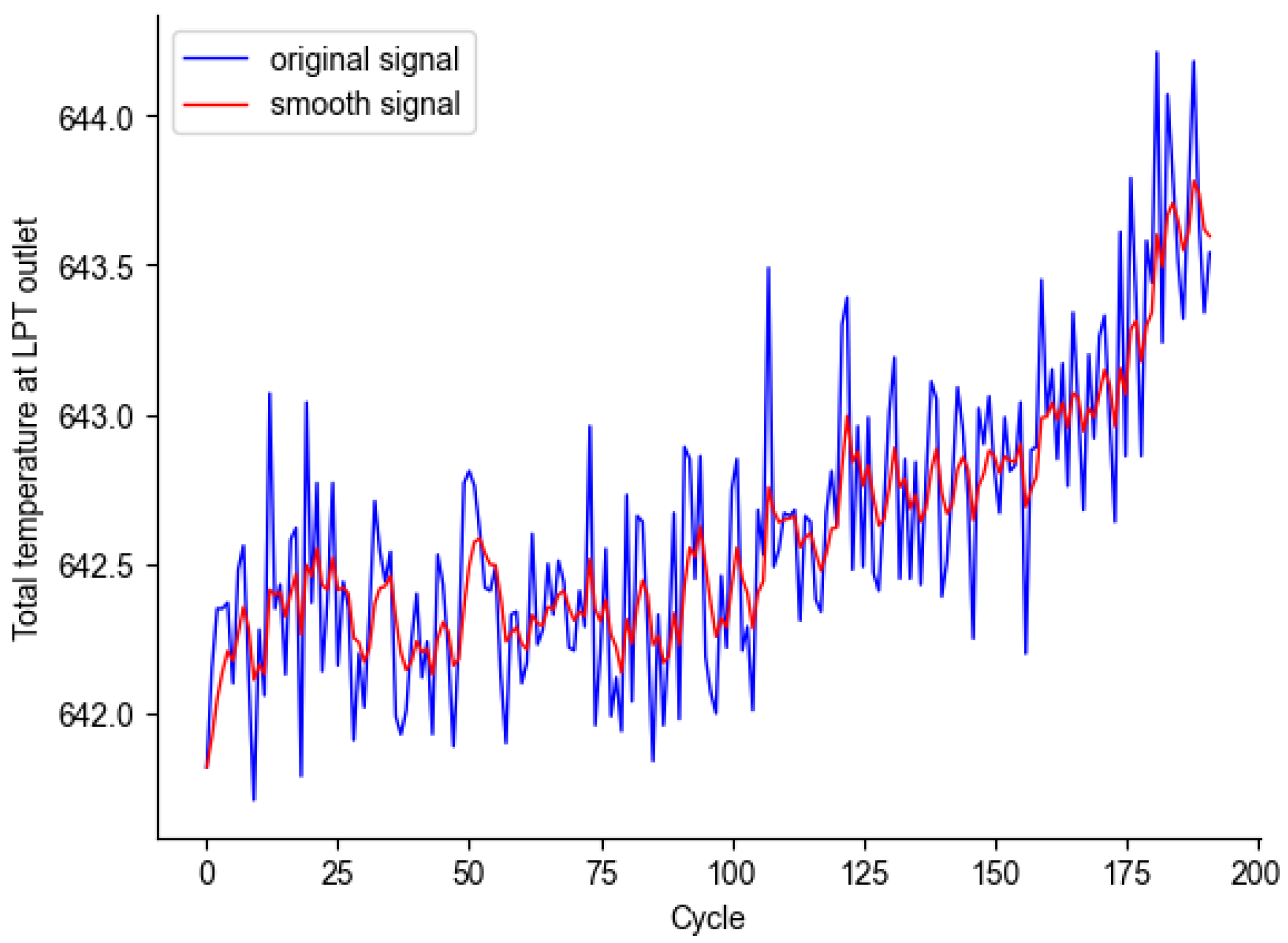
Therefore, leveraging the strengths of both models and the advantages of weight assignment of multi-head self-attention mechanisms to important features, this study presents a model for the RUL prediction of aero-engines, which fuses features from a three-branch network of a transformer, TCN, and multi-head self-attention mechanism, abbreviated as TTSNet. The model first uses exponential smoothing to reduce noise, then captures both global degradation information and detailed features based on a three-branch network of transformer encoders, TCN, and multi-head attention and highlights the contribution of different features to the model. The three types of features are processed through linear layers and concatenated, followed by a fully connected layer to establish the mapping relationship between the feature matrix and the output RUL, obtaining the RUL prediction value and achieving the RUL prediction of aircraft engines.
5. Analysis of Experiment Results
This study uses the Pytorch deep learning framework and employs the Adam optimizer to optimize network parameters. During model training, Mean Squared Error (MSE) is used as the loss function to guide optimization. The learning rate of the optimizer directly affects the training speed and convergence performance of the model. Therefore, to make the network more stable and efficient during training, a linear learning rate adjustment strategy is adopted, with the initial learning rate set to 0.001 and gradually decaying to 0.0001.
Experiments were conducted on FD001–FD004 to test the model’s performance. To obtain suitable hyperparameters, 10-fold cross-validation is performed on the training set. The training set is divided into 10 parts based on the engine ID, and one part is selected as the validation set each time. After 10 experiments, the average RMSE of the validation set is calculated and then the hyperparameters corresponding to the lowest metric are searched for. The hyperparameters of model are set as shown in
Table 4. After training the model on the training set, its performance is tested on the test set. To prevent random errors in the experiments, five experiments are conducted under the same conditions for testing.
5.1. Impact of Window Size
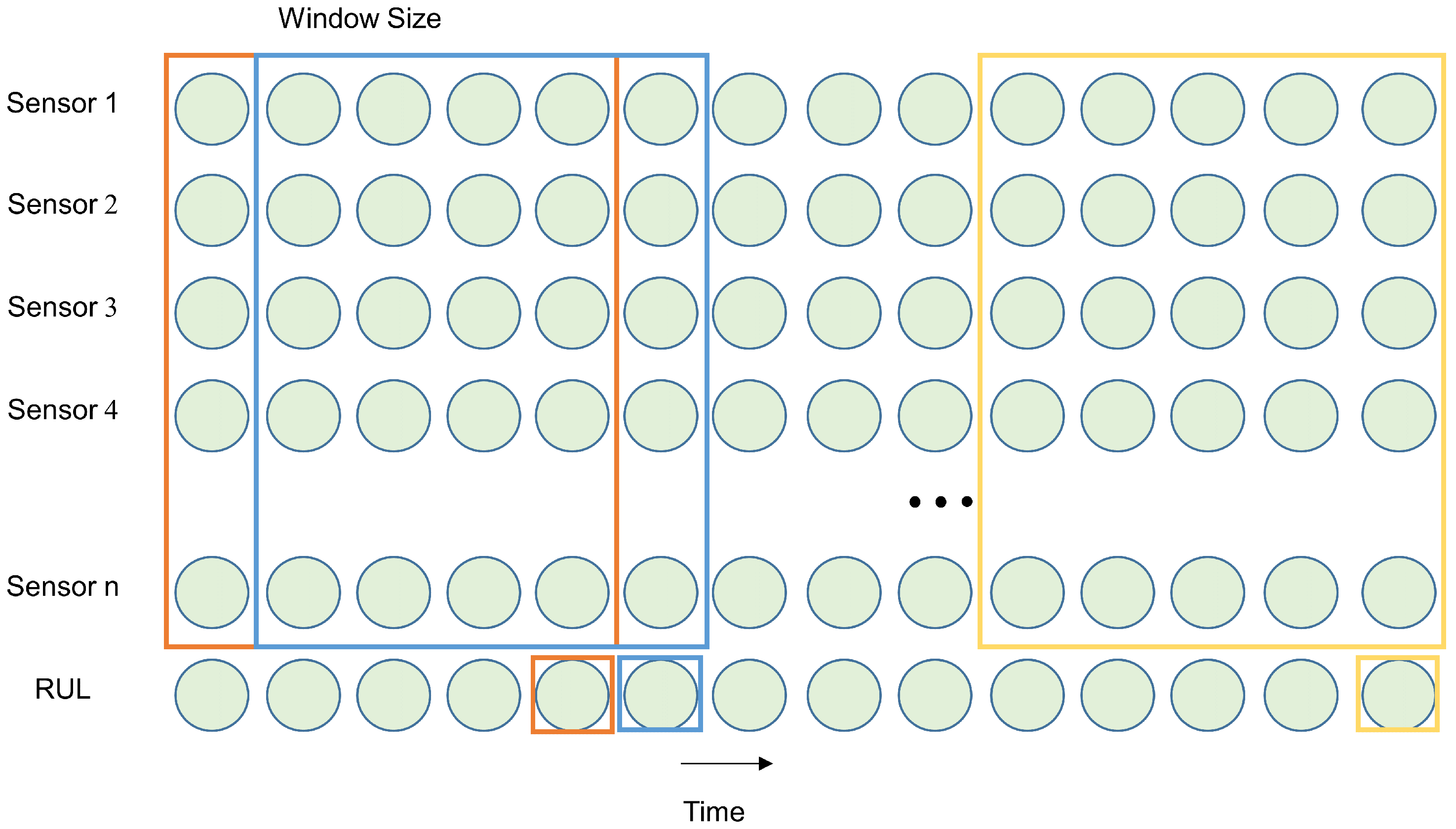
A smaller time window results in fewer degradation information contained in the data samples. A larger time window contains more degradation information. Experiments were conducted to study the impact of different window widths on the model’s predictive capability. In the experiments, the range of the window width was set from 20 to 60, with a step size of 10. The experimental results are shown in
Figure 11. As can be seen from
Figure 11, in the FD001 dataset, the RMSE and Score are minimized when the window size is 30. In the FD002 dataset, the RMSE and Score are minimized when the window size is 60. In the FD003 dataset, the RMSE and Score are optimal overall when the window size is 40. In the FD004 dataset, the RMSE and Score are minimized when the window size is 50. Compared to single-condition datasets, multi-condition datasets have a larger window width. This is because multi-condition datasets are more complex and the model requires more degradation information.
5.2. Comparison Experiments
To verify the effectiveness of the proposed method, the results of the proposed method in this paper were compared with the prediction methods proposed in the existing literature [
28,
30,
31,
32,
33,
34,
35,
36,
37,
38]. The comparison results are shown in
Table 5. The RMSE of the proposed method is lower than other methods on FD001, FD002, and FD003, and the scores on four subsets are lower than those of DCNN, AGCNN, Attention+TCN, SCTA-LSTM, TATFA-Transformer, and DBA-DCRN methods. On dataset FD001, the RMSE of the proposed method is improved by 0.18% compared to [
38], but the Score of the proposed method is higher compared to [
30]. On the FD002 dataset, the RMSE of the proposed method improves by 10.1% compared to [
30]; the Score of the proposed method is improved by 4.37% compared to [
30]. On dataset FD003, the RMSE of the proposed method is improved by 1.5% compared to [
37]. On the FD004 dataset, the RMSE of the proposed method improves by 2.9% compared to [
37], but its prediction capability is inferior to that of ATCN and MLEAN.
Figure 12 shows the comparison of RUL prediction results of the proposed method on the test sets of four subsets. The predicted values of the engines are distributed near the true values, and the prediction curve fits the true curve well. Although the prediction is poor for individual engines, the overall prediction accuracy of the model is high.
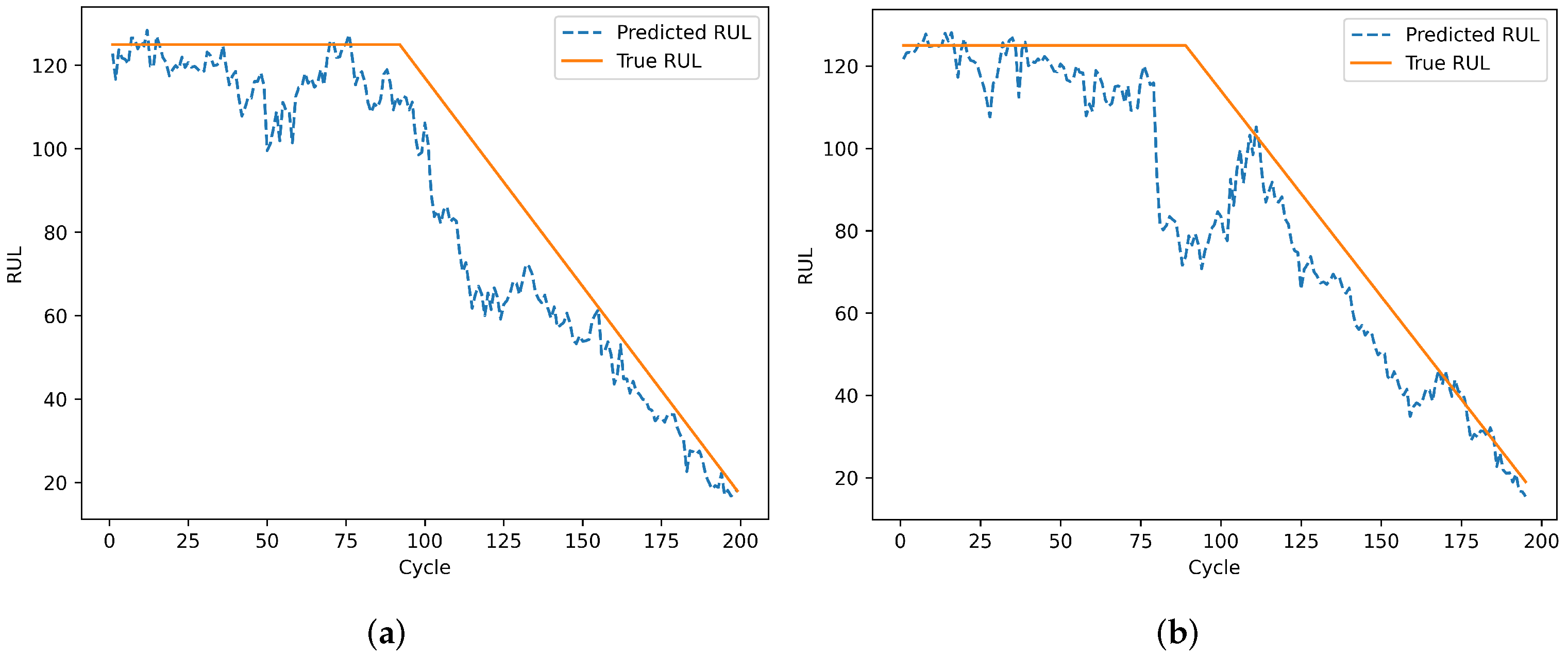
To evaluate the model’s prediction results on individual engines, engines 24 and 76 from the test set of dataset FD001 and engines 1 and 185 from the test set of dataset FD002 were selected. Engines 78 and 79 from the test set of dataset FD003, and engines 135 and 213 from the test set of dataset FD004 were also selected. The remaining useful life prediction results are shown in
Figure 13,
Figure 14,
Figure 15 and
Figure 16. From
Figure 13 and
Figure 15, although the model prediction curves exhibit some fluctuations, the overall fit between the predicted values and the true values is high. As the number of engine cycles increases and more degradation information accumulates, the model’s prediction results improve. From
Figure 14 and
Figure 16, compared to FD001 and FD003, the engine prediction curves for FD002 and FD004 show significant fluctuations and poor fitting. The reason is that FD002 and FD004 have multiple operating conditions, making the data more complex, and the model’s extracted features are insufficient. During the degradation phase before a fault occurs, the model’s predicted values are lower than the true operating state values of the engines, enabling the early prediction of the remaining useful life of aero-engines, which has practical predictive value.
5.3. Ablation Experiments
To further evaluate the effectiveness of the model designed in this paper, ablation experiments were conducted on four subsets to verify the effectiveness of the ES denoising module, multi-head attention, transformer encoder, and TCN module in RUL prediction. The experimental results are shown in
Table 6.
To objectively measure the predictive capability of the model in this study, all prediction models used the same input and fully connected layers. Five models were employed to conduct a comparative analysis of the experimental data. Under the same hyperparameters, the RMSE and Score metrics of the proposed method generally outperformed the other four methods.
The results indicate that the proposed method inherits the strengths of the TCN and transformer models and significantly improves the performance of the RUL model. Comparing the proposed method with the model without TCN, the RMSE and Score of the model on four subsets were better, indicating that the addition of TCN enhances the model’s ability to extract local features. Comparing the proposed method with the model without the transformer encoder, the RMSE and Score on four subsets were better, indicating that the addition of the transformer encoder enhances the model’s ability to extract global features. Comparing the proposed method with the model without the ES module, it was found that the inclusion of the ES denoising module reduced both the RMSE and Score. This result indicates that the ES module can effectively reduce the impact of noise on model prediction. Additionally, when multi-head attention was added, the model’s performance significantly improved. Although the Score deteriorates in FD001, FD002, and FD004, the RMSE decreases in all cases. This demonstrates that self-attention plays a crucial role in distinguishing the contributions of different sensors. In summary, the ES and multi-head attention modules, transformer encoder, and TCN all play important roles in the model of RUL prediction.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}