



Event-Trigger Reinforcement Learning-Based Coordinate Control of Modular Unmanned System via Nonzero-Sum Game

Abstract
1. Introduction
2. Background and Related Work
2.1. Reinforcement Learning
2.2. Nonzero-Sum Game
3. Dynamic Model
- (1)
- The lumped joint friction
- (2)
- The interconnected dynamic coupling
4. Event-Trigger Reinforcement Learning-Based Coordinate Control via Nonzero-Sum Game
4.1. Problem Transformation
4.2. Event-Trigger Reinforcement Learning-Based Coordinate Control
- Case 1:
- The events are not triggered, i.e., .
- Case 2:
- When events are triggered, , the difference of (36) is rewritten as
4.3. Exclusion of Zeno Behaviors
5. Experiment
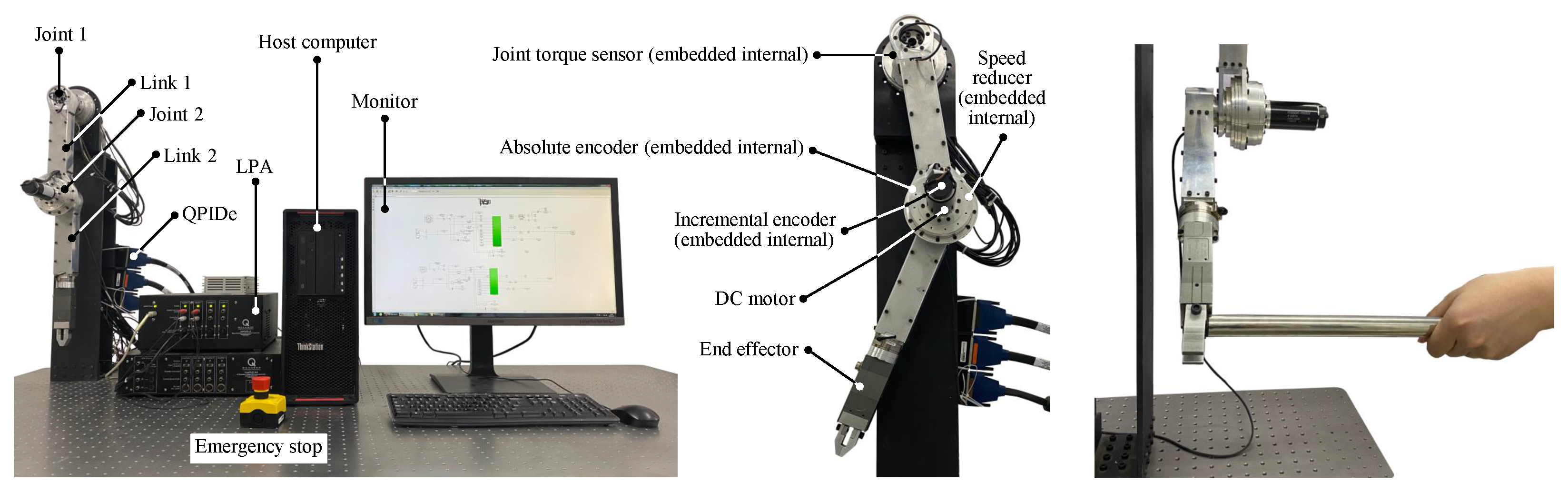
5.1. Experimental Setup
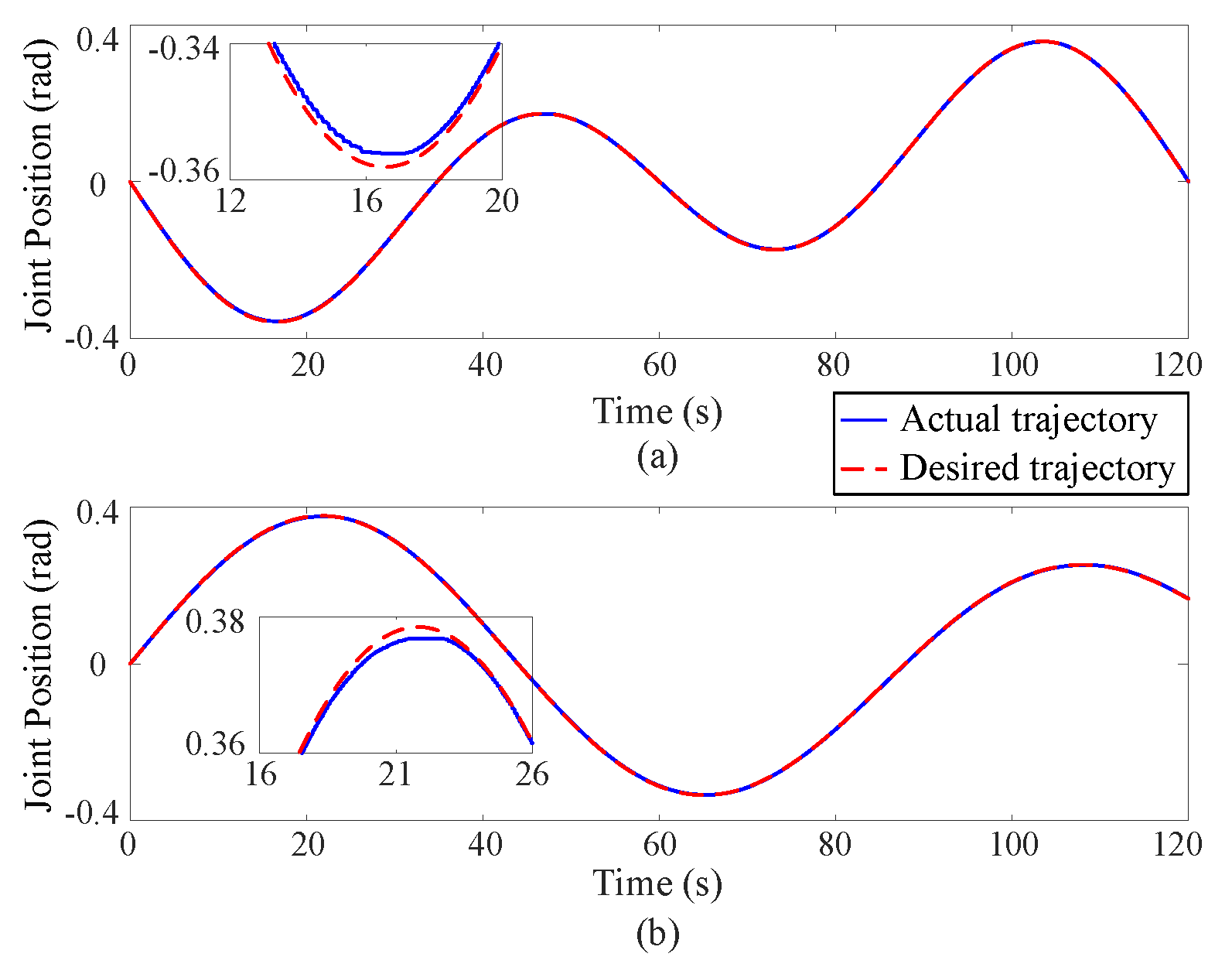
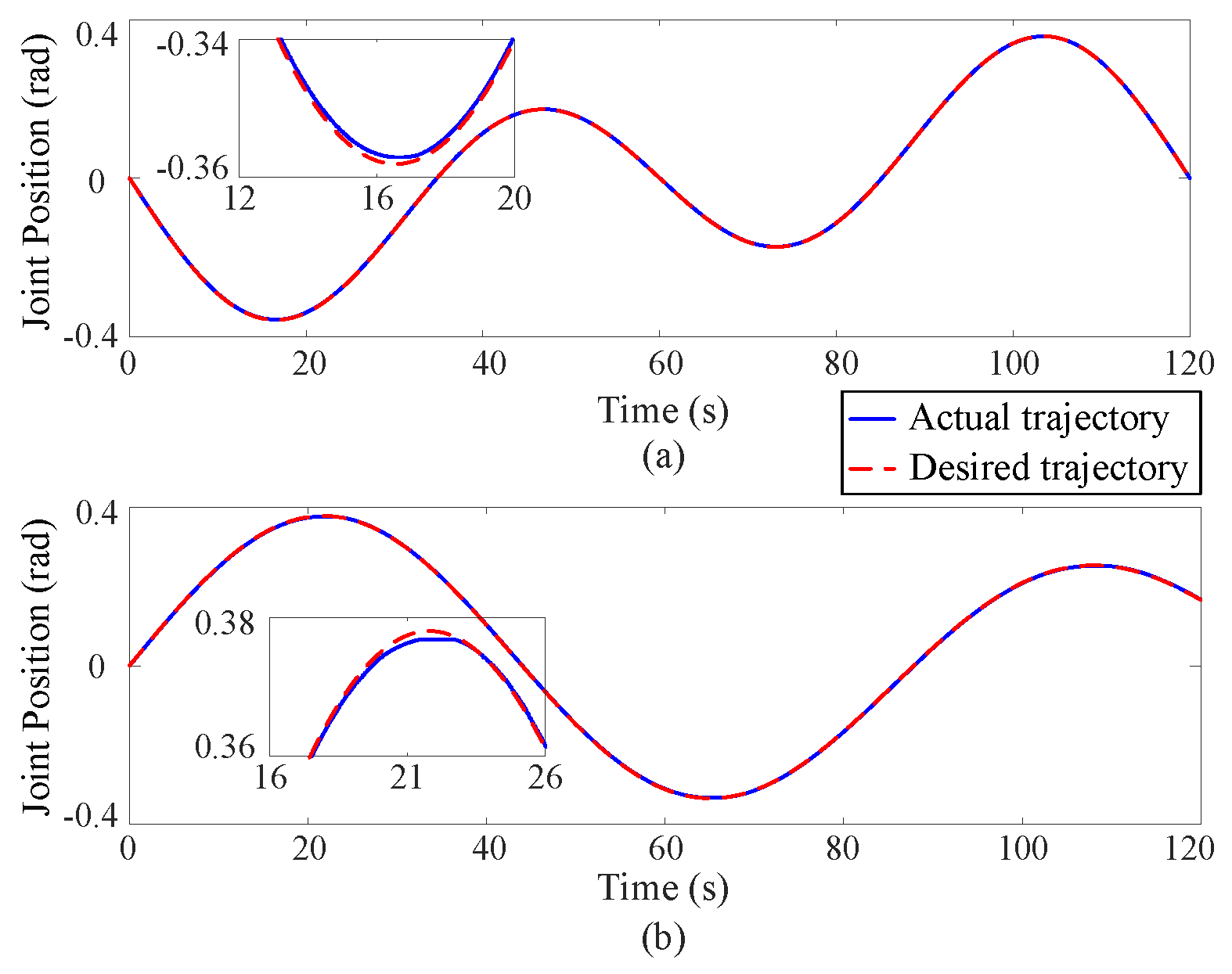
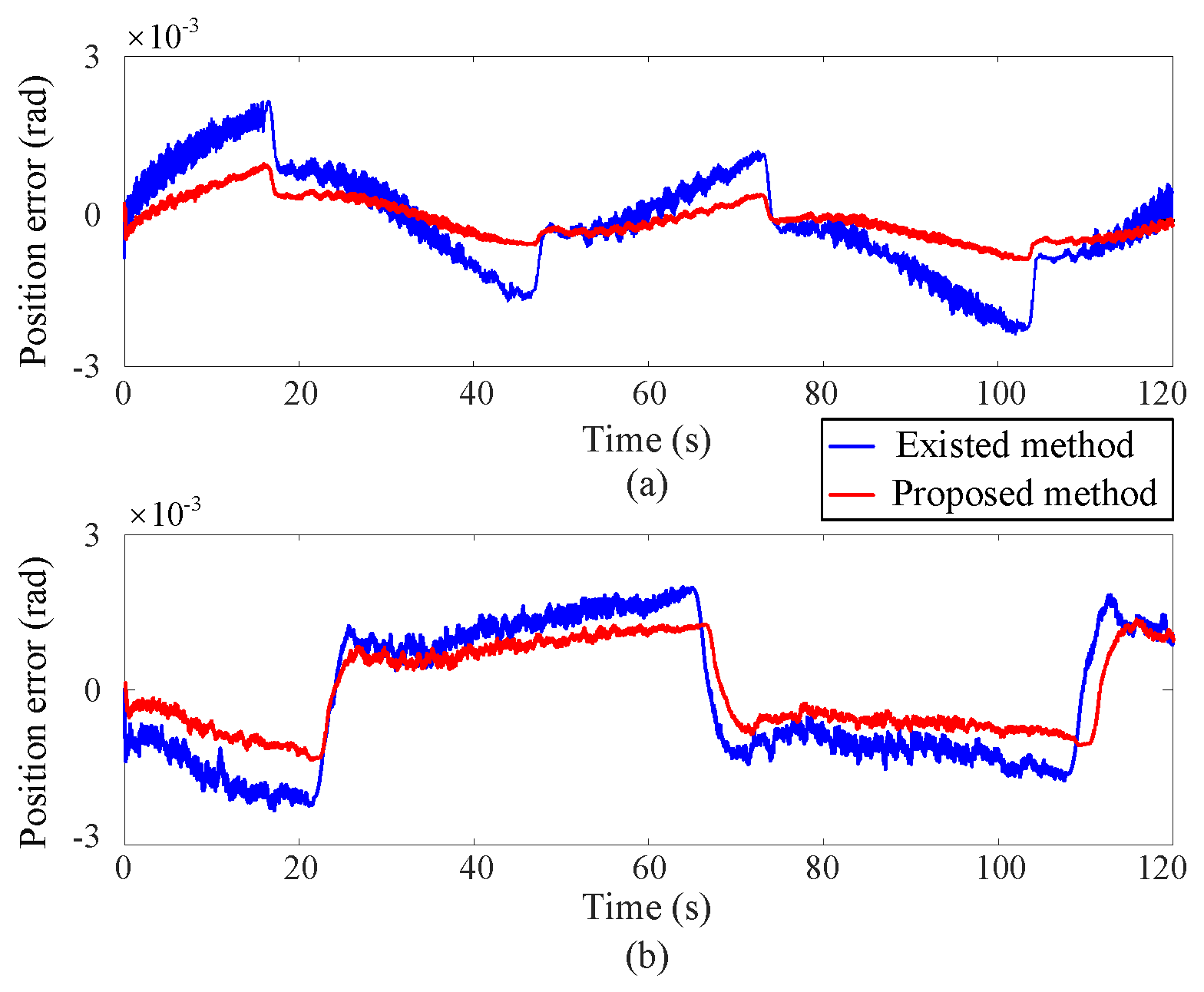
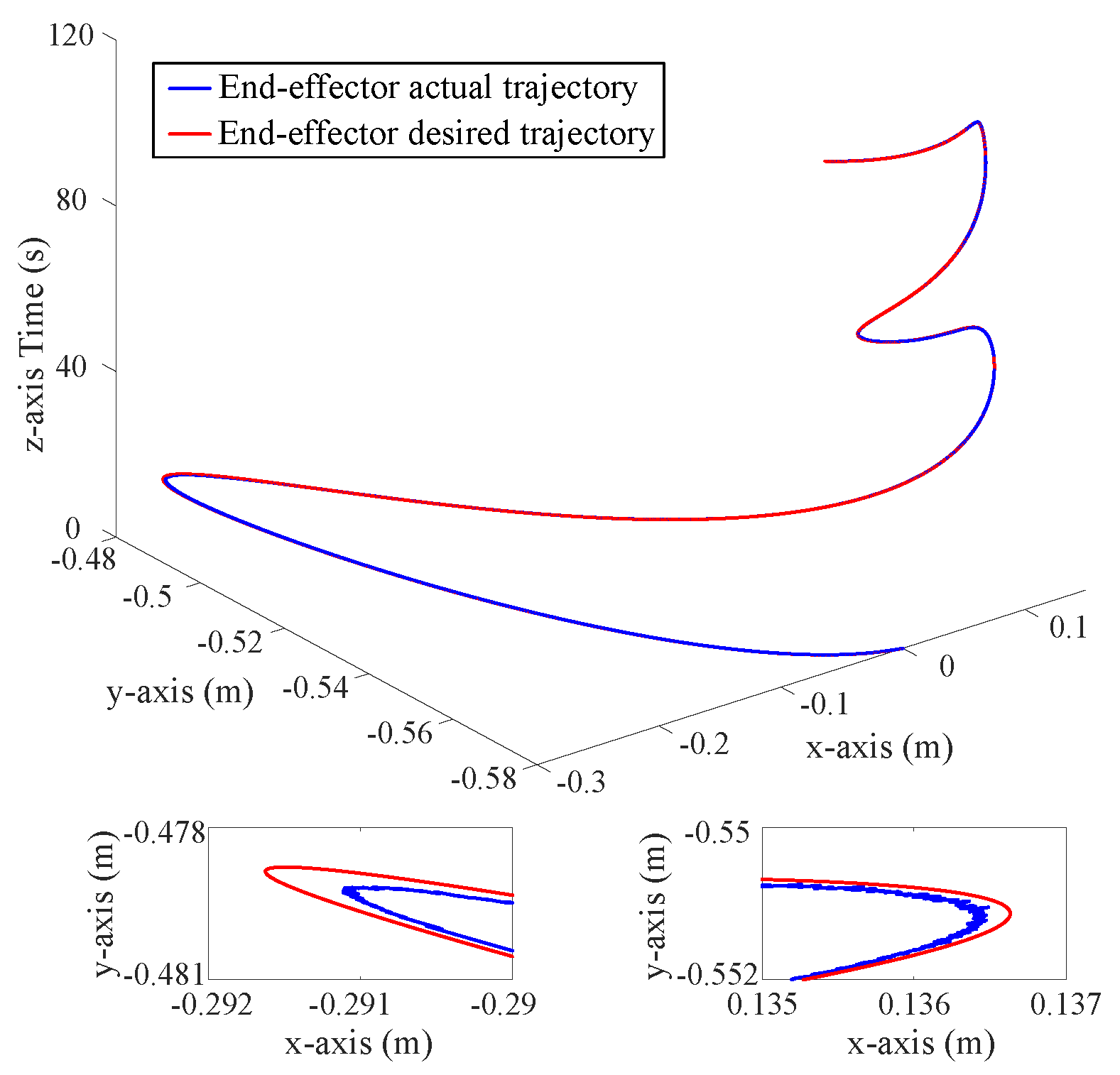
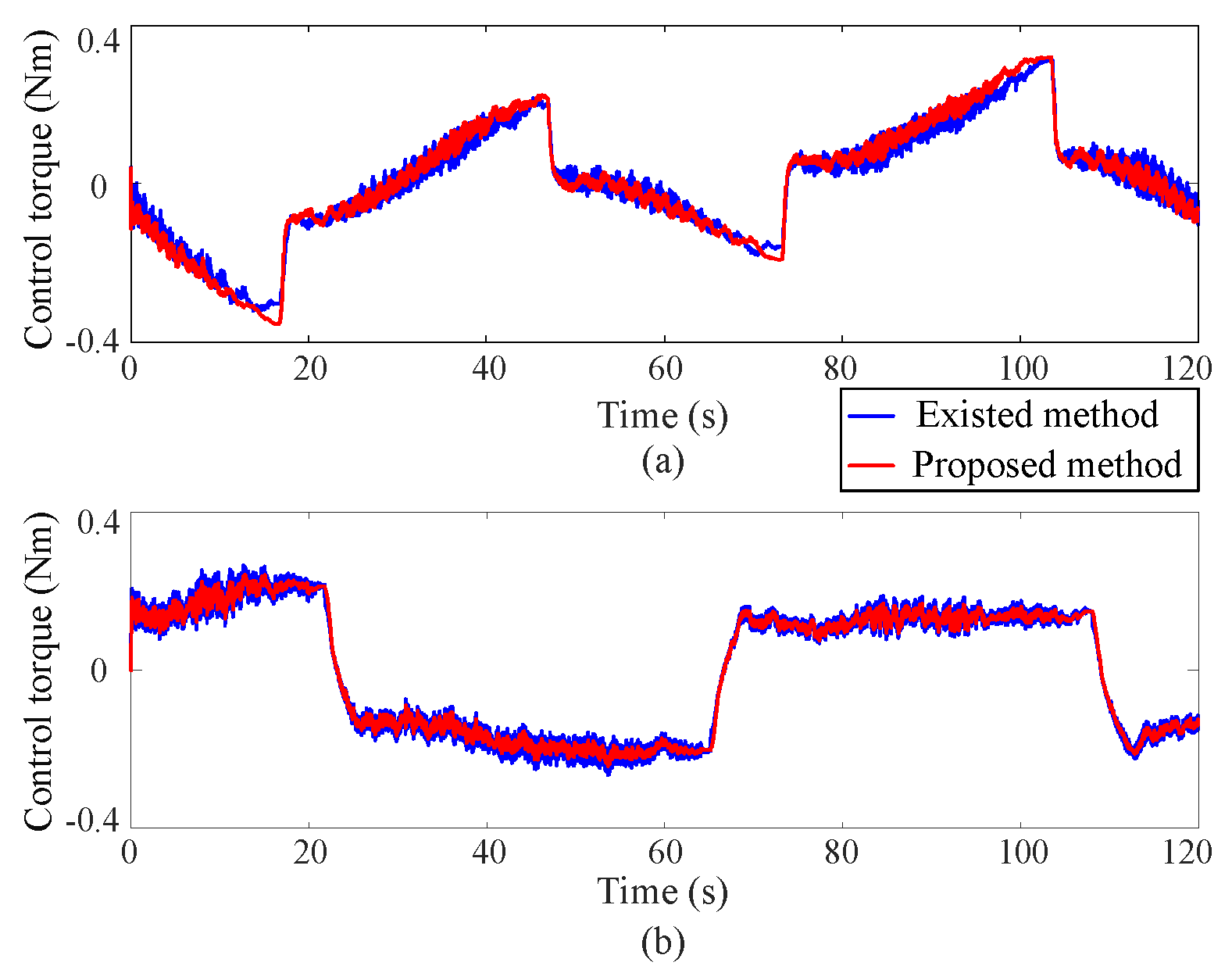
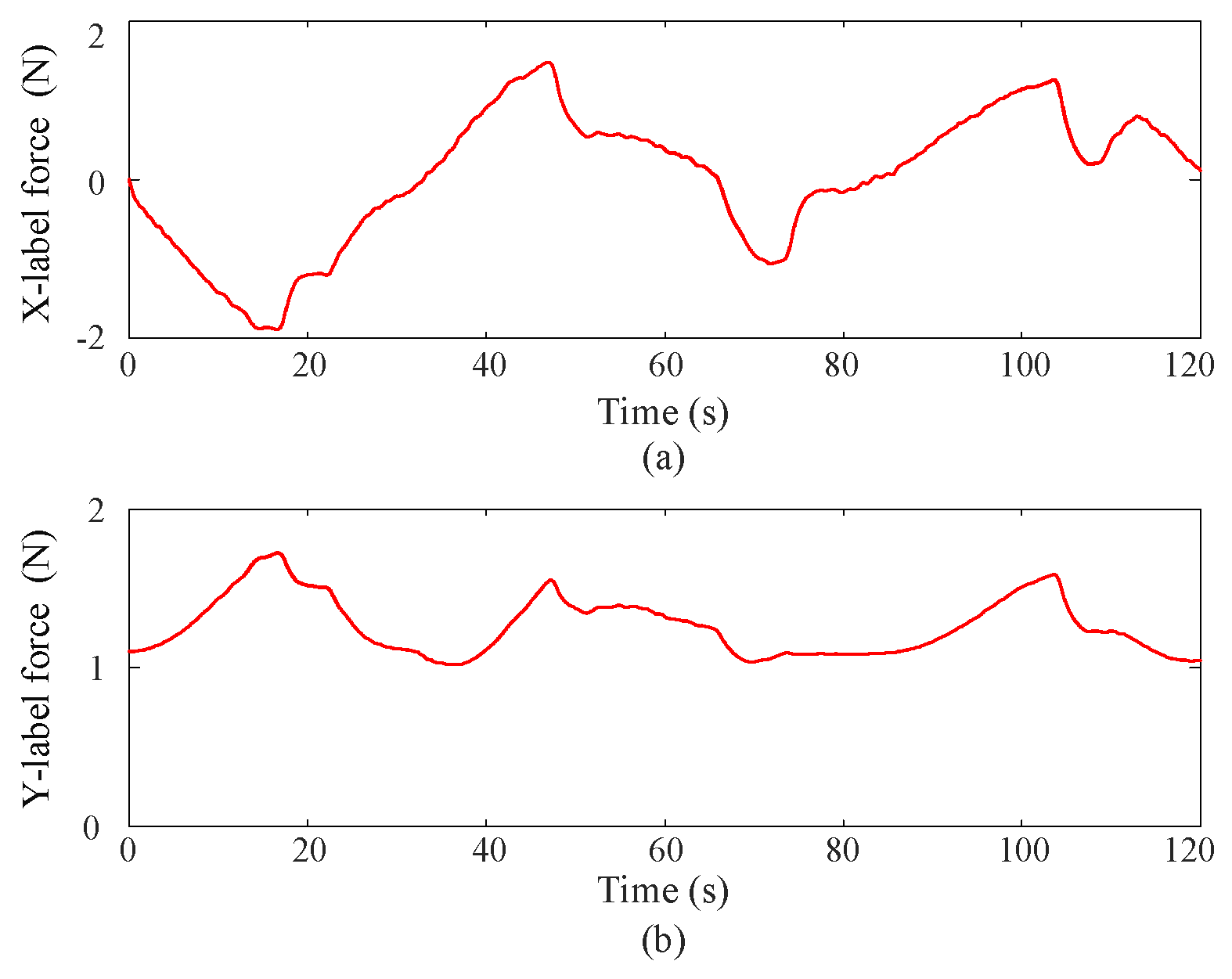
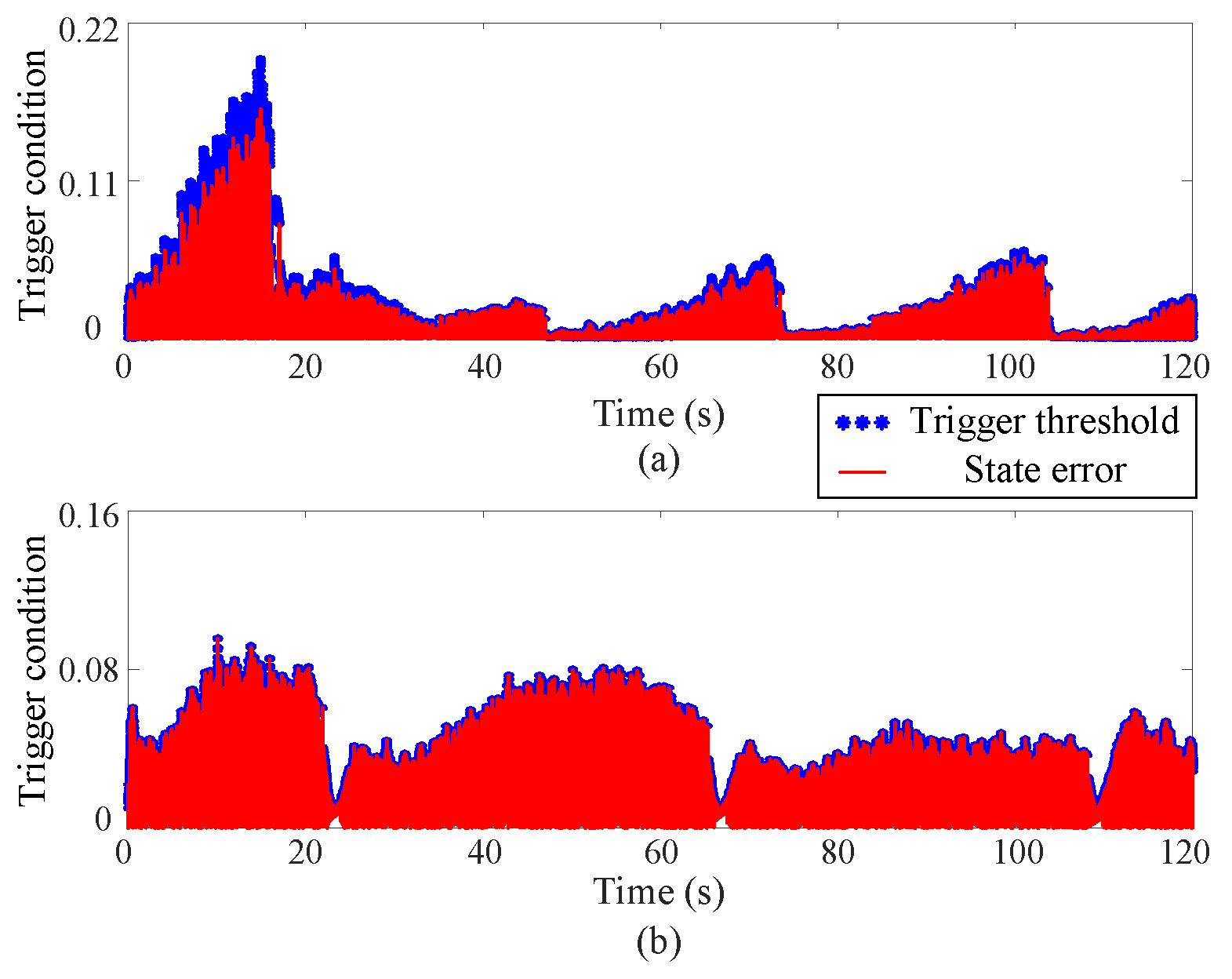
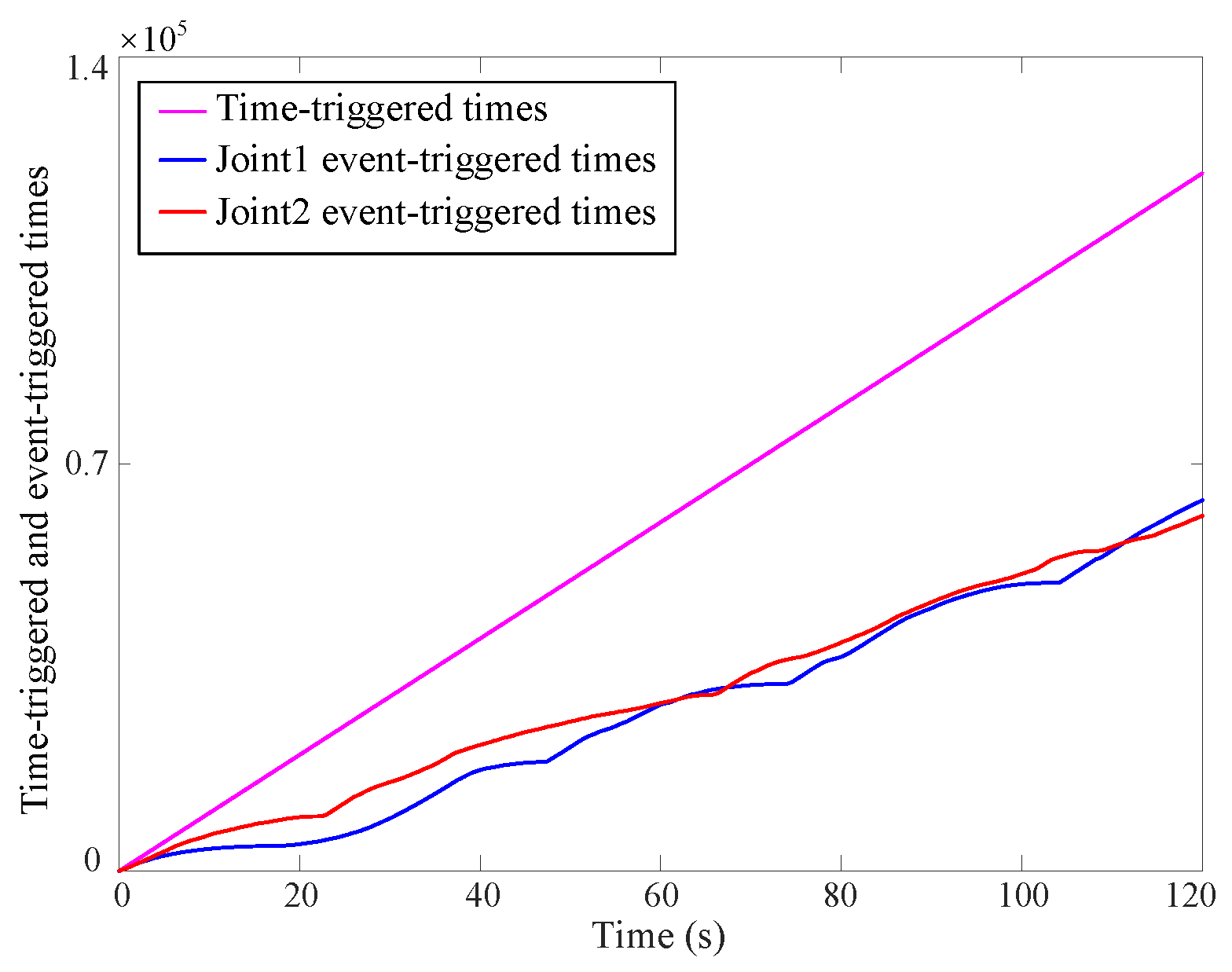
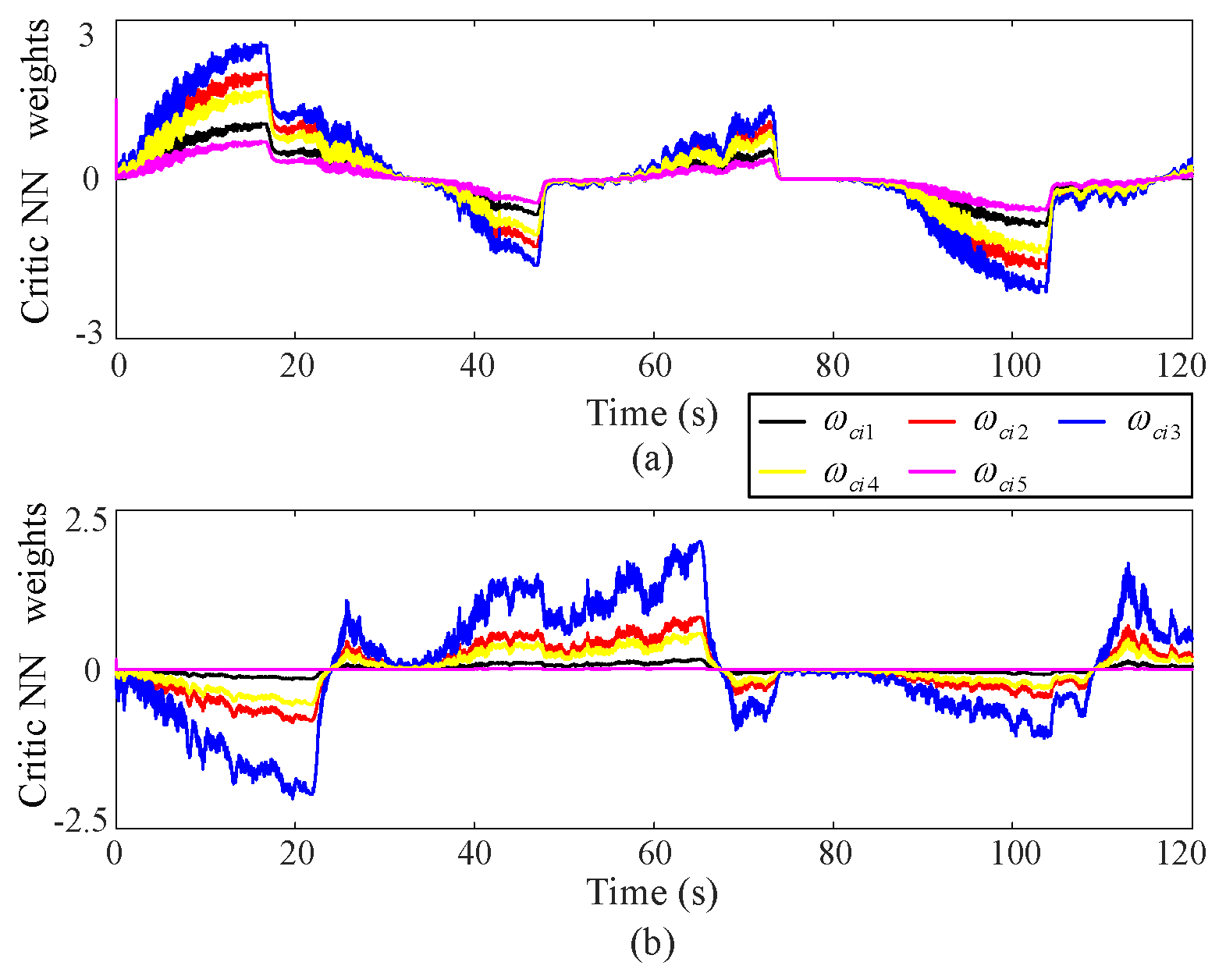
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirano, D.; Inazawa, M.; Sutoh, M.; Sawada, H.; Kawai, Y.; Nagata, M.; Sakoda, G.; Yoneda, Y.; Watanabe, K. Transformable Nano Rover for Space Exploration. IEEE Robot. Autom. Lett. 2024, 9, 3139–3146. [Google Scholar] [CrossRef]
- Kedia, R.; Goel, S.; Balakrishnan, M.; Paul, K.; Sen, R. Design Space Exploration of FPGA-Based System With Multiple DNN Accelerators. IEEE Embed. Syst. Lett. 2021, 13, 114–117. [Google Scholar] [CrossRef]
- Goyal, M.; Dewaskar, M.; Duggirala, P.S. NExG: Provable and Guided State-Space Exploration of Neural Network Control Systems Using Sensitivity Approximation. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 4265–4276. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Ajib, W.; Assi, C. A Novel Cooperative NOMA for Designing UAV-Assisted Wireless Backhaul Networks. IEEE J. Sel. Areas Commun. 2018, 36, 2497–2507. [Google Scholar] [CrossRef]
- Cheng, X.; Jiang, R.; Sang, H.; Li, G.; He, B. Joint Optimization of Multi-UAV Deployment and User Association Via Deep Reinforcement Learning for Long-Term Communication Coverage. IEEE Trans. Instrum. Meas. 2024, 73, 5503613. [Google Scholar] [CrossRef]
- Xue, S.; Luo, B.; Liu, D.; Yang, Y. Constrained Event-Triggered H∞ Control Based on Adaptive Dynamic Programming With Concurrent Learning. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 357–369. [Google Scholar] [CrossRef]
- Yang, X.; Xu, M.; Wei, Q. Adaptive Dynamic Programming for Nonlinear-Constrained H∞ Control. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4393–4403. [Google Scholar] [CrossRef]
- Renga, D.; Spoturno, F.; Meo, M. Reinforcement Learning for charging scheduling in a renewable powered Battery Swapping Station. IEEE Trans. Veh. Technol. 2024, 73, 14382–14398. [Google Scholar] [CrossRef]
- Lv, Y.; Wu, Z.; Zhao, X. Data-Based Optimal Microgrid Management for Energy Trading With Integral Q-Learning Scheme. IEEE Internet Things J. 2023, 10, 16183–16193. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, H.; Yan, Y.; Xu, S.; Fan, X. Optimal Regulation Strategy for Nonzero-Sum Games of the Immune System Using Adaptive Dynamic Programming. IEEE Trans. Cybern. 2023, 53, 1475–1484. [Google Scholar] [CrossRef]
- Sun, J.; Dai, J.; Zhang, H.; Yu, S.; Xu, S.; Wang, J. Neural-Network-Based Immune Optimization Regulation Using Adaptive Dynamic Programming. IEEE Trans. Cybern. 2023, 53, 1944–1953. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Gao, N.; Liu, D.; Li, J.; Lewis, F.L. Recent Progress in Reinforcement Learning and Adaptive Dynamic Programming for Advanced Control Applications. IEEE/CAA J. Autom. Sin. 2024, 11, 18–36. [Google Scholar] [CrossRef]
- Lv, Y.; Chang, H.; Zhao, J. Online Adaptive Integral Reinforcement Learning for Nonlinear Multi-Input System. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 4176–4180. [Google Scholar] [CrossRef]
- Na, J.; Lv, Y.; Zhang, K.; Zhao, J. Adaptive Identifier-Critic-Based Optimal Tracking Control for Nonlinear Systems With Experimental Validation. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 459–472. [Google Scholar] [CrossRef]
- Jin, P.; Ma, Q.; Lewis, F.L.; Xu, S. Robust Optimal Output Regulation for Nonlinear Systems With Unknown Parameters. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 4908–4917. [Google Scholar] [CrossRef]
- Jin, P.; Ma, Q.; Gu, J. Fixed-Time Practical Anti-Saturation Attitude Tracking Control of QUAV with Prescribed Performance: Theory and Experiments. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 6050–6060. [Google Scholar] [CrossRef]
- An, T.; Wang, Y.; Liu, G.; Li, Y.; Dong, B. Cooperative Game-Based Approximate Optimal Control of Modular Robot Manipulators for Human–Robot Collaboration. IEEE Trans. Cybern. 2023, 53, 4691–4703. [Google Scholar] [CrossRef]
- Sahabandu, D.; Moothedath, S.; Allen, J.; Bushnell, L.; Lee, W.; Poovendran, R. RL-ARNE: A Reinforcement Learning Algorithm for Computing Average Reward Nash Equilibrium of Nonzero-Sum Stochastic Games. IEEE Trans. Autom. Control 2024, 69, 7824–7831. [Google Scholar] [CrossRef]
- Zhao, B.; Shi, G.; Liu, D. Event-Triggered Local Control for Nonlinear Interconnected Systems Through Particle Swarm Optimization-Based Adaptive Dynamic Programming. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 7342–7353. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, B.; Liu, D.; Zhang, S. Distributed Fault Tolerant Consensus Control of Nonlinear Multiagent Systems via Adaptive Dynamic Programming. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 9041–9053. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, B.; Liu, D.; Zhang, S. Event-Triggered Control of Discrete-Time Zero-Sum Games via Deterministic Policy Gradient Adaptive Dynamic Programming. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4823–4835. [Google Scholar] [CrossRef]
- Ye, J.; Dong, H.; Bian, Y.; Qin, H.; Zhao, X. ADP-Based Optimal Control for Discrete-Time Systems With Safe Constraints and Disturbances. IEEE Trans. Autom. Sci. Eng. 2024; early access. [Google Scholar] [CrossRef]
- Song, S.; Gong, D.; Zhu, M.; Zhao, Y.; Huang, C. Data-Driven Optimal Tracking Control for Discrete-Time Nonlinear Systems With Unknown Dynamics Using Deterministic ADP. IEEE Trans. Neural Netw. Learn. Syst. 2023; early access. [Google Scholar] [CrossRef] [PubMed]
- Mu, C.; Wang, K.; Xu, X.; Sun, C. Safe Adaptive Dynamic Programming for Multiplayer Systems With Static and Moving No-Entry Regions. IEEE Trans. Artif. Intell. 2024, 5, 2079–2092. [Google Scholar] [CrossRef]
- Xiao, G.; Zhang, H. Convergence Analysis of Value Iteration Adaptive Dynamic Programming for Continuous-Time Nonlinear Systems. IEEE Trans. Cybern. 2024, 54, 1639–1649. [Google Scholar] [CrossRef]
- Davari, M.; Gao, W.; Aghazadeh, A.; Blaabjerg, F.; Lewis, F.L. An Optimal Synchronization Control Method of PLL Utilizing Adaptive Dynamic Programming to Synchronize Inverter-Based Resources With Unbalanced, Low-Inertia, and Very Weak Grids. IEEE Trans. Autom. Sci. Eng. 2024; early access. [Google Scholar] [CrossRef]
- Wei, Q.; Li, T. Constrained-Cost Adaptive Dynamic Programming for Optimal Control of Discrete-Time Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 3251–3264. [Google Scholar] [CrossRef]
- Lin, M.; Zhao, B. Policy Optimization Adaptive Dynamic Programming for Optimal Control of Input-Affine Discrete-Time Nonlinear Systems. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4339–4350. [Google Scholar] [CrossRef]
- Mu, C.; Wang, K.; Ni, Z. Adaptive Learning and Sampled-Control for Nonlinear Game Systems Using Dynamic Event-Triggering Strategy. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4437–4450. [Google Scholar] [CrossRef]
- Vamvoudakis, K.; Kokolakis, N. Synchronous Reinforcement Learning-Based Control for Cognitive Autonomy. Found. Trends Syst. Control 2020, 8, 1–175. [Google Scholar] [CrossRef]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive Dynamic Programming for Control: A Survey and Recent Advances. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Dong, B.; Zhu, X.; An, T.; Jiang, H.; Ma, B. Barrier-critic-disturbance Approximate Optimal Control of Nonzero-sum Differential Games for Modular Robot Manipulators. Neural Netw. 2025, 181, 106880. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cui, D.; Peng, W. Optimum Control for Path Tracking Problem of Vehicle Handling Inverse Dynamics. Sensors 2023, 23, 6673. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cui, D. Optimal Control of Vehicle Path Tracking Problem. World Electr. Veh. J. 2024, 15, 429. [Google Scholar] [CrossRef]
- Wu, P.; Wang, H.; Liang, G.; Zhang, P. Research on Unmanned Aerial Vehicle Cluster Collaborative Countermeasures Based on Dynamic Non-Zero-Sum Game under Asymmetric and Uncertain Information. Aerospace 2023, 10, 711. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, P.; Yuan, J. Nonzero-Sum Pursuit-Evasion Game Control for Spacecraft Systems: A Q-Learning Method. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3971–3981. [Google Scholar] [CrossRef]
- An, T.; Dong, B.; Yan, H.; Liu, L.; Ma, B. Dynamic Event-triggered Strategy-based Optimal Control of Modular Robot Manipulator: A Multiplayer Nonzero-Sum Game Perspective. IEEE Trans. Cybern. 2024, 54, 7514–7526. [Google Scholar] [CrossRef]
- Dong, B.; Gao, Y.; An, T.; Jiang, H.; Ma, B. Nonzero-sum Game-based Decentralized Approximate Optimal Control of Modular Robot Manipulators with Coordinate Operation Tasks using Value Iteration. Meas. Sci. Technol. 2024. [Google Scholar] [CrossRef]
- Liu, F.; Xiao, W.; Chen, S.; Jiang, C. Adaptive Dynamic Programming-based Multi-sensor Scheduling for Collaborative Target Tracking in Energy Harvesting Wireless Sensor Networks. Sensors 2018, 18, 4090. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Absolute Value of Position Error | Mean Absolute Value of Control Torque | |
|---|---|---|
| The existing method (Joint 1) | rad | 0.32 Nm |
| The proposed method (Joint 1) | rad | 0.29 Nm |
| The existing method (Joint 2) | rad | 0.30 Nm |
| The existing method (Joint 2) | rad | 0.26 Nm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; An, T.; Chen, J.; Zhong, L.; Qian, Y. Event-Trigger Reinforcement Learning-Based Coordinate Control of Modular Unmanned System via Nonzero-Sum Game. Sensors 2025, 25, 314. https://doi.org/10.3390/s25020314
Liu Y, An T, Chen J, Zhong L, Qian Y. Event-Trigger Reinforcement Learning-Based Coordinate Control of Modular Unmanned System via Nonzero-Sum Game. Sensors. 2025; 25(2):314. https://doi.org/10.3390/s25020314
Chicago/Turabian StyleLiu, Yebao, Tianjiao An, Jianguo Chen, Luyang Zhong, and Yuhan Qian. 2025. "Event-Trigger Reinforcement Learning-Based Coordinate Control of Modular Unmanned System via Nonzero-Sum Game" Sensors 25, no. 2: 314. https://doi.org/10.3390/s25020314
APA StyleLiu, Y., An, T., Chen, J., Zhong, L., & Qian, Y. (2025). Event-Trigger Reinforcement Learning-Based Coordinate Control of Modular Unmanned System via Nonzero-Sum Game. Sensors, 25(2), 314. https://doi.org/10.3390/s25020314