Abstract
Decreasing the position error and control torque is important for the coordinate control of a modular unmanned system with less communication burden between the sensor and the actuator. Therefore, this paper proposes event-trigger reinforcement learning (ETRL)-based coordinate control of a modular unmanned system (MUS) via the nonzero-sum game (NZSG) strategy. The dynamic model of the MUS is established via joint torque feedback (JTF) technology. Based on the NZSG strategy, the existing coordinate control problem is transformed into an RL issue. With the help of the ET mechanism, the periodic communication mechanism of the system is avoided. The ET-critic neural network (NN) is used to approximate the performance index function, thus obtaining the ETRL coordinate control policy. The stability of the closed-loop system is verified via Lyapunov’s theorem. Experiment results demonstrate the validity of the proposed method. The experimental results show that the proposed method reduces the position error by 30% and control torque by 10% compared with the existing control methods.
1. Introduction
With the rapid development of the space industry and the continuous increase in the demand for space exploration, the complexity of the environment and the precision of the control requirements faced by space operations are also constantly improving [1,2,3]. The problems of high risk and low efficiency caused by traditional astronaut operations relying on them leaving the capsule are becoming increasingly prominent. In recent years, thanks to the rapid improvement and development of unmanned systems research and development technology, the use of high-precision and -performance unmanned systems to solve the assembly and maintenance of space operations in orbit is gradually becoming a scientific value of the goal-oriented basic research topic in the field of space exploration. So far, unmanned systems operating in conventional ground environments have achieved good reliability and accuracy. However, under the high standard requirements of coordinate missions in complex space environments, traditional unmanned systems are difficult to meet the transportation requirements of launch vehicles and spacecraft due to their large volume, heavy mass, and difficulty in disassembly and assembly. However, for the space unmanned systems that are in service to overcome the above difficulties, there are still some limitations in the configuration of the mechanism, and it is difficult to change its assembly configuration and working mode according to different task requirements. The modular unmanned system (MUS) [4,5] is a kind of autonomous unmanned system with standard modules and interfaces that can reassemble and configure itself according to different task requirements. Through the reconfiguration of modules, the unmanned system can show a variety of assembly configurations to complete different tasks, thus showing advantages that traditional unmanned systems do not possess.
As an important branch of game theory, differential game [6,7] focuses on the dynamic decision-making process of continuous time systems described by differential equations. It is an ideal tool to deal with multi-participant decision making and control problems and to solve optimal strategies, and it is widely used in economics [8], management [9], computer science [10], and other fields [11,12]. Reinforcement learning [13,14] originated as an imitation of the human brain learning mechanism, reflecting the mapping of learning environment state to action, so that the system can obtain the maximum cumulative reward from the environment and then optimize the system performance through the optimal strategy selection. In recent years, it has been widely used in complex nonlinear differential games because it can effectively solve the problem of “dimensionality disaster” in traditional dynamic programming [15,16]. As a kind of game, the nonzero-sum game (NZSG) [17,18] needs to solve the corresponding coupled Hamilton–Jacobi (HJ) equation for each player in order to obtain its Nash equilibrium solution.
As an important part of modern control theory, the core problem of optimal control is to select control strategies to make some performance indexes of a given controlled system optimal. For a large number of nonlinear systems in practical engineering, to obtain the optimal control strategy, it is necessary to solve the HJ(-Bellman) (HJB) equation, which is a class of nonlinear partial differential equation, and it is difficult to obtain the optimal solution by analytical methods. The reinforcement learning method is a powerful tool to solve the optimal control problem of nonlinear systems. In reinforcement learning systems, a neural network (NN) [19,20] is designed to approximate the performance index function and estimate the solution of the HJ(B) equation. Due to its strong advantages in solving nonlinear optimal control, reinforcement learning has attracted extensive attention from scholars both domestic and abroad in recent years, and has made rich achievements in solving problems such as discrete time optimal control [21,22,23], continuous time optimal control [24,25,26], and data-driven optimal control [27,28,29] of complex nonlinear systems. However, these results are based on periodic sampling or event triggering, resulting in a waste of resources and high computational costs.
Motivated by the above, this paper develops event-trigger (ET) reinforcement learning (ETRL)-based coordinate control of MUS via the NZSG strategy. The main contributions of this paper are mainly the following two aspects:
1. To the best of the authors’ knowledge, it is the first time to introduce the NZSG via reinforcement learning applied to an MUS. By considering the control torque of n modules in the MUS as decision-makers, the optimal control problem for the MUS system is morphed into an NZSG issue with n players.
2. The stability of the developed method is guaranteed and the experiment on MUS is conducted. Through the experimental results, we can conclude that the proposed method produces less tracking errors and power consumption.
2. Background and Related Work
2.1. Reinforcement Learning
Optimal control is widely utilized and holds great importance in many areas. However, with the increase in the system’s dimension, the issue of the dimensionality curse has appeared. Reinforcement learning, as an effective solution to the dimensionality curse in optimal control, has emerged as a crucial approach for addressing approximate optimal control issues. Vamvoudakis et al. [30] published a book about RL-based control for cognitive autonomy. Wang et al. [12] developed a review in the field of RL for advanced control applications. Liu and Xue et al. [31] concluded the RL with applications in control. The above three papers are all surveys about the RL or adaptive dynamic programming. The proposed method in this paper deals with the coordinate control of an modular unmanned system that is a specific application environment using RL. Dong et al. [32] proposed safe RL for the sake of trajectory tracking for a modular robot system. Event-trigger is not mentioned, as it causes computation and communication burdens. An et al. [17] designed a cooperative game-based RL method for human–robot interaction. Liu et al. [33] used the RL control method to deal with the vehicle path tracking issue. The particle swarm optimization method is utilized in the vehicle path tracking issue [34]. However, the above methods only consider a single controller to guarantee optimality. The modern industry needs more than one player/controller to finish the task using other player’s information. Hence, the developed nonzero-sum game has great importance.
2.2. Nonzero-Sum Game
Differential game theory focuses on the dynamic decision-making process in multi-player interactive systems and with advantages in dealing with uncertain interaction and disturbance. Differential games include the zero-sum game, nonzero-sum game, cooperative game, etc. Each module in the MUS system functions as a participant in NZSG, each with its own policy, collectively operating within the group using a general quadratic performance index function as the basis for the game. Wu et al. [35] proposed NZSG for an unmanned aerial vehicle with uncertain as well as asymmetric information. Coordinate control is not considered. Zheng et al. [36] developed a Q-learning-based NZSG for spacecraft system under a pursuit–evasion condition. The above method is based on a time-triggered mechanism. Besides optimum, the communication burden between the sensor and actuator needs to be considered. Therefore, an event-trigger has been developed to decrease the quantity of sampling. An et al. [37] used a dynamic event-trigger to complete a robot’s tracking task via NZSG. Dong et al. [38] proposed event-trigger value iteration RL for a coordinated task under the framework of NZSG. The above methods are only applied on robots; thus, they are unsuitable for modular unmanned systems.
3. Dynamic Model
For an MUS employing the JTF technique, the dynamic model of the ith subsystem is presented below:
where f is the contact force between the MUS and object; means lumped joint friction; indicates the gear ratio; reflects joint position; represents coupled joint torque; is the IDC effect among MUS subsystems; indicates control torque; and subscript i is ith joint module subsystem. The property analyses are described below:
- (1)
- The lumped joint friction
The joint friction term is formulated as
in which
where is the position dependency friction term; are viscous and Stribect friction effects; and are static and Coulomb friction parameters. Furthermore, and are the estimated values.
Remark 1.
The variables are bounded, and their corresponding estimates also possess boundedness. Consequently, this ensures that the variable is bounded, as indicated by , where represents a known positive constant for each m in (1,2,3,4). Consequently, can be derived, which is designated as . Additionally, , in which is a known positive constant.
- (2)
- The interconnected dynamic coupling
The IDC is expressible as a nonlinear function of the coupled vectors of the entire modular subsystem in this way:
in which denote the unit vectors along with the ith, jth, and kth joint rotation axes, respectively. Consequently, define and . We also have the relation that and , in which represent the estimated values of , and are alignment errors.
Remark 2.
Based on (4), which characterizes , it is inferred that the magnitudes of the associated vector products are bounded, where and . Additionally, our findings indicate that is bounded and the up-bound is given as with a positive constant.
Define state vector and the control input . The state space of the ith subsystem is
where
Control objectives aim to ensure optimal tracking error performance for the MUS in coordinate control. Within the subsequent section, we introduce an event-trigger reinforcement learning-based coordinate control via nonzero-sum game framework.
4. Event-Trigger Reinforcement Learning-Based Coordinate Control via Nonzero-Sum Game
4.1. Problem Transformation
Based on the dynamic model (1) and state space (5), the control object of this paper is completing optimal trajectory tracking. Therefore, to facilitate designing the controller, the augmenting subsystem is deduced:
where is global state of the MUS, in which the vectors are given by and . Moreover, , , where .
Define the cost function:
where position error is and velocity error vector ; means fusion error; represent the determined reference vectors; denote determined positive definite matrices; and indicates the utility function. Employing the infinitesimal version of (8), the Hamiltonian function can be derived:
where is the partial derivative of , . Additionally, the optimal value function can be described as
Based on the stationary condition , the local optimal control policy is defined as
By substituting (8) and (11) into the Hamiltonian function (9), the coupled Hamilton–Jacobi (HJ) equation can be derived:
It is hard to obtain an analytical solution because of the nonlinearity system. Therefore, an event-trigger reinforcement learning-based coordinate control is introduced.
4.2. Event-Trigger Reinforcement Learning-Based Coordinate Control
The optimal control policy (11) is addressed from periodic sampling as well as the coupled HJ equation (12). Fixed sampling control not only escalates computational demands but also excessively taps into communication resources, jeopardizing the timeliness of control in environments with constrained bandwidth. Therefore, an event-triggered strategy is introduced to optimize efficiency.
Set a series of monotonously increasing , which contains trigger instants . Then, define the sampling state
where denotes triggering instant state for . To obtain the trigger condition, the subsequent gap function is introduced:
Upon event triggering, based on (13), the actual state undergoes sampling to become the sampled state, after which is reset to zero. The optimal control law is updated to during , . It should be noted that are discrete values updated irregularly, necessitating conversion to continuous values. Therefore, a zero-order holder is derived to cope with this issue.
According to the dynamic model of MUS (7), one gives the event-trigger value function as follows:
One has the event-triggered HJ equation:
where is the partial derivative of with regard to . To eliminate the assumption of norm-boundness regarding interconnections, the desired states of coupled subsystems are used as a replacement for their actual states. Consequently, the interconnection term is depicted:
where is the desired state of coupled subsystems for and represents the substitution error. Given the interconnection’s compliance with the global Lipschitz condition, this indicates
where and denotes an unknown global Lipschitz constant.
The improved event-triggered optimal value function is
Through the substitution of (19) into (16), it can be inferred that
Based on (21), one has the event-triggered optimal control law
For any , the control law is Lipschitz continuous. Then, one has a constant satisfying
Given the challenging nature of solving the coupled HJ equation and the curse of dimensionality that arises with increasing dimensions, we employ the reinforcement learning algorithm for deriving an approximate solution for the event-triggered HJ equation in real-time.
The improved value function can be obtained by the radial basis function neural network (RBFNN) as follows:
where is the desired critic NN weight vector; is the number of neurons in the hidden-layer; denotes the activation function; and is critic NN approximation error, which is bounded as , with the positive constants and .
Therefore, the partial derivative of can be obtained as follows:
where is Lipschitz continuous.
The relationship can be derived, and is a positive constant.
Substituting (24) into (21) can yield the following:
Therefore, one obtains the event-triggered HJ equation as follows:
where means residual error, and the positive constant is the upper bound of .
Since we cannot obtain the desired critic NN weight vector, we approximate the improved value function
Furthermore, the partial derivative is formulated as follows:
Therefore, merging (28) with (21), the event-trigger-based approximate optimal control law is obtained as
According to (25), (28) and (29), we can obtain the event-triggered approximate HJ equation as
Define the critic approximation error vector as ; from (30), we can define . To refine the estimation of the desired vector , we employ the gradient descent algorithm to minimize the objective function , with the update rate given by
Then, the approximation error vector is
Theorem 1.
Taking the value function (23) into account, it is estimated by the critic NN with weights . The cost function, as given by Equation (27), is approximated using the weights . Assuming the update law for the critic NN is defined by (31), the weight approximation error is proven to be UUB.
Proof.
The candidate for the Lyapunov function is selected as
The derivative of can be obtained as
Upon analyzing (34), we observe that if , this leads to , which in turn confirms the UUB of the critic approximation error vector. □
Theorem 2.
Given an MUS with joint subsystem dynamic model (1) and state space (7), the closed-loop MUS with coordinate control is UUB under the presented event-triggered reinforcement learning-based coordinate control law (35) if
holds, where is the designed sampling frequency parameter, means the minimum eigenvalue of the matrix, and is a positive constant that satisfies , assuming .
Proof.
We select the Lyapunov candidate function
where and . □
The following proof is divided into two cases.
- Case 1:
- The events are not triggered, i.e., .
Computing the derivative with respect to time of (36), the result is obtained as follows:
Based on the optimal control law (11) and time-triggered HJ equation (12), one has
Substituting (39) and (40) into (37), we can obtain the following equation:
in which the function term has the following up-bound:
where is a computable positive constant.
According to (24) and (28), (41) can be transformed into
Thus, we have as
According to (38) and (43) as well as (44), one has
Given that (35) is valid, (45) is compliant with the requirement . The condition that ensures the negativity of is that does not fall within the confines of , a requirement critical for affirming the negativity of the proposed Lyapunov function.
- Case 2:
- When events are triggered, , the difference of (36) is rewritten as
Based on (35), one has . Therefore, we have .
Then, one has (46) as the following form:
where denotes a class-k function, .
Taking into account Cases 1 and 2 collectively, it follows that under the condition specified by (35), the closed-loop MUS’s tracking error is UUB. Thus, the conclusion of the proof is established.
4.3. Exclusion of Zeno Behaviors
The minimum trigger interval is likely to be 0—that is, Zeno behavior. Therefore, we give the following theorem to avoid the phenomenon:
Theorem 3.
Considering MUS (1), the triggering condition (35) and the event-triggered approximate optimal control law (29), the minimum trigger interval is with a positive lower bound by
where , are positive constants.
Proof.
The time derivative of the event-triggered gap function (14) can be derived as follows:
The upper bound of is derived as
Combining (14) and (49) with (50), it can be obtained that
When , the event-triggered condition satisfies
Based on (51) and (52), the jth triggering interval has the lower bound by
This concludes the proof. □
5. Experiment
5.1. Experimental Setup
The validation of the proposed control method’s effectiveness is demonstrated through experiments on a 2 degrees of freedom (DOF) MUS platform. Detailed information about the experimental setup can be found in Figure 1. Joint control torque is measured using a joint torque sensor, while joint position information is acquired from both absolute and incremental encoders. The data acquisition board acts as the intermediary allowing interaction between the software environment (Simulink of Matlab 2016a) and hardware components. It is noted that the proposed ETRL via NZSG, which is in the form of continuous time, needs to be realized discretely when it is implemented in experiments. Fortunately, the control system, which is constructed under the Simulink environment, may complete the discrete realization automatically and adjust the sampling period adaptively. The model parameters are as follows: = 120 g·cm2, = 100, = 12 m·Nm/rad, = 30 m·Nm, = 40 m·Nm, = 20 s2/rad2. We consider the coordinate control, which is illustrated in Figure 1. The purpose of the experiment is satisfying the requirements of position tracking performance and control torque optimization under a coordinate operation with MUS. The critic NN is selected as RBFNN, and the activation function of (23) is with initial value denote the center and width of the activation function. The purpose of the control method is to decrease the position error and control torque as much as possible. The experimental results show that the proposed method reduces the position error by 30% and control torque by 10% compared with the existing control methods.

Figure 1.
Experimental platform.
5.2. Experimental Results
The experimental outcomes are utilized to evaluate the system’s position tracking accuracy, tracking error magnitude, applied control torque, contact forces, event-triggering mechanism’s efficiency, and neural network (NN) weights’ performance individually. Two distinct control methodologies are implemented: the established learning-based tracking approach, as seen in references [37,39], and the novel proposed control strategy. The coordinate control was subjected to the implementation of two distinct control approaches. The upper figure corresponds to joint one, while the lower one illustrates joint two.
(1) Position tracking
Figure 2, Figure 3 and Figure 4 depict the position tracking and tracking error curves in joint space during coordinate control using both the existing learning-based tracking control method and the proposed approximate optimal control method. The graphical analysis indicates that the position tracking error is notably lower and smoother with the newly proposed control method as opposed to the previously established method. The proposed method reduces the position error by 30%. This is attributed to the accurate solution of the coordinate control problem achieved by the proposed method. At the corners of the trajectory, the tracking error tends to increase but is effectively mitigated back to an acceptable range along the smooth path by the proposed approximate optimal control method. Figure 5 shows the 3D tracking curves.
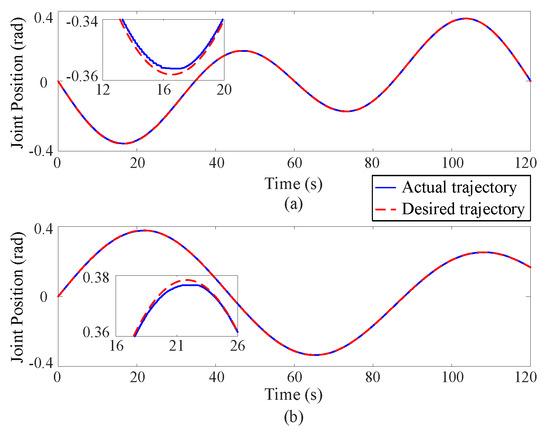
Figure 2.
Position tracking curves in joint space via the existing learning-based tracking control method, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
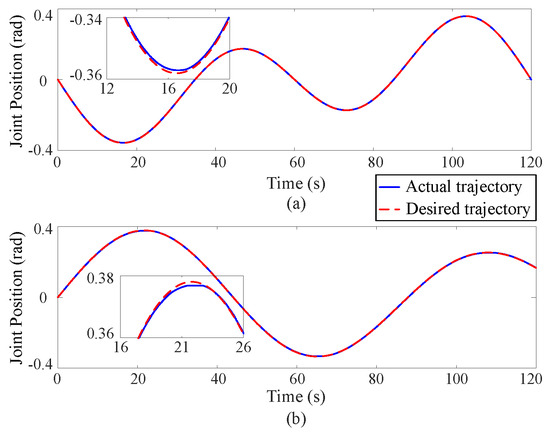
Figure 3.
Position tracking curves in joint space via the proposed approximate optimal control method, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
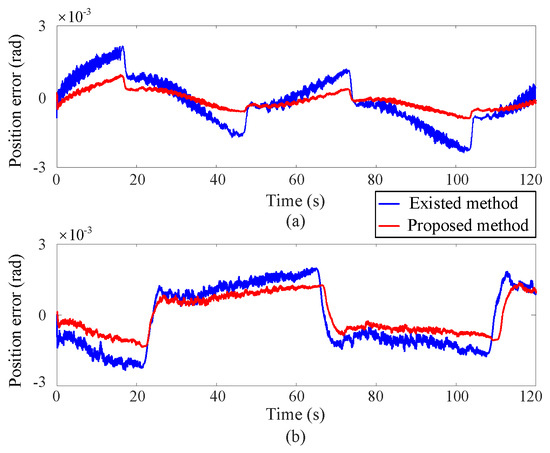
Figure 4.
Position tracking error curves in joint space, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
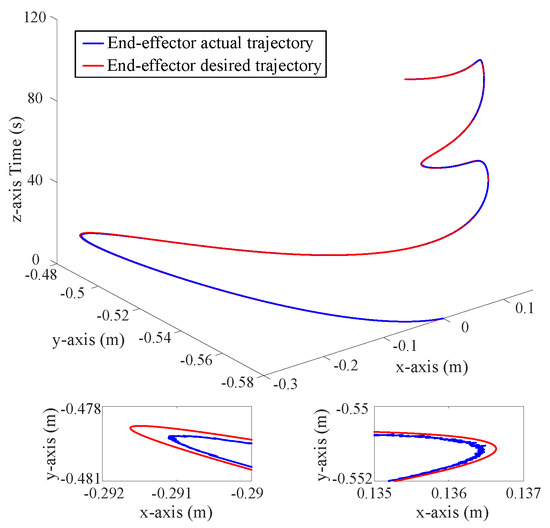
Figure 5.
Position tracking curves in 3D space.
(2) Control torque
Figure 6 displays the control torque curves during coordinate control using both the existing learning-based tracking control method and the proposed approximate optimal control method. The illustrations indicate that the control torque experiences a sharp increase during sudden trajectory changes, potentially impacting the lifespan of the DC motors. The proposed method reduces the control torque by 10% compared with the existing control methods. Furthermore, the control torque curves under the current control method display pronounced chattering, potentially degrading the accuracy of trajectory tracking. However, by employing the developed approximate optimal control method, the output torques are optimized to minimize motor power consumption and instantaneous increases in control torques are maintained within safe boundaries.
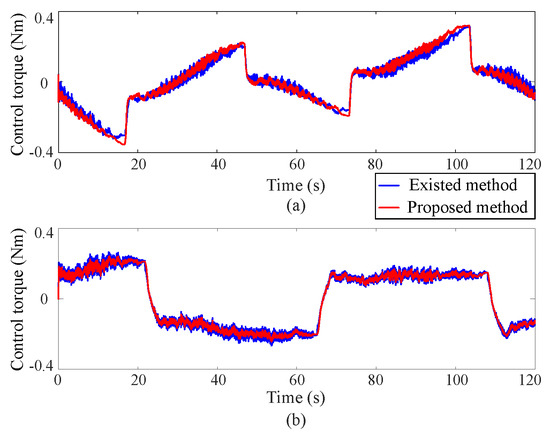
Figure 6.
Control torque curves, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
(3) Contact force
Figure 7 depicts the contact force curves during coordinate control using the proposed approximate optimal control method. Since the MUS has 2-DOF and the joint axes are assembled in parallel, the contact force curves appear in a two-dimensional space. From the figures, it can be observed that the proposed approximate optimal control method ensures that the contact force remains below 2N, with minimal chattering phenomenon.
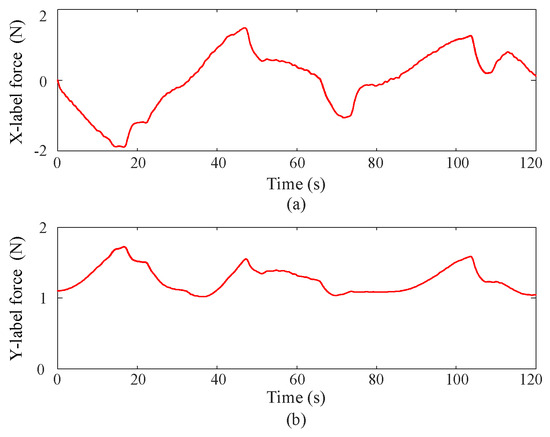
Figure 7.
Contact force curves via the proposed approximate optimal control method, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
(4) Event-triggered mechanism
Figure 8 and Figure 9 depict the trigger threshold and trigger condition curves. Owing to the incorporation of the NN within the reinforcement learning process, both the trigger condition and the trigger threshold exhibit large values. The proposed method’s trigger time is nearly half that of the existing method. However, the trigger condition stays within the threshold limits, confirming the reliability of the newly introduced strategy. Figure 9 demonstrates that the developed controller substantially reduces the communication burden of the MUS.
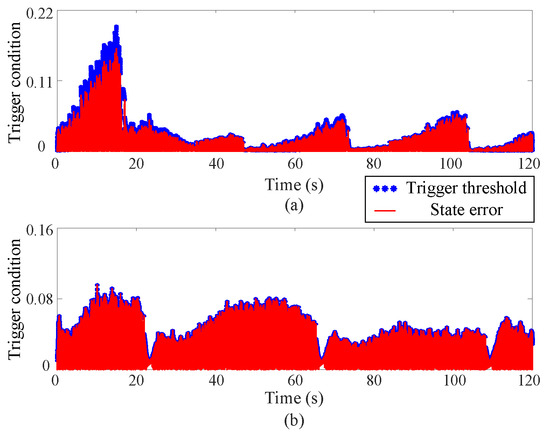
Figure 8.
Trigger threshold and trigger condition curves via the proposed approximate optimal control method, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
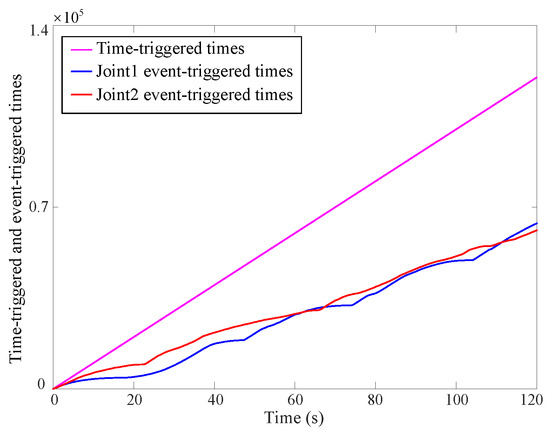
Figure 9.
Time-triggered and event-triggered time curves via the proposed approximate optimal control method.
(5) NN weight
Figure 10 illustrates the behavior of the critic NN via RBFNN under coordinate control facilitated by the proposed approximate optimal control method. The converged weights obtained from the proposed approximate optimal control policies allow the NN to accurately reflect the ongoing coordinate operations in real-time.
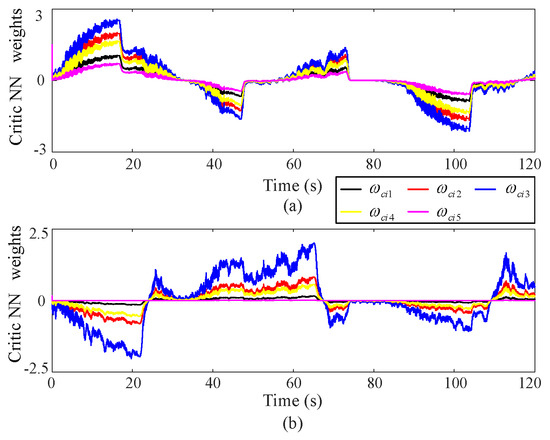
Figure 10.
NN curve via the proposed approximate optimal control method, where the upper (a) and lower (b) subgraphs correspond to Joint 1 and Joint 2 respectively.
Based on the experimental results, the closed-loop MUS systems have better performance than the existing methods in terms of position tracking and control torque under the proposed ETRL via the NZSG approach (cf. Table 1). Drawing from the experimental figure findings, when compared to existing methods, the closed-loop MUS demonstrates enhanced performance in position tracking, control torque, contact force, and event-triggered conditions under the proposed approximate optimal control method.

Table 1.
Performance comparisons.
6. Conclusions
An ETRL-based coordinate control of MUS via NZSG is proposed in the paper. JTF is utilized to form the MUS’s dynamic. The coordinate control problem is transformed into an RL issue via the NZSG strategy. Conventional periodic communication is avoided by the ET mechanism. The performance index function is approximated by the critic NN to obtain the optimal control strategy. According to the Lyapunov theorem, the closed-loop system is guaranteed to be stable. The experimental results show that the proposed method reduces the position error by 30% and control torque by 10% compared with the existing control methods. The mentioned control algorithm only concerns the static event-trigger. However, the computation burden and power consumption can be optimized by the dynamic event-trigger or self-event-trigger. This is the future research direction that we will work on.
Author Contributions
Conceptualization, Y.L.; methodology, T.A.; software, J.C.; validation, L.Z. and Y.Q. All authors have read and agreed to the published version of the manuscript.
Funding
The work is supported by the National Natural Science Foundation of China (62473063), the Scientific Technological Development Plan Project in Jilin Province of China (20220201038GX), Key Laboratory of Advanced Structural Materials (Changchun University of Technology), Ministry of Education, China (ASM-202202).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
Authors Y.L., J.C., L.Z. and Y.Q. were employed by the company Aerospace Times Feihong Technology Company Limited. The remaining author declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Hirano, D.; Inazawa, M.; Sutoh, M.; Sawada, H.; Kawai, Y.; Nagata, M.; Sakoda, G.; Yoneda, Y.; Watanabe, K. Transformable Nano Rover for Space Exploration. IEEE Robot. Autom. Lett. 2024, 9, 3139–3146. [Google Scholar] [CrossRef]
- Kedia, R.; Goel, S.; Balakrishnan, M.; Paul, K.; Sen, R. Design Space Exploration of FPGA-Based System With Multiple DNN Accelerators. IEEE Embed. Syst. Lett. 2021, 13, 114–117. [Google Scholar] [CrossRef]
- Goyal, M.; Dewaskar, M.; Duggirala, P.S. NExG: Provable and Guided State-Space Exploration of Neural Network Control Systems Using Sensitivity Approximation. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 4265–4276. [Google Scholar] [CrossRef]
- Nguyen, T.M.; Ajib, W.; Assi, C. A Novel Cooperative NOMA for Designing UAV-Assisted Wireless Backhaul Networks. IEEE J. Sel. Areas Commun. 2018, 36, 2497–2507. [Google Scholar] [CrossRef]
- Cheng, X.; Jiang, R.; Sang, H.; Li, G.; He, B. Joint Optimization of Multi-UAV Deployment and User Association Via Deep Reinforcement Learning for Long-Term Communication Coverage. IEEE Trans. Instrum. Meas. 2024, 73, 5503613. [Google Scholar] [CrossRef]
- Xue, S.; Luo, B.; Liu, D.; Yang, Y. Constrained Event-Triggered H∞ Control Based on Adaptive Dynamic Programming With Concurrent Learning. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 357–369. [Google Scholar] [CrossRef]
- Yang, X.; Xu, M.; Wei, Q. Adaptive Dynamic Programming for Nonlinear-Constrained H∞ Control. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4393–4403. [Google Scholar] [CrossRef]
- Renga, D.; Spoturno, F.; Meo, M. Reinforcement Learning for charging scheduling in a renewable powered Battery Swapping Station. IEEE Trans. Veh. Technol. 2024, 73, 14382–14398. [Google Scholar] [CrossRef]
- Lv, Y.; Wu, Z.; Zhao, X. Data-Based Optimal Microgrid Management for Energy Trading With Integral Q-Learning Scheme. IEEE Internet Things J. 2023, 10, 16183–16193. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, H.; Yan, Y.; Xu, S.; Fan, X. Optimal Regulation Strategy for Nonzero-Sum Games of the Immune System Using Adaptive Dynamic Programming. IEEE Trans. Cybern. 2023, 53, 1475–1484. [Google Scholar] [CrossRef]
- Sun, J.; Dai, J.; Zhang, H.; Yu, S.; Xu, S.; Wang, J. Neural-Network-Based Immune Optimization Regulation Using Adaptive Dynamic Programming. IEEE Trans. Cybern. 2023, 53, 1944–1953. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Gao, N.; Liu, D.; Li, J.; Lewis, F.L. Recent Progress in Reinforcement Learning and Adaptive Dynamic Programming for Advanced Control Applications. IEEE/CAA J. Autom. Sin. 2024, 11, 18–36. [Google Scholar] [CrossRef]
- Lv, Y.; Chang, H.; Zhao, J. Online Adaptive Integral Reinforcement Learning for Nonlinear Multi-Input System. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 4176–4180. [Google Scholar] [CrossRef]
- Na, J.; Lv, Y.; Zhang, K.; Zhao, J. Adaptive Identifier-Critic-Based Optimal Tracking Control for Nonlinear Systems With Experimental Validation. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 459–472. [Google Scholar] [CrossRef]
- Jin, P.; Ma, Q.; Lewis, F.L.; Xu, S. Robust Optimal Output Regulation for Nonlinear Systems With Unknown Parameters. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 4908–4917. [Google Scholar] [CrossRef]
- Jin, P.; Ma, Q.; Gu, J. Fixed-Time Practical Anti-Saturation Attitude Tracking Control of QUAV with Prescribed Performance: Theory and Experiments. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 6050–6060. [Google Scholar] [CrossRef]
- An, T.; Wang, Y.; Liu, G.; Li, Y.; Dong, B. Cooperative Game-Based Approximate Optimal Control of Modular Robot Manipulators for Human–Robot Collaboration. IEEE Trans. Cybern. 2023, 53, 4691–4703. [Google Scholar] [CrossRef]
- Sahabandu, D.; Moothedath, S.; Allen, J.; Bushnell, L.; Lee, W.; Poovendran, R. RL-ARNE: A Reinforcement Learning Algorithm for Computing Average Reward Nash Equilibrium of Nonzero-Sum Stochastic Games. IEEE Trans. Autom. Control 2024, 69, 7824–7831. [Google Scholar] [CrossRef]
- Zhao, B.; Shi, G.; Liu, D. Event-Triggered Local Control for Nonlinear Interconnected Systems Through Particle Swarm Optimization-Based Adaptive Dynamic Programming. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 7342–7353. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, B.; Liu, D.; Zhang, S. Distributed Fault Tolerant Consensus Control of Nonlinear Multiagent Systems via Adaptive Dynamic Programming. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 9041–9053. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, B.; Liu, D.; Zhang, S. Event-Triggered Control of Discrete-Time Zero-Sum Games via Deterministic Policy Gradient Adaptive Dynamic Programming. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 4823–4835. [Google Scholar] [CrossRef]
- Ye, J.; Dong, H.; Bian, Y.; Qin, H.; Zhao, X. ADP-Based Optimal Control for Discrete-Time Systems With Safe Constraints and Disturbances. IEEE Trans. Autom. Sci. Eng. 2024; early access. [Google Scholar] [CrossRef]
- Song, S.; Gong, D.; Zhu, M.; Zhao, Y.; Huang, C. Data-Driven Optimal Tracking Control for Discrete-Time Nonlinear Systems With Unknown Dynamics Using Deterministic ADP. IEEE Trans. Neural Netw. Learn. Syst. 2023; early access. [Google Scholar] [CrossRef] [PubMed]
- Mu, C.; Wang, K.; Xu, X.; Sun, C. Safe Adaptive Dynamic Programming for Multiplayer Systems With Static and Moving No-Entry Regions. IEEE Trans. Artif. Intell. 2024, 5, 2079–2092. [Google Scholar] [CrossRef]
- Xiao, G.; Zhang, H. Convergence Analysis of Value Iteration Adaptive Dynamic Programming for Continuous-Time Nonlinear Systems. IEEE Trans. Cybern. 2024, 54, 1639–1649. [Google Scholar] [CrossRef]
- Davari, M.; Gao, W.; Aghazadeh, A.; Blaabjerg, F.; Lewis, F.L. An Optimal Synchronization Control Method of PLL Utilizing Adaptive Dynamic Programming to Synchronize Inverter-Based Resources With Unbalanced, Low-Inertia, and Very Weak Grids. IEEE Trans. Autom. Sci. Eng. 2024; early access. [Google Scholar] [CrossRef]
- Wei, Q.; Li, T. Constrained-Cost Adaptive Dynamic Programming for Optimal Control of Discrete-Time Nonlinear Systems. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 3251–3264. [Google Scholar] [CrossRef]
- Lin, M.; Zhao, B. Policy Optimization Adaptive Dynamic Programming for Optimal Control of Input-Affine Discrete-Time Nonlinear Systems. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 4339–4350. [Google Scholar] [CrossRef]
- Mu, C.; Wang, K.; Ni, Z. Adaptive Learning and Sampled-Control for Nonlinear Game Systems Using Dynamic Event-Triggering Strategy. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4437–4450. [Google Scholar] [CrossRef]
- Vamvoudakis, K.; Kokolakis, N. Synchronous Reinforcement Learning-Based Control for Cognitive Autonomy. Found. Trends Syst. Control 2020, 8, 1–175. [Google Scholar] [CrossRef]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive Dynamic Programming for Control: A Survey and Recent Advances. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Dong, B.; Zhu, X.; An, T.; Jiang, H.; Ma, B. Barrier-critic-disturbance Approximate Optimal Control of Nonzero-sum Differential Games for Modular Robot Manipulators. Neural Netw. 2025, 181, 106880. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cui, D.; Peng, W. Optimum Control for Path Tracking Problem of Vehicle Handling Inverse Dynamics. Sensors 2023, 23, 6673. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Cui, D. Optimal Control of Vehicle Path Tracking Problem. World Electr. Veh. J. 2024, 15, 429. [Google Scholar] [CrossRef]
- Wu, P.; Wang, H.; Liang, G.; Zhang, P. Research on Unmanned Aerial Vehicle Cluster Collaborative Countermeasures Based on Dynamic Non-Zero-Sum Game under Asymmetric and Uncertain Information. Aerospace 2023, 10, 711. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, P.; Yuan, J. Nonzero-Sum Pursuit-Evasion Game Control for Spacecraft Systems: A Q-Learning Method. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3971–3981. [Google Scholar] [CrossRef]
- An, T.; Dong, B.; Yan, H.; Liu, L.; Ma, B. Dynamic Event-triggered Strategy-based Optimal Control of Modular Robot Manipulator: A Multiplayer Nonzero-Sum Game Perspective. IEEE Trans. Cybern. 2024, 54, 7514–7526. [Google Scholar] [CrossRef]
- Dong, B.; Gao, Y.; An, T.; Jiang, H.; Ma, B. Nonzero-sum Game-based Decentralized Approximate Optimal Control of Modular Robot Manipulators with Coordinate Operation Tasks using Value Iteration. Meas. Sci. Technol. 2024. [Google Scholar] [CrossRef]
- Liu, F.; Xiao, W.; Chen, S.; Jiang, C. Adaptive Dynamic Programming-based Multi-sensor Scheduling for Collaborative Target Tracking in Energy Harvesting Wireless Sensor Networks. Sensors 2018, 18, 4090. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).