Abstract
Next-point-of-interest (POI) recommendation aims to model user preferences based on historical information to predict future mobility behavior, which has significant application value in fields such as urban planning, traffic management, and optimizing business decisions. However, existing methods often overlook the differences in location, time, and category information features, fail to fully utilize information from various modalities, and lack effective solutions for addressing users’ incidental behavior. Additionally, existing methods are somewhat lacking in capturing users’ personalized preferences. To address these issues, we propose a new method called Multi-Branch Spectral Network with Contrastive Learning (MBSCL-Net) for next-POI recommendation. We use a multihead attention mechanism to separately capture the distinct features of location, time, and category information, and then fuse the captured features to effectively integrate cross-modal features, avoid feature confusion, and achieve effective modeling of multi-modal information. We propose converting the time-domain information of user check-ins into frequency-domain information through Fourier transformation, directly enhancing the low-frequency signals of users’ periodic behavior and suppressing occasional high-frequency noise, thereby greatly alleviating noise interference caused by the introduction of too much information. Additionally, we introduced contrastive learning loss to distinguish user behavior patterns and better model personalized preferences. Extensive experiments on two real-world datasets demonstrate that MBSCL-Net outperforms state-of-the-art (SOTA) methods.
1. Introduction
With the widespread use of GPS-enabled mobile devices and the development of location-based social networks (LBSNs), people are increasingly willing and able to share information about their activities. The large amount of check-in information accumulated as a result has led to the rapid development of next-POI recommendation systems, with many studies focusing on this task [1,2]. The development of next-POI recommendation systems provides important insights for traffic congestion management and urban planning, and can also help companies improve their advertising strategies [3].
In early studies, the focus was primarily on Markov chains (MCs), such as MMC [4], which utilized Markov chains to model the transition patterns of location sequences. With the advancement of deep learning, recurrent neural networks (RNNs) and their variants have been widely adopted in research due to their effectiveness in modeling sequence data, particularly for capturing users’ short-term preferences [5,6,7]. Later, the success of the Transformer architecture [8] also led to the application of attention mechanisms, with some studies [9,10] introducing attention mechanisms to model users’ long-term and short-term preferences. Other studies [11,12] referenced self-attention and multihead attention. Subsequently, the powerful ability of graph neural networks [13] to process spatial–structural data was utilized to model spatiotemporal relationships between locations [14], gaining widespread application [15,16,17]. Recently, some studies [18] have applied frequency-domain processing to time series. Other studies, such as POIFormer [19], SLS-REC [20], and CLSPRec [21], have introduced contrastive learning for next-POI recommendation.
These methods have been hugely successful, but when introducing various types of information such as location, time, and category to address data sparsity, they often overlook the differences in characteristics between them, fail to model each type of information in a targeted manner, do not make full use of user information, and are insufficient in modeling user interests. Additionally, while the application of attention mechanisms has driven the rapid development of next-POI recommendation systems, their large parameter scale may lead to the issue of overfitting [22]. Furthermore, the simple attention mechanism struggles to handle the inherent noise issues in time-series data [23]. There is also the challenge of better modeling users’ personalized preferences. Existing models have not effectively addressed the issues of gradient vanishing and training difficulties when handling long sequences.
To address the above issues, we propose a method called Multi-Branch Spectral Network with Contrastive Learning (MBSCL-Net) for next-POI recommendation. In MBSCL-Net, to capture users’ different preferences in terms of location, time, and POI category information, we use a multihead attention mechanism to process different types of information separately, modeling their respective fine-grained association patterns. When users have only a few check-in records, it is often difficult to capture their preference information. Additionally, to mitigate the inherent noise in time-series data, we transform the user’s check-in time-domain data into the frequency domain using the Fourier transform. In the frequency domain, we enhance the key frequency components through adaptive filtering while suppressing noise signals. This method significantly reduces noise interference and improves signal clarity. To address potential information loss during data transmission and mitigate gradient vanishing and gradient explosion issues when processing long sequences, we fuse the original data with the processed data using skip connections. Finally, we employ contrastive learning with a contrastive loss function to better capture users’ personalized preferences, enabling more accurate recommendations for the next POI.
In summary, the contributions of this paper are as follows:
- We took into account the differences in characteristics between different types of information in user check-in records. We used a multihead attention mechanism to independently process various types of information in order to capture their different characteristics.
- MBSCL-Net effectively utilizes the Fourier transform to convert check-in information from the time domain to the frequency domain.
- We use contrastive learning to better capture users’ personalized preferences and improve the accuracy of recommendations.
- Extensive experiments conducted on two real-world datasets (NYC and TKY) demonstrate the superior performance of MBSCL-Net. The results show that our model significantly outperforms existing SOTA methods.
2. Related Work
2.1. Next-POI Recommendation
Next-POI recommendation aims to recommend the next destination for users by combining their long-term preferences based on historical behavior and the recent spatiotemporal context. The methods used in earlier studies have been widely applied in other sequential recommendation tasks, such as Markov chains and their variants [24,25]. Cheng et al. [25] proposed a personalized Markov chain model, FPMC-LR, to decompose user behavior in sequence data to obtain personalized preferences and predict the next POI in a time series. Meanwhile, Zhang et al. [26] proposed an additive Markov chain to simulate sequential influence propagation and predict sequential transmission probabilities. Other studies [27,28] utilize matrix decomposition for POI prediction. However, these early methods have limited modeling capabilities and cannot effectively capture user preferences.
In recent years, with the development of deep learning, many studies have been conducted based on RNNs and their variants due to their excellent modeling capabilities. Liu et al. [6] proposed STRNN, a pioneering work that incorporates spatial and temporal information about user visits into RNNs to predict human flow behavior. Some methods combine attention mechanisms to enhance model performance. In DeepMove [9], a multi-module embedding method is used to convert sparse features into dense representations, followed by combining the attention mechanism with RNN to capture users’ long-term and short-term preferences. Wu et al. [29] proposed the PLSPL model, which attempts to model category information and then uses the attention mechanism to learn users’ long-term preferences and LSTM to learn short-term preferences. Sun et al. [30] proposed LSTPM, which combines context-aware non-local networks and geographically expanded RNNs to model users’ long-term and short-term preferences. Luo et al. [10] proposed STAN, which combines self-attention mechanisms with spatiotemporal correlation matrices to learn non-adjacent locations and noncontinuous check-ins. PG2Net [31] combines attention mechanisms with Bi-LSTM to separately model users’ collective preferences and personalized preferences through spatiotemporal dependencies. Li et al. [32] proposed a multi-level collaborative neural network model, MCN4Rec, which captures complex heterogeneous relationships between different pieces of information to recommend the next location.
However, the attention mechanism used in the above methods struggles to handle the inherent noise problems in time-series data, resulting in suboptimal model performance.
2.2. Frequency-Aware Time-Series Forecasting
Recently, to address the issue of noise in time-series data, some studies have attempted to incorporate frequency-domain information and achieved good results. TSLA-Net [18] proposed adaptive spectral blocks and interactive convolution blocks for adaptive denoising in the frequency domain, enhancing periodic modeling capabilities. TimesNet [33] extracts periodicity through the Fourier transform (FFT) and then performs convolution operations on the periodic signal. FreTS [34] utilized the frequency domain to capture global dependencies and perform energy compression, effectively capturing time-series patterns. Additionally, FITS [35] directly trains sequences using fully connected layers in the frequency domain, achieving performance improvements while maintaining a small number of parameters.
Inspired by these works, we designed a spectrum block that converts time-domain information to the frequency domain through Fourier transform (FFT) and then filters out noise through adaptive filters.
2.3. Contrastive Learning
Contrastive learning has also made significant progress in time series [36,37]. Contrastive learning is an unsupervised learning method that learns data representations by maximizing the similarity between relevant samples and minimizing the similarity between irrelevant samples. Contrastive learning methods have been widely applied in computer vision, natural language processing, and time-series prediction. SimCLR [38] generates augmented views by performing data augmentation on the original data and learns through a simple and effective framework. In time series, TS2Vec [39] better captures contextual information through hierarchical contrastive learning. TSTCC [40] generates positive sample pairs from related sequences and negative sample pairs from unrelated time series, ultimately learning local and global features by maximizing the similarity of positive sample pairs.
3. Methodology
In this section, we provide a detailed introduction to our model. As shown in Figure 1, the MBSCL-Net mainly consists of five parts: Multi-Branch Attention Fusion Network, Adaptive Spectral Gate, LSTM encoder, Transformer decoder, skip connection, and contrastive learning module.
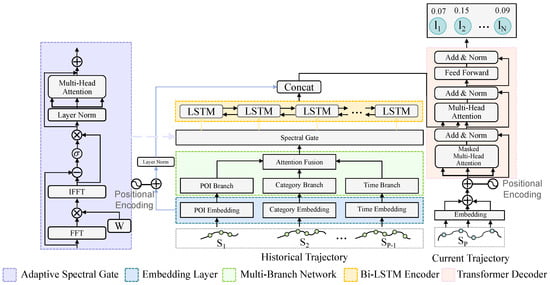
Figure 1.
The overview of our proposed MBSCL-Net.
3.1. Problem Formulation
We define the user set U = {, , …, }, the location set l = {, , …, }, and the POI category set C = {, , …, }. Then we define some concepts used in this paper.
Definition 1 (Check-in).
A check-in record is a tuple q = (, , , ), indicating that user visited location of category at time .
Definition 2 (Session).
We define all check-in records generated by a user as = (, , , …), where represents the i-th check-in record of user U. We divide the check-in records of a user within a certain period of time into a session S, and the length of each session S may vary.
Definition 3 (Next-POI Recommendation).
We define next-POI recommendation as follows: given a user and its historical check-in records , the task is to recommend the top-K points of interest that the user is likely to visit at the next timestamp.
3.2. Multi-Branch Attention Fusion Network
The structure of the Multi-Branch Attention Fusion Network is shown in Figure 2, where N is set to 2. We use light-colored solid figures to represent the original embedded data, with different colors representing different embedding modalities, and then use dark-colored solid figures to represent the feature-enhanced modalities obtained after capturing features through each branch. The Multi-Branch Attention Fusion Network consists of three branches—POI Branch, Time Branch, and Category Branch—and a final Branch Fusion module. It first splits various embedded information into different branches, each focusing on a specific modality, and then fuses them together.
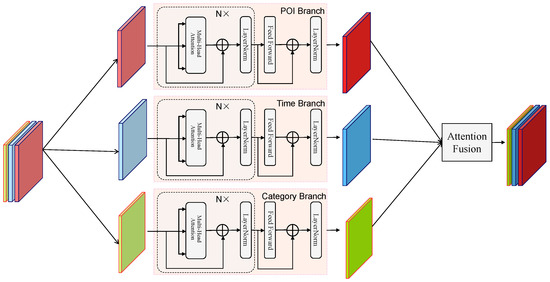
Figure 2.
The framework of the Multi-Branch Attention Fusion Network.
From human trajectory data, we can learn a great deal about human movement patterns, but due to the sparsity of trajectory sequences, we adopted the embedding method described in [9]. For user ID, location, and POI category information, based on word2vec [41], we map these sparse data into low-dimensional feature dense vectors, represented as , , and , respectively. Here, denotes the number of users, denotes the number of locations, denotes the number of location categories, and , , and represent the embedding dimensions of the corresponding features. For timestamp information, since it is continuous and cannot be directly embedded, we first divide the 24 h of a day into 24 time segments from 0 to 23 to represent weekdays, and then use 24 time segments from 24 to 47 to represent weekends, thereby distinguishing between weekdays and weekends. We then map the timestamps to the corresponding time segments and finally encode them, represented as , with a dimension of .
In previous studies, there has been a lack of further capture of embedded features, often simply concatenating various embedded information through various methods. While progress has been made at the basic feature representation level, the modal differences between multi-source heterogeneous features have been widely overlooked. Furthermore, this coarse-grained feature mixing method, which fuses embedded vectors such as geographic coordinates, timestamps, and POI categories, through simple concatenation or weighted summation, can lead to two issues: first, the semantic orthogonality of features across different dimensions is disrupted, causing temporal–spatial patterns and semantic information to become feature-confused; second, the fine-grained associative patterns unique to each dimension are difficult to model in a targeted manner. To address this issue, we designed the Multi-Branch Attention Fusion Network module. Liu et al. [42] proposed a multi-behavioral sequential recommendation model called MAINT, which makes recommendations to users by extracting different preferences from target behaviors. This model has achieved significant results, proving the feasibility of our method.
POI Branch is a component specifically designed to extract geospatial correlation features in multi-branch spatiotemporal modeling networks. This module employs a deep attention mechanism [43,44] to explicitly model the spatial dependencies between POIs in user movement trajectories, including geographic proximity, regional functionality, and potential spatial access patterns. Its design objective is to address the limitations of traditional sequence models in modeling local geographic context, providing fine-grained spatial semantic representations for personalized location recommendations.
The input to this module is the raw embedding of the POI sequence, denoted here as X. First, it goes through two layers of multihead attention. In each layer, multiview feature projection is performed to generate the Query, Key, and Value matrices:
Among them, are learnable parameters. Then, the attention score is obtained through the scaled dot-product attention operation, with the specific formula as follows:
where H represents the number of attention heads. In addition, layer normalization and residual connections are applied within the attention module. The formula is as follows:
When people select the next POI, they often exhibit path dependency in their movement trajectories, such as having fixed commuting routes. For example, most people have a fixed route from home to the subway station and then to the office. Given this phenomenon, we use dot-product attention operations to adaptively learn the transition probabilities between POIs, suppressing low-probability unreasonable transitions and capturing regular patterns in users’ historical visit paths. We have set up two attention layers. The first-layer attention primarily focuses on adjacent POIs in the sequence, modeling local interactions to represent neighboring relationships. The higher-layer attention receives the local features from the lower layer’s output, utilizing residual connections and feature propagation. The second layer can access a broader range of POIs, expanding the receptive field to capture regional functional features.
After multi-level attention refinement, the module further integrates multi-level spatial semantics through a feedforward network. The feedforward network extracts high-order spatial interaction information through expansion–compression dimensional operations, suppresses noise, and then adds the FFN output to the final features of the attention layer via residual connections to mitigate the vanishing gradient problem in deep networks, ensuring training stability. It then performs layer normalization again to ensure that the output feature scale is consistent with the remaining branches of the multi-branch network. The specific formula is as follows:
where and are trainable weight matrices, and are two bias parameters, and the dimension of the final output H is the same as that of the input X,. For POI recommendation tasks, SpatialBranch significantly enhances the consistency of path prediction and avoids unreasonable candidate targets.
The architectural design of the Time Branch and Category Branch is largely similar to that of the POI Branch, with each branch adopting a hierarchical structure consisting of multihead attention mechanisms, feature enhancement, and hierarchical fusion. For the Time Branch, the lower-level time attention focuses on local continuity, while the higher-level attention integrates global periodicity. The Category Branch reinforces the semantic association modeling of POI categories through a hierarchical feature learning mechanism. This branch focuses on fine-grained category interaction patterns in the first-layer attention, enabling POIs with similar functional attributes to obtain higher association weights even if their physical locations are dispersed, thereby capturing users’ consumption intentions. The higher-level attention identifies regional functional combination features by expanding the receptive field. This module breaks through the limitations of pure distance through semantic association modeling, providing theoretical support for cross-regional same-category recommendations and cross-category functional combination recommendations, and suppressing redundant phenomena of excessive concentration of a single category in recommendation results.
After capturing the features of each branch, we achieve hierarchical fusion of multi-branch features through BranchAttentionFusion module with static and dynamic dual pathway design. When a new POI lacks historical data, the pure attention mechanism may fail due to noise or sparse data, and we obtain static weights to provide the base recommendation. In the static pathway, the module assigns learnable normalized weight parameters to each branch, generates probabilistic weight distributions via Softmax, and then weights and sums the output features of POI, Time, and Category Branches. To capture the complex behavioral patterns of users, we design a dynamic pathway to dynamically capture fine-grained semantic associations across branches using an attention mechanism. Based on the physical foundation of POI recommendations based on spatial location, user movement is strictly constrained by distance. Dynamic pathways use spatial branch features as the query benchmark, then project each branch feature as a key and value, concatenate them to form a global context, and then calculate the attention score through scaling dot-product attention to dynamically fuse the semantic information of each branch. Finally, the module sums the projected output of the dynamic pathway with the static weighted features through residual concatenation, and applies layer normalization to eliminate the feature scale differences to output the fused unified representation. The specific process is as follows:
In the equation, N denotes the number of branches (in this work ), where represents the output tensor of the i-th branch. Here, B indicates the batch size, L stands for the length of historical behavior sequence, and D is the unified feature dimension. The symbol denotes the branch static weight parameters. The matrices , , and are linear transformation matrices for generating queries, keys, and values, respectively. represents the weighted sum result from the static pathway, while denotes the dynamically fused result through attention mechanisms in the dynamic pathway. constitutes the ultimate output, formed by layer-normalized integration of both static and dynamic fusion results.
3.3. Adaptive Spectral Gate
Inspired by [33], we proposed an Adaptive Spectral Gate module based on frequency-domain signal processing to address the coexistence of periodic patterns and random noise in users’ mobile behavior. The specific structure of this module is shown in Figure 3. The colored blocks in the figure represent frequencies from low to high, from bottom to top. We use dark red to indicate higher weights, with the color gradually lightening to light blue and then darkening to dark blue to indicate weights from high to low. This module projects user behavior sequences into the frequency domain using fast Fourier transform (FFT) and performs global spectral modulation using learnable adaptive filters. The design also provides time–frequency dual-domain collaborative modeling capability to effectively decouple long-term behavioral patterns from short-term random fluctuations.
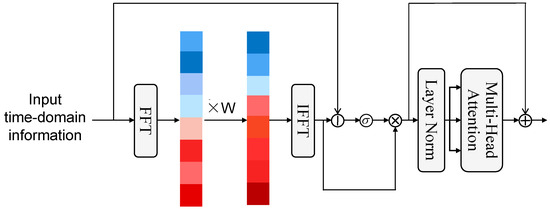
Figure 3.
The framework of the Adaptive Spectral Gate.
This is accomplished by first performing a real fast Fourier transform on the input time-domain signal along the time dimension:
The input is a time-domain user behavior sequence , where B is the batch size, L is the sequence length, and D is the feature dimension. Output frequency-domain complex signal () retains the non-redundant frequency components after conjugate symmetry to reduce computational effort, and orthogonal normalization is used to ensure energy conservation. This decomposes the user behavior sequence into different frequency components, with low frequencies corresponding to long-term patterns and high frequencies corresponding to short-term fluctuations. Since high-frequency signals usually represent rapid fluctuations that deviate from the underlying trend, this can make the data more random and difficult to interpret [45]; we propose a frequency-domain adaptive filter that generates dimension-independent filters through a trainable complex weight matrix, constraining the real and imaginary parts of each dimension to the (0, 1) interval using the Sigmoid function. Define the learnable complex filter whose real and imaginary parts of each dimension d are parameterized by the weights after Sigmoid activation, respectively:
where is a Sigmoid function that learns the real and imaginary weights of the parameter matrices and corresponding to the feature dimension d. The weights are then applied to the frequency-domain signal element by element. Then complex multiplication is applied to the frequency-domain signal element by element:
We expand the result into real and imaginary part weights:
Finally, we reconstruct the time-domain signals by inverse transformation and keep the length of the output sequence consistent with the input:
We obtain the result . To further optimize the feature characterization, the module further introduces a difference-driven attention gating mechanism to generate dynamic weights from the feature differences before and after spectral processing:
In the above equation, if , it represents that the frequency-domain enhancement is effective and amplifies the contribution of the dimension, and if , the frequency-domain processing is distorted and attenuates the impact of the dimension. This is followed by a dual-domain synergy with the multihead time-domain attention module:
The final output of the time–frequency synergy feature is obtained by residual concatenation:
The final result is .
This module adapts through backpropagation by jointly optimizing the trainable parameter with other parts of the network, enabling it to adaptively amplify task-relevant global spectral patterns and suppress noise-dominated spectral components. Specifically, if high-frequency components are generally associated with noise, this mechanism automatically weakens the spectral weights of the corresponding features. Overall, this module indirectly emphasizes low-frequency long-term patterns and suppresses high-frequency short-term noise in user behavior sequences by utilizing learnable global modulation combined with data-driven frequency-domain attention and time-domain multihead attention.
3.4. Skip Connection
Deep learning models often face the dual challenges of feature degradation and vanishing gradients when processing long trajectory data. In our model, the main path passes through a multi-branch network and an Adaptive Spectral Gate module, which offer significant advantages in feature extraction and noise filtering. However, during propagation, degradation issues may arise, leading to the loss of certain features, and there is also the risk of vanishing gradients. The residual network proposed by He et al. [46] largely addresses this issue. Its core idea is to directly connect the input to the output in certain layers of the network, enabling information to jump and propagate between different layers. Therefore, we designed a skip connection section inspired by this method, aiming to resolve the issues of gradient vanishing and training difficulties.
In the specific implementation method, we first concatenate the original POI, time, and category of the historical sequence, and then inject the concatenated result into the sequence order information through a position-encoding module. We use sine and cosine functions of different frequencies:
where is the position and i is the dimension. This corresponds to the input of the subsequent Transformer decoder. Then concatenate it with the output result of the encoder.
This module concatenates the original shallow local features with the extracted deep global features in the channel dimension. In addition to preventing information loss and gradient vanishing during deep network processing, it also forms complementary and enhanced feature representations. Furthermore, this module accelerates the training process.
3.5. LSTM Encoder and Transformer Decoder
In order to better capture contextual information, unlike earlier work that directly used LSTM encoding, we use Bi-LSTM for encoding. The Bi-LSTM calculation is specifically as follows:
where denotes the hidden information of record in the historical trajectory, and ⊕ denotes the concatenation of forward and backward output combinations. The Bi-LSTM encoder is used to capture bidirectional contextual dependencies in each user session. Bi-LSTM can naturally model local and sequential dependencies, favoring temporal order, which is particularly useful for human mobile data, where short-range patterns are critical.
The Transformer is a deep learning model architecture designed for natural language processing and other sequence-to-sequence tasks, first proposed by Vaswani et al. in 2017 [8]. The core idea of this model is the self-attention mechanism, which enables the model to consider information from different positions within an input sequence during processing. The Transformer model consists of multiple self-attention layers, which can process the input in parallel. We adopt the Transformer as the decoder, first concatenating the target POI, time, and category embeddings to obtain a combined spatiotemporal embedding representation, and then applying a position-encoding module to inject sequence order information. We use sine and cosine functions of different frequencies:
where is the position, and i is the dimension. The input is then fed into a two-layer Transformer decoder, each layer comprising three core components: a causal self-attention mechanism using a lower triangular mask matrix to ensure that position i can only attend to elements ; an encoder–decoder cross-attention layer that queries the final encoded memory of the historical trajectory as key–value pairs; and a feedforward neural network to enhance nonlinear expression capabilities.
3.6. Contrastive Learning Loss
To better uncover user behavior patterns and travel preferences, we use contrastive learning loss, which is a user–POI contrastive learning component, with its core functionality being to enhance the semantic association between user preferences and location features through a contrastive learning mechanism. By maximizing the interaction information between users and the POIs they visit, it learns more discriminative representations. The core idea is that user embeddings should be similar to the embeddings of POIs they have visited, while being distinct from the embeddings of POIs they have not visited.
The loss’s input consists of user embeddings and POI embeddings. We first use two independent MLP networks to process user and location features for deep semantic transformation, followed by a normalization layer to stabilize the distribution. Then, through L2 normalization, the vectors are converted to unit vectors to ensure the rationality of similarity calculations. For POI sequence inputs, the loss selects the last visited location as the positive sample. The core contrastive learning calculates the cosine similarity matrix via dot-product operations, where the temperature coefficient finely tunes the steepness of the probability distribution. The cross-entropy loss function forces user features to align with their own visited POIs while pushing away similarities with other users’ POIs. The contrastive loss expression is as follows:
where N denotes the batch size, denotes the normalized final feature representation of user i, denotes the positive sample POI features corresponding to user i, denotes all POI features in the batch, the sim function is used to calculate the cosine similarity between two vectors, and is a temperature parameter used to control the smoothness of normalization.
3.7. Prediction
Here, we adopt a Transformer-based sequence-to-sequence architecture for multi-step POI prediction. At each time step, the temporal–spatial embeddings of the target sequence are received, combined with encoder memory and positional encoding, and gradually generated into future POI sequences through an autoregressive decoder under causal masking constraints. The main prediction head generates an accurate POI probability distribution, while an MLP serves as an auxiliary category prediction head as a regularization term, constraining the model to learn general features related to POI categories through KL divergence loss. The final multi-task loss function combines POI prediction loss, category regularization loss, and user–POI contrast loss. The final loss function is as follows:
where is the weighting coefficient for the contrast loss . This hyperparameter balances the training emphasis of different loss terms through a dynamic scheduling mechanism to optimize model performance.
4. Experiments
In this section, we evaluate the proposed MBSCL-Net model on two datasets, compare our proposed method with the SOTA next-POI recommendation model, and discuss the experimental results.
4.1. Datasets
We evaluated our model on publicly available Foursquare check-in datasets for NYC and TKY, which are widely used. Regarding privacy and ethical considerations, both datasets have been publicly released and widely used in previous studies. We strictly adhere to the terms of use of the original datasets and ensure that all experiments comply with ethical research standards. Each dataset includes a user ID, a POI ID, a category ID, a timestamp, and the latitude and longitude of the POI, among other details. In our experiments, we preprocessed the datasets by excluding POIs with fewer than 10 visits in the NYC and TKY datasets. Additionally, for each dataset, each user’s check-in records were divided into multiple sessions based on a 24 h time window. Each session must contain at least three check-ins, and users with fewer than five sessions were filtered out. Finally, we strictly followed the time sequence and used the first 80% of each user session as the training set and the remaining 20% as the test set. The statistical information of the preprocessed dataset is summarized in Table 1.

Table 1.
Statistics of datasets.
4.2. Baseline Models
To demonstrate the effectiveness of MBSCL-Net, we selected several mainstream next-POI recommendation models for comparisons. The baseline models are described as follows:
LSTM: LSTM is a neural network-based model, a variant of recurrent neural networks, capable of efficiently processing sequence data.
STAN [10]: STAN models spatiotemporal correlations between non-adjacent locations and non-adjacent visits using a self-attention network.
DeepMove [9]: DeepMove uses an attention mechanism to learn users’ long-term and short-term preferences by leveraging their historical and current sessions.
PLSPL [29]: A neural network model that considers category information during network construction to learn each user’s specific preferences.
LSTPM [30]: This is a location prediction model that uses a context-aware non-local network structure and a geographically extended RNN to capture users’ long-term and short-term preferences, respectively.
PG2Net [31]: PG2Net uses a bidirectional long short-term memory network based on spatiotemporal attention to learn user group and personalized preferences.
HUE-SCL [47]: HUE-SCL constructs a hypergraph based on user–interest point interaction information and utilizes the complex higher-order information embedded in the hypergraph to further embed users and deeply mine their personalized preferences.
For our method, the embedding dimensions , , , and for users, locations, categories, and timestamps are all equal and set to . The batch size is set to 32. We use the AdamW optimizer, a gradient descent optimization algorithm, and set the initial learning rate and regularization weight to 0.001 and 1 × 10−5, respectively. The hidden layer dimension is set to 128, and the dropout rate is 0.3. The temperature parameter is set to 0.1. In Figure 4, we show the loss comparison between our model MBSCL-Net and PG2Net trained for the same number of epochs on the TKY dataset. In Figure 5, we show the loss comparison between our model MBSCL-Net and PG2Net trained for the same number of epochs on the NYC dataset. The loss curves for the training set and validation set in Figure 4 and Figure 5 remain highly consistent, indicating that there is no overfitting issue.
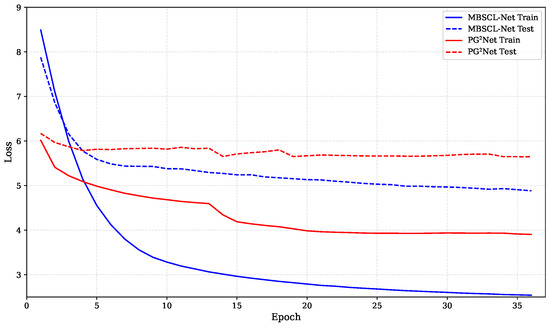
Figure 4.
Loss comparison between MBSCL-Net and PG2Net during training and testing on the TKY dataset.
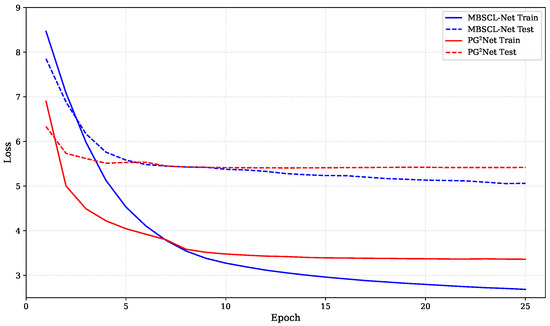
Figure 5.
Loss comparison between MBSCL-Net and PG2Net during training and testing on the NYC dataset.
4.3. Evaluation Metrics
To compare our model with the baseline model, we adopted two commonly used evaluation metrics from previous studies [48,49]: Recall@K and NDCG@K. Recall@K is used to measure whether the correct location appears among the top-K recommended POIs, thereby assessing the accuracy of the model’s predictions. NDCG@K, on the other hand, is used to evaluate the ranking quality of the top-K recommended POIs. Higher metrics indicate better performance. For a comprehensive evaluation, we selected K = 1, 5, and 10. The formulas for Recall@K and NDCG@K are as follows:
where denotes the top-K positions recommended for user i, N denotes the number of users, denotes the list of positions accessed in the test set, is the index function, denotes the jth position recommended in , and is the maximum value in DCG@K, which is a normalization constant representing the number of prediction records for each user. For each test instance, the model ranks the ground-truth POI among all possible POIs in the dataset.
4.4. Main Results
The experimental results comparing the performance of our model with the baseline models on the two datasets are shown in Table 2. The best results for each metric are indicated in bold. The results show that our method outperforms all baseline models on all metrics on both datasets. In particular, our model demonstrates outstanding performance on the TKY dataset. Specifically, compared to the baseline model PG2Net, on the NYC dataset, Recall@1 improved by 1.78%, Recall@5 improved by 3.48%, Recall@10 improved by 4.33%, NDCG@1 improved by 1.78%, NDCG@5 improved by 2.7%, and NDCG@10 improved by 2.97%. On the TKY dataset, Recall@1 improved by 5.02%, Recall@5 improved by 14.69%, Recall@10 improved by 16.81%, NDCG@1 improved by 5.02%, NDCG@5 improved by 10.07%, and NDCG@10 improved by 10.77%. These results demonstrate the superiority and effectiveness of our model in the point-of-interest recommendation task.
Table 2.
Performance comparison on NYC and TKY datasets. The values in parentheses are the standard deviations of the model.
LSTM is a variant of RNN that effectively alleviates the gradient vanishing problem when processing long sequence data and has stronger modeling capabilities for long-term and short-term preferences. However, the model is too simple to capture more complex user behavior patterns.
Although STAN models discontinuous check-in behavior by introducing self-attention networks, it lacks the ability to capture features across modalities and does not model personalized preferences. STAN models discontinuous check-in behavior using a special spatiotemporal embedding method, but it lacks the ability to capture continuous check-in behavior. In contrast, our model models personalized preferences through contrastive learning and captures the features of each model more precisely through a multi-branch network, resulting in superior performance.
DeepMove introduces an attention mechanism to process trajectory sequences, enhancing its ability to model user preferences. PLSPL introduces an attention mechanism and category information to address data sparsity to a certain extent. However, their modeling capabilities remain limited. Specifically, they do not consider the association information between users and POIs, and the method of directly concatenating category information introduces noise. In contrast, our method captures the association information between users and POIs through contrastive learning, thereby enhancing the modeling of user-personalized preferences. The independent processing of each modality reduces the increase in noise caused by introducing more information. Additionally, the spectral module directly identifies noise information in the frequency domain, thereby reducing interference.
LSTPM uses LSTM to model users’ long-term preferences and geographically extended LSTM to model short-term preferences. Compared to other baseline models, PG2Net performs well. It models user preferences using a Bi-LSTM combined with spatiotemporal attention, demonstrating stronger information capture capabilities. HUE-SCL models users as hyperedges and models the POIs they visit as nodes in these hyperedges, constructing a hypergraph to capture the interaction between users and POIs. While these models have further enhanced their modeling capabilities, they still do not account for the feature differences between different modalities, have limitations in modeling user periodic behavior, and overlook user–POI interactions. Our model captures the features of different modalities. Additionally, in terms of effectiveness, our spectral module has stronger modeling capabilities for users’ periodic behaviors and strengthens the connection between users and POIs through contrastive learning, which is why our model performs more effectively compared to others.
Our model MBSCL-Net and the baseline model PG2Net are compared in terms of the time required for each training round on the TKY dataset under the same experimental conditions, as shown in Table 3. The results indicate that our model requires less time for each training round and is more efficient than the baseline model PG2Net.
Table 3.
Comparison of the time required for each training round on the TKY dataset between MBSCL-Net and PG2Net under the same experimental conditions.
Our model enables independent processing of different modal features. When one type of feature is sparse, information from other categories can be used to supplement it, thereby alleviating the problem of data sparsity to a certain extent and reducing the introduction of noise information. We also use contrastive learning to model users’ personalized preferences. Even if a user has limited check-in data, we can still recommend points of interest (POIs) based on other users with similar preferences. Our model demonstrates superior performance when handling sparse data.
4.5. Ablation Study
To validate the effectiveness of different modules in the model, fifteen degraded models were obtained by decomposing MBSCL-Net. We use MB to represent Multi-Branch Attention Fusion Network, ASG to represent Adaptive Spectral Gate, CL to represent Contrastive Learning, and Skip to represent Skip Connection. The results of the ablation experiments are shown in Table 4 and Table 5.
Table 4.
Ablation results on NYC.
Table 5.
Ablation results on TKY.
The results show that the complete MBSCL-Net model has the best performance on both datasets, and each module plays its own role in further improving the model’s performance. Through observation, we found that Multi-Branch Attention Fusion Network and Skip Connection have a greater impact on model performance, while Contrastive Learning has a smaller impact. Based on this analysis, the following can be derived:
The significant impact of the Multi-Branch Attention Fusion Network on performance indicates that users indeed have different preferences across various modal information. Independently processing preferences for different modalities can better capture user preferences. The significant impact of Skip Connection on model performance indicates that while our model can mitigate noise interference and better model preferences through the Multi-Branch Network and Adaptive Spectral Gate modules, it also loses some original features, thereby reducing the model’s effectiveness to some extent. Contrastive Learning can better capture user–POI interactions and model users’ personalized preferences, but its effectiveness is relatively secondary compared to other modules.
We also conducted ablation experiments on the static and dynamic pathways in the Multi-Branch Attention Fusion Network module, with the results shown in Table 6.
Table 6.
Static and dynamic pathway ablation experiments in the Multi-Branch Attention Fusion Network module.
As shown in Table 6, both the static and dynamic pathways in the Multi-Branch Attention Fusion Network module can enhance the performance of the model and are effective. Furthermore, when used in combination, they demonstrate even stronger performance.
We also verified the performance of the Bi-LSTM encoder and Transformer decoder separately by replacing the Bi-LSTM encoder with an LSTM encoder and removing the Transformer decoder. The results are shown in Table 7.
Table 7.
Effect of encoder and decoder architectures on MBSCL-Net performance.
The results show that the use of both the Bi-LSTM encoder and the Transformer decoder enhances the model’s performance. Among these, the Transformer decoder plays a key role in our model.
In addition, we found that our model performed significantly better on the TKY dataset than on the NYC dataset. This may be due to the increased complexity of the model, while the NYC dataset is relatively smaller than the TKY dataset, resulting in a decline in performance.
4.6. Hyperparameter Analysis
In this section, we further analyze the impact of two hyperparameters—the dimension dim of the embedded feature vector and the number of attention layers in the Multi-Branch Attention Fusion Network module—on the performance of the MBSCL-Net model.
The experimental results for embedding dimension dim are shown in Figure 6. In the experiment, we set the values of dim to 32, 64, 96, and 128. It can be observed that the performance is worst when dim is set to 32, possibly because the smaller embedding dimension limits the model’s learning capacity. As dim increases, the model performance gradually improves and stabilizes. When dim is set to 64, the model already achieves good performance. Further increasing the value of dim adds additional computational overhead but only results in a slight improvement in performance. Therefore, we set dim to 64.
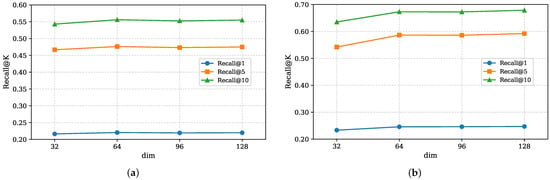
Figure 6.
Impact of hyperparameter dim. (a) Impact on the NYC dataset; (b) impact on the TKY dataset.
The experimental results for the number of attention layers are shown in Figure 7. It can be observed that the model performance is optimal when Layers is set to 2. When the number of layers is 1, the receptive field is limited, and only basic associations between information can be established, making it impossible to capture more complex semantic relationships. This leads to underfitting of the model, requiring more layers for deeper understanding. However, when the number of layers is too high, noise may be learned, leading to overfitting of the model.
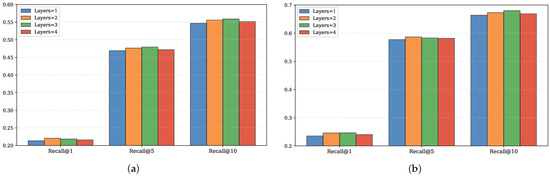
Figure 7.
The impact of attention layers; (a) impact on the NYC dataset, (b) Impact on the TKY dataset.
5. Conclusions
In this paper, we propose the MBSCL-Net model. This model uses a Multi-Branch Attention Fusion Network to independently process different modal information, capturing the features of each modality. It is also the first model to remove noise by transforming time-domain information into frequency-domain information and capture user periodic features for next-POI recommendation. Additionally, to prevent information loss during feature capture, we use skip connections to fuse the original information. Our model also enhances the modeling capability of user-personalized preferences through contrastive learning. Through experiments on two real-world datasets, we demonstrate that our model significantly outperforms current SOTA models and validate the effectiveness of its various components. In future work, we will introduce graph neural networks to handle the complex dependencies among different features, further improving the performance of next-POI recommendation.
Author Contributions
Conceptualization, S.W. and J.Z.; methodology, S.W.; software, S.W.; validation, S.W., J.Z. and T.Z.; formal analysis, S.W.; investigation, S.W.; resources, S.W.; data curation, S.W.; writing—original draft preparation, S.W.; writing—review and editing, S.W.; visualization, S.W.; supervision, S.W.; project administration, S.W.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Humanities and Social Science Fund of Ministry of Education (No. 24YJCZH416), the National Natural Science Foundation of China (No. 62403076).
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Correction Statement
This article has been republished with a minor correction to the Data Availability Statement. This change does not affect the scientific content of the article.
References
- Zhang, Z.; Li, C.; Wu, Z.; Sun, A.; Ye, D.; Luo, X. Next: A neural network framework for next poi recommendation. Front. Comput. Sci. 2020, 14, 314–333. [Google Scholar] [CrossRef]
- Feng, S.; Li, X.; Zeng, Y.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized ranking metric embedding for next new poi recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Jiang, S.; Qian, X.; Shen, J.; Fu, Y.; Mei, T. Author topic model-based collaborative filtering for personalized POI recommendations. IEEE Trans. Multimed. 2015, 17, 907–918. [Google Scholar] [CrossRef]
- Gambs, S.; Killijian, M.O.; del Prado Cortez, M.N. Next place prediction using mobility markov chains. In Proceedings of the First Workshop on Measurement, Privacy, and Mobility; Association for Computing Machinery: New York, NY, USA, 2012; pp. 1–6. [Google Scholar]
- Manotumruksa, J.; Macdonald, C.; Ounis, I. A deep recurrent collaborative filtering framework for venue recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1429–1438. [Google Scholar]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the next location: A recurrent model with spatial and temporal contexts. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Zhao, P.; Luo, A.; Liu, Y.; Xu, J.; Li, Z.; Zhuang, F.; Sheng, V.S.; Zhou, X. Where to go next: A spatio-temporal gated network for next poi recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 2512–2524. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Feng, J.; Li, Y.; Zhang, C.; Sun, F.; Meng, F.; Guo, A.; Jin, D. Deepmove: Predicting human mobility with attentional recurrent networks. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1459–1468. [Google Scholar]
- Luo, Y.; Liu, Q.; Liu, Z. Stan: Spatio-temporal attention network for next location recommendation. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2177–2185. [Google Scholar]
- Bashir, S.R.; Raza, S.; Misic, V.B. BERT4Loc: BERT for Location—POI recommender system. Future Internet 2023, 15, 213. [Google Scholar] [CrossRef]
- Yang, S.; Liu, J.; Zhao, K. GETNext: Trajectory flow map enhanced transformer for next POI recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1144–1153. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Dang, W.; Wang, H.; Pan, S.; Zhang, P.; Zhou, C.; Chen, X.; Wang, J. Predicting human mobility via graph convolutional dual-attentive networks. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 192–200. [Google Scholar]
- Wang, C.; Yuan, M.; Zhang, R.; Peng, K.; Liu, L. Efficient point-of-interest recommendation services with heterogenous hypergraph embedding. IEEE Trans. Serv. Comput. 2022, 16, 1132–1143. [Google Scholar] [CrossRef]
- Ju, W.; Qin, Y.; Qiao, Z.; Luo, X.; Wang, Y.; Fu, Y.; Zhang, M. Kernel-based substructure exploration for next POI recommendation. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 221–230. [Google Scholar]
- Qin, Y.; Wang, Y.; Sun, F.; Ju, W.; Hou, X.; Wang, Z.; Cheng, J.; Lei, J.; Zhang, M. DisenPOI: Disentangling sequential and geographical influence for point-of-interest recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, 27 February–3 March 2023; pp. 508–516. [Google Scholar]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Li, X. Tslanet: Rethinking transformers for time series representation learning. arXiv 2024, arXiv:2404.08472. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, Y.; Chung, F.l.; Liu, Y.; Chen, C.W. End-to-end personalized next location recommendation via contrastive user preference modeling. arXiv 2023, arXiv:2303.12507. [Google Scholar]
- Fu, J.; Gao, R.; Yu, Y.; Wu, J.; Li, J.; Liu, D.; Ye, Z. Contrastive graph learning long and short-term interests for POI recommendation. Expert Syst. Appl. 2024, 238, 121931. [Google Scholar] [CrossRef]
- Duan, C.; Fan, W.; Zhou, W.; Liu, H.; Wen, J. Clsprec: Contrastive learning of long and short-term preferences for next poi recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 473–482. [Google Scholar]
- Wen, Q.; Zhou, T.; Zhang, C.; Chen, W.; Ma, Z.; Yan, J.; Sun, L. Transformers in time series: A survey. arXiv 2022, arXiv:2202.07125. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence IJCAI, Beijing, China, 3–9 August 2013; Volume 13, pp. 2605–2611. [Google Scholar]
- Zhang, J.D.; Chow, C.Y.; Li, Y. Lore: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; pp. 103–112. [Google Scholar]
- Liu, Y.; Liu, C.; Liu, B.; Qu, M.; Xiong, H. Unified point-of-interest recommendation with temporal interval assessment. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1015–1024. [Google Scholar]
- Zhao, S.; Zhao, T.; Yang, H.; Lyu, M.; King, I. STELLAR: Spatial-temporal latent ranking for successive point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Personalized long-and short-term preference learning for next POI recommendation. IEEE Trans. Knowl. Data Eng. 2020, 34, 1944–1957. [Google Scholar] [CrossRef]
- Sun, K.; Qian, T.; Chen, T.; Liang, Y.; Nguyen, Q.V.H.; Yin, H. Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 214–221. [Google Scholar]
- Li, H.; Wang, B.; Xia, F.; Zhai, X.; Zhu, S.; Xu, Y. PG2Net: Personalized and Group Preferences Guided Network for Next Place Prediction. arXiv 2021, arXiv:2110.08266. [Google Scholar]
- Li, S.; Chen, W.; Wang, B.; Huang, C.; Yu, Y.; Dong, J. Mcn4rec: Multi-level collaborative neural network for next location recommendation. ACM Trans. Inf. Syst. 2024, 42, 1–26. [Google Scholar] [CrossRef]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis. arXiv 2022, arXiv:2210.02186. [Google Scholar]
- Yi, K.; Zhang, Q.; Fan, W.; Wang, S.; Wang, P.; He, H.; An, N.; Lian, D.; Cao, L.; Niu, Z. Frequency-domain mlps are more effective learners in time series forecasting. Adv. Neural Inf. Process. Syst. 2023, 36, 76656–76679. [Google Scholar]
- Xu, Z.; Zeng, A.; Xu, Q. FITS: Modeling time series with 10k parameters. arXiv 2023, arXiv:2307.03756. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph contrastive learning with augmentations. Adv. Neural Inf. Process. Syst. 2020, 33, 5812–5823. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PmLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Yue, Z.; Wang, Y.; Duan, J.; Yang, T.; Huang, C.; Tong, Y.; Xu, B. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 8980–8987. [Google Scholar]
- Eldele, E.; Ragab, M.; Chen, Z.; Wu, M.; Kwoh, C.K.; Li, X.; Guan, C. Time-series representation learning via temporal and contextual contrasting. arXiv 2021, arXiv:2106.14112. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar] [CrossRef]
- Liu, H.; Ding, J.; Zhu, Y.; Tang, F.; Yu, J.; Jiang, R.; Guo, Z. Modeling multi-aspect preferences and intents for multi-behavioral sequential recommendation. Knowl.-Based Syst. 2023, 280, 111013. [Google Scholar] [CrossRef]
- Song, X.; Zhang, J.; Liang, D.; Zhang, Z.; Cai, J.; Hu, L. Adaptive Dual Cross-Attention Network for Multispectral Object Detection. In Proceedings of the International Conference on Intelligent Computing, Ningbo, China, 26–29 July 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 139–150. [Google Scholar]
- Wu, J.; Zhang, J.; Zhu, J.; Duan, Y.; Fang, Y.; Zhu, J.; Yin, L.; Jiang, J.; He, Z.; Huang, Y.; et al. Multi-scale convolution and dynamic task interaction detection head for efficient lightweight plum detection. Food Bioprod. Process. 2025, 149, 353–367. [Google Scholar] [CrossRef]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Wang, B.; Zhang, Q.; Zhu, S.; Ma, Y. Hypergraph User Embeddings and Session Contrastive Learning for POI Recommendation. IEEE Access 2025, 13, 17983–17995. [Google Scholar] [CrossRef]
- Li, R.; Shen, Y.; Zhu, Y. Next point-of-interest recommendation with temporal and multi-level context attention. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1110–1115. [Google Scholar]
- Huang, L.; Ma, Y.; Liu, Y.; He, K. DAN-SNR: A deep attentive network for social-aware next point-of-interest recommendation. ACM Trans. Internet Technol. (TOIT) 2020, 21, 1–27. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).