Abstract
Functional near-infrared spectroscopy (fNIRS) offers a safe and portable signal source for brain–computer interface (BCI) applications, particularly in motor imagery (MI) decoding. However, its low sampling rate and hemodynamic delay pose challenges for temporal modeling and dynamic brain network analysis. To address these limitations in temporal dynamics, static graph modeling, and feature fusion interpretability, we propose TopoTempNet, an innovative topology-enhanced temporal network for biomedical signal decoding. TopoTempNet integrates multi-level graph features with temporal modeling through three key innovations: (1) multi-level topological feature construction using local and global functional connectivity metrics (e.g., connection strength, density, global efficiency); (2) a graph-modulated attention mechanism combining Transformer and Bi-LSTM to dynamically model key connections; and (3) a multimodal fusion strategy uniting raw signals, graph structures, and temporal representations into a high-dimensional discriminative space. Evaluated on three public fNIRS datasets (MA, WG, UFFT), TopoTempNet achieves superior accuracy (up to 90.04% ± 3.53%) and Kappa scores compared to state-of-the-art models. The ROC curves and t-SNE visualizations confirm its excellent feature discrimination and structural clarity. Furthermore, the statistical analysis of graph features reveals the model’s ability to capture task-specific functional connectivity patterns, enhancing the interpretability of decoding outcomes. TopoTempNet provides a novel pathway for building interpretable and high-performance BCI systems based on fNIRS.
1. Introduction
Brain–computer interface (BCI), as a cutting-edge technology enabling direct information exchange between the brain and external devices, is particularly valuable for assisting individuals with motor impairments in achieving non-muscle-dependent intent expression. Among BCI modalities, functional near-infrared spectroscopy (fNIRS) has garnered significant attention in recent research due to its non-invasiveness, portability, and excellent user adaptability [1,2]. By detecting absorption changes in near-infrared light (650–950 nm wavelength) [3], fNIRS records dynamic concentration variations in oxygenated hemoglobin (HbO) and deoxygenated hemoglobin (HbR) in the cerebral cortex, thereby indirectly reflecting hemodynamic responses evoked by neural activity [4]. Combined with the motor imagery (MI) paradigm, fNIRS-based BCI systems offer a safe and efficient neural signal decoding solution for patients with motor disabilities [5].
To further enhance decoding performance in MI tasks, researchers have progressively explored the multimodal fusion of electroencephalography (EEG) and fNIRS [6,7]. EEG provides millisecond-level temporal resolution [8], enabling real-time monitoring of neuronal population electrical activity [9], while fNIRS delivers spatial information on neurovascular coupling [10], rendering the two modalities highly complementary in spatiotemporal dimensions. For instance, Cooney et al. proposed an EEG-fNIRS hybrid BCI using dual convolutional networks for speech decoding, where concatenated EEG and fNIRS features were fed into a gated recurrent unit (GRU) layer [11]. Similarly, Arif et al. achieved cross-subject mental state recognition by fusing spatiotemporal features of EEG and fNIRS [7].
However, despite EEG’s inherent advantage in temporal resolution, its practical application faces multiple challenges. On the one hand, EEG is highly susceptible to physiological and environmental noise such as ocular/muscular artifacts and powerline interference [12,13,14], with noise control becoming particularly difficult during natural or movement conditions [15]. Wang et al. systematically verified the anti-interference advantages of fNIRS: quantitative comparisons showed superior resistance to motion and electromagnetic artifacts compared with fMRI, PET, and EEG; in practice, it is suitable for children and multi-electromagnetic environments; and in principle, it relies on near-infrared light to detect hemoglobin changes, inherently providing strong noise resistance [16].
Current fNIRS-based signal decoding methods predominantly adopt a four-stage pipeline: signal acquisition, preprocessing, feature extraction, and state classification. Feature extraction typically relies on manually designed statistical metrics including mean, variance, and slope coupled with traditional classifiers like SVM, LDA, or RF [17,18,19]. Such approaches heavily depend on handcrafted feature selection and domain expertise, constraining their generalization capability. Recently, deep learning has emerged as a mainstream technical pathway for fNIRS decoding. For example, Rojas et al. demonstrated superior performance of deep learning models such as CNN and LSTM over machine learning in pain type identification [20]. In neuroscience research, graph-based methods leverage connectivity metrics such as Pearson correlation coefficient (PCC), phase lag index (PLI), and phase locking value (PLV) to holistically analyze brain networks [21]. Representative works include Wang et al.’s fNIRSNet incorporating hemodynamic delay characteristics [22] and Cheng et al.’s approach for transforming fNIRS time series into 2D images via Gramian Angular Field fused with cognitive scale data at the decision level to improve diagnostic accuracy for amnestic mild cognitive impairment (aMCI) [23].
The inherent functional connectivity information embedded in fNIRS signals has propelled graph-based modeling into a research hotspot. To precisely capture inter-regional brain collaboration patterns, researchers have introduced learnable and dynamically updated graph structures. For instance, Seo et al. constructed PCC-based graphs with channels as nodes and inter-channel connections as edges, and then extracted functional connectivity patterns using graph convolutional networks (GCNs) [24], while Yu et al. employed coherence-based graphs with GCNs for spatiotemporal feature extraction in depression recognition [25], achieving notable improvements in decoding performance and interpretability.
Furthermore, to mitigate overfitting in fNIRS deep learning models, strategies including multimodal fusion, data augmentation, and adaptive receptive field design have been proposed [26,27,28]. Examples include the GCN-CA-CapsNet model for EEG-fNIRS emotion recognition, which fused features via Pearson correlation graphs and optimized accuracy using capsule attention mechanisms [29]. Graph theory, as a tool for modeling system elements and interactions via nodes and edges, exhibits unique advantages in brain network analysis [30]. For fNIRS channel connectivity, metrics like average degree and global efficiency have been applied to quantify functional connectivity in the dorsolateral prefrontal cortex (DLPFC) [31].
Despite these advances, critical challenges that remain are as follows: 1. Inadequate temporal modeling: most models fail to adapt to fNIRS’s low sampling rate and delayed response characteristics, limiting dynamic feature extraction. 2. Static graph structures: graph construction often relies on fixed or manual designs, unable to reflect dynamic functional connectivity during cognitive processes. 3. Weak feature fusion and interpretability: insufficient multi-scale feature integration and neural network interpretability hinder further performance gains.
To address these issues, this paper proposes TopoTempNet, a novel fNIRS-MI classification method integrating graph theory and temporal dynamic modeling, with three key contributions: 1. Multi-level graph feature modeling: constructs local channel pair and global whole-network functional connectivity graphs, extracting metrics including connection strength, density, Reciprocal of Functional Signal Mean Difference (RFSMD), and global efficiency to unify local–global brain network relationships. 2. Graph-enhanced temporal architecture: designs a hybrid temporal network combining Transformer and Bi-LSTM with graph attention to highlight critical channel pairs, capturing spatiotemporal dynamics and structural dependencies. 3. Multi-source fusion mechanism: combines raw signals, graph features, and temporal representations into a high-dimensional fusion space, boosting decoding accuracy and cross-subject generalization.
Experimental results demonstrate significant performance improvements over state-of-the-art methods on multiple fNIRS datasets, providing robust support for dynamic modeling of complex brain networks and differential region identification.
2. Materials and Methods
2.1. Selected Dataset
To evaluate the effectiveness of the proposed TopoTempNet, experiments were conducted on three publicly available datasets.
2.1.1. MA Dataset [32]
This dataset includes 29 participants (mean age: 28.5 ± 3.7 years). During experiments, participants performed mental arithmetic (MA) tasks and baseline (BL) tasks. In MA tasks, participants memorized arithmetic expressions displayed on-screen and performed consecutive addition/subtraction operations. BL tasks required participants to remain motionless without additional instructions. Each trial began with a 2 s cue period, followed by a 10 s task execution phase, with 15–17 s of rest between trials. Each participant completed three experimental blocks, with 10 MA and 10 BL trials per block.
2.1.2. WG Dataset [33]
Comprising 26 subjects (mean age: 26.1 ± 3.5 years), this dataset involved word generation (WG) and baseline (BL) tasks. During WG tasks, subjects generated as many words as possible starting with a displayed letter within a time limit, while BL tasks required quiet rest. Each task type was repeated 30 times, with 10 s task durations and 13–15 s of rest intervals.
2.1.3. UFFT Dataset [34]
This dataset contains fNIRS signals from 30 volunteers (17 males) performing three motor tasks: right-hand tapping (RHT), left-hand tapping (LHT), and foot tapping (FT), with 25 trials per task. Each trial consisted of a 2 s cue phase, a 10 s execution phase, and 17–19 s of rest.
2.2. Data Preprocessing
The near-infrared spectroscopy (NIRS) acquisition system records raw optical density changes (), which are converted to oxygenated hemoglobin ) and deoxygenated hemoglobin ) concentration changes using the modified Beer–Lambert law [35]. The mathematical formulation is as follows:
where and denote the extinction coefficients of HbO and HbR at wavelength , is the differential pathlength factor, and represents the source–detector separation distance.
Following the protocols described in the respective dataset references, the NIRS signals for MA and WG were downsampled to 10 Hz, while UTTF maintained its original 13.3 Hz sampling rate. Since raw fNIRS signals contain instrument noise, physiological noise, and motion artifacts, task-specific filtering strategies were applied, i.e., MA and UTTF: bandpass filter (0.01–0.1 Hz); WG: lowpass filter (cutoff: 0.2 Hz).
Subsequently, signals were segmented into non-overlapping 1 s epochs. To account for hemodynamic response delays, each epoch included pre- and post-stimulus periods to ensure the complete capture of task-related dynamics. Baseline correction was performed by subtracting the mean value of the pre-stimulus reference interval from each fNIRS epoch to mitigate drift.
As illustrated in Figure 1, the proposed TopoTempNet framework is designed for multi-class time series signal classification. Its core innovation lies in a multi-level graph-theoretic feature extraction framework that quantifies inter-channel functional connectivity patterns (local associations and global network properties), integrated with a hybrid GAM-Bi-LSTM architecture for precise temporal pattern classification.
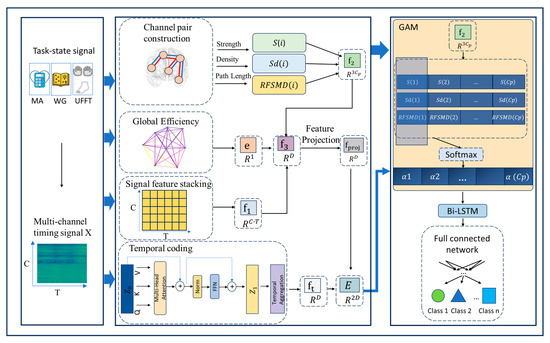
Figure 1.
The overall architecture of the model.
2.3. Data Structure Definition
The model input data are represented as a multichannel temporal signal matrix:
where denotes the total number of channels, and represents the number of time points in each signal segment. To further model the pairing relationships between channels, let , meaning that all channels are grouped into pairs, with each pair corresponding to a potential functional connection.
To construct the initial feature representation, is stacked column-wise and reshaped into a one-dimensional vector as follows:
This vector serves as the foundational feature representation, preserving the joint information across channels and time dimensions from the original temporal signals, thereby providing the input basis for subsequent graph-structured and temporal modeling.
2.4. Channel Pair Construction
To more effectively model the functional connectivity between brain regions, this study converts the raw optical density change signals using the modified Beer–Lambert law to extract the concentration changes in oxygenated hemoglobin (HbO) and deoxygenated hemoglobin (HbR). Since each measurement channel contains both HbO and HbR hemodynamic signals, this study treats them as the fundamental unit of functional coupling—referred to as a channel pair—with a total of pairs.
2.5. Graph-Theoretic Feature Extraction Module
This module aims to extract two types of key features from fNIRS signals through graph-theoretic analysis: local connectivity features (based on channel pairs) and global topological features (based on the overall network structure), incorporating both raw signal characteristics and functional connectivity features.
2.5.1. Local Feature Extraction of Homologous Channel Pairs
For each channel pair (the -th pair), its local functional connectivity characteristics are quantified from the following three aspects:
- Connection Strength: it is defined as the normalized Pearson correlation coefficient, measuring the linear association between the channels in the pair.
- Connection Density: it is defined as the proportion of significant correlations within a sliding window, measuring the stability of the connection.
- Reciprocal of Functional Signal Mean Difference (RFSMD): it is defined as the reciprocal of the mean difference between two channel signals, used to quantify the efficiency of functional information transfer between channel pairs.
2.5.2. Global Network Feature Extraction
A functional connectivity graph is constructed at the full-channel scale, and topological metrics of the overall brain network are extracted.
- Construction of the Functional Connectivity Network
An adjacency matrix is constructed to indicate whether a significant functional connection exists between channels:
where ρ(·) denotes the Pearson correlation coefficient, and 0.3 is the global connection threshold. = 1 indicates that a significant functional connection exists between the two corresponding channels.
- Global Efficiency
It is defined as the average of the inverse shortest path lengths between all pairs of nodes in the network, and global efficiency measures the average efficiency of information transfer across the entire network. It is formally defined as follows:
where denotes the shortest path length between nodes and , calculated based on the adjacency matrix A. The global efficiency [0, 1], with higher values indicating more efficient global information transfer within the network.
2.6. Feature Fusion Module
To integrate information from multiple sources, this study designs a feature fusion mechanism that concatenates the raw temporal signal features, graph-theoretic local connectivity features, and global topological metrics into a unified representation. The details are as follows:
where , and is the vector formed by sequentially stacking the local features of all channel pairs. The dimension of the fused feature vector is D = C .
2.7. Temporal Modeling Module
2.7.1. Transformer Temporal Encoding [36]
To model the temporal dynamics of fNIRS signals, this study introduces a Transformer module to encode the channel pair signals. The specific steps are as follows:
- Input Projection: the dual-channel signals (HbO and HbR) of each channel pair are mapped into a high-dimensional feature space:where , with d representing the feature dimension; is the projection weight matrix, and is the bias vector.
- Transformer Encoding: A standard Transformer layer is applied to model the temporal dependencies within the time series of each channel pair, capturing relationships across different time points:
- Temporal Aggregation: average pooling is performed along the temporal dimension to obtain an overall temporal representation for each channel pairwhere and represents the features of at the t-th time point.
2.7.2. Feature Projection and Fusion
To achieve the unified alignment of features from different sources, the fused feature is projected into the same feature space dimension as the Transformer output:
where is the projected fused feature, is the projection weight matrix, and is the bias vector. This is then further fused with the temporal features extracted by the Transformer to construct a unified input representation:
where . This process jointly represents structural (graph-theoretic) and dynamic (temporal) features on a unified scale, providing the foundation for subsequent attention modulation and decoding.
2.7.3. Graph-Theoretic Temporal Association Network Module
This module integrates the topological characteristics of the functional connectivity network with temporal dynamics through graph-theory-guided gated sequence modeling. The core lies in the design of a graph attention mechanism (GAM), which enables the precise capture of dynamic relationships between channel pairs by fusing the output features of the subsequent Bi-LSTM. Specifically, GAM utilizes weights derived from graph-theoretic metrics (such as connection strength) to modulate the input sequence to LSTM. By introducing graph structural priors into the gating layer, it achieves topology-aware temporal attention modeling.
Graph Attention Mechanism (GAM): It assigns differentiated semantic weights to different channel pairs. For the i-th channel pair, the attention weight is defined as follows:
where is the learnable attention weight matrix, producing the attention weights for the channel pairs.
2.7.4. Bidirectional Temporal Association Modeling (Bi-LSTM)
The Bidirectional Temporal Association Modeling (Bi-LSTM) module aims to capture bidirectional temporal dependencies in the fused feature sequences using forward and backward LSTM units (as shown in Figure 2), and enhances attention to dynamic patterns of critical channel pairs by incorporating graph-theoretic attention weights.
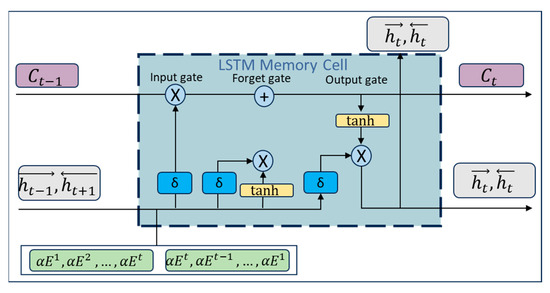
Figure 2.
LSTM module structure.
Input Data: The input consists of the fused feature sequence E (formed by concatenating temporal features from the Transformer and projected graph-theoretic features, ) and the graph attention weights (from the GAM module, ). Here, is used to modulate the LSTM’s focus on channel pairs with strong functional connectivity.
Gating Mechanism and Equations: each LSTM unit updates its state dynamically through the forget gate, input gate, and output gate, where all gating operations incorporate the attention weights :
Forget Gate: It determines the proportion of the historical hidden state to retain. The formula is as follows:
where is the weight matrix of the forget gate, is the bias term, is the sigmoid activation function, and denotes the forward hidden state from the previous time step.
Input Gate: it regulates the contribution of new features to the current cell state.
where is the input gate weight matrix, and is the bias term.
Cell State Update:
where is the weight matrix for the cell state, is the bias term, and ⊙ denotes element-wise multiplication.
Output Gate: it generates the current hidden state.
where is the output gate weight matrix, is the bias term, and is the current forward hidden state.
Bidirectional Modeling Output:
The final output is obtained by concatenating the forward and backward hidden states: , where h is the dimension of the hidden layer.
2.8. Classification Module
The classification layer takes the fused features and temporal association features as inputs and outputs the classification results through a multilayer perceptron (MLP).
2.8.1. Input Feature Definition
The fused features and temporal association features are concatenated and integrated through a linear transformation to form the input representation:
where is the learnable weight matrix (with mm denoting the dimension of the intermediate layer), is the bias vector, and represents the intermediate classification feature.
2.8.2. Nonlinear Activation
The ReLU function is applied to enhance the nonlinear representation capability of the features:
2.8.3. Classification Output
The final classification probability distribution is produced via a fully connected layer followed by a Softmax function:
where (with KK denoting the number of classes), is the output bias, and represents the probability distribution.
3. Experimental
3.1. Experimental Setup
All experiments were conducted on a GPU server with CUDA-compatible drivers using the PyTorch (v2.7.1) framework. The model was trained with the Adam optimizer [37] (learning rate = 1 × 10−3, weight decay = 1 × 10−4). A ReduceLROnPlateau scheduler [38] adjusted the learning rate based on validation accuracy.
Training used 5-fold cross-validation per subject, with a batch size of 5 and a maximum of 200 epochs. To prevent overfitting, dropout was applied in two modules:
- Bi-LSTM Module: a 0.1 dropout rate after temporal feature projection.
- Classifier Module: a 0.2 dropout rate in the intermediate MLP layer to enhance robustness and generalization.
3.2. Evaluation Metrics
Model performance was evaluated using standard classification metrics:
Accuracy: it measures overall prediction correctness.
ROC and AUC: the ROC curve evaluates classifier performance, with AUC indicating the model’s overall effectiveness (closer to 1 is better).
Cohen’s Kappa: it assesses agreement beyond chance, especially under class imbalance.
where
Higher Kappa values indicate more reliable and consistent classification.
4. Results and Discussion
Figure 3 presents the average subject-wise confusion matrices under three tasks: two binary classification tasks (mental arithmetic versus baseline, word generation versus baseline) and one three-class motor imagery task (right-hand imagery, left-hand imagery, foot imagery). In the mental arithmetic versus baseline task, an average of 90 percent of real MA samples were correctly predicted as MA, while 10 percent were misclassified as BL. Similarly, 90 percent of real BL samples were correctly recognized, with 10 percent misclassified as MA, demonstrating good classification performance for this task. In the word generation versus baseline task, 83.33 percent of real WG samples were correctly identified, while 16.66 percent were misclassified as BL. Meanwhile, 80 percent of BL samples were correctly classified, and 20 percent were misclassified as WG. For the three-class motor imagery task, 85 percent of RHF samples were correctly classified, 10 percent misclassified as LHF, and 5 percent as FT. Among the LHF samples, 80 percent were correctly identified, 5 percent misclassified as RHF, and 15 percent as FT. For FT samples, 70 percent were correctly classified, while 15 percent were misclassified as RHF and another 15 percent as LHF. These matrices intuitively illustrate the model’s average classification performance across different tasks by presenting the proportions of correct and incorrect classifications for each class.
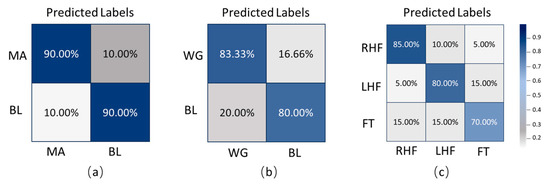
Figure 3.
Average confusion matrices of the proposed TopoTempNet model: (a) MA dataset, (b) WG dataset, and (c) UFFT dataset.
4.1. Comparative Experiments
4.1.1. Subject-Specific Evaluation
In this study, the proposed TopoTempNet model is systematically benchmarked against a series of structurally comparable baseline methods. To ensure rigor and reproducibility, all baseline models were faithfully re-implemented according to the hyperparameter configurations reported in their original publications. Furthermore, the entire preprocessing pipeline, input representation, and training and evaluation protocols were standardized across all models for a fair comparison.
The comparative results, encompassing both classification accuracy (Acc) and inference time (IT), are summarized in Table 1. Here, Acc denotes the predictive accuracy of the model, while IT quantifies the computational cost incurred during the inference stage. The baseline methods under evaluation are detailed as follows:
- CNN [39]: It consists of three convolutional layers and two dense layers. The input is the Δ[HbO2] and ΔHbR data stacked along a new dimension after separation.
- LSTM [39]: A basic three-layer Long Short-Term Memory model with a hidden size of 20. The input includes the unseparated Δ[HbO2] and ΔHbR signals [37].
- PVTv2-B0 [40]: A vision Transformer model using 4 × 4 patches and an eight-layer structure. Multichannel GADF-transformed virtual images are used as input.
- MLP-Mixer [40]: An eight-layer MLP-Mixer model based on 4 × 4 patches, which captures features through channel-mixing and spatial-mixing MLPs. It also takes multichannel GADF-transformed virtual images as input.
- fNIRS-T [41]: A Transformer-based classification model designed to capture long-range dependencies in fNIRS signals.
- FCS-TPNet [42]: It learns delayed hemodynamic features and captures the correlation between HbO and HbR through a dual-signal interaction module. A dynamic graph convolution module is employed to extract complex topological patterns between channels for fNIRS signal classification.

Table 1.
Performance comparison of different models on three public datasets (bold indicates the best performance). Acc denotes model accuracy, and IT denotes inference time.
Table 1.
Performance comparison of different models on three public datasets (bold indicates the best performance). Acc denotes model accuracy, and IT denotes inference time.
| Method | MA | WG | UFFT | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc (%) | Kappa | IT | Acc (%) | Kappa | IT | Acc (%) | Kappa | IT | |
| CNN | 72.23 ± 3.36 | 0.52 | 1.70 ± 0.11 | 69.73 ± 2.12 | 0.40 | 1.66 ± 0.12 | 70.02 ± 5.22 | 0.58 | 1.69 ± 0.23 |
| LSTM | 73.50 ± 10.74 | 0.61 | 1.84 ± 0.33 | 71.20 ± 7.38 | 0.41 | 1.71 ± 0.15 | 70.28 ± 4.16 | 0.58 | 1.70 ± 0.16 |
| PVTv2-B0 | 78.26 ± 6.59 | 0.64 | 2.12 ± 0.44 | 72.88 ± 6.22 | 0.44 | 1.85 ± 0.23 | 72.08 ± 4.98 | 0.59 | 1.92 ± 0.53 |
| MLP-MIXer | 78.73 ± 6.76 | 0.64 | 3.96 ± 0.24 | 76.44 ± 4.36 | 0.58 | 6.54 ± 0.68 | 72.51 ± 3.46 | 0.53 | 2.12 ± 0.44 |
| fNIRS-T | 78.96 ± 4.38 | 0.65 | 1.90 ± 0.44 | 76.50 ± 4.17 | 0.49 | 1.75 ± 0.38 | 79.21 ± 3.44 | 0.64 | 1.95 ± 0.43 |
| FCS-TPNet | 80.02 ± 4.12 | 0.60 | 2.03 ± 0.53 | 76.36 ± 3.38 | 0.46 | 8.99 ± 0.45 | 79.26 ± 3.16 | 0.66 | 3.68 ± 0.82 |
| TopoTempNet (Ours) | 90.04 ± 3.53 | 0.77 | 1.91 ± 0.40 | 78.33 ± 5.42 | 0.62 | 1.76 ± 0.12 | 81.66 ± 3.23 | 0.68 | 1.91 ± 0.44 |
4.1.2. ROC Curve Analysis of Different Models in Multi-Task fNIRS Classification
In this study, we further analyzed the performance of the TopoTempNet model on three different task datasets. The horizontal axis represents the false positive rate (FPR), and the vertical axis represents the true positive rate (TPR). Different colored curves correspond to different models. The corresponding ROC curves are shown in Figure 4.
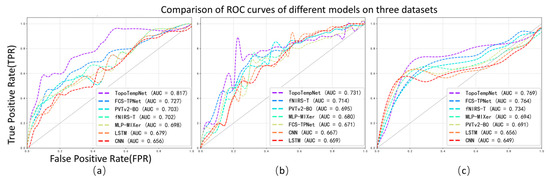
Figure 4.
Average ROC curves and corresponding AUC values of different models across the three datasets.
Figure 4a: The horizontal axis is the false positive rate (FPR), and the vertical axis is the true positive rate (TPR), with different colors representing various models. TopoTempNet (AUC = 0.817) stands out with its curve closer to the top-left corner, indicating stronger ability to correctly identify true positives while avoiding false positives in distinguishing brain signals related to the mental arithmetic task. Compared to other models, such as FCS-TPNet (AUC = 0.727) and fNIRS-T (AUC = 0.702), whose curves lie relatively lower with smaller AUC values, their performance in recognizing the mental arithmetic state is weaker than TopoTempNet, highlighting TopoTempNet’s advantage in classifying brain signals for this task.
Figure 4b: TopoTempNet (AUC = 0.769) again shows a curve closer to the top-left corner, with a higher AUC than other models. Models like FCS-TPNet (AUC = 0.764) and fNIRS-T (AUC = 0.734) have curves and AUC values indicating that their balance between correct and incorrect classifications in distinguishing brain signals during the word generation imagination task is inferior to TopoTempNet. This demonstrates TopoTempNet’s strong performance in classifying language imagination-related brain signals.
Figure 4c: TopoTempNet’s curve (AUC = 0.731) remains closer to the ideal top-left region across most intervals. Compared to models like fNIRS-T (AUC = 0.714) and FCS-TPNet (AUC = 0.671), their curves and AUC values show that, when handling multi-class motor imagery classification (distinguishing different motor intentions), TopoTempNet better captures complex motor imagery features and achieves more accurate classification, demonstrating a performance advantage in this complex scenario.
In summary, across all three figures, TopoTempNet’s ROC curves and AUC values lead the comparisons, indicating that for fNIRS signal classification in MA (mental arithmetic), WG (word generation imagination), and UFFT (motor imagery) tasks, it can more precisely identify target states and deliver superior classification performance compared to other models.
4.1.3. Subject-Independent Evaluation
To assess the generalization ability of the TopoTempNet model on unseen subjects, this study adopts the Leave-One-Subject-Out Cross-Validation (LOSO-CV) strategy across all three datasets. In this method, during each iteration, the data from one subject are used as the test set, while the remaining data from all other subjects are used for training. This approach provides a comprehensive evaluation of the model’s adaptability and stability in handling inter-subject variability.
The process is repeated until every subject has served once as the test case. The final reported performance metrics are the average results across all subjects, aiming to objectively reflect the decoding performance and generalization ability of the model in cross-subject scenarios. The comparison results are summarized in Table 2.
Table 2.
LOSO-CV results for the three datasets. Bold values indicate the best performance for each evaluation metric.
4.2. Validation of TopoTempNet’s Capability in Extracting Brain Dynamic Patterns
4.2.1. t-SNE Visualization of Learned Feature Distributions
t-SNE (t-distributed Stochastic Neighbor Embedding) [43] is a widely used nonlinear dimensionality reduction method for visualizing high-dimensional features. It preserves local structures while mapping complex features into a two-dimensional space, effectively illustrating class separability.
Figure 5 shows the low-dimensional representations of the MA, WG, and UFFT tasks in both the original feature space and after encoding by TopoTempNet. The results indicate that, in the original feature space, task distributions are scattered with significant class overlap and unclear boundaries. After TopoTempNet encoding, distinct clusters corresponding to different task states emerge clearly in the low-dimensional space, strongly demonstrating TopoTempNet’s effectiveness in enhancing feature discriminability and extracting key brain dynamic patterns.
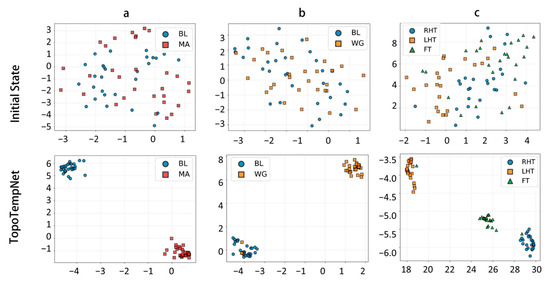
Figure 5.
t-SNE visualizations of different datasets: (a) MA dataset, (b) WG dataset, and (c) UFFT dataset.
4.2.2. Graph Theory Feature Analysis
Connectivity Strength Interpretability Analysis
As shown in the violin plot of connectivity strength (Figure 6), distinct distribution patterns are observed across significant channel pairs in the MA (mental arithmetic), WG (word generation imagination), and UFFT (motor imagery) datasets. In certain channel pairs, the connectivity strength of the MA group is concentrated in the mid-to-high range, whereas the WG group shows a greater spread in the lower range. The UFFT group, on the other hand, exhibits unique distribution patterns in some channel pairs, differing from the other two. These findings suggest that the degree of inter-channel connectivity varies in a task-specific manner, reflecting potentially distinct neural cooperation mechanisms underlying different cognitive processes such as calculation, language generation, and motor imagery.
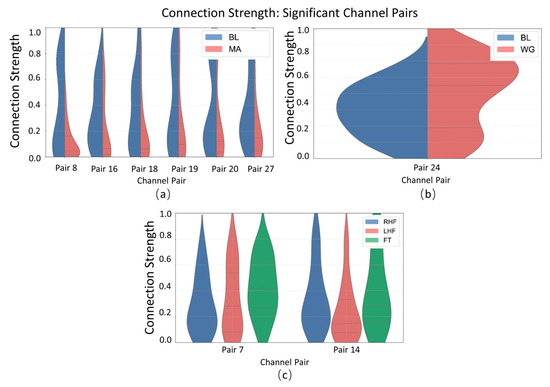
Figure 6.
Statistical significance analysis of local channel connection strength on different datasets: (a) MA dataset, (b) WG dataset, and (c) UFFT dataset.
Connectivity Density Interpretability Analysis
The boxplot of connectivity density (Figure 7) reveals the dispersion and central tendency of significant channel pairs across the MA (mental arithmetic), WG (word generation imagination), and UFFT (motor imagery) groups. In certain channel pairs, the MA group shows notable differences in median and interquartile range compared to the WG and UFFT groups, indicating a task-specific pattern of “connectivity activity frequency” in the corresponding brain regions during mental arithmetic. Additionally, the distribution of outliers varies among groups—MA exhibits more extreme high values in some channel pairs, which may suggest that the mental arithmetic task elicits statistically significant, high-frequency atypical connections in specific brain regions. Meanwhile, the density characteristics observed in the WG and UFFT groups also align with their respective task-related neural mechanisms.
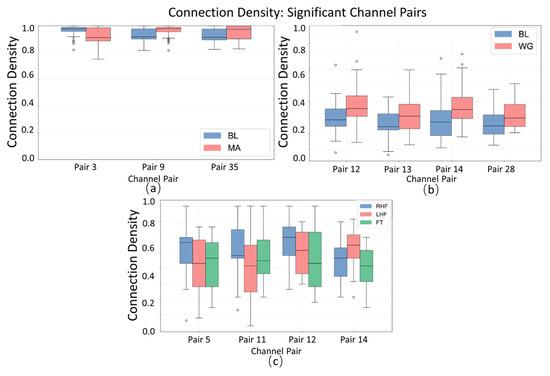
Figure 7.
Statistical significance analysis of local channel connection density on different datasets, Circles represent outlier data points, defined as values exceeding 1.5 times the interquartile range (IQR) from the box edges in boxplot visualization.: (a) MA dataset, (b) WG dataset, and (c) UFFT dataset.
Reciprocal of Functional Signal Mean Difference Interpretability Analysis
The bar chart with error bars (Figure 8), representing the mean and standard deviation, illustrates clear differences in Reciprocal of Functional Signal Mean Difference (RFSMD) across significant channel pairs for the MA (mental arithmetic), WG (word generation imagination), and UFFT (motor imagery) groups. In certain channel pairs, the MA group shows higher average RFSMD values compared to the others, suggesting more efficient signal transmission and faster neural information integration in the corresponding brain regions during mental arithmetic. The WG group, on the other hand, exhibits lower average RFSMD values in some channel pairs, indicating that information flow may be less efficient under the word generation task, reflecting a distinct neural routing pattern. For the UFFT group, the observed RFSMD features align with the hypothesis that motor imagery requires rapid integration into motor-related regions (evidenced by relatively high RFSMD values in motor cortex-associated channel pairs), but may involve varying transmission efficiencies across different areas (reflected by uneven RFSMD distributions). Additionally, differences in the lengths of error bars between groups reflect variability in neural activity—shorter error bars in some MA group channel pairs suggest more consistent RFSMD values across individuals, indicating a relatively stable neural activation pattern during mental arithmetic.
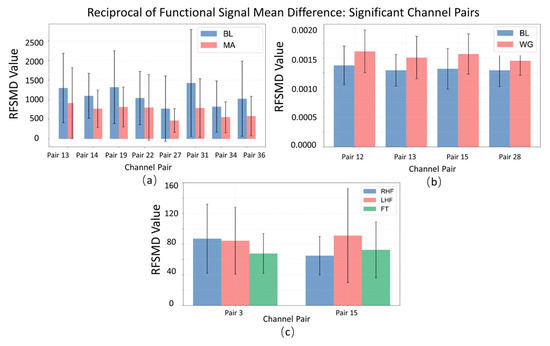
Figure 8.
Statistical significance analysis of local channel characteristic RFSMD on different datasets: (a) MA dataset, (b) WG dataset, and (c) UFFT dataset.
4.2.3. Neurophysiological Plausibility of TopoTempNet Features
As shown in Figure 9, in the MA dataset (mental arithmetic task), significant channels were primarily distributed across the bilateral prefrontal cortex, encompassing both ventromedial and dorsolateral prefrontal regions (DLPFC). This distribution reflects the reliance of mental arithmetic on working memory, executive control, and numerical cognition. In contrast, in the WG dataset (word generation task), significant channels were concentrated in the right prefrontal cortex, underscoring its role in letter-guided lexical retrieval and semantic selection in coordination with left-hemisphere language areas. Overall, the observed “prefrontal–parietal” co-activation pattern captured by the model is consistent with previously reported task-related activation mechanisms [44], thereby supporting the neurophysiological plausibility of the topological features extracted by TopoTempNet. The UFFT dataset was not analyzed due to unavailable montage location information.
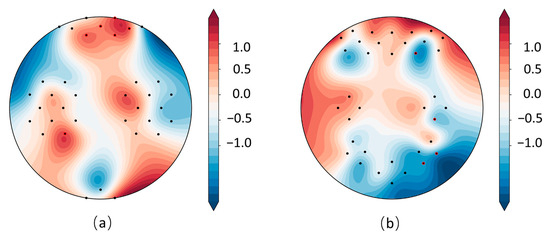
Figure 9.
MA (a) and WG (b) dataset heatmaps, with red channels indicating significant connections (p < 0.05).
4.3. Ablation Analysis
4.3.1. Module Ablation
To evaluate the effectiveness of each core module in the TopoTempNet model, ablation experiments were conducted on the three fNIRS datasets (MA, WG, UFFT) to analyze the impact of different submodules on overall performance. The ablation results are shown in Table 3, indicating that the graph theory feature module, graph attention mechanism, and bidirectional temporal modeling module each play unique yet indispensable roles across all three fNIRS datasets.
Table 3.
Ablation analysis of key modules in the TopoTempNet model.
The fully integrated model combining all three modules achieved the highest accuracies of 90.04 ± 3.53, 78.33 ± 5.42, and 81.66 ± 3.23 on the MA, WG, and UFFT datasets, respectively, highlighting the synergistic benefits among these modules and providing robust support for task recognition and neural dynamic modeling.
4.3.2. Ablation Study on the Effects of Global Connectivity Thresholds
The ablation experiments on global connection thresholds revealed task-specific sensitivities in both average efficiency (AE) and classification accuracy (Acc). For the mental arithmetic task, the optimal threshold was 0.3 (AE = 96.98, Acc = 90.04 ± 3.53%), with lower thresholds introducing noise (0.1: Acc = 88.43 ± 1.62%) and higher thresholds filtering out key links (0.5: Acc = 85.44 ± 4.37%). In the motor imagery task, accuracy was stable at low thresholds (0.1–0.2: 81.23–81.57%), while AE decreased as thresholds rose, with the best trade-off again at 0.3 (AE = 98.99, Acc = 81.66 ± 3.23%). The word generation task showed the highest sensitivity, with 0.3 yielding AE = 76.10 and Acc = 78.33 ± 5.42%, but performance fluctuated at lower thresholds (0.2: Acc = 83.33 ± 2.63%) and sharply declined at higher ones (0.5: Acc = 66.67 ± 8.33%). Overall, the results indicate that mental arithmetic requires precise threshold tuning, motor imagery is more robust, and word generation is highly sensitive, offering task-specific guidance for optimizing connectivity thresholds in BCI applications. The results are summarized in Table 4.
Table 4.
Summary of ablation results on global connection thresholds across different cognitive tasks, where AE denotes the Average Functional Connectivity Efficiency and Acc denotes the classification accuracy.
4.3.3. Window Length Sensitivity Analysis
Although our framework is described as “dynamic functional connectivity,” it should be clarified that the adopted features (e.g., Pearson correlation coefficients, global efficiency) are computed within fixed sliding windows, and therefore represent a segmented quasi-static approximation of temporal variations rather than a fully continuous dynamic model as achieved by methods such as sliding-window Hidden Markov Models or time-varying state-space approaches. Our aim is not to infer latent state transitions, but to capture task-relevant fluctuations in functional connectivity within physiologically meaningful temporal segments. To delineate the reasonable boundary of this quasi-dynamic characterization, we conducted a sensitivity analysis on epoch length () and sliding window length (L). The results show that overly short epochs (e.g., 0.5 s) are noise-sensitive, whereas overly long ones (e.g., 3 s) smooth out critical temporal details; an intermediate epoch of 1 s provided the most stable performance across MA (fast-response), WG (variable cognitive-load), and UFFT (sustained-activation) tasks. Similarly, the optimal L range was 0.5–1 s, as shorter windows (0.2 s) were noise-dominated while longer windows (>1 s) excessively smoothed connectivity features. These findings collectively define the practical dynamic boundary of the proposed model as = 0.5–2 s and L = 0.5–1 s, with task-specific sensitivities such that fast-response tasks benefit from shorter segments, whereas sustained-activation tasks tolerate longer ones (see Table 5).
Table 5.
Sensitivity analysis of window lengths: classification accuracy (Acc) under different epoch lengths () and sliding window lengths (L).
4.3.4. Ablation of Feature Fusion Strategies
To verify the impact of scale differences in the feature fusion stage on the model’s classification performance, an ablation study was conducted to compare multiple strategies. Table 6 presents the classification accuracies (mean ± standard deviation) of different fusion methods on the MA, WG, and UFFT datasets. The results show that basic feature concatenation demonstrates a significant advantage: on the MA (90.04 ± 3.53), WG (78.33 ± 5.42), and UFFT (81.66 ± 3.23) datasets, its accuracy consistently outperforms Z-score normalized concatenation, min–max normalized concatenation, and fixed-weight concatenation. The latter three approaches, due to their forced intervention on the original feature distribution or weights, led to performance degradation on certain datasets (e.g., WG and UFFT). This indicates that the simple concatenation scheme adopted in this study, when combined with the model’s subsequent dynamic modulation mechanism, can effectively mitigate optimization bias caused by scale differences. By enabling a more natural feature integration, this strategy provides a reference for the design of feature fusion methods—namely, “lightweight intervention with reliance on module collaboration.”
Table 6.
Ablation results of feature fusion strategies: comparison of classification accuracy under different scale processing.
4.4. Limitations and Future Work
Although the proposed TopoTempNet model achieved promising decoding performance on multiple public fNIRS datasets (MA, WG, UFFT), several limitations remain. The model’s applicability is currently restricted to these three task datasets, which provide only objective information (ΔHbO/ΔHbR signals, task duration, demographic data) but lack subjective assessments such as NASA-TLX scores, making it difficult to disentangle model adaptability from confounding effects of cognitive workload. Moreover, its effectiveness in more complex motor imagery scenarios or pathological populations (e.g., stroke, ADHD, ASD) has not been validated, limiting its generalizability to clinical rehabilitation. The graph-theoretic feature extraction module also involves high computational complexity, especially for global network measures, which may hinder deployment on low-power portable devices. Finally, interpretability analysis remains at the feature-visualization level without integrating neuroscientific priors to construct a refined brain network interpretation framework. Future research should therefore broaden validation to diverse tasks and clinical populations with both objective and subjective measures, adopt lightweight strategies such as knowledge distillation or sparse graph structures to reduce computational cost and enhance real-time applicability, and establish a multi-scale interpretability system linking features, brain regions, and functions to improve clinical reliability and translational potential.
5. Conclusions
The TopoTempNet model integrates graph-theoretic topology with hybrid temporal modeling, achieving leading decoding accuracy and strong interpretability across multiple fNIRS tasks. Experiments show that TopoTempNet significantly outperforms mainstream models such as CNN and LSTM on the MA, WG, and UFFT datasets, with subject-dependent accuracies of 90.04%, 78.33%, and 81.66%, and subject-independent accuracies of 81.06%, 78.68%, and 80.18%, demonstrating good generalization ability and stability. Kappa coefficients and AUC further confirm the model’s discriminative power and robustness.
Interpretability analysis reveals that TopoTempNet precisely captures dynamic brain features. Graph theory features significantly highlight task-specific functional connectivity patterns: increased connectivity strength in calculation-related brain regions during the MA task, enhanced connectivity density in language-related regions during the WG task, and shortened RFSMD in motor cortex during the UFFT task, reflecting task-induced brain network cooperation and optimized information transmission efficiency. These differences provide neural mechanism support for the model’s performance.
In summary, TopoTempNet excels in decoding accuracy, feature discriminability, and neural mechanism interpretation, offering strong technical support for fNIRS-BCI applications in cognitive modeling, disease diagnosis, and rehabilitation training.
Author Contributions
Methodology, H.Y.; Formal analysis, Y.S. and L.S.; Investigation, Z.S.; Writing—review & editing, Q.H. and J.Z.; Supervision, Z.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the development program project of the Science and Technology Department of Jilin Province, China, under Grant YDZJ202201ZYTS684.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study are publicly available in multiple repositories. These include the Open access dataset for simultaneous EEG and NIRS brain-computerinterface (BCI) (https://doc.ml.tu-berlin.de/hBCI/). Open access NIRS dataset for classification of the unilateral finger and foot-tapping https://figshare.com/articles/dataset/Open_accessfNIRS_dataset_for_classification_of_the_unilateral_finger_and_foottapping/9783755/1 and Simultaneous acquisition of EEG and NIRS during cognitive tasks for an Open access dataset (https://doc.ml.tu-berlin.de/simultaneous_EEG_NIRS/).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lee, T.; Guo, L.; Chan, A.S. fNIRS as a biomarker for individuals with subjective memory complaints and MCI. Alzheimer’s Dement. 2024, 20, 5170–5182. [Google Scholar] [CrossRef] [PubMed]
- Si, X.; Han, Y.; Li, S.; Zhang, S.; Ming, D. The cortical spatial responses and decoding of emotion imagery towards a novel fNIRS-based affective BCI. IEEE Trans. Neural Syst. Rehabil. Eng. 2025, 33, 2577–2586. [Google Scholar] [CrossRef]
- Li, H.; Fan, C.; Chen, K.; Xie, H.; Yang, G.; Li, H.; Ji, X.; Wu, Y.; Li, M. Brain Activation During Motor Preparation and Execution in Patients with Mild Cognitive Impairment: An fNIRS Study. Brain Sci. 2025, 15, 333. [Google Scholar] [CrossRef]
- Xia, A.W.; Jin, M.; Zhang, B.B.; Kan, R.L.; Lin, T.T.; Qin, P.P.; Wang, X.; Chau, W.M.; Shi, N.M.; Kannan, P.; et al. Investigating the hemodynamic response to iTBS of the left DLPFC: A concurrent iTBS/fNIRS study. Brain Stimul. 2025, 18, 235–245. [Google Scholar] [CrossRef]
- Liu, M.; Yang, B.; Meng, L.; Zhang, Y.; Gao, S.; Zan, P.; Xia, X. STA-Net: Spatial–temporal alignment network for hybrid EEG-fNIRS decoding. Inf. Fusion 2025, 119, 103023. [Google Scholar] [CrossRef]
- Hou, M.; Zhang, X.; Chen, G.; Huang, L.; Sun, Y. Emotion Recognition Based on a EEG–fNIRS Hybrid Brain Network in the Source Space. Brain Sci. 2024, 14, 1166. [Google Scholar] [CrossRef]
- Arif, A.; Wang, Y.; Yin, R.; Zhang, X.; Helmy, A. EF-Net: Mental state recognition by analyzing multimodal EEG-fNIRS via CNN. Sensors 2024, 24, 1889. [Google Scholar] [CrossRef] [PubMed]
- Al Fahoum, A.; Zyout, A. Wavelet transform, reconstructed phase space, and deep learning neural networks for EEG-based schizophrenia detection. Int. J. Neural Syst. 2024, 34, 2450046. [Google Scholar] [CrossRef] [PubMed]
- Dash, S.; Dash, D.K.; Tripathy, R.K.; Pachori, R.B. Time–frequency domain machine learning for detection of epilepsy using wearable EEG sensor signals recorded during physical activities. Biomed. Signal Process. Control 2025, 100, 107041. [Google Scholar] [CrossRef]
- Zhu, R.; She, Q.; Li, R.; Tan, T.; Zhang, Y. Neurovascular coupling analysis based on multivariate variational Gaussian process convergent cross-mapping. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 1873–1883. [Google Scholar] [CrossRef]
- Cooney, C.; Folli, R.; Coyle, D. A bimodal deep learning architecture for EEG-fNIRS decoding of overt and imagined speech. IEEE Trans. Biomed. Eng. 2021, 69, 1983–1994. [Google Scholar] [CrossRef]
- Rui, Z.; Li, Y.; Dong, Z.; Hao, L.; Chen, B.; Chang, F.; Gu, Z. EEG, EOG, Likert scale, and interview approaches for assessing stressful hazard perception scenarios. Int. J. Hum.-Comput. Interact. 2025, 41, 5199–5224. [Google Scholar] [CrossRef]
- Lévi-Strauss, J.; Marois, C.; Worbe, Y.; Bedoucha, L.; Benchikh Lehocine, R.; Rohaut, B.; Weiss, N.; Demeret, S.; Apartis, E.; Lambrecq, V. Utility and value of movement recording with combined EEG-EMG monitoring in the intensive care unit. Neurocrit. Care 2025, 43, 333–344. [Google Scholar] [CrossRef] [PubMed]
- Baghdadi, G.; Hadaeghi, F.; Kamarajan, C. Multimodal approaches to investigating neural dynamics in cognition and related clinical conditions: Integrating EEG, MEG, and fMRI data. Front. Syst. Neurosci. 2025, 19, 1495018. [Google Scholar] [CrossRef]
- Huang, H.; Hu, H.; Xu, F.; Zhang, Z.; Yang, J. Electroencephalography-based assessment of worker vigilance for evaluating safety interventions in construction. Adv. Eng. Inform. 2025, 64, 102973. [Google Scholar] [CrossRef]
- Wang, J.; Zou, Z.; Huang, H.; Wu, J.; Wei, X.; Yin, S.; Chen, Y.; Liu, Y. The functional near infrared spectroscopy applications in children with developmental diseases: A review. Front. Neurol. 2025, 16, 1495138. [Google Scholar] [CrossRef]
- Hui, P.; Jiang, Y.; Wang, J.; Wang, C.; Li, Y.; Fang, B.; Wang, H.; Wang, Y.; Qie, S. Exploring the application and challenges of fNIRS technology in early detection of Parkinson’s disease. Front. Aging Neurosci. 2024, 16, 1354147. [Google Scholar] [CrossRef]
- Khan, H.; Khadka, R.; Sultan, M.S.; Yazidi, A.; Ombao, H.; Mirtaheri, P. Unleashing the potential of fNIRS with machine learning: Classification of fine anatomical movements to empower future brain-computer interface. Front. Hum. Neurosci. 2024, 18, 1354143. [Google Scholar] [CrossRef] [PubMed]
- Maniruzzaman, M.; Hirooka, K.; Tomioka, Y.; Hasan, M.A.M.; Hwang, Y.S.; Megumi, A.; Yasumura, A.; Shin, J. Machine Learning-Based ADHD Detection From fNIRs Signal During Reverse Stroop Tasks. IEEE Access 2024, 12, 82984–82995. [Google Scholar] [CrossRef]
- Fernandez Rojas, R.; Joseph, C.; Bargshady, G.; Ou, K.-L. Empirical comparison of deep learning models for fNIRS pain decoding. Front. Neuroinform. 2024, 18, 1320189. [Google Scholar] [CrossRef]
- Akila, V.; Johnvictor, A.C. Functional near infrared spectroscopy for brain functional connectivity analysis: A graph theoretic approach. Heliyon 2023, 9, e15002. [Google Scholar] [CrossRef]
- Wang, Z.; Fang, J.; Zhang, J. Rethinking delayed hemodynamic responses for fNIRS classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 4528–4538. [Google Scholar] [CrossRef]
- Cheng, S.; Shang, P.; Zhang, Y.; Guan, J.; Chen, Y.; Lv, Z.; Huang, S.; Liu, Y.; Xie, H. An fNIRS representation and fNIRS-scales multimodal fusion method for auxiliary diagnosis of amnestic mild cognitive impairment. Biomed. Signal Process. Control 2024, 96, 106646. [Google Scholar] [CrossRef]
- Seo, M.; Jeong, E.; Kim, K.-S. Multi-Class fNIRS Classification Using an Ensemble of GNN-Based Models. IEEE Access 2023, 11, 137606–137620. [Google Scholar] [CrossRef]
- Yu, Q.; Wang, R.; Liu, J.; Hu, L.; Chen, M.; Liu, Z. GNN-based depression recognition using spatio-temporal information: A fNIRS study. IEEE J. Biomed. Health Inform. 2022, 26, 4925–4935. [Google Scholar] [CrossRef]
- Shao, K.; Liu, Y.; Mo, Y.; Qin, Y.; Hao, Y.; Chen, M. fNIRS-Driven Depression Recognition Based on Cross-Modal Data Augmentation. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 2688–2698. [Google Scholar] [CrossRef]
- Khan, M.A.; Zahour, N.; Tariq, U.; Masri, G.; Almadani, I.F.; Al-Nashah, H. Exploring Effects of Mental Stress with Data Augmentation and Classification Using fNIRS. Sensors 2025, 25, 428. [Google Scholar] [CrossRef] [PubMed]
- Hirshfield, L.M.; Wickens, C.; Doherty, E.; Spencer, C.; Williams, T.; Hayne, L. Toward workload-based adaptive automation: The utility of fNIRS for measuring load in multiple resources in the brain. Int. J. Hum.-Comput. Interact. 2024, 40, 7404–7430. [Google Scholar] [CrossRef]
- Chen, G.; Liu, Y.; Zhang, X. EEG–fNIRS-Based emotion recognition using graph convolution and capsule attention network. Brain Sci. 2024, 14, 820. [Google Scholar] [CrossRef] [PubMed]
- Sporns, O. Graph theory methods: Applications in brain networks. Dialogues Clin. Neurosci. 2018, 20, 111–121. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Chen, Z.; Cai, Z.; Ao, W.; Li, Q.; Xu, M.; Zhou, S. Exploring Graph Theory Mechanisms of Fluid Intelligence in the DLPFC: Insights From Resting-State fNIRS Across Various Time Windows. Brain Behav. 2025, 15, e70386. [Google Scholar] [CrossRef]
- Shin, J.; von Lühmann, A.; Blankertz, B.; Kim, D.-W.; Jeong, J.; Hwang, H.-J.; Müller, K.-R. Open access dataset for EEG+ NIRS single-trial classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 25, 1735–1745. [Google Scholar] [CrossRef]
- Shin, J.; Von Lühmann, A.; Kim, D.-W.; Mehnert, J.; Hwang, H.-J.; Müller, K.-R. Simultaneous acquisition of EEG and NIRS during cognitive tasks for an open access dataset. Sci. Data 2018, 5, 180003. [Google Scholar] [CrossRef]
- Bak, S.; Park, J.; Shin, J.; Jeong, J. Open-access fNIRS dataset for classification of unilateral finger-and foot-tapping. Electronics 2019, 8, 1486. [Google Scholar] [CrossRef]
- Cope, M.; Delpy, D.T. System for long-term measurement of cerebral blood and tissue oxygenation on newborn infants by near infra-red transillumination. Med. Biol. Eng. Comput. 1988, 26, 289–294. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Thakur, A.; Gupta, M.; Sinha, D.K.; Mishra, K.K.; Venkatesan, V.K.; Guluwadi, S. Transformative breast Cancer diagnosis using CNNs with optimized ReduceLROnPlateau and Early stopping Enhancements. Int. J. Comput. Intell. Syst. 2024, 17, 14. [Google Scholar]
- Lyu, B.; Pham, T.; Blaney, G.; Haga, Z.; Sassaroli, A.; Fantini, S.; Aeron, S. Domain adaptation for robust workload level alignment between sessions and subjects using fNIRS. J. Biomed. Opt. 2021, 26, 022908. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, J.; Xia, Y.; Chen, P.; Wang, B. A general and scalable vision framework for functional near-infrared spectroscopy classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 30, 1982–1991. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, J.; Zhang, X.; Chen, P.; Wang, B. Transformer model for functional near-infrared spectroscopy classification. IEEE J. Biomed. Health Inform. 2022, 26, 2559–2569. [Google Scholar] [CrossRef]
- Yang, L.; Gu, J.; Chen, J.; Gao, D.; Wang, M. FCS-TPNet: Fusion of fNIRS chromophore signals to construct temporal-spatial graph representation for topological networks. Biomed. Signal Process. Control 2025, 104, 107528. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Pfurtscheller, G.; Bauernfeind, G.; Wriessnegger, S.C.; Neuper, C. Focal frontal (de) oxyhemoglobin responses during simple arithmetic. Int. J. Psychophysiol. 2010, 76, 186–192. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).