
Multimodal Sensing-Enabled Large Language Models for Automated Emotional Regulation: A Review of Current Technologies, Opportunities, and Challenges




Abstract
1. Introduction
2. Related Work
3. Automated Emotional Regulation: Approaches and Challenges
3.1. Status of Current Unimodal Emotional Recognition and Regulation Methods
3.1.1. Modalities for Automated Emotion Recognition
- Visual modality: Computer-vision algorithms applied to camera streams extract high-level representations of facial action units, eye-gaze trajectories, pupil dilation, and head– or body-movement kinematics. Large–scale, carefully curated videos [46,47,48] enable data-driven learning of robust visual affect representations.
- Auditory modality: Microphone recordings preserve rich affective cues embedded in speech acoustics—pitch, intensity, prosody, and temporal pause structure—as well as in the linguistic content of utterances. Because vocal signals are less susceptible to physical occlusion than faces, speech analysis supports non-intrusive, always-on monitoring. Modern natural-language-processing models further uncover the cognitive component of emotion conveyed in texts [49].
- Physiological modality: Wearable sensors (e.g., ECG/PPG watches, EDA bands, and EEG headsets) measure involuntary autonomic and central-nervous-system activity such as heart-rate variability, electrodermal conductance, respiration, and cortical rhythms. These signals provide continuous, high-reliability indices of arousal that are difficult to consciously manipulate [51]. Recent miniaturization of hardware has increased their feasibility in daily-life settings.
- Behavioral/contextual modality. Smartphones [52] and wearables [53] supply contextual traces—GPS trajectories, accelerometer-derived physical activity, communication logs, and device usage patterns—that situate other sensor streams within the user’s real-world environment, thereby enriching the interpretation of moment-to-moment affective states.
3.1.2. Limitations of Unimodal Emotion Recognition Approaches
- Vision is vulnerable to occlusions (masks, glasses, and hand-to-face motion), extreme head poses, and adverse illumination. Facial expressions are also culturally moderated and can be deliberately suppressed or exaggerated, leading to systematic bias in both data and models [54]. Moreover, many everyday affective events lack a salient facial display, so purely visual systems often regress to guessing from sparse cues.
- Audio deteriorates rapidly under ambient noise, reverberation, packet loss, or low-quality microphones; even modest signal-to-noise degradation (<10 dB) can halve classification accuracy [55]. Speaker-dependent factors such as accent, age, health, and paralinguistic habits further confound counseling, while existing corpora over-represent acted emotions and read speech, thus limiting ecological validity.
- Physiology delivers involuntary signals, yet these traces are notoriously noisy: motion artifacts, electrode–skin impedance changes, temperature drift, and sensor displacement corrupt ECG/PPG and EDA. Inter-subject variability is large—baseline heart-rate variability can differ by a factor of two between healthy adults—necessitating cumbersome personal calibration. More critically, the mapping from raw autonomic activity to discrete affective states is many-to-many: elevated arousal may indicate fear, excitement, physical exertion, or caffeine intake, rendering interpretation context-dependent and ambiguous [56,57].
- Behavioral/contextual traces collected from smartphones and wearables (GPS, accelerometry, app usage, and communication logs) are typically sparse and irregular, dominated by missing data whenever devices are switched off, out of charge, or left behind. Location and activity cues are coarse-grained and can confound affect with routine (e.g., commuting) or exogenous factors (e.g., weather). Continuous tracking imposes non-trivial privacy, consent, and battery burdens, while interpretation is highly person- and culture-specific—the same mobility pattern may signal boredom in one user and relaxation in another. Finally, available datasets remain small and skewed toward convenience samples, hampering model generalization [58,59].
3.1.3. Multimodal Emotional Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Modalities | Emotion Labels | Participants/Size |
|---|---|---|---|
| eNTERFACE (2006) [65] | Visual and audio | Happiness, sadness, anger, fear, disgust, and surprise | 1277 video clips |
| IEMOCAP (2008) [64] | Text, visual, audio, and body | Happiness, sadness, anger, frustration, neutral, and others; valence, dominance, and arousal | 10,039 conversations |
| MAHNOB-HCI [63] | EEG, visual, audio, body, eye gaze, ECG, GSR, Temp, and Resp | Valence, arousal, dominance, and predictability; joy, amusement, sadness, disgust, anxiety, fear, surprise, anger, and neutral | 27–30 participants; 20 clips per subject |
| AFEW (2012) [60] | Visual, audio | anger, disgust, fear, happiness, sadness, surprise, and neutral | 1156 clips; 330 actors |
| DEAP (2012) [62] | EEG, EDA, ECG, EMG, EOG, RESP, BVP, SKT, visual, and audio | Valence, arousal, dominance, and liking | 32 participants; 40 trials |
| CMU-MOSEI (2018) [66] | Text, visual, and audio | Happiness, sadness, anger, fear, disgust, and surprise | 3229 video clips |
| RAVDESS (2018) [61] | Visual and audio | Neutral, calm, happy, sad, angry, fearful, disgust, and surprised | 24 actors; 7356 files |
| MELD (2019) [67] | Text, visual, and audio | Anger, disgust, sadness, joy, neutral, surprise, and fear | 1433 dialogues; 13,708 utterances |
| HEU (2021) [68] | Visual, audio, and body | Anger, boredom, confusion, disappointed, disgust, fear, happy, neutral, sad, and surprise | 19,004 clips |
3.2. Multimodal Sensing: Emotional State Perception and Recognition
3.2.1. Signal Interpretation for Emotional Regulation
3.2.2. Affective Computing Techniques
3.2.3. Emotion Recognition: Multimodal and Conversational Perspectives
3.2.4. Multimodal Emotion Recognition Pipeline
- 1.
- Multimodal sensing collects multimodal signal data and then subjects them to a feature extraction process.
- 2.
- Multimodal information fusion converts these raw streams into an integrated affect representation: modality-specific encoders first extract salient features; a fusion module then aligns and weights them before an emotion classifier infers the latent state.
- 3.
- Emotional classification maps the prediction to a discrete set of categories.
3.2.5. Multimodal Fusion Strategies
- Feature-level fusion combines extracted features from each modality into one vector before classification. This can capture low-level intermodal dependencies but is sensitive to missing data and requires feature alignment [76].
- Decision-level fusion trains separate classifiers per modality and combines their predictions later using methods like voting, averaging, or meta-classifiers. This is more robust to missing modalities but might miss subtle crossmodal interactions.
- Hybrid fusion combines aspects of both early and late fusion. Model-level fusion, which is common in deep learning, integrates representations learned at intermediate layers of modality-specific networks within a unified architecture. This allows adaptive learning of how to combine modalities. The choice of strategy impacts performance, robustness, and computational needs, which are especially crucial for real-time conversational systems where processing multiple streams is demanding [77].
3.2.6. State-of-the-Art Performance in Multimodal Emotion Recognition
3.3. LLM-Enabled Dialogue-Based Therapist
3.3.1. LLM Capabilities for Therapeutic Interaction
3.3.2. Current Applications
3.4. Overview of Available Multimodal LLM-Based AER Systems
4. Insight and Key Challenges
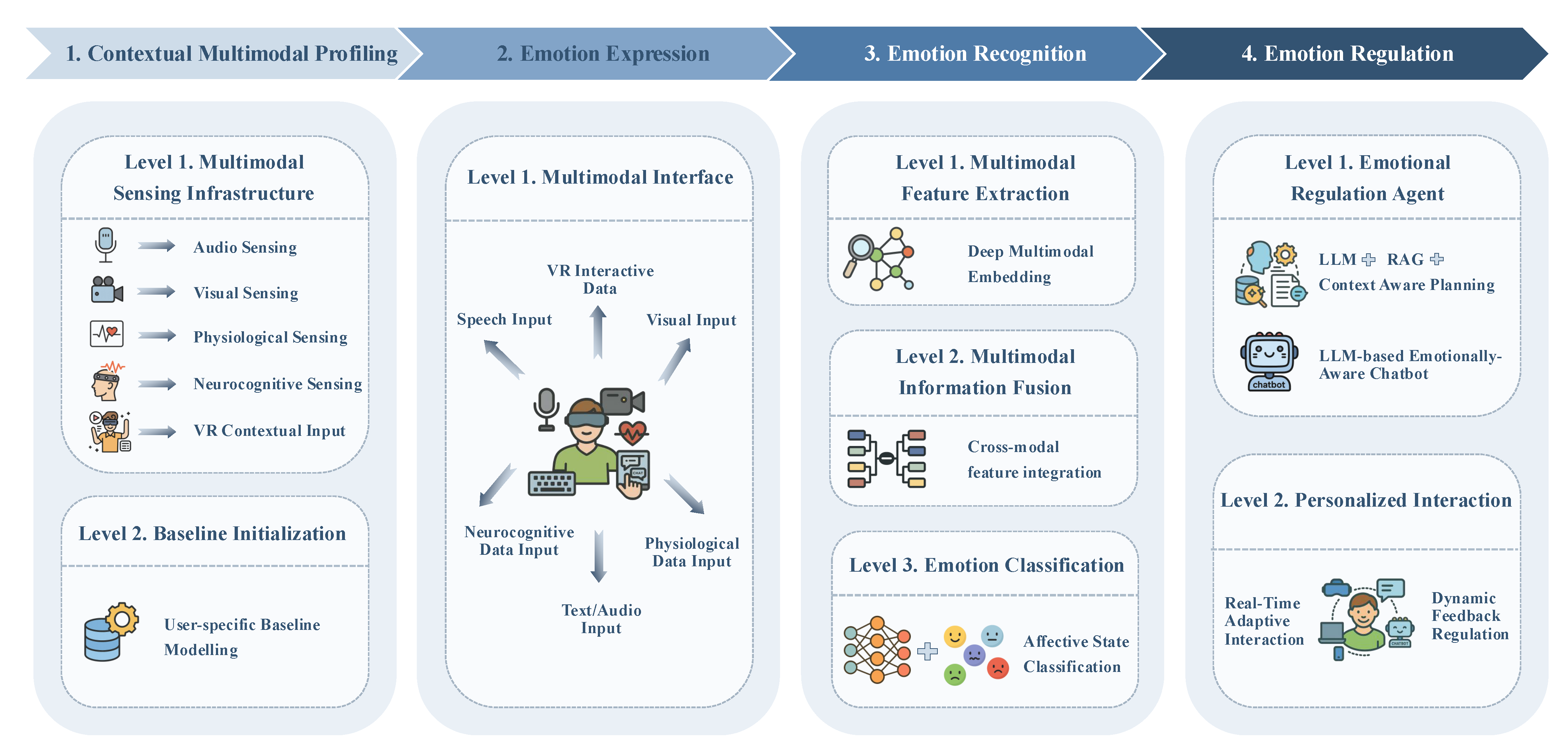
4.1. Automated Emotional Regulation Architecture Design
4.1.1. Contextual Multimodal Profiling Module
- Personal profile ingestion: Parallel to baseline recording, CMP collects the following static personal information via a privacy-preserving wizard: age, gender identity, language, cultural background, clinically relevant history, and medication. Structured answers populate a secure profile store, while data are summarized by an on-device database into key–value pairs.
- Multimodal sensing infrastructure: A network of co-located microphones, RGB-D/eye-tracking cameras, wearable ECG/EDA/EEG devices, and VR/IoT loggers continuously streams audio–visual, physiological, neurocognitive, and interaction data in lock-step with textual inputs captured by the LLM interface. Each packet carries a high-precision Unix timestamp to guarantee sub-10 ms alignment across channels, while an adaptive sampling controller throttles or boosts individual sensors according to battery, bandwidth, and privacy constraints.
- Baseline initialization: During onboarding the user performs neutral tasks for a few minutes. Gaussian-process priors model trait physiology, habitual vocal prosody, and typical postural ranges; live signals are thereafter z-normalized against these priors so that only state-driven deviations remain salient.
4.1.2. Emotion Expression Module
4.1.3. Emotion Recognition Module
- Feature extraction: Synchronously sampled audio, visual, textual, physiological, and neurocognitive channels are first routed through lightweight modality-specific encoders.
- Information fusion: To handle signal drop-outs and exploit crossmodal synergies, a hybrid strategy is adopted. A model-level transformer aligns the embeddings through crossmodal attention so co-occurring cues—e.g., elevated pitch and increased EDA—reinforce each other, while a decision-level ensemble remains available as a fallback option when an entire modality disappears. This combination inherits the robustness of late fusion and the sensitivity of early fusion, which together have the potential to address the trade-offs discussed in recent MER studies.
4.1.4. Emotion Regulation Module
4.2. Implementation and Methodological Insights
4.3. Key Challenges
4.3.1. Challenges in Contextual Multimodal Profiling
4.3.2. Challenges in Emotion Expression
4.3.3. Challenges in Emotion Recognition
4.3.4. Challenges in Emotion Regulation
4.3.5. Overarching Systemic and Ethical Challenges
5. Conclusions
Funding
Conflicts of Interest
References
- Carbonell, A.; Navarro-Pérez, J.J.; Mestre, M.V. Challenges and barriers in mental healthcare systems and their impact on the family: A systematic integrative review. Health Soc. Care Community 2020, 28, 1366–1379. [Google Scholar] [CrossRef]
- Wienand, D.; Wijnen, L.I.; Heilig, D.; Wippel, C.; Arango, C.; Knudsen, G.M.; Goodwin, G.M.; Simon, J. Comorbid physical health burden of serious mental health disorders in 32 European countries. BMJ Ment. Health 2024, 27, e301021. [Google Scholar] [CrossRef]
- Solmi, M.; Radua, J.; Olivola, M.; Croce, E.; Soardo, L.; Salazar de Pablo, G.; Il Shin, J.; Kirkbride, J.B.; Jones, P.; Kim, J.H.; et al. Age at onset of mental disorders worldwide: Large-scale meta-analysis of 192 epidemiological studies. Mol. Psychiatry 2022, 27, 281–295. [Google Scholar] [CrossRef]
- World Health Organization. Mental Disorders. Available online: https://www.who.int/news-room/fact-sheets/detail/mental-disorders (accessed on 27 June 2025).
- Walker, E.R.; McGee, R.E.; Druss, B.G. Mortality in mental disorders and global disease burden implications: a systematic review and meta-analysis. JAMA Psychiatry 2015, 72, 334–341. [Google Scholar] [CrossRef] [PubMed]
- Brouwers, E.P. Social stigma is an underestimated contributing factor to unemployment in people with mental illness or mental health issues: Position paper and future directions. BMC Psychol. 2020, 8, 36. [Google Scholar] [CrossRef] [PubMed]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Fitzpatrick, K.K.; Darcy, A.; Vierhile, M. Delivering cognitive behavior therapy to young adults with symptoms of depression and anxiety using a fully automated conversational agent (Woebot): A randomized controlled trial. JMIR Ment. Health 2017, 4, e7785. [Google Scholar] [CrossRef]
- Elyoseph, Z.; Hadar-Shoval, D.; Asraf, K.; Lvovsky, M. ChatGPT outperforms humans in emotional awareness evaluations. Front. Psychol. 2023, 14, 1199058. [Google Scholar] [CrossRef]
- Martinengo, L.; Stona, A.C.; Griva, K.; Dazzan, P.; Pariante, C.M.; von Wangenheim, F.; Car, J. Self-guided cognitive behavioral therapy apps for depression: systematic assessment of features, functionality, and congruence with evidence. J. Med. Internet Res. 2021, 23, e27619. [Google Scholar] [CrossRef]
- Clarke, J.; Proudfoot, J.; Whitton, A.; Birch, M.R.; Boyd, M.; Parker, G.; Manicavasagar, V.; Hadzi-Pavlovic, D.; Fogarty, A. Therapeutic alliance with a fully automated mobile phone and web-based intervention: Secondary analysis of a randomized controlled trial. JMIR Ment. Health 2016, 3, e4656. [Google Scholar] [CrossRef]
- Klein, B.; Meyer, D.; Austin, D.W.; Kyrios, M. Anxiety online—A virtual clinic: Preliminary outcomes following completion of five fully automated treatment programs for anxiety disorders and symptoms. J. Med. Internet Res. 2011, 13, e89. [Google Scholar] [CrossRef]
- Freeman, D.; Lister, R.; Waite, F.; Yu, L.M.; Slater, M.; Dunn, G.; Clark, D. Automated psychological therapy using virtual reality (VR) for patients with persecutory delusions: Study protocol for a single-blind parallel-group randomised controlled trial (THRIVE). Trials 2019, 20, 87. [Google Scholar] [CrossRef]
- Lambe, S.; Knight, I.; Kabir, T.; West, J.; Patel, R.; Lister, R.; Rosebrock, L.; Rovira, A.; Garnish, B.; Freeman, J.; et al. Developing an automated VR cognitive treatment for psychosis: gameChange VR therapy. J. Behav. Cogn. Ther. 2020, 30, 33–40. [Google Scholar] [CrossRef]
- Bălan, O.; Moldoveanu, A.; Leordeanu, M. A machine learning approach to automatic phobia therapy with virtual reality. In Modern Approaches to Augmentation of Brain Function; Springer: Cham, Switzerland, 2021; pp. 607–636. [Google Scholar]
- Barua, P.D.; Vicnesh, J.; Gururajan, R.; Oh, S.L.; Palmer, E.; Azizan, M.M.; Kadri, N.A.; Acharya, U.R. Artificial intelligence enabled personalised assistive tools to enhance education of children with neurodevelopmental disorders—A review. Int. J. Environ. Res. Public Health 2022, 19, 1192. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Ceja, E.; Riegler, M.; Nordgreen, T.; Jakobsen, P.; Oedegaard, K.J.; Tørresen, J. Mental health monitoring with multimodal sensing and machine learning: A survey. Pervasive Mob. Comput. 2018, 51, 1–26. [Google Scholar] [CrossRef]
- Zhou, D.; Luo, J.; Silenzio, V.; Zhou, Y.; Hu, J.; Currier, G.; Kautz, H. Tackling mental health by integrating unobtrusive multimodal sensing. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Xu, X.; Yao, B.; Dong, Y.; Gabriel, S.; Yu, H.; Hendler, J.; Ghassemi, M.; Dey, A.K.; Wang, D. Mental-llm: Leveraging large language models for mental health prediction via online text data. Proc. ACM Interactive Mobile Wearable Ubiquitous Technol. 2024, 8, 1–32. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Zhang, Y.; Zhu, K.; Hou, W.; Lian, J.; Luo, F.; Yang, Q.; Xie, X. Large language models understand and can be enhanced by emotional stimuli. arXiv 2023, arXiv:2307.11760. [Google Scholar]
- Alvarez-Gonzalez, N.; Kaltenbrunner, A.; Gómez, V. Uncovering the limits of text-based emotion detection. arXiv 2021, arXiv:2109.01900. [Google Scholar]
- Kim, B.H.; Wang, C. Large Language Models for Interpretable Mental Health Diagnosis. arXiv 2025, arXiv:2501.07653. [Google Scholar]
- Adhikary, P.K.; Srivastava, A.; Kumar, S.; Singh, S.M.; Manuja, P.; Gopinath, J.K.; Krishnan, V.; Gupta, S.K.; Deb, K.S.; Chakraborty, T. Exploring the efficacy of large language models in summarizing mental health counseling sessions: Benchmark study. JMIR Ment. Health 2024, 11, e57306. [Google Scholar] [CrossRef]
- Cabrera, J.; Loyola, M.S.; Magaña, I.; Rojas, R. Ethical dilemmas, mental health, artificial intelligence, and llm-based chatbots. In Proceedings of the International Work-Conference on Bioinformatics and Biomedical Engineering, Gran Canaria, Spain, 12–14 July 2023; Springer: Cham, Switzerland, 2023; pp. 313–326. [Google Scholar]
- Yuan, A.; Garcia Colato, E.; Pescosolido, B.; Song, H.; Samtani, S. Improving workplace well-being in modern organizations: A review of large language model-based mental health chatbots. ACM Trans. Manag. Inf. Syst. 2025, 16, 1–26. [Google Scholar] [CrossRef]
- Yu, H.; McGuinness, S. An experimental study of integrating fine-tuned LLMs and prompts for enhancing mental health support chatbot system. J. Med. Artif. Intell. 2024, 7, 1–16. [Google Scholar] [CrossRef]
- Khoo, L.S.; Lim, M.K.; Chong, C.Y.; McNaney, R. Machine learning for multimodal mental health detection: A systematic review of passive sensing approaches. Sensors 2024, 24, 348. [Google Scholar] [CrossRef] [PubMed]
- Lutz, W.; Schwartz, B.; Delgadillo, J. Measurement-based and data-informed psychological therapy. Annu. Rev. Clin. Psychol. 2022, 18, 71–98. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Lai, A.; Thygesen, J.H.; Farrington, J.; Keen, T.; Li, K. Large language models for mental health applications: Systematic review. JMIR Ment. Health 2024, 11, e57400. [Google Scholar] [CrossRef]
- Sun, J.; Dong, Q.X.; Wang, S.W.; Zheng, Y.B.; Liu, X.X.; Lu, T.S.; Yuan, K.; Shi, J.; Hu, B.; Lu, L.; et al. Artificial intelligence in psychiatry research, diagnosis, and therapy. Asian J. Psychiatry 2023, 87, 103705. [Google Scholar] [CrossRef]
- Xu, B.; Zhuang, Z. Survey on psychotherapy chatbots. Concurr. Comput. Pract. Exp. 2022, 34, e6170. [Google Scholar] [CrossRef]
- Bendig, E.; Erb, B.; Schulze-Thuesing, L.; Baumeister, H. The next generation: Chatbots in clinical psychology and psychotherapy to foster mental health—A scoping review. Verhaltenstherapie 2022, 32, 64–76. [Google Scholar] [CrossRef]
- Lim, S.M.; Shiau, C.W.C.; Cheng, L.J.; Lau, Y. Chatbot-delivered psychotherapy for adults with depressive and anxiety symptoms: A systematic review and meta-regression. Behav. Ther. 2022, 53, 334–347. [Google Scholar] [CrossRef]
- Olawade, D.B.; Wada, O.Z.; Odetayo, A.; David-Olawade, A.C.; Asaolu, F.; Eberhardt, J. Enhancing mental health with Artificial Intelligence: Current trends and future prospects. J. Med. Surgery Public Health 2024, 3, 100099. [Google Scholar] [CrossRef]
- Zhou, S.; Zhao, J.; Zhang, L. Application of artificial intelligence on psychological interventions and diagnosis: An overview. Front. Psychiatry 2022, 13, 811665. [Google Scholar] [CrossRef] [PubMed]
- Ray, A.; Bhardwaj, A.; Malik, Y.K.; Singh, S.; Gupta, R. Artificial intelligence and Psychiatry: An overview. Asian J. Psychiatry 2022, 70, 103021. [Google Scholar] [CrossRef] [PubMed]
- Boucher, E.M.; Harake, N.R.; Ward, H.E.; Stoeckl, S.E.; Vargas, J.; Minkel, J.; Parks, A.C.; Zilca, R. Artificially intelligent chatbots in digital mental health interventions: A review. Expert Rev. Med. Devices 2021, 18, 37–49. [Google Scholar] [CrossRef] [PubMed]
- Gual-Montolio, P.; Jaén, I.; Martínez-Borba, V.; Castilla, D.; Suso-Ribera, C. Using artificial intelligence to enhance ongoing psychological interventions for emotional problems in real-or close to real-time: A systematic review. Int. J. Environ. Res. Public Health 2022, 19, 7737. [Google Scholar] [CrossRef]
- Thomas, R.; Zimmer-Gembeck, M.J. Behavioral outcomes of parent-child interaction therapy and Triple P—Positive Parenting Program: A review and meta-analysis. J. Abnorm. Child Psychol. 2007, 35, 475–495. [Google Scholar] [CrossRef]
- D’alfonso, S.; Santesteban-Echarri, O.; Rice, S.; Wadley, G.; Lederman, R.; Miles, C.; Gleeson, J.; Alvarez-Jimenez, M. Artificial intelligence-assisted online social therapy for youth mental health. Front. Psychol. 2017, 8, 796. [Google Scholar] [CrossRef]
- Pham, K.T.; Nabizadeh, A.; Selek, S. Artificial intelligence and chatbots in psychiatry. Psychiatr. Q. 2022, 93, 249–253. [Google Scholar] [CrossRef]
- Kourtesis, P. A Comprehensive Review of Multimodal XR Applications, Risks, and Ethical Challenges in the Metaverse. Multimodal Technol. Interact. 2024, 8, 98. [Google Scholar] [CrossRef]
- Xiao, H.; Zhou, F.; Liu, X.; Liu, T.; Li, Z.; Liu, X.; Huang, X. A comprehensive survey of large language models and multimodal large language models in medicine. Inf. Fusion 2025, 117, 102888. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, H.; Liu, Y.; Ma, C.; Zhang, X.; Pan, Y.; Liu, M.; Gu, P.; Xia, S.; Li, W.; et al. A comprehensive review of multimodal large language models: Performance and challenges across different tasks. arXiv 2024, arXiv:2408.01319. [Google Scholar]
- Wang, P.; Liu, A.; Sun, X. Integrating emotion dynamics in mental health: A trimodal framework combining ecological momentary assessment, physiological measurements, and speech emotion recognition. Interdiscip. Med. 2025, 3, e20240095. [Google Scholar] [CrossRef]
- Middya, A.I.; Nag, B.; Roy, S. Deep learning based multimodal emotion recognition using model-level fusion of audio–visual modalities. Knowl.-Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-visual emotion recognition in video clips. IEEE Trans. Affect. Comput. 2017, 10, 60–75. [Google Scholar] [CrossRef]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep learning-based multimodal emotion recognition from audio, visual, and text modalities: A systematic review of recent advancements and future prospects. Expert Syst. Appl. 2024, 237, 121692. [Google Scholar] [CrossRef]
- Zhao, S.; Jia, G.; Yang, J.; Ding, G.; Keutzer, K. Emotion recognition from multiple modalities: Fundamentals and methodologies. IEEE Signal Process. Mag. 2021, 38, 59–73. [Google Scholar] [CrossRef]
- Pantic, M.; Rothkrantz, L.J. Toward an affect-sensitive multimodal human-computer interaction. Proc. IEEE 2003, 91, 1370–1390. [Google Scholar] [CrossRef]
- Kang, S.; Choi, W.; Park, C.Y.; Cha, N.; Kim, A.; Khandoker, A.H.; Hadjileontiadis, L.; Kim, H.; Jeong, Y.; Lee, U. K-emophone: A mobile and wearable dataset with in-situ emotion, stress, and attention labels. Sci. Data 2023, 10, 351. [Google Scholar] [CrossRef]
- Wu, Y.; Daoudi, M.; Amad, A. Transformer-based self-supervised multimodal representation learning for wearable emotion recognition. IEEE Trans. Affect. Comput. 2023, 15, 157–172. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2584–2593. [Google Scholar]
- Schuller, B.W.; Batliner, A.; Bergler, C.; Messner, E.M.; Hamilton, A.; Amiriparian, S.; Baird, A.; Rizos, G.; Schmitt, M.; Stappen, L.; et al. The Interspeech 2020 Computational Paralinguistics Challenge: Elderly Emotion, Breathing & Masks. 2020. Available online: https://www.isca-archive.org/interspeech_2020/schuller20_interspeech.html (accessed on 27 June 2025).
- Pané-Farré, C.A.; Alius, M.G.; Modeß, C.; Methling, K.; Blumenthal, T.; Hamm, A.O. Anxiety sensitivity and expectation of arousal differentially affect the respiratory response to caffeine. Psychopharmacology 2015, 232, 1931–1939. [Google Scholar] [CrossRef]
- Raz, S.; Lahad, M. Physiological indicators of emotional arousal related to ANS activity in response to associative cards for psychotherapeutic PTSD treatment. Front. Psychiatry 2022, 13, 933692. [Google Scholar] [CrossRef] [PubMed]
- Harari, Y.; Shawen, N.; Mummidisetty, C.K.; Albert, M.V.; Kording, K.P.; Jayaraman, A. A smartphone-based online system for fall detection with alert notifications and contextual information of real-life falls. J. Neuroeng. Rehabil. 2021, 18, 124. [Google Scholar] [CrossRef] [PubMed]
- Chan, S.; Santoro, A.; Lampinen, A.; Wang, J.; Singh, A.; Richemond, P.; McClelland, J.; Hill, F. Data distributional properties drive emergent in-context learning in transformers. Adv. Neural Inf. Process. Syst. 2022, 35, 18878–18891. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting Large, Richly Annotated Facial-Expression Databases from Movies. IEEE MultiMedia 2012, 19, 34–41. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.; Yazdani, A.; Patras, I. DEAP: A Database for Emotion Analysis; Using Physiological Signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A Multimodal Database for Affect Recognition and Implicit Tagging. IEEE Trans. Affect. Comput. 2011, 3, 42–55. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 Audio-Visual Emotion Database. In Proceedings of the First IEEE Workshop on Multimedia Database Management (ICDEW’06), Atlanta, GA, USA, 8 April 2006. [Google Scholar] [CrossRef]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar]
- Chen, J.; Wang, C.; Wang, K.; Yin, C.; Zhao, C.; Xu, T.; Zhang, X.; Huang, Z.; Liu, M.; Yang, T. HEU Emotion: A Large–Scale Database for Multi–modal Emotion Recognition in the Wild. Neural Comput. Appl. 2021, 33, 8669–8685. [Google Scholar] [CrossRef]
- García, J.A.B. Description and limitations of instruments for the assessment of expressed emotion. Papeles Psicólogo 2011, 32, 152–158. [Google Scholar]
- Guo, R.; Guo, H.; Wang, L.; Chen, M.; Yang, D.; Li, B. Development and application of emotion recognition technology—A systematic literature review. BMC Psychol. 2024, 12, 95. [Google Scholar] [CrossRef]
- Pillalamarri, R.; Shanmugam, U. A review on EEG-based multimodal learning for emotion recognition. Artif. Intell. Rev. 2025, 58, 131. [Google Scholar] [CrossRef]
- Al Machot, F.; Elmachot, A.; Ali, M.; Al Machot, E.; Kyamakya, K. A deep-learning model for subject-independent human emotion recognition using electrodermal activity sensors. Sensors 2019, 19, 1659. [Google Scholar] [CrossRef]
- Younis, E.M.; Zaki, S.M.; Kanjo, E.; Houssein, E.H. Evaluating ensemble learning methods for multi-modal emotion recognition using sensor data fusion. Sensors 2022, 22, 5611. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.S.; Muhammad, G. Emotion recognition using deep learning approach from audio–visual emotional big data. Inf. Fusion 2019, 49, 69–78. [Google Scholar] [CrossRef]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Int. J. Adv. Comput. Sci. Appl. 2017, 8. [Google Scholar] [CrossRef]
- Cai, H.; Qu, Z.; Li, Z.; Zhang, Y.; Hu, X.; Hu, B. Feature-level fusion approaches based on multimodal EEG data for depression recognition. Inf. Fusion 2020, 59, 127–138. [Google Scholar] [CrossRef]
- Cimtay, Y.; Ekmekcioglu, E.; Caglar-Ozhan, S. Cross-subject multimodal emotion recognition based on hybrid fusion. IEEE Access 2020, 8, 168865–168878. [Google Scholar] [CrossRef]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Chow, K.; Fritz, T.; Holsti, L.; Barbic, S.; McGrenere, J. Feeling stressed and unproductive? A field evaluation of a therapy-inspired digital intervention for knowledge workers. ACM Trans. Comput.-Hum. Interact. 2023, 31, 1–33. [Google Scholar] [CrossRef]
- Tomar, P.S.; Mathur, K.; Suman, U. Fusing facial and speech cues for enhanced multimodal emotion recognition. Int. J. Inf. Technol. 2024, 16, 1397–1405. [Google Scholar] [CrossRef]
- Tripathi, S.; Beigi, H. Multi-modal emotion recognition on IEMOCAP with neural networks. arXiv 2018, arXiv:1804.05788. [Google Scholar]
- Wiem, M.B.H.; Lachiri, Z. Emotion classification in arousal valence model using MAHNOB-HCI database. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 318–323. [Google Scholar] [CrossRef]
- Kossaifi, J.; Tzimiropoulos, G.; Todorovic, S.; Pantic, M. AFEW-VA database for valence and arousal estimation in-the-wild. Image Vis. Comput. 2017, 65, 23–36. [Google Scholar] [CrossRef]
- Tripathi, S.; Acharya, S.; Sharma, R.; Mittal, S.; Bhattacharya, S. Using deep and convolutional neural networks for accurate emotion classification on DEAP data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 4746–4752. [Google Scholar]
- Luna-Jiménez, C.; Griol, D.; Callejas, Z.; Kleinlein, R.; Montero, J.M.; Fernández-Martínez, F. Multimodal emotion recognition on RAVDESS dataset using transfer learning. Sensors 2021, 21, 7665. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Bansal, G.; Zhang, J.; Wu, Y.; Li, B.; Zhu, E.; Jiang, L.; Zhang, X.; Zhang, S.; Liu, J.; et al. Autogen: Enabling next-gen llm applications via multi-agent conversation. arXiv 2023, arXiv:2308.08155. [Google Scholar]
- Wang, J.; Xiao, Y.; Li, Y.; Song, C.; Xu, C.; Tan, C.; Li, W. Towards a client-centered assessment of llm therapists by client simulation. arXiv 2024, arXiv:2406.12266. [Google Scholar]
- Chiu, Y.Y.; Sharma, A.; Lin, I.W.; Althoff, T. A computational framework for behavioral assessment of llm therapists. arXiv 2024, arXiv:2401.00820. [Google Scholar]
- Qiu, H.; Lan, Z. Interactive agents: Simulating counselor-client psychological counseling via role-playing llm-to-llm interactions. arXiv 2024, arXiv:2408.15787. [Google Scholar]
- Na, H. CBT-LLM: A Chinese large language model for cognitive behavioral therapy-based mental health question answering. arXiv 2024, arXiv:2403.16008. [Google Scholar]
- Antico, C.; Giordano, S.; Koyuturk, C.; Ognibene, D. Unimib Assistant: Designing a student-friendly RAG-based chatbot for all their needs. arXiv 2024, arXiv:2411.19554. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Sorin, V.; Brin, D.; Barash, Y.; Konen, E.; Charney, A.; Nadkarni, G.; Klang, E. Large language models and empathy: Systematic review. J. Med. Internet Res. 2024, 26, e52597. [Google Scholar] [CrossRef] [PubMed]
- Sanjeewa, R.; Iyer, R.; Apputhurai, P.; Wickramasinghe, N.; Meyer, D. Empathic conversational agent platform designs and their evaluation in the context of mental health: Systematic review. JMIR Ment. Health 2024, 11, e58974. [Google Scholar] [CrossRef] [PubMed]
- Chu, Y.; Liao, L.; Zhou, Z.; Ngo, C.W.; Hong, R. Towards multimodal emotional support conversation systems. arXiv 2024, arXiv:2408.03650. [Google Scholar]
- Yang, Q.; Ye, M.; Du, B. Emollm: Multimodal emotional understanding meets large language models. arXiv 2024, arXiv:2406.16442. [Google Scholar]
- Zhang, S.; Hu, Y.; Yi, X.; Nanayakkara, S.; Chen, X. IntervEEG-LLM: Exploring EEG-Based Multimodal Data for Customized Mental Health Interventions. In Companion Proceedings of the ACM on Web Conference 2025; ACM: New York, NY, USA, 2025; pp. 2320–2326. [Google Scholar]
- Laban, G.; Wang, J.; Gunes, H. A Robot-Led Intervention for Emotion Regulation: From Expression to Reappraisal. arXiv 2025, arXiv:2503.18243. [Google Scholar]
- Dong, T.; Liu, F.; Wang, X.; Jiang, Y.; Zhang, X.; Sun, X. Emoada: A multimodal emotion interaction and psychological adaptation system. In Proceedings of the International Conference on Multimedia Modeling, Amsterdam, The Netherlands, 29 January–2 February 2024; Springer: Cham Switzerland, 2024; pp. 301–307. [Google Scholar]
- Aqajari, S.A.H.; Naeini, E.K.; Mehrabadi, M.A.; Labbaf, S.; Dutt, N.; Rahmani, A.M. pyeda: An open-source python toolkit for pre-processing and feature extraction of electrodermal activity. Procedia Comput. Sci. 2021, 184, 99–106. [Google Scholar] [CrossRef]
- Ittichaichareon, C.; Suksri, S.; Yingthawornsuk, T. Speech recognition using MFCC. In Proceedings of the International Conference on Computer Graphics, Simulation and Modeling, Pattaya, Thailand, 28–29 July 2012; Volume 9, p. 2012. [Google Scholar]
- Shaikh, M.B.; Chai, D.; Islam, S.M.S.; Akhtar, N. From CNNs to transformers in multimodal human action recognition: A survey. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 1–24. [Google Scholar] [CrossRef]
- Peng, L.; Zhang, Z.; Pang, T.; Han, J.; Zhao, H.; Chen, H.; Schuller, B.W. Customising general large language models for specialised emotion recognition tasks. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 11326–11330. [Google Scholar]
- Zhang, Q.; Wei, Y.; Han, Z.; Fu, H.; Peng, X.; Deng, C.; Hu, Q.; Xu, C.; Wen, J.; Hu, D.; et al. Multimodal fusion on low-quality data: A comprehensive survey. arXiv 2024, arXiv:2404.18947. [Google Scholar]
- Udahemuka, G.; Djouani, K.; Kurien, A.M. Multimodal Emotion Recognition using visual, vocal and Physiological Signals: A review. Appl. Sci. 2024, 14, 8071. [Google Scholar] [CrossRef]
- Plaza-del Arco, F.M.; Curry, A.; Curry, A.C.; Hovy, D. Emotion analysis in NLP: Trends, gaps and roadmap for future directions. arXiv 2024, arXiv:2403.01222. [Google Scholar]
- Huang, W.; Wang, D.; Ouyang, X.; Wan, J.; Liu, J.; Li, T. Multimodal federated learning: Concept, methods, applications and future directions. Inf. Fusion 2024, 112, 102576. [Google Scholar] [CrossRef]
- Louwerse, M.M.; Dale, R.; Bard, E.G.; Jeuniaux, P. Behavior matching in multimodal communication is synchronized. Cogn. Sci. 2012, 36, 1404–1426. [Google Scholar] [CrossRef]
- Lee, Y.K.; Jung, Y.; Kang, G.; Hahn, S. Developing social robots with empathetic non-verbal cues using large language models. arXiv 2023, arXiv:2308.16529. [Google Scholar]
- Mesquita, B. Culture and emotion: Different approaches to the question. In Emotions: Currrent Issues and Future Directions; Guilford Press: New York, NY, USA, 2001. [Google Scholar]
- Liu, G.K.M. Transforming Human Interactions with AI via Reinforcement Learning with Human Feedback (RLHF); Massachusetts Institute of Technology: Cambridge, MA, USA, 2023. [Google Scholar]
- Ali, M.; Al Machot, F.; Haj Mosa, A.; Jdeed, M.; Al Machot, E.; Kyamakya, K. A globally generalized emotion recognition system involving different physiological signals. Sensors 2018, 18, 1905. [Google Scholar] [CrossRef] [PubMed]
- Goodman, K.E.; Paul, H.Y.; Morgan, D.J. AI-generated clinical summaries require more than accuracy. JAMA 2024, 331, 637–638. [Google Scholar] [CrossRef] [PubMed]
- Rydzewski, N.R.; Dinakaran, D.; Zhao, S.G.; Ruppin, E.; Turkbey, B.; Citrin, D.E.; Patel, K.R. Comparative evaluation of LLMs in clinical oncology. NEJM AI 2024, 1, AIoa2300151. [Google Scholar] [CrossRef]
- Bedi, S.; Liu, Y.; Orr-Ewing, L.; Dash, D.; Koyejo, S.; Callahan, A.; Fries, J.A.; Wornow, M.; Swaminathan, A.; Lehmann, L.S.; et al. Testing and evaluation of health care applications of large language models: A systematic review. JAMA 2024, 333, 319–328. [Google Scholar] [CrossRef]
- Qiu, H.; Zhao, T.; Li, A.; Zhang, S.; He, H.; Lan, Z. A benchmark for understanding dialogue safety in mental health support. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Foshan, China, 12–15 October 2023; Springer: Cham, Switzerland, 2023; pp. 1–13. [Google Scholar]
- Dai, S.; Xu, C.; Xu, S.; Pang, L.; Dong, Z.; Xu, J. Bias and unfairness in information retrieval systems: New challenges in the llm era. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6437–6447. [Google Scholar]
- U.S. Food and Drug Administration. Software as a Medical Device (SaMD). 2024. Available online: https://www.fda.gov/medical-devices/digital-health-center-excellence/software-medical-device-samd (accessed on 24 July 2025).
- ISO/IEC 27001:2022; Information Security, Cybersecurity and Privacy Protection—Information Security Management Systems—Requirements. International Organization for Standardization: Geneva, Switzerland, 2022. Available online: https://www.iso.org/standard/27001 (accessed on 24 July 2025).



| Publication | Multimodal Sensing | Emotion Expression | Emotion Recognition | Emotion Regulation | AI Methods (Non-LLM) | LLMs | User Interaction | Discussion of Framework Design |
|---|---|---|---|---|---|---|---|---|
| Sun et al., 2023 [30] | √ | √ | √ | √ | √ | √ | × | × |
| Khoo et al., 2024 [27] | √ | √ | √ | Few | √ | × | × | × |
| Lutz et al., 2022 [28] | √ | × | × | √ | Few | × | Few | × |
| Bendig et al., 2022 [32] | × | √ | √ | √ | √ | × | Few | × |
| Xu et al., 2022 [31] | × | √ | √ | √ | √ | × | √ | √ |
| Lim et al., 2022 [33] | × | √ | Few | √ | × | × | √ | × |
| Olawade et al., 2024 [34] | Few | √ | √ | √ | √ | × | √ | × |
| Zhou et al., 2022 [35] | × | Few | √ | Few | √ | × | √ | × |
| Ray et al., 2022 [36] | Few | Few | × | √ | √ | × | √ | × |
| Boucher et al., 2021 [37] | × | Few | Few | √ | √ | × | √ | √ |
| Gual-Montolio et al., 2022 [38] | × | Few | Few | √ | √ | × | √ | × |
| Thomas et al., 2007 [39] | × | × | × | √ | × | × | √ | √ |
| D’Alfonso1 et al., 2017 [40] | × | × | × | √ | √ | × | √ | √ |
| Pham et al., 2022 [41] | × | × | × | × | √ | × | √ | √ |
| Kourtesis et al., 2024 [42] | Few | × | × | × | √ | × | √ | √ |
| Xiao et al., 2025 [43] | × | √ | × | √ | √ | √ | √ | √ |
| Wang et al., 2024 [44] | Few | Few | √ | × | × | √ | × | Few |
| Guo et al., 2024 [29] | Few | × | × | Few | √ | √ | √ | × |
| Our Paper | √ | √ | √ | √ | √ | √ | √ | √ |
| Publication | Visual | Auditory | Physiological | Behavioral/Contextual |
|---|---|---|---|---|
| Middya et al., 2022 [46] | √ | √ | × | × |
| Noroozi et al., 2017 [47] | √ | √ | × | × |
| Tzirakis et al., 2017 [48] | √ | √ | × | × |
| Zhang et al., 2024 [49] | √ | √ | × | × |
| Zhao et al., 2021 [50] | √ | √ | √ | × |
| Pantic et al., 2003 [51] | √ | √ | √ | × |
| Kang et al., 2023 [52] | × | √ | × | √ |
| Wu et al., 2023 [53] | × | × | √ | √ |
| Publication | Feature Extraction | Fusion Method | Classifier/Model | Emotion Labels |
|---|---|---|---|---|
| Al et al., 2019 [72] | Electrodermal activity | × | CNN (with grid search tuning) | Discrete |
| Younis et al., 2022 [73] | On-body physiological markers | Feature fusion | KNN, DT, RF, and SVM + DT meta | Discrete |
| Hossain et al., 2019 [74] | Electrodermal activity | × | CNN (with grid search tuning) | Discrete |
| Alhagry et al., 2017 [75] | ERaw EEG signals | × | LSTM + Dense Layer | Valence–Arousal + Liking |
| Wu et al., 2023 [53] | Multimodal physiological signals (ECG, EDA, EMG, and Resp) | Transformer-based shared encoder | SSL with modality-specific Conv transformer encoders | Discrete |
| Cai et al., 2020 [76] | Linear & non-linear EEG features | Feature-level fusion | KNN, DT, and SVM | Binary (Depressed/Control) |
| Cimtay et al., 2020 [77] | Facial expressions, GSR, and EEG | Hybrid fusion | CNN-based + fusion layers | Discrete |
| Publication | Dataset | Model | Environment | Accuracy/F1 |
|---|---|---|---|---|
| Tomar et al., 2024 [80] | eNTERFACE | Multimodal (feature-level fusion and CNN + MLP) | Lab | 62.93% |
| Tripathi et al., 2018 [81] | IEMOCAP | Multimodal contextual LSTM with 3D-CNN, Text-CNN, and openSMILE | Lab | 71.59% |
| Wiem et al., 2017 [82] | MAHNOB-HCI | SVM (with Gaussian kernel best) | Lab | Arousal: 64.23% and valence: 68.75% |
| Kossaifi et al., 2017 [83] | AFEW | MKL (shape + DCT) | In-the-wild | CORR = 0.445 and ICC = 0.340 |
| Tripathi et al., 2017 [84] | DEAP | CNN | Lab | Valence (2-class): 81.41% Arousal (2-class): 73.36% Valence (3-class): 66.79% Arousal (3-class): 57.58% |
| Zadeh Tripathi et al., 2018 [66] | CMU-MOSEI | Graph-MFN | Wild | Sentiment: Acc = 76.9 and F1 = 77.0 Emotion (happy): WA = 69.1 and F1 = 76.6 Emotion (sad): WA = 66.3 and F1 = 66.3 |
| Luna-Jimenez et al., 2021 [85] | RAVDESS | Fine-tuned CNN-14 (PANNs) + STN + bi-LSTM + late fusion | Lab | 80.08% |
| Chen et al., 2021 [68] | HEU | MMA (face + speech + body) | Wild | Val: 55.04% |
| Publication | Technique | LLM Involvement | Therapy Type |
|---|---|---|---|
| Wu et al., 2023 [86] | LLM-based multi-agent collaboration | GPT-4 | Potential for CBT-style management |
| Wang et al., 2024 [87] | LLM-based prompting | GPT-3.5/GPT-4 | Supportive emotional co-regulation |
| Chiu et al., 2024 [88] | LLM-based chatbot | ChatGPT and Flama | Supportive conversation |
| Qiu et al., 2024 [89] | Zero-shot prompting | GPT-4 | Supportive conversation and counselor–client interactions |
| Na et al., 2024 [90] | Zero-shot prompting and fine-tuned LLMs using structured CBT prompts and QA dataset | GPT-3.5-turbo | Derived from CBT and the CBT dataset |
| Antico et al., 2024 [91] | Contextualized informational support via a RAG-enhanced chatbot | GPT-4 | Supportive conversation |
| Publication | Modalities | LLMs | Therapy Type | Annotations |
|---|---|---|---|---|
| Chu et al., 2024 [95] | Text, audio, and video | BlenderBot, GPT-3.5, GPT-4.0, and video-LLaMA | Emotional support therapy; AI-based conversational agent | Applied/ research prototype |
| Yang et al., 2024 [96] | Text, image, audio, and video | LLaMA2-7B and GPT-4V | Emotional understanding | Theoretical/ research prototype |
| Zhang et al., 2025 [97] | EEG, text, audio, and wearable sensor | GPT-3.5, GPT-4.0, and video-LLaMA | Evidence-based intervention | Applied/ research prototype |
| Laban et al., 2025 [98] | Audio, text, and video | GPT-3.5 | Cognitive reappraisal; robot in university | Applied/ product-level |
| Dong et al., 2024 [99] | Audio, text, and video | Baichuan-13B-chat | Psychological profiling; digital psychological; avatar multimodal | Hybrid/ research prototype |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Ge, Y.; Ansari, S.; Imran, M.; Ahmad, W. Multimodal Sensing-Enabled Large Language Models for Automated Emotional Regulation: A Review of Current Technologies, Opportunities, and Challenges. Sensors 2025, 25, 4763. https://doi.org/10.3390/s25154763
Yu L, Ge Y, Ansari S, Imran M, Ahmad W. Multimodal Sensing-Enabled Large Language Models for Automated Emotional Regulation: A Review of Current Technologies, Opportunities, and Challenges. Sensors. 2025; 25(15):4763. https://doi.org/10.3390/s25154763
Chicago/Turabian StyleYu, Liangyue, Yao Ge, Shuja Ansari, Muhammad Imran, and Wasim Ahmad. 2025. "Multimodal Sensing-Enabled Large Language Models for Automated Emotional Regulation: A Review of Current Technologies, Opportunities, and Challenges" Sensors 25, no. 15: 4763. https://doi.org/10.3390/s25154763
APA StyleYu, L., Ge, Y., Ansari, S., Imran, M., & Ahmad, W. (2025). Multimodal Sensing-Enabled Large Language Models for Automated Emotional Regulation: A Review of Current Technologies, Opportunities, and Challenges. Sensors, 25(15), 4763. https://doi.org/10.3390/s25154763