
Feature-Based Normality Models for Anomaly Detection



Abstract
1. Introduction
- Unexpected types of anomalies can occur.
- Every deployed sensor will exhibit expected but potentially unknown application-specific and location-specific deviations from signals generated under laboratory conditions.
- Only short calibration periods of sensor data are available in real-world applications, assuming that an engineer can set up and monitor the sensors in a short deployment period a few days after installation.
- A sensor-specific anomaly detection framework that learns a normality model of the sensor dynamics, allowing anomaly detection to be adaptive for distributed sensor devices;
- A comprehensive evaluation of our anomaly detection model compared to other state-of-the-art anomaly detection models, including one-class classifiers and clustering approaches over six evaluation metrics;
- The demonstration of the applicability and robustness of the developed framework on different types of complex anomalies, such as point, contextual, and collective anomalies, on three public environmental monitoring datasets.
2. Related Works
3. Methodology
3.1. Background
- A point anomaly occurs when an individual data point is considered anomalous when viewed against the entire dataset.
- A contextual anomaly is a data point that is anomalous in a specific context but not otherwise. An example of a contextual anomaly is a sensor time series with yearly temperature measurements where a temperature reading of 3 °C is not unusual for winter months but is a contextual anomaly if it occurs in the summer.
- A collective anomaly occurs when a collection of related data instances is anomalous regarding the entire dataset, where the individual data points might not be anomalies, but their occurrence together as a collection is anomalous.
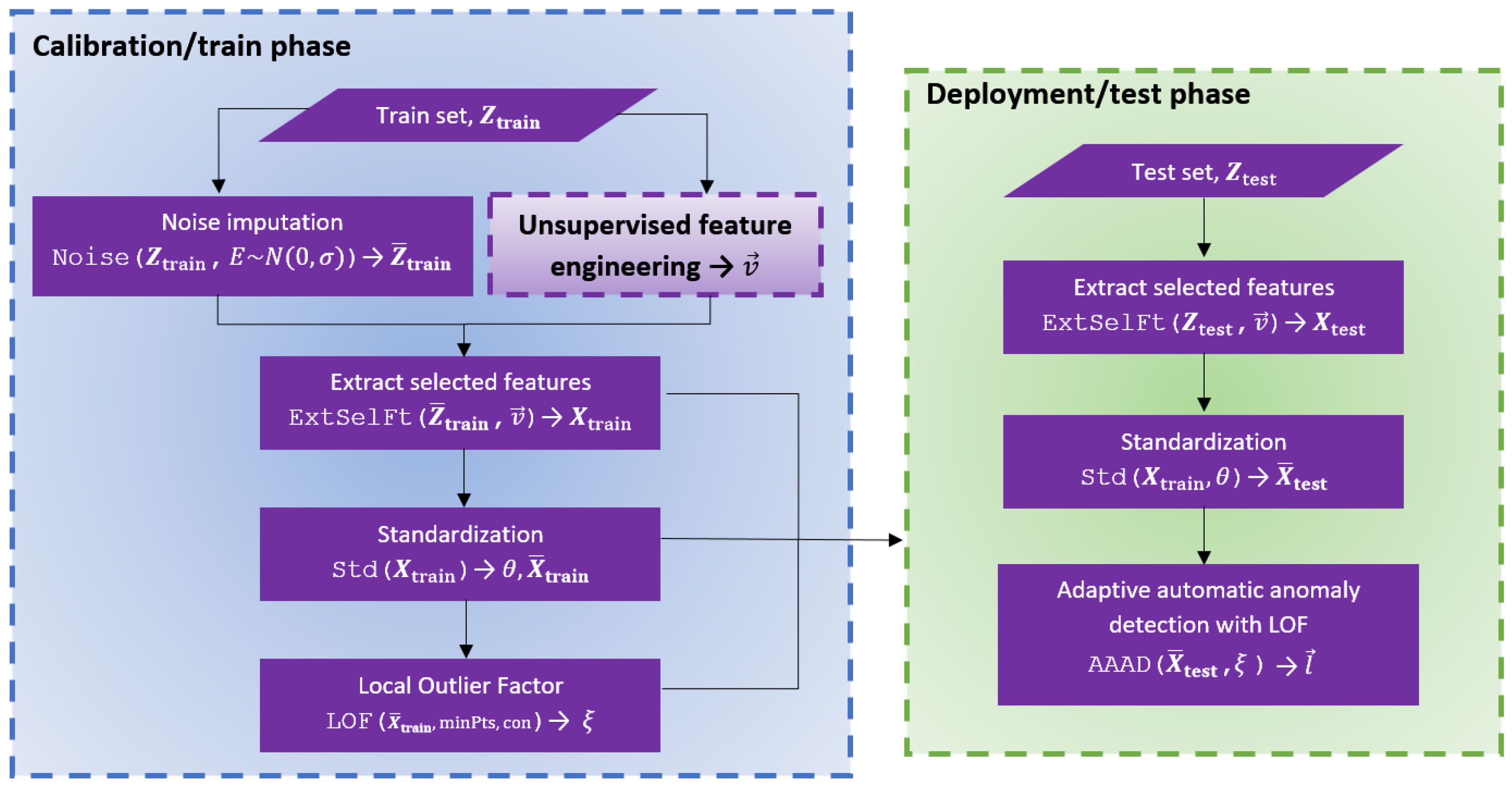
3.2. Sensor-Specific Normality Model
- The feature extraction vector function , which is a tuple of m time series feature extraction functions characterising a sequence of T consecutive sensor readings by an m-dimensional feature vector .
- The standardisation model , with parameters and standard deviations , which characterises the expected means and standard deviations along the axes of time series feature space .
- The Local Outlier Factor model , returning the anomaly score of standardised time series feature vector .
3.3. Local Outlier Factor
4. Datasets and Experiments
4.1. Experimental Set Up
- Python = 3.7.4.
- Pandas = 1.3.5.
- Numpy = 1.21.1.
- Plotly = 5.11.0.
- Scikit-learn = 0.23.2.
- Tsfresh = 0.16.0.
- One-cCass Principal Component Classifier (OC-PCA) [30], which finds the top two principal components and a linear threshold to separate the normal and anomalous data;
4.2. Dataset Preparation
4.2.1. IBRL and LUCE
- The data point is more than three standard deviations away from the mean of the time series ,
- The difference between and its neighbouring readings is larger than the standard deviation of the time series ,
4.2.2. UCR
4.3. Hyperparameter Optimisation
4.3.1. Local Outlier Factor (LOF)
4.3.2. Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
4.3.3. One-Class Principal Component Classifier (OC-PCA)
4.3.4. Isolation Forest (IF)
5. Results and Discussion
5.1. Performance Measure for Anomaly Detection
- True positives is the number of time series samples correctly identified as anomalies.
- True negatives is the number of time series samples correctly identified as normal.
- False positives is the number of time series samples that are normal but incorrectly labelled as anomalies (type 1 error).
- False negatives is the number of anomalous time series samples that were incorrectly identified as normal (type 2 error).
- False Positive Rate FPR , also known as fall-out or the false alarm rate, is useful for applications that focus on avoiding the misclassification of normal data as anomalous. A smaller FPR is better.
- Recall , also known as true-positive rate, sensitivity, or hit rate, is useful for applications that require that all anomalies are detected. At the same time, costs for classifying normal data as anomalous can be ignored. A larger Recall is better.
- Precision , also known as the positive predictive value, is useful for applications that associate high costs with false positives. A large Precision is better.
- F-Score is a harmonic mean of recall and precision. A larger F-score is better.
- Accuracy is very inaccurate for imbalanced problems, because predicting the majority class always results in high Accuracy (cf last row of Table 2).
- Matthews Correlation Coefficient MCC is well-suited to measure the performance of imbalanced classification problems [72]. Larger MCC scores are better. An MCC score of zero indicates guessing of the majority class.
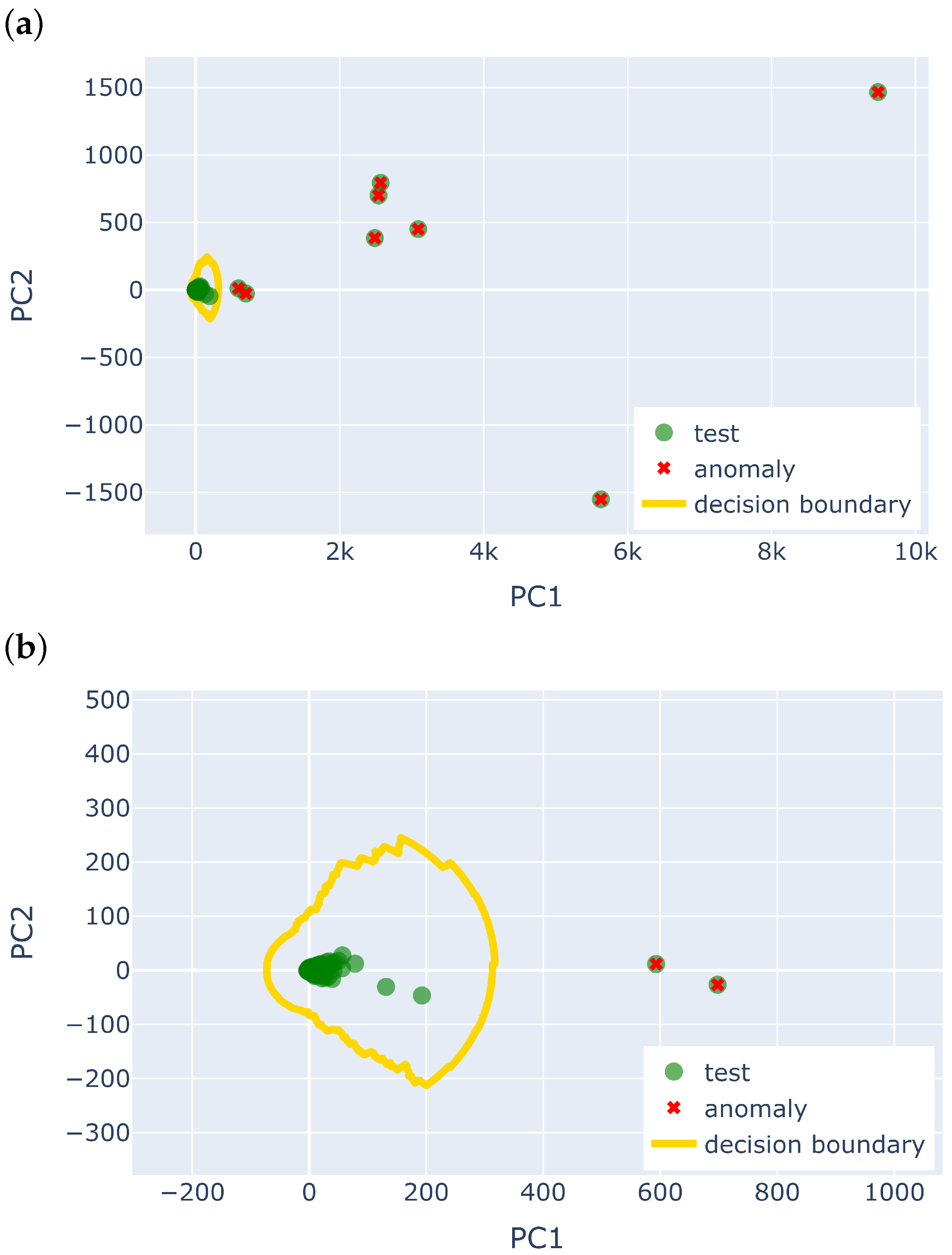
5.2. Point Anomalies in IBRL and LUCE
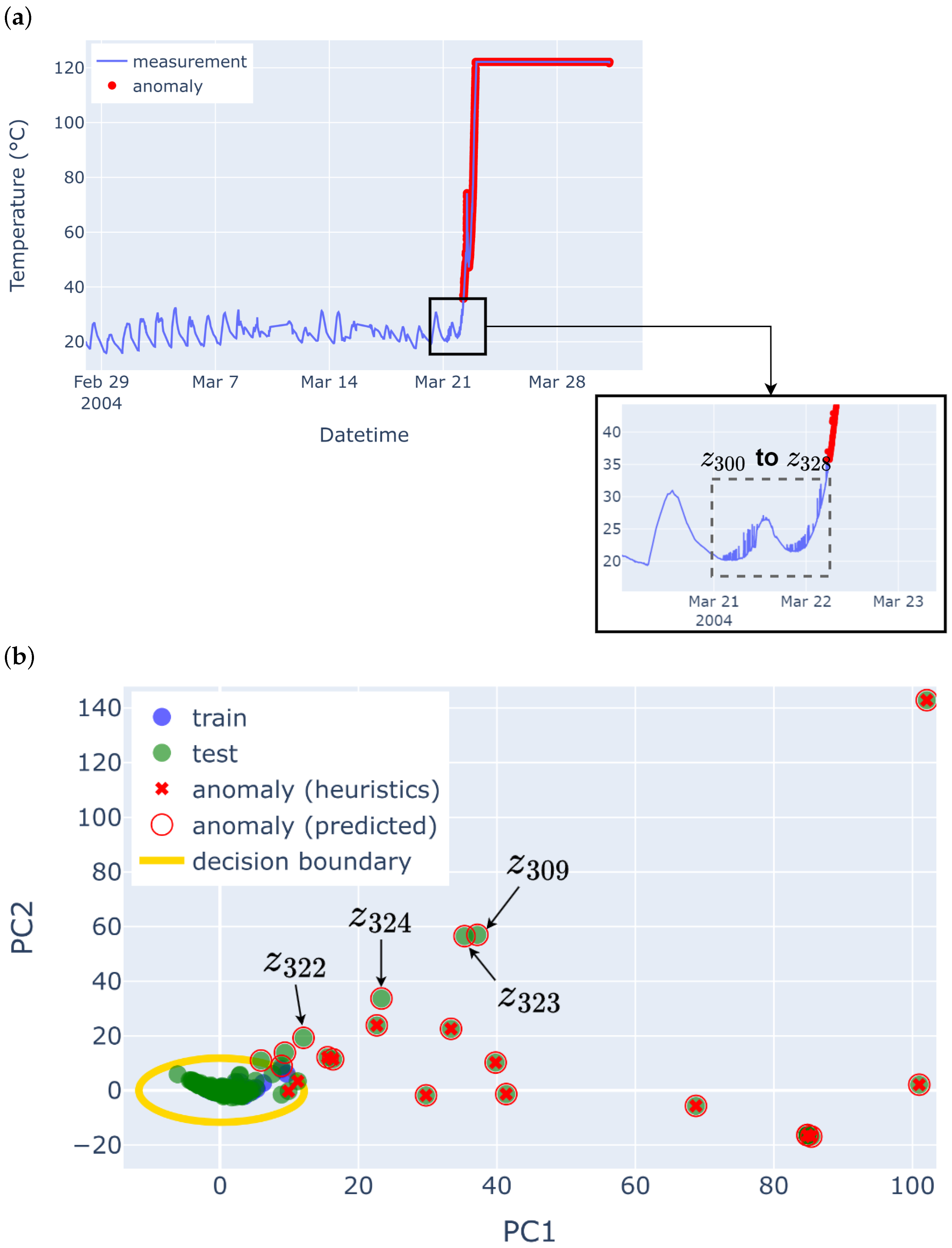
5.3. Contextual and Collective Anomalies in UCR
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rahman, A.; Smith, D.V.; Timms, G. A Novel Machine Learning Approach Toward Quality Assessment of Sensor Data. IEEE Sens. J. 2013, 14, 1035–1047. [Google Scholar] [CrossRef]
- Yu, Z.; Bedig, A.; Montalto, F.; Quigley, M. Automated detection of unusual soil moisture probe response patterns with association rule learning. Environ. Model. Softw. 2018, 105, 257–269. [Google Scholar] [CrossRef]
- Liu, G.; Li, L.; Zhang, L.; Li, Q.; Law, S.S. Sensor faults classification for SHM systems using deep learning-based method with Tsfresh features. Smart Mater. Struct. 2020, 29, 075005. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, J.; Pang, A.C. A Bayesian network model for data losses and faults in medical body sensor networks. Comput. Netw. 2018, 143, 166–175. [Google Scholar] [CrossRef]
- Zhao, C.; Fu, Y. Statistical analysis based online sensor failure detection for continuous glucose monitoring in type I diabetes. Chemom. Intell. Lab. Syst. 2015, 144, 128–137. [Google Scholar] [CrossRef]
- Liu, H.; Chen, J.; Huang, F.; Li, H. An Electric Power Sensor Data Oriented Data Cleaning Solution. In Proceedings of the 2017 14th International Symposium on Pervasive Systems, Algorithms and Networks & 2017 11th International Conference on Frontier of Computer Science and Technology & 2017 Third International Symposium of Creative Computing (ISPAN-FCST-ISCC), Exeter, UK, 21–23 June 2017; pp. 430–435. [Google Scholar] [CrossRef]
- Wang, X.; Kong, L.; Wei, T.; He, L.; Chen, G.; Wang, J.; Xu, C. VLD: Smartphone-assisted Vertical Location Detection for Vehicles in Urban Environments. In Proceedings of the 2020 19th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Sydney, NSW, Australia, 21–24 April 2020; pp. 25–36. [Google Scholar] [CrossRef]
- Sehrawat, D.; Gill, N.S. Smart Sensors: Analysis of Different Types of IoT Sensors. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 523–528. [Google Scholar] [CrossRef]
- Mao, F.; Khamis, K.; Krause, S.; Clark, J.; Hannah, D.M. Low-Cost Environmental Sensor Networks: Recent Advances and Future Directions. Front. Earth Sci. 2019, 7, 221. [Google Scholar] [CrossRef]
- Petrellis, N.; Birbas, M.; Gioulekas, F. On the Design of Low-Cost IoT Sensor Node for e-Health Environments. Electronics 2019, 8, 178. [Google Scholar] [CrossRef]
- de Camargo, E.T.; Spanhol, F.A.; Slongo, J.S.; da Silva, M.V.R.; Pazinato, J.; de Lima Lobo, A.V.; Coutinho, F.R.; Pfrimer, F.W.D.; Lindino, C.A.; Oyamada, M.S.; et al. Low-Cost Water Quality Sensors for IoT: A Systematic Review. Sensors 2023, 23, 4424. [Google Scholar] [CrossRef] [PubMed]
- Fascista, A. Toward Integrated Large-Scale Environmental Monitoring Using WSN/UAV/Crowdsensing: A Review of Applications, Signal Processing, and Future Perspectives. Sensors 2022, 22, 1824. [Google Scholar] [CrossRef]
- Connolly, R.E.; Yu, Q.; Wang, Z.; Chen, Y.H.; Liu, J.Z.; Collier-Oxandale, A.; Papapostolou, V.; Polidori, A.; Zhu, Y. Long-term evaluation of a low-cost air sensor network for monitoring indoor and outdoor air quality at the community scale. Sci. Total Environ. 2022, 807, 150797. [Google Scholar] [CrossRef]
- Anastasiou, E.; Vilcassim, M.J.R.; Adragna, J.; Gill, E.; Tovar, A.; Thorpe, L.E.; Gordon, T. Feasibility of low-cost particle sensor types in long-term indoor air pollution health studies after repeated calibration, 2019–2021. Sci. Rep. 2022, 12, 14571. [Google Scholar] [CrossRef]
- Abuaitah, G.R.; Wang, B. Data-centric anomalies in sensor network deployments: Analysis and detection. In Proceedings of the 2012 IEEE 9th International Conference on Mobile Ad-Hoc and Sensor Systems (MASS 2012), Las Vegas, NV, USA, 8–11 October 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Fawzy, A.; Mokhtar, H.M.O.; Hegazy, O. Outliers detection and classification in wireless sensor networks. Egypt. Inform. J. 2013, 14, 157–164. [Google Scholar] [CrossRef]
- Soares, N.; de Aguiar, E.P.; Souza, A.; Goliatt, L. Unsupervised Machine Learning Techniques to Prevent Faults in Railroad Switch Machines. Int. J. Crit. Infrastruct. Prot. 2021, 33, 100423. [Google Scholar] [CrossRef]
- Kong, L.; Yu, J.; Tang, D.; Song, Y.; Han, D. Multivariate Time Series Anomaly Detection with Generative Adversarial Networks Based on Active Distortion Transformer. IEEE Sens. J. 2023, 23, 9658–9668. [Google Scholar] [CrossRef]
- Jiang, D.; Chu, T.; Li, W. Research on Industrial Sensor Self-Diagnosis Method Based on Redundancy Relationship Analysis. IEEE Trans. Instrum. Meas. 2025, 74, 3527614. [Google Scholar] [CrossRef]
- Harandi, M.Z.; Li, C.; Schou, C.; Villumsen, S.L.; Bøgh, S.; Madsen, O. STAD-FEBTE, a shallow and supervised framework for time series anomaly detection by automatic feature engineering, balancing, and tree-based ensembles: An industrial case study. In Proceedings of the 2023 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Seattle, WA, USA, 28–30 June 2023; pp. 840–846. [Google Scholar] [CrossRef]
- Rassam, M.A.; Maarof, M.A.; Zainal, A. Adaptive and online data anomaly detection for wireless sensor systems. Knowl.-Based Syst. 2014, 60, 44–57. [Google Scholar] [CrossRef]
- Vercruyssen, V.; Meert, W.; Verbruggen, G.; Maes, K.; Bäumer, R.; Davis, J. Semi-Supervised Anomaly Detection with an Application to Water Analytics. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 527–536. [Google Scholar] [CrossRef]
- Saeedi Emadi, H.; Mazinani, S.M. A Novel Anomaly Detection Algorithm Using DBSCAN and SVM in Wireless Sensor Networks. Wirel. Pers. Commun. 2018, 98, 2025–2035. [Google Scholar] [CrossRef]
- Zhang, W.; Dong, X.; Li, H.; Xu, J.; Wang, D. Unsupervised Detection of Abnormal Electricity Consumption Behavior Based on Feature Engineering. IEEE Access 2020, 8, 55483–55500. [Google Scholar] [CrossRef]
- Best, L.; Foo, E.; Tian, H. Utilising K-Means Clustering and Naive Bayes for IoT Anomaly Detection: A Hybrid Approach. In Secure and Trusted Cyber Physical Systems: Recent Approaches and Future Directions; Pal, S., Jadidi, Z., Foo, E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 177–214. [Google Scholar] [CrossRef]
- Bosman, H.H.W.J.; Iacca, G.; Tejada, A.; Wörtche, H.J.; Liotta, A. Ensembles of incremental learners to detect anomalies in ad hoc sensor networks. Ad Hoc Netw. 2015, 35, 14–36. [Google Scholar] [CrossRef]
- Ouyang, Z.; Sun, X.; Yue, D. Hierarchical Time Series Feature Extraction for Power Consumption Anomaly Detection. In Advanced Computational Methods in Energy, Power, Electric Vehicles, and Their Integration; Li, K., Xue, Y., Cui, S., Niu, Q., Yang, Z., Luk, P., Eds.; Communications in Computer and Information Science; Springer: Singapore, 2017; pp. 267–275. [Google Scholar] [CrossRef]
- Attarha, S.; Band, S.; Förster, A. Automated Fault Detection Framework for Reliable Provision of IoT Applications in Agriculture. In Proceedings of the 2023 19th International Conference on the Design of Reliable Communication Networks (DRCN), Vilanova i la Geltru, Spain, 17–20 April 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Sinha, A.; Das, D. SNRepair: Systematically Addressing Sensor Faults and Self-Calibration in IoT Networks. IEEE Sens. J. 2023, 23, 14915–14922. [Google Scholar] [CrossRef]
- Teh, H.Y.; Wang, K.I.K.; Kempa-Liehr, A.W. Expect the Unexpected: Unsupervised feature selection for automated sensor anomaly detection. IEEE Sens. J. 2021, 21, 18033–18046. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. ACM SIGMOD Rec. 2000, 29, 93–104. [Google Scholar] [CrossRef]
- Teh, H.Y.; Kempa-Liehr, A.W.; Wang, K.I.K. Sensor data quality: A systematic review. J. Big Data 2020, 7, 11. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Outlier Analysis, 2nd ed.; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Barde, A.; Jain, S. A Survey of Multi-Sensor Data Fusion in Wireless Sensor Networks. In Proceedings of the 3rd International Conference on Internet of Things and Connected Technologies (ICIoTCT), Jaipur, India, 26–27 March 2018. [Google Scholar] [CrossRef]
- Acquaah, Y.T.; Kaushik, R. Normal-Only Anomaly Detection in Environmental Sensors in CPS: A Comprehensive Review. IEEE Access 2024, 12, 191086–191107. [Google Scholar] [CrossRef]
- Alwan, A.A.; Ciupala, M.A.; Brimicombe, A.J.; Ghorashi, S.A.; Baravalle, A.; Falcarin, P. Data quality challenges in large-scale cyber-physical systems: A systematic review. Inf. Syst. 2022, 105, 101951. [Google Scholar] [CrossRef]
- Perera, P.; Oza, P.; Patel, V.M. One-Class Classification: A Survey. arXiv 2021, arXiv:2101.03064. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Zhang, Y.; Meratnia, N.; Havinga, P.J.M. Distributed online outlier detection in wireless sensor networks using ellipsoidal support vector machine. Ad Hoc Netw. 2013, 11, 1062–1074. [Google Scholar] [CrossRef]
- Lamrini, B.; Gjini, A.; Daudin, S.; Armando, F.; Pratmarty, P.; Travé-Massuyès, L. Anomaly Detection Using Similarity-based One-Class SVM for Network Traffic Characterization. In Proceedings of the 29th International Workshop on Principles of Diagnosis, Warsaw, Poland, 27–30 August 2018. [Google Scholar]
- Hejazi, M.; Singh, Y.P. One-Class Support Vector Machines Approach to Anomaly Detection. Appl. Artif. Intell. 2013, 27, 351–366. [Google Scholar] [CrossRef]
- Vuong Trinh, V.; Phuc Tran, K.; Thu Huong, T. Data driven hyperparameter optimization of one-class support vector machines for anomaly detection in wireless sensor networks. In Proceedings of the 2017 International Conference on Advanced Technologies for Communications (ATC), Quy Nhon, Vietnam, 18–20 October 2017; pp. 6–10. [Google Scholar] [CrossRef]
- Jia, Y.; Chen, H.; Yuan, L.; Hou, X. Flight operation anomaly detection based on one-class SVM. In Proceedings of the Fifth International Conference on Traffic Engineering and Transportation System (ICTETS 2021), Chongqing, China, 24–26 September 2021; Volume 12058, pp. 816–820. [Google Scholar] [CrossRef]
- Alghushairy, O.; Alsini, R.; Soule, T.; Ma, X. A Review of Local Outlier Factor Algorithms for Outlier Detection in Big Data Streams. Big Data Cogn. Comput. 2021, 5, 1. [Google Scholar] [CrossRef]
- Xu, L.; Yeh, Y.R.; Lee, Y.J.; Li, J. A Hierarchical Framework Using Approximated Local Outlier Factor for Efficient Anomaly Detection. Procedia Comput. Sci. 2013, 19, 1174–1181. [Google Scholar] [CrossRef]
- Ma, M.X.; Ngan, H.Y.; Liu, W. Density-based Outlier Detection by Local Outlier Factor on Largescale Traffic Data. Electron. Imaging 2016, 28, art00003. [Google Scholar] [CrossRef]
- Auskalnis, J.; Paulauskas, N.; Baskys, A. Application of Local Outlier Factor Algorithm to Detect Anomalies in Computer Network. Elektronika Ir Elektrotechnika 2018, 24, 96–99. [Google Scholar] [CrossRef]
- Paulauskas, N.; Bagdonas, Ą.F. Local outlier factor use for the network flow anomaly detection. Secur. Commun. Netw. 2015, 8, 4203–4212. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Susto, G.A.; Beghi, A.; McLoone, S. Anomaly detection through on-line isolation Forest: An application to plasma etching. In Proceedings of the 2017 28th Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), Saratoga Springs, NY, USA, 15–18 May 2017. [Google Scholar] [CrossRef]
- Zhong, S.; Fu, S.; Lin, L.; Fu, X.; Cui, Z.; Wang, R. A novel unsupervised anomaly detection for gas turbine using Isolation Forest. In Proceedings of the 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Qin, Y.; Lou, Y. Hydrological Time Series Anomaly Pattern Detection based on Isolation Forest. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1706–1710. [Google Scholar] [CrossRef]
- Cheng, Z.; Zou, C.; Dong, J. Outlier detection using isolation forest and local outlier factor. In Proceedings of the Conference on Research in Adaptive and Convergent Systems, Chongqing, China, 24–27 September 2019; pp. 161–168. [Google Scholar] [CrossRef]
- Çelik, M.; Dadaşer-Çelik, F.; Dokuz, A.c. Anomaly detection in temperature data using DBSCAN algorithm. In Proceedings of the 2011 International Symposium on Innovations in Intelligent Systems and Applications, Istanbul, Turkey, 15–18 June 2011; pp. 91–95. [Google Scholar] [CrossRef]
- Wibisono, S.; Anwar, M.T.; Supriyanto, A.; Amin, I.H.A. Multivariate weather anomaly detection using DBSCAN clustering algorithm. J. Phys. Conf. Ser. 2021, 1869, 012077. [Google Scholar] [CrossRef]
- Zidi, S.; Moulahi, T.; Alaya, B. Fault Detection in Wireless Sensor Networks Through SVM Classifier. IEEE Sens. J. 2018, 18, 340–347. [Google Scholar] [CrossRef]
- Pota, M.; De Pietro, G.; Esposito, M. Real-time anomaly detection on time series of industrial furnaces: A comparison of autoencoder architectures. Eng. Appl. Artif. Intell. 2023, 124, 106597. [Google Scholar] [CrossRef]
- Li, W.; Shang, Z.; Zhang, J.; Gao, M.; Qian, S. A novel unsupervised anomaly detection method for rotating machinery based on memory augmented temporal convolutional autoencoder. Eng. Appl. Artif. Intell. 2023, 123, 106312. [Google Scholar] [CrossRef]
- Goyal, V.; Yadav, A.; Kumar, S.; Mukherjee, R. Lightweight LAE for Anomaly Detection With Sound-Based Architecture in Smart Poultry Farm. IEEE Internet Things J. 2024, 11, 8199–8209. [Google Scholar] [CrossRef]
- Liu, Y.; Garg, S.; Nie, J.; Zhang, Y.; Xiong, Z.; Kang, J.; Hossain, M.S. Deep Anomaly Detection for Time-Series Data in Industrial IoT: A Communication-Efficient On-Device Federated Learning Approach. IEEE Internet Things J. 2021, 8, 6348–6358. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Assem, H.; Xu, L.; Buda, T.S.; O’Sullivan, D. Chapter 8—Cognitive Applications and Their Supporting Architecture for Smart Cities. In Big Data Analytics for Sensor-Network Collected Intelligence; Hsu, H.H., Chang, C.Y., Hsu, C.H., Eds.; Part of Series Intelligent Data-Centric Systems; Academic Press: London, UK, 2017; pp. 167–185. [Google Scholar] [CrossRef]
- Madden, S. Intel Lab Data. 2004. Available online: http://db.csail.mit.edu/labdata/labdata.html (accessed on 23 June 2020).
- Barrenetxea, G. Sensorscope Data. 2019. Available online: https://zenodo.org/records/2654726 (accessed on 23 June 2020).
- Dau, H.A.; Keogh, E.; Kamgar, K.; Yeh, C.-C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Chen, Y.; Hu, B.; Begum, N.; et al. The UCR Time Series Classification Archive. 2018. Available online: https://www.cs.ucr.edu/~eamonn/time_series_data_2018/ (accessed on 26 April 2022).
- Keogh, E.; Dutta Roy, T.; Naik, U.; Agrawal, A. Multi-Dataset Time-Series Anomaly Detection Competition, SIGKDD. 2021. Available online: https://compete.hexagon-ml.com/practice/competition/39/ (accessed on 26 April 2022).
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time Series FeatuRe Extraction on basis of Scalable Hypothesis tests (tsfresh—A Python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Kennedy, A.; Nash, G.; Rattenbury, N.; Kempa-Liehr, A.W. Modelling the projected separation of microlensing events using systematic time-series feature engineering. Astron. Comput. 2021, 35, 100460. [Google Scholar] [CrossRef]
- Wu, R.; Keogh, E. Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress. IEEE Trans. Knowl. Data Eng. 2021, 35, 2421–2429. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow, 4th release ed.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and Its Applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Bear, A.; Knobe, J. Normality: Part descriptive, part prescriptive. Cognition 2017, 167, 25–37. [Google Scholar] [CrossRef]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Dakalbab, F.M. Machine Learning for Anomaly Detection: A Systematic Review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Abrasaldo, P.M.B.; Zarrouk, S.J.; Mudie, A.; Cen, J.; Siega, C.; Kempa-Liehr, A.W. Detection of abnormal operation in geothermal binary plant feed pumps using time-series analytics. Expert Syst. Appl. 2024, 247, 123305. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; van den Hengel, A. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2021, 54, 38. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Anomaly Type | Anomaly Chunk Index |
|---|---|---|
| (i) | Merge peaks and remove valley | 237–238 |
| (ii) | Flipped data across mean | 271–272 |
| (iii) | Noise | 231–233 |
| (iv) | Random walk | 202–204 |
| (v) | Smoothed random walk and anomalous peak | 250–252 |
| Dataset | Features | Classifier | FPR | Recall | Precision | F-Score | Accuracy | MCC |
|---|---|---|---|---|---|---|---|---|
| IBRL | AAAD | 0.007 | 0.991 | 0.999 | 0.995 | 0.991 | 0.968 | |
| OC-PCA | 0.003 | 0.948 | 0.937 | 0.944 | 0.962 | 0.931 | ||
| DBSCAN | 0.003 | 0.805 | 0.839 | 0.811 | 0.980 | 0.810 | ||
| OC-SVM | 0.0 | 0.942 | 1.0 | 0.959 | 0.949 | 0.886 | ||
| IF | 0.142 | 0.866 | 0.975 | 0.915 | 0.865 | 0.599 | ||
| LUCE | AAAD | 0.051 | 0.958 | 0.998 | 0.977 | 0.959 | 0.802 | |
| OC-PCA | 0.004 | 0.656 | 0.628 | 0.646 | 0.986 | 0.662 | ||
| DBSCAN | 0.0003 | 0.781 | 0.827 | 0.730 | 0.993 | 0.762 | ||
| OC-SVM | 0.045 | 0.761 | 0.776 | 0.768 | 0.773 | 0.643 | ||
| IF | 0.356 | 0.959 | 0.979 | 0.968 | 0.941 | 0.508 | ||
| UCR | AAAD | 0.0 | 0.733 | 1.0 | 0.82 | 0.995 | 0.840 | |
| OC-PCA | 0.001 | 0.466 | 0.9 | 0.593 | 0.990 | 0.632 | ||
| DBSCAN | 0.005 | 0.733 | 0.633 | 0.666 | 0.989 | 0.669 | ||
| OC-SVM | 0.0 | 0.633 | 1.0 | 0.75 | 0.994 | 0.781 | ||
| IF | 0.169 | 0.799 | 0.064 | 0.119 | 0.829 | 0.193 |
| Feature | tsfresh Algorithm | Parameters |
|---|---|---|
| Maximum | maximum | None |
| Quantile | quantile | q=0.6 |
| Quantile | quantile | q=0.7 |
| Quantile | quantile | q=0.8 |
| Conditional Dynamics | change_quantiles | f_agg="mean", isabs=False, |
| qh=1.0, ql=0.0 |
| Feature | tsfresh Algorithm | Parameters |
|---|---|---|
| Maximum | maximum | None |
| Complexity | cid_ce | normalize=False |
| Conditional Dynamics | change_quantiles | f_agg="var", isabs=False, |
| qh=0.6, ql=0.0 | ||
| Conditional Dynamics | change_quantiles | f_agg="var", isabs=False, |
| qh=0.8, ql=0.0 | ||
| Conditional Dynamics | change_quantiles | f_agg="var", isabs=True, |
| qh=1.0, ql=0.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teh, H.Y.; Wang, K.I.-K.; Kempa-Liehr, A.W. Feature-Based Normality Models for Anomaly Detection. Sensors 2025, 25, 4757. https://doi.org/10.3390/s25154757
Teh HY, Wang KI-K, Kempa-Liehr AW. Feature-Based Normality Models for Anomaly Detection. Sensors. 2025; 25(15):4757. https://doi.org/10.3390/s25154757
Chicago/Turabian StyleTeh, Hui Yie, Kevin I-Kai Wang, and Andreas W. Kempa-Liehr. 2025. "Feature-Based Normality Models for Anomaly Detection" Sensors 25, no. 15: 4757. https://doi.org/10.3390/s25154757
APA StyleTeh, H. Y., Wang, K. I.-K., & Kempa-Liehr, A. W. (2025). Feature-Based Normality Models for Anomaly Detection. Sensors, 25(15), 4757. https://doi.org/10.3390/s25154757