
Lightweight Vision Transformer for Frame-Level Ergonomic Posture Classification in Industrial Workflows
 ,
,  and
and 
Abstract
1. Introduction
- Occlusion resilience—despite temporal fusion and person segmentation, long or permanent occlusions still degrade joint tracking and risk estimates.
- Dataset realism and scale—many claims of near-perfect accuracy rely on small or proprietary datasets that do not capture the lighting, attire and workflow variability of real factories.
- Outcome linkage—only a handful of studies quantify posture recognition through indices directly linked to musculoskeletal risk prediction.
- A vision-based ergonomic risk classification framework is proposed, leveraging a ViT architecture for direct analysis of RGB images, without relying on skeleton reconstruction or joint angle estimation.
- The system is designed to classify multiple body regions simultaneously within a single model, reducing computational complexity and simplifying training and inference procedures.
- The approach is validated on a multimodal dataset of simulated industrial tasks, reflecting realistic working conditions and addressing common challenges such as posture variability and occlusion.
- The classification output is directly linked to ergonomic risk indices, enabling frame-level posture risk assessment applicable to industrial monitoring scenarios.
2. Materials and Methods
2.1. Dataset Creation
- 1.
- Extraction of individual frames from the video recording.
- 2.
- Removal of non-relevant frames (e.g., neutral postures, transitions).
- 3.
- Matching of each frame to its corresponding motion data entry.
- 4.
- Calculation of joint angles and ergonomic risk label for each body segment.
- 5.
- Saving each frame as a labeled image, where the filename encodes the frame number and the ergonomic classification for the specific body part.
2.2. Data Processing
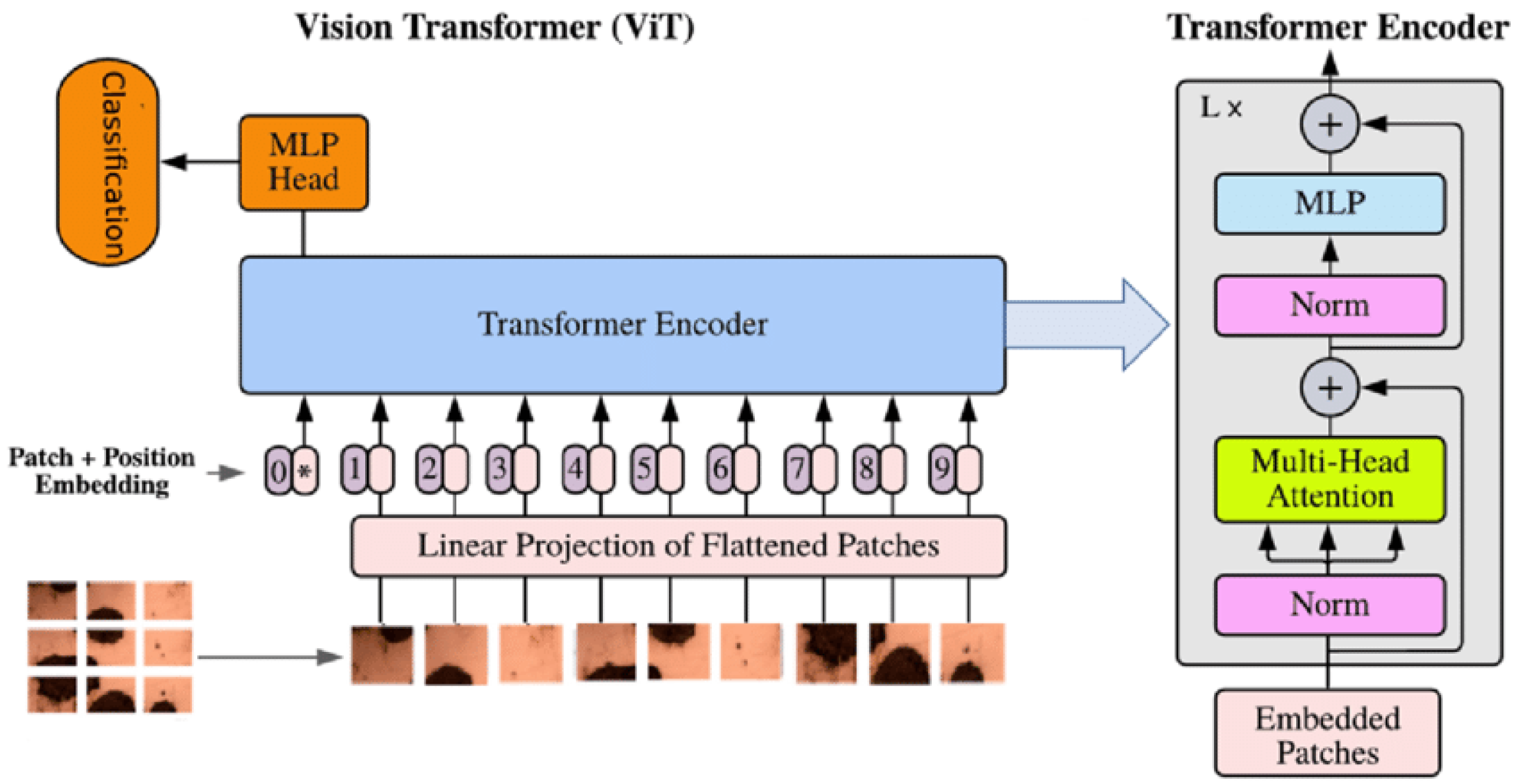
2.3. Network Architecture
Architecture Parameters
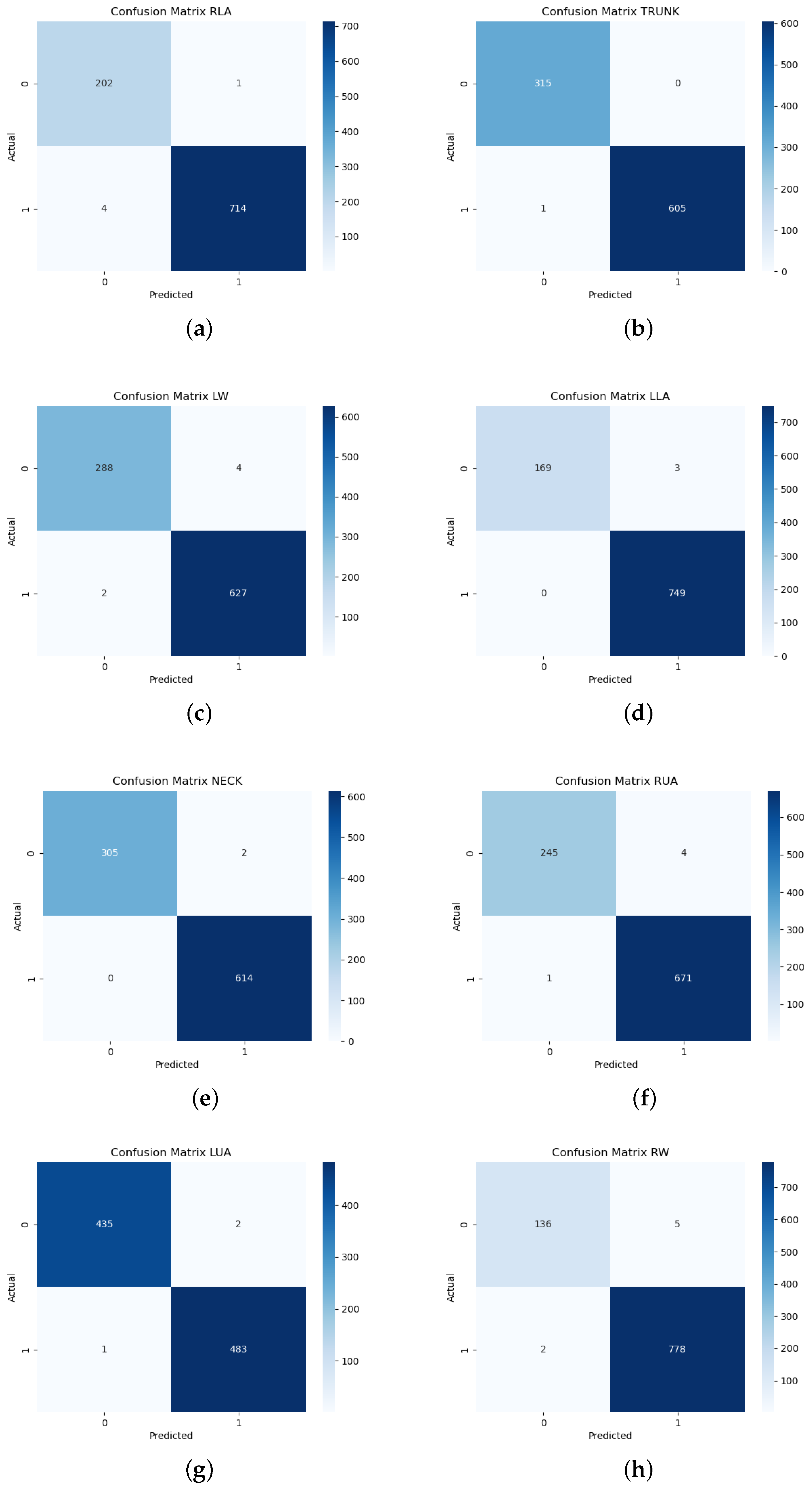
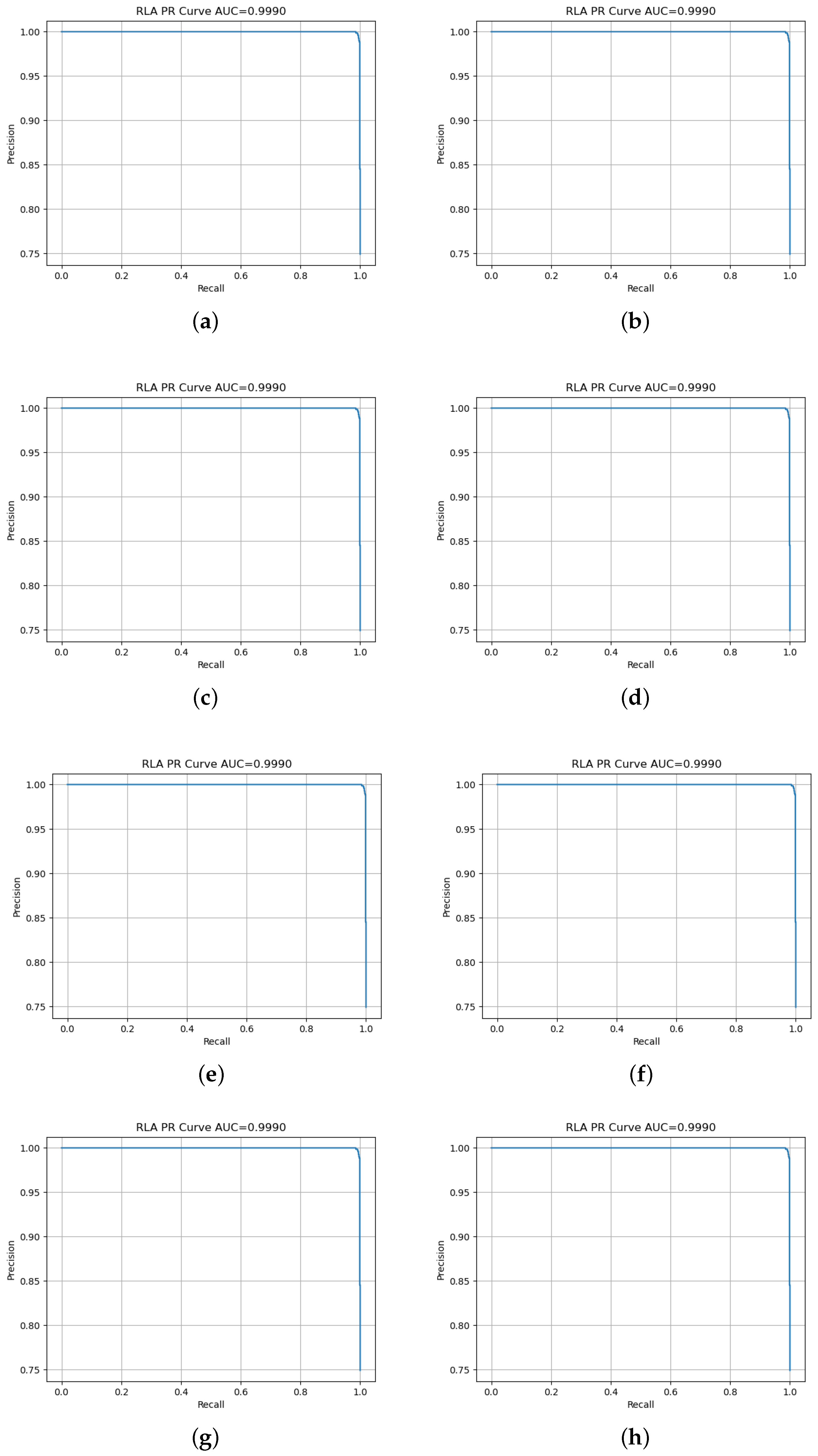
3. Results
- Accuracy, i.e., the percentage of correct predictions out of the total number of predictionswhere TP represents the True Positives, TN represents the True Negatives, FP represents the False Positives, and FN represents the False Negatives.
- Area Under the Curve (AUC) reporting the model’s ability to discriminate between the two classeswhere TPR is the True Positive Rate and FPR is the False Positive Rate.
- Precision that considers among all positive predictions those that are truly positive
- Recall (Sensitivity) which measures the TP predictions that have been detected, giving a measure descriptive of the discriminative capacity of the model
- F1-Score, i.e., the harmonic mean between Precision and Recall, which provides an analytical compromise for highly unbalanced datasets such as the one under study
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- European Agency for Safety and Health at Work. Work-Related Musculoskeletal Disorders: Prevalence, Costs and Demographics in the EU; Publications Office of the European Union: Luxembourg, 2019. [Google Scholar]
- Parent-Thirion, A.; Biletta, I.; Cabrita, J.; Vargas, O.; Vermeylen, G.; Wilczynska, A.; Wilkens, M. Eurofound (2017), Sixth European Working Conditions Survey-Overview Report (2017 Update); Publications Office of the European Union: Luxembourg, 2017; pp. 1–164. [Google Scholar]
- Korhan, O.; Memon, A.A. Introductory chapter: Work-related musculoskeletal disorders. In Work-Related Musculoskeletal Disorders; IntechOpen: Rijeka, Croatia, 2019. [Google Scholar] [CrossRef]
- Copsey, S.; Irastorza, X.; Schneider, E. Work-Related Musculoskeletal Disorders in the EU—Facts and Figures; Publications Office of the European Union: Luxembourg, 2010; pp. 29–49. [Google Scholar]
- De Kok, J.; Vroonhof, P.; Snijders, J.; Roullis, G.; Clarke, M.; Peereboom, K.; van Dorst, P.; Isusi, I. Work-Related Musculoskeletal Disorders: Prevalence, Costs and Demographics in the EU; Publications Office of the European Union: Luxembourg, 2019; p. 215. [Google Scholar] [CrossRef]
- Malchaire, J.; Gauthy, R.; Piette, A.; Strambi, F. A Classification of Methods for Assessing and/or Preventing the Risks of Musculoskeletal Disorders; ETUI, European Trade Union Institute: Brussels, Belgium, 2011. [Google Scholar]
- Humadi, A.; Nazarahari, M.; Ahmad, R.; Rouhani, H. In-field instrumented ergonomic risk assessment: Inertial measurement units versus Kinect V2. Int. J. Ind. Ergon. 2021, 84, 103147. [Google Scholar] [CrossRef]
- Abbasi-Ghiri, A.; Ebrahimkhani, M.; Arjmand, N. Novel force–displacement control passive finite element models of the spine to simulate intact and pathological conditions; comparisons with traditional passive and detailed musculoskeletal models. J. Biomech. 2022, 141, 111173. [Google Scholar] [CrossRef]
- Bonakdar, A.; Houshmand, S.; Martinez, K.B.; Golabchi, A.; Tavakoli, M.; Rouhani, H. Fatigue assessment in multi-activity manual handling tasks through joint angle monitoring with wearable sensors. Biomed. Signal Process. Control 2025, 102, 107398. [Google Scholar] [CrossRef]
- Salisu, S.; Ruhaiyem, N.I.R.; Eisa, T.A.E.; Nasser, M.; Saeed, F.; Younis, H.A. Motion Capture Technologies for Ergonomics: A Systematic Literature Review. Diagnostics 2023, 13, 2593. [Google Scholar] [CrossRef] [PubMed]
- Battini, D.; Persona, A.; Sgarbossa, F. Innovative real-time system to integrate ergonomic evaluations into warehouse design and management. Comput. Ind. Eng. 2014, 77, 1–10. [Google Scholar] [CrossRef]
- Peppoloni, L.; Filippeschi, A.; Ruffaldi, E.; Avizzano, C. A novel wearable system for the online assessment of risk for biomechanical load in repetitive efforts. Int. J. Ind. Ergon. 2016, 52, 1–11. [Google Scholar] [CrossRef]
- Merino, G.; da Silva, L.; Mattos, D.; Guimarães, B.; Merino, E. Ergonomic evaluation of the musculoskeletal risks in a banana harvesting activity through qualitative and quantitative measures, with emphasis on motion capture (Xsens) and EMG. Int. J. Ind. Ergon. 2019, 69, 80–89. [Google Scholar] [CrossRef]
- Caputo, F.; Greco, A.; D’Amato, E.; Notaro, I.; Spada, S. On the use of Virtual Reality for a human-centered workplace design. Procedia Struct. Integr. 2018, 8, 297–308. [Google Scholar] [CrossRef]
- González-Alonso, J.; Simón-Martínez, C.; Antón-Rodríguez, M.; González-Ortega, D.; Díaz-Pernas, F.; Martínez-Zarzuela, M. Development of an end-to-end hardware and software pipeline for affordable and feasible ergonomics assessment in the automotive industry. Saf. Sci. 2024, 173, 106431. [Google Scholar] [CrossRef]
- Lim, S.; D’Souza, C. A narrative review on contemporary and emerging uses of inertial sensing in occupational ergonomics. Int. J. Ind. Ergon. 2020, 76, 102937. [Google Scholar] [CrossRef]
- Vlasic, D.; Adelsberger, R.; Vannucci, G.; Barnwell, J.; Gross, M.; Matusik, W.; Popović, J. Practical Motion Capture in Everyday Surroundings. ACM Trans. Graph. 2007, 26, 35-es. [Google Scholar] [CrossRef]
- Yadav, S.K.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. A review of multimodal human activity recognition with special emphasis on classification, applications, challenges and future directions. Knowl.-Based Syst. 2021, 223, 106970. [Google Scholar] [CrossRef]
- Schall, M.C., Jr.; Sesek, R.F.; Cavuoto, L.A. Barriers to the Adoption of Wearable Sensors in the Workplace: A Survey of Occupational Safety and Health Professionals. Hum. Factors 2018, 60, 351–362. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.Y.; Chou, L.W.; Lee, H.M.; Young, S.T.; Lin, C.H.; Zhou, Y.S.; Tang, S.T.; Lai, Y.H. Human Motion Tracking Using 3D Image Features with a Long Short-Term Memory Mechanism Model—An Example of Forward Reaching. Sensors 2022, 22, 292. [Google Scholar] [CrossRef]
- Lind, C.M.; Abtahi, F.; Forsman, M. Wearable Motion Capture Devices for the Prevention of Work-Related Musculoskeletal Disorders in Ergonomics—An Overview of Current Applications, Challenges, and Future Opportunities. Sensors 2023, 23, 4259. [Google Scholar] [CrossRef]
- Diego-Mas, J.A.; Poveda-Bautista, R.; Garzon-Leal, D. Using RGB-D sensors and evolutionary algorithms for the optimization of workstation layouts. Appl. Ergon. 2017, 65, 530–540. [Google Scholar] [CrossRef] [PubMed]
- Naranjo, J.E.; Mora, C.A.; Bustamante Villagómez, D.F.; Mancheno Falconi, M.G.; Garcia, M.V. Wearable Sensors in Industrial Ergonomics: Enhancing Safety and Productivity in Industry 4.0. Sensors 2025, 25, 1526. [Google Scholar] [CrossRef] [PubMed]
- Fernández, M.M.; Álvaro Fernández, J.; Bajo, J.M.; Delrieux, C.A. Ergonomic risk assessment based on computer vision and machine learning. Comput. Ind. Eng. 2020, 149, 106816. [Google Scholar] [CrossRef]
- Abobakr, A.; Nahavandi, D.; Hossny, M.; Iskander, J.; Attia, M.; Nahavandi, S.; Smets, M. RGB-D ergonomic assessment system of adopted working postures. Appl. Ergon. 2019, 80, 75–88. [Google Scholar] [CrossRef]
- Damle, R.; Gurjar, A.; Joshi, A.; Nagre, K. Human Body Skeleton Detection and Tracking. Int. J. Tech. Res. Appl. 2015, 3, 222–225. [Google Scholar]
- Slembrouck, M.; Luong, H.Q.; Gerlo, J.; Schütte, K.; Cauwelaert, D.V.; Clercq, D.D.; Vanwanseele, B.; Veelaert, P.; Philips, W. Multiview 3D Markerless Human Pose Estimation from OpenPose Skeletons. In Advanced Concepts for Intelligent Vision Systems; Springer International Publishing: Cham, Switzerland, 2020; pp. 166–178. [Google Scholar] [CrossRef]
- Tu, H.; Wang, C.; Zeng, W. End-to-End Estimation of Multi-Person 3D Poses from Multiple Cameras. arXiv 2020, arXiv:2004.06239. [Google Scholar] [CrossRef]
- Kim, W.; Sung, J.; Saakes, D.; Huang, C.; Xiong, S. Ergonomic postural assessment using a new open-source human pose estimation technology (OpenPose). Int. J. Ind. Ergon. 2021, 84, 103164. [Google Scholar] [CrossRef]
- Bibi, S.; Anjum, N.; Sher, M. Automated multi-feature human interaction recognition in complex environment. Comput. Ind. 2018, 99, 282–293. [Google Scholar] [CrossRef]
- Seo, J.; Lee, S. Automated postural ergonomic risk assessment using vision-based posture classification. Autom. Constr. 2021, 128, 103725. [Google Scholar] [CrossRef]
- Xiao, B.; Xiao, H.; Wang, J.; Chen, Y. Vision-based method for tracking workers by integrating deep learning instance segmentation in off-site construction. Autom. Constr. 2022, 136, 104148. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Liu, Y.; Xiang, S.; Pan, C. 3D PostureNet: A unified framework for skeleton-based posture recognition. Pattern Recognit. Lett. 2020, 140, 143–149. [Google Scholar] [CrossRef]
- Andrade-Ambriz, Y.A.; Ledesma, S.; Ibarra-Manzano, M.A.; Oros-Flores, M.I.; Almanza-Ojeda, D.L. Human activity recognition using temporal convolutional neural network architecture. Expert Syst. Appl. 2022, 191, 116287. [Google Scholar] [CrossRef]
- Zhu, S.; Fang, Z.; Wang, Y.; Yu, J.; Du, J. Multimodal activity recognition with local block CNN and attention-based spatial weighted CNN. J. Vis. Commun. Image Represent. 2019, 60, 38–43. [Google Scholar] [CrossRef]
- Nayak, G.K.; Kim, E. Development of a fully automated RULA assessment system based on computer vision. Int. J. Ind. Ergon. 2021, 86, 103218. [Google Scholar] [CrossRef]
- Clark, R.A.; Mentiplay, B.F.; Hough, E.; Pua, Y.H. Three-dimensional cameras and skeleton pose tracking for physical function assessment: A review of uses, validity, current developments and Kinect alternatives. Gait Posture 2019, 68, 193–200. [Google Scholar] [CrossRef]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Skeleton-based action recognition with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 597–600. [Google Scholar] [CrossRef]
- Yoshikawa, Y.; Shishido, H.; Suita, M.; Kameda, Y.; Kitahara, I. Shot detection using skeleton position in badminton videos. In Proceedings of the International Workshop on Advanced Imaging Technology (IWAIT) 2021, Online, 5–6 January 2021. [Google Scholar]
- Bonakdar, A.; Riahi, N.; Shakourisalim, M.; Miller, L.; Tavakoli, M.; Rouhani, H.; Golabchi, A. Validation of markerless vision-based motion capture for ergonomics risk assessment. Int. J. Ind. Ergon. 2025, 107, 103734. [Google Scholar] [CrossRef]
- Mahjourian, N.; Nguyen, V. Sanitizing Manufacturing Dataset Labels Using Vision-Language Models. arXiv 2025, arXiv:2506.23465. [Google Scholar]
- Agostinelli, T.; Generosi, A.; Ceccacci, S.; Mengoni, M. Validation of computer vision-based ergonomic risk assessment tools for real manufacturing environments. Sci. Rep. 2024, 14, 27785. [Google Scholar] [CrossRef] [PubMed]
- Muntean, E.; Leba, M. Comparative Analysis of Wearable and Computer Vision-Based Methods for Human Torso Posture Estimation. In Proceedings of the 2024 9th International Conference on Mathematics and Computers in Sciences and Industry (MCSI), Rhodes Island, Greece, 22–24 August 2024; pp. 56–61. [Google Scholar] [CrossRef]
- Menanno, M.; Riccio, C.; Benedetto, V.; Gissi, F.; Savino, M.M.; Troiano, L. An Ergonomic Risk Assessment System Based on 3D Human Pose Estimation and Collaborative Robot. Appl. Sci. 2024, 14, 4823. [Google Scholar] [CrossRef]
- Hung, J.S.; Liu, P.L.; Chang, C.C. A deep learning-based approach for human posture classification. In Proceedings of the 2020 2nd International Conference on Management Science and Industrial Engineering, Osaka, Japan, 7–9 April 2020; pp. 171–175. [Google Scholar]
- Hasib, R.; Khan, K.N.; Yu, M.; Khan, M.S. Vision-based human posture classification and fall detection using convolutional neural network. In Proceedings of the 2021 International Conference on Artificial Intelligence (ICAI), Lucknow, India, 22–23 May 2021; pp. 74–79. [Google Scholar]
- Aghamohammadi, A.; Beheshti Shirazi, S.A.; Banihashem, S.Y.; Shishechi, S.; Ranjbarzadeh, R.; Jafarzadeh Ghoushchi, S.; Bendechache, M. A deep learning model for ergonomics risk assessment and sports and health monitoring in self-occluded images. Signal Image Video Process. 2024, 18, 1161–1173. [Google Scholar] [CrossRef]
- Çalışkan, A. Detecting human activity types from 3D posture data using deep learning models. Biomed. Signal Process. Control 2023, 81, 104479. [Google Scholar] [CrossRef]
- Hossain, M.S.; Azam, S.; Karim, A.; Montaha, S.; Quadir, R.; De Boer, F.; Altaf-Ul-Amin, M. Ergonomic Risk Prediction for Awkward Postures From 3D Keypoints Using Deep Learning. IEEE Access 2023, 11, 114497–114508. [Google Scholar] [CrossRef]
- Kwon, Y.J.; Kim, D.H.; Son, B.C.; Choi, K.H.; Kwak, S.; Kim, T. A work-related musculoskeletal disorders (WMSDs) risk-assessment system using a single-view pose estimation model. Int. J. Environ. Res. Public Health 2022, 19, 9803. [Google Scholar] [CrossRef]
- Jung, S.; Kim, B.; Kim, Y.J.; Lee, E.S.; Kang, D.; Kim, Y. Prediction of work-relatedness of shoulder musculoskeletal disorders as by using machine learning. Saf. Health Work 2025, 16, 113–121. [Google Scholar] [CrossRef]
- Ciccarelli, M.; Corradini, F.; Germani, M.; Menchi, G.; Mostarda, L.; Papetti, A.; Piangerelli, M. SPECTRE: A deep learning network for posture recognition in manufacturing. J. Intell. Manuf. 2022, 34, 3469–3481. [Google Scholar] [CrossRef]
- McAtamney, L.; Nigel Corlett, E. RULA: A survey method for the investigation of work-related upper limb disorders. Appl. Ergon. 1993, 24, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Alrfou, K.; Kordijazi, A.; Zhao, T. Computer Vision Methods for the Microstructural Analysis of Materials: The State-of-the-art and Future Perspectives. arXiv 2022, arXiv:2208.04149. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Tested Values |
|---|---|
| batch_size | 8, 16, 32, 64 |
| optimizer | Adam, AdamW, Adamax |
| learning rate (LR) | , , |
| dropout | 0.1, 0.3, 0.5 |
| Patch size | 8, 16, 32, 64 |
| Embedding dim. | 192, 256, 512, 1024 |
| Depth | 1, 2, 4, 6 |
| qkv_bias | True or False |
| Labels | Coded Labels |
|---|---|
| Neck | NECK |
| Trunk | TRUNK |
| Right Upper Arm | RUA |
| Right Lower Arm | RLA |
| Right Wrist | RW |
| Left Upper Arm | LUA |
| Left Lower Arm | LLA |
| Left Wrist | LW |
| Labels | AUC | Accuracy | F1 | Precision | Recall |
|---|---|---|---|---|---|
| NECK | 0.9998 | 0.9961 | 0.9971 | 0.9971 | 0.9971 |
| TRUNK | 0.9999 | 0.9965 | 0.9974 | 0.9970 | 0.9977 |
| RUA | 0.9996 | 0.9928 | 0.9947 | 0.9962 | 0.9933 |
| RLA | 0.9986 | 0.9894 | 0.9930 | 0.9951 | 0.9909 |
| RW | 0.9962 | 0.9878 | 0.9927 | 0.9891 | 0.9963 |
| LUA | 0.9995 | 0.9944 | 0.9942 | 0.9947 | 0.9938 |
| LLA | 0.9999 | 0.9944 | 0.9964 | 0.9945 | 0.9983 |
| LW | 0.9995 | 0.9909 | 0.9932 | 0.9961 | 0.9904 |
| Labels | SPECTRE-ViT | SPECTRE [52] |
|---|---|---|
| NECK | 1.0000 | 0.9870 |
| TRUNK | 1.0000 | 0.9950 |
| RUA | 0.9997 | 0.9600 |
| RLA | 0.9990 | 0.9230 |
| RW | 0.9997 | 0.8700 |
| LUA | 0.9998 | 0.9980 |
| LLA | 0.9998 | 0.9750 |
| LW | 0.9986 | 0.9700 |
| SPECTRE [52] | SPECTRE-ViT | |
|---|---|---|
| Architecture | Parallel CNNs (one per body part) | Unified Vision Transformer (ViT) with multi-label output |
| Input Type | Segmented RGB + skeleton overlay | Raw RGB frames (full frame) |
| Preprocessing | Mediapipe segmentation + joint alignment | None (no cropping or skeleton extraction) |
| Number of Models | 8 CNNs (independent classifiers) | Single ViT model (shared encoder) |
| Explainability | LIME applied to each CNN | Not applied (future work) |
| Lowest F1-score (Right Wrist) | 0.9260 | 0.9927 |
| Highest F1-score (Trunk) | 0.9409 | 0.9974 |
| Highest F1-score (Neck) | 0.9362 | 0.9971 |
| Inference Mode | Offline only | Near real-time |
| Hardware Requirements | High (A100 GPU) | Edge-capable (GTX-class or mobile) |
| Study | Input Type | Pipeline | Evaluation Metrics | Limitations |
|---|---|---|---|---|
| Nayak & Kim (2021) [36] | 2D Joint Data (from images) | CNN-based joint localization → RULA scoring | ICC = 0.776–0.867 (reliability vs. experts) | No F1 reported; requires side-view image pair; dependent on person detection |
| Zhu et al. (2019) [35] | RGB video | Spatiotemporal CNN with spatial fusion | 95–97% (action recognition) | Not task-agnostic; no ergonomic score estimation |
| Andrade-Ambriz et al. (2022) [34] | RGB video | Temporal CNN trained on short clips | Accuracy = 96.4% (human activity) | Not validated for ergonomic classification or real-time deployment |
| Aghamohammadi et al. (2024) [47] | RGB video (4-frame sequence) | Multi-route CNN with temporal fusion | F1 = 0.88 | Temporal input required; occlusion robustness limited to short intervals |
| SPECTRE-ViT (2025) | Raw RGB (single frame) | Vision Transformer (ViT), direct multi-region classification | F1 > 0.99 (all regions) | Latency not evaluated; field tests ongoing |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cruciata, L.; Contino, S.; Ciccarelli, M.; Pirrone, R.; Mostarda, L.; Papetti, A.; Piangerelli, M. Lightweight Vision Transformer for Frame-Level Ergonomic Posture Classification in Industrial Workflows. Sensors 2025, 25, 4750. https://doi.org/10.3390/s25154750
Cruciata L, Contino S, Ciccarelli M, Pirrone R, Mostarda L, Papetti A, Piangerelli M. Lightweight Vision Transformer for Frame-Level Ergonomic Posture Classification in Industrial Workflows. Sensors. 2025; 25(15):4750. https://doi.org/10.3390/s25154750
Chicago/Turabian StyleCruciata, Luca, Salvatore Contino, Marianna Ciccarelli, Roberto Pirrone, Leonardo Mostarda, Alessandra Papetti, and Marco Piangerelli. 2025. "Lightweight Vision Transformer for Frame-Level Ergonomic Posture Classification in Industrial Workflows" Sensors 25, no. 15: 4750. https://doi.org/10.3390/s25154750
APA StyleCruciata, L., Contino, S., Ciccarelli, M., Pirrone, R., Mostarda, L., Papetti, A., & Piangerelli, M. (2025). Lightweight Vision Transformer for Frame-Level Ergonomic Posture Classification in Industrial Workflows. Sensors, 25(15), 4750. https://doi.org/10.3390/s25154750