
Distributed Collaborative Data Processing Framework for Unmanned Platforms Based on Federated Edge Intelligence


Abstract
1. Introduction
- (1)
- Data heterogeneity [22]: During the process of data collection and processing by large-scale unmanned platforms, due to varying task requirements and environmental conditions, different platforms may gather data with significantly different categories. Additionally, the numbers of samples collected by each platform may be unevenly distributed [23]. These factors result in the data collected by unmanned platforms exhibiting non-independent and identically distributed (Non-IID) characteristics.
- (2)
- Device heterogeneity: Unmanned platforms vary significantly in terms of computational resources, storage resources, and other aspects. This heterogeneity necessitates that algorithms and models in collaborative operations must adapt to the hardware limitations of different devices to achieve optimal resource allocation and utilization.
- (3)
- Model heterogeneity [24]: Different unmanned platforms may face diverse task requirements, necessitating the use of varying model architectures or parameter configurations.
- (4)
- Privacy protection [25]: Traditional data processing methods typically involve transmitting collected data to a centralized data processing center (such as a cloud server) for storage and analysis. During data transmission, due to the openness of the network, data is susceptible to interception by third parties. In this process, data privacy faces significant risks.
- (1)
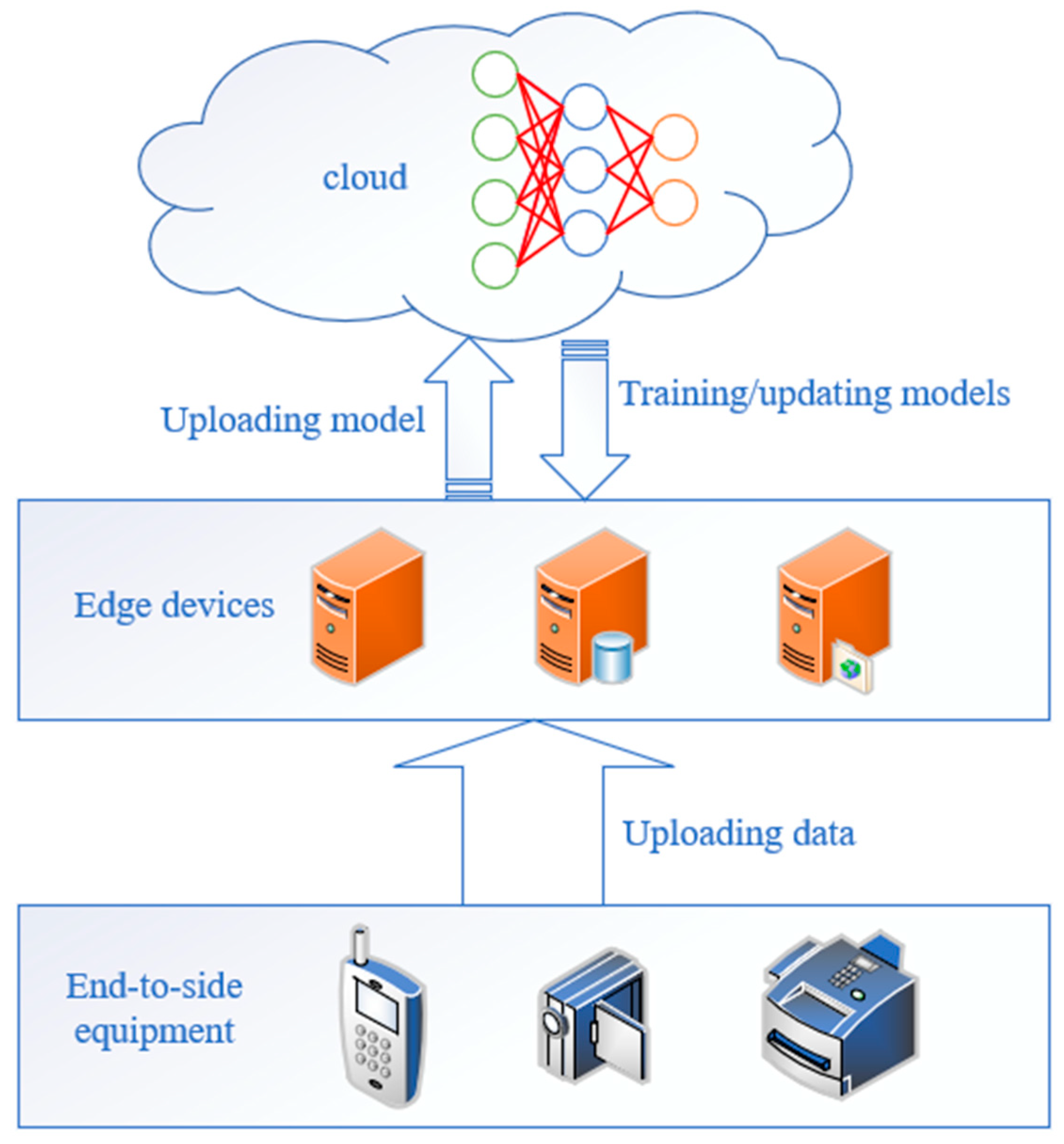
- This paper proposes a federated edge computing architecture for unmanned platform clusters, integrating technologies such as federated learning and edge computing into the cloud-edge-end paradigm. Compared with traditional federated learning methods, this architecture better adapts to the dynamic and distributed application scenarios of unmanned platforms through three-level collaboration: global scheduling at the cloud layer, distributed processing at the edge layer, and data collection at the terminal layer.
- (2)
- In the federated edge intelligence framework, to address the issues of data class imbalance and large distribution differences among edge platforms, a privacy-enhanced data sharing mechanism is introduced. While mitigating the problem of data distribution heterogeneity across platforms, this mechanism strengthens data privacy protection by adding random perturbations to data using Gaussian noise.
- (3)
- This paper proposes an intelligent model screening strategy that combines similarity measurement and loss gradient. The strategy first uses a hierarchical parameter alignment method to map the parameters of heterogeneous models to a unified space; then, according to the similarity coefficient and loss gradient, the local model that is most beneficial to the global model aggregation is selected, which significantly reduces the interference of device and model heterogeneity on the global model aggregation in the federated learning process.
2. Cloud-Edge-End Architecture for Unmanned Platform Swarms
- (1)
- At the data level, it ensures the privacy and security of raw data while facilitating cross-platform knowledge sharing.
- (2)
- At the computational level, localized processing at edge nodes significantly reduces data transmission overhead.
- (3)
- At the model level, a hierarchical collaborative training mechanism is employed, ensuring both the timeliness and accuracy of model updates.
3. Method of Federated Edge Intelligence
3.1. Data Sharing Strategy
- (1)
- Data Sampling: In the terminal platforms, data is sampled according to a predefined sharing ratio. Research indicates that model accuracy plateaus when the data-sharing ratio is between 20% and 30% [11]. Beyond this range, further increasing the sharing ratio does not lead to unlimited accuracy gains. Thus, in the subsequent experiments, the sharing ratio was set at 20%. Additionally, data normalization and noise reduction were performed to eliminate redundant components from the original data.
- (2)
- Data Transmission: The sampled data is transmitted to the data-sharing platform. This process necessitates ensuring the accuracy and efficiency of data transfer.
- (3)
- Data Integration: The data-sharing platform integrates the received data to form a public dataset. This process involves data cleaning and preprocessing to ensure data quality.
- (4)
- Data Distribution: The common data in the data sharing platform is randomly sampled and distributed to each edge platform. The edge platforms utilize both the public dataset and their local datasets for model training.
3.2. Intelligent Model Aggregation Mechanism
- Numerical Characteristics: The absolute values of the matrix elements reflect the strength of neuronal connections, indicating the model’s focus on different features.
- Directional Characteristics: Treating the weight matrix as a vector in high-dimensional space, its directional information implicitly captures the learning trends and convergence direction of the model, analogous to semantic direction indicators in vector space models.
3.2.1. Alignment of Hierarchical Parameters
3.2.2. Coefficient of Similarity and Loss Gradient
3.2.3. Model Aggregation Strategy
3.3. Federated Learning Process
| Algorithm 1 Federated Learning Algorithm | |
| Input | Maximum number of iterations |
| Output | Global model parameters |
| 1 | Initiate |
| 2 | for to |
| 3 | for to |
| 4 | |
| 5 | end |
| 6 | end |
| 7 | for to |
| 8 | for to |
| 9 | for |
| 10 | |
| 11 | Parametric mapping |
| 12 | end |
| 13 | Calculate the coefficient of similarity and gradient of loss |
| 14 | if then |
| 15 | Agg [ ].append() |
| 16 | end |
| 17 | end |
| 18 | if then |
| 19 | Aggregation of all local models |
| 20 | end |
| 21 | end |
| 22 | for |
| 23 | |
| 24 | end |
4. Experimental Results and Analysis
4.1. Dataset
4.2. Experimental Setup
4.2.1. Assessment Indicators
- (1)
- : Accuracy reflects the model’s overall classification performance on all edge unmanned platforms’ data. However, when the dataset has Non-IID characteristics, accuracy may not indicate the model’s performance on minority classes, especially in cases of class imbalance.
- (2)
- : In Non-IID datasets, the number of samples for certain classes may be limited. The F1 score is better suited to reflect the model’s performance on minority classes. For a dataset with M classes, after calculating the F1 score for any individual class C (F1_score_C), the macro-averaged F1 score (macro_F1) is computed to evaluate the model’s classification capability across samples of different classes.
- (3)
- : In Non-IID datasets, due to the differing data distributions across various edge platforms, gradient divergence is typically more pronounced. The magnitude of gradient divergence can effectively reflect the efficacy of the data-sharing strategy.
- (4)
- Rounds: Communication rounds are a key metric in federated learning that reflect how often participants exchange information during model training. They indicate how frequently client devices communicate with the central server for parameter updates and synchronization. Lower communication rounds mean less communication resource consumption. In this study, the number of communication rounds needed for the federated learning model to converge is used as an evaluation metric. A lower value of this metric indicates that the model consumes fewer communication resources.
4.2.2. Baseline Methods
4.2.3. Training Settings
4.3. Ablation Experiment
4.4. Comparative Experiment
5. Conclusions
6. Future Perspectives
- (1)
- Privacy Protection Strategies: The data sharing strategy employed in this paper can effectively alleviate data heterogeneity. However, there are still data leakage and privacy risks during data sharing between edge and end-device unmanned platforms. In the future, we need to further explore privacy/utility trade-off mechanisms for data sharing in open environments. For example, we can organically integrate secure enhancing technologies such as differential privacy and homomorphic encryption with the federated learning framework. In addition, constructing verifiable privacy protection paradigms will be crucial.
- (2)
- Cross-Modal Data Fusion: The federated edge intelligence framework in this paper solves the non-IID property of heterogeneous data, but has not fully considered the semantic correlation of cross-modal data. As unmanned swarms may collect and process multi-modal data in practical scenarios, future work can explore cross-modal federated learning frameworks. By using knowledge distillation and building hierarchical semantic alignment networks, deep feature fusion of multi-modal data like images, sounds, and electric currents can be achieved.
- (3)
- Hybrid Simulation System Construction: The experimental verification of the federated edge intelligence method proposed in this paper is mainly based on simulation and limited real data, lacking adaptive verification in complex dynamic scenarios. With the rapid development of hybrid reality and digital twin technologies, future research can design hybrid simulation systems with multi-physics coupling. Creating high-fidelity unmanned swarm training environments to simulate complex scenarios like battlefields and urban canyons can validate the algorithm’s robustness in diverse conditions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Non-IID | Non-Independent and Identically Distributed |
| DSM | Data Sharing Mechanism |
| IMAS | Intelligent Model Aggregation Strategy |
| FedAvg | Federated Averaging |
| FedProx | Federated Proximal |
| FedCosA | Federated Using Cosine Annealing |
| FEI | Federated Edge Intelligence |
| DSIA-FEI | Federated Edge Intelligence Based on Data Sharing and Intelligent Model Aggregation |
References
- Li, G.S.; Liu, Y.; Zheng, Q.B.; Yang, G.L.; Liu, K.; Wang, Q.; Diao, X.C. Review of multi-sensor data fusion for UAV. J. Softw. 2025, 36, 1881–1905. [Google Scholar]
- Wong, T.W. Research on Multi-Function UAV System for Cooperative Operation. Master’s Thesis, Zhejiang University, Hangzhou, China, 2023. [Google Scholar]
- Yan, R.C.; Li, S.; Wang, C.; Wu, Q.; Sun, G.N.; Zhang, S.K.; Xie, G.M. A Collaborative Confrontation Decision-Making Method for Heterogeneous Drone Swarms Based on Self-Play Reinforcement Learning. Sci. China Inf. Sci. 2024, 54, 1709–1729. [Google Scholar]
- Shi, Z.G.; Xu, K.P.; Gong, X.; Li, S.N.; Wang, F.F.; Yang, A.; Xiong, Z.K. Research on Autonomous Collaborative Capability Verification of Drone Swarms Based on Meta-Battlefield Domain. J. Ordnance Equip. Eng. 2024, 45, 38–43+49. [Google Scholar]
- Xue, S.X.; Ma, Y.J.; Jiang, B.; Li, W.B.; Liu, C.R. A Distributed Task Allocation Algorithm for Heterogeneous Drone Swarms Based on Coalition Formation Game. Sci. China Inf. Sci. 2024, 54, 2657–2673. [Google Scholar]
- Liu, H.; Zhang, Y.F.; Zhang, W.B.; Hu, Q.Z. A Collaborative Cruise Method for Heterogeneous Swarms Based on Quantum Decision-Makin. Command. Control Simul. 2024, 46, 66–76. [Google Scholar]
- Lu, Y.F.; Wu, T.; Liu, C.S.; Yan, K.; Qu, Y.B. Survey on uav-assisted energy-efficient marginal federated learning. Comput. Sci. 2024, 51, 270–279. [Google Scholar]
- Indu, C.; Kizheppatt, V. Decentralized Multi-Hop Data Processing in UAV Networks Using MARL. Veh. Commun. 2024, 50, 100858. [Google Scholar] [CrossRef]
- Wang, Q.; Shao, K.; Cai, Z.B.; Che, Y.P.; Chen, H.C.; Xiao, S.F.; Wang, R.L.; Liu, Y.L.; Li, B.G.; Ma, Y.T. Prediction of Sugar Beet Yield and Quality Parameters Using Stacked-LSTM Model with Pre-Harvest UAV Time Series Data and Meteorological Factors. Artif. Intell. Agric. 2025, 15, 252–265. [Google Scholar] [CrossRef]
- Min, W.; Muthanna, M.S.A.; Ibrahim, M.; Alkanhel, R.; Muthanna, A.; Laouid, A. Privacy-preserving Federated UAV Data Collection Framework for Autonomous Path Optimization in Maritime Operations. Appl. Soft Comput. 2025, 173, 112906. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sun, Y.; Wang, Z.; Liu, C.; Wang, Z.; Li, M. Personalized Federated Multi-Task Learning Algorithm Based on Knowledge Distillation. J. Beijing Univ. Posts Telecommun. 2025, 48, 91–96. [Google Scholar]
- Zhang, M.Q.; Jia, Y.Y.; Zhang, R.H. Heterogeneous Federated Class-Incremental Learning Assisted by Hybrid Knowledge Distillation in Digital Twins. J. Intell. Syst. 2025, 1–11. Available online: https://kns.cnki.net/kcms2/article/abstract?v=9IId9Ku_yBbYkdgHkFjtw6pDFD3fe70ibGC4vL1OpEE09pXDI0FdraN5sE4V_8FzGIcgtKtPMVJIinpRJ3W60pPVVBIrhGstXNzaj-VPLUxy5rqrBY1qbLmgR49r6Dg2blNQmwvKSJGztEs7tXsQ85XjB_0i35iPXe4d0RnEH2saN6SymZhtwQ==&uniplatform=NZKPT&language=CHS (accessed on 29 July 2025).
- Liu, L.; Wu, S.H.; Yu, D.; Ma, Y.; Chen, Y. Federated Learning with Adaptive Encoder Allocation for Heterogeneous Devices. Comput. Eng. Des. 2024, 45, 2569–2576. [Google Scholar]
- Yin, H.J.; Zheng, K.Q.; Ke, J.N.; Dong, Y.Q. Federated Learning Method for Non-IID Data with Local Momentum Acceleration. Comput. Eng. 2025, 1–9. [Google Scholar] [CrossRef]
- Xiong, Z.J. Research on Federated Learning Algorithm Based on Device Clustering and Differential Privacy. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2024. [Google Scholar]
- Rodríguez-Barroso, N.; Jiménez-López, D.; Luzón, M.V.; Herrera, F.; Martínez-Cámara, E. Survey on Federated Learning Threats: Concepts, Taxonomy on Attacks and Defences, Experimental Study and Challenges. Inf. Fusion 2023, 90, 148–173. [Google Scholar] [CrossRef]
- Ballhausen, H.; Hinske, L.C. Federated Secure Computing. Informatics 2023, 10, 83. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Giotopoulos, K.C.; Tsolis, D.; Oikonomou, K.; Sioutas, S. Federated Edge Intelligence and Edge Caching Mechanisms. Information 2023, 14, 414. [Google Scholar] [CrossRef]
- Zhang, Y.T.; Di, B.Y.; Wang, P.F.; Lin, J.L.; Song, L.Y. HetMEC: Heterogeneous Multi-Layer Mobile Edge Computing in the 6 G Era. IEEE Trans. Veh. Technol. 2020, 69, 4388–4400. [Google Scholar] [CrossRef]
- Shi, J.F.; Chen, X.Y.; Li, B.L. Research on task offloading and resource allocation algorithm in Cloud Edge collaborative computing for Internet of Thing. J. Electron. Inf. 2024, 47, 458–469. [Google Scholar]
- Zhang, H.Y.; Zhang, Z.Y.; Cao, C.M. A federated learning method to solve the problem of data heterogeneity. Comput. Appl. Res. 2024, 41, 713–720. [Google Scholar]
- Alladi, T.; Bansal, G.; Chamola, V.; Guizani, M. SecAuthUAV: A Novel Authentication Scheme for UAV-Ground Station and UAV-UAV Communication. IEEE Trans. Veh. Technol. 2020, 69, 15068–15077. [Google Scholar] [CrossRef]
- Yu, H.; Fan, J.; Sun, Y.H. Survey of heterogeneous federated learning in unmanned systems. Comput. Appl. Res. 2024, 42, 641. [Google Scholar]
- Liu, C. Research on Optimization Method of Joint Resource Utilization in Internet of Things Based on Federated Edge Intelligence. Master’s Thesis, The Huazhong University of Science and Technology, Wuhan, China, 2022. [Google Scholar]
- Ma, C.W.; Xu, X.; Chang, W.W. Research progress on cooperative control of unmanned ground platform swarms. Unmanned Syst. Technol. 2022, 5, 1–11. [Google Scholar]
- Liu, J.; Xu, Y.; Xu, H.; Liao, Y.; Wang, Z.; Huang, H. Enhancing Federated Learning with Intelligent Model Migration in Heterogeneous Edge Computing. In Proceedings of the IEEE International Conference on Data Engineering, Kuala Lumpur, Malaysia, 9–12 May 2022. [Google Scholar]
- Herzog, R.; Köhne, F.; Kreis, L.; Schiela, A. Frobenius-Type Norms and Inner Products of Matrices and Linear Maps with Applications to Neural Network Training. arXiv 2023, arXiv:2311.15419. [Google Scholar] [CrossRef]
- Huang, Y.; Liao, G.; Xiang, Y.; Zhang, L.; Li, J.; Nehorai, A. Low-Rank Approximation Via Generalized Reweighted Iterative Nuclear and Frobenius Norms. IEEE Trans. Image Process. 2019, 29, 2244–2257. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, T.; Peng, S.L.; Wang, G.J.; Jia, W. Edge-based federated learning model cleaning and equipment clustering method. Acta Comput. Sin. 2021, 44, 2515–2528. [Google Scholar]
- Congzheng, S.; Filip, G.; Kunal, T. FLAIR: Federated Learning Annotated Image Repository. Adv. Neural Inf. Process. Syst. 2022, 35, 37792–37805. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Binu, J.; Varun, G.; Mainak, A. FedCosA: Optimized Federated Learning Model Using Cosine Annealing. In 2025 Emerging Technologies for Intelligent Systems (ETIS); IEEE: New York, NY, USA, 2025; pp. 1–6. [Google Scholar]
- Li, X.; Jiang, M.; Zhang, X.; Kamp, M.; Dou, Q. FedBN: Federated Learning on Non-IID Features Via Local Batch Normalization. In Proceedings of the International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Yang, N.; Chen, X.; Liu, C.Z.; Yuan, D.; Bao, W.; Cui, L. FedMAE: Federated Self-Supervised Learning with One-Block Masked Auto-Encoder. arXiv 2023, arXiv:2303.11339. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | GPU | Memory | |
|---|---|---|---|
| Jetson Nano Developer Kit | Quad-core Arm Cortex-A57 MPCore | 128-core NVIDIA Maxwell architecture GPU | 4 GB 64-bit LPDDR4 |
| Jetson Orin Nano 4 GB | 6-core Arm Cortex-A78AE v8.2 | 512-core NVIDIA Ampere architecture GPU | 4 GB 64-bit LPDDR5 |
| Jetson Orin Nano 8 GB | 6-core Arm Cortex-A78AE v8.2 | 1024-core NVIDIA Ampere architecture GPU | 8 GB 128-bit LPDDR5 |
| Dataset | Methods | Rounds | |||
|---|---|---|---|---|---|
| FEMNIST | FedAvg | 0.7489 | 0.73 | 2.6874 | 144 |
| w/o DSM | 0.8142 | 0.82 | 1.3658 | 112 | |
| w/o IMAS | 0.7774 | 0.79 | 0.5471 | 71 | |
| FLAIR | FedAvg | 0.7632 | 0.69 | 2.3987 | 150 |
| w/o DSM | 0.8346 | 0.86 | 1.2471 | 74 | |
| w/o IMAS | 0.7936 | 0.81 | 0.2841 | 60 | |
| EuroSAT | FedAvg | 0.7702 | 0.61 | 2.0697 | 102 |
| w/o DSM | 0.8207 | 0.85 | 1.3698 | 96 | |
| w/o IMAS | 0.8390 | 0.83 | 1.0214 | 82 | |
| RSSCN7 | FedAvg | 0.7495 | 0.70 | 2.6471 | 220 |
| w/o DSM | 0.8109 | 0.88 | 1.2684 | 183 | |
| w/o IMAS | 0.7943 | 0.84 | 0.3207 | 150 |
| Dataset | Methods | Rounds | |||
|---|---|---|---|---|---|
| FEMNIST | FedAvg | 0.7489 | 0.73 | 2.6874 | 144 |
| FedProx | 0.8017 | 0.79 | 2.3014 | 120 | |
| FedCosA | 0.8124 | 0.79 | 0.6541 | 95 | |
| FedBN | 0.8236 | 0.78 | 2.0674 | 114 | |
| FedMAE | 0.8147 | 0.80 | 1.9874 | 126 | |
| DSIA-FEI | 0.9087 | 0.90 | 0.1789 | 48 | |
| FLAIR | FedAvg | 0.7632 | 0.69 | 2.3987 | 150 |
| FedProx | 0.8336 | 0.82 | 1.3654 | 130 | |
| FedCosA | 0.8324 | 0.79 | 2.0347 | 89 | |
| FedBN | 0.8321 | 0.80 | 2.9874 | 90 | |
| FedMAE | 0.7961 | 0.81 | 2.4789 | 103 | |
| DSIA-FEI | 0.9130 | 0.88 | 0.3654 | 51 | |
| EuroSAT | FedAvg | 0.7702 | 0.61 | 2.0697 | 152 |
| FedProx | 0.7804 | 0.78 | 2.0314 | 141 | |
| FedCosA | 0.8265 | 0.82 | 1.3654 | 115 | |
| FedBN | 0.7813 | 0.80 | 2.3654 | 132 | |
| FedMAE | 0.8126 | 0.81 | 2.2745 | 145 | |
| DSIA-FEI | 0.8792 | 0.86 | 0.4127 | 80 | |
| RSSCN7 | FedAvg | 0.7495 | 0.70 | 2.6471 | 220 |
| FedProx | 0.7980 | 0.88 | 1.6874 | 183 | |
| FedCosA | 0.8147 | 0.85 | 1.8415 | 151 | |
| FedBN | 0.7869 | 0.80 | 3.2471 | 177 | |
| FedMAE | 0.8062 | 0.86 | 2.6815 | 187 | |
| DSIA-FEI | 0.8656 | 0.90 | 0.2314 | 122 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Shan, N.; Bao, X.; Xu, X. Distributed Collaborative Data Processing Framework for Unmanned Platforms Based on Federated Edge Intelligence. Sensors 2025, 25, 4752. https://doi.org/10.3390/s25154752
Liu S, Shan N, Bao X, Xu X. Distributed Collaborative Data Processing Framework for Unmanned Platforms Based on Federated Edge Intelligence. Sensors. 2025; 25(15):4752. https://doi.org/10.3390/s25154752
Chicago/Turabian StyleLiu, Siyang, Nanliang Shan, Xianqiang Bao, and Xinghua Xu. 2025. "Distributed Collaborative Data Processing Framework for Unmanned Platforms Based on Federated Edge Intelligence" Sensors 25, no. 15: 4752. https://doi.org/10.3390/s25154752
APA StyleLiu, S., Shan, N., Bao, X., & Xu, X. (2025). Distributed Collaborative Data Processing Framework for Unmanned Platforms Based on Federated Edge Intelligence. Sensors, 25(15), 4752. https://doi.org/10.3390/s25154752