Complex-Scene SAR Aircraft Recognition Combining Attention Mechanism and Inner Convolution Operator




Abstract
1. Introduction
2. Materials and Methods
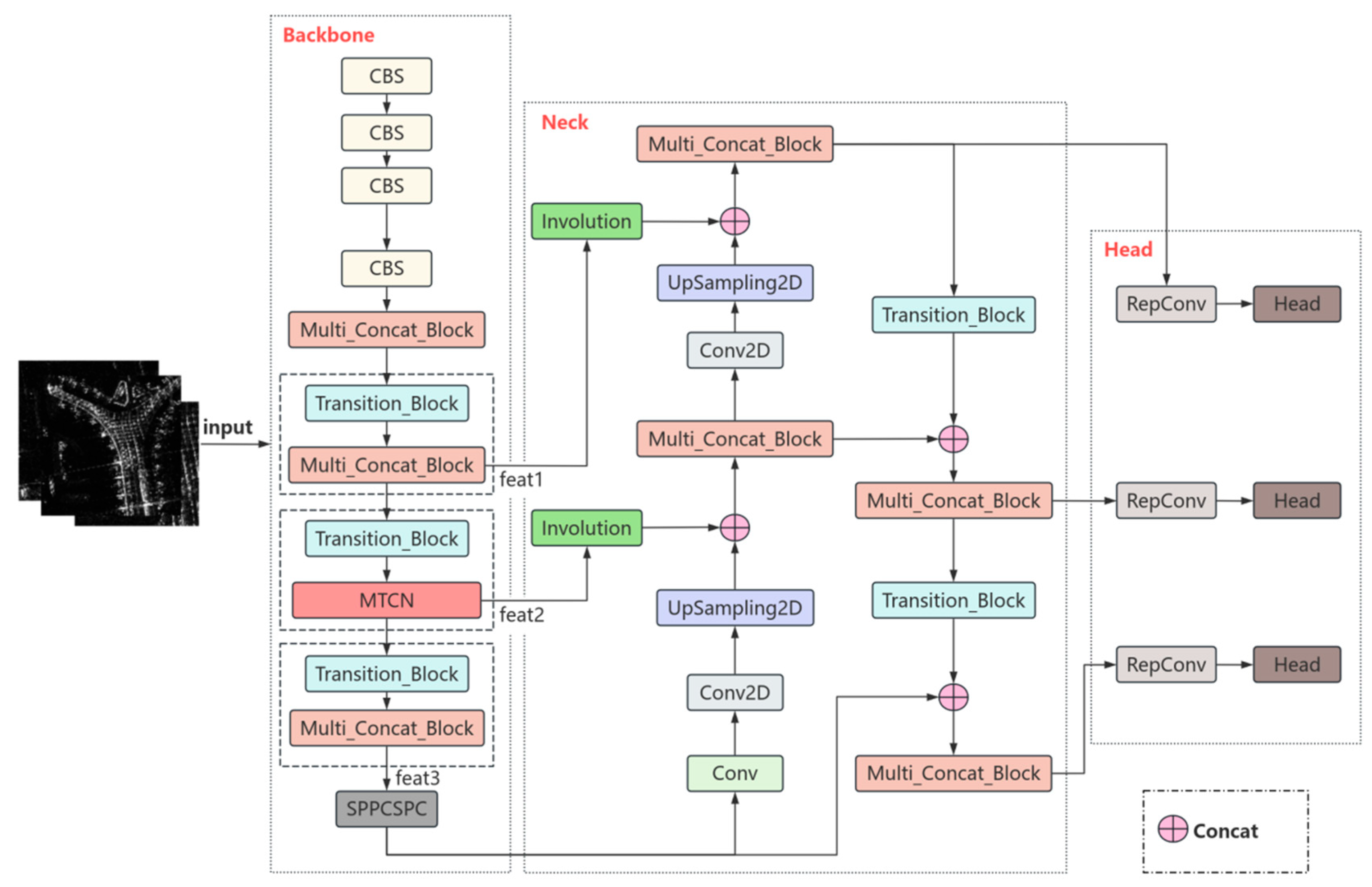
2.1. Overall Detection Framework
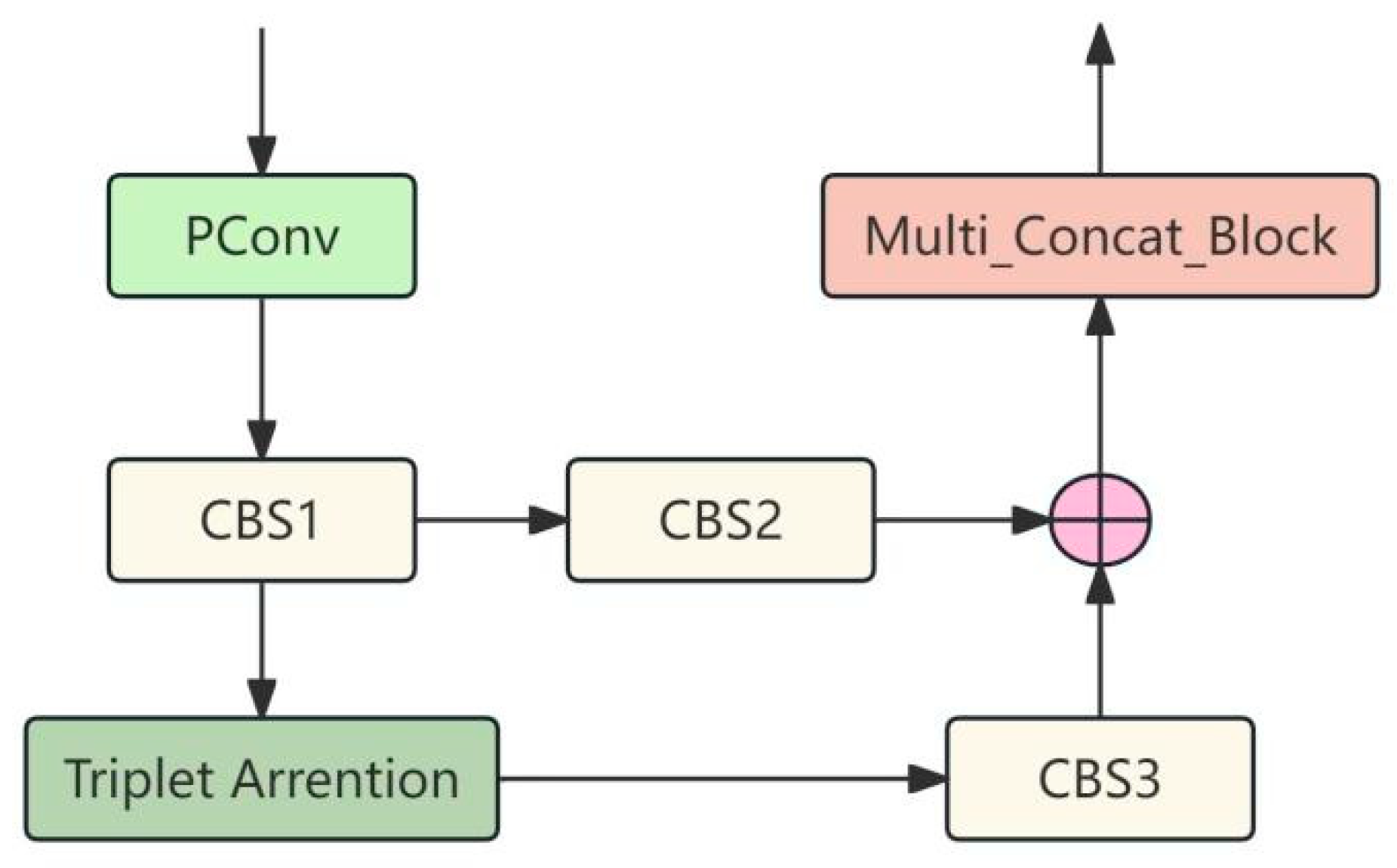
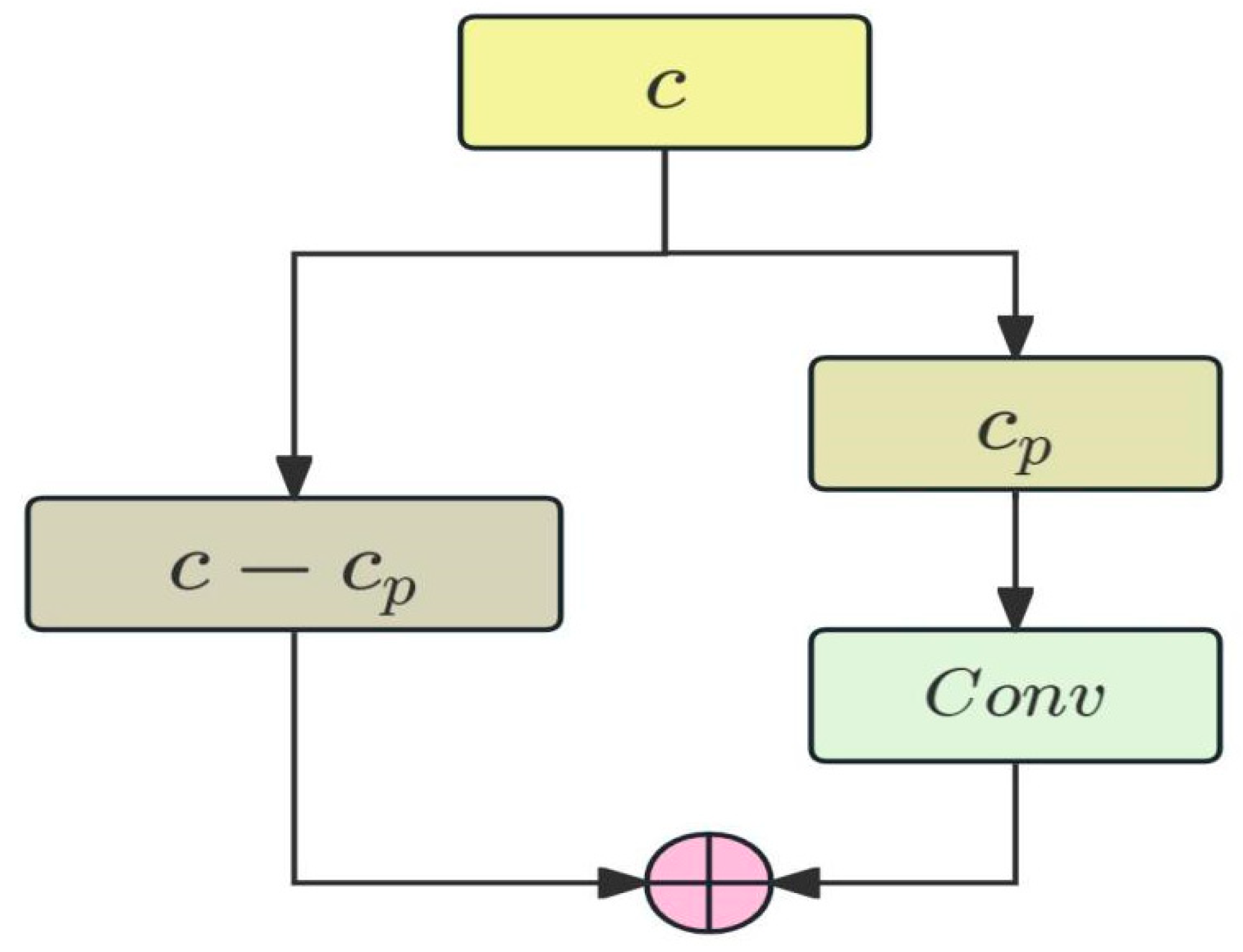
2.2. MTCN Module
2.3. Involution
3. Experimental Results and Analysis
3.1. Aircraft Recognition Dataset
3.2. Evaluation Metrics
3.3. Implementation Details
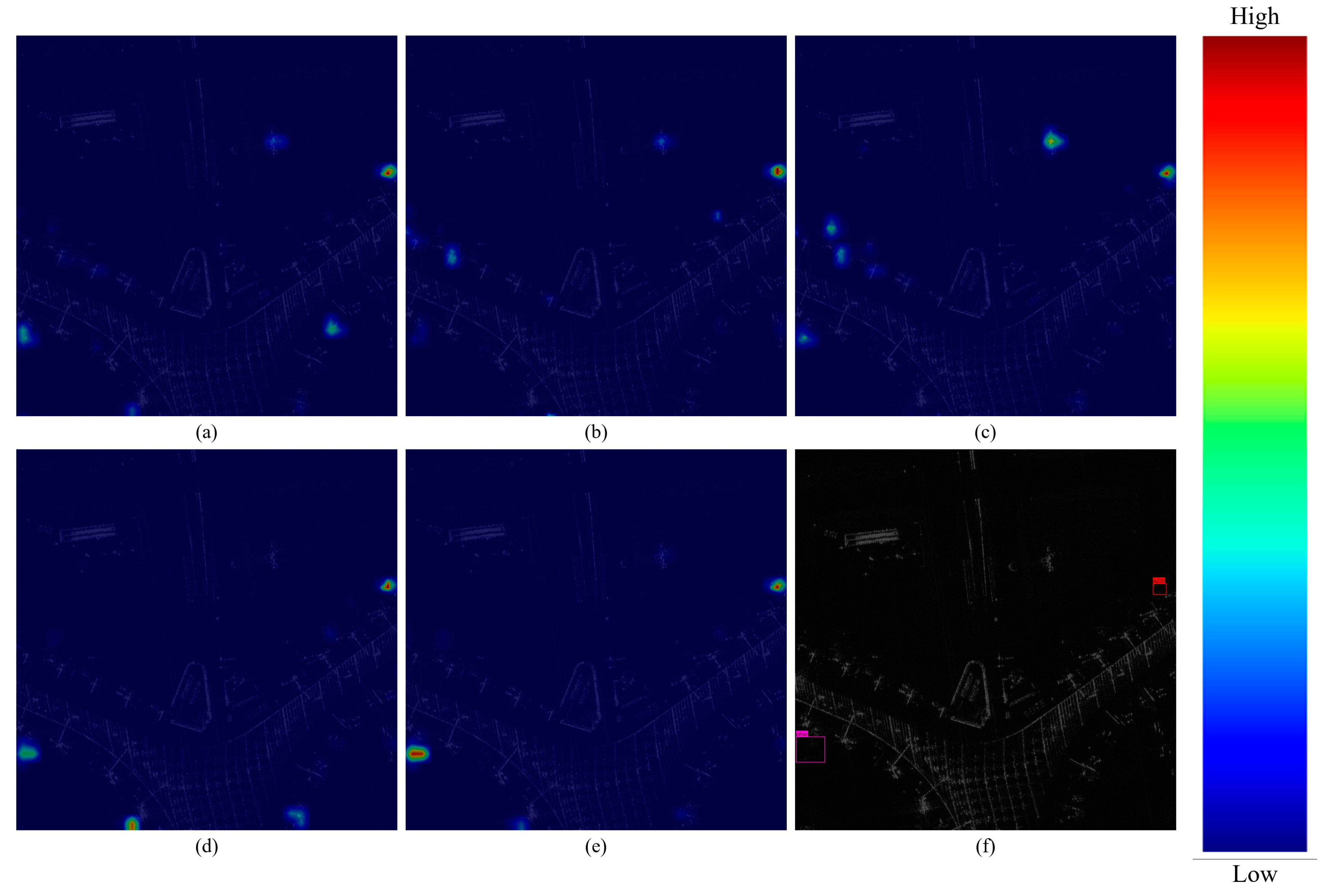
3.4. Ablation Experiment
3.5. Network Comparison Experiment
3.6. Comparison Test of MTCN
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Castellett, D.; Farquharson, G.; Stringham, C.; Duersch, M.; Eddy, D. Capella Space First Operational SAR Satellite. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 12–16 July 2021; pp. 1483–1486. [Google Scholar] [CrossRef]
- Sciotti, M.; Pastina, D.; Lombardo, P. Polarimetric detectors of extended targets for ship detection in SAR images. In Proceedings of the IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No.01CH37217), Sydney, Australia, 9–3 July 2001; pp. 3132–3134. [Google Scholar]
- Guo, Q.; Wang, H.; Xu, F. Research progress on aircraft detection and recognition in SAR imagery. J. Radars 2020, 9, 17. [Google Scholar] [CrossRef]
- Du, L.; Dai, H.; Wang, Y.; Xie, W.; Wang, Z. Target Discrimination Based on Weakly Supervised Learning for High-Resolution SAR Images in Complex Scenes. IEEE Trans. Geosci. Remote Sens. 2020, 58, 461–472. [Google Scholar] [CrossRef]
- Wu, W. Fusion of Infrared and CCD Images and FPGA Design Analysis. Autom. Today 2023, 8, 76–78. [Google Scholar] [CrossRef]
- Long, T.; Ding, Z.; Xiao, F.; Wang, Y.; Li, Z. Spaceborne high-resolution stepped-frequency SAR imaging technology. J. Radars 2019, 8, 782–792. [Google Scholar] [CrossRef]
- Yang, G.; Chen, K.; Zhou, M.; Xu, Z.; Wang, Z. Study evolution of detection and recognition on target in SAR image. Prog. Geophys. 2007, 22, 617–621. [Google Scholar] [CrossRef]
- Kuttikkad, S.; Chellappa, R. Non-Gaussian CFAR techniques for target detection in high resolution SAR images. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; pp. 910–914. [Google Scholar]
- Steenson, B.O. Detection Performance of a Mean-Level Threshold. IEEE Trans. Aerosp. Electron. Syst. 1968, AES-4, 529–534. [Google Scholar] [CrossRef]
- Smith, M.E.; Varshney, P.K. VI-CFAR: A novel CFAR algorithm based on data variability. In Proceedings of the 1997 IEEE National Radar Conference, New York, NY, USA, 13–15 May 1997; pp. 263–268. [Google Scholar]
- Hammoudi, Z.; Soltani, F. Distributed CA-CFAR and OS-CFAR detection using fuzzy spaces and fuzzy fusion rules. IEE Proc. Radar Sonar Navig. 2004, 151, 135–142. [Google Scholar] [CrossRef]
- Shao, X.; Huang, X.; Qi, Z.; Cui, S.; Zhang, K. Radar Vital Signs Detection Based on Improved SO-CFAR and ACA-VMD Algorithms. J. Microw. 2022, 38, 88–94. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Q.; Hang, L.; Han, X.; Wang, B.; Liu, Y. Aircraft type recognition method by integrating target segmentation and key points detection. Natl. Remote Sens. Bull. 2024, 28, 1010–1024. [Google Scholar] [CrossRef]
- Zhang, L.; Li, C.; Zhao, L.; Xiong, B.; Quan, S.; Kuang, G. A cascaded three-look network for aircraft detection in SAR images. Remote Sens. Lett. 2020, 11, 57–65. [Google Scholar] [CrossRef]
- Wang, J.; Xiao, H.; Chen, L.; Xing, J.; Cai, X. Integrating Weighted Feature Fusion and the Spatial Attention Module with Convolutional Neural Networks for Automatic Aircraft Detection from SAR Images. Remote Sens. 2021, 13, 910. [Google Scholar] [CrossRef]
- Liu, X.; Wang, H.; Zhao, L. Inshore Warship Detection Method Based on Multi-task Learning. Comput. Mod. 2024, 29–33. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Y.; Wang, P.; Yin, X.; Yang, H. YOLO-ML: Sliding rail defect detection method based on multi-scale feature layer attention mechanism. J. Chongqing Univ. Posts Telecommun. 2024, 36, 992–1003. [Google Scholar] [CrossRef]
- Chen, L.; Luo, R.; Xing, J.; Li, Z.; Yuan, Z.; Cai, X. Geospatial Transformer Is What You Need for Aircraft Detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5225715. [Google Scholar] [CrossRef]
- Han, P.; Liao, D.; Han, B.; Cheng, Z. SEAN: A Simple and Efficient Attention Network for Aircraft Detection in SAR Images. Remote Sens. 2022, 14, 4669. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, H.; Xu, F. Scattering Enhanced Attention Pyramid Network for Aircraft Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7570–7587. [Google Scholar] [CrossRef]
- Yu, N.; Feng, D.; Zhu, Y.; Zhnag, H.; Lu, P. Lightweight attention-based SAR ship detector. Chin. J. Internet Things 2024, 8, 156–166. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Li, C.; Kuang, G. Pyramid Attention Dilated Network for Aircraft Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 662–666. [Google Scholar] [CrossRef]
- Li, M.; Wen, G.; Huang, X.; Li, K.; Lin, S. A Lightweight Detection Model for SAR Aircraft in a Complex Environment. Remote Sens. 2021, 13, 5020. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Kuang, G. Attention Feature Fusion Network for Rapid Aircraft Detection in SAR Images. Acta Electron. Sin. 2021, 49, 1665–1674. [Google Scholar] [CrossRef]
- Luo, R.; Chen, L.; Xing, J.; Yuan, Z.; Wang, J. A Fast Aircraft Detection Method for SAR Images Based on Efficient Bidirectional Path Aggregated Attention Network. Remote Sens. 2021, 13, 2940. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Liu, Z.; Hu, D.; Kuang, G.; Liu, L. Attentional Feature Refinement and Alignment Network for Aircraft Detection in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5220616. [Google Scholar] [CrossRef]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 3138–3147. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Cai, Z.; Ding, X.; Shen, Q.; Cao, X. RefConv: Reparameterized Refocusing Convolution for Powerful ConvNets. IEEE Trans. Neural Netw. Learn. Syst. 2023, 36, 11617–11631. [Google Scholar] [CrossRef]
- Singh, Y.P.; Chaurasia, B.K.; Shukla, M.M. Mango Fruit Variety Classification Using Lightweight VGGNet Model. SN Comput. Sci. 2024, 5, 1083. [Google Scholar] [CrossRef]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 12316–12325. [Google Scholar] [CrossRef]
- Wang, Z.; Kang, Y.; Zeng, X.; Wang, Y.; Zhang, T.; Sun, X. SAR-AIRcraft-1.0: High-resolution SAR aircraft detection and recognition dataset. J. Radars 2023, 12, 906–922. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance Problems in Object Detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Boeing787 | Boeing737 | A220 | A330 | other | ARJ21 | A320or321 |
| Number | 2645 | 2557 | 3730 | 309 | 4264 | 1187 | 1771 |
| A330 | Boeing787 | Boeing737 | ARJ21 | A320/321 | A220 | Other | |
|---|---|---|---|---|---|---|---|
| YOLOv7 | 97.92 | 95.42 | 93.44 | 91.11 | 89.20 | 88.99 | 88.20 |
| TAM | 99.36 | 95.67 | 93.65 | 93.81 | 88.23 | 89.87 | 89.09 |
| PConv(F) | 97.32 | 96.10 | 93.82 | 95.70 | 88.75 | 88.71 | 90.55 |
| PConv(L) | 97.23 | 95.34 | 94.67 | 92.87 | 88.84 | 87.54 | 90.65 |
| MTCN | 98.79 | 95.80 | 93.31 | 92.64 | 89.44 | 89.83 | 91.00 |
| Involution | 99.20 | 94.74 | 93.39 | 96.81 | 89.51 | 88.42 | 91.81 |
| YOLOv7-MTI | 99.43 | 96.37 | 93.10 | 93.86 | 91.26 | 90.40 | 90.12 |
| Faster R-CNN | SSD | YOLOv5 | YOLOv8 | YOLOv7-MTI | |
|---|---|---|---|---|---|
| mPrecision | 49.35 | 75.42 | 88.10 | 93.43 | 93.51 |
| mRecall | 47.97 | 93.00 | 87.14 | 86.76 | 81.42 |
| mF1 | 56.56 | 43.31 | 79.47 | 87.03 | 96.45 |
| FPS | 50.14 | 57.43 | 82.86 | 86.71 | 88.10 |
| mAP | mAP (MTCN) | mPrecision | mPrecision (MTCN) | mRecall | mRecall (MTCN) | |
|---|---|---|---|---|---|---|
| YOLOv5 | 88.10 | 92.60 | 87.14 | 88.02 | 79.47 | 86.56 |
| YOLOv7 | 92.04 | 93.03 | 82.67 | 83.48 | 94.81 | 94.42 |
| YOLOv8 | 93.43 | 94.53 | 86.76 | 88.03 | 87.03 | 86.56 |
| YOLOv7 | TAM | PConv(F) | PConv(L) | MTCN | Involution | YOLOv7-MTI | |
|---|---|---|---|---|---|---|---|
| mAP | 92.04 | 92.81 | 92.99 | 92.45 | 93.03 | 93.41 | 93.51 |
| mPrecision | 82.67 | 83.33 | 82.65 | 82.69 | 83.48 | 82.16 | 81.42 |
| mRecall | 94.81 | 93.52 | 94.83 | 94.91 | 94.42 | 96.08 | 96.45 |
| mF1 | 88.33 | 88.12 | 88.29 | 88.28 | 88.71 | 88.42 | 88.29 |
| FPS | 16.82 | 25.40 | 25.75 | 25.70 | 25.46 | 24.28 | 25.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Wang, H.; Duan, J.; Cao, L.; Feng, T.; Tian, X. Complex-Scene SAR Aircraft Recognition Combining Attention Mechanism and Inner Convolution Operator. Sensors 2025, 25, 4749. https://doi.org/10.3390/s25154749
Liu W, Wang H, Duan J, Cao L, Feng T, Tian X. Complex-Scene SAR Aircraft Recognition Combining Attention Mechanism and Inner Convolution Operator. Sensors. 2025; 25(15):4749. https://doi.org/10.3390/s25154749
Chicago/Turabian StyleLiu, Wansi, Huan Wang, Jiapeng Duan, Lixiang Cao, Teng Feng, and Xiaomin Tian. 2025. "Complex-Scene SAR Aircraft Recognition Combining Attention Mechanism and Inner Convolution Operator" Sensors 25, no. 15: 4749. https://doi.org/10.3390/s25154749
APA StyleLiu, W., Wang, H., Duan, J., Cao, L., Feng, T., & Tian, X. (2025). Complex-Scene SAR Aircraft Recognition Combining Attention Mechanism and Inner Convolution Operator. Sensors, 25(15), 4749. https://doi.org/10.3390/s25154749