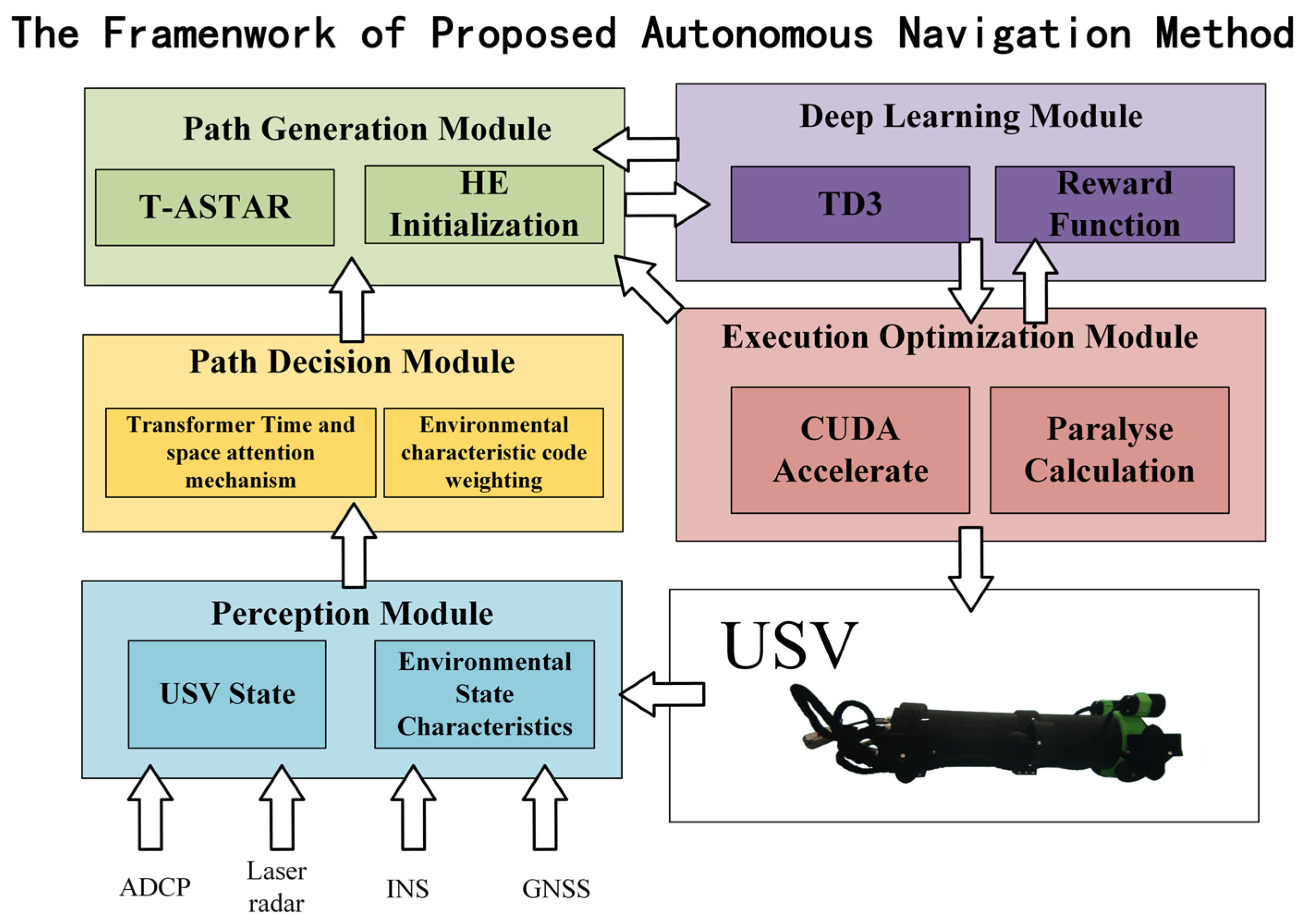
2.3.1. Performance-Enhanced Variants of the T-ASTAR Algorithm
- (1)
Underwater energy consumption equation
The energy consumption model considers both hull resistance from linear motion and the energy cost of steering, based on fluid mechanics principles. The energy evaluation model is in the form of a weighted function:
Motion parameters’ weight coefficient
determined by hull resisting characteristics; Resistance coefficient
relates with calculation of Reynolds number
, and shearing stress integral term
, pressure force energy grade
obtained from CFD (Computational Fluid Dynamics) simulation; steering correction coefficient δ fits to Navier–Stokes transience solution’s dataset in order to establish non-linear relation between curvature parameter
and ship’s characteristic length
;
Nonlinear regressing using many sets steers power and angular speed ω in order to optimize the model’s parameter ; the mapping connection path’s geometrical features—total dimensional length —turning circle times —curvature integrating —to vessel energy consumptions are established for multiple least squares regression, vessel path planning real-time energy aware dynamically.
To validate the accuracy of our CFD-calibrated energy model (Equations (5) and (6)), we quantify its performance using two metrics: the α Fitting Error and the Root Mean Square Error (RMSE). The α Fitting Error is calculated as the Mean Absolute Percentage Error (MAPE) between the predicted energy consumption (
) and the energy consumption from the high-fidelity CFD simulation (
) over a set of N test scenarios:
- (2)
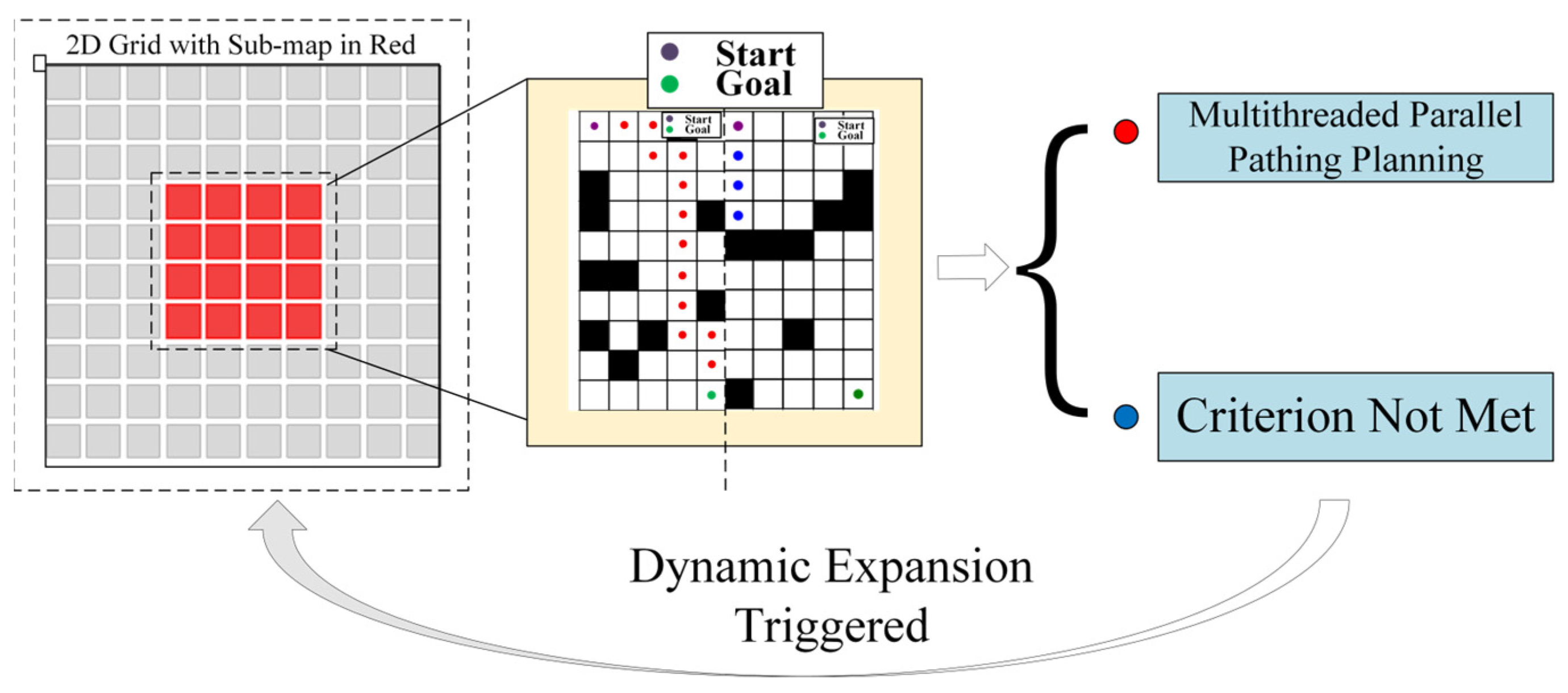
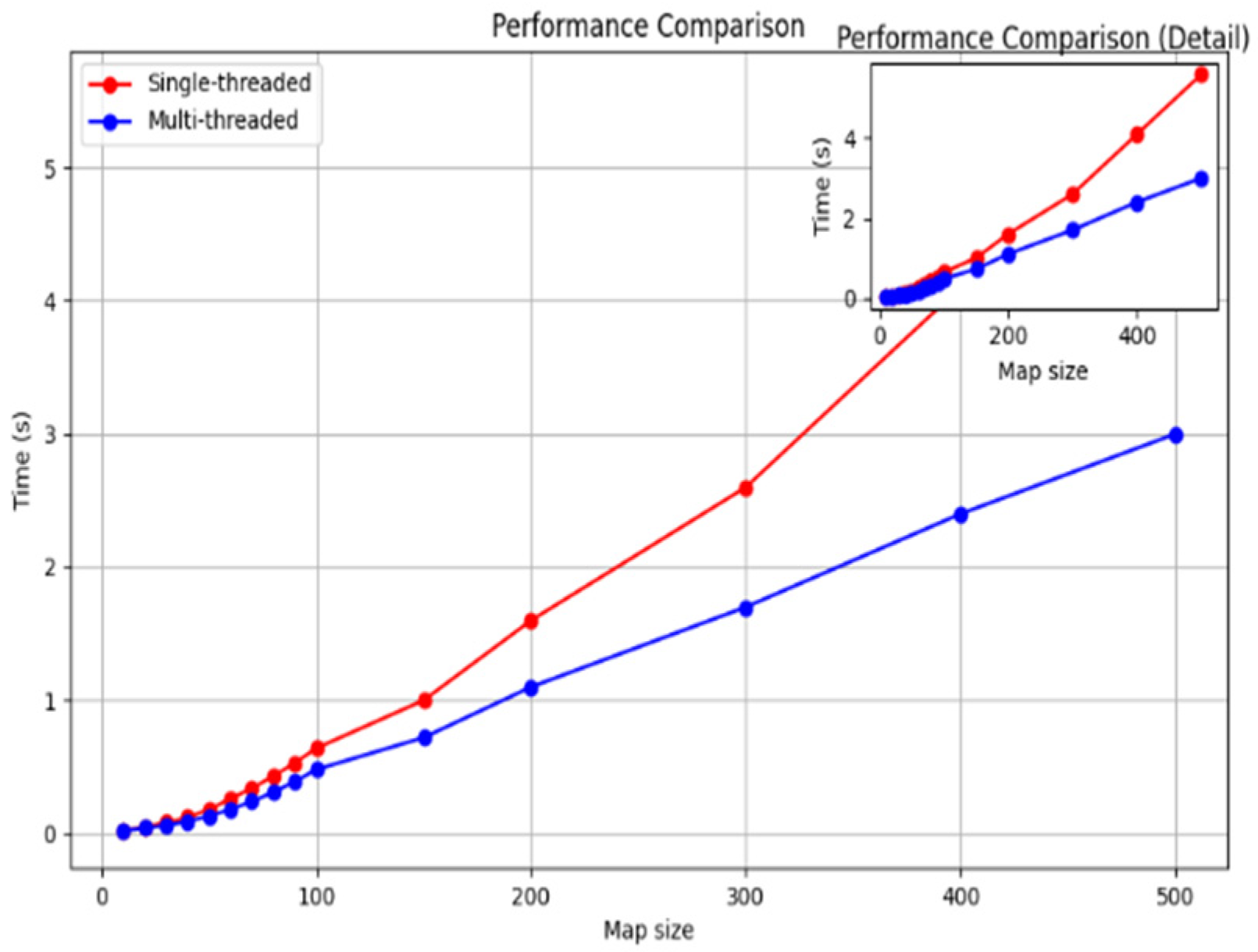
Thread parallel algorithm and optimization
To achieve real-time path planning in large-scale marine environments, this study employs a multi-threaded parallel architecture to significantly enhance computational efficiency. Using the formula
we output exactly the key-point pairs of the whole map and real-time decomposed the high-resolution grid map into multiple continuous sub-graph groups. Using a tensor product operation-based algebraic connectivity judgement criterion
to realize fast sub-graph partitioning, when a path breakage hazard occurs locally, a multi-level radius expansion mechanism (initial radius
) is triggered, and a sliding convolution kernel is used to dynamically expand the radius until the subgraph connection condition is met; at the GPU parallel acceleration layer, CUDA warp level parallelism strategy can be used to accelerate node expansion 32 times. We aimed at the priority conflict problem in the asynchronous queue update process, and a double buffer atomic lock was used to solve it; each thread block contains a local priority queue
and updates the global queue
with CAS atomic operations, so as to achieve the synchronization of multi-scale subgraph path search.
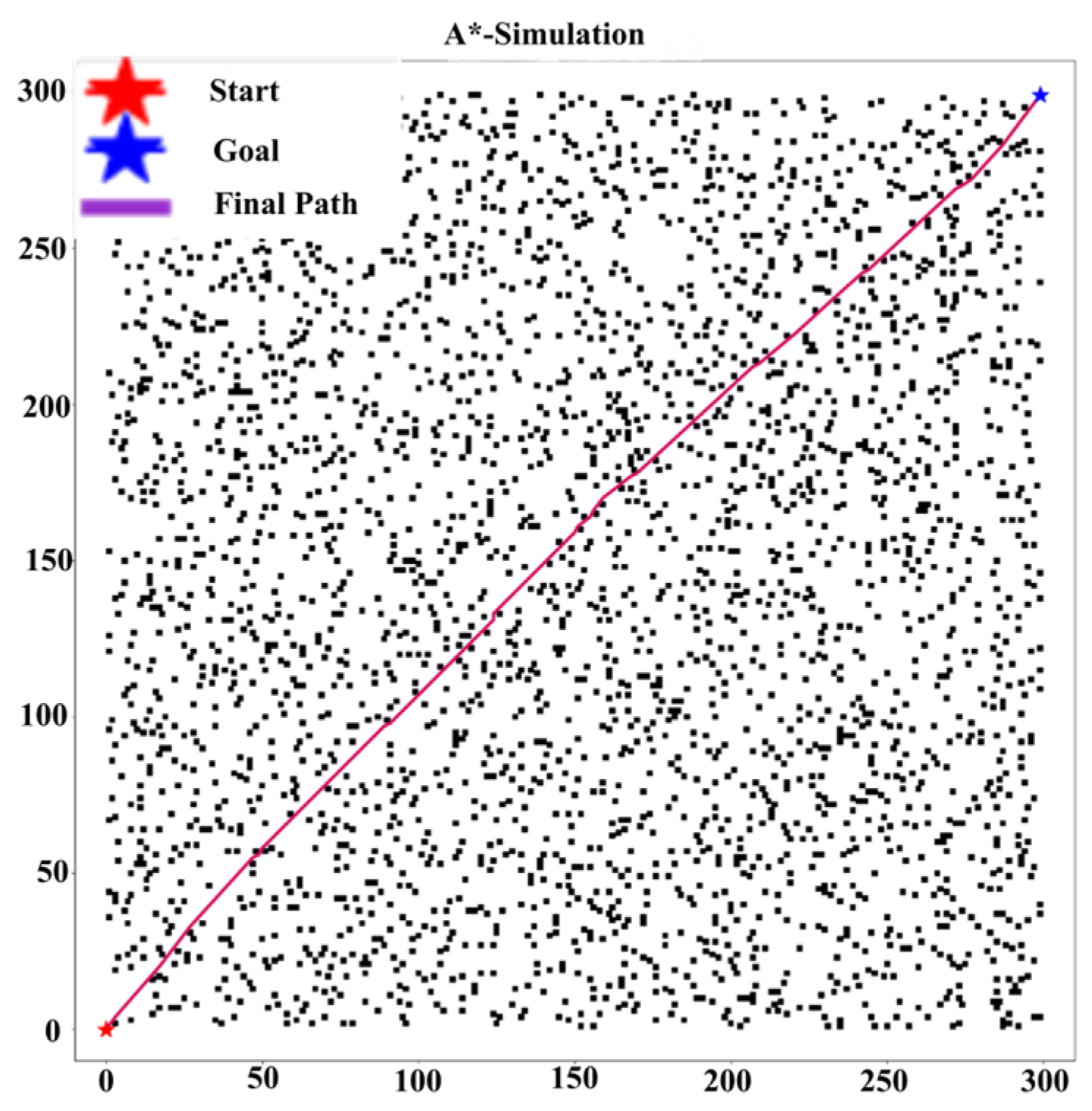
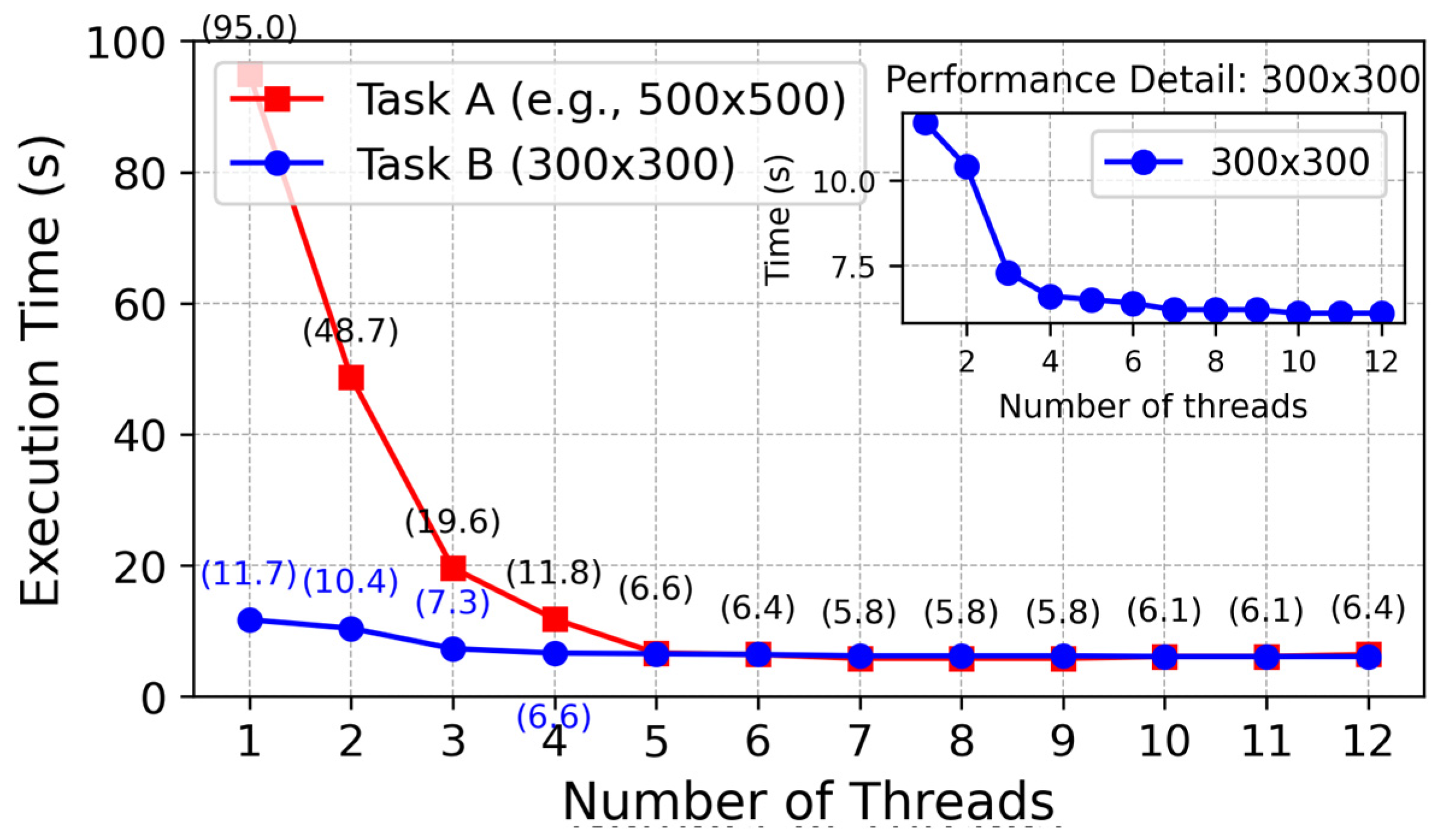
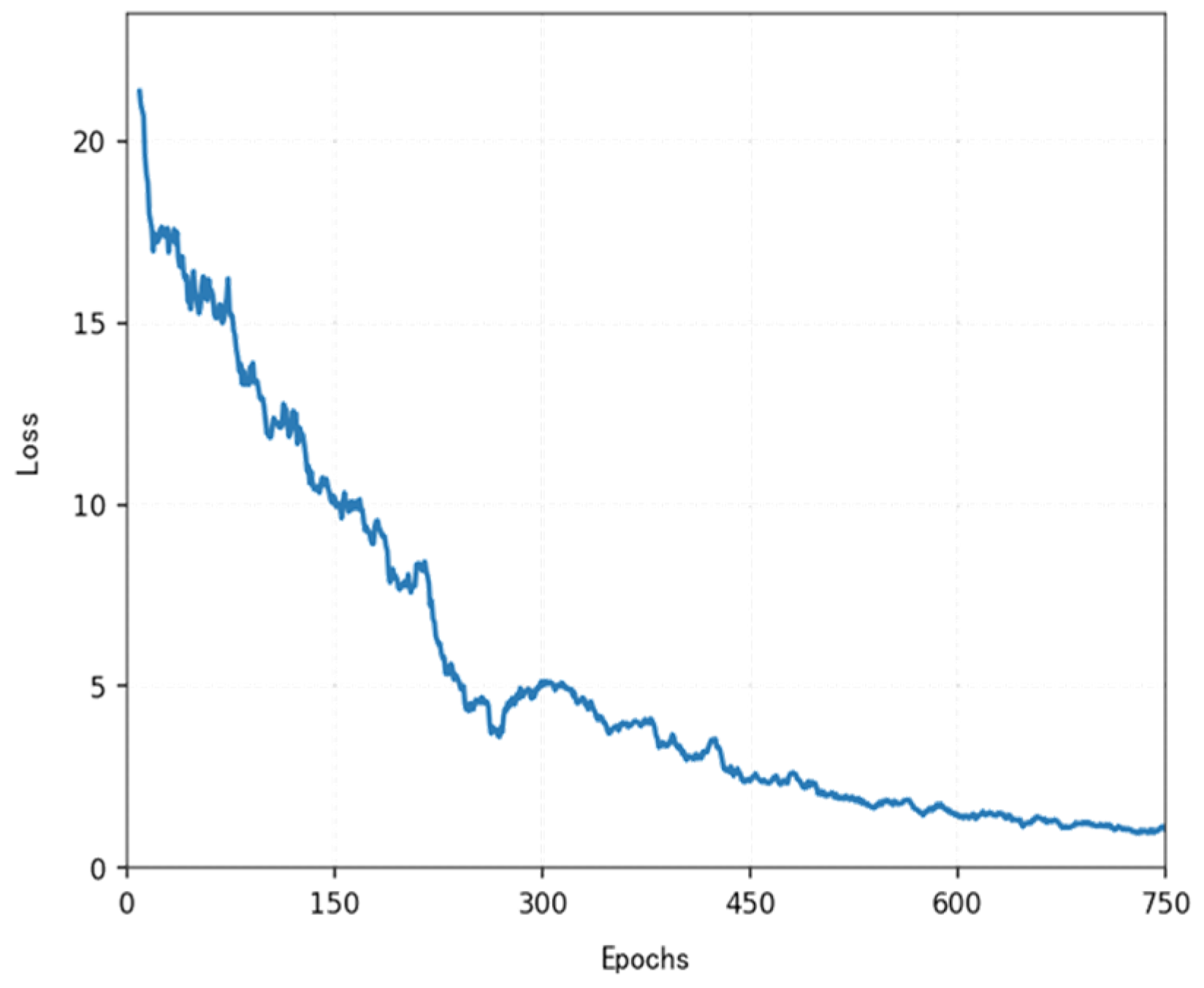
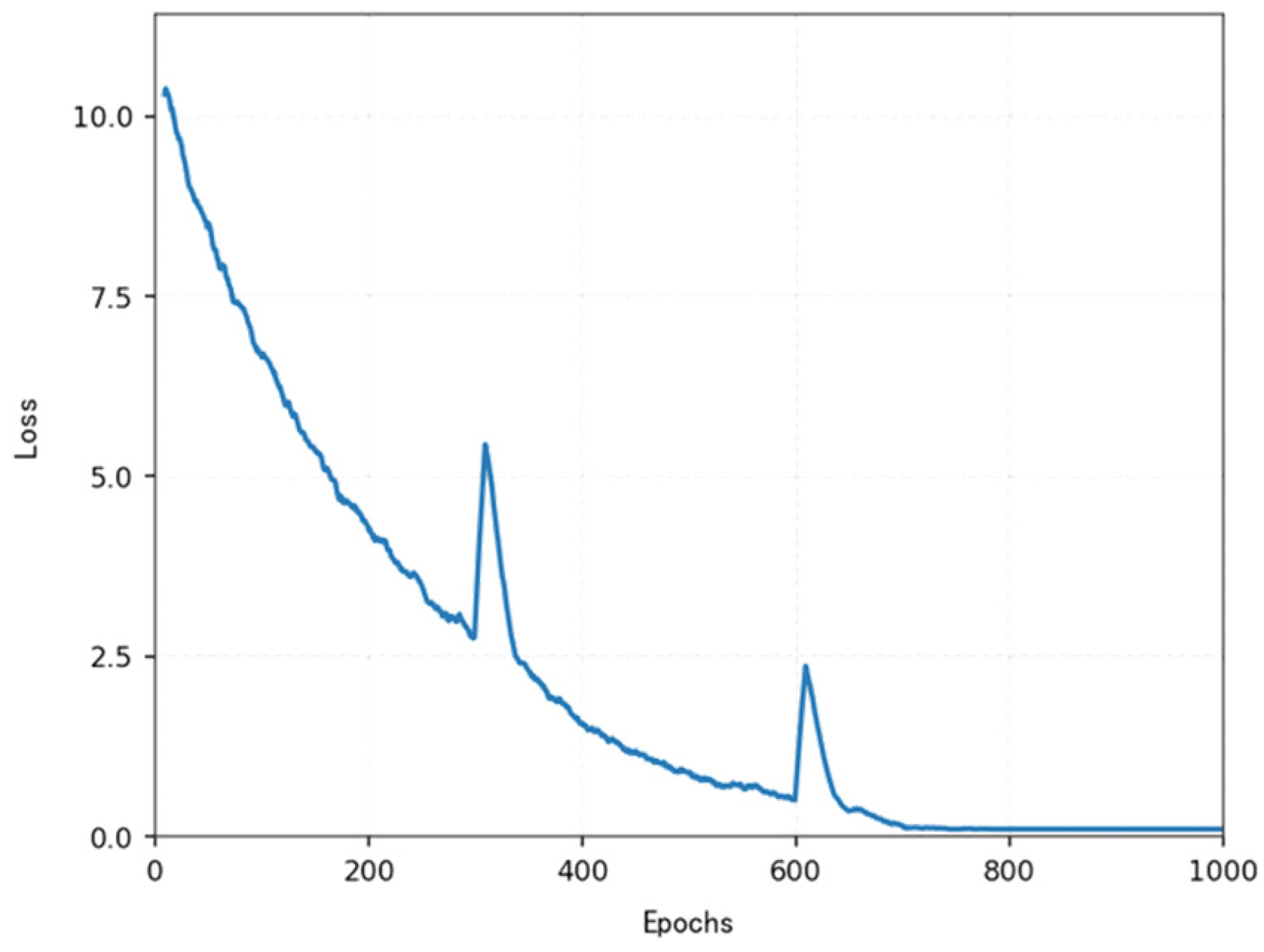
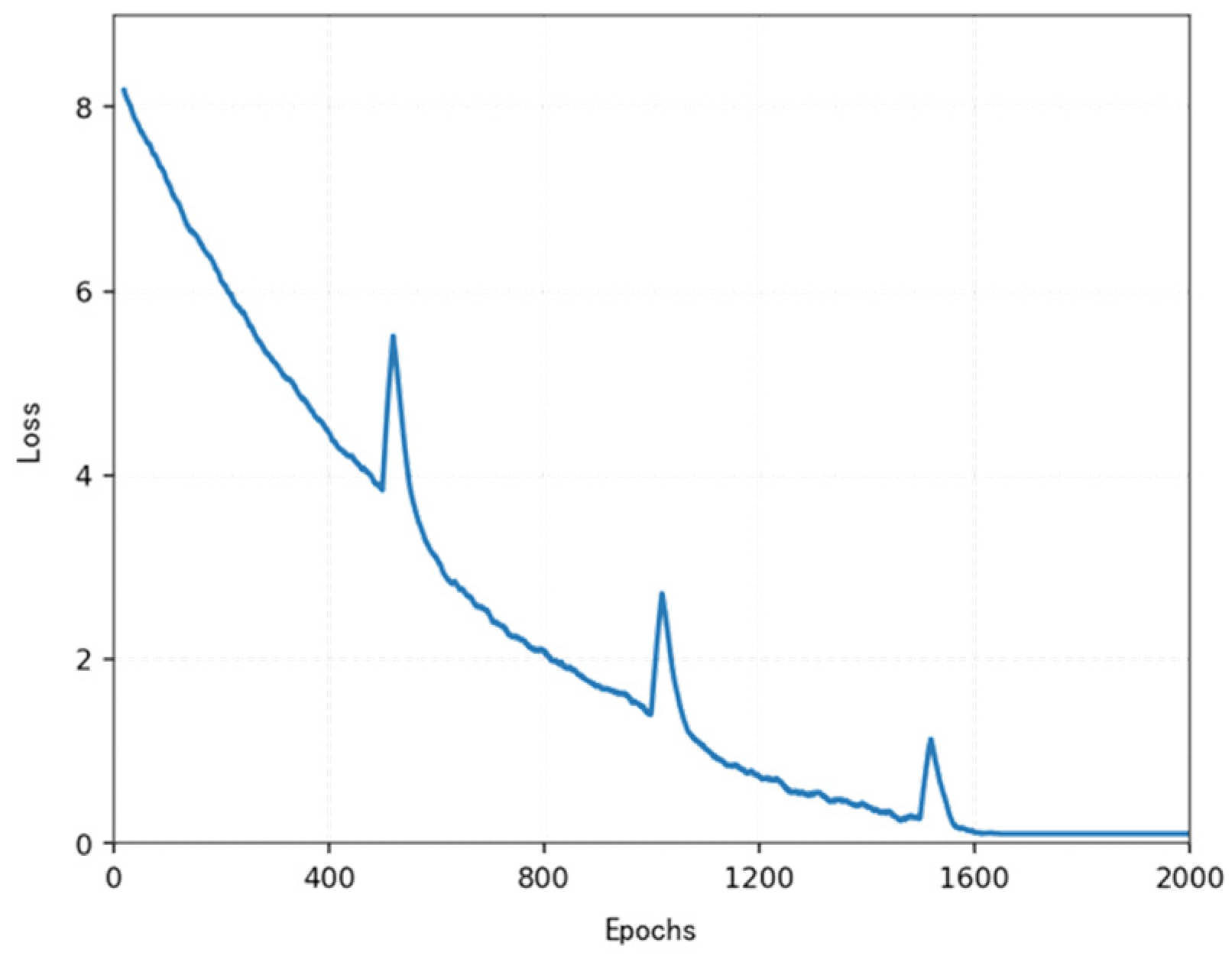
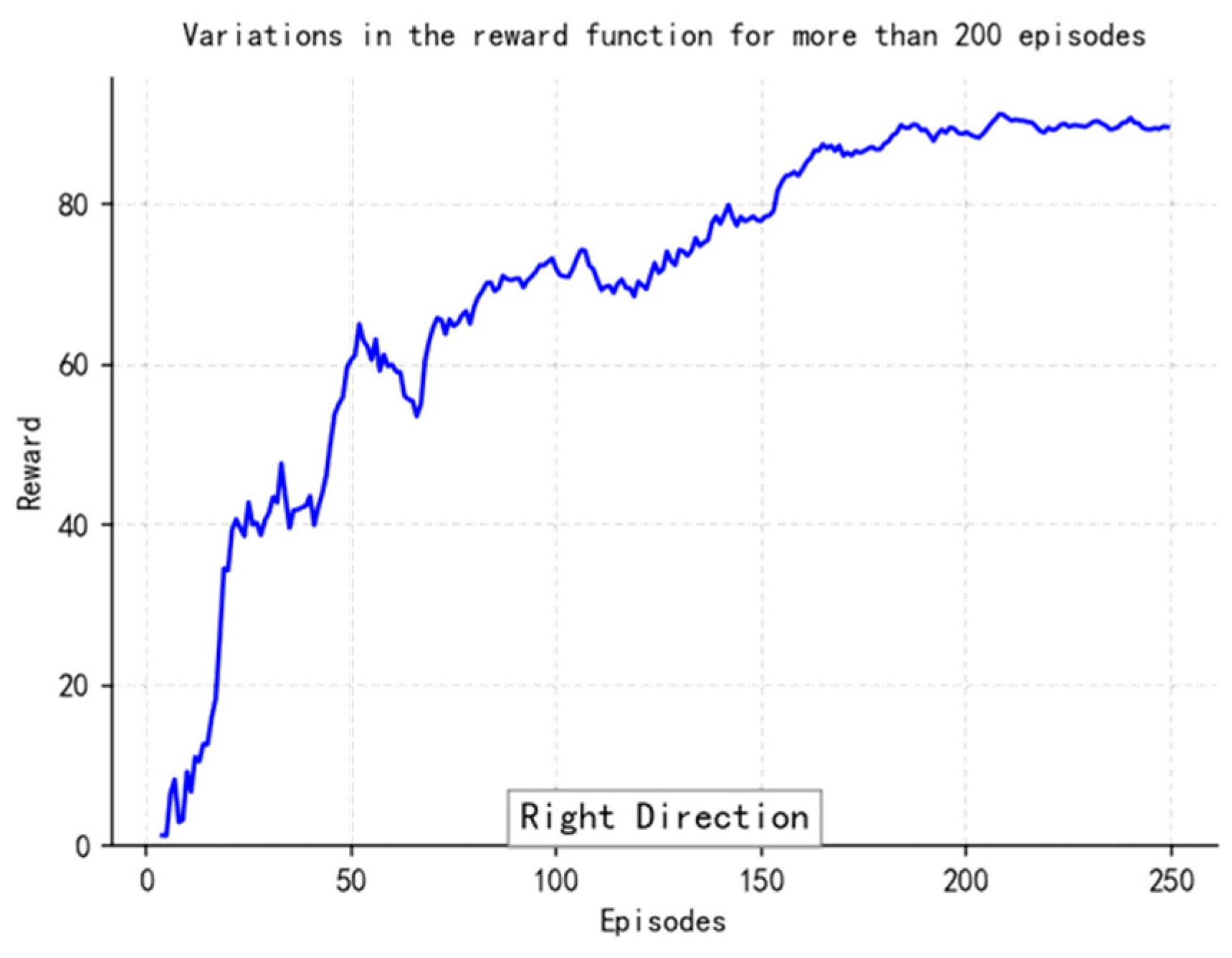
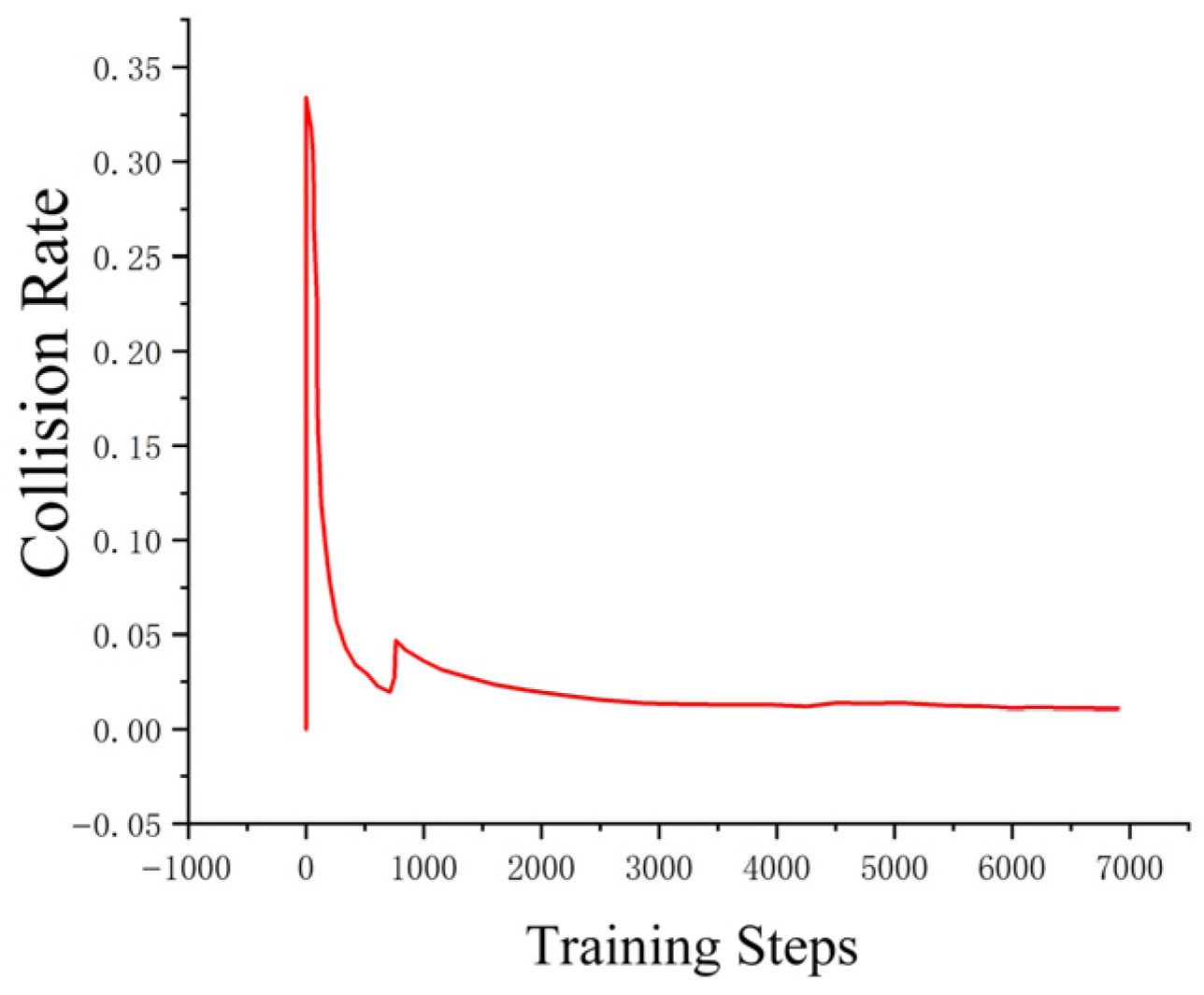
As shown in the
Figure 2 below, under the cooperation of the task decomposition module, dynamic extension module, and parallel calculation module, the planning time in million level grids decreases from 650 ms of traditional algorithm to only 3.3 ms, while maintaining good path quality and obstacle avoidance ability.
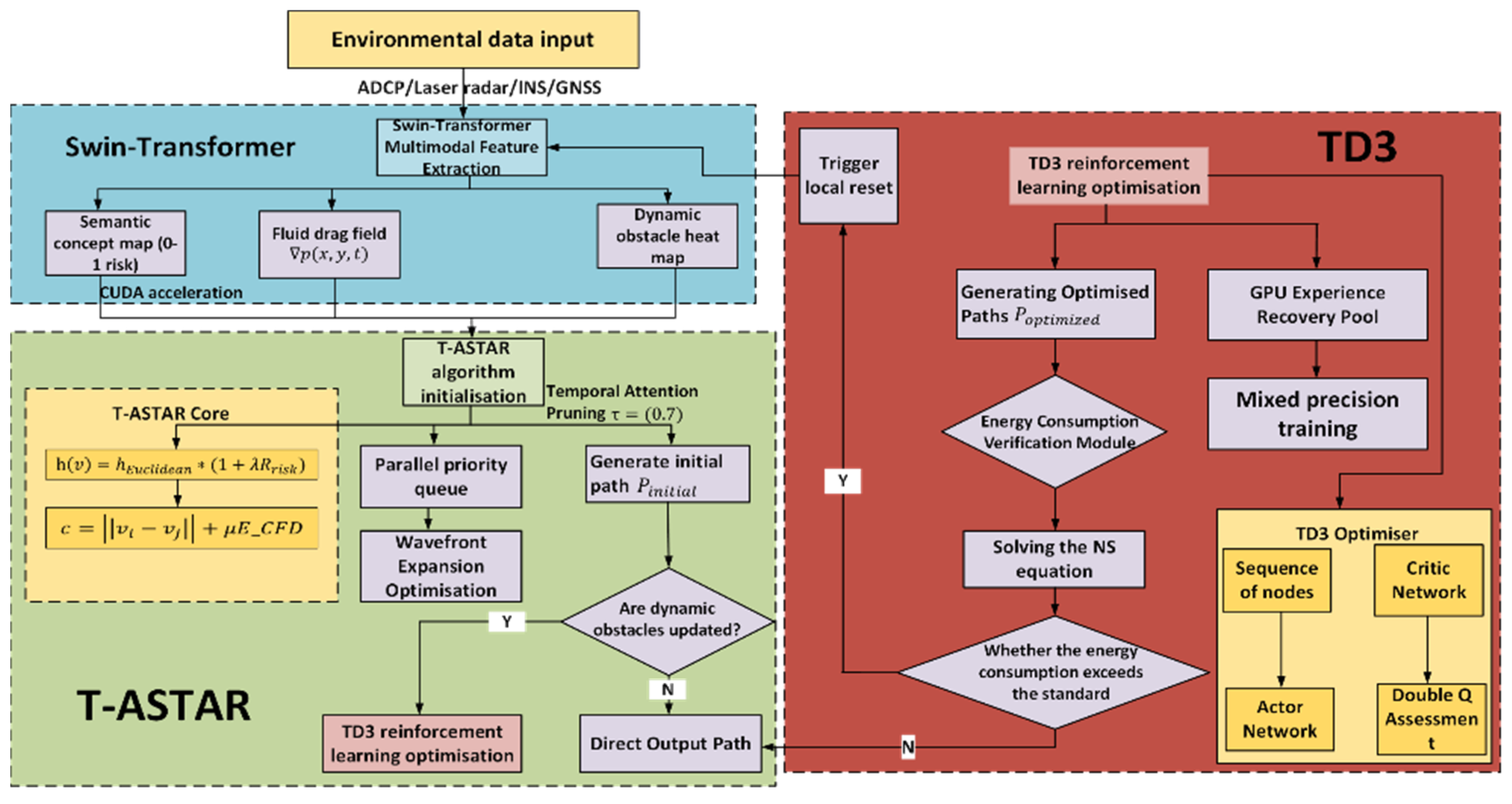
2.3.2. T-ASTAR + Energy Consumption Equation + TD3 + Swin-Transformer + CUDA-Accelerated Hybrid Path Planning Strategy Model
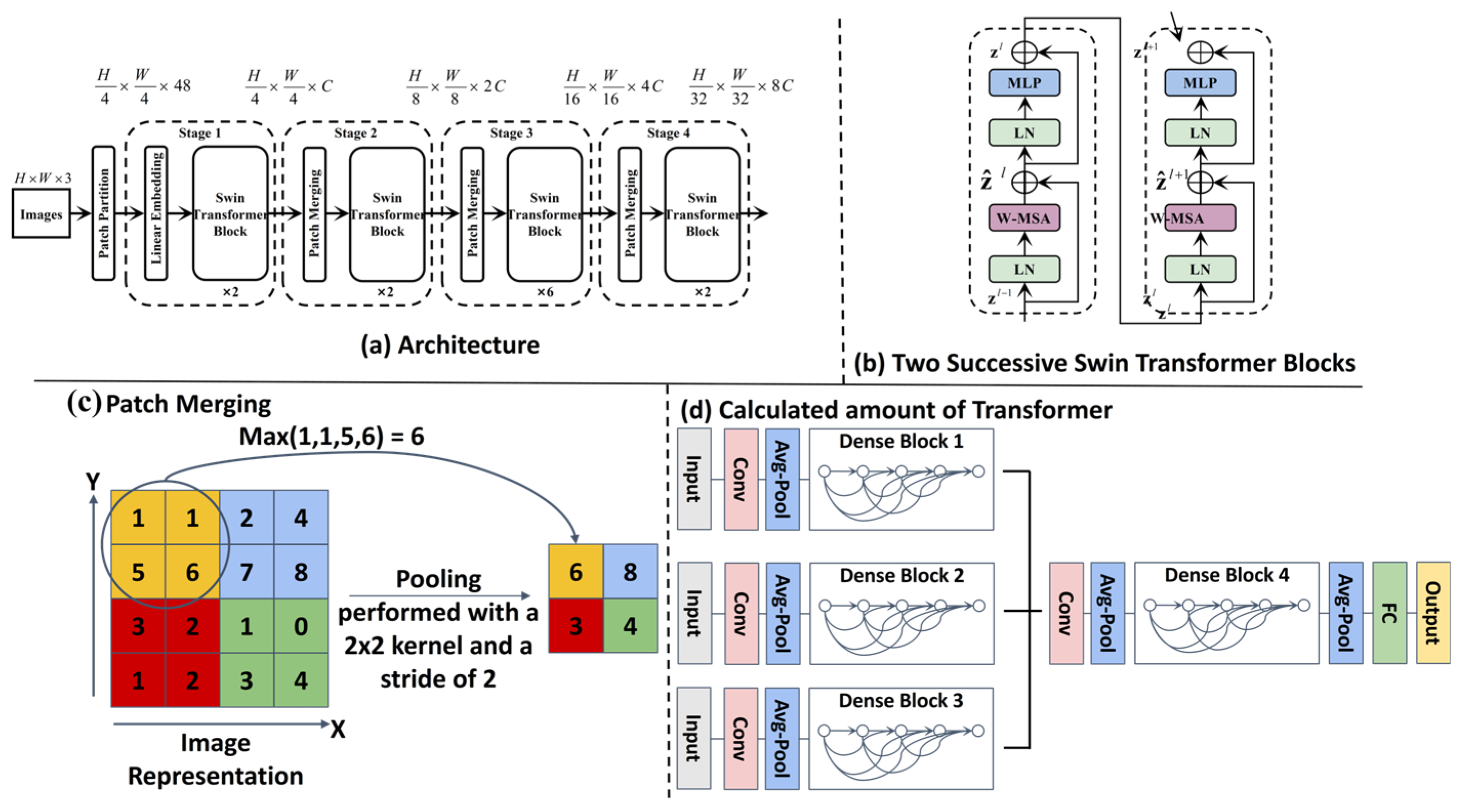
Unlike typical applications of Swin-Transformer for object classification, we repurpose it here as a dense risk predictor. This required training on a custom-annotated dataset where pixel values correspond to navigational risk, allowing the model to learn the subtle visual features unique to marine environments (
Figure 3).
- (1)
Configuration environment map of Swin-Transformer
We use Swin Transformer to process USV image data for good quality map drawing. The Swin Transformer captures important visual information such as obstacles, walkways, and terrain. The self-attention mechanism multi-level was used to capture picture materials for better-quality environmental recognition to draw feature pictures for our next-generation path plan update drawings.
Figure 4 shows the model of the swin-transformation frame diagram.
Figure 4 illustrates the novel adaptation of the Swin-Transformer architecture within our framework. Its key innovation lies not in the core Swin-Transformer blocks themselves, but in their repurposing for dense semantic risk map prediction in marine environments. Unlike standard applications for image classification, our model is specifically trained on pixel-level navigational risk annotations derived from challenging marine visual data (e.g., sun glare, choppy water, turbidity). This enables it to translate raw USV camera input into a fine-grained risk assessment map (where pixel intensity corresponds to navigational hazard probability), providing crucial environmental understanding for subsequent path planning modules (T-ASTAR, TD3). This transformation from a generic image classifier to a specialized marine risk perception engine is the figure’s primary significance.
- (2)
Path configuration method: Turning weight
According to the unmanned surface vehicle turning motion energy consumption characteristics, establish the turning cost quantification model under kinematics constraints. Through calculating the value of heading angle change by two adjacent paths’ formation through motion vector sequences, calculate the angle formed between any adjacent paths according to
, using the dot product formula cos θ to accurately calculate the turning angle.
and
are respectively the motion vectors of two adjacent navigation segments. For different motion levels, propose an automatic turning weight adjustment mechanism to quantify the influence of turning motion on energy consumption.
Among them, is the absolute value of the steering angle; is the hydrodynamic correction coefficient related to the Reynolds number. Through fitting CFD simulation data, the engineering expression can be obtained. The model encodes the nonlinear factors such as the ship’s differential pressure resistance when turning and the propeller power loss due to deflection into a calculable path evaluation index, guiding the planning algorithm to balance between path smoothness and energy consumption. Experiments have shown that compared with general geometric path optimization schemes, it can reduce up to 23.7% of the turning energy loss and ensure the integral value of the path curvature is less than 0.85 rad·m−1 to improve the stability of USV navigation in complex sea conditions.
- (3)
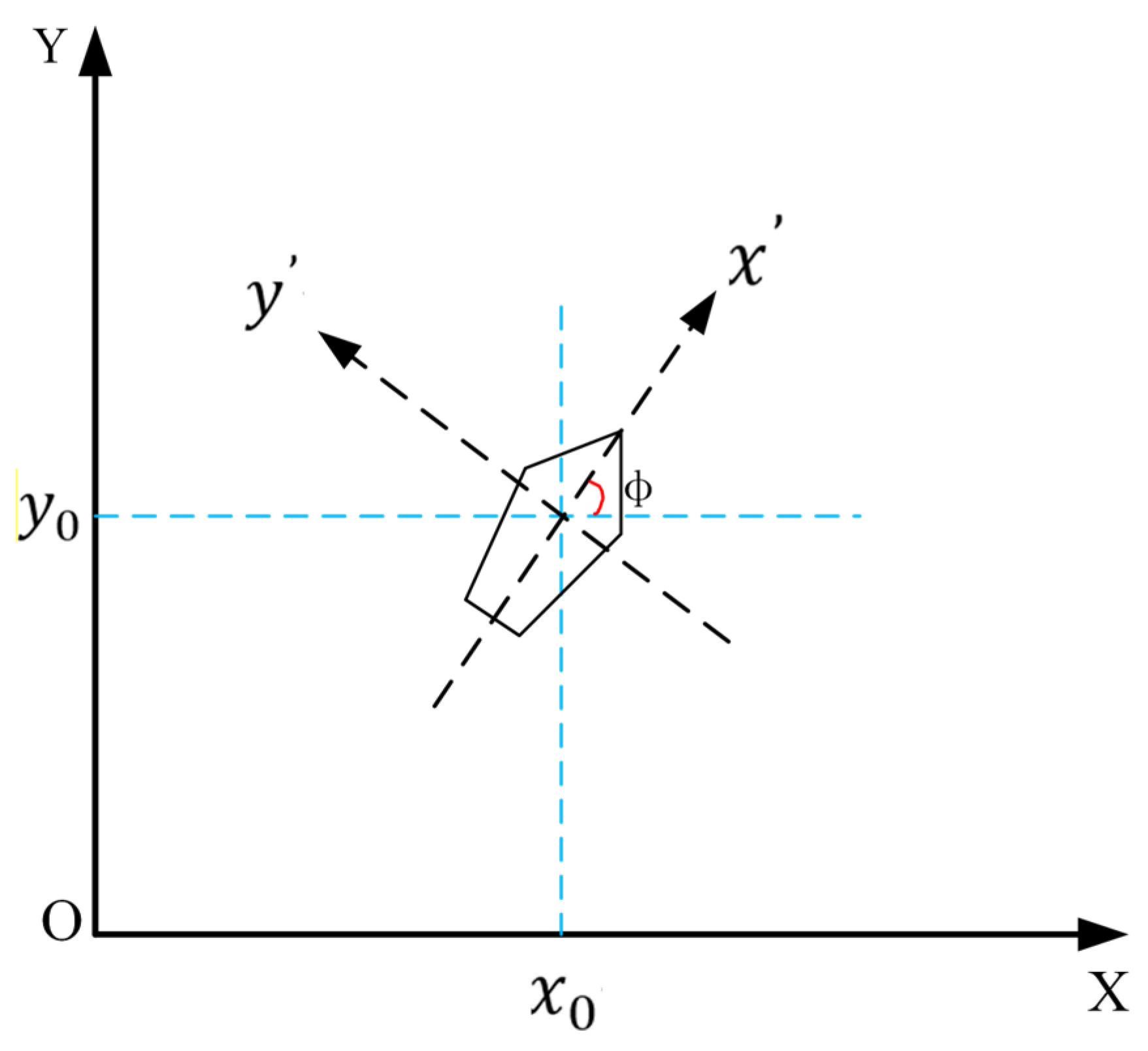
USV Dynamic Model
The USV is modeled as a 3-degree-of-freedom (3-DoF) rigid body with state vector
, where
denotes position,
heading angle,
surge velocity,
sway velocity, and
yaw rate. The kinematic equations are
Control inputs include surge thrust and yaw torque . Dynamic parameters feed a CFD-calibrated energy model (Equations (5) and (6)) rather than full dynamics, as hydrodynamic effects (added mass, damping) are embedded in the energy coefficient via Navier–Stokes simulations. This simplification maintains control feasibility while capturing dominant energy consumption patterns.
The USV’s onboard sensors (stereo camera, IMU, GPS) stream raw data to the perception module at 10 Hz. Swin-Transformer processes RGB images to output a semantic risk map (
Figure 4) and fuses IMU/GPS for real-time pose estimation
. These signals are transmitted via ROS topics to the planning layer, where T-ASTAR receives
and the risk map for global planning, while TD3 uses
and local obstacle data for reactive control. The three-degree-of-freedom hydrodynamic model is shown in
Figure 5.
- (4)
Design of path reward mechanism
The path reward mechanism for A* takes into account path length, turning cost, and energy consumption to ensure the USV avoids collisions while saving energy. The formula is
is path length, is turning cost, and is total energy consumption. More rewards mean shorter paths, less turning cost, and less energy used. This weight can help us balance the path length, smoothness, and energy use. When increasing , more energy can be saved while working to save energy. But when performing speedy tasks, the speed of the ’s path planning process will increase. We can adjust these weights to change the performance of different paths. For example, we could accept a longer path because it would need fewer turns and angles, which makes it more rewarding. It allows A* to balance between path length, turning cost, and energy consumption to plan efficient and energy-saving paths for USVs to travel through complicated environments.
- (5)
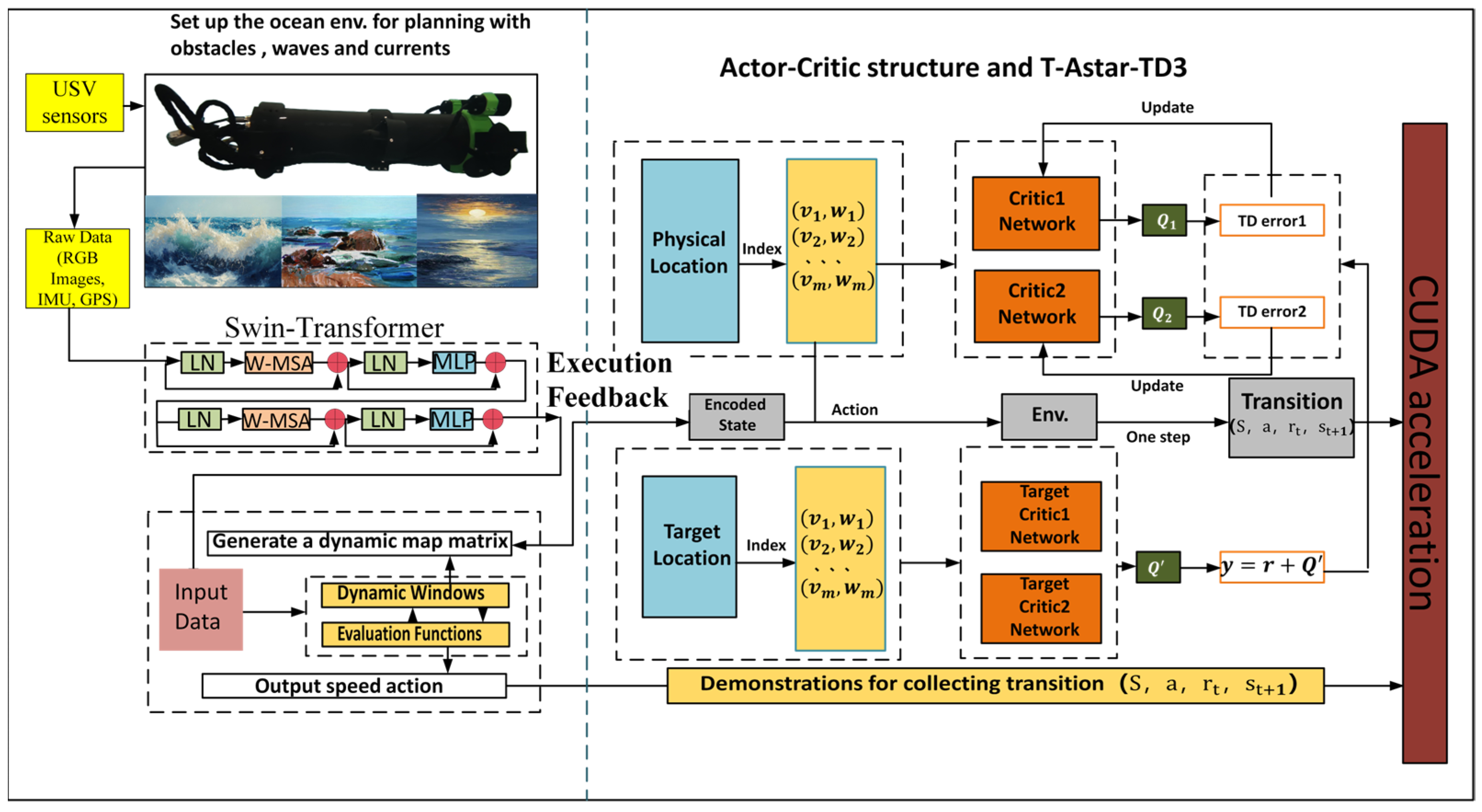
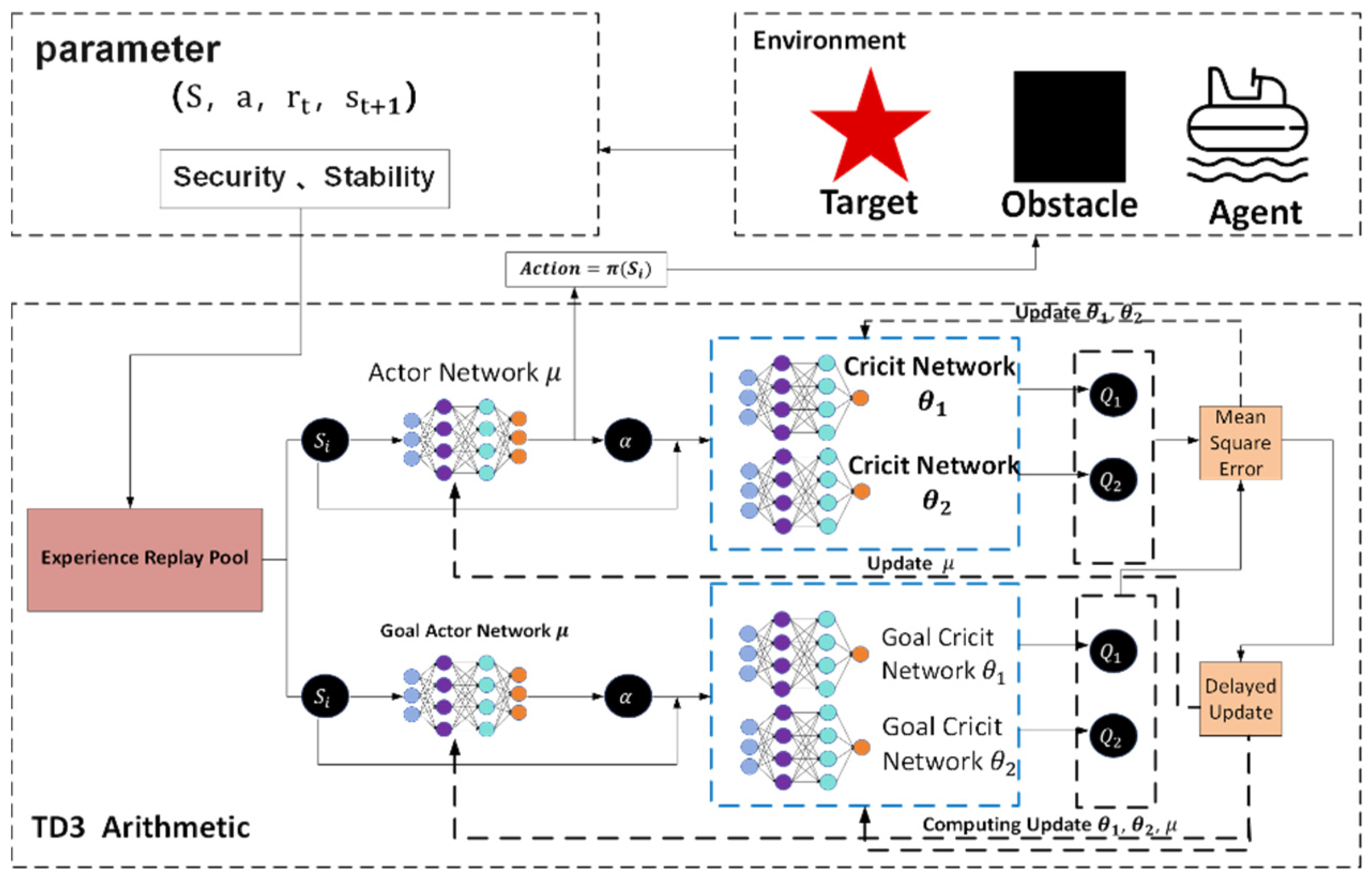
Parameter configuration of the TD3 deep reinforcement learning strategy model
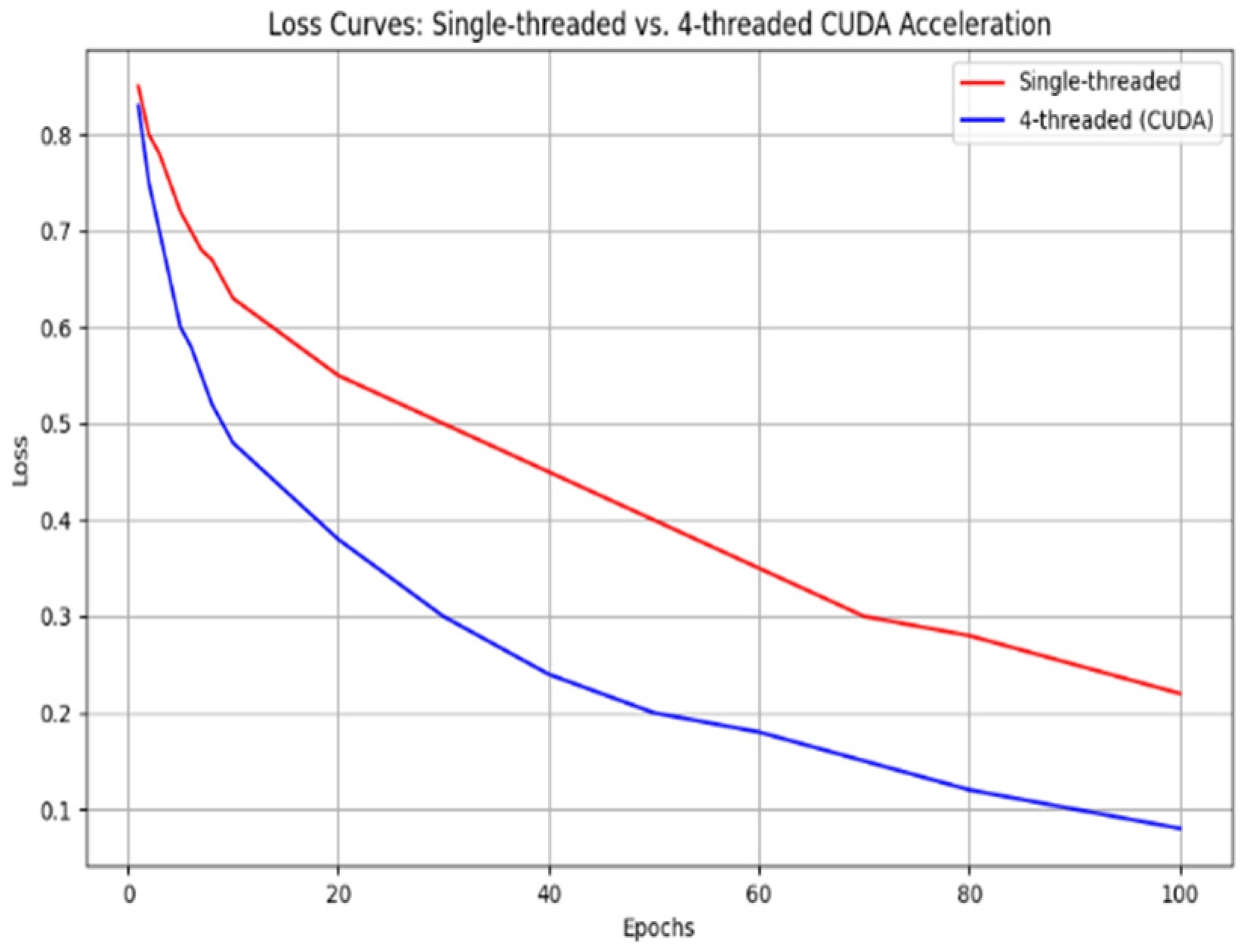
In order to achieve dynamic path optimization for the USV, this system designs a reinforcement learning strategy based on the TD3 algorithm to construct a strategic model. In the process design diagram shown in
Figure 6, based on PyTorch library, the collaborative working mode of the policy network and dual Q-value network is achieved, taking the three-dimensional information of state space (USV posture, local risk map, and energy coefficient) as input; after passing through the Actor network composed of the fully connected neural network (three layers, size: 256-128-64), the action guidance signal output by the action output layer is used as the basis for decision-making for the next driving behavior. In order to eliminate the bias caused by value estimation, the parallel separate type Q network structure is designed for the Critic network. At the same time, in order to improve the generalization ability of the algorithm to adapt to changes in different dynamic environments, the mechanism of delaying updating the policy (one actor is updated for two critic updates) and target network soft update coefficient τ = 0.005 is adopted to form a relatively stable training relationship, thus solving the problem of policy overestimation existing in the original DDPG algorithm.
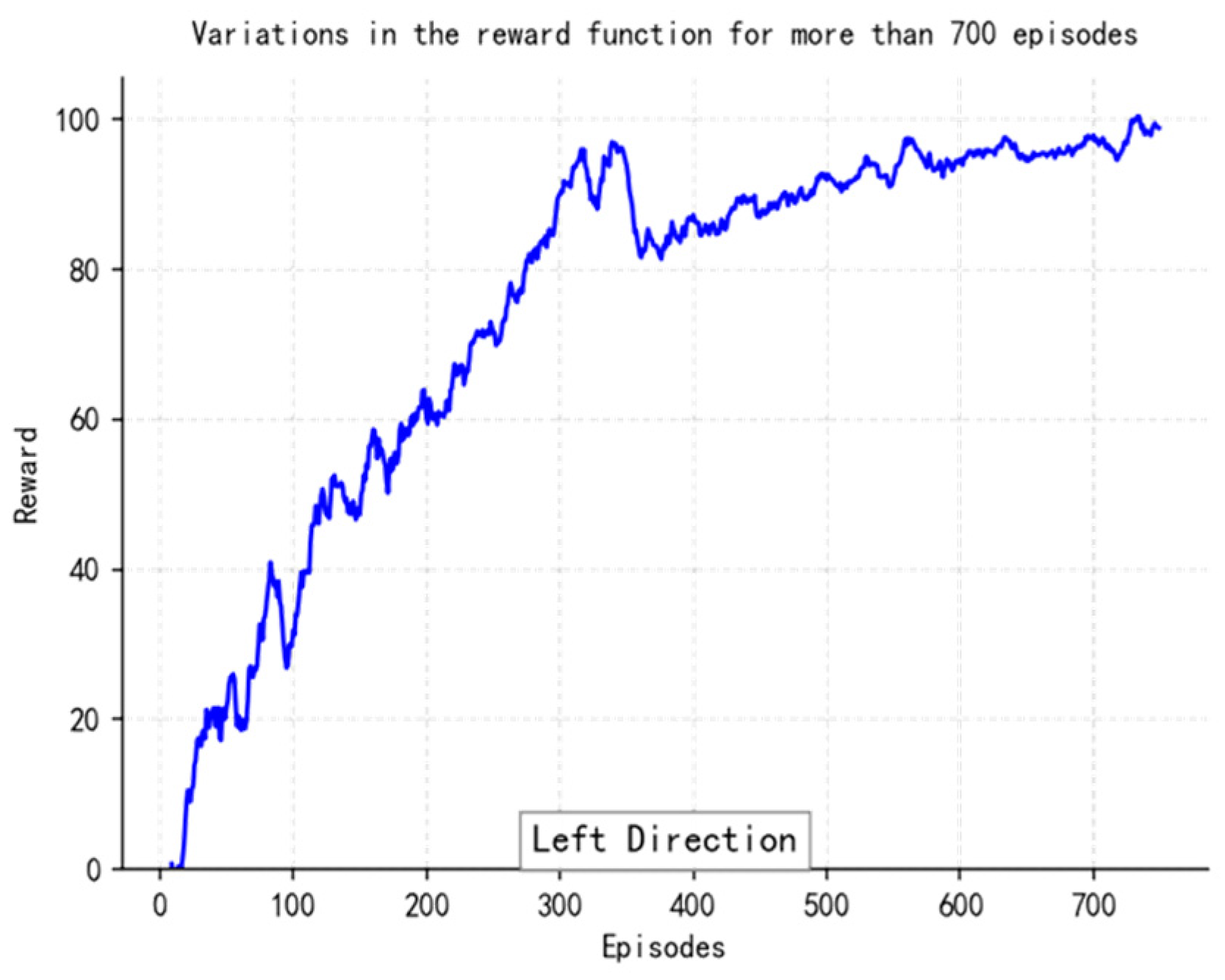
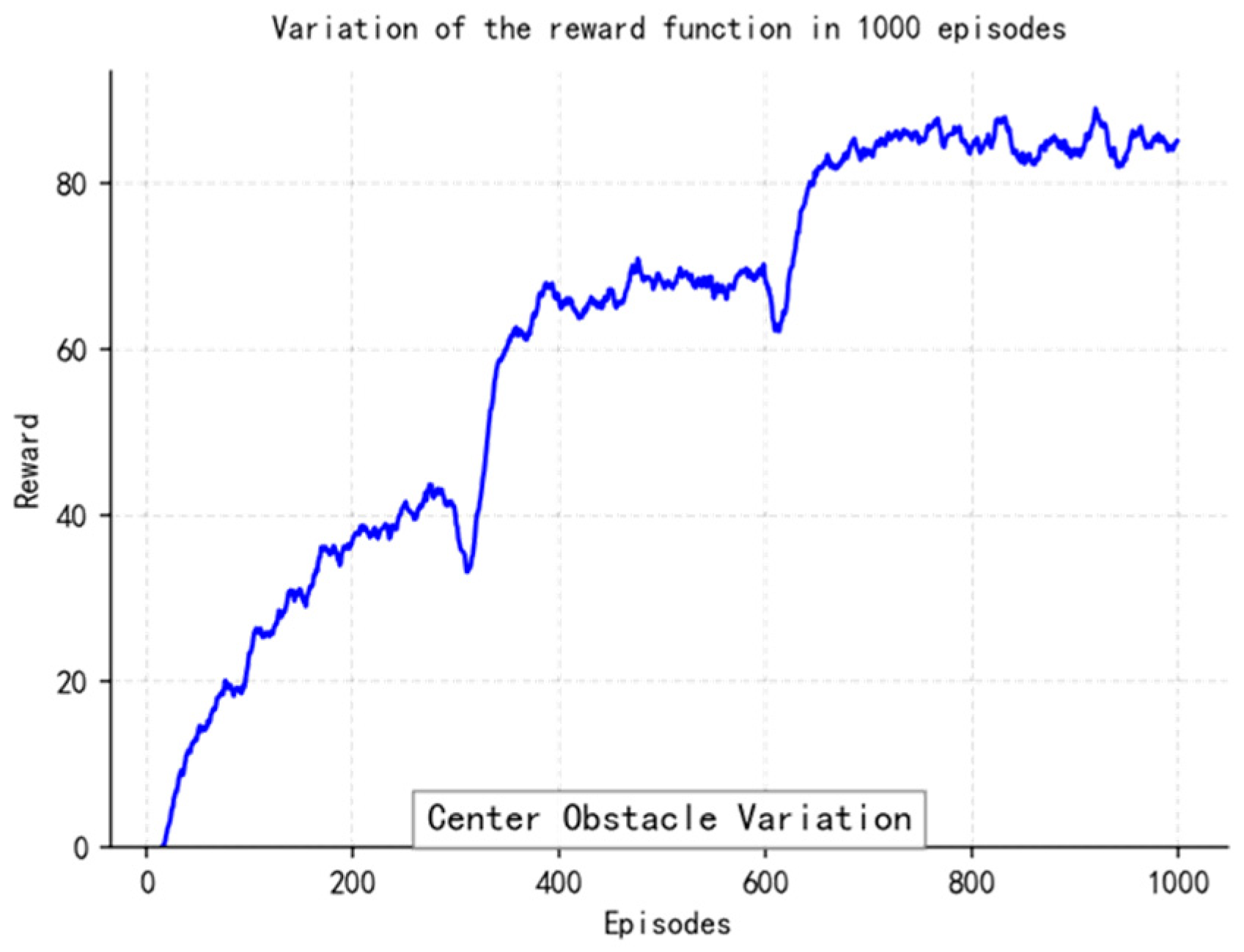
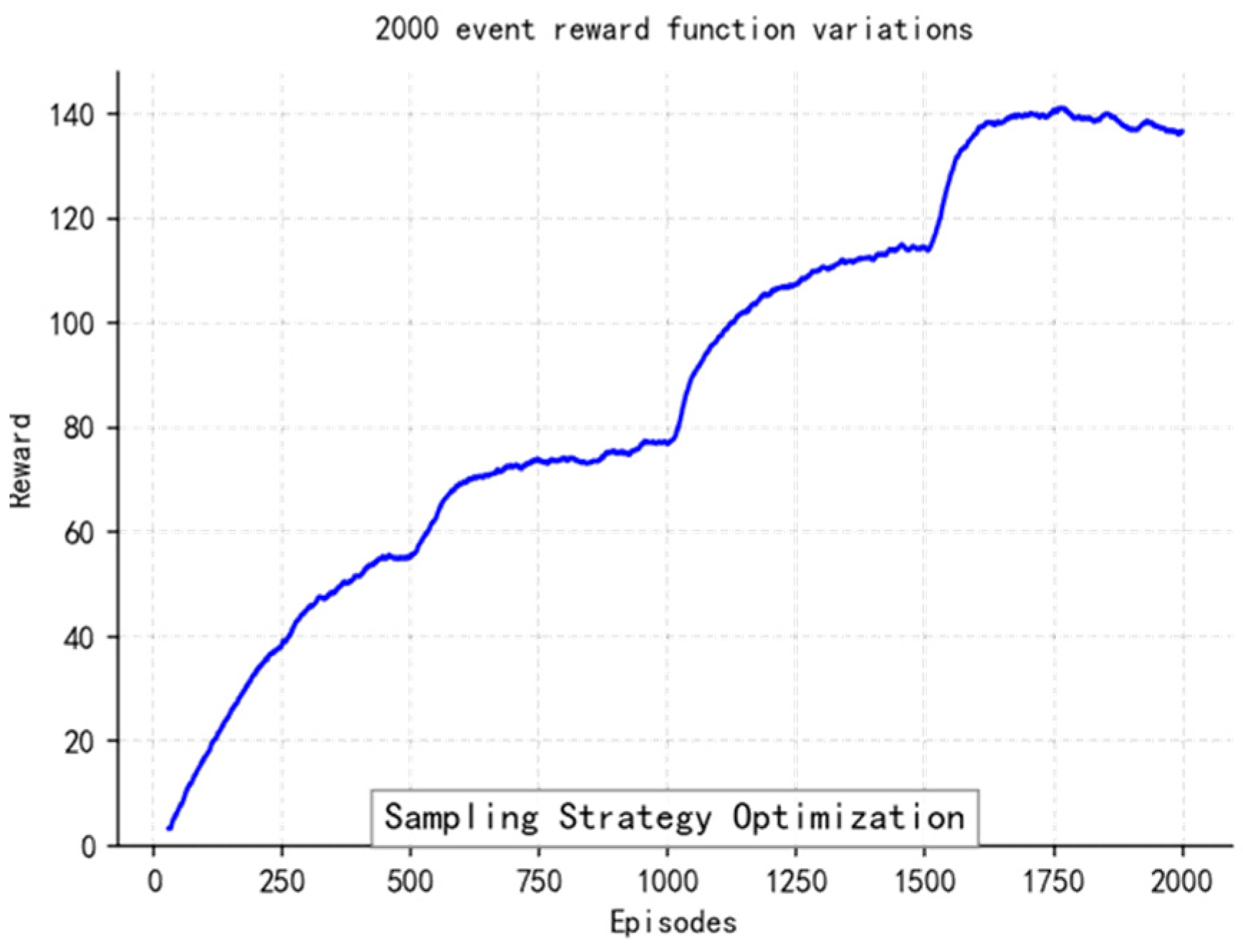
At the reward function design level, non-linear weighting is performed on the elements of path tracking error, change rate of heading angle, and energy consumption rate (the weight ratio was taken as 3.2:1). It is also necessary to use Gaussian noise (σ = 0.1) to inject strong exploratory robustness at the same time. The experience retraining buffer adopts a layered priority sampling scheme, multiplying the collision event sample’s priority by threefold so as to accelerate learning about obstacles. Dynamic selection of the local path optimizing window realizes an effective connection of global planning and local adjustment through a sliding time window mechanism (the length range of the window is 5–15 path points), allowing automatic adjustment of the optimal grain according to the current environment’s complexity, reducing the computing burden by 12% while enhancing system adaptability.
So, with this parameter setting situation combined with the deep sense-plan-control closed loop, the TD3 policy model can withstand the moving obstacle on schedule within one control period of 0.1 s, and its Q-network converges at a rate 1.8 times faster than the general DRL method’s. As we can see from its algorithm flow, illustrated in
Figure 6 above, the min operator strategy owned by the Critic doubly network and Policy gradient clipped in magnitude tactic (with max clipping quantity as 1.0) constitute together the anti-interference vital part enabling the USV to maintain track tracking firmly under water-flow interference.
- (6)
The interaction mechanism between T-ASTAR and TD3 and the key design of the TD3 model
To reach a destination smoothly along an efficient path, the navigation direction for the USV can be given in terms of commanded linear and angular () speeds obtained as action “at” from TD3 actor output, whereas the desired behavior during learning can be captured as td3 reward “rt” using goal achieving signal as reward for approaching the path segments like ASTAR’s target/end-of-local-path-points, also encouraging smooth motions (such as minimum rate of change in curvature/velocity value), arriving on time with conserved energy in navigating dynamic regions. By punishing undesired events such as hitting any object/person present in it by dynamic obstacle-detection perception function integrated in it that gives us safer surroundings awareness by Swin-transformer approach, T-distribution-based optimal control actions can also give our guidance process a wider selection region so that different behaviors/path options at the same stage provide high-level flexibility of action based on learned decision-making policy over multiple steps through the long-run goal-directed optimization phase.
With the above two major modules’ joint support toward achieving safe behavior at a maximum feasible degree within limited environment knowledge and resource access, both TD3 and the local sensor fused-Swim Transformer can thus achieve a new adaptive solution of dynamically providing useful path segments for performing necessary guidance/control tasks for high-quality maneuvers, thereby keeping our main focus towards making decisions about how to act next by generating behavior/policy with reference to its long-range goal being solved by TASTAR here, where we want the navigation planner T-ASTAR to work mainly during low search effort stages and TD3 to come into play when more efforts are needed.
- (7)
Energy consumption equation
The energy consumption model quantifies two main components: propulsion energy to overcome water resistance () and steering energy (). By assigning costs to both distance and turning, the planner can make informed trade-offs. For instance, a shorter path with a sharp 90° turn might consume less energy (e.g., 7.7 J) than a slightly longer path with a gentle 30° turn (e.g., 8.4 J), guiding the algorithm to select the most energy-efficient route.
The algorithm flowchart can be referred to in
Figure 7.


 ,
, 



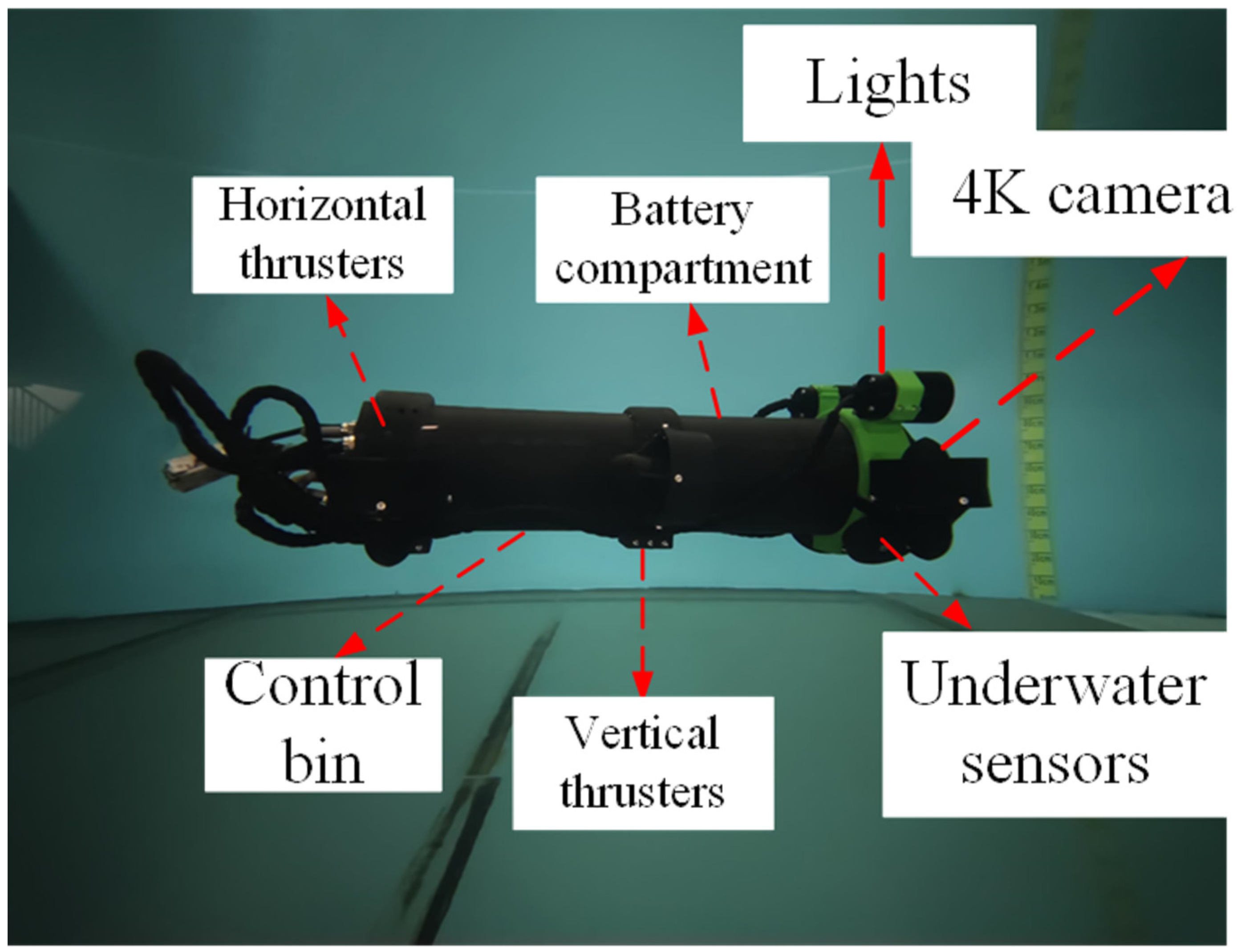




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}